人工智能 - 神经网络
神经网络是 AI 中另一个研究领域,其灵感来自于人类神经系统的自然神经网络。
什么是人工神经网络 (ANN)?
第一台神经计算机的发明者罗伯特·赫克特-尼尔森博士将神经网络定义为:
“......一种由许多简单、高度互连的处理单元组成的计算系统,这些单元通过对外部输入的动态状态响应来处理信息。”
ANN 的基本结构
ANN 的思想基于这样的信念:人脑通过建立正确的连接来工作,可以使用硅和导线来模仿活的神经元和树突。
人脑由 860 亿个称为神经元的神经细胞组成。它们通过轴突与其他数千个细胞连接。来自外部环境或感觉器官的输入刺激被树突接收。这些输入产生电脉冲,这些电脉冲迅速穿过神经网络。然后,神经元可以将信息发送给其他神经元来处理问题,或者不将其转发。
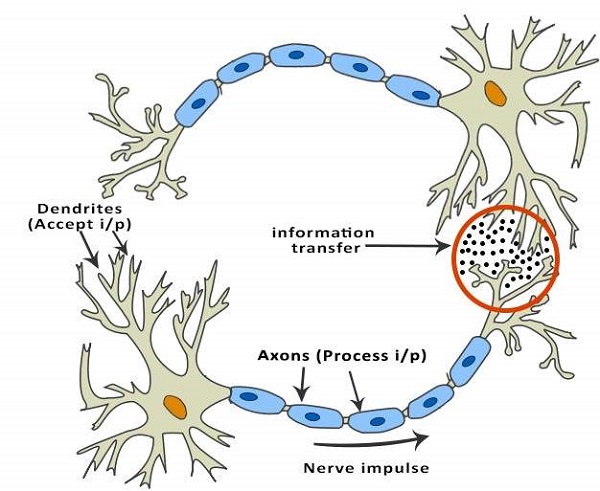
ANN 由多个节点组成,这些节点模仿人脑的生物神经元。神经元通过链接连接,它们相互作用。节点可以接收输入数据并在数据上执行简单的操作。这些操作的结果传递给其他神经元。每个节点的输出称为其激活或节点值。
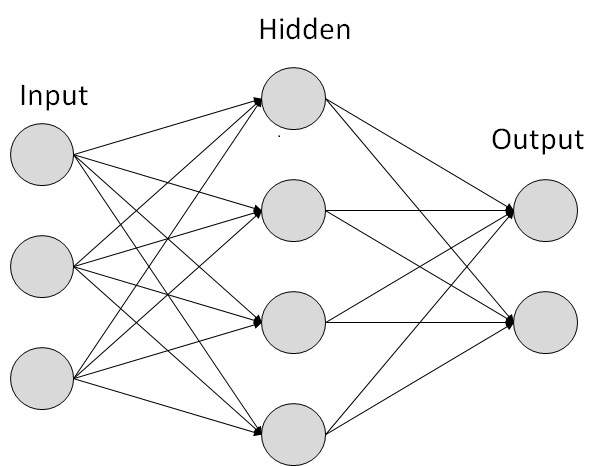
每个链接都与权重相关联。ANN 能够学习,学习是通过改变权重值来实现的。下图显示了一个简单的 ANN:
人工神经网络的类型
人工神经网络有两种拓扑结构:前馈和反馈。
前馈 ANN
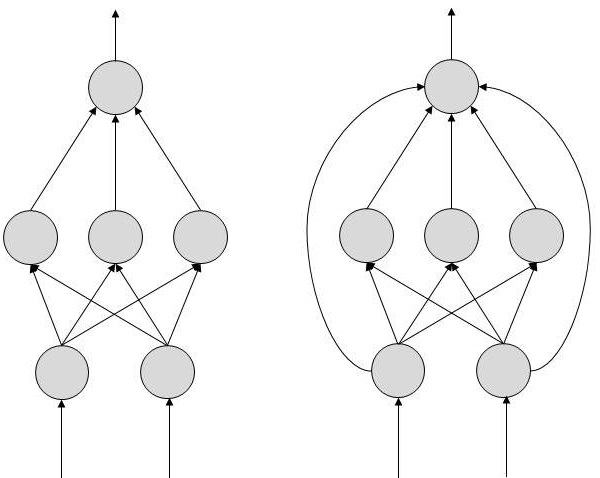
在这种 ANN 中,信息流是单向的。一个单元将信息发送到另一个单元,而它不会从该单元接收任何信息。没有反馈回路。它们用于模式生成/识别/分类。它们具有固定的输入和输出。
反馈 ANN
在这里,允许反馈回路。它们用于内容寻址存储器。
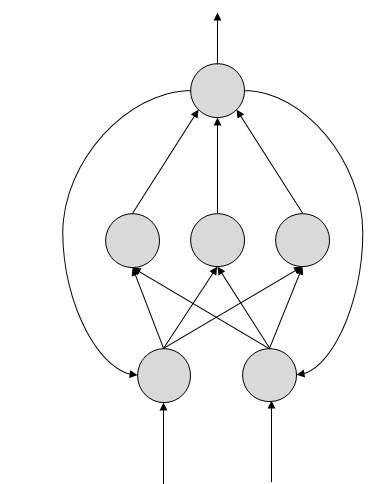
ANN 的工作原理
在所示的拓扑图中,每个箭头表示两个神经元之间的连接,并指示信息流的路径。每个连接都有一个权重,一个控制两个神经元之间信号的整数。
如果网络生成“良好或期望的”输出,则无需调整权重。但是,如果网络生成“差或不期望的”输出或错误,则系统会更改权重以改进后续结果。
ANN 中的机器学习
ANN 能够学习,并且需要进行训练。有几种学习策略:
监督学习 - 它涉及一位比 ANN 本身更博学的教师。例如,教师提供一些示例数据,教师已经知道这些数据的答案。
例如,模式识别。ANN 在识别时会提出猜测。然后,教师会向 ANN 提供答案。然后,网络将其猜测与教师的“正确”答案进行比较,并根据错误进行调整。
无监督学习 - 当没有带有已知答案的示例数据集时需要这种学习。例如,搜索隐藏模式。在这种情况下,聚类,即根据现有数据集中的一些未知模式将一组元素划分为组,是基于现有的数据集进行的。
强化学习 - 这种策略建立在观察的基础上。ANN 通过观察其环境做出决策。如果观察结果为负,则网络会调整其权重,以便下次能够做出不同的所需决策。
反向传播算法
它是训练或学习算法。它通过示例学习。如果您向算法提交您希望网络执行的操作的示例,它会更改网络的权重,以便它在完成训练后可以为特定输入生成所需的输出。
反向传播网络非常适合简单的模式识别和映射任务。
贝叶斯网络 (BN)
这些是用于表示一组随机变量之间概率关系的图形结构。贝叶斯网络也称为信念网络或贝叶斯网。BN 推理不确定域。
在这些网络中,每个节点都表示具有特定命题的随机变量。例如,在医学诊断领域,节点 Cancer 表示患者患有癌症的命题。
连接节点的边表示这些随机变量之间的概率依赖关系。如果两个节点中的一个影响另一个,那么它们必须在影响的方向上直接连接。变量之间关系的强度由与每个节点相关的概率来量化。
BN 中的弧线只有一个约束,即您不能简单地沿着有向弧线返回到一个节点。因此,BN 被称为有向无环图 (DAG)。
BN 能够同时处理多值变量。BN 变量由两个维度组成:
- 命题的范围
- 分配给每个命题的概率。
考虑一个有限集 X = {X1, X2, …,Xn} 的离散随机变量,其中每个变量Xi可以取自一个有限集的值,表示为Val(Xi)。如果从变量Xi到变量Xj有一条有向链接,则变量Xi将是变量Xj的父节点,显示变量之间的直接依赖关系。
BN 的结构非常适合结合先验知识和观察数据。BN 可用于学习因果关系并理解各种问题域,以及预测未来事件,即使在数据缺失的情况下也是如此。
构建贝叶斯网络
知识工程师可以构建贝叶斯网络。知识工程师在构建它时需要采取许多步骤。
示例问题 - 肺癌。一位患者一直患有呼吸困难。他去看医生,怀疑自己患有肺癌。医生知道,除了肺癌外,患者还可能患有其他各种疾病,例如结核病和支气管炎。
收集问题相关信息
- 患者是否吸烟?如果是,则患癌症和支气管炎的可能性很高。
- 患者是否接触过空气污染?如果是,是什么样的空气污染?
- 进行 X 光检查阳性 X 光检查表明结核病或肺癌。
识别有趣的变量
知识工程师尝试回答以下问题:
- 表示哪些节点?
- 它们可以取什么值?它们可以处于什么状态?
现在让我们考虑只有离散值的节点。变量必须每次恰好取这些值中的一个。
常见的离散节点类型有:
布尔节点 - 它们表示命题,取二元值 TRUE (T) 和 FALSE (F)。
有序值 - 节点Pollution可以表示并取自{low, medium, high}的值,描述患者接触污染的程度。
整数值 - 一个名为Age的节点可以表示患者的年龄,可能的值范围为 1 到 120。即使在这么早的阶段,建模选择也在进行。
肺癌示例中可能的节点和值:
| 节点名称 | 类型 | 值 | 节点创建 |
|---|---|---|---|
| 污染 | 二进制 | {LOW, HIGH, MEDIUM} |  |
| 吸烟者 | 布尔值 | {TRUE, FASLE} | |
| 肺癌 | 布尔值 | {TRUE, FASLE} | |
| X 射线 | 二进制 | {阳性,阴性} |
创建节点之间的弧线
网络的拓扑结构应捕捉变量之间的定性关系。
例如,是什么导致患者患肺癌?- 污染和吸烟。然后从节点Pollution和节点Smoker添加弧线到节点Lung-Cancer。
同样,如果患者患有肺癌,则 X 光检查结果将为阳性。然后从节点Lung-Cancer添加弧线到节点X-Ray。
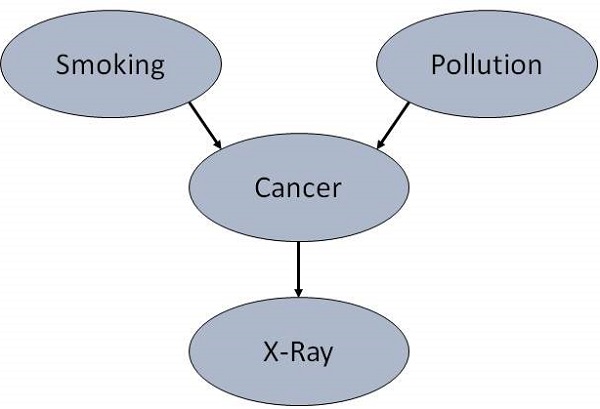
指定拓扑结构
按照惯例,BN 的布局方式是弧线从上到下指向。节点 X 的父节点集由 Parents(X) 给出。
Lung-Cancer节点有两个父节点(原因):Pollution和Smoker,而节点Smoker是节点X-Ray的祖先。类似地,X-Ray是节点Lung-Cancer的子节点(结果或影响)和节点Smoker和Pollution的后继。
条件概率
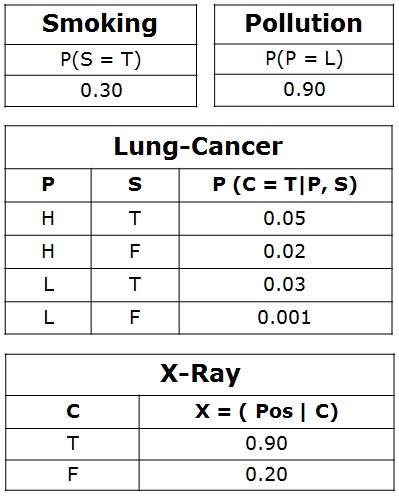
现在量化连接节点之间的关系:这是通过为每个节点指定条件概率分布来完成的。由于这里只考虑离散变量,因此它采用条件概率表 (CPT)的形式。
首先,对于每个节点,我们需要查看这些父节点的所有可能的值组合。每个这样的组合称为父集的实例化。对于父节点值的每个不同的实例化,我们需要指定子节点将取的值的概率。
例如,Lung-Cancer节点的父节点是Pollution和Smoking。它们取可能的值 = {(H,T), ( H,F), (L,T), (L,F)}。CPT 分别指定了每种情况下癌症的概率为<0.05, 0.02, 0.03, 0.001>。
每个节点将具有如下关联的条件概率:
神经网络的应用
它们可以执行对人类来说很容易但对机器来说很困难的任务:
航空航天 - 自动驾驶飞机,飞机故障检测。
汽车 - 汽车导航系统。
军事 - 武器定位和转向,目标跟踪,目标识别,面部识别,信号/图像识别。
电子 - 代码序列预测,IC 芯片布局,芯片故障分析,机器视觉,语音合成。
金融 - 房地产估价、贷款顾问、抵押贷款筛选、公司债券评级、投资组合交易程序、公司财务分析、货币价值预测、文件阅读器、信用申请评估员。
工业 - 制造过程控制、产品设计与分析、质量检验系统、焊接质量分析、纸张质量预测、化学产品设计分析、化学过程系统的动态建模、机器维护分析、项目投标、计划和管理。
医疗 - 癌细胞分析、脑电图和心电图分析、假肢设计、移植时间优化器。
语音 - 语音识别、语音分类、文本到语音转换。
电信 - 图像和数据压缩、自动化信息服务、实时口语翻译。
交通 - 卡车制动系统诊断、车辆调度、路线系统。
软件 - 人脸识别、光学字符识别等中的模式识别。
时间序列预测 - 人工神经网络用于预测股票和自然灾害。
信号处理 - 神经网络可以被训练来处理音频信号并在助听器中对其进行适当的过滤。
控制 - 人工神经网络通常用于做出物理车辆的转向决策。
异常检测 - 由于人工神经网络擅长识别模式,因此它们也可以被训练在发生与模式不符的异常情况时生成输出。