人工智能 - 自然语言处理
自然语言处理 (NLP) 指的是人工智能利用自然语言(例如英语)与智能系统进行交流的方法。
当您希望机器人等智能系统根据您的指令执行操作时,或者当您希望从基于对话的临床专家系统中听到决策时,就需要进行自然语言处理。
NLP 领域涉及使计算机能够使用人类使用的自然语言执行有用的任务。NLP 系统的输入和输出可以是:
- 语音
- 书面文本
NLP 的组成部分
NLP 有两个组成部分:
自然语言理解 (NLU)
理解包括以下任务:
- 将给定的自然语言输入映射到有用的表示形式。
- 分析语言的不同方面。
自然语言生成 (NLG)
它是从某种内部表示生成有意义的短语和句子的过程,以自然语言的形式呈现。
它包括:
文本规划 - 它包括从知识库中检索相关内容。
句子规划 - 它包括选择所需的单词,形成有意义的短语,设定句子的语气。
文本实现 - 它是将句子计划映射到句子结构。
NLU 比 NLG 更难。
NLU 的难点
自然语言具有极其丰富的形式和结构。
它非常模糊。可能存在不同级别的歧义:
词汇歧义 - 这是在非常原始的级别,例如词级。
例如,将单词“board”视为名词还是动词?
句法级别歧义 - 一个句子可以以不同的方式解析。
例如,“He lifted the beetle with red cap.” - 他是用帽子举起甲虫,还是举起了一只戴着红色帽子的甲虫?
指称歧义 - 使用代词指代某事物。例如,丽玛去了高丽。她说:“我累了。” - 到底是谁累了?
一个输入可以表示不同的含义。
许多输入可以表示相同的含义。
NLP 术语
音系学 - 它是对系统地组织声音的研究。
形态学 - 它是对从原始有意义的单元构建单词的研究。
语素 - 它是语言中意义的原始单位。
句法 - 它指的是排列单词以构成句子。它还包括确定单词在句子和短语中的结构作用。
语义学 - 它关注单词的含义以及如何将单词组合成有意义的短语和句子。
语用学 - 它处理在不同情况下使用和理解句子,以及句子的解释是如何受到影响的。
语篇 - 它处理紧接的前一句如何影响下一句的解释。
世界知识 - 它包括关于世界的常识。
NLP 的步骤
一般有五个步骤:
词汇分析 - 它涉及识别和分析单词的结构。一种语言的词汇表是指该语言中单词和短语的集合。词汇分析是将整块文本划分为段落、句子和单词。
句法分析(解析) - 它涉及分析句子中单词的语法,并以显示单词之间关系的方式排列单词。例如,“The school goes to boy”这样的句子会被英语句法分析器拒绝。
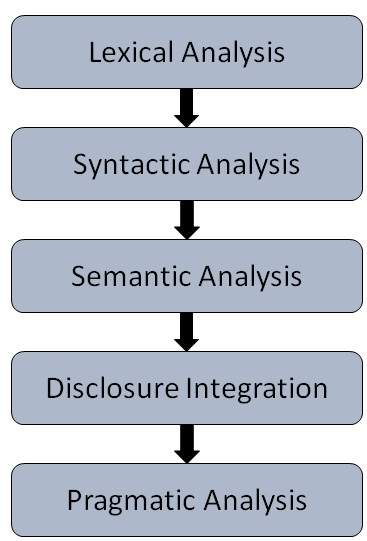
语义分析 - 它从文本中提取确切的含义或字典含义。文本的意义会被检查。这是通过将句法结构和任务域中的对象映射来完成的。语义分析器会忽略诸如“热的冰淇淋”之类的句子。
语篇整合 - 任何句子的含义都取决于其之前的句子的含义。此外,它还带来了紧随其后的句子的含义。
语用分析 - 在此过程中,所说的话会被重新解释为其实际含义。它涉及推导出需要现实世界知识的语言方面。
句法分析的实现方面
研究人员已经开发了许多用于句法分析的算法,但我们只考虑以下简单方法:
- 上下文无关文法
- 自顶向下解析器
让我们详细了解一下:
上下文无关文法
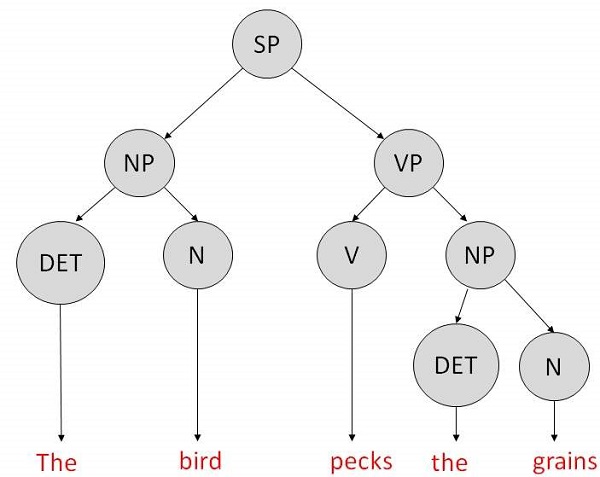
它是一种文法,其规则在重写规则的左侧只有一个符号。让我们创建一个文法来解析句子:
“The bird pecks the grains”
冠词 (DET) - a | an | the
名词 - bird | birds | grain | grains
名词短语 (NP) - 冠词 + 名词 | 冠词 + 形容词 + 名词
= DET N | DET ADJ N
动词 - pecks | pecking | pecked
动词短语 (VP) - NP V | V NP
形容词 (ADJ) - beautiful | small | chirping
解析树将句子分解成结构化的部分,以便计算机可以轻松地理解和处理它。为了让解析算法构建这个解析树,需要构建一组重写规则,这些规则描述哪些树结构是合法的。
这些规则说明树中的某个符号可以通过其他符号的序列来展开。根据一阶逻辑规则,如果有两个字符串名词短语 (NP) 和动词短语 (VP),则由 NP 后跟 VP 组合的字符串就是一个句子。句子的重写规则如下:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
词汇表 -
DET → a | the
ADJ → beautiful | perching
N → bird | birds | grain | grains
V → peck | pecks | pecking
可以创建如下所示的解析树:
现在考虑上述重写规则。由于 V 可以被“peck”或“pecks”两者替换,因此诸如“The bird peck the grains”之类的句子可能会被错误地允许。即主谓一致错误被认为是正确的。
优点 - 最简单的语法风格,因此也是最常用的。
缺点:
它们不够精确。例如,“The grains peck the bird”根据解析器在句法上是正确的,但即使它没有意义,解析器也会将其视为正确的句子。
为了提高精度,需要准备多组语法。它可能需要为解析单数和复数变体、被动句等完全不同的规则集,这可能导致创建难以管理的大量规则集。
自顶向下解析器
在这里,解析器从 S 符号开始,并尝试将其重写成与输入句子中单词类别匹配的终端符号序列,直到它完全由终端符号组成。
然后将其与输入句子进行检查以查看是否匹配。如果不匹配,则使用不同的规则集重新启动该过程。重复此过程,直到找到描述句子结构的特定规则。
优点 - 易于实现。
缺点:
- 它效率低下,因为如果发生错误,则必须重复搜索过程。
- 工作速度慢。