- 人工智能教程
- AI - 首页
- AI - 概述
- AI - 智能系统
- AI - 研究领域
- AI - 智能体与环境
- AI - 常用搜索算法
- AI - 模糊逻辑系统
- AI - 自然语言处理
- AI - 专家系统
- AI - 机器人技术
- AI - 神经网络
- AI - 问题
- AI - 术语
- 人工智能资源
- 人工智能快速指南
- 人工智能 - 面试问题与解答
- AI - 有用资源
- 人工智能 - 讨论
人工智能快速指南
人工智能 - 概述
自从计算机或机器发明以来,它们执行各种任务的能力呈指数级增长。人类在计算机系统的各种工作领域、不断提高的速度以及随着时间的推移而减小的尺寸方面,都提高了计算机系统的能力。
一个名为人工智能的计算机科学分支致力于创造与人类一样聪明的计算机或机器。
什么是人工智能?
根据人工智能之父约翰·麦卡锡的说法,它是“制造智能机器,特别是智能计算机程序的科学和工程”。
人工智能是一种使计算机、计算机控制的机器人或软件能够像聪明的人类一样思考的方法。
人工智能是通过研究人脑如何思考,以及人类如何学习、决策和工作来解决问题,然后将这项研究的结果作为开发智能软件和系统的基础来实现的。
人工智能的哲学
在利用计算机系统能力的同时,人类的好奇心促使人们思考:“机器能否像人类一样思考和行动?”
因此,人工智能的发展始于在机器中创造类似于我们在人类身上发现和高度重视的智能的意图。
人工智能的目标
创建专家系统——展示智能行为、学习、演示、解释和为用户提供建议的系统。
在机器中实现人类智能——创建能够理解、思考、学习和像人类一样行动的系统。
什么促成了人工智能?
人工智能是一门基于计算机科学、生物学、心理学、语言学、数学和工程等学科的科学和技术。人工智能的一个主要推动力是开发与人类智能相关的计算机功能,例如推理、学习和解决问题。
在以下领域中,一个或多个领域可以有助于构建智能系统。
有无AI的编程
有无AI的编程在以下方面有所不同:
| 无AI编程 | 有AI编程 |
|---|---|
| 没有AI的计算机程序可以回答其旨在解决的特定问题。 | 带有AI的计算机程序可以回答其旨在解决的通用问题。 |
| 程序的修改会导致其结构发生变化。 | AI程序可以通过将高度独立的信息片段组合在一起来吸收新的修改。因此,您可以修改程序的甚至很小一部分信息,而不会影响其结构。 |
| 修改并不迅速和容易。它可能会对程序产生不利影响。 | 快速简单的程序修改。 |
什么是AI技术?
在现实世界中,知识具有一些不受欢迎的特性:
- 其数量巨大,难以想象。
- 它组织不完善或格式不规范。
- 它不断变化。
AI技术是一种有效组织和使用知识的方式,其方式如下:
- 它应该被提供它的人理解。
- 它应该易于修改以纠正错误。
- 即使不完整或不准确,它也应该在许多情况下有用。
AI技术提高了其配备的复杂程序的执行速度。
AI的应用
AI在各个领域都占据主导地位,例如:
游戏——AI在国际象棋、扑克、井字棋等策略游戏中发挥着至关重要的作用,机器可以根据启发式知识思考大量可能的位置。
自然语言处理——可以与理解人类所说的自然语言的计算机进行交互。
专家系统——有些应用程序集成了机器、软件和特殊信息以提供推理和建议。它们为用户提供解释和建议。
视觉系统——这些系统理解、解释和理解计算机上的视觉输入。例如:
间谍飞机拍摄照片,这些照片用于找出区域的空间信息或地图。
医生使用临床专家系统来诊断病人。
警方使用可以识别罪犯面部与法医艺术家制作的存储肖像相匹配的计算机软件。
语音识别——一些智能系统能够听到和理解人类说话时的句子及其含义。它可以处理不同的口音、俚语、背景噪音、因感冒而导致的人声变化等。
手写识别——手写识别软件读取用笔写在纸上或用触控笔写在屏幕上的文本。它可以识别字母的形状并将其转换为可编辑文本。
智能机器人——机器人能够执行人类赋予的任务。它们具有传感器,可以检测来自现实世界的物理数据,例如光、热、温度、运动、声音、碰撞和压力。它们拥有高效的处理器、多个传感器和巨大的内存,以展现智能。此外,它们能够从错误中学习,并且能够适应新的环境。
AI的历史
以下是20世纪人工智能的历史:
| 年份 | 里程碑/创新 |
|---|---|
| 1923 | 卡雷尔·恰佩克的戏剧《罗素姆万能机器人》(RUR)在伦敦上演,这是“机器人”一词首次在英语中使用。 |
| 1943 | 神经网络的基础奠定。 |
| 1945 | 哥伦比亚大学校友艾萨克·阿西莫夫创造了机器人技术一词。 |
| 1950 | 艾伦·图灵介绍了用于评估智能的图灵测试,并发表了《计算机器与智能》。克劳德·香农发表了《国际象棋博弈的详细分析》作为一种搜索方法。 |
| 1956 | 约翰·麦卡锡创造了人工智能一词。卡内基梅隆大学展示了第一个运行的AI程序。 |
| 1958 | 约翰·麦卡锡发明了用于AI的LISP编程语言。 |
| 1964 | 丹尼·鲍勃罗在麻省理工学院的论文表明,计算机能够足够好地理解自然语言,以正确解决代数文字题。 |
| 1965 | 麻省理工学院的约瑟夫·魏泽鲍姆构建了ELIZA,一个能够用英语进行对话的交互式程序。 |
| 1969 | 斯坦福研究院的科学家开发了Shakey,一个配备了运动、感知和解决问题能力的机器人。 |
| 1973 | 爱丁堡大学的装配机器人小组建造了Freddy,这个著名的苏格兰机器人能够利用视觉来定位和组装模型。 |
| 1979 | 第一辆计算机控制的自主车辆斯坦福车问世。 |
| 1985 | 哈罗德·科恩创建并演示了绘图程序Aaron。 |
| 1990 | 人工智能所有领域取得重大进展:
|
| 1997 | 深蓝国际象棋程序击败了当时的国际象棋世界冠军加里·卡斯帕罗夫。 |
| 2000 | 交互式机器人宠物开始商业化。麻省理工学院展示了Kismet,一个面部可以表达情感的机器人。Nomad机器人探索南极洲的偏远地区并寻找陨石。 |
人工智能 - 智能系统
在学习人工智能时,你需要了解什么是智能。本章涵盖了智能的概念、类型和组成部分。
什么是智能?
系统计算、推理、感知关系和类比、从经验中学习、从记忆中存储和检索信息、解决问题、理解复杂思想、流利地使用自然语言、分类、概括和适应新情况的能力。
智能类型
正如美国发展心理学家霍华德·加德纳所描述的那样,智力是多方面的:
| 智力 | 描述 | 例子 |
|---|---|---|
| 语言智能 | 说话、识别和使用语音(语音)、语法(语法)和语义(意义)机制的能力。 | 叙述者、演说家 |
| 音乐智能 | 创造、交流和理解由声音构成的意义的能力,理解音调、节奏。 | 音乐家、歌手、作曲家 |
| 逻辑-数学智能 | 在没有行动或物体的情况下使用和理解关系的能力。理解复杂和抽象的思想。 | 数学家、科学家 |
| 空间智能 | 感知视觉或空间信息、改变它以及在不参考物体的情况下重新创建视觉图像的能力,构建3D图像以及移动和旋转它们。 | 地图阅读者、宇航员、物理学家 |
| 身体-动觉智能 | 使用全部或部分身体来解决问题或制作产品的能力,对精细和粗略运动技能的控制以及操纵物体。 | 运动员、舞蹈家 |
| 内省智能 | 区分自身感受、意图和动机的能力。 | 乔达摩·悉达多 |
| 人际智能 | 识别和区分他人感受、信念和意图的能力。 | 大众传播者、采访者 |
当机器或系统至少具备一种,最多具备所有智能时,你可以说它是人工智能的。
智能由什么组成?
智能是无形的。它由以下部分组成:
- 推理
- 学习
- 解决问题
- 感知
- 语言智能
让我们简要了解所有组成部分:
推理——这是一组使我们能够为判断、决策和预测提供依据的过程。主要分为两种:
| 归纳推理 | 演绎推理 |
|---|---|
| 它进行具体的观察以做出广泛的概括性陈述。 | 它从一个一般的陈述开始,并检查各种可能性以得出具体的、合乎逻辑的结论。 |
| 即使陈述中所有前提都是正确的,归纳推理也允许结论是错误的。 | 如果某事物普遍适用于某一类事物,则它也适用于该类的所有成员。 |
| 例如:“尼塔是一位老师。尼塔很勤奋。因此,所有老师都很勤奋。” | 例如:“所有60岁以上的女人都是祖母。莎丽妮65岁。因此,莎丽妮是祖母。” |
学习——通过学习、练习、被教导或体验某事物来获得知识或技能的活动。学习增强了对学习主题的认识。
人类、一些动物和启用AI的系统都拥有学习能力。学习分为:
听觉学习——通过聆听和听到来学习。例如,学生收听录制的音频讲座。
情景学习——通过记住自己见证或经历的事件序列来学习。这是线性的和有序的。
动作学习——通过精确的肌肉运动来学习。例如,拾取物体、书写等。
观察学习——通过观察和模仿他人来学习。例如,孩子试图通过模仿父母来学习。
感知学习 (gǎnzhī xuéxí) − 它指的是学习识别之前见过的刺激。例如,识别和分类物体和情境。
关系学习 (guānxi xuéxí) − 它涉及基于关系属性而非绝对属性来区分各种刺激。例如,上次煮土豆太咸了(加了一汤匙盐),这次煮土豆时就少加一点盐。
空间学习 (kōngjiān xuéxí) − 它指的是通过视觉刺激(如图像、颜色、地图等)进行学习。例如,一个人可以在实际走路线之前在脑海中创建路线图。
刺激-反应学习 (cìjī-fǎnyìng xuéxí) − 它指的是学习在出现某种刺激时执行特定行为。例如,狗听到门铃声会竖起耳朵。
问题解决 (wèntí jiějué) − 它是一个过程,在这个过程中,人们感知并试图通过某种路径从当前情境中得出期望的解决方案,而这条路径可能被已知或未知的障碍所阻碍。
问题解决还包括决策 (juécè),它是从多个可用的替代方案中选择最佳方案以达到期望目标的过程。
感知 (gǎnzhī) − 它是一个获取、解释、选择和组织感觉信息的过程。
感知预设了感觉 (gǎnjué)。在人类中,感知借助感觉器官。在人工智能领域,感知机制以有意义的方式将传感器获取的数据组合在一起。
语言智能 (yǔyán zhìnéng) − 指的是一个人使用、理解、说和写口头和书面语言的能力。这在人际交往中非常重要。
人类智能与机器智能的差异
人类通过模式感知,而机器通过规则和数据集合感知。
人类通过模式存储和回忆信息,机器通过搜索算法来实现。例如,数字 40404040 很容易记住、存储和回忆,因为它的模式很简单。
即使某些部分缺失或变形,人类也能弄清楚完整的物体;而机器却做不到。
人工智能 - 研究领域
人工智能领域范围很广。在接下来的讨论中,我们将考虑人工智能领域中广泛且蓬勃发展的一些研究领域:
语音识别和声纹识别
这两个术语在机器人技术、专家系统和自然语言处理中很常见。虽然这两个术语可以互换使用,但它们的目标不同。
| 语音识别 | 声纹识别 |
|---|---|
| 语音识别的目标是理解和领会说了什么 (shuōle shénme)。 | 声纹识别的目标是识别说话者是谁 (shuōhuà zhě shì shuí)。 |
| 它用于免提计算、地图或菜单导航。 | 它通过分析说话人的音调、音高和口音等来识别一个人。 |
| 语音识别不需要机器进行训练,因为它不依赖于说话者。 | 这种识别系统需要训练,因为它面向特定人员。 |
| 开发独立于说话者的语音识别系统非常困难。 | 与之相比,开发依赖于说话者的语音识别系统相对容易。 |
语音识别和声纹识别系统的运作方式
用户在麦克风上说的话会传到系统的声卡。转换器将模拟信号转换为等效的数字信号,用于语音处理。数据库用于比较声音模式以识别单词。最后,会向数据库提供反向反馈。
源语言文本成为翻译引擎的输入,翻译引擎将其转换为目标语言文本。它们支持交互式图形用户界面、大型词汇数据库等。
研究领域的现实应用
人工智能在人们日常生活中有很多应用:
| 序号 | 研究领域 | 现实应用 |
|---|---|---|
| 1 | 专家系统 例如:航班追踪系统、临床系统。 |
 |
| 2 | 自然语言处理 例如:Google Now 功能、语音识别、自动语音输出。 |
 |
| 3 | 神经网络 例如:模式识别系统,如人脸识别、字符识别、手写识别。 |
 |
| 4 | 机器人技术 例如:用于移动、喷涂、绘画、精密检查、钻孔、清洁、涂层、雕刻等的工业机器人。 |
 |
| 5 | 模糊逻辑系统 例如:消费电子产品、汽车等。 |
 |
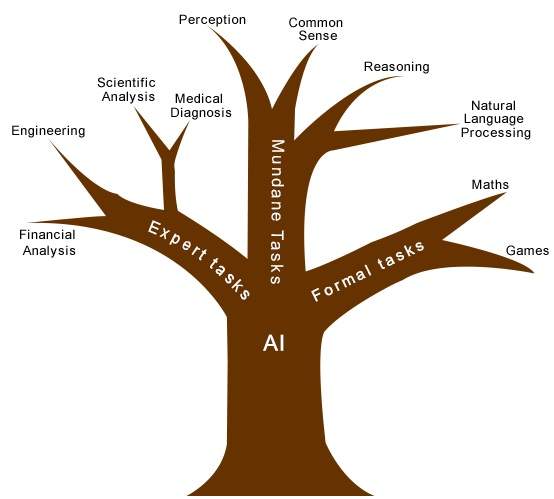
人工智能的任务分类
人工智能领域分为形式化任务 (xíngshì huà rènwu)、日常任务 (rìcháng rènwu)和专家任务 (zhuānjiā rènwu)。
| 人工智能的任务领域 | ||
|---|---|---|
| 日常任务 | 形式化任务 | 专家任务 |
感知
|
|
|
自然语言处理
|
游戏
|
科学分析 |
| 常识 | 验证 | 财务分析 |
| 推理 | 定理证明 | 医学诊断 |
| 规划 | 创造力 | |
机器人技术
|
||
人类从出生起就学习日常任务。他们通过感知、说话、使用语言和运动来学习。他们后来按顺序学习形式化任务和专家任务。
对于人类来说,日常任务最容易学习。在尝试将日常任务应用于机器之前,人们也认为这是正确的。早期,人工智能的所有工作都集中在日常任务领域。
后来,事实证明,机器需要更多的知识、复杂 的知识表示和复杂的算法来处理日常任务。这就是为什么人工智能工作现在在专家任务领域发展得更好的原因,因为专家任务领域需要专家知识而不需要常识,这更容易表示和处理。
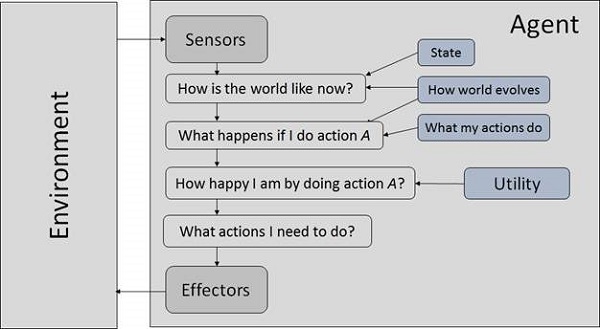
人工智能 - 智能体和环境
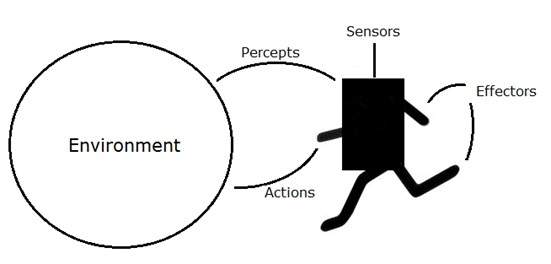
一个 AI 系统由一个智能体及其环境组成。智能体在其环境中行动。环境可能包含其他智能体。
什么是智能体和环境?
智能体 (zhìnéng tǐ) 是任何能够通过传感器 (chuǎncè qì)感知其环境并通过效应器 (xiàoyìng qì)作用于该环境的事物。
人类智能体具有与传感器平行的感觉器官,如眼睛、耳朵、鼻子、舌头和皮肤,以及作为效应器的其他器官,如手、脚、嘴。
机器人智能体用摄像头和红外测距仪代替传感器,用各种电机和执行器代替效应器。
软件智能体将其程序和操作编码为位字符串。
智能体术语
智能体性能度量 (zhìnéng tǐ xìngnéng dùliáng) − 它是确定智能体成功程度的标准。
智能体的行为 (zhìnéng tǐ de xíngwéi) − 它是智能体在任何给定的感知序列后执行的动作。
感知 (gǎnzhī) − 它是在给定时刻智能体的感知输入。
感知序列 (gǎnzhī xuélìè) − 它是一个智能体迄今为止感知到的所有内容的历史记录。
智能体函数 (zhìnéng tǐ hánshù) − 它是一个从感知序列到动作的映射。
理性
理性只不过是合理、明智和具有良好判断力的状态。
理性与预期行为和结果有关,这取决于智能体感知了什么。以获取有用信息为目标执行操作是理性中的重要部分。
什么是理想理性智能体?
理想理性智能体能够根据以下条件执行预期操作以最大化其性能度量:
- 其感知序列
- 其内置的知识库
智能体的理性取决于以下因素:
性能度量,它决定成功的程度。
智能体迄今为止的感知序列。
智能体对环境的先验知识。
智能体可以执行的动作。
理性智能体总是执行正确的动作,其中正确的动作是指导致智能体在给定的感知序列中最成功的动作。智能体解决的问题的特征在于性能度量、环境、执行器和传感器 (PEAS)。
智能体的结构
智能体的结构可以看作:
- 智能体 = 体系结构 + 智能体程序
- 体系结构 = 智能体在其上执行的机制。
- 智能体程序 = 智能体函数的实现。
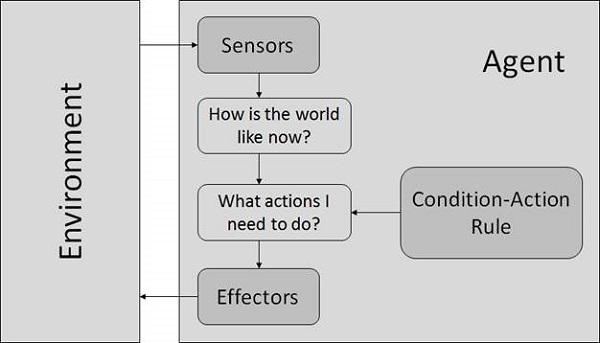
简单的反射智能体
- 它们仅根据当前感知选择动作。
- 只有在仅根据当前感知做出正确决策的情况下,它们才是理性的。
- 它们的环境是完全可观察的。
条件-动作规则 (tiáojiàn-dòngzuò guīzé) − 它是一个将状态(条件)映射到动作的规则。
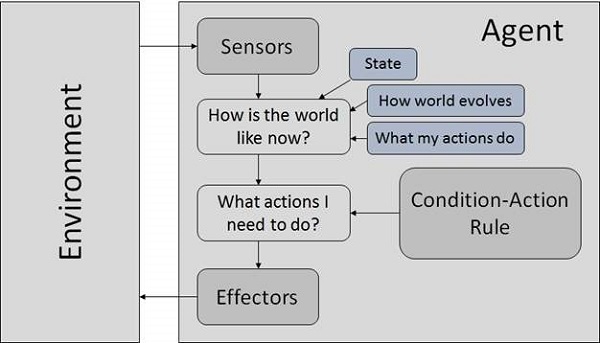
基于模型的反射智能体
它们使用世界模型来选择其动作。它们保持内部状态。
模型 (móxíng) − 关于“事物如何在世界上发生”的知识。
内部状态 (nèibù zhuàngtài) − 它是一个根据感知历史对当前状态的未观察到的方面的表示。
更新状态需要以下信息:
- 世界如何演变。
- 智能体的行为如何影响世界。
基于目标的智能体
它们选择动作是为了实现目标。基于目标的方法比反射智能体更灵活,因为支持决策的知识是显式建模的,从而允许进行修改。
目标 (mùbiāo) − 它是理想情况的描述。
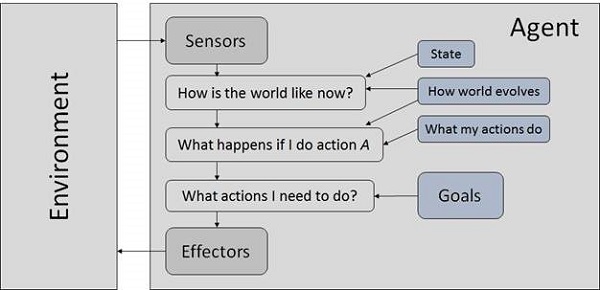
基于效用的智能体
它们根据对每个状态的偏好(效用)来选择动作。
当以下情况发生时,目标是不够的:
存在冲突的目标,其中只能实现少数目标。
目标实现存在一定的不确定性,需要权衡成功的可能性与目标的重要性。
环境的性质
某些程序完全在人工环境 (rén gōng huánjìng)中运行,该环境仅限于键盘输入、数据库、计算机文件系统和屏幕上的字符输出。
相反,一些软件代理(软件机器人或软机器人)存在于丰富、无限的软机器人领域。模拟器具有非常详细、复杂的环境。软件代理需要实时地从一系列动作中进行选择。设计用于扫描客户在线偏好并向客户展示有趣商品的软机器人,既可在真实环境中工作,也可在人工环境中工作。
最著名的人工环境是图灵测试环境,其中一个真实代理和另一个人工代理在同等条件下进行测试。这是一个非常具有挑战性的环境,因为对于软件代理来说,要像人类一样表现出色非常困难。
图灵测试
可以使用图灵测试来衡量系统智能行为的成功程度。
测试中包括两个人和一台待评估的机器。两人中一人担任测试员。他们分别坐在不同的房间里。测试员不知道谁是机器,谁是人。他通过输入问题并将其发送给两个智能体来进行提问,并接收他们的文字回复。
此测试旨在迷惑测试员。如果测试员无法区分机器的回应和人类的回应,则认为该机器具有智能。
环境特性
环境具有多种特性:
离散/连续 - 如果环境只有有限数量的不同、明确定义的状态,则该环境是离散的(例如,国际象棋);否则它是连续的(例如,驾驶)。
可观察/部分可观察 - 如果能够根据感知结果确定每个时间点的环境完整状态,则它是可观察的;否则,它只是部分可观察的。
静态/动态 - 如果在代理采取行动时环境没有变化,则它是静态的;否则它是动态的。
单代理/多代理 - 环境可能包含其他代理,这些代理可能与该代理相同或不同。
可访问/不可访问 - 如果代理的感知装置可以访问环境的完整状态,则该环境对于该代理是可访问的。
确定性/非确定性 - 如果环境的下一个状态完全由当前状态和代理的动作决定,则该环境是确定性的;否则是非确定性的。
情景式/非情景式 - 在情景式环境中,每个情景都包括代理感知然后采取行动。其行动的质量仅取决于情景本身。后续情景不依赖于先前情景中的行动。情景式环境要简单得多,因为代理不需要提前考虑。
AI - 常用搜索算法
搜索是人工智能中解决问题的通用技术。有一些单人游戏,例如拼图游戏、数独、填字游戏等。搜索算法可以帮助您在这些游戏中搜索特定位置。
单代理寻路问题
像 3X3 八块拼图、4X4 十五块拼图和 5X5 二十四块拼图这样的游戏都是单代理寻路挑战。它们由带有空白块的矩阵组成。玩家需要通过垂直或水平地将一个块滑入空白处来排列这些块,目的是实现某个目标。
单代理寻路问题的其他例子包括旅行商问题、魔方和定理证明。
搜索术语
问题空间 - 搜索发生的环境。(一组状态和一组改变这些状态的操作符)
问题实例 - 初始状态 + 目标状态。
问题空间图 - 它表示问题状态。状态用节点表示,操作符用边表示。
问题的深度 - 从初始状态到目标状态的最短路径或最短操作符序列的长度。
空间复杂度 - 存储在内存中的最大节点数。
时间复杂度 - 创建的最大节点数。
可采纳性 - 算法始终找到最优解的特性。
分支因子 - 问题空间图中子节点的平均数量。
深度 - 从初始状态到目标状态的最短路径的长度。
蛮力搜索策略
它们是最简单的,因为它们不需要任何特定领域的知识。它们在可能状态数量较少的情况下效果很好。
要求:
- 状态描述
- 一组有效的操作符
- 初始状态
- 目标状态描述
广度优先搜索
它从根节点开始,首先探索相邻节点,然后移向下一层邻居。它一次生成一棵树,直到找到解决方案。它可以使用 FIFO 队列数据结构来实现。此方法提供到解决方案的最短路径。
如果分支因子(给定节点的子节点平均数量)= b,深度 = d,则 d 层的节点数 = bd。
最坏情况下创建的节点总数为 b + b2 + b3 + … + bd。
缺点 - 由于为了创建下一个节点而保存每一层节点,因此它会消耗大量内存空间。存储节点的空间需求是指数级的。
其复杂度取决于节点数。它可以检查重复节点。
深度优先搜索
它使用 LIFO 堆栈数据结构以递归方式实现。它创建与广度优先方法相同的节点集,只是顺序不同。
由于在每次迭代中从根节点到叶节点存储单路径上的节点,因此存储节点的空间需求是线性的。分支因子为 *b*,深度为 *m*,存储空间为 *bm*。
缺点 - 此算法可能不会终止,并可能在一条路径上无限期地进行下去。解决这个问题的方法是选择一个截止深度。如果理想的截止深度为 *d*,而选择的截止深度小于 *d*,则此算法可能会失败。如果选择的截止深度大于 *d*,则执行时间会增加。
其复杂度取决于路径数。它无法检查重复节点。
双向搜索
它从初始状态向前搜索,从目标状态向后搜索,直到两者相遇以识别公共状态。
初始状态的路径与目标状态的反向路径连接在一起。每次搜索仅进行到总路径的一半。
一致代价搜索
按到达节点的路径成本递增排序。它总是扩展成本最低的节点。如果每个转换的成本相同,则它与广度优先搜索相同。
它按成本递增的顺序探索路径。
缺点 - 可能有多条成本 ≤ C* 的长路径。一致代价搜索必须全部探索它们。
迭代加深深度优先搜索
它执行到 1 层的深度优先搜索,然后重新开始,执行到 2 层的完整深度优先搜索,以此类推,直到找到解决方案。
在生成所有较低节点之前,它永远不会创建节点。它只保存一个节点堆栈。当它在深度 *d* 找到解决方案时,算法结束。深度 *d* 处创建的节点数为 bd,深度 *d-1* 处为 bd-1。
各种算法复杂度的比较
让我们根据各种标准查看算法的性能:
| 标准 | 广度优先 | 深度优先 | 双向 | 一致代价 | 迭代加深 |
|---|---|---|---|---|---|
| 时间 | bd | bm | bd/2 | bd | bd |
| 空间 | bd | bm | bd/2 | bd | bd |
| 最优性 | 是 | 否 | 是 | 是 | 是 |
| 完整性 | 是 | 否 | 是 | 是 | 是 |
启发式(启发式)搜索策略
为了解决具有大量可能状态的大型问题,需要添加特定于问题的知识以提高搜索算法的效率。
启发式评估函数
它们计算两个状态之间最优路径的成本。滑动块游戏的启发式函数是通过计算每个块与其目标状态之间的移动次数,并将所有块的这些移动次数相加来计算的。
纯启发式搜索
它按照启发式值的顺序扩展节点。它创建两个列表,一个用于已扩展节点的封闭列表和一个用于已创建但未扩展节点的开放列表。
在每次迭代中,扩展具有最小启发式值的节点,创建其所有子节点并将其放入封闭列表中。然后,将启发式函数应用于子节点,并根据其启发式值将其放入开放列表中。保存较短的路径,并丢弃较长的路径。
A*搜索
它是最佳优先搜索最著名的形式。它避免扩展已经很昂贵的路径,但首先扩展最有希望的路径。
f(n) = g(n) + h(n),其中
- g(n) 到达节点的成本(迄今为止)
- h(n) 从节点到目标的估计成本
- f(n) 通过 n 到目标的路径的估计总成本。它使用优先级队列按 f(n) 递增的方式实现。
贪婪最佳优先搜索
它扩展估计最接近目标的节点。它基于 f(n) = h(n) 扩展节点。它使用优先级队列实现。
缺点 - 它可能会陷入循环。它不是最优的。
局部搜索算法
它们从一个可能的解决方案开始,然后移动到一个相邻的解决方案。即使在它们结束之前任何时候中断,它们也可以返回一个有效的解决方案。
爬山搜索
这是一个迭代算法,它从问题的任意解开始,并尝试通过增量更改解的单个元素来找到更好的解。如果更改产生更好的解,则将增量更改作为新的解。重复此过程,直到没有进一步的改进。
函数爬山(问题),返回局部最大值的状态。
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
end
缺点 - 此算法既不完整,也不最优。
局部束搜索
在此算法中,它在任何给定时间都保存 k 个状态。一开始,这些状态是随机生成的。借助目标函数计算这些 k 个状态的后继状态。如果这些后继状态中的任何一个是目标函数的最大值,则算法停止。
否则,将(初始 k 个状态和 k 个状态的后继状态 = 2k)状态放入池中。然后对池进行数值排序。选择最高的 k 个状态作为新的初始状态。这个过程持续到达到最大值。
函数束搜索( 问题,k),返回一个解决方案状态。
start with k randomly generated states loop generate all successors of all k states if any of the states = solution, then return the state else select the k best successors end
模拟退火
退火是加热和冷却金属以改变其内部结构从而改变其物理性质的过程。当金属冷却时,它的新结构被固定,金属保留其新获得的性质。在模拟退火过程中,温度保持可变。
我们最初将温度设置得很高,然后随着算法的进行,使其缓慢“冷却”。当温度高时,算法允许高频地接受较差的解决方案。
开始
- 初始化 k = 0;L = 整数个变量;
- 从 i → j,搜索性能差异 Δ。
- 如果 Δ <= 0 则接受,否则如果 exp(-Δ/T(k)) > random(0,1) 则接受;
- 重复步骤 1 和 2,进行 L(k) 步。
- k = k + 1;
重复步骤 1 到 4,直到满足条件。
结束
旅行商问题
在这个算法中,目标是找到一条低成本的路线,从一个城市开始,沿途精确访问所有城市,最后回到同一个起始城市。
Start Find out all (n -1)! Possible solutions, where n is the total number of cities. Determine the minimum cost by finding out the cost of each of these (n -1)! solutions. Finally, keep the one with the minimum cost. end
人工智能 - 模糊逻辑系统
模糊逻辑系统 (FLS) 对不完整、模糊、扭曲或不准确(模糊)的输入产生可接受但确定的输出。
什么是模糊逻辑?
模糊逻辑 (FL) 是一种类似于人类推理的推理方法。FL 的方法模仿了人类决策的方式,其中包括数字值 YES 和 NO 之间的全部中间可能性。
计算机可以理解的常规逻辑块采用精确的输入并产生确定的输出 TRUE 或 FALSE,这相当于人类的 YES 或 NO。
模糊逻辑的发明者 Lotfi Zadeh 观察到,与计算机不同,人类的决策包括 YES 和 NO 之间的一系列可能性,例如:
| 肯定的 YES |
| 可能的 YES |
| 无法确定 |
| 可能的 NO |
| 肯定的 NO |
模糊逻辑基于输入的可能性级别来实现确定的输出。
实现
它可以实现于各种规模和能力的系统中,从小型微控制器到大型联网的工作站控制系统。
它可以以硬件、软件或两者的结合方式实现。
为什么选择模糊逻辑?
模糊逻辑对于商业和实际用途非常有用。
- 它可以控制机器和消费产品。
- 它可能不会给出精确的推理,但会给出可接受的推理。
- 模糊逻辑有助于处理工程中的不确定性。
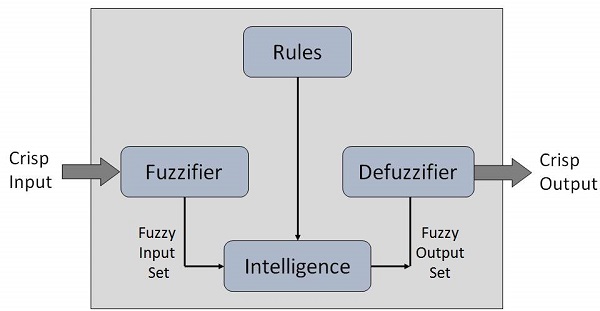
模糊逻辑系统架构
它有四个主要部分,如下所示:
模糊化模块 - 它将系统的输入(即清晰的数字)转换为模糊集。它将输入信号分成五个步骤,例如:
| LP | x 为大正数 |
| MP | x 为中等正数 |
| S | x 为小数 |
| MN | x 为中等负数 |
| LN | x 为大负数 |
知识库 - 它存储专家提供的 IF-THEN 规则。
推理引擎 - 通过对输入和 IF-THEN 规则进行模糊推理,它模拟人类的推理过程。
反模糊化模块 - 它将推理引擎获得的模糊集转换为清晰的值。
隶属函数作用于变量的模糊集。
隶属函数
隶属函数允许你量化语言术语并以图形方式表示模糊集。模糊集 *A* 在论域 X 上的隶属函数定义为 μA:X → [0,1]。
在这里,X 的每个元素都映射到 0 到 1 之间的值。它被称为隶属值或隶属度。它量化了 X 中元素对模糊集 *A* 的隶属度。
- x 轴表示论域。
- y 轴表示 [0, 1] 区间内的隶属度。
可以有多个隶属函数适用于将数值模糊化。使用简单的隶属函数,因为使用复杂的函数不会提高输出的精度。
LP、MP、S、MN 和 LN 的所有隶属函数如下所示:
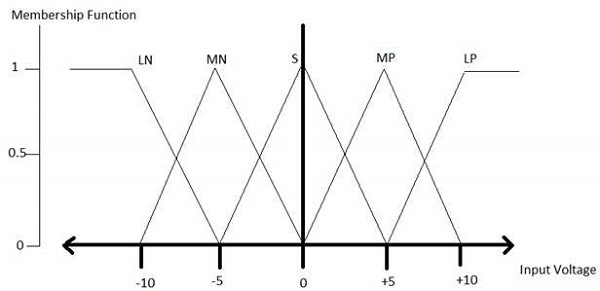
三角形隶属函数形状在各种其他隶属函数形状(如梯形、单例和高斯)中最常见。
这里,5 级模糊器的输入范围为 -10 伏特到 +10 伏特。因此,相应的输出也会发生变化。
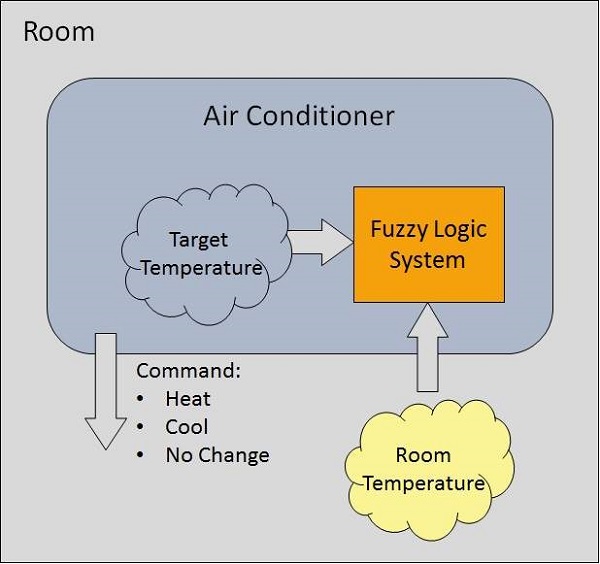
模糊逻辑系统示例
让我们考虑一个具有 5 级模糊逻辑系统的空调系统。该系统通过比较房间温度和目标温度值来调整空调的温度。
算法
- 定义语言变量和术语(开始)
- 为它们构建隶属函数。(开始)
- 构建规则的知识库(开始)
- 使用隶属函数将清晰数据转换为模糊数据集。(模糊化)
- 评估规则库中的规则。(推理引擎)
- 组合每个规则的结果。(推理引擎)
- 将输出数据转换为非模糊值。(反模糊化)
开发
步骤 1 - 定义语言变量和术语
语言变量是以简单词语或句子的形式出现的输入和输出变量。对于室温,冷、暖、热等是语言术语。
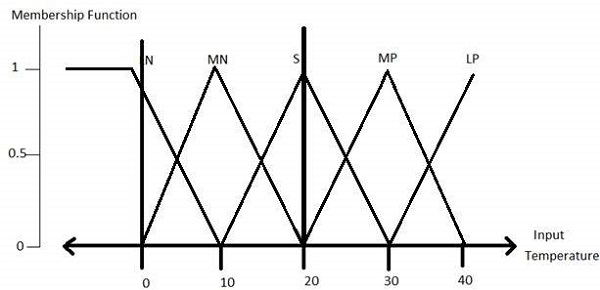
温度 (t) = {非常冷、冷、暖、非常暖、热}
该集合的每个成员都是一个语言术语,它可以覆盖一部分整体温度值。
步骤 2 - 为它们构建隶属函数
温度变量的隶属函数如下所示:
步骤 3 - 构建知识库规则
创建一个房间温度值与空调系统预期提供的目标温度值的矩阵。
| RoomTemp./Target | 非常冷 | 冷 | 暖 | 热 | 非常热 |
|---|---|---|---|---|---|
| 非常冷 | 不变 | 加热 | 加热 | 加热 | 加热 |
| 冷 | 冷却 | 不变 | 加热 | 加热 | 加热 |
| 暖 | 冷却 | 冷却 | 不变 | 加热 | 加热 |
| 热 | 冷却 | 冷却 | 冷却 | 不变 | 加热 |
| 非常热 | 冷却 | 冷却 | 冷却 | 冷却 | 不变 |
将一组规则以 IF-THEN-ELSE 结构的形式构建到知识库中。
| 序号 | 条件 | 动作 |
|---|---|---|
| 1 | 如果温度 =(冷或非常冷)并且目标 = 暖则 | 加热 |
| 2 | 如果温度 =(热或非常热)并且目标 = 暖则 | 冷却 |
| 3 | 如果(温度 = 暖)并且(目标 = 暖)则 | 不变 |
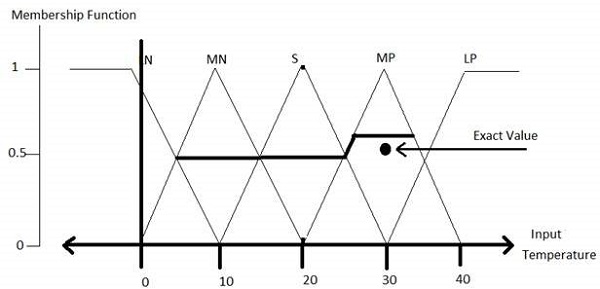
步骤 4 - 获取模糊值
模糊集运算执行规则评估。用于 OR 和 AND 的运算分别是 Max 和 Min。组合所有评估结果以形成最终结果。此结果是一个模糊值。
步骤 5 - 执行反模糊化
然后根据输出变量的隶属函数执行反模糊化。
模糊逻辑的应用领域
模糊逻辑的主要应用领域如下所示:
汽车系统
- 自动变速箱
- 四轮转向
- 车辆环境控制
消费电子产品
- 高保真音响系统
- 复印机
- 静态和摄像机
- 电视
家用电器
- 微波炉
- 冰箱
- 烤面包机
- 真空吸尘器
- 洗衣机
环境控制
- 空调/干燥机/加热器
- 加湿器
FLS 的优点
模糊推理中的数学概念非常简单。
由于模糊逻辑的灵活性,你可以通过添加或删除规则来修改 FLS。
模糊逻辑系统可以接受不精确、扭曲、嘈杂的输入信息。
FLS 易于构建和理解。
模糊逻辑是解决包括医学在内的所有领域复杂问题的解决方案,因为它类似于人类的推理和决策。
FLS 的缺点
- 没有系统的方法来设计模糊系统。
- 只有简单的时候才容易理解。
- 它们适用于不需要高精度的难题。
AI - 自然语言处理
自然语言处理 (NLP) 指的是使用英语等自然语言与智能系统进行通信的 AI 方法。
当你希望机器人等智能系统根据你的指示执行操作时,当你希望从基于对话的临床专家系统听到决策时,需要自然语言处理等。
NLP 领域涉及使计算机能够使用人类使用的自然语言执行有用的任务。NLP 系统的输入和输出可以是:
- 语音
- 书面文本
NLP 的组成部分
NLP 有两个组成部分,如下所示:
自然语言理解 (NLU)
理解涉及以下任务:
- 将给定的自然语言输入映射到有用的表示中。
- 分析语言的不同方面。
自然语言生成 (NLG)
它是根据某种内部表示,生成有意义的短语和句子的过程,以自然语言的形式呈现。
它包括:
文本规划 - 它包括从知识库中检索相关内容。
句子规划 - 它包括选择所需的词语、形成有意义的短语、设定句子的语气。
文本实现 - 它将句子计划映射到句子结构。
NLU 比 NLG 更难。
NLU 的难点
NL 具有极其丰富的形式和结构。
它非常模糊。可能存在不同级别的模糊性:
词汇歧义 - 它处于非常原始的级别,例如词级别。
例如,将单词“board”作为名词还是动词处理?
句法级别歧义 - 一个句子可以以不同的方式解析。
例如,“他用红色的帽子举起了甲壳虫。” - 他是用帽子举起甲壳虫,还是举起了一只戴着红色帽子的甲壳虫?
指称歧义 - 使用代词指代某事物。例如,丽玛去看高丽。她说,“我累了。” - 到底是谁累了?
一个输入可以有多种含义。
许多输入可以表示相同的含义。
NLP 术语
音系学 - 它是有系统地组织声音的研究。
形态学 - 它是由原始有意义的单位构成单词的研究。
语素 - 它是语言中意义的原始单位。
句法 - 它指的是排列单词以构成句子。它还涉及确定单词在句子和短语中的结构作用。
语义学 - 它关注单词的含义以及如何将单词组合成有意义的短语和句子。
语用学 - 它处理在不同情况下使用和理解句子,以及如何影响句子的解释。
语篇 - 它处理紧接在前的句子如何影响下一句子的解释。
世界知识 - 它包括关于世界的常识。
NLP 的步骤
一般有五个步骤:
词法分析 - 它涉及识别和分析单词的结构。语言的词典是指语言中单词和短语的集合。词法分析是将整块文本分成段落、句子和单词。
句法分析(解析) - 它涉及分析句子中单词的语法并以显示单词之间关系的方式排列单词。“学校去男孩”之类的句子会被英语句法分析器拒绝。
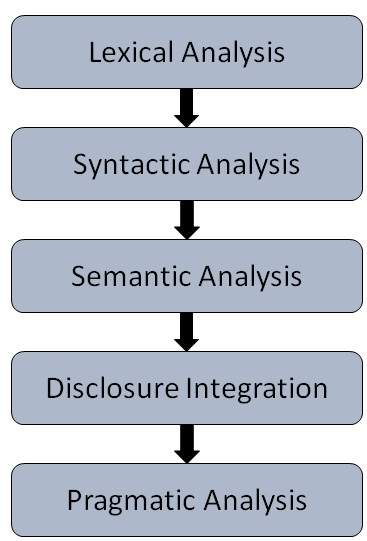
语义分析 − 它从文本中提取确切的含义或字典含义。文本被检查其是否有意义。这是通过将句法结构和对象映射到任务域来完成的。语义分析器会忽略诸如“热冰淇淋”之类的句子。
语篇整合 − 任何句子的含义都取决于其前面句子的含义。此外,它还会带来紧随其后的句子的含义。
语用分析 − 在此过程中,所说的话会被重新解释为其实际含义。它涉及推导出需要现实世界知识的语言方面。
句法分析的实现方面
研究人员已经开发了许多用于句法分析的算法,但我们只考虑以下简单方法:
- 上下文无关文法
- 自顶向下分析器
让我们详细了解一下:
上下文无关文法
它是一种文法,其规则在重写规则的左侧只有一个符号。让我们创建一个文法来解析一个句子:
“鸟啄谷粒”
冠词 (DET) − a | an | the
名词 − bird | birds | grain | grains
名词短语 (NP) − 冠词 + 名词 | 冠词 + 形容词 + 名词
= DET N | DET ADJ N
动词 − pecks | pecking | pecked
动词短语 (VP) − NP V | V NP
形容词 (ADJ) − beautiful | small | chirping
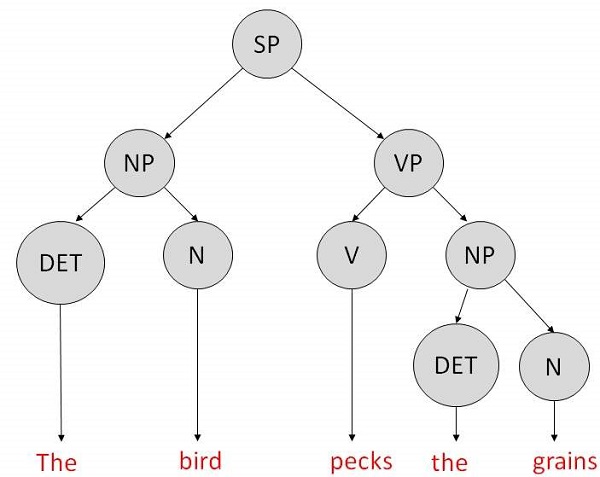
句法树将句子分解成结构化的部分,以便计算机能够轻松地理解和处理它。为了使解析算法能够构建此句法树,需要构建一组重写规则,这些规则描述哪些树结构是合法的。
这些规则说明,某个符号可以通过其他符号的序列在树中展开。根据一阶逻辑规则,如果存在两个字符串名词短语 (NP) 和动词短语 (VP),那么由 NP 后跟 VP 组合而成的字符串就是一个句子。句子的重写规则如下:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
词典 −
DET → a | the
ADJ → beautiful | perching
N → bird | birds | grain | grains
V → peck | pecks | pecking
可以创建如下所示的句法树:
现在考虑上述重写规则。由于 V 可以被“peck”或“pecks”替换,因此诸如“The bird peck the grains”之类的句子可能会被错误地允许。即,主谓一致错误被认为是正确的。
优点 − 最简单的文法类型,因此被广泛使用。
缺点 −
它们不够精确。例如,“谷粒啄鸟”根据解析器在句法上是正确的,但即使它没有意义,解析器也将其视为正确的句子。
为了提高精度,需要准备多组文法。它可能需要为解析单数和复数变体、被动句等准备完全不同的规则集,这可能导致创建难以管理的大量规则集。
自顶向下分析器
在这里,解析器从 S 符号开始,并尝试将其重写为与输入句子中单词类别匹配的终端符号序列,直到它完全由终端符号组成。
然后将这些与输入句子进行检查以查看是否匹配。如果没有匹配,则使用不同的规则集重新开始该过程。重复此过程,直到找到描述句子结构的特定规则。
优点 − 易于实现。
缺点 −
- 它效率低下,因为如果发生错误,则必须重复搜索过程。
- 工作速度慢。
人工智能 - 专家系统
专家系统 (ES) 是人工智能的一个重要研究领域。它是由斯坦福大学计算机科学系的研究人员提出的。
什么是专家系统?
专家系统是开发的计算机应用程序,用于解决特定领域中的复杂问题,达到非凡的人类智能和专业知识水平。
专家系统的特点
- 高性能
- 易于理解
- 可靠
- 高度响应
专家系统的功能
专家系统能够:
- 提供建议
- 指导和协助人类决策
- 演示
- 得出解决方案
- 诊断
- 解释
- 解释输入
- 预测结果
- 论证结论
- 为问题提出替代方案
它们不能:
- 取代人类决策者
- 拥有人的能力
- 为知识库不足的情况产生准确的输出
- 完善自身的知识
专家系统的组成部分
ES 的组成部分包括:
- 知识库
- 推理引擎
- 用户界面
让我们简要地逐一了解一下:
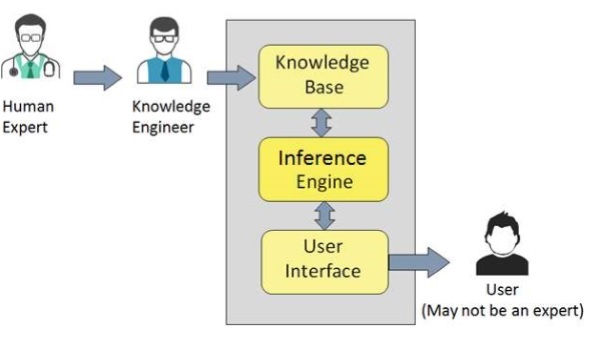
知识库
它包含特定领域和高质量的知识。
知识是展现智能所必需的。任何 ES 的成功都主要取决于高度准确和精确的知识的收集。
什么是知识?
数据是事实的集合。信息被组织成关于任务域的数据和事实。数据、信息和过去的经验组合在一起被称为知识。
知识库的组成部分
ES 的知识库既存储事实性知识,也存储启发式知识。
事实性知识 − 这是任务领域中的知识工程师和学者广泛接受的信息。
启发式知识 − 关于实践、准确的判断、评估能力和猜测。
知识表示
它是用于组织和形式化知识库中知识的方法。它是 IF-THEN-ELSE 规则的形式。
知识获取
任何专家系统的成功都主要取决于存储在知识库中的信息的质量、完整性和准确性。
知识库是通过阅读各种专家、学者和知识工程师的资料形成的。知识工程师是一个具有同理心、快速学习和案例分析能力的人。
他通过记录、采访和观察专家在工作中的情况等方式从主题专家那里获取信息。然后,他以有意义的方式对信息进行分类和组织,以 IF-THEN-ELSE 规则的形式,供干预机器使用。知识工程师还监控 ES 的开发。
推理引擎
推理引擎使用高效的过程和规则对于推导出正确、无瑕疵的解决方案至关重要。
对于基于知识的 ES,推理引擎从知识库中获取和操作知识以得出特定解决方案。
对于基于规则的 ES,它:
重复将规则应用于从早期规则应用中获得的事实。
根据需要向知识库中添加新知识。
当多个规则适用于特定情况时,解决规则冲突。
为了推荐解决方案,推理引擎使用以下策略:
- 正向链接
- 反向链接
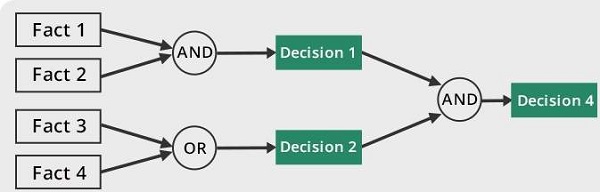
正向链接
这是专家系统回答问题“接下来会发生什么?”的一种策略。
在这里,推理引擎遵循条件和推导链,最终推导出结果。它考虑所有事实和规则,并在得出解决方案之前对它们进行排序。
此策略用于处理结论、结果或影响。例如,预测利率变化对股市状况的影响。
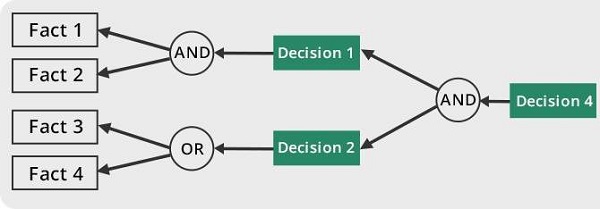
反向链接
使用此策略,专家系统可以找到答案:“为什么会发生这种情况?”
根据已经发生的事情,推理引擎试图找出过去可能发生过哪些条件导致了这个结果。此策略用于找出原因或理由。例如,人类血液癌症的诊断。
用户界面
用户界面提供 ES 用户和 ES 本身之间的交互。它通常是自然语言处理,以便那些精通任务领域的用户可以使用。ES 的用户不必一定是人工智能专家。
它解释了 ES 如何得出特定建议。解释可能以以下形式出现:
- 显示在屏幕上的自然语言。
- 自然语言的口头叙述。
- 显示在屏幕上的规则编号列表。
用户界面使追踪推论的可信度变得容易。
高效 ES 用户界面的要求
它应该帮助用户以最短的时间完成他们的目标。
它应该被设计用于用户现有的或期望的工作实践。
其技术应该适应用户的需求;反之则不然。
它应该有效地利用用户输入。
专家系统的局限性
没有任何技术可以提供轻松和完整的解决方案。大型系统成本高昂,需要大量的开发时间和计算机资源。ES 有其局限性,包括:
- 技术的局限性
- 知识获取困难
- ES 难以维护
- 高昂的开发成本
专家系统的应用
下表显示了 ES 的应用领域。
| 应用 | 描述 |
|---|---|
| 设计领域 | 相机镜头设计、汽车设计。 |
| 医疗领域 | 诊断系统,根据观察到的数据推断疾病的原因,对人类进行医疗手术。 |
| 监控系统 | 将数据与观察到的系统或规定的行为(例如长输油管道中的泄漏监控)持续进行比较。 |
| 过程控制系统 | 基于监控控制物理过程。 |
| 知识领域 | 找出车辆、计算机的故障。 |
| 金融/商业 | 检测可能的欺诈、可疑交易、股票市场交易、航空公司调度、货物调度。 |
专家系统技术
有多种级别的 ES 技术可用。专家系统技术包括:
专家系统开发环境 − ES 开发环境包括硬件和工具。它们是:
工作站、小型计算机、大型机。
高级符号编程语言,例如LISt Programming (LISP) 和PROgrammation en LOGique (PROLOG)。
大型数据库。
工具 − 它们在很大程度上减少了开发专家系统的努力和成本。
具有多窗口功能的强大的编辑器和调试工具。
它们提供快速原型设计
具有模型、知识表示和推理设计的内置定义。
外壳 − 外壳只不过是没有知识库的专家系统。外壳为开发人员提供了知识获取、推理引擎、用户界面和解释功能。例如,以下是一些外壳:
Java 专家系统外壳 (JESS),它提供完全开发的 Java API 用于创建专家系统。
Vidwan是1993年在孟买国家软件技术中心开发的一种shell。它能够以IF-THEN规则的形式进行知识编码。
专家系统开发:一般步骤
专家系统(ES)的开发过程是迭代的。开发ES的步骤包括:
确定问题领域
- 问题必须适合由专家系统解决。
- 为ES项目找到任务领域的专家。
- 确定系统的成本效益。
系统设计
确定ES技术
了解并确定与其他系统和数据库的集成程度。
了解如何最好地表示领域知识的概念。
开发原型
从知识库:知识工程师的工作包括:
- 从专家那里获取领域知识。
- 将其表示为If-THEN-ELSE规则。
测试和改进原型
知识工程师使用示例案例来测试原型在性能方面的任何缺陷。
最终用户测试ES的原型。
开发并完成ES
测试并确保ES与其环境的所有元素(包括最终用户、数据库和其他信息系统)的交互。
做好ES项目的文档工作。
培训用户使用ES。
系统维护
通过定期审查和更新,保持知识库的最新状态。
随着这些系统的演变,满足与其他信息系统的新接口的需求。
专家系统的优点
可用性——由于软件的大规模生产,它们很容易获得。
生产成本低——生产成本合理。这使得它们负担得起。
速度——它们速度很快。它们减少了个人投入的工作量。
错误率低——与人为错误相比,错误率较低。
降低风险——它们可以在对人类危险的环境中工作。
响应稳定——它们稳定地工作,不会情绪化、紧张或疲劳。
人工智能 - 机器人技术
机器人技术是人工智能领域的一个分支,它涉及研究创造智能高效的机器人。
什么是机器人?
机器人是在真实世界环境中行动的智能代理。
目标
机器人的目标是通过感知、拾取、移动、修改物体的物理属性、破坏物体或产生某种效果来操纵物体,从而将人力从重复性功能中解放出来,而不会感到厌倦、分心或筋疲力尽。
什么是机器人技术?
机器人技术是人工智能的一个分支,它由电气工程、机械工程和计算机科学组成,用于机器人的设计、建造和应用。
机器人技术的各个方面
机器人具有机械结构、形状或形式,旨在完成特定任务。
它们具有电气组件,为机械提供动力和控制。
它们包含一定程度的计算机程序,决定机器人做什么、何时做以及如何做。
机器人系统与其他AI程序的区别
以下是两者之间的区别:
| AI程序 | 机器人 |
|---|---|
| 它们通常在计算机模拟的世界中运行。 | 它们在真实的物理世界中运行 |
| AI程序的输入是符号和规则。 | 机器人的输入是语音波形或图像形式的模拟信号 |
| 它们需要通用计算机来运行。 | 它们需要带有传感器和效应器的专用硬件。 |
机器人运动
运动是使机器人能够在其环境中移动的机制。有各种类型的运动:
- 腿式
- 轮式
- 腿式和轮式运动的组合
- 履带式滑动/滑行
腿式运动
这种类型的运动在行走、跳跃、慢跑、跳跃、爬上或爬下等过程中消耗更多能量。
它需要更多的电机来完成运动。它适用于崎岖不平的地形以及光滑的地形,在不规则或过于光滑的表面上,轮式运动会消耗更多能量。由于稳定性问题,它很难实现。
它有多种类型,包括一足、二足、四足和六足机器人。如果机器人有多条腿,则需要腿部协调才能进行运动。
机器人可以移动的步态(每条腿的提升和释放事件的周期性序列)总数取决于其腿的数量。
如果机器人有k条腿,则可能的事件数N = (2k-1)!。
对于双足机器人(k=2),可能的事件数为N = (2k-1)! = (2*2-1)! = 3! = 6。
因此,共有六个可能的不同事件:
- 抬起左腿
- 放下左腿
- 抬起右腿
- 放下右腿
- 同时抬起双腿
- 同时放下双腿
对于k=6条腿,共有39916800个可能的事件。因此,机器人的复杂度与其腿的数量成正比。

轮式运动
它需要较少的电机来完成运动。它比较容易实现,因为在轮子数量较多的情况下,稳定性问题较少。与腿式运动相比,它更节能。
标准轮——绕车轮轴和接触点旋转
万向轮——绕车轮轴和偏置转向关节旋转。
瑞典45o和瑞典90o轮——全向轮,绕接触点、车轮轴和滚轮旋转。
球形轮——全向轮,技术上难以实现。

滑动/滑行运动
在这种类型中,车辆使用履带,就像坦克一样。通过以相同或相反的方向以不同速度移动履带来转向机器人。由于履带与地面的接触面积大,因此具有稳定性。

机器人的组成部分
机器人由以下部分构成:
电源——机器人由电池、太阳能、液压或气动电源供电。
执行器——它们将能量转换为运动。
电动机(交流/直流)——它们需要进行旋转运动。
气动人工肌肉——当空气被吸入其中时,它们会收缩近40%。
形状记忆合金丝——当电流通过时,它们会收缩5%。
压电电机和超声波电机——最适合工业机器人。
传感器——它们提供有关任务环境实时信息的知识。机器人配备了视觉传感器,可以计算环境中的深度。触觉传感器模仿人手指触觉感受器的机械特性。
计算机视觉
这是一项人工智能技术,机器人可以用它来“看”。计算机视觉在安全、安保、健康、访问和娱乐领域发挥着至关重要的作用。
计算机视觉自动从单个图像或一系列图像中提取、分析和理解有用的信息。此过程涉及开发算法以实现自动视觉理解。
计算机视觉系统的硬件
这包括:
- 电源
- 图像采集设备,如摄像机
- 处理器
- 软件
- 用于监控系统的显示设备
- 附件,如摄像机支架、电缆和连接器
计算机视觉的任务
OCR——在计算机领域,光学字符识别器 (OCR) 是一种将扫描文档转换为可编辑文本的软件,它与扫描仪一起使用。
人脸检测——许多最先进的摄像机都具有此功能,它能够读取人脸并拍摄具有完美表情的照片。它用于在正确匹配时让用户访问软件。
物体识别——它们安装在超市、摄像机、宝马、通用汽车和沃尔沃等高端汽车中。
位置估计——它是在摄像机方面估计物体的位置,例如人体肿瘤的位置。
计算机视觉的应用领域
- 农业
- 自动驾驶车辆
- 生物识别
- 字符识别
- 法医、安全和监控
- 工业质量检验
- 人脸识别
- 手势分析
- 地球科学
- 医学影像
- 污染监测
- 过程控制
- 遥感
- 机器人技术
- 交通运输
机器人技术的应用
机器人技术在各个领域发挥了重要作用,例如:
工业——机器人用于处理材料、切割、焊接、涂色、钻孔、抛光等。
军事——自主机器人可以在战争期间到达无法进入和危险区域。国防研究与发展组织 (DRDO) 开发的名为Daksh的机器人正在发挥作用,以安全地摧毁危及生命的物体。
医学——机器人能够同时进行数百项临床测试,康复永久性残疾人士,并进行复杂的手术,例如脑肿瘤手术。
勘探——用于太空探索的机器人攀岩者、用于海洋探索的水下无人机,仅举几例。
娱乐——迪士尼的工程师为电影制作创造了数百个机器人。
人工智能 - 神经网络
人工智能的另一个研究领域,神经网络,是受人类神经系统自然神经网络的启发。
什么是人工神经网络 (ANN)?
第一台神经计算机的发明者罗伯特·赫克特-尼尔森博士将神经网络定义为:
“...一种由许多简单、高度互连的处理单元组成的计算系统,它通过对外部输入的动态状态响应来处理信息。”
人工神经网络的基本结构
人工神经网络的思想是基于这样的信念:通过建立正确的连接,人类大脑的工作可以利用硅和电线来模仿活的神经元和树突。
人脑由860亿个称为神经元的神经细胞组成。它们通过轴突与其他数千个细胞相连。来自外部环境的刺激或来自感觉器官的输入被树突接受。这些输入产生电脉冲,这些脉冲迅速穿过神经网络。然后,神经元可以向其他神经元发送消息来处理问题,或者不将其转发。
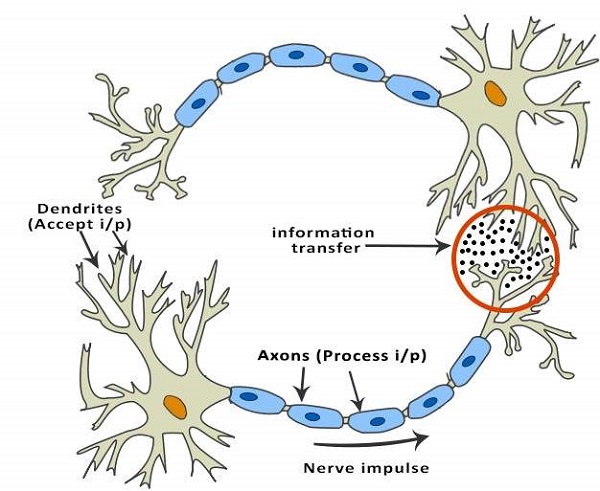
人工神经网络由多个节点组成,这些节点模拟人脑的生物神经元。神经元通过链接连接,它们相互作用。节点可以接收输入数据并对数据执行简单的运算。这些运算的结果传递给其他神经元。每个节点的输出称为其激活或节点值。
每个链接都与权重相关联。人工神经网络能够学习,学习是通过改变权重值来实现的。下图显示了一个简单的人工神经网络:
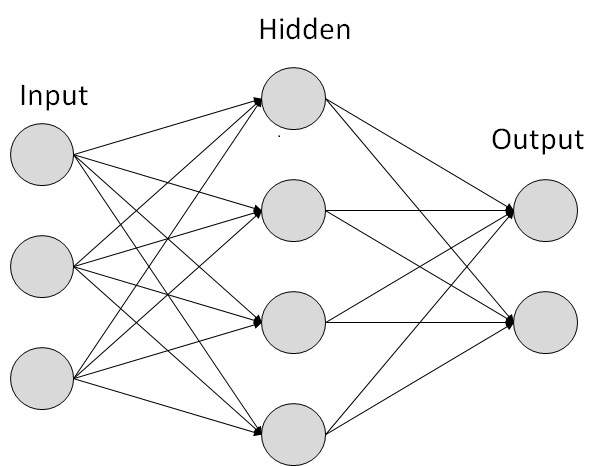
人工神经网络的类型
有两种人工神经网络拓扑结构:前馈和反馈。
前馈人工神经网络
在这种人工神经网络中,信息流是单向的。一个单元向另一个单元发送信息,而它不从该单元接收任何信息。没有反馈循环。它们用于模式生成/识别/分类。它们具有固定的输入和输出。
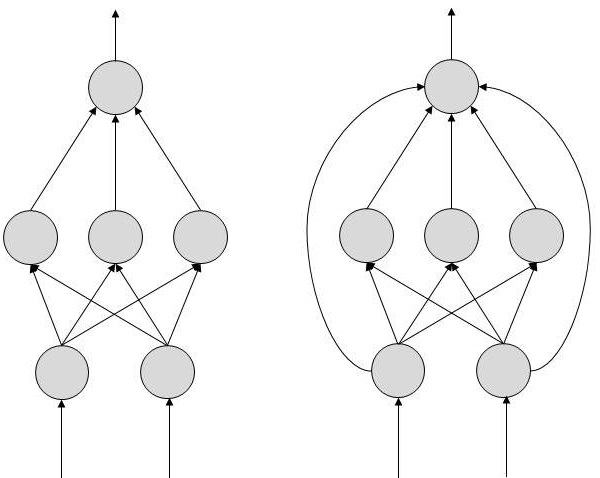
反馈人工神经网络
在这里,允许反馈循环。它们用于内容寻址存储器。
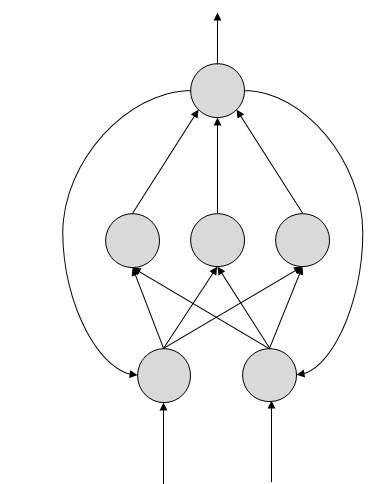
人工神经网络的工作原理
在上图所示的拓扑图中,每个箭头表示两个神经元之间的连接,并指示信息流的路径。每个连接都有一个权重,这是一个控制两个神经元之间信号的整数。
如果网络生成“良好或期望的”输出,则无需调整权重。但是,如果网络生成“不良或非期望的”输出或错误,则系统会改变权重以改进后续结果。
人工神经网络中的机器学习
人工神经网络 (ANN) 能够学习,并且需要进行训练。有几种学习策略:
监督学习 − 它涉及一位比 ANN 本身更有知识的“老师”。例如,老师会提供一些示例数据,而老师已经知道这些数据的答案。
例如,模式识别。ANN 在识别过程中会做出猜测。然后,老师会向 ANN 提供答案。网络随后会将它的猜测与老师的“正确”答案进行比较,并根据错误进行调整。
无监督学习 − 当没有带有已知答案的示例数据集时,就需要这种学习。例如,搜索隐藏模式。在这种情况下,聚类(即根据某些未知模式将一组元素分成几组)是基于现有数据集进行的。
强化学习 − 此策略建立在观察的基础上。ANN 通过观察其环境来做出决策。如果观察结果为负面,则网络会调整其权重,以便下次能够做出不同的所需决策。
反向传播算法
这是一种训练或学习算法。它通过示例学习。如果您向算法提交您希望网络执行的操作示例,它会更改网络的权重,以便在完成训练后能够针对特定输入产生所需的输出。
反向传播网络非常适合简单的模式识别和映射任务。
贝叶斯网络 (BN)
这些是用于表示一组随机变量之间概率关系的图形结构。贝叶斯网络也称为信念网络或贝叶斯网。BN 用于推断不确定领域。
在这些网络中,每个节点代表一个具有特定命题的随机变量。例如,在医学诊断领域中,节点“癌症”表示患者患有癌症的命题。
连接节点的边表示这些随机变量之间的概率依赖关系。如果两个节点中的一个影响另一个,则它们必须直接连接在影响的方向上。变量之间关系的强度由与每个节点相关的概率来量化。
BN 中的弧只有一个约束条件,即您不能简单地通过跟随有向弧返回到一个节点。因此,BN 称为有向无环图 (DAG)。
BN 能够同时处理多值变量。BN 变量由两个维度组成:
- 命题范围
- 分配给每个命题的概率。
考虑一个有限集 X = {X1, X2, …,Xn} 的离散随机变量,其中每个变量 Xi 可以取自一个有限集的值,记为 Val(Xi)。如果从变量 Xi 到变量 Xj 有一个有向链接,则变量 Xi 将是变量 Xj 的父节点,表示变量之间的直接依赖关系。
BN 的结构非常适合结合先验知识和观察数据。BN 可用于学习因果关系,理解各种问题领域,并预测未来事件,即使在数据缺失的情况下也是如此。
构建贝叶斯网络
知识工程师可以构建贝叶斯网络。知识工程师在构建过程中需要采取许多步骤。
示例问题 − 肺癌。一位病人一直呼吸困难。他去看医生,怀疑自己患有肺癌。医生知道,除了肺癌外,病人还可能患有其他各种疾病,例如结核病和支气管炎。
收集相关问题信息
- 病人是吸烟者吗?如果是,则患癌症和支气管炎的可能性很高。
- 病人是否接触过空气污染?如果是,是什么类型的空气污染?
- 进行 X 光检查,阳性的 X 光检查表明可能是结核病或肺癌。
识别有趣的变量
知识工程师尝试回答以下问题:
- 要表示哪些节点?
- 它们可以取哪些值?它们可以处于什么状态?
现在让我们考虑只有离散值的节点。变量必须一次只取这些值中的一个。
常见的离散节点类型包括:
布尔节点 − 它们表示命题,取二元值 TRUE (T) 和 FALSE (F)。
有序值 − 节点 污染可以表示并取自 {低,中,高} 的值,描述患者接触污染的程度。
整数值 − 一个名为 年龄 的节点可以表示患者的年龄,其可能值范围为 1 到 120。即使在这个早期阶段,建模选择也在进行中。
肺癌示例的可能节点和值:
| 节点名称 | 类型 | 值 | 节点创建 |
|---|---|---|---|
| 污染 | 二元 | {低,高,中} | 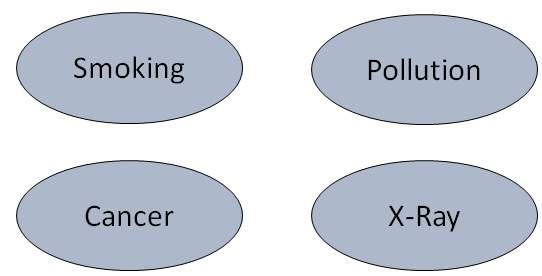 |
| 吸烟者 | 布尔 | {真,假} | |
| 肺癌 | 布尔 | {真,假} | |
| X 光 | 二元 | {阳性,阴性} |
创建节点之间的弧
网络的拓扑结构应捕捉变量之间的定性关系。
例如,是什么导致病人患肺癌?- 污染和吸烟。然后从节点 污染 和节点 吸烟者 添加弧到节点 肺癌。
同样,如果病人患有肺癌,则 X 光检查结果将为阳性。然后从节点 肺癌 添加弧到节点 X 光。
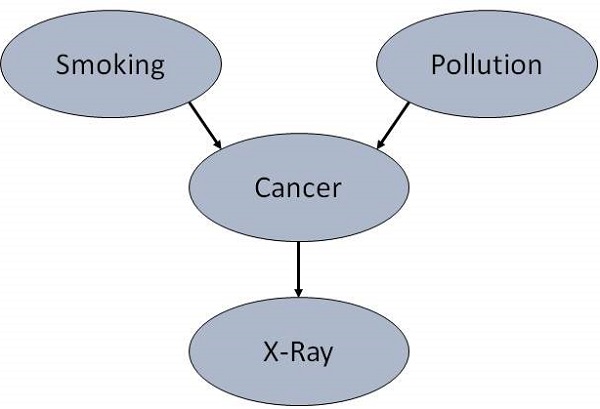
指定拓扑结构
通常,BN 的布局方式是从上到下指向弧。节点 X 的父节点集由 Parents(X) 给出。
肺癌 节点有两个父节点(原因):污染 和 吸烟者,而节点 吸烟者 是节点 X 光 的祖先。同样,X 光 是节点 肺癌 的子节点(结果或影响)和节点 吸烟者 和 污染 的后代。
条件概率
现在量化连接节点之间的关系:这是通过为每个节点指定条件概率分布来完成的。由于这里只考虑离散变量,因此它采用条件概率表 (CPT) 的形式。
首先,对于每个节点,我们需要查看其所有父节点值的可能组合。每个这样的组合称为父节点集的一个实例。对于父节点值的每个不同实例,我们需要指定子节点将取的值的概率。
例如,肺癌 节点的父节点是 污染 和 吸烟。它们取可能的值 = {(H,T), (H,F), (L,T), (L,F)}。CPT 分别指定每种情况下癌症的概率为 <0.05, 0.02, 0.03, 0.001>。
每个节点将具有如下关联的条件概率:
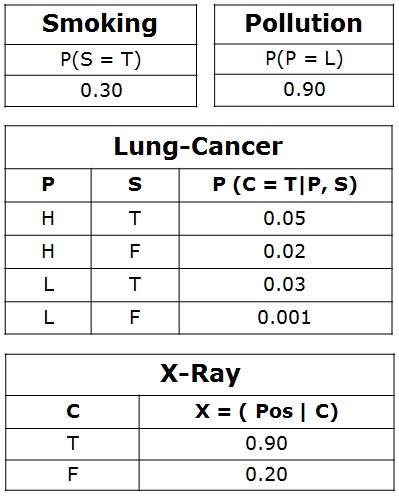
神经网络的应用
它们可以执行对人类来说很容易但对机器来说很难的任务:
航空航天 − 自动驾驶飞机,飞机故障检测。
汽车 − 汽车导航系统。
军事 − 武器定向和转向,目标跟踪,目标识别,面部识别,信号/图像识别。
电子 − 代码序列预测,IC 芯片布局,芯片故障分析,机器视觉,语音合成。
金融 − 房地产估价,贷款顾问,抵押贷款筛选,公司债券评级,投资组合交易程序,公司财务分析,货币价值预测,文档阅读器,信用申请评估器。
工业 − 制造过程控制,产品设计和分析,质量检验系统,焊接质量分析,纸张质量预测,化工产品设计分析,化工过程系统的动态建模,机器维护分析,项目投标,规划和管理。
医学 − 癌细胞分析,脑电图和心电图分析,假体设计,移植时间优化器。
语音 − 语音识别,语音分类,文本到语音转换。
电信 − 图像和数据压缩,自动化信息服务,实时口语翻译。
交通运输 − 卡车制动系统诊断,车辆调度,路线系统。
软件 − 面部识别、光学字符识别等中的模式识别。
时间序列预测 − ANN 用于预测股票和自然灾害。
信号处理 − 可以训练神经网络来处理音频信号并在助听器中对其进行适当滤波。
控制 − ANN 常用于对物理车辆进行转向决策。
异常检测 − 由于 ANN 擅长识别模式,因此也可以对其进行训练以在发生不符合模式的异常情况时生成输出。
人工智能 - 问题
人工智能发展速度如此之快,有时似乎很神奇。研究人员和开发人员认为,人工智能可能会变得如此强大,以至于人类难以控制。
人类通过向人工智能系统中引入他们所能想到的一切可能的智能来开发人工智能系统,而人类自己现在似乎受到了威胁。
对隐私的威胁
理论上,能够识别语音并理解自然语言的人工智能程序能够理解电子邮件和电话上的每一次对话。
对人类尊严的威胁
人工智能系统已经开始在一些行业取代人类。它不应取代那些从事与伦理相关的尊严职位的人,例如护士、外科医生、法官、警官等。
对安全的威胁
自我改进的人工智能系统可能会变得比人类强大得多,以至于很难阻止它们实现目标,这可能会导致意想不到的后果。
人工智能 - 术语
以下是人工智能领域中常用术语的列表:
| 序号 | 术语及含义 |
|---|---|
| 1 | 智能体 智能体是能够自主、有目的且推理导向一个或多个目标的系统或软件程序。它们也称为助手、经纪人、机器人、机器人、智能体和软件智能体。 |
| 2 | 自主机器人 摆脱外部控制或影响并能够独立控制自身的机器人。 |
| 3 | 反向链接 用于解决问题的原因/起因的反向工作策略。 |
| 4 | 黑板 这是计算机内部的内存,用于协同专家系统之间的通信。 |
| 5 | 环境 这是代理所处的真实世界或计算世界的一部分。 |
| 6 | 正向链接 一种用于得出问题结论/解决方案的前向工作策略。 |
| 7 | 启发式 这是基于试错、评估和实验的知识。 |
| 8 | 知识工程 从人类专家和其他资源获取知识。 |
| 9 | 感知 这是代理获取有关环境信息的格式。 |
| 10 | 剪枝 在人工智能系统中忽略不必要和不相关的考虑因素。 |
| 11 | 规则 这是专家系统中表示知识库的一种格式。它采用IF-THEN-ELSE的形式。 |
| 12 | 壳 (Shell) 壳是一个软件,有助于设计专家系统的推理引擎、知识库和用户界面。 |
| 13 | 任务 这是代理试图完成的目标。 |
| 14 | 图灵测试 阿兰·图灵设计的一个测试,用于测试机器的智能与人类智能的比较。 |