
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Matplotlib 在 Python 中分析和可视化地震数据
使用 Python 的 matplotlib 库分析地震数据可以提供关于地震频率、震级和位置的宝贵见解,这有助于预测和减轻其影响。在本文中,我们将探讨如何使用 Python 和 Matplotlib(一个流行的数据可视化库)来分析和可视化地震数据。我们将逐步向您展示如何将地震数据加载到 Python 中,清理和预处理数据,以及创建可视化效果以更好地理解数据中的模式和趋势。
介绍
与数据的文字描述相比,人类大脑更容易理解数据的视觉表示。当我们看到图片时,更容易理解它。数据集是关于特定主题的原始信息集合。在本文中,我们有一个地震数据集,它以 CSV 文件的形式存在。我们需要分析和可视化数据集以了解数据集中的趋势和模式,以便我们可以预测未来可能发生的情况。例如,在本文中,我们将使用地震数据集,使用 matplotlib,我们将分析和可视化数据以了解过去几年地震的强度模式,然后我们可以预测未来地震的强度。
为了可视化和分析数据集,我们使用一个名为 Matplotlib 的 Python 库。我们将详细讨论什么是 matplotlib 以及如何使用它来分析和可视化数据集。
数据可视化
图形为检查数据提供了良好的工具,这对于呈现结果至关重要。数据可视化这个术语比较新。它反映了一个概念,即它不仅仅是事实的图形表示(而不是使用文本形式)。
这对于识别和理解数据集,以及对趋势、错误数据、异常值等进行分类特别有用。只需少量主题专业知识,数据可视化就可以使用绘图和图表来传达和说明重要的联系。
Matplotlib
在 Python 中,有一个名为 Matplotlib 的包,用于数据可视化,并且基于 Numpy 数组。它对于图形用户界面、shell 脚本、web 应用程序等非常有用。
2002 年,John D. Hunter 最初开发了 matplotlib。它是在类似 BSD 的许可下提供的,并且有一个活跃的开发人员社区在开发它。2003 年发布了该程序的第一个版本,而今天,2019 年 7 月 1 日,发布了该程序的最新版本 3.1.1。
随着 Matplotlib 1.2 版的发布,增加了对 Python3 的支持。当前也是最后一个与 Python 2.6 兼容的 Matplotlib 版本是 1.4 版。
数据集
本文中使用的数据集取自 CORGIS 数据集项目,文件名是 earthquake.csv。
我们将在接下来的代码中分析和准备数据集。
使用 matplotlib 分析和可视化地震数据
现在我们将看到如何使用 Python 和 matplotlib 分析和可视化地震数据。
导入库和数据集
我们将首先导入所有重要的库。
Pandas − 它有助于分析数据集并将数据帧存储为二维数组格式。
Seaborn/Matplotlib − 这两者都用于可视化数据
import pandas as pdd import numpy as npp import matplotlib.pyplot as pltt import seaborn as sbb
现在让我们加载数据集。我们将数据集加载到 Python 数据帧中,以便可以轻松访问它。
df1 = pdd.read_csv('C:/Users/Tutorialspoint/Downloads/earthquakes.csv')
df1.shape
输出
(8394,19)
我们将查看列中的数据,以了解数据中存在多少空值以及列中数据的类型。
df1.info()
输出
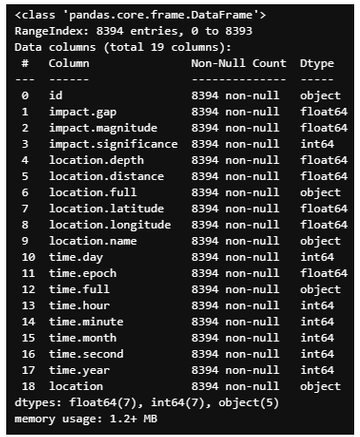
为了了解数据集的分布情况,我们将查看数据集的一些统计量。
df1.describe()
输出

从上述数据集描述中,我们可以得出结论,地震发生的最大震级为 7.7,最大深度为 622。
探索性数据分析
此分析用于使用图表和图表来探索数据中的趋势和模式。
pltt.figure(figsize=(10, 5))
x1 = df1.groupby('time.year').mean()['location.depth']
x1.plot.bar()
pltt.show()
输出
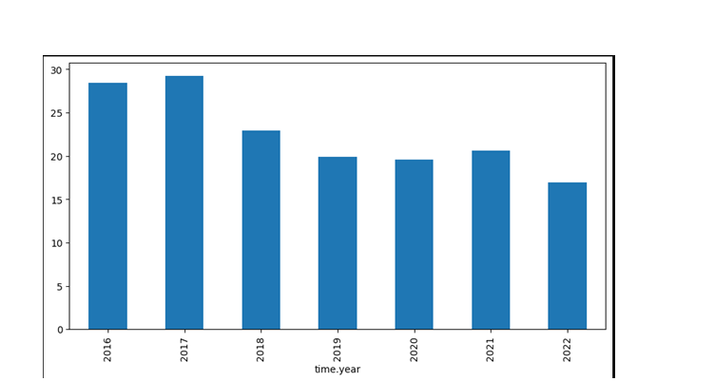
从上面的条形图中,我们可以注意到,2016 年以后地震次数增加,2017 年以后连续三年逐渐减少,然后增加,2021 年以后再次减少。
fig1 = pltt.figure() ax1 = fig1.add_axes([.1, .1, 2, 1]) ax1.plot(df1['impact.magnitude'])
输出
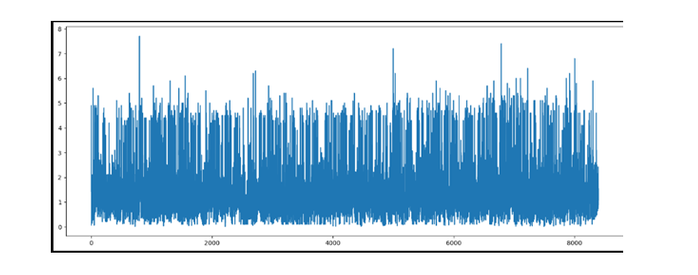
pltt.figure(figsize=(10, 5)) sbb.lineplot(data=df1, x='time.month', y='impact.magnitude') pltt.show()
输出
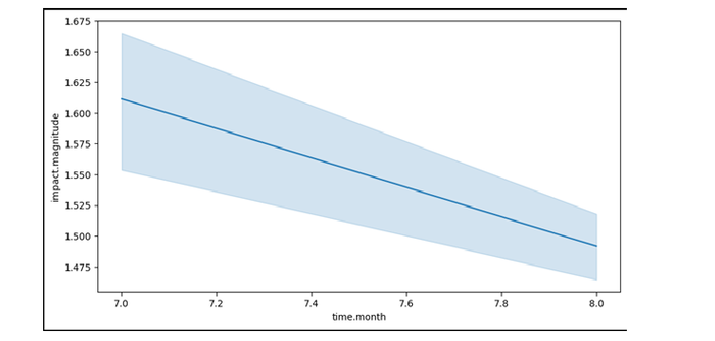
我们可以看到,地震的震级每个月都在减小。
pltt.subplots(figsize=(15, 5)) pltt.subplot(1, 2, 1) sbb.distplot(df1['location.depth']) pltt.subplot(1, 2, 2) sbb.boxplot(df1['location.depth']) pltt.show()
输出
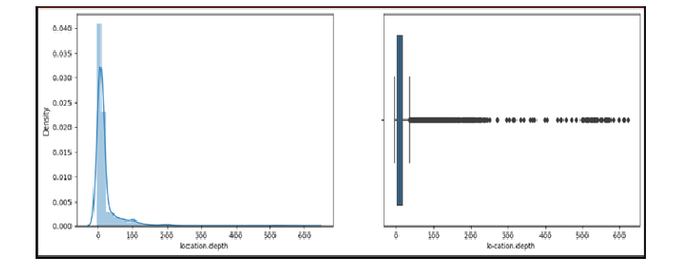
从分布图可以看出,存在多个异常值,这可以使用箱线图来验证。然而,最重要的收获是,地震发生深度的分布存在左偏。
pltt.subplots(figsize=(15, 5)) pltt.subplot(1, 2, 1) sbb.distplot(df1['impact.magnitude']) pltt.subplot(1, 2, 2) sbb.boxplot(df1['impact.magnitude']) pltt.show()
输出

pltt.figure(figsize=(20, 10)) sbb.scatterplot(data=df1, x='location.latitude', y='location.longitude', hue='impact.magnitude') pltt.show()
输出
现在,我们将查看数据的散点图:
import plotly.express as pxx import pandas as pdd fig_w = pxx.scatter_geo(df1, lat='location.latitude', lon='location.longitude', color="impact.magnitude", scope='usa') fig_w.show()
输出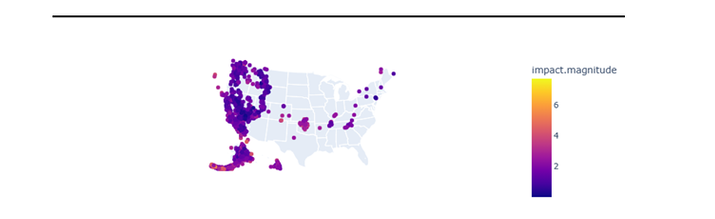
从上图可以看出,美国哪些地区更容易发生地震。
结论
在本文中,我们学习了 Python 的 matplotlib 库以及如何使用它。我们还使用 matplotlib 库分析和可视化了地震数据集。

594 次浏览
