- C语言数据结构与算法教程
- C语言数据结构与算法 - 首页
- C语言数据结构与算法 - 概述
- C语言数据结构与算法 - 环境配置
- C语言数据结构与算法 - 算法
- C语言数据结构与算法 - 概念
- C语言数据结构与算法 - 数组
- C语言数据结构与算法 - 链表
- C语言数据结构与算法 - 双向链表
- C语言数据结构与算法 - 循环链表
- C语言数据结构与算法 - 栈
- C语言数据结构与算法 - 表达式解析
- C语言数据结构与算法 - 队列
- C语言数据结构与算法 - 优先队列
- C语言数据结构与算法 - 树
- C语言数据结构与算法 - 哈希表
- C语言数据结构与算法 - 堆
- C语言数据结构与算法 - 图
- C语言数据结构与算法 - 搜索技术
- C语言数据结构与算法 - 排序技术
- C语言数据结构与算法 - 递归
- C语言数据结构与算法 - 有用资源
- C语言数据结构与算法 - 快速指南
- C语言数据结构与算法 - 有用资源
- C语言数据结构与算法 - 讨论
C语言数据结构与算法 - 快速指南
C语言数据结构与算法 - 概述
什么是数据结构?
数据结构是以一种可以有效使用的方式组织数据的方法。以下术语是数据结构的基础术语。
接口 - 每个数据结构都有一个接口。接口表示数据结构支持的一组操作。接口仅提供支持的操作列表、它们可以接受的参数类型以及这些操作的返回类型。
实现 - 实现提供了数据结构的内部表示。实现还提供了数据结构操作中使用的算法的定义。
数据结构的特性
正确性 - 数据结构实现应正确实现其接口。
时间复杂度 - 数据结构操作的运行时间或执行时间应尽可能短。
空间复杂度 - 数据结构操作的内存使用量应尽可能少。
数据结构的必要性
随着应用程序越来越复杂和数据丰富,如今应用程序面临三个常见问题。
数据搜索 - 考虑一个商店拥有100万(106)件商品的库存。如果应用程序要搜索一件商品,它每次都必须在100万(106)件商品中搜索商品,从而减慢搜索速度。随着数据量的增长,搜索会变得越来越慢。
处理器速度 - 尽管处理器速度非常高,但如果数据增长到数十亿条记录,处理器速度仍然有限。
多个请求 - 由于数千个用户可以同时在一个 Web 服务器上搜索数据,即使是速度非常快的服务器在搜索数据时也会失败。
为了解决上述问题,数据结构可以提供帮助。数据可以以这样一种方式组织在数据结构中,使得可能不需要搜索所有项目,并且可以几乎立即搜索所需的数据。
执行时间情况
通常使用三种情况来相对比较各种数据结构的执行时间。
最坏情况 - 这是一种场景,其中特定数据结构操作花费可能花费的最长时间。如果操作的最坏情况时间为 ƒ(n),则此操作不会花费超过 ƒ(n) 时间,其中 ƒ(n) 表示 n 的函数。
平均情况 - 这是一种场景,描述了数据结构操作的平均执行时间。如果一个操作需要 ƒ(n) 时间执行,则 m 个操作将需要 mƒ(n) 时间。
最佳情况 - 这是一种场景,描述了数据结构操作的最小可能执行时间。如果一个操作需要 ƒ(n) 时间执行,则实际操作可能花费的时间是一个随机数,其最大值为 ƒ(n)。
C语言数据结构与算法 - 环境搭建
本地环境搭建
如果您仍然希望为 C 编程语言设置环境,则需要在您的计算机上安装以下两种软件:(a) 文本编辑器和 (b) C 编译器。
文本编辑器
这将用于键入您的程序。一些编辑器的示例包括 Windows 记事本、OS Edit 命令、Brief、Epsilon、EMACS 和 vim 或 vi。
文本编辑器的名称和版本在不同的操作系统上可能有所不同。例如,Notepad 将在 Windows 上使用,而 vim 或 vi 也可以在 Windows 以及 Linux 或 UNIX 上使用。
您使用编辑器创建的文件称为源文件,其中包含程序源代码。C 程序的源文件通常以扩展名“.c”命名。
在开始编程之前,请确保您已准备好一个文本编辑器,并且您有足够的经验来编写计算机程序,将其保存在文件中,编译它并最终执行它。
C 编译器
源文件中编写的源代码是程序的人类可读源代码。它需要“编译”才能转换为机器语言,以便您的 CPU 能够根据给定的指令实际执行程序。
此 C 编程语言编译器将用于将您的源代码编译成最终的可执行程序。我假设您了解编程语言编译器的基本知识。
最常用的免费编译器是 GNU C/C++ 编译器,如果您有相应的操作系统,也可以使用 HP 或 Solaris 的编译器。
以下部分指导您如何在各种操作系统上安装 GNU C/C++ 编译器。我同时提及 C/C++,因为 GNU gcc 编译器适用于 C 和 C++ 编程语言。
在 UNIX/Linux 上安装
如果您使用的是Linux 或 UNIX,请通过从命令行输入以下命令来检查您的系统上是否安装了 GCC:
$ gcc -v
如果您的计算机上安装了 GNU 编译器,则它应该打印如下消息:
Using built-in specs. Target: i386-redhat-linux Configured with: ../configure --prefix=/usr ....... Thread model: posix gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
如果未安装 GCC,则您必须使用https://gcc.gnu.org/install/上提供的详细说明自行安装。
本教程是基于 Linux 编写的,所有给出的示例都在 Cent OS 版本的 Linux 系统上编译。
在 Mac OS 上安装
如果您使用的是 Mac OS X,获取 GCC 的最简单方法是从 Apple 的网站下载 Xcode 开发环境,然后按照简单的安装说明进行操作。设置 Xcode 后,您将能够使用 GNU C/C++ 编译器。
Xcode 目前可在developer.apple.com/technologies/tools/获取。
在 Windows 上安装
要在 Windows 上安装 GCC,您需要安装 MinGW。要安装 MinGW,请访问 MinGW 主页 www.mingw.org,然后点击链接进入 MinGW 下载页面。下载最新版本的 MinGW 安装程序,其名称应为 MinGW-<version>.exe。
安装 MinWG 时,至少必须安装 gcc-core、gcc-g++、binutils 和 MinGW 运行时,但您可能希望安装更多内容。
将 MinGW 安装的 bin 子目录添加到您的PATH环境变量中,以便您可以通过简单的名称在命令行中指定这些工具。
安装完成后,您将能够从 Windows 命令行运行 gcc、g++、ar、ranlib、dlltool 和其他几个 GNU 工具。
C语言数据结构与算法 - 算法
算法
算法是一个逐步的过程,它定义了一组指令,这些指令以一定的顺序执行以获得预期的输出。就数据结构而言,算法分为以下几类。
搜索 - 在数据结构中搜索项目的算法。
排序 - 按特定顺序对项目进行排序的算法
插入 - 将项目插入数据结构的算法
更新 - 更新数据结构中现有项目的算法
删除 - 从数据结构中删除现有项目的算法
算法分析
算法分析处理的是数据结构各种操作的执行时间或运行时间。操作的运行时间可以定义为每个操作执行的计算机指令数。由于任何操作的确切运行时间因计算机而异,我们通常将任何操作的运行时间分析为 n 的某个函数,其中 n 是数据结构中该操作处理的项目数。
渐近分析
渐近分析是指使用数学计算单元来计算任何操作的运行时间。例如,一个操作的运行时间计算为 *f*(n),另一个操作的运行时间计算为 *g*(n2)。这意味着第一个操作的运行时间将随着 n 的增加而线性增加,而第二个操作的运行时间将随着 n 的增加而呈指数增长。同样,如果 n 非常小,则这两个操作的运行时间几乎相同。
渐近符号
以下是计算算法运行时间复杂度时常用的渐近符号。
Ο 符号
Ω 符号
θ 符号
大O符号,Ο
Ο(n) 是表达算法运行时间上限的正式方法。它衡量的是最坏情况下的时间复杂度,或者算法可能完成所需的最长时间。
例如,对于函数 *f*(n)
大O符号用于简化函数。例如,我们可以用 Ο(*f*(nlogn)) 来代替特定的函数方程 7nlogn + n - 1。考虑如下场景:
这表明 *f*(n) = 7nlogn +n - 1 在使用常数 c = 8 和 n0 = 2 的 *O*(nlogn) 输出范围内。
欧米茄符号,Ω
Ω(n) 是表达算法运行时间下界的正式方法。它衡量的是最佳情况下的时间复杂度,或者算法可能完成所需的最短时间。
例如,对于函数 *f*(n)
西塔符号,θ
θ(n) 是表达算法运行时间下界和上界的正式方法。它表示如下。
C语言数据结构与算法 - 概念
数据结构是以一种可以有效使用的方式组织数据的方法。以下术语是数据结构的基本术语。
数据定义
数据定义使用以下特性定义特定数据。
原子性 - 定义应定义单个概念
可追溯性 - 定义应该能够映射到某些数据元素。
准确性 - 定义应该明确。
清晰简洁 - 定义应该易于理解。
数据对象
数据对象表示具有数据的对象。
数据类型
数据类型是对各种类型的数据(例如整数、字符串等)进行分类的方式,它决定了可以与相应类型的数据一起使用的值,以及可以对相应类型的数据执行的操作。数据类型分为两种:
内置数据类型
派生数据类型
内置数据类型
语言内置支持的那些数据类型称为内置数据类型。例如,大多数语言提供以下内置数据类型。
整数
布尔值(true,false)
浮点数(小数)
字符和字符串
派生数据类型
那些实现独立的数据类型,因为它们可以以一种或另一种方式实现,被称为派生数据类型。这些数据类型通常由主数据类型或内置数据类型及其相关操作组合构建而成。例如:
列表
数组
栈
队列
使用 C 语言的 DSA - 数组
概述
数组是一个容器,它可以容纳固定数量的项,并且这些项应该属于同一类型。大多数数据结构都利用数组来实现其算法。以下是理解数组概念的重要术语。
元素 - 存储在数组中的每个项目都称为元素。
索引 - 数组中每个元素的位置都有一个数值索引,用于标识该元素。
数组表示
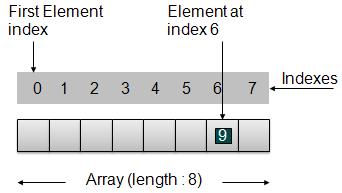
根据上图所示,以下是需要考虑的重要几点。
索引从 0 开始。
数组长度为 8,这意味着它可以存储 8 个元素。
每个元素都可以通过其索引访问。例如,我们可以获取索引为 6 的元素 9。
基本操作
以下是数组支持的基本操作。
插入 - 在给定索引处添加元素。
删除 - 删除给定索引处的元素。
搜索 - 使用给定索引或值搜索元素。
更新 - 更新给定索引处的元素。
在 C 语言中,当数组初始化大小后,它会按照以下顺序为其元素分配默认值。
| 序号 | 数据类型 | 默认值 |
|---|---|---|
| 1 | bool | false |
| 2 | char | 0 |
| 3 | int | 0 |
| 4 | float | 0.0 |
| 5 | double | 0.0f |
| 6 | void | |
| 7 | wchar_t | 0 |
示例
#include <stdio.h>
#include <string.h>
static void display(int intArray[], int length){
int i=0;
printf("Array : [");
for(i = 0; i < length; i++) {
/* display value of element at index i. */
printf(" %d ", intArray[i]);
}
printf(" ]\n ");
}
int main() {
int i = 0;
/* Declare an array */
int intArray[8];
// initialize elements of array n to 0
for ( i = 0; i < 8; i++ ) {
intArray[ i ] = 0; // set elements to default value of 0;
}
printf("Array with default data.");
/* Display elements of an array.*/
display(intArray,8);
/* Operation : Insertion
Add elements in the array */
for(i = 0; i < 8; i++) {
/* place value of i at index i. */
printf("Adding %d at index %d\n",i,i);
intArray[i] = i;
}
printf("\n");
printf("Array after adding data. ");
display(intArray,8);
/* Operation : Insertion
Element at any location can be updated directly */
int index = 5;
intArray[index] = 10;
printf("Array after updating element at index %d.\n",index);
display(intArray,8);
/* Operation : Search using index
Search an element using index.*/
printf("Data at index %d:%d\n" ,index,intArray[index]);
/* Operation : Search using value
Search an element using value.*/
int value = 4;
for(i = 0; i < 8; i++) {
if(intArray[i] == value ){
printf("value %d Found at index %d \n", intArray[i],i);
break;
}
}
return 0;
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Array with default data.Array : [ 0 0 0 0 0 0 0 0 ] Adding 0 at index 0 Adding 1 at index 1 Adding 2 at index 2 Adding 3 at index 3 Adding 4 at index 4 Adding 5 at index 5 Adding 6 at index 6 Adding 7 at index 7 Array after adding data. Array : [ 0 1 2 3 4 5 6 7 ] Array after updating element at index 5. Array : [ 0 1 2 3 4 10 6 7 ] Data at index 5: 10 4 Found at index 4
C语言数据结构与算法 - 链表
概述
链表是一系列包含项的链接。每个链接都包含与另一个链接的连接。链表是继数组之后第二常用的数据结构。以下是理解链表概念的重要术语。
链接 - 链表的每个链接都可以存储称为元素的数据。
Next - 链表的每个链接都包含指向下一个链接的链接,称为 Next。
链表 - 链表包含指向第一个链接的连接链接,称为 First。
链表表示
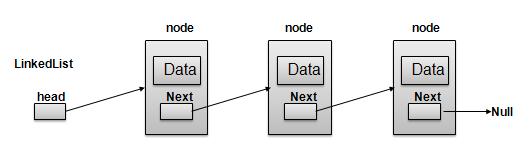
根据上图所示,以下是需要考虑的重要几点。
链表包含一个称为 first 的链接元素。
每个链接都包含一个或多个数据字段和一个称为 next 的链接字段。
每个链接都使用其 next 链接与其下一个链接链接。
最后一个链接包含一个值为 null 的链接,用于标记列表的结尾。
链表类型
以下是链表的各种类型。
单链表 - 项目导航仅向前。
双向链表 - 项目可以向前和向后导航。
循环链表 - 最后一项包含指向第一个元素的 next 链接,而第一个元素包含指向最后一项的 prev 链接。
基本操作
以下是列表支持的基本操作。
插入 - 在列表开头添加元素。
删除 - 删除列表开头的元素。
显示 - 显示完整列表。
搜索 - 使用给定键搜索元素。
删除 - 使用给定键删除元素。
插入操作
插入是一个三步过程:
使用提供的数据创建一个新的链接。
将新链接指向旧的 First 链接。
将 First 链接指向此新链接。
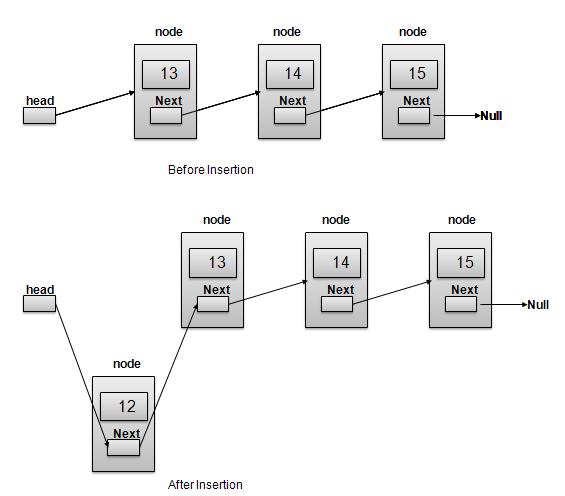
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
删除操作
删除是一个两步过程:
获取 First 链接指向的链接作为 Temp 链接。
将 First 链接指向 Temp 链接的 Next 链接。
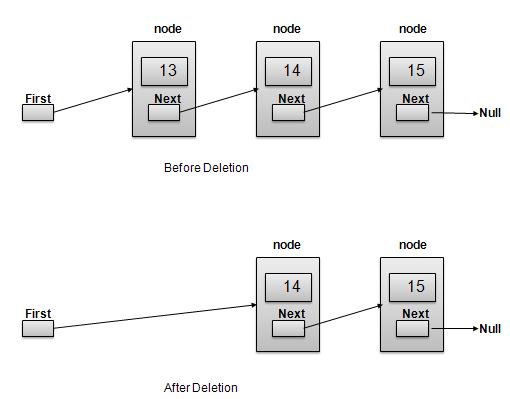
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
导航操作
导航是一个递归步骤过程,是许多操作(如搜索、删除等)的基础:
获取 First 链接指向的链接作为 Current 链接。
检查 Current 链接是否不为空,并显示它。
将 Current 链接指向 Current 链接的 Next 链接,并移动到上述步骤。
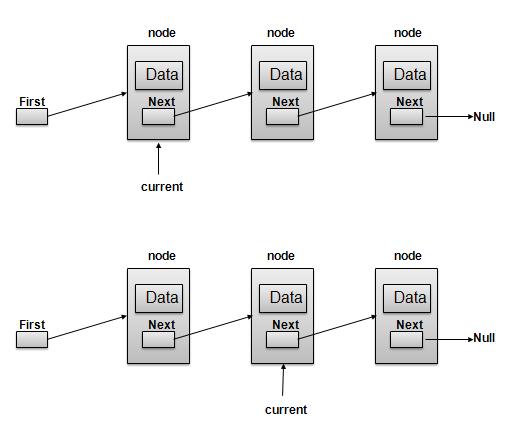
注意:
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
while(ptr != NULL){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
printf(" ]");
}
高级操作
以下是为列表指定的高级操作。
排序 - 基于特定顺序对列表进行排序。
反转 - 反转链表。
排序操作
我们使用冒泡排序来排序列表。
void sort(){
int i, j, k, tempKey, tempData ;
struct node *current;
struct node *next;
int size = length();
k = size ;
for ( i = 0 ; i < size - 1 ; i++, k-- ) {
current = head ;
next = head->next ;
for ( j = 1 ; j < k ; j++ ) {
if ( current->data > next->data ) {
tempData = current->data ;
current->data = next->data;
next->data = tempData ;
tempKey = current->key;
current->key = next->key;
next->key = tempKey;
}
current = current->next;
next = next->next;
}
}
}
反转操作
以下代码演示了反转单链表。
void reverse(struct node** head_ref) {
struct node* prev = NULL;
struct node* current = *head_ref;
struct node* next;
while (current != NULL) {
next = current->next;
current->next = prev;
prev = current;
current = next;
}
*head_ref = prev;
}
示例
LinkedListDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
int key;
struct node *next;
};
struct node *head = NULL;
struct node *current = NULL;
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
while(ptr != NULL){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
printf(" ]");
}
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
//is list empty
bool isEmpty(){
return head == NULL;
}
int length(){
int length = 0;
struct node *current;
for(current = head; current!=NULL;
current = current->next){
length++;
}
return length;
}
//find a link with given key
struct node* find(int key){
//start from the first link
struct node* current = head;
//if list is empty
if(head == NULL){
return NULL;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return NULL;
} else {
//go to next link
current = current->next;
}
}
//if data found, return the current Link
return current;
}
//delete a link with given key
struct node* delete(int key){
//start from the first link
struct node* current = head;
struct node* previous = NULL;
//if list is empty
if(head == NULL){
return NULL;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return NULL;
} else {
//store reference to current link
previous = current;
//move to next link
current = current->next;
}
}
//found a match, update the link
if(current == head) {
//change first to point to next link
head = head->next;
} else {
//bypass the current link
previous->next = current->next;
}
return current;
}
void sort(){
int i, j, k, tempKey, tempData ;
struct node *current;
struct node *next;
int size = length();
k = size ;
for ( i = 0 ; i < size - 1 ; i++, k-- ) {
current = head ;
next = head->next ;
for ( j = 1 ; j < k ; j++ ) {
if ( current->data > next->data ) {
tempData = current->data ;
current->data = next->data;
next->data = tempData ;
tempKey = current->key;
current->key = next->key;
next->key = tempKey;
}
current = current->next;
next = next->next;
}
}
}
void reverse(struct node** head_ref) {
struct node* prev = NULL;
struct node* current = *head_ref;
struct node* next;
while (current != NULL) {
next = current->next;
current->next = prev;
prev = current;
current = next;
}
*head_ref = prev;
}
main() {
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("Original List: ");
//print list
printList();
while(!isEmpty()){
struct node *temp = deleteFirst();
printf("\nDeleted value:");
printf("(%d,%d) ",temp->key,temp->data);
}
printf("\nList after deleting all items: ");
printList();
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("\nRestored List: ");
printList();
printf("\n");
struct node *foundLink = find(4);
if(foundLink != NULL){
printf("Element found: ");
printf("(%d,%d) ",foundLink->key,foundLink->data);
printf("\n");
} else {
printf("Element not found.");
}
delete(4);
printf("List after deleting an item: ");
printList();
printf("\n");
foundLink = find(4);
if(foundLink != NULL){
printf("Element found: ");
printf("(%d,%d) ",foundLink->key,foundLink->data);
printf("\n");
} else {
printf("Element not found.");
}
printf("\n");
sort();
printf("List after sorting the data: ");
printList();
reverse(&head);
printf("\nList after reversing the data: ");
printList();
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Original List: [ (6,56) (5,40) (4,1) (3,30) (2,20) (1,10) ] Deleted value:(6,56) Deleted value:(5,40) Deleted value:(4,1) Deleted value:(3,30) Deleted value:(2,20) Deleted value:(1,10) List after deleting all items: [ ] Restored List: [ (6,56) (5,40) (4,1) (3,30) (2,20) (1,10) ] Element found: (4,1) List after deleting an item: [ (6,56) (5,40) (3,30) (2,20) (1,10) ] Element not found. List after sorting the data: [ (1,10) (2,20) (3,30) (5,40) (6,56) ] List after reversing the data: [ (6,56) (5,40) (3,30) (2,20) (1,10) ]
C语言数据结构与算法 - 双向链表
概述
双向链表是链表的一种变体,与单链表相比,它可以很容易地向前和向后两种方式进行导航。以下是理解双向链表概念的重要术语。
链接 - 链表的每个链接都可以存储称为元素的数据。
Next - 链表的每个链接都包含指向下一个链接的链接,称为 Next。
Prev - 链表的每个链接都包含指向先前链接的链接,称为 Prev。
链表 - 链表包含指向第一个链接的连接链接(称为 First)和指向最后一个链接的链接(称为 Last)。
双向链表表示
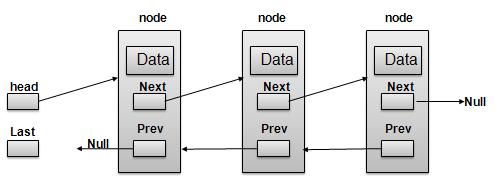
根据上图所示,以下是需要考虑的重要几点。
双向链表包含一个称为 first 和 last 的链接元素。
每个链接都包含一个或多个数据字段和一个称为 next 的链接字段。
每个链接都使用其 next 链接与其下一个链接链接。
每个链接都使用其 prev 链接与其先前的链接链接。
最后一个链接包含一个值为 null 的链接,用于标记列表的结尾。
基本操作
以下是列表支持的基本操作。
插入 - 在列表开头添加元素。
删除 - 删除列表开头的元素。
插入末尾 - 在列表末尾添加元素。
删除末尾 - 删除列表末尾的元素。
插入到…之后 - 在列表的某个项之后添加元素。
删除 - 使用键从列表中删除元素。
向前显示 - 以向前的方式显示完整列表。
向后显示 - 以向后的方式显示完整列表。
插入操作
以下代码演示了在双向链表开头进行插入操作。
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}
删除操作
以下代码演示了在双向链表开头进行删除操作。
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL){
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}
在末尾插入操作
以下代码演示了在双向链表的最后一个位置进行插入操作。
//insert link at the last location
void insertLast(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}
示例
DoublyLinkedListDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
int key;
struct node *next;
struct node *prev;
};
//this link always point to first Link
struct node *head = NULL;
//this link always point to last Link
struct node *last = NULL;
struct node *current = NULL;
//is list empty
bool isEmpty(){
return head == NULL;
}
int length(){
int length = 0;
struct node *current;
for(current = head; current!=NULL;
current = current->next){
length++;
}
return length;
}
//display the list in from first to last
void displayForward(){
//start from the beginning
struct node *ptr = head;
//navigate till the end of the list
printf("\n[ ");
while(ptr != NULL){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
printf(" ]");
}
//display the list from last to first
void displayBackward(){
//start from the last
struct node *ptr = last;
//navigate till the start of the list
printf("\n[ ");
while(ptr != NULL){
//print data
printf("(%d,%d) ",ptr->key,ptr->data);
//move to next item
ptr = ptr ->prev;
printf(" ");
}
printf(" ]");
}
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}
//insert link at the last location
void insertLast(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL){
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}
//delete link at the last location
struct node* deleteLast(){
//save reference to last link
struct node *tempLink = last;
//if only one link
if(head->next == NULL){
head = NULL;
} else {
last->prev->next = NULL;
}
last = last->prev;
//return the deleted link
return tempLink;
}
//delete a link with given key
struct node* delete(int key){
//start from the first link
struct node* current = head;
struct node* previous = NULL;
//if list is empty
if(head == NULL){
return NULL;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return NULL;
} else {
//store reference to current link
previous = current;
//move to next link
current = current->next;
}
}
//found a match, update the link
if(current == head) {
//change first to point to next link
head = head->next;
} else {
//bypass the current link
current->prev->next = current->next;
}
if(current == last){
//change last to point to prev link
last = current->prev;
} else {
current->next->prev = current->prev;
}
return current;
}
bool insertAfter(int key, int newKey, int data){
//start from the first link
struct node *current = head;
//if list is empty
if(head == NULL){
return false;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return false;
} else {
//move to next link
current = current->next;
}
}
//create a link
struct node *newLink = (struct node*) malloc(sizeof(struct node));
newLink->key = key;
newLink->data = data;
if(current==last) {
newLink->next = NULL;
last = newLink;
} else {
newLink->next = current->next;
current->next->prev = newLink;
}
newLink->prev = current;
current->next = newLink;
return true;
}
main() {
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("\nList (First to Last): ");
displayForward();
printf("\n");
printf("\nList (Last to first): ");
displayBackward();
printf("\nList , after deleting first record: ");
deleteFirst();
displayForward();
printf("\nList , after deleting last record: ");
deleteLast();
displayForward();
printf("\nList , insert after key(4) : ");
insertAfter(4,7, 13);
displayForward();
printf("\nList , after delete key(4) : ");
delete(4);
displayForward();
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
List (First to Last): [ (6,56) (5,40) (4,1) (3,30) (2,20) (1,10) ] List (Last to first): [ (1,10) (2,20) (3,30) (4,1) (5,40) (6,56) ] List , after deleting first record: [ (5,40) (4,1) (3,30) (2,20) (1,10) ] List , after deleting last record: [ (5,40) (4,1) (3,30) (2,20) ] List , insert after key(4) : [ (5,40) (4,1) (4,13) (3,30) (2,20) ] List , after delete key(4) : [ (5,40) (4,13) (3,30) (2,20) ]
C语言数据结构与算法 - 循环链表
概述
循环链表是链表的一种变体,其中第一个元素指向最后一个元素,而最后一个元素指向第一个元素。单链表和双向链表都可以制成循环链表。
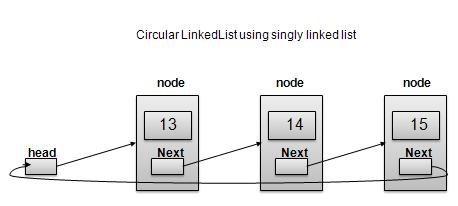
单链表作为循环链表
双向链表作为循环链表
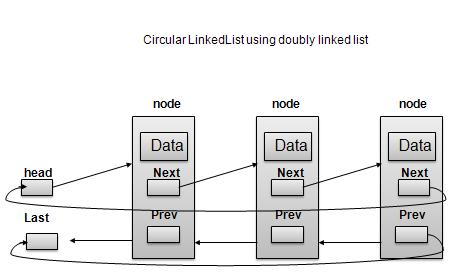
根据上图所示,以下是需要考虑的重要几点。
在单链表和双向链表的两种情况下,最后一个链接的 next 都指向列表的第一个链接。
对于双向链表,第一个链接的 prev 指向列表的最后一个链接。
基本操作
以下是循环列表支持的重要操作。
插入 - 在列表开头插入元素。
删除 - 从列表开头删除元素。
显示 - 显示列表。
长度操作
以下代码演示了基于单链表在循环链表中进行插入操作。
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key =key;
link->data=data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}
删除操作
以下代码演示了基于单链表在循环链表中进行删除操作。
//delete first item
struct node * deleteFirst(){
//save reference to first link
struct node *tempLink = head;
if(head->next == head){
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
显示列表操作
以下代码演示了在循环链表中显示列表操作。
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL){
while(ptr->next != ptr){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}
示例
DoublyLinkedListDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
int key;
struct node *next;
};
struct node *head = NULL;
struct node *current = NULL;
bool isEmpty(){
return head == NULL;
}
int length(){
int length = 0;
//if list is empty
if(head == NULL){
return 0;
}
current = head->next;
while(current != head){
length++;
current = current->next;
}
return length;
}
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key =key;
link->data=data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}
//delete first item
struct node * deleteFirst(){
//save reference to first link
struct node *tempLink = head;
if(head->next == head){
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL){
while(ptr->next != ptr){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}
main() {
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("Original List: ");
//print list
printList();
while(!isEmpty()){
struct node *temp = deleteFirst();
printf("\nDeleted value:");
printf("(%d,%d) ",temp->key,temp->data);
}
printf("\nList after deleting all items: ");
printList();
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Original List: [ (6,56) (5,40) (4,1) (3,30) (2,20) ] Deleted value:(6,56) Deleted value:(5,40) Deleted value:(4,1) Deleted value:(3,30) Deleted value:(2,20) Deleted value:(1,10) List after deleting all items: [ ]
C语言数据结构与算法 - 栈
概述
栈是一种数据结构,它只允许在一端对数据进行操作。它只允许访问最后插入的数据。栈也被称为 LIFO(后进先出)数据结构,并且 Push 和 Pop 操作以这样的方式相关:只有最后压入(添加到栈中)的项目才能弹出(从栈中移除)。
栈表示
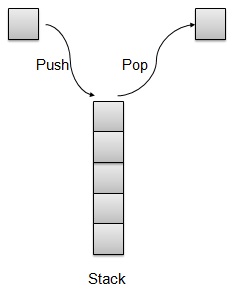
我们将在本文中使用数组来实现栈。
基本操作
以下是栈的两个主要操作。
Push - 将元素压入栈顶。
Pop - 从栈顶弹出元素。
栈还支持一些其他操作。
Peek - 获取栈顶元素。
isFull - 检查栈是否已满。
isEmpty - 检查栈是否为空。
Push 操作
每当将元素压入栈中时,栈都会将该元素存储在存储区的顶部,并递增顶部索引以供以后使用。如果存储区已满,则通常会显示错误消息。
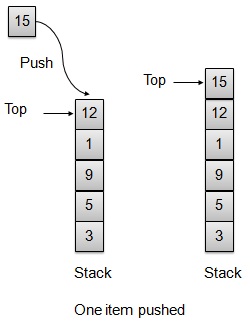
// Operation : Push
// push item on the top of the stack
void push(int data) {
if(!isFull()){
// increment top by 1 and insert data
intArray[++top] = data;
} else {
printf("Cannot add data. Stack is full.\n");
}
}
Pop 操作
每当要从栈中弹出元素时,栈都会从存储区的顶部检索元素,并递减顶部索引以供以后使用。
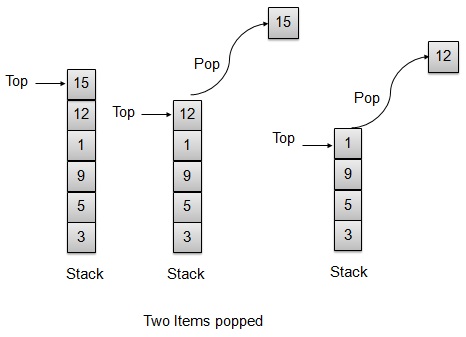
// Operation : Pop
// pop item from the top of the stack
int pop() {
//retrieve data and decrement the top by 1
return intArray[top--];
}
示例
StackDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
// size of the stack
int size = 8;
// stack storage
int intArray[8];
// top of the stack
int top = -1;
// Operation : Pop
// pop item from the top of the stack
int pop() {
//retrieve data and decrement the top by 1
return intArray[top--];
}
// Operation : Peek
// view the data at top of the stack
int peek() {
//retrieve data from the top
return intArray[top];
}
//Operation : isFull
//return true if stack is full
bool isFull(){
return (top == size-1);
}
// Operation : isEmpty
// return true if stack is empty
bool isEmpty(){
return (top == -1);
}
// Operation : Push
// push item on the top of the stack
void push(int data) {
if(!isFull()){
// increment top by 1 and insert data
intArray[++top] = data;
} else {
printf("Cannot add data. Stack is full.\n");
}
}
main() {
// push items on to the stack
push(3);
push(5);
push(9);
push(1);
push(12);
push(15);
printf("Element at top of the stack: %d\n" ,peek());
printf("Elements: \n");
// print stack data
while(!isEmpty()){
int data = pop();
printf("%d\n",data);
}
printf("Stack full: %s\n" , isFull()?"true":"false");
printf("Stack empty: %s\n" , isEmpty()?"true":"false");
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Element at top of the stack: 15 Elements: 15 12 1 9 5 3 Stack full: false Stack empty: true
C语言数据结构与算法 - 表达式解析
像 2*(3*4) 这样的普通算术表达式更容易让人理解,但对于算法来说,解析这样的表达式会相当困难。为了减轻这种困难,可以使用两步法通过算法解析算术表达式。
将提供的算术表达式转换为后缀表示法。
计算后缀表示法。
中缀表示法
正常的算术表达式遵循中缀表示法,其中运算符位于操作数之间。例如 A+B,其中 A 是第一个操作数,B 是第二个操作数,+ 是作用于这两个操作数的运算符。
后缀表示法
后缀表示法与正常的算术表达式或中缀表示法的区别在于,运算符位于操作数之后。例如,请考虑以下示例。
| 序号 | 中缀表示法 | 后缀表示法 |
|---|---|---|
| 1 | A+B | AB+ |
| 2 | (A+B)*C | AB+C* |
| 3 | A*(B+C) | ABC+* |
| 4 | A/B+C/D | AB/CD/+ |
| 5 | (A+B)*(C+D) | AB+CD+* |
| 6 | ((A+B)*C)-D | AB+C*D- |
中缀转后缀转换
在查看将中缀转换为后缀表示法的方法之前,我们需要考虑中缀表达式计算的基本知识。
中缀表达式的计算从左到右开始。
记住优先级,例如 * 的优先级高于 +。例如
2+3*4 = 2+12.
2+3*4 = 14.
-
使用括号来覆盖优先级,例如
(2+3)*4 = 5*4.
(2+3)*4= 20.
现在让我们手动将简单的中缀表达式 A+B*C 转换为后缀表达式。
| 序号 | 读取的字符 | 到目前为止已解析的中缀表达式 | 到目前为止已生成的逆波兰表达式 | 备注 |
|---|---|---|---|---|
| 1 | A | A | A | |
| 2 | + | A+ | A | |
| 3 | B | A+B | AB | |
| 4 | * | A+B* | AB | 因为 * 的优先级高于 +,所以 + 不能复制。 |
| 5 | C | A+B*C | ABC | |
| 6 | A+B*C | ABC* | 复制 *,因为有两个操作数 B 和 C | |
| 7 | A+B*C | ABC*+ | 复制 +,因为有两个操作数 BC 和 A |
现在让我们使用栈将上述中缀表达式 A+B*C 转换为后缀表达式。
| 序号 | 读取的字符 | 到目前为止已解析的中缀表达式 | 到目前为止已生成的逆波兰表达式 | 栈内容 | 备注 |
|---|---|---|---|---|---|
| 1 | A | A | A | ||
| 2 | + | A+ | A | + | 将 + 操作符压入栈中。 |
| 3 | B | A+B | AB | + | |
| 4 | * | A+B* | AB | +* | * 操作符的优先级高于 +。将 * 操作符压入栈中。否则,+ 将弹出。 |
| 5 | C | A+B*C | ABC | +* | |
| 6 | A+B*C | ABC* | + | 没有更多操作数,弹出 * 操作符。 | |
| 7 | A+B*C | ABC*+ | 弹出 + 操作符。 |
现在让我们看另一个例子,使用栈将中缀表达式 A*(B+C) 转换为后缀表达式。
| 序号 | 读取的字符 | 到目前为止已解析的中缀表达式 | 到目前为止已生成的逆波兰表达式 | 栈内容 | 备注 |
|---|---|---|---|---|---|
| 1 | A | A | A | ||
| 2 | * | A* | A | * | 将 * 操作符压入栈中。 |
| 3 | ( | A*( | A | *( | 将 ( 压入栈中。 |
| 4 | B | A*(B | AB | *( | |
| 5 | + | A*(B+ | AB | *(+ | 将 + 压入栈中。 |
| 6 | C | A*(B+C | ABC | *(+ | |
| 7 | ) | A*(B+C) | ABC+ | *( | 弹出 + 操作符。 |
| 8 | A*(B+C) | ABC+ | * | 弹出 ( 操作符。 | |
| 9 | A*(B+C) | ABC+* | 弹出其余的操作符。 |
示例
现在我们将演示使用栈将中缀表达式转换为后缀表达式,然后计算后缀表达式的值。
#include<stdio.h>
#include<string.h>
//char stack
char stack[25];
int top=-1;
void push(char item) {
stack[++top]=item;
}
char pop() {
return stack[top--];
}
//returns precedence of operators
int precedence(char symbol) {
switch(symbol) {
case '+':
case '-':
return 2;
break;
case '*':
case '/':
return 3;
break;
case '^':
return 4;
break;
case '(':
case ')':
case '#':
return 1;
break;
}
}
//check whether the symbol is operator?
int isOperator(char symbol) {
switch(symbol){
case '+':
case '-':
case '*':
case '/':
case '^':
case '(':
case ')':
return 1;
break;
default:
return 0;
}
}
//converts infix expression to postfix
void convert(char infix[],char postfix[]){
int i,symbol,j=0;
stack[++top]='#';
for(i=0;i<strlen(infix);i++){
symbol=infix[i];
if(isOperator(symbol)==0){
postfix[j]=symbol;
j++;
} else {
if(symbol=='('){
push(symbol);
} else {
if(symbol==')'){
while(stack[top]!='('){
postfix[j]=pop();
j++;
}
pop();//pop out (.
} else {
if(precedence(symbol)>precedence(stack[top])) {
push(symbol);
} else {
while(precedence(symbol)<=precedence(stack[top])) {
postfix[j]=pop();
j++;
}
push(symbol);
}
}
}
}
}
while(stack[top]!='#') {
postfix[j]=pop();
j++;
}
postfix[j]='\0';//null terminate string.
}
//int stack
int stack_int[25];
int top_int=-1;
void push_int(int item) {
stack_int[++top_int]=item;
}
char pop_int() {
return stack_int[top_int--];
}
//evaluates postfix expression
int evaluate(char *postfix){
char ch;
int i=0,operand1,operand2;
while( (ch=postfix[i++]) != '\0') {
if(isdigit(ch)){
push_int(ch-'0'); // Push the operand
} else {
//Operator,pop two operands
operand2=pop_int();
operand1=pop_int();
switch(ch) {
case '+':
push_int(operand1+operand2);
break;
case '-':
push_int(operand1-operand2);
break;
case '*':
push_int(operand1*operand2);
break;
case '/':
push_int(operand1/operand2);
break;
}
}
}
return stack_int[top_int];
}
void main() {
char infix[25] = "1*(2+3)",postfix[25];
convert(infix,postfix);
printf("Infix expression is: %s\n" , infix);
printf("Postfix expression is: %s\n" , postfix);
printf("Evaluated expression is: %d\n" , evaluate(postfix));
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Infix expression is: 1*(2+3) Postfix expression is: 123+* Result is: 5
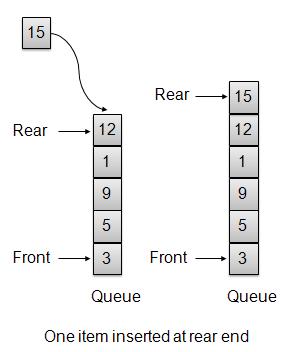
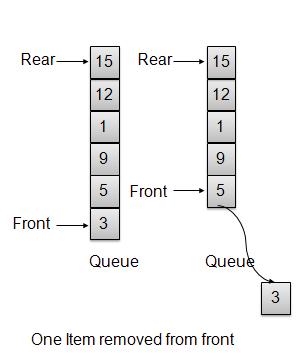
C语言数据结构与算法 - 队列
概述
队列是一种类似于栈的数据结构,主要区别在于第一个插入的项是第一个被移除的项(FIFO - 先进先出),而栈是基于 LIFO(后进先出)原则的。
队列表示
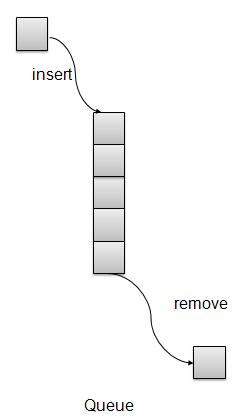
基本操作
插入/入队 − 将一个项添加到队列的尾部。
移除/出队 − 从队列的头部移除一个项。
在本文中,我们将使用数组实现队列。队列还支持一些其他操作,如下所示。
Peek − 获取队列头部元素。
isFull − 检查队列是否已满。
isEmpty − 检查队列是否为空。
插入/入队操作
每当一个元素插入到队列中时,队列都会递增尾部索引以备后用,并将该元素存储在存储区的尾部。如果尾部到达最后一个索引,则将其环绕到底部位置。这种安排称为环绕,这种队列称为循环队列。此方法也称为入队操作。
void insert(int data){
if(!isFull()){
if(rear == MAX-1){
rear = -1;
}
intArray[++rear] = data;
itemCount++;
}
}
移除/出队操作
每当要从队列中移除一个元素时,队列都会使用头部索引获取元素并递增头部索引。作为环绕安排,如果头部索引大于数组的最大索引,则将其设置为 0。
int removeData(){
int data = intArray[front++];
if(front == MAX){
front = 0;
}
itemCount--;
return data;
}
示例
QueueDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 6
int intArray[MAX];
int front = 0;
int rear = -1;
int itemCount = 0;
int peek(){
return intArray[front];
}
bool isEmpty(){
return itemCount == 0;
}
bool isFull(){
return itemCount == MAX;
}
int size(){
return itemCount;
}
void insert(int data){
if(!isFull()){
if(rear == MAX-1){
rear = -1;
}
intArray[++rear] = data;
itemCount++;
}
}
int removeData(){
int data = intArray[front++];
if(front == MAX){
front = 0;
}
itemCount--;
return data;
}
int main() {
/* insert 5 items */
insert(3);
insert(5);
insert(9);
insert(1);
insert(12);
// front : 0
// rear : 4
// ------------------
// index : 0 1 2 3 4
// ------------------
// queue : 3 5 9 1 12
insert(15);
// front : 0
// rear : 5
// ---------------------
// index : 0 1 2 3 4 5
// ---------------------
// queue : 3 5 9 1 12 15
if(isFull()){
printf("Queue is full!\n");
}
// remove one item
int num = removeData();
printf("Element removed: %d\n",num);
// front : 1
// rear : 5
// -------------------
// index : 1 2 3 4 5
// -------------------
// queue : 5 9 1 12 15
// insert more items
insert(16);
// front : 1
// rear : -1
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 5 9 1 12 15
// As queue is full, elements will not be inserted.
insert(17);
insert(18);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 5 9 1 12 15
printf("Element at front: %d\n",peek());
printf("----------------------\n");
printf("index : 5 4 3 2 1 0\n");
printf("----------------------\n");
printf("Queue: ");
while(!isEmpty()){
int n = removeData();
printf("%d ",n);
}
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Queue is full! Element removed: 3 Element at front: 5 ---------------------- index : 5 4 3 2 1 0 ---------------------- Queue: 5 9 1 12 15 16
C语言数据结构与算法 - 优先队列
概述
优先队列比队列更专业的数据结构。与普通队列一样,优先队列具有相同的方法,但有一个主要区别。在优先队列中,项按键值排序,以便键值最低的项位于前面,键值最高的项位于后面,反之亦然。因此,我们根据项的键值分配优先级。值越低,优先级越高。以下是优先队列的主要方法。
基本操作
插入/入队 − 将一个项添加到队列的尾部。
移除/出队 − 从队列的头部移除一个项。
优先队列表示
在本文中,我们将使用数组实现队列。队列还支持一些其他操作,如下所示。
Peek − 获取队列头部元素。
isFull − 检查队列是否已满。
isEmpty − 检查队列是否为空。
插入/入队操作
每当将元素插入队列时,优先队列会根据其顺序插入该项。这里我们假设数据值越高,优先级越低。
void insert(int data){
int i =0;
if(!isFull()){
// if queue is empty, insert the data
if(itemCount == 0){
intArray[itemCount++] = data;
} else {
// start from the right end of the queue
for(i = itemCount - 1; i >= 0; i-- ){
// if data is larger, shift existing item to right end
if(data > intArray[i]){
intArray[i+1] = intArray[i];
} else {
break;
}
}
// insert the data
intArray[i+1] = data;
itemCount++;
}
}
}
移除/出队操作
每当要从队列中移除一个元素时,队列会使用项目计数获取该元素。一旦元素被移除,项目计数就会减少一个。
int removeData(){
return intArray[--itemCount];
}
示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 6
int intArray[MAX];
int itemCount = 0;
int peek(){
return intArray[itemCount - 1];
}
bool isEmpty(){
return itemCount == 0;
}
bool isFull(){
return itemCount == MAX;
}
int size(){
return itemCount;
}
void insert(int data){
int i =0;
if(!isFull()){
// if queue is empty, insert the data
if(itemCount == 0){
intArray[itemCount++] = data;
} else {
// start from the right end of the queue
for(i = itemCount - 1; i >= 0; i-- ){
// if data is larger, shift existing item to right end
if(data > intArray[i]){
intArray[i+1] = intArray[i];
} else {
break;
}
}
// insert the data
intArray[i+1] = data;
itemCount++;
}
}
}
int removeData(){
return intArray[--itemCount];
}
int main() {
/* insert 5 items */
insert(3);
insert(5);
insert(9);
insert(1);
insert(12);
// ------------------
// index : 0 1 2 3 4
// ------------------
// queue : 12 9 5 3 1
insert(15);
// ---------------------
// index : 0 1 2 3 4 5
// ---------------------
// queue : 15 12 9 5 3 1
if(isFull()){
printf("Queue is full!\n");
}
// remove one item
int num = removeData();
printf("Element removed: %d\n",num);
// ---------------------
// index : 0 1 2 3 4
// ---------------------
// queue : 15 12 9 5 3
// insert more items
insert(16);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 15 12 9 5 3
// As queue is full, elements will not be inserted.
insert(17);
insert(18);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 15 12 9 5 3
printf("Element at front: %d\n",peek());
printf("----------------------\n");
printf("index : 5 4 3 2 1 0\n");
printf("----------------------\n");
printf("Queue: ");
while(!isEmpty()){
int n = removeData();
printf("%d ",n);
}
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Queue is full! Element removed: 1 Element at front: 3 ---------------------- index : 5 4 3 2 1 0 ---------------------- Queue: 3 5 9 12 15 16
C语言数据结构与算法 - 树
概述
树表示由边连接的节点。我们将专门讨论二叉树或二叉搜索树。
二叉树是一种用于数据存储的特殊数据结构。二叉树有一个特殊条件,即每个节点最多可以有两个子节点。二叉树兼具有序数组和链表的优点,搜索速度与排序数组一样快,插入或删除操作速度与链表一样快。
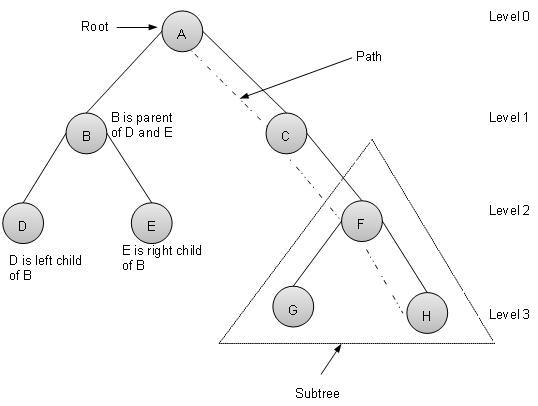
术语
以下是关于树的一些重要术语。
路径 − 路径是指沿着树的边的节点序列。
根 − 树顶部的节点称为根。每棵树只有一个根,并且从根节点到任何节点只有一条路径。
父节点 − 除根节点外的任何节点都有一条向上指向称为父节点的节点的边。
子节点 − 通过其向下边连接到给定节点下方的节点称为其子节点。
叶子节点 − 没有子节点的节点称为叶子节点。
子树 − 子树表示节点的后代。
访问 − 访问是指当控制处于节点上时检查节点的值。
遍历 − 遍历意味着以特定顺序通过节点。
层级 − 节点的层级表示节点的代数。如果根节点位于第 0 层,则其下一个子节点位于第 1 层,其孙子节点位于第 2 层,依此类推。
键 − 键表示节点的值,基于此值将对节点执行搜索操作。
二叉搜索树表现出一种特殊行为。节点的左子节点的值必须小于其父节点的值,节点的右子节点的值必须大于其父节点的值。
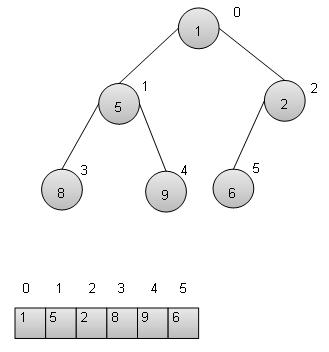
二叉搜索树表示
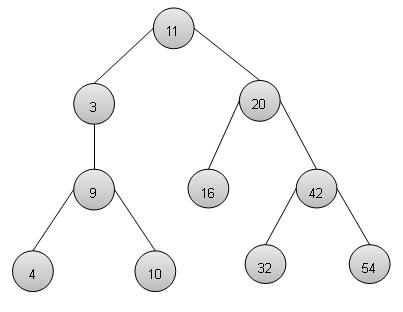
我们将使用节点对象实现树,并通过引用将它们连接起来。
基本操作
以下是树的基本主要操作:
搜索 − 在树中搜索元素。
插入 − 在树中插入元素。
先序遍历 − 以先序方式遍历树。
中序遍历 − 以中序方式遍历树。
后序遍历 − 以后序方式遍历树。
节点
定义一个节点,它包含一些数据以及对其左右子节点的引用。
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
搜索操作
每当要搜索元素时,从根节点开始搜索,如果数据小于键值,则在左子树中搜索元素,否则在右子树中搜索元素。对每个节点遵循相同的算法。
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
return current;
}
插入操作
每当要插入元素时,首先找到其适当的位置。从根节点开始搜索,如果数据小于键值,则在左子树中搜索空位置并插入数据。否则,在右子树中搜索空位置并插入数据。
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
} else {
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
先序遍历
这是一个简单的三步过程。
访问根节点
遍历左子树
遍历右子树
void preOrder(struct node* root){
if(root!=NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
中序遍历
这是一个简单的三步过程。
遍历左子树
访问根节点
遍历右子树
void inOrder(struct node* root){
if(root!=NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
后序遍历
这是一个简单的三步过程。
遍历左子树
遍历右子树
访问根节点
void postOrder(struct node* root){
if(root!=NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
struct node *root = NULL;
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
} else {
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
return current;
}
void preOrder(struct node* root){
if(root!=NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
void inOrder(struct node* root){
if(root!=NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
void postOrder(struct node* root){
if(root!=NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
void traverse(int traversalType){
switch(traversalType){
case 1:
printf("\nPreorder traversal: ");
preOrder(root);
break;
case 2:
printf("\nInorder traversal: ");
inOrder(root);
break;
case 3:
printf("\nPostorder traversal: ");
postOrder(root);
break;
}
}
int main()
{
/* 11 //Level 0
*/
insert(11);
/* 11 //Level 0
* |
* |---20 //Level 1
*/
insert(20);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
*/
insert(3);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
*/
insert(42);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
* |
* |--54 //Level 3
*/
insert(54);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* |--54 //Level 3
*/
insert(16);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(32);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(9);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--| 32--|--54 //Level 3
*/
insert(4);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--|--10 32--|--54 //Level 3
*/
insert(10);
struct node * temp = search(32);
if(temp!=NULL){
printf("Element found.\n");
printf("( %d )",temp->data);
printf("\n");
} else {
printf("Element not found.\n");
}
struct node *node1 = search(2);
if(node1!=NULL){
printf("Element found.\n");
printf("( %d )",node1->data);
printf("\n");
} else {
printf("Element not found.\n");
}
//pre-order traversal
//root, left ,right
traverse(1);
//in-order traversal
//left, root ,right
traverse(2);
//post order traversal
//left, right, root
traverse(3);
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Visiting elements: 11 20 42 Element found.(32) Visiting elements: 11 3 Element not found. Preorder traversal: 11 3 9 4 10 20 16 42 32 54 Inorder traversal: 3 4 9 10 11 16 20 32 42 54 Postorder traversal: 4 10 9 3 16 32 54 42 20 11
C语言数据结构与算法 - 哈希表
概述
哈希表是一种数据结构,其中插入和搜索操作非常快,与哈希表的大小无关。它几乎是常数或 O(1)。哈希表使用数组作为存储介质,并使用哈希技术生成要插入元素或从中定位元素的索引。
哈希
哈希是一种将一系列键值转换为数组索引范围的技术。我们将使用模运算符来获取一系列键值。考虑一个大小为 20 的哈希表的例子,并且要存储以下项。项采用 (键,值) 格式。
(1,20)
(2,70)
(42,80)
(4,25)
(12,44)
(14,32)
(17,11)
(13,78)
(37,98)
| 序号 | 键 | 哈希值 | 数组索引 |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
线性探测
正如我们所看到的,使用的方法创建的哈希技术可能会创建数组中已经使用的索引。在这种情况下,我们可以通过查看下一个单元格直到找到一个空单元格来搜索数组中的下一个空位置。这种技术称为线性探测。
| 序号 | 键 | 哈希值 | 数组索引 | 线性探测后,数组索引 |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
基本操作
以下是哈希表的基本主要操作:
搜索 − 在哈希表中搜索元素。
插入 − 在哈希表中插入元素。
删除 − 从哈希表中删除元素。
数据项
定义一个数据项,它包含一些数据和键,基于该键在哈希表中进行搜索。
struct DataItem {
int data;
int key;
};
哈希方法
定义一个哈希方法来计算数据项键的哈希码。
int hashCode(int key){
return key % SIZE;
}
搜索操作
每当要搜索元素时,计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位元素。如果在计算的哈希码处找不到元素,则使用线性探测来获取前方的元素。
struct DataItem *search(int key){
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL){
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
插入操作
每当要插入元素时,计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位索引。如果在计算的哈希码处找到元素,则使用线性探测查找空位置。
void insert(int key,int data){
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] !=NULL &&
hashArray[hashIndex]->key != -1){
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
删除操作
每当要删除元素时,计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位索引。如果在计算的哈希码处找不到元素,则使用线性探测来获取前方的元素。找到后,在那里存储一个虚拟项以保持哈希表的性能不变。
struct DataItem* delete(struct DataItem* item){
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL){
if(hashArray[hashIndex]->key == key){
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define SIZE 20
struct DataItem {
int data;
int key;
};
struct DataItem* hashArray[SIZE];
struct DataItem* dummyItem;
struct DataItem* item;
int hashCode(int key){
return key % SIZE;
}
struct DataItem *search(int key){
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL){
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void insert(int key,int data){
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] !=NULL &&
hashArray[hashIndex]->key != -1){
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
struct DataItem* delete(struct DataItem* item){
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL){
if(hashArray[hashIndex]->key == key){
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void display(){
int i=0;
for(i=0; i<SIZE; i++) {
if(hashArray[i] != NULL)
printf(" (%d,%d)",hashArray[i]->key,hashArray[i]->data);
else
printf(" ~~ ");
}
printf("\n");
}
int main(){
dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem));
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
display();
item = search(37);
if(item != NULL){
printf("Element found: %d\n", item->data);
} else {
printf("Element not found\n");
}
delete(item);
item = search(37);
if(item != NULL){
printf("Element found: %d\n", item->data);
} else {
printf("Element not found\n");
}
}
如果我们编译并运行上述程序,则它将产生以下结果:
~~ (1,20) (2,70) (42,80) (4,25) ~~ ~~ ~~ ~~ ~~ ~~ ~~ (12,44) (13,78) (14,32) ~~ ~~ (17,11) (37,97) ~~ Element found: 97 Element not found
C语言数据结构与算法 - 堆
概述
堆表示一种特殊的基于树的数据结构,用于表示优先队列或用于堆排序。我们将专门讨论二叉堆树。
二叉堆树可以分为具有两个约束的二叉树:
完整性 − 二叉堆树是一个完整的二叉树,除了最后一层可能并非所有元素都存在,但元素应该从左到右填充。
堆特性 − 所有父节点都应该大于或小于其子节点。如果父节点大于其子节点,则称为最大堆,否则称为最小堆。最大堆用于堆排序,最小堆用于优先队列。我们正在考虑最小堆,并将使用数组实现。
基本操作
以下是最小堆的基本主要操作:
插入 − 在堆中插入元素。
获取最小值 − 从堆中获取最小元素。
移除最小值 − 从堆中移除最小元素
插入操作
每当要插入元素时,将元素插入数组的末尾。将堆的大小增加 1。
当堆属性被破坏时,向上调整元素。将元素与其父节点的值进行比较,如果需要则交换它们。
void insert(int value) {
size++;
intArray[size - 1] = value;
heapUp(size - 1);
}
void heapUp(int nodeIndex){
int parentIndex, tmp;
if (nodeIndex != 0) {
parentIndex = getParentIndex(nodeIndex);
if (intArray[parentIndex] > intArray[nodeIndex]) {
tmp = intArray[parentIndex];
intArray[parentIndex] = intArray[nodeIndex];
intArray[nodeIndex] = tmp;
heapUp(parentIndex);
}
}
}
获取最小值
获取实现堆的数组的第一个元素作为根。
int getMinimum(){
return intArray[0];
}
移除最小值
每当要移除元素时,获取数组的最后一个元素并将堆的大小减少 1。
当堆属性被破坏时,向下调整元素。将元素与其子节点的值进行比较,如果需要则交换它们。
void removeMin() {
intArray[0] = intArray[size - 1];
size--;
if (size > 0)
heapDown(0);
}
void heapDown(int nodeIndex){
int leftChildIndex, rightChildIndex, minIndex, tmp;
leftChildIndex = getLeftChildIndex(nodeIndex);
rightChildIndex = getRightChildIndex(nodeIndex);
if (rightChildIndex >= size) {
if (leftChildIndex >= size)
return;
else
minIndex = leftChildIndex;
} else {
if (intArray[leftChildIndex] <= intArray[rightChildIndex])
minIndex = leftChildIndex;
else
minIndex = rightChildIndex;
}
if (intArray[nodeIndex] > intArray[minIndex]) {
tmp = intArray[minIndex];
intArray[minIndex] = intArray[nodeIndex];
intArray[nodeIndex] = tmp;
heapDown(minIndex);
}
}
示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
int intArray[10];
int size;
bool isEmpty(){
return size == 0;
}
int getMinimum(){
return intArray[0];
}
int getLeftChildIndex(int nodeIndex){
return 2*nodeIndex +1;
}
int getRightChildIndex(int nodeIndex){
return 2*nodeIndex +2;
}
int getParentIndex(int nodeIndex){
return (nodeIndex -1)/2;
}
bool isFull(){
return size == 10;
}
/**
* Heap up the new element,until heap property is broken.
* Steps:
* 1. Compare node's value with parent's value.
* 2. Swap them, If they are in wrong order.
* */
void heapUp(int nodeIndex){
int parentIndex, tmp;
if (nodeIndex != 0) {
parentIndex = getParentIndex(nodeIndex);
if (intArray[parentIndex] > intArray[nodeIndex]) {
tmp = intArray[parentIndex];
intArray[parentIndex] = intArray[nodeIndex];
intArray[nodeIndex] = tmp;
heapUp(parentIndex);
}
}
}
/**
* Heap down the root element being least in value,until heap property is broken.
* Steps:
* 1.If current node has no children, done.
* 2.If current node has one children and heap property is broken,
* 3.Swap the current node and child node and heap down.
* 4.If current node has one children and heap property is broken, find smaller one
* 5.Swap the current node and child node and heap down.
* */
void heapDown(int nodeIndex){
int leftChildIndex, rightChildIndex, minIndex, tmp;
leftChildIndex = getLeftChildIndex(nodeIndex);
rightChildIndex = getRightChildIndex(nodeIndex);
if (rightChildIndex >= size) {
if (leftChildIndex >= size)
return;
else
minIndex = leftChildIndex;
} else {
if (intArray[leftChildIndex] <= intArray[rightChildIndex])
minIndex = leftChildIndex;
else
minIndex = rightChildIndex;
}
if (intArray[nodeIndex] > intArray[minIndex]) {
tmp = intArray[minIndex];
intArray[minIndex] = intArray[nodeIndex];
intArray[nodeIndex] = tmp;
heapDown(minIndex);
}
}
void insert(int value) {
size++;
intArray[size - 1] = value;
heapUp(size - 1);
}
void removeMin() {
intArray[0] = intArray[size - 1];
size--;
if (size > 0)
heapDown(0);
}
main() {
/* 5 //Level 0
*
*/
insert(5);
/* 1 //Level 0
* |
* 5---| //Level 1
*/
insert(1);
/* 1 //Level 0
* |
* 5---|---3 //Level 1
*/
insert(3);
/* 1 //Level 0
* |
* 5---|---3 //Level 1
* |
* 8--| //Level 2
*/
insert(8);
/* 1 //Level 0
* |
* 5---|---3 //Level 1
* |
* 8--|--9 //Level 2
*/
insert(9);
/* 1 //Level 0
* |
* 5---|---3 //Level 1
* | |
* 8--|--9 6--| //Level 2
*/
insert(6);
/* 1 //Level 0
* |
* 5---|---2 //Level 1
* | |
* 8--|--9 6--|--3 //Level 2
*/
insert(2);
printf("%d", getMinimum());
removeMin();
/* 2 //Level 0
* |
* 5---|---3 //Level 1
* | |
* 8--|--9 6--| //Level 2
*/
printf("\n%d", getMinimum());
}
如果我们编译并运行上述程序,则它将产生以下结果:
1 2
C语言数据结构与算法 - 图
概述
图是一种数据结构,用于模拟数学图。它由一组称为顶点的边的连接对组成。我们可以使用顶点数组和二维边数组来表示图。
重要术语
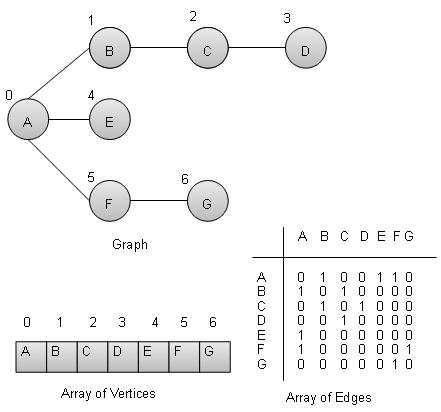
顶点 − 图的每个节点都表示为一个顶点。在下面的示例中,标记的圆圈表示顶点。因此 A 到 G 是顶点。我们可以使用数组来表示它们,如下面的图像所示。这里 A 可以用索引 0 标识。B 可以用索引 1 标识,依此类推。
边 − 边表示两个顶点之间的路径或两点之间的线。在下面的示例中,从 A 到 B、B 到 C 等等的线表示边。我们可以使用二维数组来表示数组,如下面的图像所示。这里 AB 可以用第 0 行第 1 列的 1 表示,BC 可以用第 1 行第 2 列的 1 表示,依此类推,其他组合保持为 0。
邻接 − 如果两个节点或顶点通过一条边相互连接,则它们是邻接的。在下面的示例中,B 与 A 邻接,C 与 B 邻接,依此类推。
路径 − 路径表示两个顶点之间的一系列边。在下面的示例中,ABCD 表示从 A 到 D 的路径。
基本操作
以下是图的基本主要操作:
添加顶点 − 向图中添加一个顶点。
添加边 − 在图的两个顶点之间添加一条边。
显示顶点 − 显示图中的一个顶点。
添加顶点操作
//add vertex to the vertex list
void addVertex(char label){
struct vertex* vertex =
(struct vertex*) malloc(sizeof(struct vertex));
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
添加边操作
//add edge to edge array
void addEdge(int start,int end){
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
显示边操作
//display the vertex
void displayVertex(int vertexIndex){
printf("%c ",lstVertices[vertexIndex]->label);
}
遍历算法
以下是图中重要的遍历算法。
深度优先搜索 − 深度优先遍历图。
广度优先搜索 − 广度优先遍历图。
深度优先搜索算法
深度优先搜索算法 (DFS) 以深度优先的方式遍历图,并使用堆栈来记住当任何迭代中出现死胡同时要开始搜索的下一个顶点。
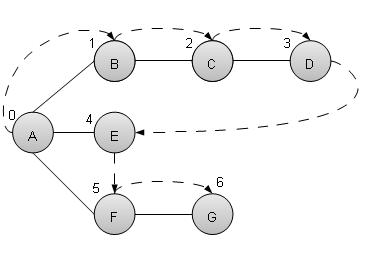
如上例所示,DFS 算法首先从 A 遍历到 B、C、D,然后到 E,然后到 F,最后到 G。它采用以下规则。
规则 1 − 访问相邻的未访问顶点。标记为已访问。显示它。将其压入堆栈。
规则 2 − 如果找不到相邻顶点,则从堆栈中弹出顶点。(它将弹出堆栈中所有没有相邻顶点的顶点。)
规则 3 − 重复规则 1 和规则 2,直到堆栈为空。
void depthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while(!isStackEmpty()){
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if(unvisitedVertex == -1){
pop();
} else {
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for(i=0;i < vertexCount;i++){
lstVertices[i]->visited = false;
}
}
广度优先搜索算法
广度优先搜索算法 (BFS) 以广度优先的方式遍历图,并使用队列来记住当任何迭代中出现死胡同时要开始搜索的下一个顶点。
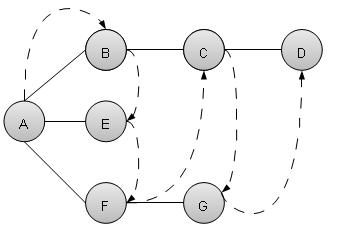
如上例所示,BFS 算法首先从 A 遍历到 B、E、F,然后到 C 和 G,最后到 D。它采用以下规则。
规则 1 − 访问相邻的未访问顶点。标记为已访问。显示它。将其插入队列。
规则 2 − 如果找不到相邻顶点,则从队列中移除第一个顶点。
规则 3 − 重复规则 1 和规则 2,直到队列为空。
void breadthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//insert vertex index in queue
insert(0);
int unvisitedVertex;
while(!isQueueEmpty()){
//get the unvisited vertex of vertex which is at front of the queue
int tempVertex = removeData();
//no adjacent vertex found
while((unvisitedVertex=getAdjUnvisitedVertex(tempVertex)) != -1){
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
insert(unvisitedVertex);
}
}
//queue is empty, search is complete, reset the visited flag
for(i=0;i<vertexCount;i++){
lstVertices[i]->visited = false;
}
}
示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 10
struct Vertex {
char label;
bool visited;
};
//stack variables
int stack[MAX];
int top=-1;
//queue variables
int queue[MAX];
int rear=-1;
int front=0;
int queueItemCount = 0;
//graph variables
//array of vertices
struct Vertex* lstVertices[MAX];
//adjacency matrix
int adjMatrix[MAX][MAX];
//vertex count
int vertexCount = 0;
//stack functions
void push(int item) {
stack[++top]=item;
}
int pop() {
return stack[top--];
}
int peek() {
return stack[top];
}
bool isStackEmpty(){
return top == -1;
}
//queue functions
void insert(int data){
queue[++rear] = data;
queueItemCount++;
}
int removeData(){
queueItemCount--;
return queue[front++];
}
bool isQueueEmpty(){
return queueItemCount == 0;
}
//graph functions
//add vertex to the vertex list
void addVertex(char label){
struct Vertex* vertex = (struct Vertex*) malloc(sizeof(struct Vertex));
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
//add edge to edge array
void addEdge(int start,int end){
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
//display the vertex
void displayVertex(int vertexIndex){
printf("%c ",lstVertices[vertexIndex]->label);
}
//get the adjacent unvisited vertex
int getAdjUnvisitedVertex(int vertexIndex){
int i;
for(i=0; i<vertexCount; i++)
if(adjMatrix[vertexIndex][i]==1 && lstVertices[i]->visited==false)
return i;
return -1;
}
void depthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while(!isStackEmpty()){
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if(unvisitedVertex == -1){
pop();
} else {
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for(i=0;i < vertexCount;i++){
lstVertices[i]->visited = false;
}
}
void breadthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//insert vertex index in queue
insert(0);
int unvisitedVertex;
while(!isQueueEmpty()){
//get the unvisited vertex of vertex which is at front of the queue
int tempVertex = removeData();
//no adjacent vertex found
while((unvisitedVertex=getAdjUnvisitedVertex(tempVertex)) != -1){
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
insert(unvisitedVertex);
}
}
//queue is empty, search is complete, reset the visited flag
for(i=0;i<vertexCount;i++){
lstVertices[i]->visited = false;
}
}
main() {
int i, j;
for(i=0; i<MAX; i++) // set adjacency
for(j=0; j<MAX; j++) // matrix to 0
adjMatrix[i][j] = 0;
addVertex('A'); //0
addVertex('B'); //1
addVertex('C'); //2
addVertex('D'); //3
addVertex('E'); //4
addVertex('F'); //5
addVertex('G'); //6
/* 1 2 3
* 0 |--B--C--D
* A--|
* |
* | 4
* |-----E
* | 5 6
* | |--F--G
* |--|
*/
addEdge(0, 1); //AB
addEdge(1, 2); //BC
addEdge(2, 3); //CD
addEdge(0, 4); //AC
addEdge(0, 5); //AF
addEdge(5, 6); //FG
printf("Depth First Search: ");
//A B C D E F G
depthFirstSearch();
printf("\nBreadth First Search: ");
//A B E F C G D
breadthFirstSearch();
}
如果我们编译并运行上述程序,则它将产生以下结果:
Depth First Search: A B C D E F G Breadth First Search: A B E F C G D
使用 C 语言的 DSA - 搜索技术
搜索是指在项目集合中查找具有指定属性的所需元素。我们将使用以下常用且简单的搜索算法开始我们的讨论。
| 序号 | 技术和描述 |
|---|---|
| 1 |
线性搜索搜索所有项目,其最坏执行时间为 n,其中 n 是项目数。 |
| 2 |
二分搜索要求项目按排序顺序排列,但其最坏执行时间是常数,并且比线性搜索快得多。 |
| 3 |
插值搜索要求项目按排序顺序排列,但其最坏执行时间为 O(n),其中 n 是项目数,并且它比线性搜索快得多。 |
使用 C 语言的 DSA - 排序技术
概述
排序是指以特定格式排列数据。排序算法指定以特定顺序排列数据的方式。最常见的顺序是数字顺序或字典顺序。
排序的重要性在于,如果数据以排序方式存储,则可以将数据搜索优化到非常高的水平。排序还用于以更易读的格式表示数据。现实生活中排序的一些示例如下。
电话簿 − 电话簿按姓名对人的电话号码进行排序。以便可以搜索姓名。
字典 − 字典按字母顺序排列单词,以便任何单词的搜索都变得容易。
排序类型
以下是流行的排序算法及其比较列表。
| 序号 | 技术和描述 |
|---|---|
| 1 |
冒泡排序易于理解和实现,但性能非常差。 |
| 2 |
选择排序顾名思义,使用选择所需项目并相应准备排序数组的技术。 |
| 3 |
插入排序是选择排序的一种变体。 |
| 4 |
希尔排序是插入排序的有效版本。 |
| 5 |
快速排序是一种高效的排序算法。 |
C语言数据结构与算法 - 递归
概述
递归是指编程语言中一种函数调用自身的技术。调用自身的函数称为递归方法。
特性
递归函数必须具有以下两个特征。
基本情况
一组规则,通过减少情况来导致基本情况。
递归阶乘
阶乘是递归的经典示例之一。阶乘是一个满足以下条件的非负数。
0! = 1
1! = 1
n! = n * (n-1)!
阶乘用“!”表示。这里规则 1 和规则 2 是基本情况,规则 3 是阶乘规则。
例如,3! = 3 x 2 x 1 = 6
int factorial(int n){
//base case
if(n == 0){
return 1;
} else {
return n * factorial(n-1);
}
}
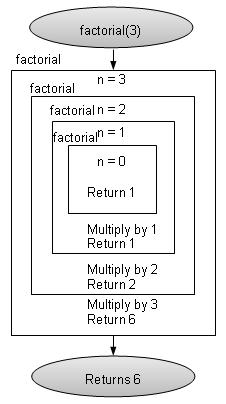
递归斐波那契数列
斐波那契数列是递归的另一个经典示例。斐波那契数列是一系列满足以下条件的整数。
F0 = 0
F1 = 1
Fn = Fn-1 + Fn-2
斐波那契数列用“F”表示。这里规则 1 和规则 2 是基本情况,规则 3 是斐波那契规则。
例如,F5 = 0 1 1 2 3
示例
#include <stdio.h>
int factorial(int n){
//base case
if(n == 0){
return 1;
} else {
return n * factorial(n-1);
}
}
int fibbonacci(int n){
if(n ==0){
return 0;
}
else if(n==1){
return 1;
} else {
return (fibbonacci(n-1) + fibbonacci(n-2));
}
}
main(){
int n = 5;
int i;
printf("Factorial of %d: %d\n" , n , factorial(n));
printf("Fibbonacci of %d: " , n);
for(i=0;i<n;i++){
printf("%d ",fibbonacci(i));
}
}
输出
如果我们编译并运行上述程序,它将产生以下输出:
Factorial of 5: 120 Fibbonacci of 5: 0 1 1 2 3