- Scikit Learn 教程
- Scikit Learn - 首页
- Scikit Learn - 简介
- Scikit Learn - 建模过程
- Scikit Learn - 数据表示
- Scikit Learn - 估计器API
- Scikit Learn - 约定
- Scikit Learn - 线性模型
- Scikit Learn - 扩展线性模型
- 随机梯度下降
- Scikit Learn - 支持向量机
- Scikit Learn - 异常检测
- Scikit Learn - K近邻算法
- Scikit Learn - KNN学习
- 朴素贝叶斯分类
- Scikit Learn - 决策树
- 随机决策树
- Scikit Learn - 集成方法
- Scikit Learn - 聚类方法
- 聚类性能评估
- 使用PCA进行降维
- Scikit Learn 有用资源
- Scikit Learn - 快速指南
- Scikit Learn - 有用资源
- Scikit Learn - 讨论
Scikit Learn - K近邻分类器
此分类器名称中的K代表k个最近邻,其中k是由用户指定的整数。因此,顾名思义,此分类器实现基于k个最近邻的学习。k值的选取取决于数据。让我们借助一个实现示例来进一步理解它。
实现示例
在这个例子中,我们将使用scikit-learn的KNeighborsClassifier在名为Iris Flower数据集的数据集上实现KNN。
此数据集每个不同的鸢尾花物种(setosa、versicolor、virginica)有50个样本,即总共150个样本。
对于每个样本,我们有4个特征,分别命名为萼片长度、萼片宽度、花瓣长度、花瓣宽度。
首先,导入数据集并打印特征名称,如下所示:
from sklearn.datasets import load_iris iris = load_iris() print(iris.feature_names)
输出
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
示例
现在我们可以打印目标,即表示不同物种的整数。这里0 = setosa,1 = versicolor,2 = virginica。
print(iris.target)
输出
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 ]
示例
以下代码行将显示目标的名称:
print(iris.target_names)
输出
['setosa' 'versicolor' 'virginica']
示例
我们可以使用以下代码行检查观察值和特征的数量(iris数据集有150个观察值和4个特征):
print(iris.data.shape)
输出
(150, 4)
现在,我们需要将数据分成训练数据和测试数据。我们将使用Sklearn的train_test_split函数将数据按70(训练数据)和30(测试数据)的比例分割:
X = iris.data[:, :4] y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
接下来,我们将使用Sklearn预处理模块进行数据缩放,如下所示:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
示例
以下代码行将给出train和test对象的形状:
print(X_train.shape) print(X_test.shape)
输出
(105, 4) (45, 4)
示例
以下代码行将给出新的y对象的形状:
print(y_train.shape) print(y_test.shape)
输出
(105,) (45,)
接下来,从Sklearn导入KNeighborsClassifier类,如下所示:
from sklearn.neighbors import KNeighborsClassifier
为了检查准确性,我们需要导入Metrics模型,如下所示:
from sklearn import metrics
We are going to run it for k = 1 to 15 and will be recording testing accuracy, plotting it, showing confusion matrix and classification report:
Range_k = range(1,15)
scores = {}
scores_list = []
for k in range_k:
classifier = KNeighborsClassifier(n_neighbors=k)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
scores[k] = metrics.accuracy_score(y_test,y_pred)
scores_list.append(metrics.accuracy_score(y_test,y_pred))
result = metrics.confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = metrics.classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
示例
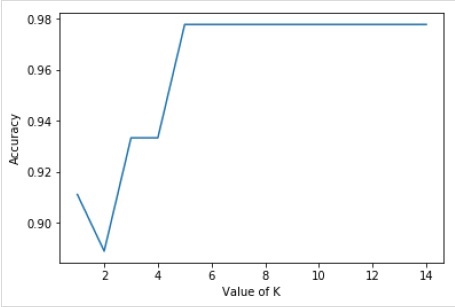
现在,我们将绘制K值与相应的测试精度之间的关系。这将使用matplotlib库完成。
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(k_range,scores_list)
plt.xlabel("Value of K")
plt.ylabel("Accuracy")
输出
Confusion Matrix:
[
[15 0 0]
[ 0 15 0]
[ 0 1 14]
]
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 15
1 0.94 1.00 0.97 15
2 1.00 0.93 0.97 15
micro avg 0.98 0.98 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Text(0, 0.5, 'Accuracy')
示例
对于上述模型,我们可以选择K的最优值(由于精度在此范围内最高,因此任何介于6到14之间的值),例如8,并重新训练模型,如下所示:
classifier = KNeighborsClassifier(n_neighbors = 8) classifier.fit(X_train, y_train)
输出
KNeighborsClassifier(
algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = None, n_neighbors = 8, p = 2,
weights = 'uniform'
)
classes = {0:'setosa',1:'versicolor',2:'virginicia'}
x_new = [[1,1,1,1],[4,3,1.3,0.2]]
y_predict = rnc.predict(x_new)
print(classes[y_predict[0]])
print(classes[y_predict[1]])
输出
virginicia virginicia
完整的可运行程序
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.target_names)
print(iris.data.shape)
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print(X_train.shape)
print(X_test.shape)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
Range_k = range(1,15)
scores = {}
scores_list = []
for k in range_k:
classifier = KNeighborsClassifier(n_neighbors=k)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
scores[k] = metrics.accuracy_score(y_test,y_pred)
scores_list.append(metrics.accuracy_score(y_test,y_pred))
result = metrics.confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = metrics.classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(k_range,scores_list)
plt.xlabel("Value of K")
plt.ylabel("Accuracy")
classifier = KNeighborsClassifier(n_neighbors=8)
classifier.fit(X_train, y_train)
classes = {0:'setosa',1:'versicolor',2:'virginicia'}
x_new = [[1,1,1,1],[4,3,1.3,0.2]]
y_predict = rnc.predict(x_new)
print(classes[y_predict[0]])
print(classes[y_predict[1]])
广告