- 算法设计与分析
- 首页
- 算法基础
- DAA - 算法导论
- DAA - 算法分析
- DAA - 分析方法
- DAA - 渐进符号与先验分析
- DAA - 时间复杂度
- DAA - 主定理
- DAA - 空间复杂度
- 分治法
- DAA - 分治算法
- DAA - 最大最小问题
- DAA - 归并排序算法
- DAA - Strassen 矩阵乘法
- DAA - Karatsuba 算法
- DAA - 汉诺塔问题
- 贪心算法
- DAA - 贪心算法
- DAA - 旅行商问题
- DAA - Prim 最小生成树
- DAA - Kruskal 最小生成树
- DAA - Dijkstra 最短路径算法
- DAA - 地图着色算法
- DAA - 分数背包问题
- DAA - 带截止日期的作业排序
- DAA - 最优合并模式
- 动态规划
- DAA - 动态规划
- DAA - 矩阵链乘法
- DAA - Floyd-Warshall 算法
- DAA - 0-1 背包问题
- DAA - 最长公共子序列算法
- DAA - 使用动态规划的旅行商问题
- 随机化算法
- DAA - 随机化算法
- DAA - 随机快速排序算法
- DAA - Karger 最小割算法
- DAA - Fisher-Yates 洗牌算法
- 近似算法
- DAA - 近似算法
- DAA - 顶点覆盖问题
- DAA - 集合覆盖问题
- DAA - 旅行商问题近似算法
- 排序技术
- DAA - 冒泡排序算法
- DAA - 插入排序算法
- DAA - 选择排序算法
- DAA - 希尔排序算法
- DAA - 堆排序算法
- DAA - 桶排序算法
- DAA - 计数排序算法
- DAA - 基数排序算法
- DAA - 快速排序算法
- 搜索技术
- DAA - 搜索技术简介
- DAA - 线性搜索
- DAA - 二分搜索
- DAA - 插值搜索
- DAA - 跳跃搜索
- DAA - 指数搜索
- DAA - 斐波那契搜索
- DAA - 子列表搜索
- DAA - 哈希表
- 图论
- DAA - 最短路径
- DAA - 多阶段图
- DAA - 最优代价二叉搜索树
- 堆算法
- DAA - 二叉堆
- DAA - 插入方法
- DAA - 堆化方法
- DAA - 提取方法
- 复杂度理论
- DAA - 确定性计算与非确定性计算
- DAA - 最大团
- DAA - 顶点覆盖
- DAA - P 类和 NP 类
- DAA - 库克定理
- DAA - NP-Hard 和 NP-Complete 类
- DAA - 爬山算法
- DAA 有用资源
- DAA - 快速指南
- DAA - 有用资源
- DAA - 讨论
二叉堆的设计与分析

堆有很多种类型,但在本章中,我们将讨论二叉堆。二叉堆是一种数据结构,它看起来类似于一棵完全二叉树。堆数据结构遵循下面讨论的排序属性。通常,堆用数组表示。在本章中,我们用H表示堆。
由于堆的元素存储在数组中,假设起始索引为1,则第i个元素的父节点的位置可以在⌊ i/2 ⌋找到。第i个节点的左孩子和右孩子分别位于2i和2i + 1的位置。
根据排序属性,二叉堆可以进一步分类为最大堆或最小堆。
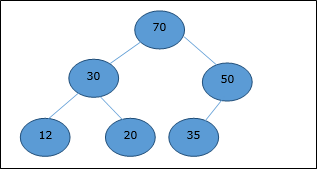
最大堆
在这种堆中,节点的键值大于或等于其最高子节点的键值。
因此,H[Parent(i)] ≥ H[i]
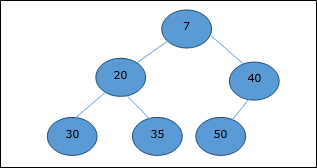
最小堆
在最小堆中,节点的键值小于或等于其最低子节点的键值。
因此,H[Parent(i)] ≤ H[i]
在本例中,基本操作如下所示,针对最大堆。在堆中插入和删除元素需要重新排列元素。因此,需要调用堆化函数。
数组表示
完全二叉树可以用数组表示,使用层序遍历存储其元素。
让我们考虑一个堆(如下所示),它将由数组H表示。
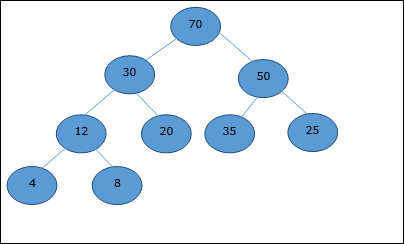
假设起始索引为0,使用层序遍历,元素按如下方式保存在数组中。
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... |
| 元素 | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ... |
在本例中,堆上的操作针对最大堆进行表示。
要查找索引为i的元素的父节点的索引,使用以下算法Parent (numbers[], i)。
Algorithm: Parent (numbers[], i) if i == 1 return NULL else [i / 2]
可以使用以下算法Left-Child (numbers[], i)查找索引为i的元素的左孩子的索引。
Algorithm: Left-Child (numbers[], i) If 2 * i ≤ heapsize return [2 * i] else return NULL
可以使用以下算法Right-Child(numbers[], i)查找索引为i的元素的右孩子的索引。
Algorithm: Right-Child (numbers[], i) if 2 * i < heapsize return [2 * i + 1] else return NULL
广告