- 超大规模集成电路设计教程
- 超大规模集成电路设计 - 首页
- 超大规模集成电路设计 - 数字系统
- 超大规模集成电路设计 - FPGA 技术
- 超大规模集成电路设计 - MOS 晶体管
- 超大规模集成电路设计 - MOS 反相器
- 组合 MOS 逻辑电路
- 时序 MOS 逻辑电路
- VHDL 编程
- VHDL - 简介
- VHDL - 组合电路
- VHDL - 时序电路
- Verilog
- Verilog - 简介
- 行为建模与时序
- 超大规模集成电路设计有用资源
- 超大规模集成电路设计 - 快速指南
- 超大规模集成电路设计 - 有用资源
- 超大规模集成电路设计 - 讨论
超大规模集成电路设计 - 快速指南
超大规模集成电路设计 - 数字系统
超大规模集成电路 (VLSI) 是通过将数千个晶体管组合到单个芯片上来创建集成电路 (IC) 的过程。VLSI 起源于 20 世纪 70 年代,当时复杂的半导体和通信技术正在发展。微处理器是一种 VLSI 器件。
在引入 VLSI 技术之前,大多数 IC 的功能有限。一个电子电路可能由CPU、ROM、RAM和其他粘合逻辑组成。VLSI 使 IC 设计人员能够将所有这些都添加到一个芯片中。
电子工业在过去几十年中取得了惊人的发展,这主要是由于大规模集成技术和系统设计应用的快速发展。随着超大规模集成 (VLSI) 设计的出现,集成电路 (IC) 在高性能计算、控制、电信、图像和视频处理以及消费电子产品中的应用数量正在快速增长。
当前的尖端技术,例如高分辨率和低比特率视频以及蜂窝通信,为最终用户提供了大量的应用程序、处理能力和便携性。预计这一趋势将快速增长,这对 VLSI 设计和系统设计具有非常重要的意义。
VLSI 设计流程
下图显示了 VLSI IC 电路设计流程。各个设计级别均已编号,各个模块显示设计流程中的过程。
规范是首先要确定的,它们抽象地描述了待设计的数字 IC 电路的功 能、接口和架构。
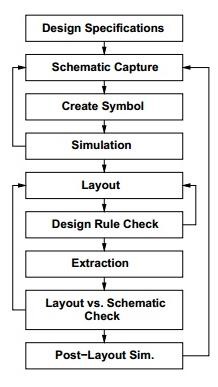
然后创建行为描述,以根据功能、性能、对给定标准的符合性以及其他规范来分析设计。
使用 HDL 完成 RTL 描述。对该 RTL 描述进行仿真以测试功能。从这里开始,我们需要 EDA 工具的帮助。
然后使用逻辑综合工具将 RTL 描述转换为门级网表。门级网表是根据门和它们之间连接来描述电路的,这些门以满足时序、功耗和面积规范的方式制造。
最后,制作物理布局,对其进行验证,然后发送到制造工厂。
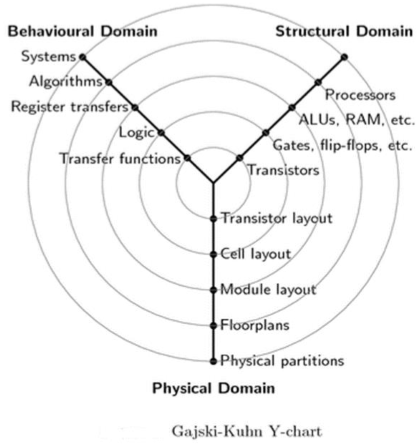
Y 图表
Gajski-Kuhn Y 图表是一个模型,它捕获了设计半导体器件时的考虑因素。
Gajski-Kuhn Y 图表的三个域位于径向轴上。每个域都可以使用同心环细分为不同的抽象级别。
在顶层(外环),我们考虑芯片的架构;在较低的级别(内环),我们依次将设计细化为更详细的实现 -
通过高级综合或逻辑综合过程,可以从行为描述创建结构描述。
通过布局综合,可以从结构描述创建物理描述。
设计层次结构 - 结构
设计层次结构涉及“分而治之”的原则。它只不过是将任务分解成更小的任务,直到达到最简单的级别。此过程最适用,因为设计的最后演变变得非常简单,其制造变得更容易。
我们可以将给定任务设计到设计流程过程的域(行为、结构和几何)。为了理解这一点,让我们以设计一个 16 位加法器为例,如下图所示。
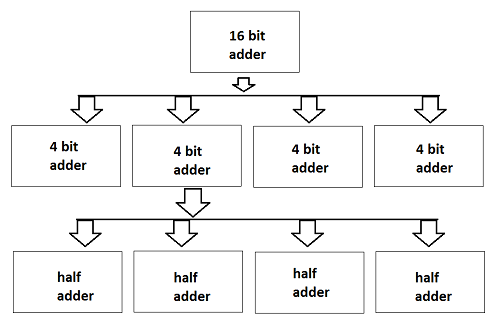
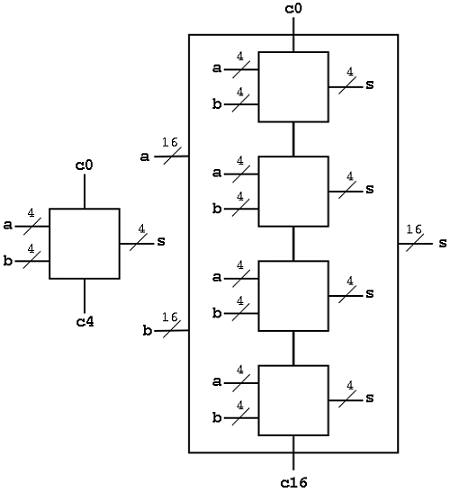
在这里,整个 16 位加法器芯片被分成四个 4 位加法器模块。此外,将 4 位加法器进一步划分为 1 位加法器或半加法器。1 位加法是最简单的设计过程,其内部电路也很容易在芯片上制造。现在,连接所有最后的四个加法器,我们可以设计一个 4 位加法器,继续下去,我们可以设计一个 16 位加法器。
超大规模集成电路设计 - FPGA 技术
FPGA – 简介
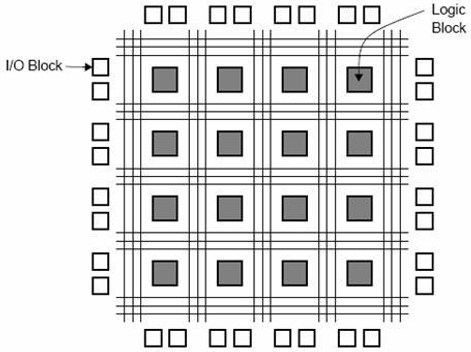
FPGA的全称是“现场可编程门阵列”。它包含一万到一百万多个具有可编程互连的逻辑门。可编程互连可供用户或设计人员轻松执行给定功能。给定图中显示了一个典型的 FPGA 芯片模型。有一些 I/O 块,它们根据功能进行设计和编号。对于每个逻辑级别组合模块,都有CLB(可配置逻辑块)。
CLB 执行分配给模块的逻辑运算。CLB 和 I/O 块之间的互连是借助水平布线通道、垂直布线通道和 PSM(可编程多路复用器)实现的。
它包含的 CLB 数量仅决定 FPGA 的复杂性。CLB 和 PSM 的功能由 VHDL 或任何其他硬件描述语言设计。编程后,CLB 和 PSM 被放置在芯片上,并通过布线通道相互连接。
优点
- 它只需要很少的时间;从设计过程到功能芯片。
- 它不涉及任何物理制造步骤。
- 唯一的缺点是,它比其他样式贵。
门阵列设计
就快速原型制作能力而言,门阵列 (GA) 排名第二,仅次于 FPGA。虽然用户编程对于 FPGA 芯片的设计实现非常重要,但 GA 使用金属掩模设计和处理。门阵列实现需要两步制造过程。
第一阶段产生每个 GA 芯片上的一组未提交的晶体管。这些未提交的芯片可以存储以备后用,这可以通过定义阵列晶体管之间的金属互连来完成。金属互连的图案化是在芯片制造过程结束时完成的,因此周转时间仍然可以很短,从几天到几周不等。下图显示了门阵列实现的基本处理步骤。
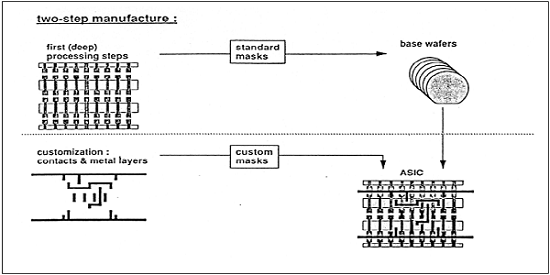
典型的门阵列平台使用称为通道的专用区域,用于 MOS 晶体管行或列之间的单元间布线。它们简化了互连。执行基本逻辑门的互连模式存储在库中,然后可以使用该库根据网表定制未提交晶体管的行。
在大多数现代 GA 中,多层金属用于通道布线。通过使用多层互连,可以在有源单元区域上实现布线;因此,可以像在海门 (SOG) 芯片中一样移除布线通道。在这里,整个芯片表面都覆盖着未提交的 nMOS 和 pMOS 晶体管。可以使用金属掩模定制相邻晶体管以形成基本逻辑门。
对于单元间布线,必须牺牲一些未提交的晶体管。这种设计风格带来了更高的互连灵活性,通常还具有更高的密度。GA 芯片利用率由使用的芯片面积除以总芯片面积来衡量。它高于 FPGA,芯片速度也是如此。
基于标准单元的设计
基于标准单元的设计需要开发完整的定制掩模组。标准单元也称为多单元。在这种方法中,所有常用的逻辑单元都经过开发、表征并存储在标准单元库中。
库可能包含几百个单元,包括反相器、与非门、或非门、复杂的 AOI、OAI 门、D 锁存器和触发器。每种门类型都可以实现多个版本,以提供针对不同扇出足够的驱动能力。反相器门可以具有标准尺寸、双倍尺寸和四倍尺寸,以便芯片设计人员可以选择合适的尺寸以获得高电路速度和布局密度。
根据几个不同的表征类别对每个单元进行表征,例如:
- 延迟时间与负载电容
- 电路仿真模型
- 时序仿真模型
- 故障仿真模型
- 用于布局布线的单元数据
- 掩模数据
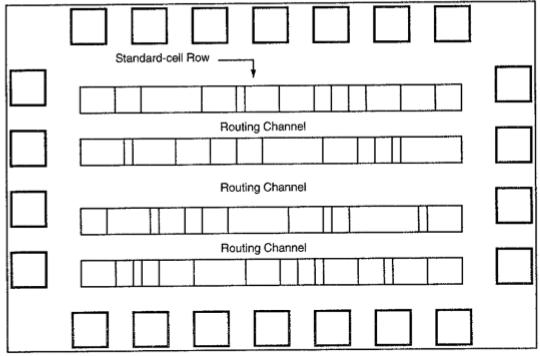
为了自动放置单元和布线,每个单元布局的设计高度固定,以便可以并排绑定多个单元以形成行。电源和地轨平行于单元的上边界和下边界运行。因此,相邻单元共享一个公共电源总线和一个公共地总线。下图是基于标准单元的设计的平面图。
全定制设计
在全定制设计中,整个掩模设计都是新的,无需使用任何库。这种设计风格的开发成本正在上升。因此,设计重用的概念正变得越来越流行,以缩短设计周期和降低开发成本。
最难的全定制设计可能是存储单元的设计,无论是静态的还是动态的。对于逻辑芯片设计,可以使用同一芯片上不同设计风格的组合(即标准单元、数据路径单元和可编程逻辑阵列 (PLA))获得良好的协商。
实际上,设计人员进行全定制布局,即每个晶体管的几何形状、方向和位置。设计效率通常非常低;通常每个设计人员每天只有几十个晶体管。在数字 CMOS VLSI 中,由于人工成本高,几乎不使用全定制设计。这些设计风格包括高产量产品的 设计,例如存储芯片、高性能微处理器和 FPGA。
超大规模集成电路设计 - MOS 晶体管
互补金属氧化物半导体 (CMOS) 技术现已被广泛用于在众多不同应用中形成电路。如今的计算机、CPU 和手机都使用 CMOS,因为它具有几个关键优势。CMOS 具有低功耗、相对较高的速度、两种状态下的高噪声容限,并且可以在很宽的源电压和输入电压范围内工作(前提是源电压固定)。
对于我们将讨论的过程,可用的晶体管类型是金属氧化物半导体场效应晶体管 (MOSFET)。这些晶体管像“三明治”一样形成,由半导体层(通常是切片或晶片,来自单晶硅)、一层二氧化硅(氧化物)和一层金属组成。
MOSFET 的结构
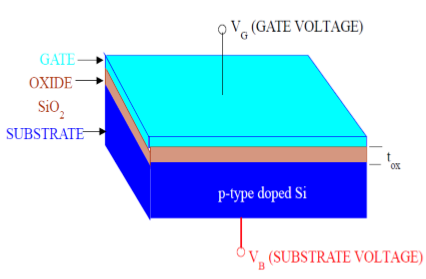
如图所示,MOS 结构包含三层 -
金属栅极电极
绝缘氧化层 (SiO2)
P 型半导体(衬底)
MOS 结构形成一个电容器,栅极和衬底作为两个极板,氧化层作为介电材料。介电材料 (SiO2) 的厚度通常在 10 nm 到 50 nm 之间。可以通过施加到栅极和衬底端子的外部电压来控制衬底内的载流子浓度和分布。现在,为了理解 MOS 的结构,首先考虑 P 型半导体衬底的基本电特性。
半导体材料中载流子的浓度始终遵循**质量作用定律**。质量作用定律表示为:
$$n.p=n_{i}^{2}$$
其中:
n 为电子载流子浓度
p 为空穴载流子浓度
ni 为硅的本征载流子浓度
现在假设衬底以受主(硼)浓度NA均匀掺杂。因此,p型衬底中的电子和空穴浓度为:
$$n_{po}=\frac{n_{i}^{2}}{N_{A}}$$
$$p_{po}=N_{A}$$
这里,掺杂浓度NA比本征浓度ni大(1015到1016 cm−3)。现在,为了理解MOS结构,考虑p型硅衬底的能级图。
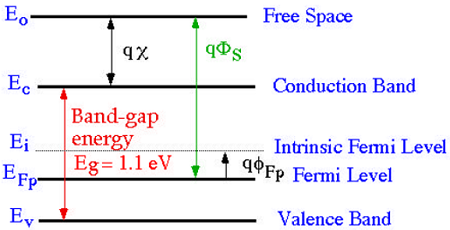
如图所示,导带和价带之间的带隙为1.1eV。这里,费米势ΦF是本征费米能级(Ei)和费米能级(EFP)之间的差值。
其中费米能级EF取决于掺杂浓度。费米势ΦF是本征费米能级(Ei)和费米能级(EFP)之间的差值。
数学上表示为:
$$\Phi_{Fp}=\frac{E_{F}-E_{i}}{q}$$
导带和自由空间之间的电势差称为电子亲和势,用qx表示。
因此,电子从费米能级移动到自由空间所需的能量称为功函数(qΦS),其表达式为:
$$q\Phi _{s}=(E_{c}-E_{F})+qx$$
下图显示了构成MOS器件的各组成部分的能带图。
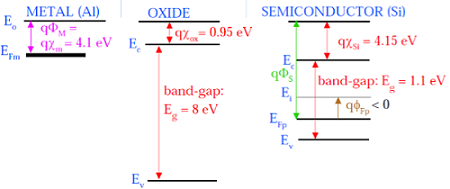
如图所示,绝缘SiO2层具有8eV的大能带隙,功函数为0.95 eV。金属栅极的功函数为4.1eV。这里,功函数不同,因此会在MOS系统中产生压降。下图显示了MOS系统的组合能带图。
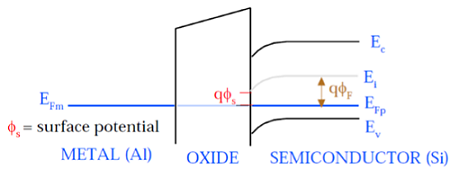
如图所示,金属栅极和半导体(Si)的费米能级处于相同的电势。表面处的费米势称为表面势ΦS,其大小小于费米势ΦF。
MOSFET的工作原理
MOSFET由一个MOS电容和两个放置在沟道区域附近的p-n结组成,该区域由栅极电压控制。为了使两个p-n结反向偏置,衬底电势保持低于其他三个端子的电势。
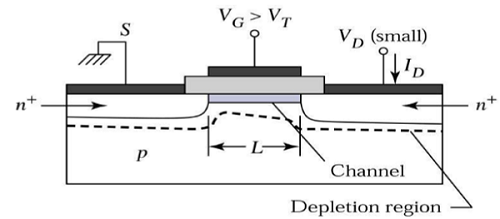
如果栅极电压升高到超过阈值电压(VGS>VTO),则会在表面上形成反型层,并在源极和漏极之间形成n型沟道。该n型沟道将根据VDS的值传输漏极电流。
对于不同的VDS值,MOSFET可以工作在不同的区域,如下所述。
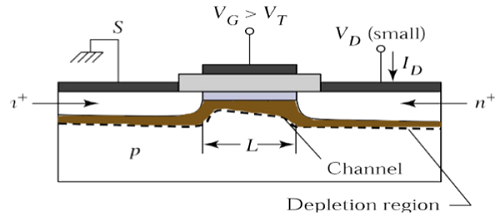
线性区
在VDS = 0时,反型沟道区域处于热平衡状态,漏极电流ID = 0。现在,如果施加小的漏极电压VDS > 0,则与VDS成比例的漏极电流将开始从源极流向漏极,穿过沟道。
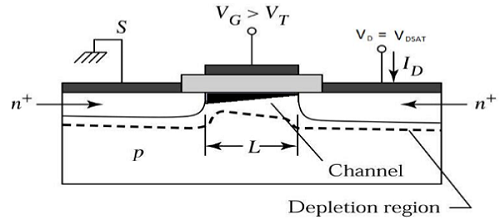
沟道为电流从源极流向漏极提供了连续的路径。这种工作模式称为**线性区**。下图显示了在线性区工作的n沟道MOSFET的截面图。
饱和区边缘
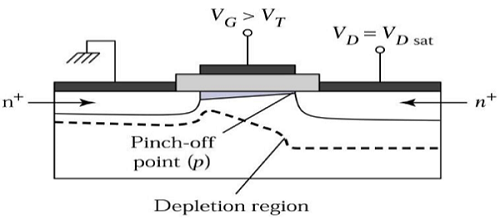
现在,如果增加VDS,则沟道中的电荷和沟道深度在漏极端减小。对于VDS = VDSAT,沟道中的电荷减少到零,这称为**夹断点**。下图显示了在饱和区边缘工作的n沟道MOSFET的截面图。
饱和区
对于VDS>VDSAT,在漏极附近会形成耗尽层,并且通过增加漏极电压,该耗尽层会延伸到源极。
这种工作模式称为**饱和区**。来自源极到沟道末端的电子进入漏极耗尽区,并在高电场中被加速朝向漏极。
MOSFET电流-电压特性
为了理解MOSFET的电流-电压特性,对沟道进行了近似。如果没有这种近似,MOS系统的三维分析将变得复杂。用于电流-电压特性的**渐变沟道近似(GCA)** 将简化分析问题。
渐变沟道近似(GCA)
考虑在线性模式下工作的n沟道MOSFET的截面图。这里,源极和衬底连接到地。VS = VB = 0。栅源电压(VGS)和漏源电压(VDS)是控制漏极电流ID的外部参数。
将VGS设置为高于阈值电压VTO的电压,以在源极和漏极之间形成沟道。如图所示,x方向垂直于表面,y方向平行于表面。
这里,y = 0在源极端,如图所示。相对于源极的沟道电压用VC(Y)表示。假设阈值电压VTO沿沟道区域(从y = 0到y = L)是恒定的。沟道电压VC的边界条件为:
$$V_{c}\left ( y = 0 \right ) = V_{s} = 0 \,且\,V_{c}\left ( y = L \right ) = V_{DS}$$
我们还可以假设:
$$V_{GS}\geq V_{TO}$$ 且
$$V_{GD} = V_{GS}-V_{DS}\geq V_{TO}$$
设Q1(y)为表面反型层中的总可动电子电荷。此电子电荷可表示为:
$$Q1(y)=-C_{ox}.[V_{GS}-V_{C(Y)}-V_{TO}]$$
下图显示了表面反型层的空间几何形状并指出了其尺寸。当我们从漏极移动到源极时,反型层逐渐变细。现在,如果我们考虑沟道长度L的小区域dy,则该区域提供的增量电阻dR可表示为:
$$dR=-\frac{dy}{w.\mu _{n}.Q1(y)}$$
这里,负号是由于反型层电荷Q1的负极性,μn是表面迁移率,它是常数。现在,将Q1(y)的值代入dR方程:
$$dR=-\frac{dy}{w.\mu _{n}.\left \{ -C_{ox}\left [ V_{GS}-V_{C\left ( Y \right )} \right ]-V_{TO} \right \}}$$
$$dR=\frac{dy}{w.\mu _{n}.C_{ox}\left [ V_{GS}-V_{C\left ( Y \right )} \right ]-V_{TO}}$$
现在,小dy区域中的电压降可以表示为:
$$dV_{c}=I_{D}.dR$$
将dR的值代入上述方程:
$$dV_{C}=I_{D}.\frac{dy}{w.\mu_{n}.C_{ox}\left [ V_{GS}-V_{C(Y)} \right ]-V_{TO}}$$
$$w.\mu _{n}.C_{ox}\left [ V_{GS}-V_{C(Y)}-V_{TO} \right ].dV_{C}=I_{D}.dy$$
为了获得整个沟道区域上的漏极电流ID,上述方程可以沿沟道从y = 0积分到y = L,电压VC(y) = 0到VC(y) = VDS,
$$C_{ox}.w.\mu _{n}.\int_{V_{c}=0}^{V_{DS}} \left [ V_{GS}-V_{C\left ( Y \right )}-V_{TO} \right ].dV_{C} = \int_{Y=0}^{L}I_{D}.dy$$
$$\frac{C_{ox}.w.\mu _{n}}{2}\left ( 2\left [ V_{GS}-V_{TO} \right ] V_{DS}-V_{DS}^{2}\right ) = I_{D}\left [ L-0 \right ]$$
$$I_{D} = \frac{C_{ox}.\mu _{n}}{2}.\frac{w}{L}\left ( 2\left [ V_{GS}-V_{TO} \right ]V_{DS}-V_{DS}^{2} \right )$$
对于线性区VDS < VGS − VTO。对于饱和区,VDS的值大于(VGS − VTO)。因此,对于饱和区VDS = (VGS − VTO)。
$$I_{D} = C_{ox}.\mu _{n}.\frac{w}{2}\left ( \frac{\left [ 2V_{DS} \right ]V_{DS}-V_{DS}^{2}}{L} \right )$$
$$I_{D} = C_{ox}.\mu _{n}.\frac{w}{2}\left ( \frac{2V_{DS}^{2}-V_{DS}^{2}}{L} \right )$$
$$I_{D} = C_{ox}.\mu _{n}.\frac{w}{2}\left ( \frac{V_{DS}^{2}}{L} \right )$$
$$I_{D} = C_{ox}.\mu _{n}.\frac{w}{2}\left ( \frac{\left [ V_{GS}-V_{TO} \right ]^{2}}{L} \right )$$
超大规模集成电路设计 - MOS 反相器
反相器是所有数字设计的核心。一旦清楚地理解了它的工作原理和特性,设计更复杂的结构,如与非门、加法器、乘法器和微处理器就会大大简化。这些复杂电路的电气行为几乎可以完全通过推断反相器的结果来推导。
反相器的分析可以扩展到解释更复杂门(如与非门、或非门或异或门)的行为,而这些门又构成了乘法器和处理器等模块的构建块。在本章中,我们关注反相器门的单一实现形式,即静态CMOS反相器——简称CMOS反相器。这当然是目前最流行的,因此值得我们特别关注。
工作原理
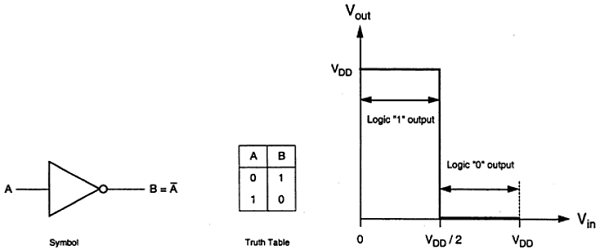
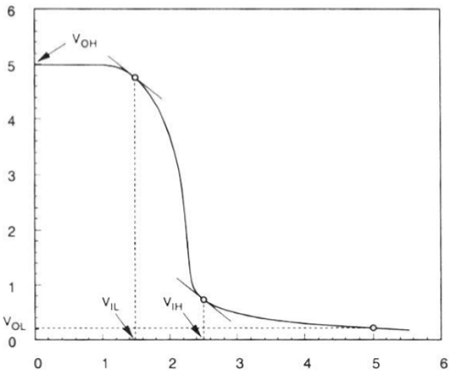
理想反相器的逻辑符号和真值表如下图所示。这里A是输入,B是反相输出,由它们的节点电压表示。使用正逻辑,逻辑1的布尔值由Vdd表示,逻辑0由0表示。Vth是反相器阈值电压,其值为Vdd /2,其中Vdd是输出电压。
当输入小于Vth时,输出从0切换到Vdd。因此,对于0<Vin<Vth,输出等于逻辑0输入;对于Vth<Vin< Vdd,输出等于反相器的逻辑1输入。
图中所示的特性是理想的。nMOS反相器的通用电路结构如下图所示。
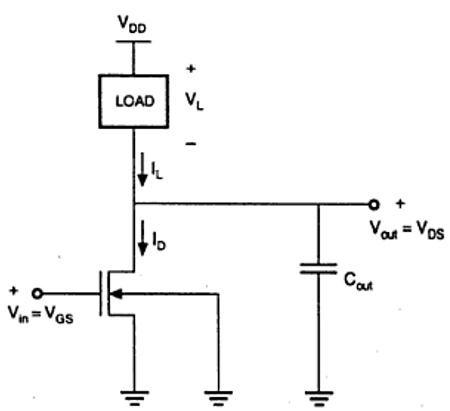
从给定的图中,我们可以看到反相器的输入电压等于nMOS晶体管的栅极到源极电压,反相器的输出电压等于nMOS晶体管的漏极到源极电压。nMOS的源极到衬底电压也称为晶体管驱动器,其接地;因此VSS = 0。输出节点连接到用于VTC的集总电容。
电阻负载反相器
基本电阻负载反相器的结构如下图所示。这里,增强型nMOS充当驱动晶体管。负载由一个简单的线性电阻RL组成。电路的电源为VDD,漏极电流ID等于负载电流IR。
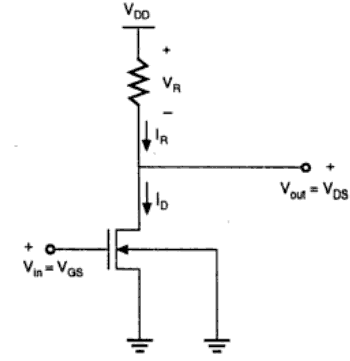
电路工作原理
当驱动晶体管的输入小于阈值电压VTH (Vin < VTH)时,驱动晶体管处于截止区域,不导通任何电流。因此,负载电阻上的电压降为零,输出电压等于VDD。现在,当输入电压进一步增加时,驱动晶体管将开始导通非零电流,nMOS进入饱和区。
数学上表示为:
$$I_{D} = \frac{K_{n}}{2}\left [ V_{GS}-V_{TO} \right ]^{2}$$
进一步增加输入电压,驱动晶体管将进入线性区域,驱动晶体管的输出减小。
$$I_{D} = \frac{K_{n}}{2}2\left [ V_{GS}-V_{TO} \right ]V_{DS}-V_{DS}^{2}$$
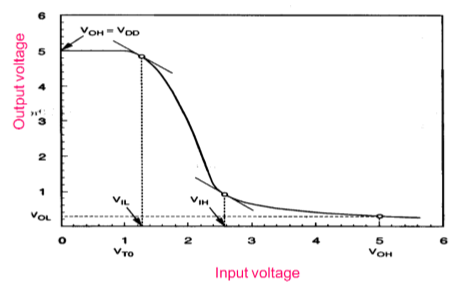
下图所示的电阻负载反相器的VTC指示驱动晶体管的工作模式和电压点。
采用N型MOSFET负载的反相器
使用MOSFET作为负载器件的主要优点是晶体管占用的硅面积小于电阻负载占用的面积。这里,MOSFET是有源负载,采用有源负载的反相器比采用电阻负载的反相器性能更好。
增强型负载NMOS
图中显示了两个带有增强型负载器件的反相器。负载晶体管可以在饱和区或线性区工作,具体取决于施加到其栅极端的偏置电压。饱和增强型负载反相器如图(a)所示。它只需要一个电源和简单的制造工艺,因此VOH限制为VDD − VT。
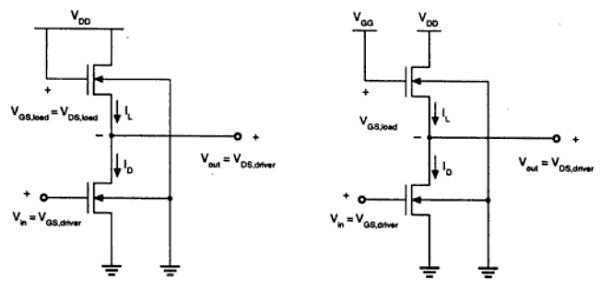
线性增强型负载反相器如图(b)所示。它始终在线性区域工作;因此VOH电平等于VDD。
与饱和增强型反相器相比,线性负载反相器具有更高的噪声容限。但是,线性增强型反相器的缺点是需要两个独立的电源,并且这两个电路都存在高功耗问题。因此,增强型反相器不用于任何大规模数字应用。
耗尽型负载NMOS
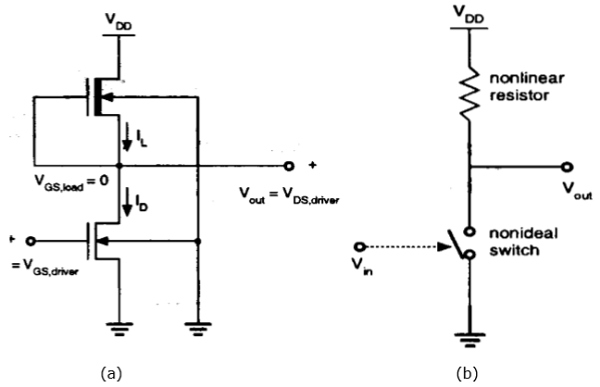
可以使用耗尽型负载反相器克服增强型负载反相器的缺点。与增强型负载反相器相比,耗尽型负载反相器需要更多几个制造步骤来进行沟道注入,以调整负载的阈值电压。
耗尽型负载反相器的优点是:VTC转换尖锐、噪声容限更好、单电源和整体布局面积更小。
如图所示,负载的栅极和源极端子相连接;因此,VGS = 0。因此,负载的阈值电压为负。因此,
$$V_{GS,load}> V_{T,load}$$ 成立
因此,无论输入和输出电压电平如何,负载器件始终具有导电通道。
当负载晶体管处于饱和区时,负载电流由下式给出
$$I_{D,load} = \frac{K_{n,load}}{2}\left [ -V_{T,load}\left ( V_{out} \right ) \right ]^{2}$$
当负载晶体管处于线性区时,负载电流由下式给出
$$I_{D,load} = \frac{K_{n,load}}{2}\left [ 2\left | V_{T,load}\left ( V_{out} \right ) \right |.\left ( V_{DD}-V_{out} \right )-\left ( V_{DD}-V_{out} \right )^{2} \right ]$$
耗尽型负载反相器的电压传输特性如下图所示:
CMOS反相器——电路、工作原理和描述
CMOS反相器电路如下图所示。这里,nMOS和pMOS晶体管充当驱动晶体管;当一个晶体管导通时,另一个晶体管截止。

这种配置称为**互补MOS(CMOS)**。输入连接到两个晶体管的栅极端,以便可以用输入电压直接驱动两者。nMOS的衬底连接到地,pMOS的衬底连接到电源VDD。
因此,两个晶体管的VSB = 0。
$$V_{GS,n}=V_{in}$$
$$V_{DS,n}=V_{out}$$
并且,
$$V_{GS,p}=V_{in}-V_{DD}$$
$$V_{DS,p}=V_{out}-V_{DD}$$
当nMOS的输入小于阈值电压(Vin < VTO,n)时,nMOS截止,pMOS处于线性区。因此,两个晶体管的漏极电流均为零。
$$I_{D,n}=I_{D,p}=0$$
因此,输出电压VOH等于电源电压。
$$V_{out}=V_{OH}=V_{DD}$$
当输入电压大于VDD + VTO,p时,pMOS晶体管处于截止区,nMOS处于线性区,因此两个晶体管的漏极电流均为零。
$$I_{D,n}=I_{D,p}=0$$
因此,输出电压VOL等于零。
$$V_{out}=V_{OL}=0$$
如果Vin > VTO并且满足以下条件,则nMOS工作在饱和区。
$$V_{DS,n}\geq V_{GS,n}-V_{TO,n} $$
$$V_{out}\geq V_{in}-V_{TO,n} $$
如果Vin < VDD + VTO,p并且满足以下条件,则pMOS工作在饱和区。
$$V_{DS,p}\leq V_{GS,p}-V_{TO,p} $$
$$V_{out}\leq V_{in}-V_{TO,p} $$
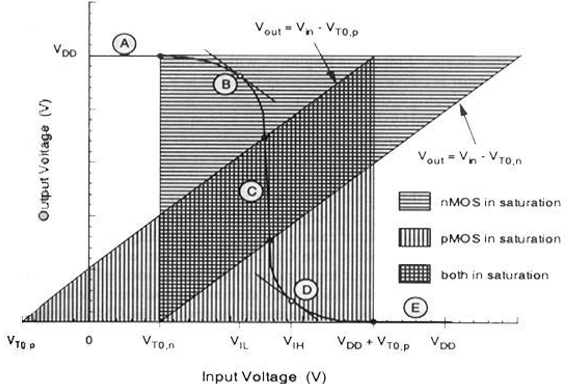
对于不同的输入电压值,下面列出了两个晶体管的工作区域。
| 区域 | Vin | Vout | nMOS | pMOS |
|---|---|---|---|---|
| A | < VTO, n | VOH | 截止 | 线性 |
| B | VIL | 高 ≈ VOH | 饱和 | 线性 |
| C | Vth | Vth | 饱和 | 饱和 |
| D | VIH | 低 ≈ VOL | 线性 | 饱和 |
| E | > (VDD + VTO, p) | VOL | 线性 | 截止 |
CMOS的VTC如下图所示:
组合 MOS 逻辑电路
组合逻辑电路或门是所有数字系统的基本构建块,它们对多个输入变量执行布尔运算,并将输出确定为输入的布尔函数。我们将检查简单的电路配置,例如双输入NAND门和NOR门,然后将我们的分析扩展到更一般的多输入电路结构。
接下来,将以类似的方式介绍CMOS逻辑电路。我们将强调nMOS耗尽型负载逻辑和CMOS逻辑电路之间的异同,并通过示例指出CMOS门的优点。在其最一般的形式中,执行布尔函数的组合逻辑电路或门可以表示为多输入单输出系统,如图所示。
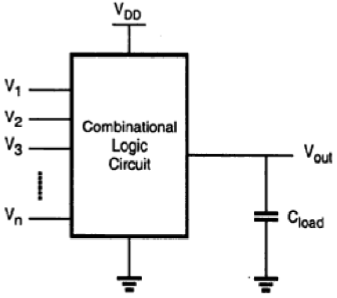
参考接地电位的节点电压表示所有输入变量。使用正逻辑约定,“1”的布尔(或逻辑)值可以用VDD的高电压表示,“0”的布尔(或逻辑)值可以用0的低电压表示。输出节点加载了电容CL,它表示电路中寄生器件的组合电容。
CMOS逻辑电路
CMOS双输入NOR门
该电路由并联连接的n网络和串联连接的互补p网络组成。输入电压VX和VY施加到一个nMOS晶体管和一个pMOS晶体管的栅极。
当一个或两个输入都为高电平时,即当n网络在输出节点和地之间创建导电路径时,p网络将截止。如果两个输入电压都低,即n网络截止,则p网络在输出节点和电源电压之间创建导电路径。
对于任何给定的输入组合,互补电路结构使得输出通过低电阻路径连接到VDD或地,并且对于任何输入组合,VDD和地之间都不会建立直流电流路径。CMOS双输入NOR门的输出电压将获得VOL = 0的逻辑低电压和VOH = VDD的逻辑高电压。开关阈值电压Vth的方程为
$$V_{th}\left ( NOR2 \right ) = \frac{V_{T,n}+\frac{1}{2}\sqrt{\frac{k_{p}}{k_{n}}\left ( V_{DD}-\left | V_{T,p} \right | \right )}}{1+\frac{1}{2}\sqrt{\frac{k_{p}}{k_{n}}}}$$
CMOS双输入NOR门的布局
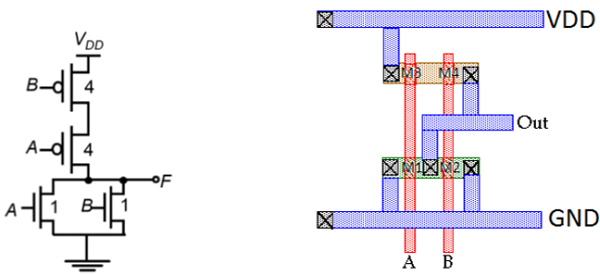
该图显示了使用单层金属和单层多晶硅的CMOS双输入NOR门的示例布局。此布局的特性为:
- 每个输入的单垂直多晶线
- 分别为N型和P型器件的单活性形状
- 水平运行的金属总线
下图显示了CMOS N0R2门的示意图;它直接对应于布局,但不包含W和L信息。扩散区域由矩形表示,金属连接和实线和圆分别表示触点,交叉影线条带分别表示多晶硅柱。示意图用于规划最佳布局拓扑。
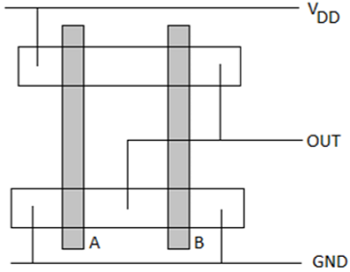
CMOS双输入NAND门
下图给出了双输入CMOS NAND门的电路图。
该电路的工作原理与CMOS双输入NOR运算完全对偶。由两个串联连接的nMOS晶体管组成的n网络,如果两个输入电压都为逻辑高电平,则在输出节点和地之间创建导电路径。p网络中的两个并联连接的pMOS晶体管将关闭。
对于所有其他输入组合,一个或两个pMOS晶体管将导通,而p网络截止,从而在输出节点和电源电压之间创建电流路径。该门的开关阈值获得为:
$$V_{th}\left ( NAND2 \right ) = \frac{V_{T,n}+2\sqrt{\frac{k_{p}}{k_{n}}\left ( V_{DD}-\left | V_{T,p} \right | \right )}}{1+2\sqrt{\frac{k_{p}}{k_{n}}}}$$
此布局的特性如下:
- 输入的单多晶硅线垂直穿过N和P有源区域。
- 单个有源形状用于构建nMOS器件和pMOS器件。
- 电源总线在布局的顶部和底部水平运行。
- 输出线水平运行,便于与相邻电路连接。
复杂逻辑电路
NMOS耗尽负载复杂逻辑门
为了实现多个输入变量的复杂功能,可以将为NOR和NAND开发的基本电路结构和设计原理扩展到复杂的逻辑门。使用少量晶体管实现复杂逻辑功能的能力是nMOS和CMOS逻辑电路最吸引人的特性之一。考虑以下布尔函数为例:
$$ \overline{Z=P\left ( S+T \right )+QR} $$
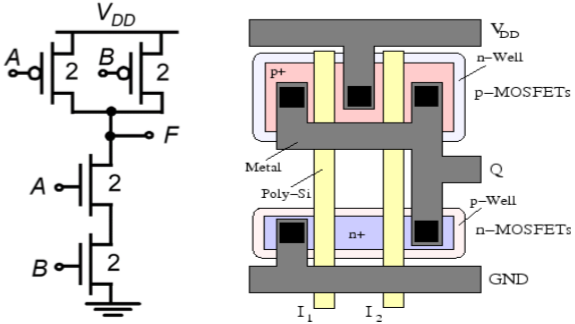
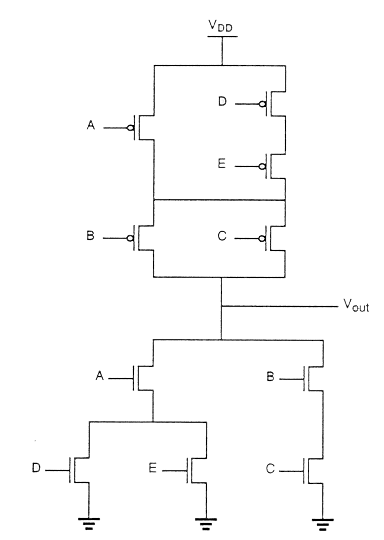
用于实现此功能的nMOS耗尽负载复杂逻辑门如图所示。在此图中,三个驱动晶体管的左侧nMOS驱动分支用于执行逻辑函数P(S+T),而右侧分支执行函数QR。通过并联连接这两个分支,并将负载晶体管置于输出节点和电源电压VDD之间,我们得到给定的复杂函数。每个输入变量只分配给一个驱动器。
检查电路拓扑结构可以得到下拉网络的简单设计原则:
- OR运算由并联连接的驱动器执行。
- AND运算由串联连接的驱动器执行。
- 反转由MOS电路操作的特性提供。
如果实现该函数的电路中所有输入变量均为逻辑高电平,则由五个nMOS晶体管组成的下拉网络的等效驱动器(W/L)比率为
$$ \frac{W}{L}=\frac{1}{\frac{1}{\left ( W/L \right )Q}+\frac{1}{\left ( W/L \right )R}}+\frac{1}{\frac{1}{\left ( W/L \right )P}+\frac{1}{\left ( W/L \right )S+\left ( W/L \right )Q}} $$
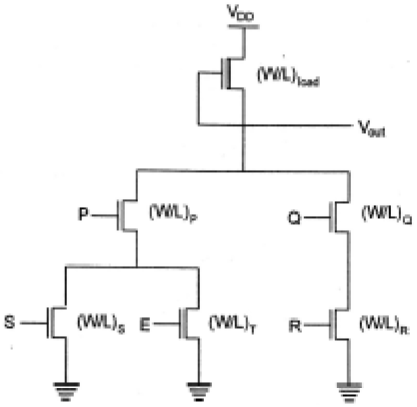
复杂的CMOS逻辑门
n网络或下拉网络的实现基于为nMOS耗尽负载复杂逻辑门检查的相同基本设计原则。pMOS上拉网络必须是n网络的对偶网络。
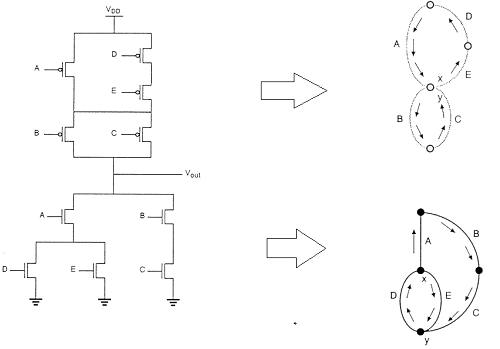
这意味着nMOS网络中的所有并联连接都将对应于pMOS网络中的串联连接,而nMOS网络中的所有串联连接都将对应于pMOS网络中的并联连接。该图显示了从n网络(下拉)图构建对偶p网络(上拉)图的简单方法。
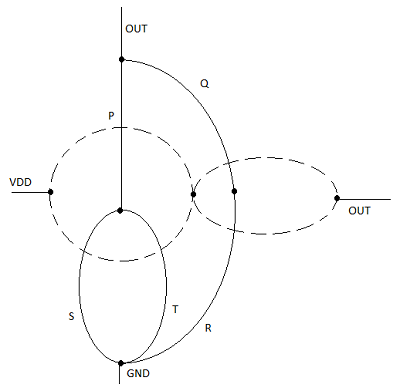
下拉网络中的每个驱动晶体管用ai表示,每个节点用下拉图中的一个顶点表示。接下来,在下拉图的每个封闭区域内创建一个新的顶点,并且相邻的顶点通过边连接,这些边只穿过下拉图中的每条边一次。这个新图显示了上拉网络。
使用欧拉图法的布局技术
该图显示了复杂函数的CMOS实现及其采用任意门排序的简图,该排序为CMOS门提供了非常非优化的布局。
在这种情况下,多晶硅列之间的间距必须允许扩散之间的扩散到扩散间距。这肯定会消耗相当多的额外硅面积。
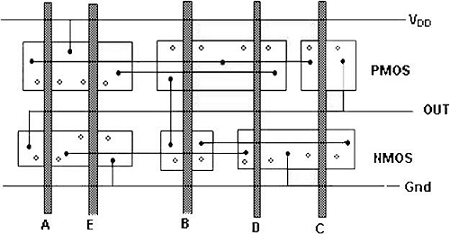
通过使用欧拉路径,我们可以获得最佳布局。欧拉路径定义为一条不间断的路径,它恰好遍历图的每条边(分支)一次。在下拉树图和上拉树图中找到具有相同输入顺序的欧拉路径。
VLSI设计 - 顺序MOS逻辑电路
逻辑电路分为两类:(a)组合电路和(b)时序电路。
在组合电路中,输出仅取决于最新输入的条件。
在时序电路中,输出不仅取决于最新的输入,还取决于早期输入的条件。时序电路包含存储单元。
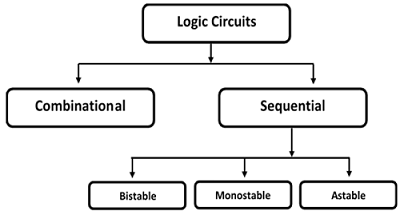
时序电路有三种类型:
双稳态 - 双稳态电路有两个稳定的工作点,并将处于任一状态。例如:存储单元、锁存器、触发器和寄存器。
单稳态 - 单稳态电路只有一个稳定的工作点,即使它们暂时被扰动到相反的状态,它们也会及时返回到它们稳定的工作点。例如:定时器、脉冲发生器。
无稳态 - 电路没有稳定的工作点,并在多个状态之间振荡。例如:环形振荡器。
CMOS逻辑电路
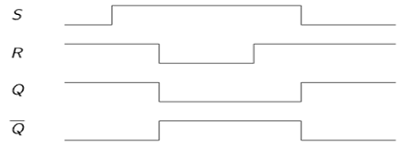
基于NOR门的SR锁存器
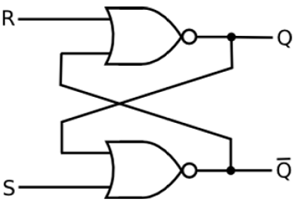
如果置位输入 (S) 等于逻辑 "1" 并且复位输入等于逻辑 "0",则输出 Q 将被强制为逻辑 "1"。而 $\overline{Q}$ 被强制为逻辑 "0"。这意味着 SR 锁存器将被置位,而不管其先前状态如何。
类似地,如果 S 等于 "0" 并且 R 等于 "1",则输出 Q 将被强制为 "0",而 $\overline{Q}$ 被强制为 "1"。这意味着锁存器被复位,而不管其先前保持的状态如何。最后,如果输入 S 和 R 都等于逻辑 "1",则两个输出都将被强制为逻辑 "0",这与 Q 和 $\overline{Q}$ 的互补性相冲突。
因此,此输入组合在正常操作期间不允许使用。基于NOR的SR锁存器的真值表在表中给出。
| S | R | Q | $\overline{Q}$ | 操作 |
|---|---|---|---|---|
| 0 | 0 | Q | $\overline{Q}$ | 保持 |
| 1 | 0 | 1 | 0 | 置位 |
| 0 | 1 | 0 | 1 | 复位 |
| 1 | 1 | 0 | 0 | 不允许 |
基于NOR门的CMOS SR锁存器如下图所示。
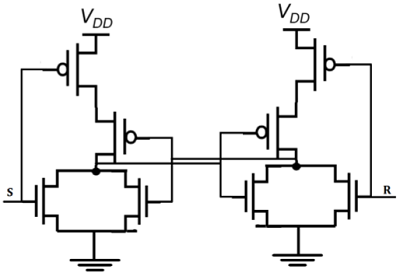
如果 S 等于 VOH 并且 R 等于 VOL,则并联连接的晶体管 M1 和 M2 都将导通。节点 $\overline{Q}$ 上的电压将假设 VOL = 0 的低逻辑电平。
同时,M3 和 M4 关闭,导致节点 Q 处的逻辑高电压 VOH。如果 R 等于 VOH 并且 S 等于 VOL,则 M1 和 M2 关闭,M3 和 M4 导通。
基于NAND门的SR锁存器
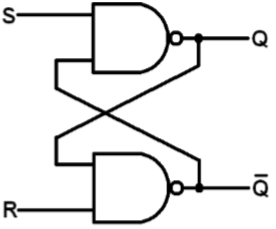
基于NAND的SR锁存器的框图和门级原理图如图所示。S和R输入端的小圆圈表示电路响应于低电平有效输入信号。基于NAND的SR锁存器的真值表在表中给出。
| S | R | Q | Q′ | |
| 0 | 0 | NC | NC | 无变化。锁存器保持当前状态。 |
| 1 | 0 | 1 | 0 | 锁存器置位。 |
| 0 | 1 | 0 | 1 | 锁存器复位。 |
| 1 | 1 | 0 | 0 | 无效条件。 |
如果 S 变为 0(当 R = 1 时),Q 变为高电平,将 $\overline{Q}$ 拉低,锁存器进入置位状态。
S = 0 则 Q = 1(如果 R = 1)
如果 R 变为 0(当 S = 1 时),Q 变为高电平,将 $\overline{Q}$ 拉低,锁存器被复位。
R = 0 则 Q = 1(如果 S = 1)
保持状态需要 S 和 R 都为高电平。如果 S = R = 0,则输出不允许,因为它会导致不确定的状态。基于NAND门的CMOS SR锁存器如图所示。
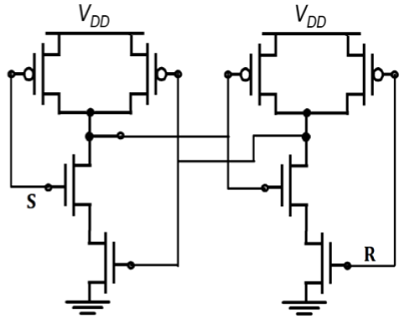
基于NAND门的耗尽负载nMOS SR锁存器如图所示。其操作类似于CMOS NAND SR锁存器。CMOS电路实现具有低静态功耗和高噪声容限。
CMOS逻辑电路
带时钟的SR锁存器
该图显示了一个添加了时钟的基于NOR的SR锁存器。只有当 CLK 为高电平时,锁存器才响应输入 S 和 R。
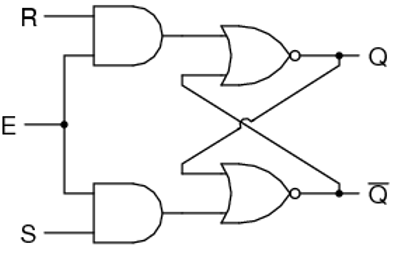
当 CLK 为低电平时,锁存器保持其当前状态。观察 Q 状态变化:
- 当 S 在正 CLK 期间变为高电平时。
- 在 CLK 低时间内 S & R 变化后的前沿 CLK 边沿。
- S 在 CLK 为高电平时出现正毛刺。
- 当 R 在正 CLK 期间变为高电平时。
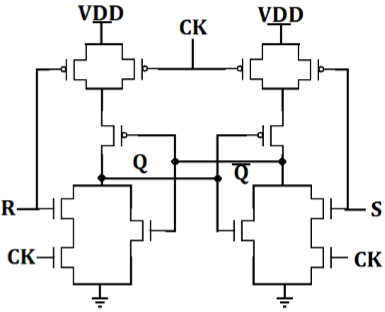
带时钟的基于NOR的SR锁存器的CMOS AOI实现如图所示。请注意,只需要12个晶体管。
当 CLK 为低电平时,N 树 N 中的两个串联端子断开,P 树中的两个并联晶体管导通,从而保持存储单元中的状态。
当时钟为高电平时,电路简单地变为基于NOR的CMOS锁存器,它将响应输入 S 和 R。
基于NAND门的带时钟的SR锁存器
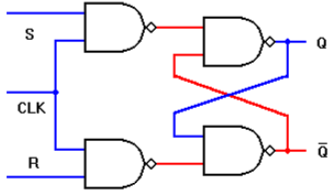
电路采用四个NAND门实现。如果使用CMOS实现此电路,则需要16个晶体管。
- 只有当 CLK 为高电平时,锁存器才响应 S 或 R。
- 如果两个输入信号和 CLK 信号都为高电平有效:即,当 CLK = "1" S = "1" 且 R = "0" 时,锁存器输出 Q 将被置位。
- 类似地,当 CLK = "1",S = "0" 时,锁存器将被复位,并且
当 CLK 为低电平时,锁存器保持其当前状态。
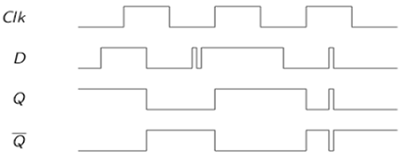
带时钟的JK锁存器
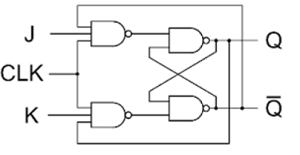
上图显示了一个基于NAND门的带时钟的JK锁存器。SR锁存器的缺点是,当S和R都为高电平时,其输出状态变得不确定。JK锁存器通过使用从输出到输入的反馈来消除这个问题,这样真值表的所有输入状态都是允许的。如果 J = K = 0,锁存器将保持其当前状态。
如果 J = 1 且 K = 0,则锁存器将在下一个正跳变时钟沿置位,即 Q = 1,$\overline{Q}$ = 0。
如果 J = 0 且 K = 1,则锁存器将在下一个正跳变时钟沿复位,即 Q = 1 且 $\overline{Q}$ = 0。
如果 J = K = 1,则锁存器将在下一个正跳变时钟沿翻转。
带时钟的JK锁存器的操作总结在表中给出的真值表中。
J |
K |
Q |
$\overline{Q}$ | S |
R |
Q |
$\overline{Q}$ | 操作 |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 保持 |
| 1 | 0 | 1 | 1 | 1 | 0 | |||
| 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 复位 |
| 1 | 0 | 1 | 0 | 0 | 1 | |||
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 置位 |
| 1 | 0 | 1 | 1 | 1 | 0 | |||
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 翻转 |
| 1 | 0 | 1 | 0 | 0 | 1 |
CMOS D锁存器实现
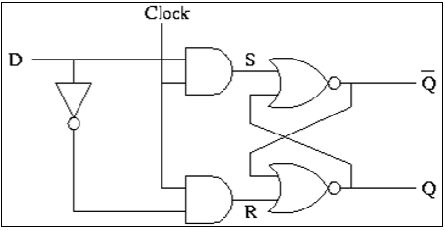
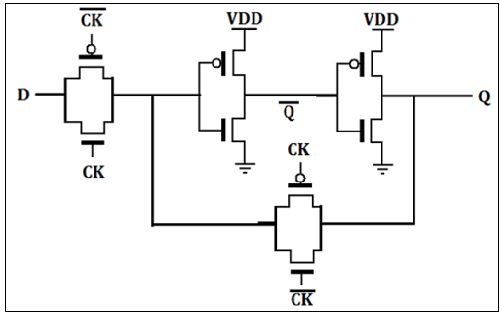
D锁存器通常使用传输门(TG)开关实现,如图所示。输入TG由CLK激活,而锁存反馈环路TG由CLK激活。当CLK为高电平时接受输入D。当CLK变为低电平时,输入电路开路,锁存器设置为先前的D数据。
VLSI设计 - VHDL简介
VHDL代表超高速集成电路硬件描述语言。它是一种编程语言,用于通过数据流、行为和结构建模风格来建模数字系统。该语言于1981年首次为国防部(DoD)在VHSIC项目下引入。
描述设计
在VHDL中,实体用于描述硬件模块。实体可以使用以下方式描述:
- 实体声明
- 结构体
- 配置
- 包声明
- 包主体
让我们看看这些是什么?
实体声明
它定义了硬件模块的名称、输入输出信号和模式。
语法 −
entity entity_name is Port declaration; end entity_name;
实体声明应以“entity”开头,以“end”结尾。方向将是输入、输出或双向。
| 输入 (In) | 端口可读 |
| 输出 (Out) | 端口可写 |
| 双向 (Inout) | 端口可读写 |
| 缓冲 (Buffer) | 端口可读写,只能有一个源。 |
结构体 −
结构体可以使用结构化、数据流、行为或混合样式来描述。
语法 −
architecture architecture_name of entity_name architecture_declarative_part; begin Statements; end architecture_name;
在这里,我们应该指定我们正在为其编写结构体主体的实体名称。结构体语句应该位于“begin”和“end”关键字内。结构体声明部分可能包含变量、常量或组件声明。
数据流建模
在这种建模风格中,数据流经实体的流程是用并发(并行)信号表达的。VHDL中的并发语句是WHEN和GENERATE。
除此之外,仅使用运算符(AND、NOT、+、*、sll等)的赋值也可以用于构建代码。
最后,这种代码中还可以使用一种特殊的赋值,称为BLOCK。
在并发代码中,可以使用以下内容:
- 运算符
- WHEN语句(WHEN/ELSE或WITH/SELECT/WHEN);
- GENERATE语句;
- BLOCK语句
行为建模
在这种建模风格中,实体的行为是一组语句,按指定的顺序依次执行。只有放在PROCESS、FUNCTION或PROCEDURE内的语句才是顺序执行的。
PROCESSES、FUNCTIONS和PROCEDURES是唯一顺序执行的代码段。
但是,作为一个整体,这些块中的任何一个仍然与放在其外部的任何其他语句并发。
行为代码的一个重要方面是它不限于顺序逻辑。事实上,我们可以用它来构建顺序电路和组合电路。
行为语句是IF、WAIT、CASE和LOOP。变量也受到限制,它们应该只在顺序代码中使用。变量永远不能是全局的,因此它的值不能直接传递出去。
结构化建模
在这种建模中,实体被描述为一组互连的组件。组件例化语句是一个并发语句。因此,这些语句的顺序并不重要。结构化建模风格只描述组件(视为黑盒)的互连,而不暗示组件本身或它们共同代表的实体的任何行为。
在结构化建模中,结构体主体由两部分组成:声明部分(在关键字begin之前)和语句部分(在关键字begin之后)。
逻辑运算 – 与门
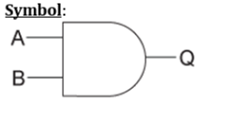
| X | Y | Z |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity and1 is port(x,y:in bit ; z:out bit); end and1; architecture virat of and1 is begin z<=x and y; end virat;
波形
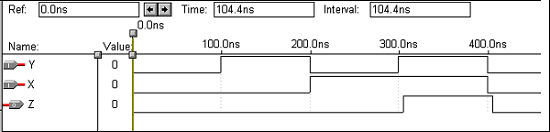
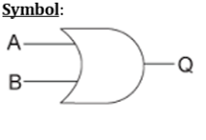
逻辑运算 – 或门
| X | Y | Z |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity or1 is port(x,y:in bit ; z:out bit); end or1; architecture virat of or1 is begin z<=x or y; end virat;
波形
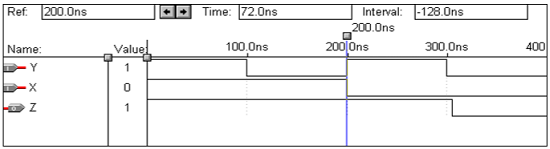
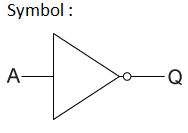
逻辑运算 – 非门
| X | Y |
|---|---|
| 0 | 1 |
| 1 | 0 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity not1 is port(x:in bit ; y:out bit); end not1; architecture virat of not1 is begin y<=not x; end virat;
波形
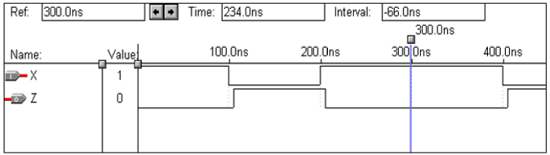
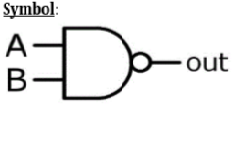
逻辑运算 – 与非门
| X | Y | Z |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity nand1 is port(a,b:in bit ; c:out bit); end nand1; architecture virat of nand1 is begin c<=a nand b; end virat;
波形
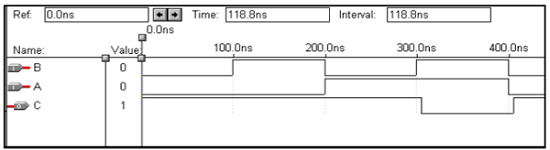
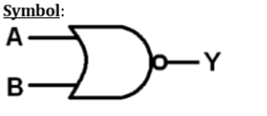
逻辑运算 – 或非门
| X | Y | Z |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity nor1 is port(a,b:in bit ; c:out bit); end nor1; architecture virat of nor1 is begin c<=a nor b; end virat;
波形
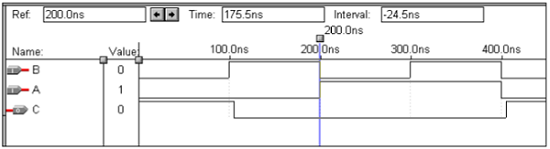
逻辑运算 – 异或门
| X | Y | Z |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity xor1 is port(a,b:in bit ; c:out bit); end xor1; architecture virat of xor1 is begin c<=a xor b; end virat;
波形
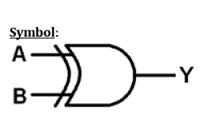
逻辑运算 – 同或门

| X | Y | Z |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity xnor1 is port(a,b:in bit ; c:out bit); end xnor1; architecture virat of xnor1 is begin c<=not(a xor b); end virat;
波形
VHDL组合电路编程
本章解释组合电路的VHDL编程。
半加器的VHDL代码
VHDL Code: Library ieee; use ieee.std_logic_1164.all; entity half_adder is port(a,b:in bit; sum,carry:out bit); end half_adder; architecture data of half_adder is begin sum<= a xor b; carry <= a and b; end data;
波形
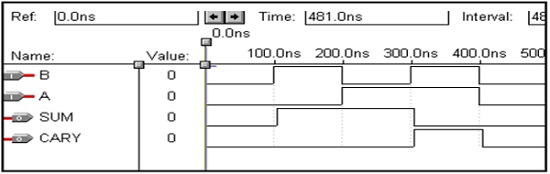
全加器的VHDL代码
Library ieee; use ieee.std_logic_1164.all; entity full_adder is port(a,b,c:in bit; sum,carry:out bit); end full_adder; architecture data of full_adder is begin sum<= a xor b xor c; carry <= ((a and b) or (b and c) or (a and c)); end data;
波形
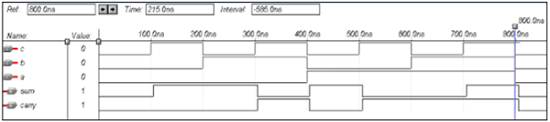
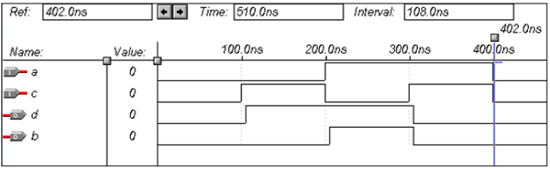
半减器的VHDL代码
Library ieee; use ieee.std_logic_1164.all; entity half_sub is port(a,c:in bit; d,b:out bit); end half_sub; architecture data of half_sub is begin d<= a xor c; b<= (a and (not c)); end data;
波形
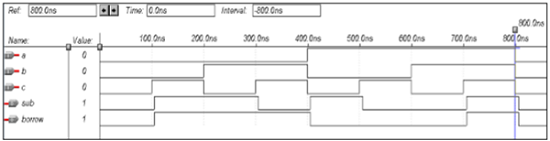
全减器的VHDL代码
Library ieee; use ieee.std_logic_1164.all; entity full_sub is port(a,b,c:in bit; sub,borrow:out bit); end full_sub; architecture data of full_sub is begin sub<= a xor b xor c; borrow <= ((b xor c) and (not a)) or (b and c); end data;
波形
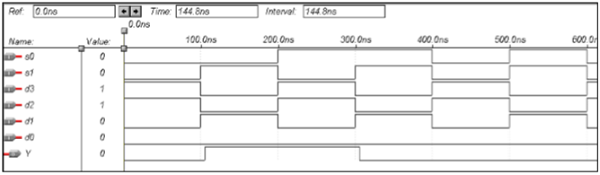
多路复用器的VHDL代码
Library ieee;
use ieee.std_logic_1164.all;
entity mux is
port(S1,S0,D0,D1,D2,D3:in bit; Y:out bit);
end mux;
architecture data of mux is
begin
Y<= (not S0 and not S1 and D0) or
(S0 and not S1 and D1) or
(not S0 and S1 and D2) or
(S0 and S1 and D3);
end data;
波形
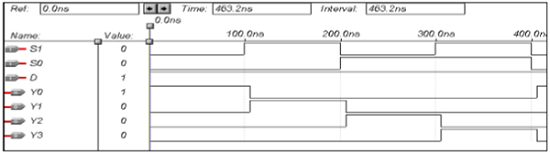
多路分解器的VHDL代码
Library ieee; use ieee.std_logic_1164.all; entity demux is port(S1,S0,D:in bit; Y0,Y1,Y2,Y3:out bit); end demux; architecture data of demux is begin Y0<= ((Not S0) and (Not S1) and D); Y1<= ((Not S0) and S1 and D); Y2<= (S0 and (Not S1) and D); Y3<= (S0 and S1 and D); end data;
波形
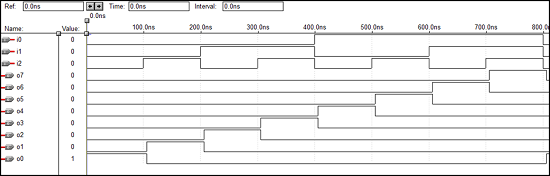
8 x 3编码器的VHDL代码
library ieee; use ieee.std_logic_1164.all; entity enc is port(i0,i1,i2,i3,i4,i5,i6,i7:in bit; o0,o1,o2: out bit); end enc; architecture vcgandhi of enc is begin o0<=i4 or i5 or i6 or i7; o1<=i2 or i3 or i6 or i7; o2<=i1 or i3 or i5 or i7; end vcgandhi;
波形
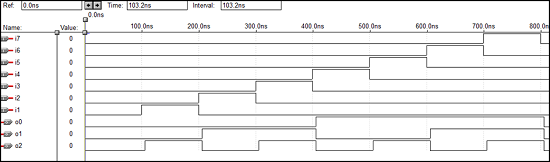
3 x 8译码器的VHDL代码
library ieee; use ieee.std_logic_1164.all; entity dec is port(i0,i1,i2:in bit; o0,o1,o2,o3,o4,o5,o6,o7: out bit); end dec; architecture vcgandhi of dec is begin o0<=(not i0) and (not i1) and (not i2); o1<=(not i0) and (not i1) and i2; o2<=(not i0) and i1 and (not i2); o3<=(not i0) and i1 and i2; o4<=i0 and (not i1) and (not i2); o5<=i0 and (not i1) and i2; o6<=i0 and i1 and (not i2); o7<=i0 and i1 and i2; end vcgandhi;
波形
4位并行加法的VHDL代码
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity pa is
port(a : in STD_LOGIC_VECTOR(3 downto 0);
b : in STD_LOGIC_VECTOR(3 downto 0);
ca : out STD_LOGIC;
sum : out STD_LOGIC_VECTOR(3 downto 0)
);
end pa;
architecture vcgandhi of pa is
Component fa is
port (a : in STD_LOGIC;
b : in STD_LOGIC;
c : in STD_LOGIC;
sum : out STD_LOGIC;
ca : out STD_LOGIC
);
end component;
signal s : std_logic_vector (2 downto 0);
signal temp: std_logic;
begin
temp<='0';
u0 : fa port map (a(0),b(0),temp,sum(0),s(0));
u1 : fa port map (a(1),b(1),s(0),sum(1),s(1));
u2 : fa port map (a(2),b(2),s(1),sum(2),s(2));
ue : fa port map (a(3),b(3),s(2),sum(3),ca);
end vcgandhi;
波形

4位奇偶校验器的VHDL代码
library ieee;
use ieee.std_logic_1164.all;
entity parity_checker is
port (a0,a1,a2,a3 : in std_logic;
p : out std_logic);
end parity_checker;
architecture vcgandhi of parity_checker is
begin
p <= (((a0 xor a1) xor a2) xor a3);
end vcgandhi;
波形
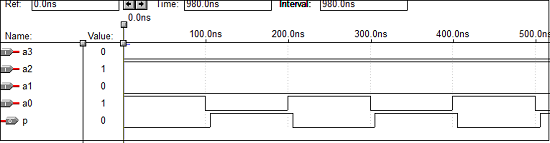
4位奇偶校验生成器的VHDL代码
library ieee;
use ieee.std_logic_1164.all;
entity paritygen is
port (a0, a1, a2, a3: in std_logic; p_odd, p_even: out std_logic);
end paritygen;
architecture vcgandhi of paritygen is
begin
process (a0, a1, a2, a3)
if (a0 ='0' and a1 ='0' and a2 ='0' and a3 =’0’)
then odd_out <= "0";
even_out <= "0";
else
p_odd <= (((a0 xor a1) xor a2) xor a3);
p_even <= not(((a0 xor a1) xor a2) xor a3);
end vcgandhi
波形
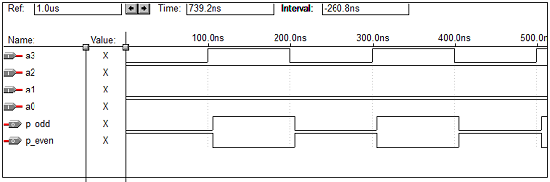
顺序电路的VHDL编程
本章解释如何进行顺序电路的VHDL编程。
SR锁存器的VHDL代码
library ieee; use ieee.std_logic_1164.all; entity srl is port(r,s:in bit; q,qbar:buffer bit); end srl; architecture virat of srl is signal s1,r1:bit; begin q<= s nand qbar; qbar<= r nand q; end virat;
波形
D锁存器的VHDL代码
library ieee; use ieee.std_logic_1164.all; entity Dl is port(d:in bit; q,qbar:buffer bit); end Dl; architecture virat of Dl is signal s1,r1:bit; begin q<= d nand qbar; qbar<= d nand q; end virat;
波形
SR触发器的VHDL代码
library ieee; use ieee.std_logic_1164.all; entity srflip is port(r,s,clk:in bit; q,qbar:buffer bit); end srflip; architecture virat of srflip is signal s1,r1:bit; begin s1<=s nand clk; r1<=r nand clk; q<= s1 nand qbar; qbar<= r1 nand q; end virat;
波形

JK触发器的VHDL代码
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity jk is
port(
j : in STD_LOGIC;
k : in STD_LOGIC;
clk : in STD_LOGIC;
reset : in STD_LOGIC;
q : out STD_LOGIC;
qb : out STD_LOGIC
);
end jk;
architecture virat of jk is
begin
jkff : process (j,k,clk,reset) is
variable m : std_logic := '0';
begin
if (reset = '1') then
m : = '0';
elsif (rising_edge (clk)) then
if (j/ = k) then
m : = j;
elsif (j = '1' and k = '1') then
m : = not m;
end if;
end if;
q <= m;
qb <= not m;
end process jkff;
end virat;
波形
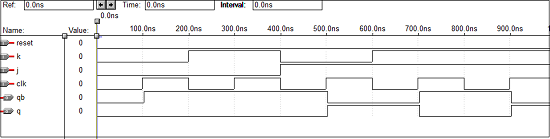
D触发器的VHDL代码
Library ieee; use ieee.std_logic_1164.all; entity dflip is port(d,clk:in bit; q,qbar:buffer bit); end dflip; architecture virat of dflip is signal d1,d2:bit; begin d1<=d nand clk; d2<=(not d) nand clk; q<= d1 nand qbar; qbar<= d2 nand q; end virat;
波形
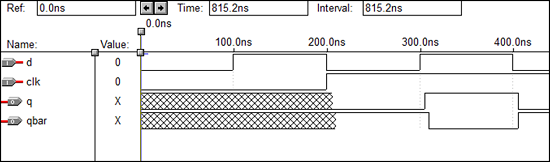
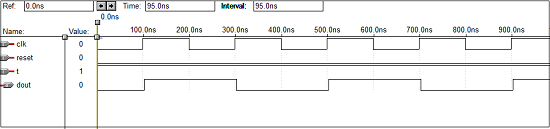
T触发器的VHDL代码
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity Toggle_flip_flop is
port(
t : in STD_LOGIC;
clk : in STD_LOGIC;
reset : in STD_LOGIC;
dout : out STD_LOGIC
);
end Toggle_flip_flop;
architecture virat of Toggle_flip_flop is
begin
tff : process (t,clk,reset) is
variable m : std_logic : = '0';
begin
if (reset = '1') then
m : = '0';
elsif (rising_edge (clk)) then
if (t = '1') then
m : = not m;
end if;
end if;
dout < = m;
end process tff;
end virat;
波形
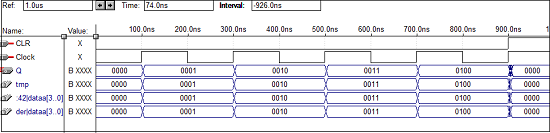
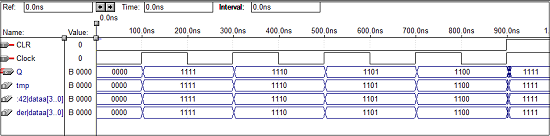
4位向上计数器的VHDL代码
library IEEE;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
entity counter is
port(Clock, CLR : in std_logic;
Q : out std_logic_vector(3 downto 0)
);
end counter;
architecture virat of counter is
signal tmp: std_logic_vector(3 downto 0);
begin
process (Clock, CLR)
begin
if (CLR = '1') then
tmp < = "0000";
elsif (Clock'event and Clock = '1') then
mp <= tmp + 1;
end if;
end process;
Q <= tmp;
end virat;
波形
4位向下计数器的VHDL代码
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
entity dcounter is
port(Clock, CLR : in std_logic;
Q : out std_logic_vector(3 downto 0));
end dcounter;
architecture virat of dcounter is
signal tmp: std_logic_vector(3 downto 0);
begin
process (Clock, CLR)
begin
if (CLR = '1') then
tmp <= "1111";
elsif (Clock'event and Clock = '1') then
tmp <= tmp - 1;
end if;
end process;
Q <= tmp;
end virat;
波形
VLSI设计 - Verilog介绍
Verilog是一种硬件描述语言(HDL)。它是一种用于描述数字系统(如网络交换机、微处理器、存储器或触发器)的语言。这意味着,使用HDL,我们可以描述任何级别的数字硬件。用HDL描述的设计与技术无关,非常易于设计和调试,通常比原理图更有用,特别是对于大型电路。
Verilog支持多个抽象级别的设计。主要三个是:
- 行为级
- 寄存器传输级
- 门级
行为级
此级别使用并发算法(行为)来描述系统。每个算法都是顺序的,这意味着它由一组依次执行的指令组成。函数、任务和块是主要元素。不考虑设计的结构实现。
寄存器传输级
使用寄存器传输级进行设计,使用操作和寄存器之间的数据传输来指定电路的特性。现代RTL代码的定义是“任何可综合的代码都称为RTL代码”。
门级
在逻辑级别内,系统的特性由逻辑链接及其定时属性来描述。所有信号都是离散信号。它们只能具有确定的逻辑值(`0`、`1`、`X`、`Z`)。可用的操作是预定义的逻辑原语(基本门)。门级建模可能不是逻辑设计的正确方法。门级代码是使用诸如综合工具之类的工具生成的,其网表用于门级仿真和后端。
词法标记
Verilog语言源文本文件是词法标记流。标记由一个或多个字符组成,每个字符都恰好在一个标记中。
Verilog HDL使用的基本词法标记类似于C编程语言中的标记。Verilog区分大小写。所有关键字都小写。
空白
空白可以包含空格、制表符、换行符和换页符。除了用于分隔标记外,这些字符都被忽略。
空白字符是空格、制表符、回车符、换行符和换页符。
注释
有两种形式可以表示注释
- 1) 单行注释以标记 // 开头,以回车符结尾。
例://这是单行语法
- 2) 多行注释以标记 /* 开头,以标记 */ 结尾。
例:/* 这是多行语法 */
数字
您可以使用二进制、八进制、十进制或十六进制格式指定数字。负数用二进制补码表示。Verilog允许整数、实数以及带符号和无符号数。
语法如下:<size> <radix> <value>
大小或无大小的数字可以在 <Size> 中定义,<radix> 定义它是二进制、八进制、十六进制还是十进制。
标识符
标识符是用于定义对象的名称,例如函数、模块或寄存器。标识符应以字母字符或下划线字符开头。例:A_Z、a_z、_
标识符是字母、数字、下划线和 $ 字符的组合。它们最多可以有 1024 个字符。
运算符
运算符是用于设置条件或操作变量的特殊字符。有时会使用一个、两个或三个字符来对变量执行操作。
例:>、+、~、&! =。
Verilog关键字
在Verilog中具有特殊含义的词称为Verilog关键字。例如,assign、case、while、wire、reg、and、or、nand和module。它们不应用作标识符。Verilog关键字还包括编译器指令以及系统任务和函数。
门级建模
Verilog具有内置的原语,如逻辑门、传输门和开关。这些很少用于设计工作,但它们在综合后用于ASIC/FPGA单元的建模。
门级建模具有两个属性:
驱动强度 − 输出门的强度由驱动强度定义。如果与源直接连接,则输出最强。如果连接是通过导电晶体管,则强度降低;如果通过上拉/下拉电阻连接,则强度最低。通常不指定驱动强度,在这种情况下,强度默认为strong1和strong0。
延迟 − 如果未指定延迟,则门没有传播延迟;如果指定两个延迟,则第一个表示上升延迟,第二个表示下降延迟;如果只指定一个延迟,则上升和下降都相等。在综合中可以忽略延迟。
门原语
Verilog中使用具有一个输出和多个输入的基本逻辑门。GATE使用一个关键字 - and、nand、or、nor、xor、xnor 在Verilog中用于N个输入和1个输出。
Example: Module gate() Wire ot0; Wire ot1; Wire ot2; Reg in0,in1,in2,in3; Not U1(ot0,in0); Xor U2(ot1,in1,in2,in3); And U3(ot2, in2,in3,in0)
传输门原语
传输门原语包括缓冲器和反相器。它们具有单个输入和一个或多个输出。在下面显示的门例化语法中,GATE代表关键字buf或NOT门。
示例:Not、buf、bufif0、bufif1、notif0、notif1
Not – n输出反相器
Buf – n输出缓冲器
Bufifo – 三态缓冲器,低电平使能
Bufif1 – 三态缓冲器,高电平使能
Notifo – 三态反相器,低电平使能
Notif1 – 三态反相器,高电平使能
Example: Module gate() Wire out0; Wire out1; Reg in0,in1; Not U1(out0,in0); Buf U2(out0,in0);
数据类型
值集合
Verilog 主要由四个基本值构成。Verilog 中使用的所有数据类型都存储这些值:
0(逻辑零,或假条件)
1(逻辑一,或真条件)
x(未知逻辑值)
z(高阻态)
x 和 z 的使用在综合中非常有限。
线网 (Wire)
线网用于表示电路中的物理线,用于连接门或模块。线网的值只能读取,不能在函数或块中赋值。线网不能存储值,始终由连续赋值语句或将线网连接到门/模块的输出驱动。其他特定类型的线网包括:
Wand(线与) – Wand 的值取决于连接到它的所有器件驱动器的逻辑与。
Wor(线或) – Wor 的值取决于连接到它的所有器件驱动器的逻辑或。
Tri(三态) – 连接到 tri 的所有驱动器都必须为 z,只有一个例外(决定 tri 的值)。
Example: Wire [msb:lsb] wire_variable_list; Wirec // simple wire Wand d; Assign d = a; // value of d is the logical AND of Assign d = b; // a and b Wire [9:0] A; // a cable (vector) of 10 wires. Wand [msb:lsb] wand_variable_list; Wor [msb:lsb] wor_variable_list; Tri [msb:lsb] tri_variable_list;
寄存器 (Register)
reg(寄存器)是一个数据对象,它保存从一个过程赋值到下一个过程赋值的值,仅用于不同的函数和过程块。reg 是一个简单的 Verilog 变量类型寄存器,不能表示物理寄存器。在多位寄存器中,数据以无符号数的形式存储,不使用符号扩展。
示例:
reg c; // 单个 1 位寄存器变量
reg [5:0] gem; // 一个 6 位向量;
reg [6:0] d, e; // 两个 7 位变量
输入 (Input)、输出 (Output)、双向口 (Inout)
这些关键字用于声明任务或模块的输入、输出和双向端口。这里的输入和双向端口是线网类型,输出端口配置为线网、寄存器、Wand、Wor 或 Tri 类型。默认类型始终为线网类型。
示例
Module sample(a, c, b, d); Input c; // An input where wire is used. Output a, b; // Two outputs where wire is used. Output [2:0] d; /* A three-bit output. One must declare type in a separate statement. */ reg [1:0] a; // The above ‘a’ port is for declaration in reg.
整型 (Integer)
整型用于通用变量。主要用于循环索引、常量和参数。它们是“reg”类型的数据类型。它们将数据存储为有符号数,而显式声明的 reg 类型则将其存储为无符号数据。如果在编译时未定义整型,则默认大小为 32 位。
如果整型包含常量,则综合器会在编译时将其调整为所需的最小宽度。
示例
Integer c; // single 32-bit integer Assign a = 63; // 63 defaults to a 7-bit variable.
Supply0,Supply1
Supply0 定义连接到逻辑 0(地)的线网,Supply1 定义连接到逻辑 1(电源)的线网。
示例
supply0 logic_0_wires; supply0 gnd1; // equivalent to a wire assigned as 0 supply1 logic_1_wires; supply1 c, s;
时间 (Time)
Time 是一个 64 位的量,可以与 $time 系统任务一起使用以保存仿真时间。Time 不支持综合,因此仅用于仿真。
示例
time time_variable_list; time c; c = $time; //c = current simulation time
参数 (Parameter)
参数定义了一个常量,可以在使用模块时设置,允许在实例化过程中自定义模块。
Example
Parameter add = 3’b010, sub = 2’b11;
Parameter n = 3;
Parameter [2:0] param2 = 3’b110;
reg [n-1:0] jam; /* A 3-bit register with length of n or above. */
always @(z)
y = {{(add - sub){z}};
if (z)
begin
state = param2[1];
else
state = param2[2];
end
运算符
算术运算符
这些运算符执行算术运算。+ 和 - 可用作一元 (x) 或二元 (z-y) 运算符。
算术运算中包含的运算符有:
+(加法),-(减法),*(乘法),/(除法),%(模)
示例:
parameter v = 5; reg[3:0] b, d, h, i, count; h = b + d; i = d - v; cnt = (cnt +1)%16; //Can count 0 thru 15.
关系运算符
这些运算符比较两个操作数,并将结果返回为一位,1 或 0。
线网和寄存器变量为正。因此,(-3'd001) == 3'd111 和 (-3b001) > 3b110。
关系运算中包含的运算符有:
- ==(等于)
- !=(不等于)
- >(大于)
- >=(大于或等于)
- <(小于)
- <=(小于或等于)
示例
if (z = = y) c = 1; else c = 0; // Compare in 2’s compliment; d>b reg [3:0] d,b; if (d[3]= = b[3]) d[2:0] > b[2:0]; else b[3]; Equivalent Statement e = (z == y);
位运算符
位运算符对两个操作数进行逐位比较。
位运算中包含的运算符有:
- &(按位与)
- |(按位或)
- ~(按位非)
- ^(按位异或)
- ~^ 或 ^~(按位异或非)
示例
module and2 (d, b, c); input [1:0] d, b; output [1:0] c; assign c = d & b; end module
逻辑运算符
逻辑运算符是位运算符,仅用于单比特操作数。它们返回一位值,0 或 1。它们可以作用于整数或位组、表达式,并将所有非零值视为 1。逻辑运算符通常用于条件语句,因为它们与表达式一起使用。
逻辑运算中包含的运算符有:
- !(逻辑非)
- &&(逻辑与)
- ||(逻辑或)
示例
wire[7:0] a, b, c; // a, b and c are multibit variables. reg x; if ((a == b) && (c)) x = 1; //x = 1 if a equals b, and c is nonzero. else x = !a; // x =0 if a is anything but zero.
归约运算符
归约运算符是位运算符的一元形式,作用于操作数向量的所有位。它们也返回一位值。
归约运算中包含的运算符有:
- &(归约与)
- |(归约或)
- ~&(归约与非)
- ~|(归约或非)
- ^(归约异或)
- ~^ 或 ^~(归约异或非)
示例
Module chk_zero (x, z); Input [2:0] x; Output z; Assign z = & x; // Reduction AND End module
移位运算符
移位运算符根据语法中第二个操作数指定的位数来移动第一个操作数。对于左移和右移,空位都填充零(不使用符号扩展)。
移位运算中包含的运算符有:
- <<(左移)
- >>(右移)
示例
Assign z = c << 3; /* z = c shifted left 3 bits;
空位填充 0
连接运算符
连接运算符组合两个或多个操作数以形成更大的向量。
连接运算中包含的运算符有:{ }(连接)
示例
wire [1:0] a, h; wire [2:0] x; wire [3;0] y, Z;
assign x = {1’b0, a}; // x[2] = 0, x[1] = a[1], x[0] = a[0]
assign b = {a, h}; /* b[3] = a[1], b[2] = a[0], b[1] = h[1],
b[0] = h[0] */
assign {cout, b} = x + Z; // Concatenation of a result
复制运算符
复制运算符创建项目的多个副本。
复制运算中使用的运算符有:{n{item}}(项目的 n 倍复制)
示例
Wire [1:0] a, f; wire [4:0] x;
Assign x = {2{1’f0}, a}; // Equivalent to x = {0,0,a }
Assign y = {2{a}, 3{f}}; //Equivalent to y = {a,a,f,f}
For synthesis, Synopsis did not like a zero replication.
For example:-
Parameter l = 5, k = 5;
Assign x = {(l-k){a}}
条件运算符
条件运算符综合成多路复用器。它与 C/C++ 中使用的一样,根据条件计算两个表达式中的一个。
条件运算中使用的运算符有:
(条件) ? (条件为真时的结果) :
(条件为假时的结果)
示例
Assign x = (g) ? a : b; Assign x = (inc = = 2) ? x+1 : x-1; /* if (inc), x = x+1, else x = x-1 */
操作数
字面量
字面量是在 Verilog 表达式中使用的常量值操作数。两个常用的 Verilog 字面量是:
字符串 – 字符串字面量操作数是由双引号 (" ") 括起来的字符的一维数组。
数值 – 常数操作数以二进制、八进制、十进制或十六进制表示。
示例
n – 表示位数的整数
F – 四种可能的基格式之一:
b 表示二进制,o 表示八进制,d 表示十进制,h 表示十六进制。
“time is” // string literal 267 // 32-bit decimal number 2’b01 // 2-bit binary 20’hB36F // 20-bit hexadecimal number ‘062 // 32-bit octal number
线网、寄存器和参数
线网、寄存器和参数是在 Verilog 表达式中用作操作数的数据类型。
位选择“x[2]”和部分选择“x[4:2]”
位选择和部分选择分别用于使用方括号“[ ]”从线网、寄存器或参数向量中选择一位和多位。位选择和部分选择也以与它们的主要数据对象相同的方式用作表达式中的操作数。
示例
reg [7:0] x, y; reg [3:0] z; reg a; a = x[7] & y[7]; // bit-selects z = x[7:4] + y[3:0]; // part-selects
函数调用
在函数调用中,函数的返回值直接在表达式中使用,无需先将其赋值给寄存器或线网。只需将函数调用作为一种操作数类型即可。需要注意函数调用返回值的位宽。
Example Assign x = y & z & chk_yz(z, y); // chk_yz is a function . . ./* Definition of the function */ Function chk_yz; // function definition Input z,y; chk_yz = y^z; End function
模块
模块声明
在 Verilog 中,模块是主要的設計實體。它指示名稱和端口列表(參數)。接下來幾行指定每個端口的輸入/輸出類型(輸入、輸出或雙向)和寬度。默認端口寬度僅為 1 位。端口變量必須通過 wire、wand……、reg 聲明。默認端口變量為 wire。通常,輸入是 wire,因為它們的數據在模塊外部鎖存。如果輸出信號存儲在內部,則輸出為 reg 類型。
示例
module sub_add(add, in1, in2, out); input add; // defaults to wire input [7:0] in1, in2; wire in1, in2; output [7:0] out; reg out; ... statements ... End module
连续赋值
模块中的连续赋值用于将值赋给线网,这是在 always 或 initial 块之外使用的常规赋值。此赋值通过显式赋值语句完成,或在声明线网时为其赋值。连续赋值在仿真时连续执行。赋值语句的顺序不影响它。如果更改任何右侧输入信号,它将更改左侧输出信号。
示例
Wire [1:0] x = 2’y01; // assigned on declaration Assign y = c | d; // using assign statement Assign d = a & b; /* the order of the assign statements does not matter. */
模块实例化
模块声明是创建实际对象的模板。模块在其他模块内实例化,每个实例化都从该模板创建一个对象。例外是顶层模块,它是它自己的实例化。模块的端口必须与模板中定义的端口匹配。它指定:
按名称,使用点“.模板端口名(连接到端口的线网名称)”。或者
按位置,将端口放在模板和实例的端口列表中的相同位置。
示例
MODULE DEFINITION Module and4 (x, y, z); Input [3:0] x, y; Output [3:0] z; Assign z = x | y; End module
Verilog中的行为建模和时序
Verilog 中的行为模型包含过程语句,这些语句控制仿真并操作数据类型的变量。所有这些语句都包含在过程中。每个过程都与一个活动流相关联。
在行为模型的仿真过程中,由“always”和“initial”语句定义的所有流程都从仿真时间“零”开始。initial 语句执行一次,always 语句重复执行。在这个模型中,寄存器变量 a 和 b 分别在仿真时间“零”初始化为二进制 1 和 0。然后 initial 语句完成,并且在该仿真运行期间不再执行。此 initial 语句包含一个 begin-end 块(也称为顺序块)语句。在此 begin-end 类型块中,a 首先初始化,然后是 b。
行为建模示例
module behave; reg [1:0]a,b; initial begin a = ’b1; b = ’b0; end always begin #50 a = ~a; end always begin #100 b = ~b; end End module
过程赋值
过程赋值用于更新 reg、integer、time 和 memory 变量。如下所述,过程赋值与连续赋值之间存在显着差异:
连续赋值驱动 net 变量,并在输入操作数的值发生变化时进行评估和更新。
过程赋值在围绕它们的程序流程结构的控制下更新寄存器变量的值。
过程赋值的右侧可以是任何计算结果为值的表达式。但是,右侧的部分选择必须具有常量索引。左侧指示从右侧接收赋值的变量。过程赋值的左侧可以采用以下形式之一:
寄存器、整数、实数或时间变量 – 对这些数据类型之一的名称引用的赋值。
寄存器、整数、实数或时间变量的位选择 – 对单个位的赋值,同时保持其他位不变。
寄存器、整数、实数或时间变量的部分选择 – 对两个或多个连续位的部分选择,同时保持其余位不变。对于部分选择形式,只有常量表达式是合法的。
存储器单元 – 存储器的一个字。请注意,在存储器单元引用上不允许使用位选择和部分选择。
上述任何形式的连接 – 可以指定上述四种形式的任何形式的连接,这有效地将右侧表达式的结果进行分区,并按顺序将分区部分分配给连接的各个部分。
赋值延迟(不适用于综合)
在延迟赋值中,语句执行和左侧赋值之前会经过 Δt 个时间单位。使用赋值内延迟,右侧立即计算,但在结果放入左侧赋值之前会延迟 Δt。如果另一个过程在 Δt 期间更改右侧信号,则不会影响输出。综合工具不支持延迟。
语法
过程赋值变量 = 表达式
延迟赋值#Δt 变量 = 表达式;
赋值内延迟变量 = #Δt 表达式;
示例
reg [6:0] sum; reg h, ziltch; sum[7] = b[7] ^ c[7]; // execute now. ziltch = #15 ckz&h; /* ckz&a evaluated now; ziltch changed after 15 time units. */ #10 hat = b&c; /* 10 units after ziltch changes, b&c is evaluated and hat changes. */
阻塞赋值
阻塞过程赋值语句必须在其顺序块中后续语句执行之前执行。阻塞过程赋值语句不会阻止其在并行块中后续语句的执行。
语法
阻塞过程赋值的语法如下:
<lvalue> = <timing_control> <expression>
其中,lvalue 是过程赋值语句中有效的 数据类型,= 是赋值运算符,timing control 是可选的赋值内延迟。timing control 延迟可以是延迟控制(例如,#6)或事件控制(例如,@(posedge clk))。表达式是模拟器赋值给左值的右侧值。阻塞过程赋值使用的 = 赋值运算符也用于过程连续赋值和连续赋值。
示例
rega = 0;
rega[3] = 1; // a bit-select
rega[3:5] = 7; // a part-select
mema[address] = 8’hff; // assignment to a memory element
{carry, acc} = rega + regb; // a concatenation
非阻塞(RTL)赋值
非阻塞过程赋值允许您安排赋值,而不会阻塞过程流程。您可以随时使用非阻塞过程语句,在同一时间步内进行多个寄存器赋值,而无需考虑顺序或相互依赖。
语法
非阻塞过程赋值的语法如下:
<lvalue> <= <timing_control> <expression>
其中,lvalue 是过程赋值语句中有效的 数据类型,<=是非阻塞赋值运算符,timing control 是可选的赋值内 timing control。timing control 延迟可以是延迟控制或事件控制(例如,@(posedge clk))。表达式是模拟器赋值给左值的右侧值。非阻塞赋值运算符与模拟器用于小于或等于关系运算符的运算符相同。当您在表达式中使用 <= 运算符时,模拟器将其解释为关系运算符;当您在非阻塞过程赋值结构中使用它时,模拟器将其解释为赋值运算符。
模拟器如何评估非阻塞过程赋值 当模拟器遇到非阻塞过程赋值时,模拟器将分两个步骤评估并执行非阻塞过程赋值:
模拟器评估右侧并安排将新值赋值的时间,该时间由过程 timing control 指定。模拟器评估右侧并安排将新值赋值的时间,该时间由过程 timing control 指定。
在给定延迟过期或发生适当事件的时间步长结束时,模拟器通过将值赋给左侧来执行赋值。
示例
module evaluates2(out); output out; reg a, b, c; initial begin a = 0; b = 1; c = 0; end always c = #5 ~c; always @(posedge c) begin a <= b; b <= a; end endmodule
条件语句
条件语句(或 if-else 语句)用于决定是否执行语句。
形式上,语法如下:
<statement> ::= if ( <expression> ) <statement_or_null> ||= if ( <expression> ) <statement_or_null> else <statement_or_null> <statement_or_null> ::= <statement> ||= ;
对
例如,以下两个语句表达相同的逻辑:
if (expression) if (expression != 0)
由于 if-else 的 else 部分是可选的,因此当从嵌套 if 序列中省略 else 时可能会产生混淆。这通过始终将 else 与缺少 else 的最近的先前 if 关联来解决。
示例
if (index > 0) if (rega > regb) result = rega; else // else applies to preceding if result = regb; If that association is not what you want, use a begin-end block statement to force the proper association if (index > 0) begin if (rega > regb) result = rega; end else result = regb;
if-else-if 结构
以下结构经常出现,值得单独简要讨论。
示例
if (<expression>) <statement> else if (<expression>) <statement> else if (<expression>) <statement> else <statement>
这个 if 序列(称为 if-else-if 结构)是编写多路决策的最通用方法。表达式按顺序求值;如果任何表达式为真,则执行与其关联的语句,这将终止整个链。每个语句要么是单个语句,要么是语句块。
if-else-if 结构的最后一个 else 部分处理“以上都不是”或默认情况,其中没有满足其他条件。有时没有默认情况的明确操作;在这种情况下,可以省略尾随 else,也可以将其用于错误检查以捕获不可能的条件。
case 语句
case 语句是一种特殊的多分支决策语句,它测试表达式是否与多个其他表达式之一匹配,并据此分支。case 语句用于描述例如微处理器指令的解码。case 语句具有以下语法:
示例
<statement> ::= case ( <expression> ) <case_item>+ endcase ||= casez ( <expression> ) <case_item>+ endcase ||= casex ( <expression> ) <case_item>+ endcase <case_item> ::= <expression> <,<expression>>* : <statement_or_null> ||= default : <statement_or_null> ||= default <statement_or_null>
case 表达式按其给出的确切顺序进行评估和比较。在线性搜索期间,如果 case 项目表达式之一与括号中的表达式匹配,则执行与该 case 项目关联的语句。如果所有比较都失败,并且给出了 default 项目,则执行 default 项目语句。如果未给出 default 语句,并且所有比较都失败,则不执行任何 case 项目语句。
除了语法之外,case 语句与多分支 if-else-if 结构在两个重要方面有所不同:
if-else-if 结构中的条件表达式比将一个表达式与其他几个表达式进行比较更通用,就像在 case 语句中一样。
当表达式中存在 x 和 z 值时,case 语句提供确定的结果。
循环语句
有四种类型的循环语句。它们提供了一种控制语句执行零次、一次或多次的方法。
forever 连续执行语句。
repeat 执行语句固定次数。
while 执行语句,直到表达式变为假。如果表达式一开始为假,则根本不执行语句。
for 通过以下三步过程控制其关联语句的执行:
执行通常用于初始化控制执行循环次数的变量的赋值
评估表达式——如果结果为零,则 for 循环退出,如果结果不为零,则 for 循环执行其关联语句,然后执行步骤 3
执行通常用于修改循环控制变量值的赋值,然后重复步骤 2
循环语句的语法规则如下:
示例
<statement> ::= forever <statement> ||=forever begin <statement>+ end <Statement> ::= repeat ( <expression> ) <statement> ||=repeat ( <expression> ) begin <statement>+ end <statement> ::= while ( <expression> ) <statement> ||=while ( <expression> ) begin <statement>+ end <statement> ::= for ( <assignment> ; <expression> ; <assignment> ) <statement> ||=for ( <assignment> ; <expression> ; <assignment> ) begin <statement>+ end
延迟控制
延迟控制
可以使用以下语法对过程语句的执行进行延迟控制:
<statement> ::= <delay_control> <statement_or_null> <delay_control> ::= # <NUMBER> ||= # <identifier> ||= # ( <mintypmax_expression> )
以下示例将赋值的执行延迟 10 个时间单位:
#10 rega = regb;
接下来的三个示例在数字符号 (#) 后提供表达式。赋值的执行将延迟表达式值指定模拟时间量。
事件控制
可以使用以下事件控制语法将过程语句的执行与网络或寄存器上的值变化或已声明事件的发生同步:
示例
<statement> ::= <event_control> <statement_or_null> <event_control> ::= @ <identifier> ||= @ ( <event_expression> ) <event_expression> ::= <expression> ||= posedge <SCALAR_EVENT_EXPRESSION> ||= negedge <SCALAR_EVENT_EXPRESSION> ||= <event_expression> <or <event_expression>>
*
网络和寄存器上的值变化可用作触发语句执行的事件。这称为检测隐式事件。Verilog 语法还允许您根据更改的方向检测更改——即朝向值 1 (posedge) 或朝向值 0 (negedge)。posedge 和 negedge 对未知表达式值的处理方式如下:
- 从 1 到未知以及从未知到 0 的转换会检测到 negedge
- 从 0 到未知以及从未知到 1 的转换会检测到 posedge
过程:always 和 initial 块
Verilog 中的所有过程都在以下四个块之一中指定。1) initial 块 2) always 块 3) 任务 4) 函数
initial 和 always 语句在模拟开始时启用。initial 块只执行一次,并且当语句完成时其活动结束。相反,always 块重复执行。其活动仅在模拟终止时结束。在一个模块中可以定义的 initial 和 always 块的数量没有限制。任务和函数是从其他过程中的一个或多个位置启用的过程。
initial 块
initial 语句的语法如下:
<initial_statement> ::= initial <statement>
以下示例说明了在模拟开始时使用 initial 语句初始化变量。
Initial Begin Areg = 0; // initialize a register For (index = 0; index < size; index = index + 1) Memory [index] = 0; //initialize a memory Word End
initial 块的另一个典型用法是指定一次执行以向被模拟电路的主要部分提供激励的波形描述。
Initial Begin Inputs = ’b000000; // initialize at time zero #10 inputs = ’b011001; // first pattern #10 inputs = ’b011011; // second pattern #10 inputs = ’b011000; // third pattern #10 inputs = ’b001000; // last pattern End
always 块
“always”语句在整个模拟运行过程中持续重复。always 语句的语法如下所示
<always_statement> ::= always <statement>
由于“always”语句的循环性质,它只有与某种形式的 timing control 结合使用时才有用。如果“always”语句不提供时间推进的方法,“always”语句会创建模拟死锁条件。例如,以下代码会创建一个无限的零延迟循环:
Always areg = ~areg;
为上述代码提供 timing control 可以创建一个可能有用的描述——如下例所示:
Always #half_period areg = ~areg;