- PyTorch 教程
- PyTorch——主页
- PyTorch——简介
- PyTorch——安装
- 神经网络的数学构件
- PyTorch——神经网络基础
- 机器学习的通用工作流
- 机器学习与深度学习
- 实现第一个神经网络
- 神经网络到功能模块
- PyTorch——术语
- PyTorch——加载数据
- PyTorch——线性回归
- PyTorch——卷积神经网络
- PyTorch——循环神经网络
- PyTorch——数据集
- PyTorch——卷积简介
- 从头开始训练一个卷积
- PyTorch——卷积中的特征提取
- PyTorch——卷积的可视化
- 使用卷积进行序列处理
- PyTorch——词嵌入
- PyTorch——递归神经网络
- PyTorch 有用资源
- PyTorch——快速指南
- PyTorch——有用资源
- PyTorch——讨论
PyTorch——使用卷积进行序列处理
在本章中,我们提出一种替代方法,而这种方法依赖于同时在两个序列间的一个二维卷积神经网络。我们网络的每一层都根据迄今为止产生的输出序列重新编码源标记。因此,类注意力属性贯穿整个网络。
这里,我们重点是利用数据集中的值从特定池中创建顺序网络。此过程也最适用于“图像识别模块”。
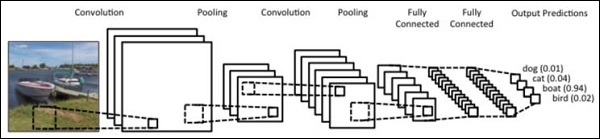
使用 PyTorch 使用卷积创建序列处理模型的步骤如下——
步骤 1
导入使用卷积进行序列处理所需的模块。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D import numpy as np
步骤 2
执行必要的操作以使用以下代码在相应序列中创建模式——
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
步骤 3
编译模型并按照展示在下面——提到的常规神经网络模型中适应模式−
model.compile(loss =
keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics =
['accuracy'])
model.fit(x_train, y_train,
batch_size = batch_size, epochs = epochs,
verbose = 1, validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
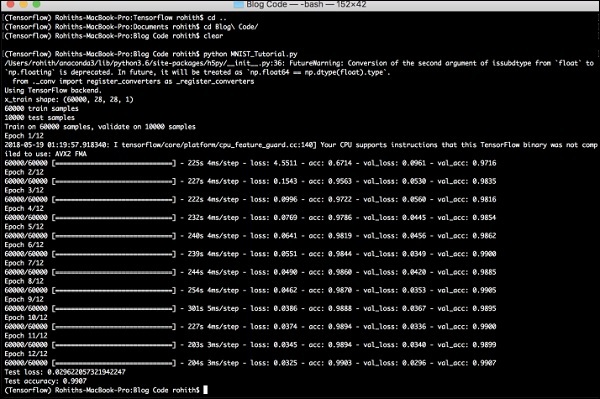
生成的输出如下——
广告