- Seaborn 教程
- Seaborn - 首页
- Seaborn - 简介
- Seaborn - 环境设置
- 导入数据集和库
- Seaborn - 图表美学
- Seaborn - 颜色调色板
- Seaborn - 直方图
- Seaborn - 核密度估计
- 可视化成对关系
- Seaborn - 绘制分类数据
- 观测值的分布
- Seaborn - 统计估计
- Seaborn - 绘制宽格式数据
- 多面板分类图
- Seaborn - 线性关系
- Seaborn - Facet Grid
- Seaborn - Pair Grid
- 函数参考
- Seaborn - 函数参考
- Seaborn 有用资源
- Seaborn - 快速指南
- Seaborn - 有用资源
- Seaborn - 讨论
Seaborn.load_dataset() 方法
Seaborn.load_dataset() 方法用于加载Seaborn库中内置的数据集。为了描述seaborn或创建可重复的错误报告示例,此函数提供了对一些示例数据集的快速访问。
日常使用不需要此方法。为了对分类变量创建合适的顺序,对某些数据集进行了一小部分预处理。
语法
以下是seaborn.load_dataset()方法的语法:
seaborn.load_dataset(name, cache=True, data_home=None, **kws)
参数
以下是seaborn.load_dataset()的参数:
| 序号 | 参数和描述 |
|---|---|
| 1 | 名称 (Name) 接受字符串值,它是数据集的名称。 |
| 2 | 缓存 (Cache) 接受布尔值,这是一个可选参数。如果为True,则首先尝试从本地缓存加载,如果需要下载则保存到缓存。 |
| 3 | 数据主目录 (Data_home) 此可选参数接受字符串值,它是设置缓存数据所在的目录。 |
返回值
此方法返回一个pandas DataFrame。
加载数据集
为了绘制图表,我们需要数据,如果所需格式的数据和所需数据没有现成可用,可以使用Seaborn库中提供的数据集。
Seaborn除了是一个统计图表工具包外,还包含各种默认数据集。我们将使用一个内置数据集作为默认数据集的示例。
让我们在第一个示例中考虑tips数据集。“tips”数据集包含关于可能在餐厅用餐的人的信息,以及他们是否给服务员留下小费,以及他们的性别、吸烟状况和其他因素。
get_dataset_names() 方法用于检索Seaborn中所有可用内置数据集的名称。
seaborn.get_dataset_names()
load_dataset() 方法用于将名称为name的数据集加载到数据结构中。
Tips=seaborn.load_dataset('tips')
以上代码行将名称为“tips”的数据集加载到名为tips的数据结构中。因此,此方法有助于从库中加载数据集。
示例1
以下是一个加载titanic数据集的示例
import seaborn as sns
import matplotlib.pyplot as plt
dts= sns.load_dataset("titanic")
dts.head()
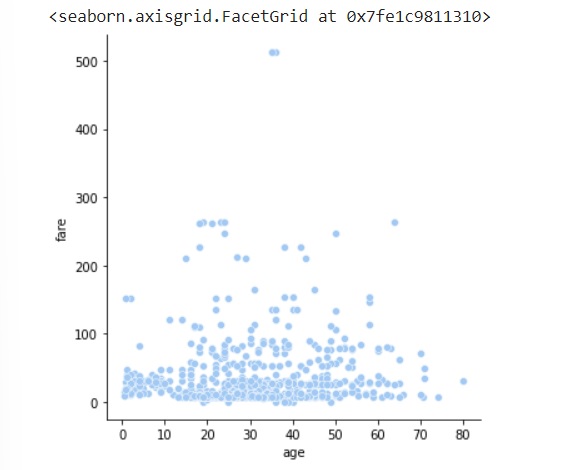
sns.relplot(data=dts, x="age", y="fare")
plt.show()
输出
以下是上述示例的输出:
示例2
在下面的示例中,我们加载tips数据集:
import seaborn as sns
import matplotlib.pyplot as plt
tips=sns.load_dataset("tips")
tips.head()
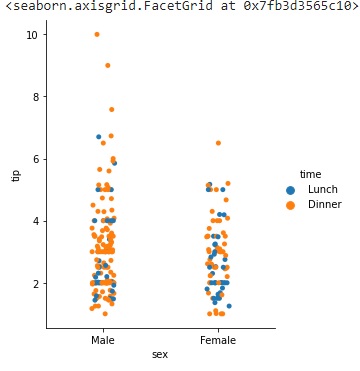
sns.catplot(data=tips,x="sex",y="tip",hue="time",height=5, aspect=.8)
plt.show()
输出
这将生成以下输出:
示例3
让我们来看另一个示例:
import seaborn as sns
import matplotlib.pyplot as plt
exercise=sns.load_dataset("exercise")
exercise.head()
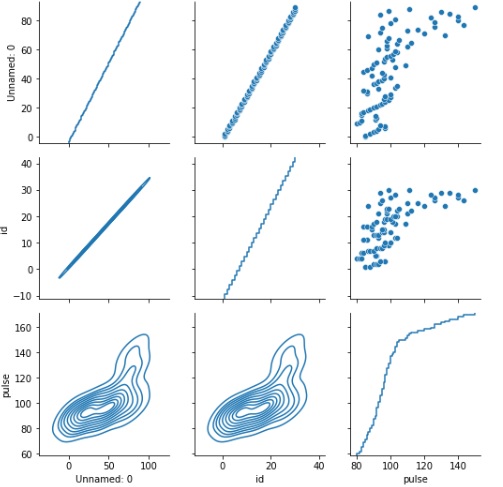
g=sns.PairGrid(exercise)
g.map_upper(sns.scatterplot)
g.map_lower(sns.kdeplot)
g.map_diag(sns.ecdfplot)
plt.show()
输出
执行后,以上示例将生成以下示例:
seaborn_utility_functions_introduction.htm
广告