- Behave 教程
- Behave - 首页
- Behave - 简介
- Behave - 安装
- Behave - 命令行
- Behave - 配置文件
- Behave - 特性测试设置
- Behave - Gherkin 关键字
- Behave - 特性文件
- Behave - 步骤实现
- Behave - 初步步骤
- Behave - 支持的语言
- Behave - 步骤参数
- Behave - 场景大纲
- Behave - 多行文本
- Behave - 设置表
- Behave - 步骤中的步骤
- Behave - 背景
- Behave - 数据类型
- Behave - 标签
- Behave - 枚举
- Behave - 步骤匹配器
- Behave - 正则表达式
- Behave - 可选部分
- Behave - 多方法
- Behave - 步骤函数
- Behave - 步骤参数
- Behave - 运行脚本
- Behave - 排除测试
- Behave - 重试机制
- Behave - 报告
- Behave - 钩子
- Behave - 调试
- Behave 有用资源
- Behave - 快速指南
- Behave - 有用资源
- Behave - 讨论
Behave - 正则表达式
让我们总体了解一下正则表达式的语法:
点 (.) - 等价于任何字符。
脱字符 (^) - 等价于字符串开头。(^…)
美元符号 ($) - 等价于字符串结尾。 (…$)
| - 表达式 x| y,匹配 x 或 y。
\ - 转义字符。
\. - 匹配点。(.)
\\ - 匹配反斜杠。(\)
[…] - 声明一组字符。([A-Za-z])
\d - 匹配数字。([0-9])
\D - 匹配非数字。
\s - 匹配空白字符。
\S - 匹配非空白字符。
\w - 匹配字母数字。
\W - 匹配非字母数字。
(…) - 对正则表达式的模式进行分组。
\number - 通过索引匹配先前组的文本。(\1)
(? P<name>…) - 匹配模式并将结果存储在 name 参数中。
(?P=name) - 匹配先前组名称匹配的所有文本。
(?:…) - 匹配模式,但不能捕获文本。
(?#...) - 注释(不被考虑)。描述模式的细节。
如果需要字符、字符集或组重复多次,则必须提供正则表达式模式的基数。
? : 基数为 0... 1 的模式:非必需(问号)
- : 基数为 0 或更多的模式,0..(星号)
+ - : 基数为 1 或更多的模式,1..(加号)
{n}: 匹配模式 n 次重复。
{a ,b}: 匹配模式 a 到 b 次重复。
[A-Za-z]+ : 匹配多个字母字符。
特性文件中可能存在步骤,这些步骤具有几乎相同的短语。Behave 具有解析能力。use_step_parser 方法用于此,我们必须将解析器类型作为参数传递给该方法。
对于正则表达式匹配器,我们必须传递参数 re。参数 (? P<name>...) 用于从步骤定义中获取参数。
特性文件(几乎相同的步骤)
类似步骤的特性文件如下所示:
Feature − Payment Process
Scenario − Check Debit transactions
Given user is on "debit" screen
Scenario − Check Credit transactions
Given user is on "credit" screen
对应的步骤实现文件
步骤实现文件如下所示:
from behave import *
#define parser type
use_step_matcher("re")
#regular expression parsing
@given('user is on "(?P<payment>.*)" screen')
def step_impl(context, payment):
print("Screen type: ")
print(payment)
输出
运行特性文件后得到的输出如下所示。这里,我们使用了命令behave --no-capture -f plain。
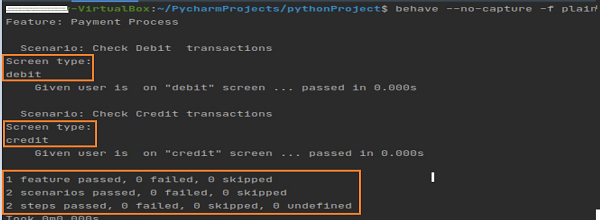
输出显示借方和贷方。这两个值已使用特性文件中几乎相同的步骤传递。在步骤实现中,我们使用正则表达式解析了这两个步骤。