Go 快速指南
Go - 概述
Go 是一种通用编程语言,其设计理念侧重于系统编程。它最初由 Robert Griesemer、Rob Pike 和 Ken Thompson 于 2007 年在 Google 开发。它是一种强类型静态语言,提供内置的垃圾回收支持,并支持并发编程。
程序使用包构建,以便有效管理依赖项。Go 编程实现使用传统的编译和链接模型来生成可执行二进制文件。Go 编程语言于 2009 年 11 月发布,并用于 Google 的一些生产系统中。
Go 编程语言的特性
Go 编程语言最重要的特性如下:
支持类似于动态语言的环境采用模式。例如,类型推断(x := 0 是 int 类型变量 x 的有效声明)
编译速度快。
内置并发支持:轻量级进程(通过 go 协程)、通道、select 语句。
Go 程序简单、简洁且安全。
支持接口和类型嵌入。
生成无需外部依赖的静态链接本地二进制文件。
故意排除的特性
为了保持语言的简单和简洁,Go 中省略了其他类似语言中常见的以下特性:
不支持类型继承
不支持方法或运算符重载
不支持包之间的循环依赖
不支持指针运算
不支持断言
不支持泛型编程
Go 程序
Go 程序的长度可以从 3 行到数百万行不等,它应该写入一个或多个扩展名为“.go”的文本文件中。例如,hello.go。
您可以使用“vi”、“vim”或任何其他文本编辑器将 Go 程序写入文件。
Go - 环境设置
本地环境设置
如果您仍然希望为 Go 编程语言设置您的环境,则需要您的计算机上有以下两个软件:
- 文本编辑器
- Go 编译器
文本编辑器
您需要一个文本编辑器来键入您的程序。文本编辑器的示例包括 Windows 记事本、OS Edit 命令、Brief、Epsilon、EMACS 以及 vim 或 vi。
文本编辑器的名称和版本在不同的操作系统上可能有所不同。例如,Notepad 用于 Windows,而 vim 或 vi 用于 Windows 以及 Linux 或 UNIX。
您使用文本编辑器创建的文件称为源文件。它们包含程序源代码。Go 程序的源文件通常以扩展名“.go”命名。
在开始编程之前,请确保您已准备好文本编辑器,并且您有足够的经验来编写计算机程序,将其保存到文件中,编译它,最后执行它。
Go 编译器
源文件中编写的源代码是程序的人类可读源代码。它需要被编译并转换成机器语言,以便您的 CPU 能够根据给定的指令实际执行程序。Go 编程语言编译器将源代码编译成最终的可执行程序。
Go 发行版作为 FreeBSD(8 版及以上)、Linux、Mac OS X(Snow Leopard 及以上)和 Windows 操作系统的二进制可安装文件提供,这些操作系统具有 32 位 (386) 和 64 位 (amd64) x86 处理器架构。
下一节将说明如何在各种操作系统上安装 Go 二进制发行版。
下载 Go 存档
从Go 下载下载最新版本的 Go 可安装存档文件。本教程中使用以下版本:go1.4.windows-amd64.msi。
它被复制到 C:\>go 文件夹中。
| 操作系统 | 存档名称 |
|---|---|
| Windows | go1.4.windows-amd64.msi |
| Linux | go1.4.linux-amd64.tar.gz |
| Mac | go1.4.darwin-amd64-osx10.8.pkg |
| FreeBSD | go1.4.freebsd-amd64.tar.gz |
在 UNIX/Linux/Mac OS X 和 FreeBSD 上安装
将下载的存档解压缩到 /usr/local 文件夹中,在 /usr/local/go 中创建一个 Go 树。例如:
tar -C /usr/local -xzf go1.4.linux-amd64.tar.gz
将 /usr/local/go/bin 添加到 PATH 环境变量。
| 操作系统 | 输出 |
|---|---|
| Linux | export PATH = $PATH:/usr/local/go/bin |
| Mac | export PATH = $PATH:/usr/local/go/bin |
| FreeBSD | export PATH = $PATH:/usr/local/go/bin |
在 Windows 上安装
使用 MSI 文件并按照提示安装 Go 工具。默认情况下,安装程序在 c:\Go 中使用 Go 发行版。安装程序应在 Window 的 PATH 环境变量中设置 c:\Go\bin 目录。重新启动任何打开的命令提示符以使更改生效。
验证安装
在C:\>Go_WorkSpace中创建一个名为 test.go 的 go 文件。
文件:test.go
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
现在运行 test.go 以查看结果:
C:\Go_WorkSpace>go run test.go
输出
Hello, World!
Go - 程序结构
在我们学习 Go 编程语言的基本构建块之前,让我们首先讨论 Go 程序的最低限度结构,以便我们可以在后续章节中将其作为参考。
Hello World 示例
Go 程序基本上包含以下部分:
- 包声明
- 导入包
- 函数
- 变量
- 语句和表达式
- 注释
让我们来看一个简单的代码,它将打印“Hello World”字样:
package main
import "fmt"
func main() {
/* This is my first sample program. */
fmt.Println("Hello, World!")
}
让我们看一下上述程序的各个部分:
程序的第一行 package main 定义了该程序应该所在的包名称。这是一个强制性语句,因为 Go 程序在包中运行。main 包是运行程序的起点。每个包都有与其关联的路径和名称。
下一行 import "fmt" 是一个预处理器命令,它告诉 Go 编译器包含位于 fmt 包中的文件。
下一行 func main() 是程序执行开始的 main 函数。
下一行 /*...*/ 被编译器忽略,它用于在程序中添加注释。注释也使用 // 表示,类似于 Java 或 C++ 注释。
下一行 fmt.Println(...) 是 Go 中的另一个函数,它导致消息“Hello, World!”显示在屏幕上。这里 fmt 包导出了 Println 方法,用于在屏幕上显示消息。
注意 Println 方法的大写 P。在 Go 语言中,如果名称以大写字母开头,则该名称会被导出。导出意味着函数或变量/常量可供相应包的导入者访问。
执行 Go 程序
让我们讨论如何将源代码保存到文件中,编译它,最后执行程序。请按照以下步骤操作:
打开文本编辑器并添加上述代码。
将文件保存为 hello.go
打开命令提示符。
转到保存文件的目录。
键入 go run hello.go 并按 Enter 键运行您的代码。
如果您的代码中没有错误,则您将在屏幕上看到打印的 “Hello World!”。
$ go run hello.go Hello, World!
确保 Go 编译器位于您的路径中,并且您在包含源文件 hello.go 的目录中运行它。
Go - 基本语法
我们在上一章讨论了 Go 程序的基本结构。现在,理解 Go 编程语言的其他基本构建块将变得更容易。
Go 中的标记
Go 程序由各种标记组成。标记要么是关键字、标识符、常量、字符串文字或符号。例如,以下 Go 语句包含六个标记:
fmt.Println("Hello, World!")
各个标记是:
fmt . Println ( "Hello, World!" )
换行符
在 Go 程序中,换行符键是语句终止符。也就是说,单个语句不需要像 C 中那样的特殊分隔符“;”。Go 编译器在内部放置“;”作为语句终止符,以指示一个逻辑实体的结束。
例如,看一下以下语句:
fmt.Println("Hello, World!")
fmt.Println("I am in Go Programming World!")
注释
注释就像 Go 程序中的帮助文本,它们会被编译器忽略。它们以 /* 开头,以 */ 结尾,如下所示:
/* my first program in Go */
您不能在注释中嵌套注释,它们不会出现在字符串或字符文字中。
标识符
Go 标识符是用于标识变量、函数或任何其他用户定义项的名称。标识符以字母 A 到 Z 或 a 到 z 或下划线 _ 开头,后跟零个或多个字母、下划线和数字 (0 到 9)。
标识符 = 字母 { 字母 | unicode_数字 }。
Go 不允许在标识符中使用标点符号,例如 @、$ 和 %。Go 是一种区分大小写的编程语言。因此,Manpower 和 manpower 在 Go 中是两个不同的标识符。以下是一些可接受的标识符示例:
mahesh kumar abc move_name a_123 myname50 _temp j a23b9 retVal
关键字
以下列表显示了 Go 中的保留字。这些保留字不能用作常量或变量或任何其他标识符名称。
| break | default | func | interface | select |
| case | defer | Go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
Go 中的空白字符
在 Go 语言中,空白符指的是空格、制表符、换行符和注释。仅包含空白符(可能还有注释)的行被称为空行,Go 编译器会完全忽略它。
空白符用于分隔语句的不同部分,使编译器能够识别语句中一个元素(例如 int)的结束位置和下一个元素的开始位置。
var age int;
因此,在下面的语句中:
fruit = apples + oranges; // get the total fruit
必须在 int 和 age 之间至少有一个空白符(通常是空格),以便编译器能够区分它们。另一方面,在下面的语句中:
Go - 数据类型
fruit 和 = 之间,以及 = 和 apples 之间不需要空白符,尽管为了可读性,您可以随意添加一些空白符。
在 Go 编程语言中,数据类型指的是一个广泛的系统,用于声明不同类型的变量或函数。变量的类型决定了它在存储中占据的空间大小以及如何解释存储的位模式。
| Go 中的类型可以分类如下: | 序号 |
|---|---|
| 1 | 类型和描述 布尔类型 |
| 2 | 它们是布尔类型,包含两个预定义的常量:(a)true (b)false 数值类型 |
| 3 | 它们也是算术类型,表示程序中的(a)整数类型或(b)浮点数。 字符串类型 |
| 4 | 字符串类型表示字符串值的集合。它的值是一系列字节。字符串是不可变类型,一旦创建,就不能更改字符串的内容。预声明的字符串类型是 string。 派生类型 |
它们包括:(a)指针类型,(b)数组类型,(c)结构体类型,(d)联合类型,(e)函数类型,(f)切片类型,(g)接口类型,(h)映射类型,(i)通道类型
数组类型和结构体类型统称为**聚合类型**。函数的类型指定了具有相同参数和结果类型的所有函数的集合。我们将在下一节讨论基本类型,其他类型将在后续章节中介绍。
整数类型
| Go 中的类型可以分类如下: | 序号 |
|---|---|
| 1 | 预定义的与体系结构无关的整数类型如下: uint8 |
| 2 | 无符号 8 位整数(0 到 255) uint16 |
| 3 | 无符号 16 位整数(0 到 65535) uint32 |
| 4 | 无符号 32 位整数(0 到 4294967295) uint64 |
| 5 | 无符号 64 位整数(0 到 18446744073709551615) int8 |
| 6 | 有符号 8 位整数(-128 到 127) int16 |
| 7 | 有符号 16 位整数(-32768 到 32767) int32 |
| 8 | 有符号 32 位整数(-2147483648 到 2147483647) int64 |
有符号 64 位整数(-9223372036854775808 到 9223372036854775807)
浮点类型
| Go 中的类型可以分类如下: | 序号 |
|---|---|
| 1 | 预定义的与体系结构无关的浮点类型如下: float32 |
| 2 | IEEE-754 32 位浮点数 float64 |
| 3 | IEEE-754 64 位浮点数 complex64 |
| 4 | 实部和虚部为 float32 的复数 complex128 |
实部和虚部为 float64 的复数
n 位整数的值为 n 位,并使用二进制补码算术运算表示。
其他数值类型
| Go 中的类型可以分类如下: | 序号 |
|---|---|
| 1 | 还有一组大小取决于实现的数值类型: byte |
| 2 | 与 uint8 相同 rune |
| 3 | 与 int32 相同 uint |
| 4 | 32 位或 64 位 int |
| 5 | 与 uint 大小相同 uintptr |
Go - 变量
无符号整数,用于存储指针值的未解释位
变量只不过是程序可以操作的存储区域的名称。Go 中的每个变量都有一个特定类型,该类型决定变量内存的大小和布局、存储在该内存中的值的范围以及可以应用于变量的操作集。
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 序号 |
|---|---|
| 1 |
还有一组大小取决于实现的数值类型: 类型和描述 |
| 2 |
32 位或 64 位 通常是一个单字节(一个字节)。这是一个字节类型。 |
| 3 | 预定义的与体系结构无关的浮点类型如下: 机器最自然的整数大小。 |
单精度浮点数。
Go 编程语言还允许定义各种其他类型的变量,例如枚举、指针、数组、结构体和联合体,我们将在后续章节中讨论这些变量。在本节中,我们将只关注基本变量类型。
Go 中的变量定义
var variable_list optional_data_type;
变量定义告诉编译器在哪里以及为变量创建多少存储空间。变量定义指定数据类型,并包含该类型的一个或多个变量列表,如下所示:
var i, j, k int; var c, ch byte; var f, salary float32; d = 42;
这里,**optional_data_type** 是一个有效的 Go 数据类型,包括 byte、int、float32、complex64、boolean 或任何用户定义的对象等,而 **variable_list** 可以包含一个或多个用逗号分隔的标识符名称。这里显示了一些有效的声明:
语句 **“var i, j, k;”** 声明并定义了变量 i、j 和 k;它指示编译器创建名为 i、j 和 k 的 int 类型变量。
variable_name = value;
可以在变量声明中初始化(赋值初始值)变量。变量的类型由编译器根据传递给它的值自动判断。初始化程序由一个等号后跟一个常量表达式组成,如下所示:
d = 3, f = 5; // declaration of d and f. Here d and f are int
例如:
对于没有初始化程序的定义:具有静态存储期限的变量隐式初始化为 nil(所有字节的值均为 0);所有其他变量的初始值都是其数据类型的零值。
Go 中的静态类型声明
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
示例
package main
import "fmt"
func main() {
var x float64
x = 20.0
fmt.Println(x)
fmt.Printf("x is of type %T\n", x)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
20 x is of type float64
编译并执行上述代码后,将产生以下结果:
Go 中的动态类型声明/类型推断
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
动态类型变量声明要求编译器根据传递给它的值来解释变量的类型。编译器不需要变量作为必要要求静态地具有类型。
package main
import "fmt"
func main() {
var x float64 = 20.0
y := 42
fmt.Println(x)
fmt.Println(y)
fmt.Printf("x is of type %T\n", x)
fmt.Printf("y is of type %T\n", y)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
20 42 x is of type float64 y is of type int
尝试以下示例,其中变量未声明任何类型。请注意,在类型推断的情况下,我们使用 := 运算符初始化变量 **y**,而使用 = 运算符初始化 **x**。
Go 中的混合变量声明
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
package main
import "fmt"
func main() {
var a, b, c = 3, 4, "foo"
fmt.Println(a)
fmt.Println(b)
fmt.Println(c)
fmt.Printf("a is of type %T\n", a)
fmt.Printf("b is of type %T\n", b)
fmt.Printf("c is of type %T\n", c)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
3 4 foo a is of type int b is of type int c is of type string
可以使用类型推断在一行中声明不同类型的变量。
Go 中的左值和右值
Go 中有两种表达式:
**左值** - 指向内存位置的表达式称为“左值”表达式。左值可以出现在赋值的左侧或右侧。
**右值** - 右值指的是存储在内存某个地址处的数据值。右值是一个不能为其赋值的表达式,这意味着右值可以出现在赋值的右侧,但不能出现在左侧。
变量是左值,因此可以出现在赋值的左侧。数字文字是右值,因此不能赋值,不能出现在左侧。
x = 20.0
以下语句有效:
10 = 20
Go - 常量
以下语句无效。它将生成编译时错误:
常量是指程序在其执行期间可能不会更改的固定值。这些固定值也称为**字面量**。
常量可以是任何基本数据类型,例如 _整数常量、浮点常量、字符常量或字符串文字_。还有枚举常量。
常量与常规变量的处理方式相同,只是它们的 值在其定义后不能修改。
整数文字
整数文字可以是十进制、八进制或十六进制常量。前缀指定基数或基:十六进制为 0x 或 0X,八进制为 0,十进制为无。
整数文字也可以有一个后缀,该后缀是 U 和 L 的组合,分别表示无符号和长整型。后缀可以是大写或小写,并且可以按任意顺序排列。
212 /* Legal */ 215u /* Legal */ 0xFeeL /* Legal */ 078 /* Illegal: 8 is not an octal digit */ 032UU /* Illegal: cannot repeat a suffix */
以下是一些整数文字示例:
85 /* decimal */ 0213 /* octal */ 0x4b /* hexadecimal */ 30 /* int */ 30u /* unsigned int */ 30l /* long */ 30ul /* unsigned long */
以下是各种类型整数文字的其他示例:
浮点文字
浮点文字具有整数部分、小数点、小数部分和指数部分。您可以使用十进制形式或指数形式表示浮点文字。
使用十进制形式表示时,必须包含小数点、指数或两者兼而有之;使用指数形式表示时,必须包含整数部分、小数部分或两者兼而有之。带符号的指数由 e 或 E 引入。
3.14159 /* Legal */ 314159E-5L /* Legal */ 510E /* Illegal: incomplete exponent */ 210f /* Illegal: no decimal or exponent */ .e55 /* Illegal: missing integer or fraction */
以下是一些浮点文字示例:
转义序列
| 当某些字符前面带有反斜杠时,它们在 Go 中将具有特殊含义。这些被称为转义序列代码,用于表示换行符(\n)、制表符(\t)、退格符等。这里列出了一些这样的转义序列代码: | 转义序列 |
|---|---|
| \\ | 含义 |
| \' | \ 字符 |
| \" | ' 字符 |
| \? | " 字符 |
| ? 字符 | \a |
| 警报或铃声 | \b |
| 退格 | \f |
| 换页 | \n |
| 换行 | \r |
| 回车 | \t |
| 水平制表符 | \v |
| 垂直制表符 | \ooo |
| 一位到三位八进制数 | \xhh . . . |
一位或多位十六进制数
package main
import "fmt"
func main() {
fmt.Printf("Hello\tWorld!")
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Hello World!
以下示例显示如何在程序中使用 **\t**:
Go 中的字符串文字
字符串文字或常量用双引号 "" 括起来。字符串包含类似于字符文字的字符:普通字符、转义序列和通用字符。
您可以使用字符串文字将长行分成多行,并使用空格将它们分隔开。
"hello, dear" "hello, \ dear" "hello, " "d" "ear"
以下是一些字符串文字示例。所有三种形式都是相同的字符串。
const 关键字
const variable type = value;
您可以使用 **const** 前缀声明具有特定类型的常量,如下所示:
package main
import "fmt"
func main() {
const LENGTH int = 10
const WIDTH int = 5
var area int
area = LENGTH * WIDTH
fmt.Printf("value of area : %d", area)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
value of area : 50
注意,使用大写字母定义常量是良好的编程习惯。
Go - 运算符
运算符是一个符号,它告诉编译器执行特定的数学或逻辑运算。Go语言富含内置运算符,并提供以下类型的运算符:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其他运算符
本教程将逐一解释算术、关系、逻辑、位、赋值和其他运算符。
算术运算符
下表显示了Go语言支持的所有算术运算符。假设变量A为10,变量B为20,则:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| + | 将两个操作数相加 | A + B 结果为 30 |
| - | 从第一个操作数中减去第二个操作数 | A - B 结果为 -10 |
| * | 将两个操作数相乘 | A * B 结果为 200 |
| / | 将分子除以分母。 | B / A 结果为 2 |
| % | 模运算符;给出整数除法后的余数。 | B % A 结果为 0 |
| ++ | 自增运算符。它将整数值增加一。 | A++ 结果为 11 |
| -- | 自减运算符。它将整数值减少一。 | A-- 结果为 9 |
关系运算符
下表列出了Go语言支持的所有关系运算符。假设变量A为10,变量B为20,则:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| == | 检查两个操作数的值是否相等;如果相等,则条件为真。 | (A == B) 为假。 |
| != | 检查两个操作数的值是否相等;如果不相等,则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值;如果大于,则条件为真。 | (A > B) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值;如果小于,则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值;如果大于或等于,则条件为真。 | (A >= B) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值;如果小于或等于,则条件为真。 | (A <= B) 为真。 |
逻辑运算符
下表列出了Go语言支持的所有逻辑运算符。假设变量A为1,变量B为0,则:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数均非零,则条件为真。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中任何一个非零,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。用于反转其操作数的逻辑状态。如果条件为真,则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
下表显示了Go语言支持的所有逻辑运算符。假设变量A为真,变量B为假,则:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都为假,则条件为假。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中任何一个是真,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。用于反转其操作数的逻辑状态。如果条件为真,则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
位运算符
位运算符作用于位并执行逐位运算。&,| 和 ^ 的真值表如下:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假设 A = 60;和 B = 13。以二进制格式,它们将如下所示:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
下表列出了C语言支持的位运算符。假设变量A为60,变量B为13,则:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| & | 二进制与运算符:如果位同时存在于两个操作数中,则将其复制到结果中。 | (A & B) 将得到 12,即 0000 1100 |
| | | 二进制或运算符:如果位存在于任何一个操作数中,则将其复制。 | (A | B) 将得到 61,即 0011 1101 |
| ^ | 二进制异或运算符:如果位在一个操作数中设置,但在另一个操作数中未设置,则将其复制。 | (A ^ B) 将得到 49,即 0011 0001 |
| << | 二进制左移运算符。左操作数的值向左移动由右操作数指定的位数。 | A << 2 将得到 240,即 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动由右操作数指定的位数。 | A >> 2 将得到 15,即 0000 1111 |
赋值运算符
下表列出了Go语言支持的所有赋值运算符:
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| = | 简单的赋值运算符,将右侧操作数的值赋给左侧操作数 | C = A + B 将 A + B 的值赋给 C |
| += | 加法赋值运算符,它将右操作数加到左操作数上并将结果赋给左操作数 | C += A 等价于 C = C + A |
| -= | 减法赋值运算符,它从左操作数中减去右操作数并将结果赋给左操作数 | C -= A 等价于 C = C - A |
| *= | 乘法赋值运算符,它将右操作数与左操作数相乘并将结果赋给左操作数 | C *= A 等价于 C = C * A |
| /= | 除法赋值运算符,它将左操作数除以右操作数并将结果赋给左操作数 | C /= A 等价于 C = C / A |
| %= | 模赋值运算符,它使用两个操作数取模并将结果赋给左操作数 | C %= A 等价于 C = C % A |
| <<= | 左移赋值运算符 | C <<= 2 与 C = C << 2 相同 |
| >>= | 右移赋值运算符 | C >>= 2 与 C = C >> 2 相同 |
| &= | 按位与赋值运算符 | C &= 2 与 C = C & 2 相同 |
| ^= | 按位异或赋值运算符 | C ^= 2 与 C = C ^ 2 相同 |
| |= | 按位或赋值运算符 | C |= 2 与 C = C | 2 相同 |
其他运算符
Go语言还支持一些其他重要的运算符,包括sizeof和?:。
| 运算符 | 描述 | 静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。 |
|---|---|---|
| & | 返回变量的地址。 | &a; 提供变量的实际地址。 |
| * | 指向变量的指针。 | *a; 提供指向变量的指针。 |
Go语言中的运算符优先级
运算符优先级决定了表达式中项的组合方式。这会影响表达式的计算方式。某些运算符的优先级高于其他运算符;例如,乘法运算符的优先级高于加法运算符。
例如 x = 7 + 3 * 2; 这里,x 被赋值为 13,而不是 20,因为运算符 * 的优先级高于 +,所以它首先计算 3*2,然后加到 7 中。
这里,优先级最高的运算符出现在表的上方,优先级最低的出现在下方。在表达式中,将首先计算优先级较高的运算符。
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ - - | 从左到右 |
| 一元 | + - ! ~ ++ -- (type)* & sizeof | 从右到左 |
| 乘法 | * / % | 从左到右 |
| 加法 | + - | 从左到右 |
| 移位 | << >> | 从左到右 |
| 关系 | < <= > >= | 从左到右 |
| 相等 | == != | 从左到右 |
| 按位与 | & | 从左到右 |
| 按位异或 | ^ | 从左到右 |
| 按位或 | | | 从左到右 |
| 逻辑与 | && | 从左到右 |
| 逻辑或 | || | 从左到右 |
| 赋值 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号 | , | 从左到右 |
Go - 决策
决策结构要求程序员指定一个或多个要由程序评估或测试的条件,以及如果确定条件为真则要执行的语句(或语句组),以及可选的,如果确定条件为假则要执行的其他语句。
以下是大多数编程语言中常见的决策结构的一般形式:
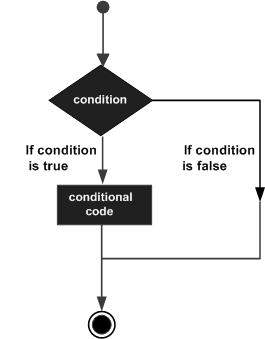
Go编程语言提供以下类型的决策语句。点击以下链接查看详细信息。
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 语句及描述 |
|---|---|
| 1 |
if语句
一个if语句由一个布尔表达式和一个或多个语句组成。 |
| 2 | if...else语句
一个if语句可以跟一个可选的else语句,当布尔表达式为假时执行。 |
| 3 |
嵌套if语句
你可以在另一个if或else if语句中使用一个if或else if语句。 |
| 4 |
switch语句
一个switch语句允许测试一个变量是否与一个值列表相等。 |
| 5 |
select语句
一个select语句类似于switch语句,不同之处在于case语句指的是通道通信。 |
Go - 循环
可能存在需要多次执行代码块的情况。一般来说,语句是顺序执行的:函数中的第一个语句首先执行,然后是第二个,依此类推。
编程语言提供了各种控制结构,允许更复杂的执行路径。
循环语句允许我们多次执行语句或语句组,以下是大多数编程语言中循环语句的一般形式:
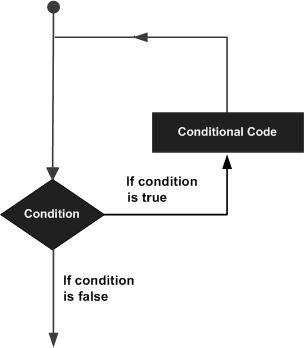
Go编程语言提供以下类型的循环来处理循环需求。
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 循环类型及描述 |
|---|---|
| 1 |
for循环
它多次执行一系列语句,并缩写管理循环变量的代码。 |
| 2 |
嵌套循环
这些是在任何for循环内部的一个或多个循环。 |
循环控制语句
循环控制语句改变执行的正常顺序。当执行离开其作用域时,在该作用域中创建的所有自动对象都将被销毁。
Go支持以下控制语句:
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 控制语句及描述 |
|---|---|
| 1 |
break语句
它终止for循环或switch语句,并将执行转移到for循环或switch语句后的语句。 |
| 2 |
continue语句
它导致循环跳过其主体的其余部分,并在重新迭代之前立即重新测试其条件。 |
| 3 |
goto语句
它将控制转移到标记的语句。 |
无限循环
如果循环的条件永远不会变为假,则循环将成为无限循环。for循环传统上用于此目的。由于构成for循环的三个表达式都不是必需的,因此您可以通过将条件表达式留空或向其传递true来创建一个无限循环。
package main
import "fmt"
func main() {
for true {
fmt.Printf("This loop will run forever.\n");
}
}
当条件表达式不存在时,它被假定为true。您可能有一个初始化和增量表达式,但是C程序员更常用for(;;)结构来表示无限循环。
注意 - 您可以通过按Ctrl + C键终止无限循环。
Go - 函数
函数是一组一起执行任务的语句。每个Go程序至少有一个函数,即main()。您可以将代码分成单独的函数。如何将代码划分到不同的函数取决于您,但从逻辑上讲,划分应该使每个函数执行特定任务。
函数**声明**告诉编译器函数名、返回类型和参数。函数**定义**提供了函数的实际主体。
Go标准库提供了许多内置函数,你的程序可以调用这些函数。例如,函数**len()**接受各种类型的参数并返回类型的长度。如果向其传递字符串,则函数返回字符串的字节长度。如果向其传递数组,则函数返回数组的长度。
函数也称为**方法、子例程**或**过程**。
定义函数
Go编程语言中函数定义的一般形式如下:
func function_name( [parameter list] ) [return_types]
{
body of the function
}
Go编程语言中的函数定义由一个函数头和一个函数体组成。以下是函数的所有部分:
**Func** − 它开始函数的声明。
**函数名** − 它是函数的实际名称。函数名和参数列表一起构成函数签名。
**参数** − 参数就像一个占位符。调用函数时,你将值传递给参数。此值称为实际参数或自变量。参数列表是指函数的参数的类型、顺序和数量。参数是可选的;也就是说,函数可能不包含任何参数。
**返回类型** − 函数可以返回多个值。`return_types`是函数返回值的数据类型的列表。有些函数执行所需的操作而不返回值。在这种情况下,`return_type`不需要。
**函数体** − 它包含定义函数功能的语句集合。
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
以下源代码显示了一个名为**max()**的函数。此函数接受两个参数 num1 和 num2,并返回两者之间的最大值:
/* function returning the max between two numbers */
func max(num1, num2 int) int {
/* local variable declaration */
result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
调用函数
创建Go函数时,你定义了函数必须执行的操作。要使用函数,你必须调用该函数来执行定义的任务。
当程序调用函数时,程序控制权将转移到被调用的函数。被调用的函数执行定义的任务,当执行其return语句或到达其函数结束的闭合大括号时,它将程序控制权返回到主程序。
要调用函数,只需传递所需的参数及其函数名即可。如果函数返回值,则可以存储返回值。例如:
package main
import "fmt"
func main() {
/* local variable definition */
var a int = 100
var b int = 200
var ret int
/* calling a function to get max value */
ret = max(a, b)
fmt.Printf( "Max value is : %d\n", ret )
}
/* function returning the max between two numbers */
func max(num1, num2 int) int {
/* local variable declaration */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
我们将 max() 函数与 main() 函数一起保留,并编译了源代码。运行最终的可执行文件时,它将产生以下结果:
Max value is : 200
从函数返回多个值
Go函数可以返回多个值。例如:
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("Mahesh", "Kumar")
fmt.Println(a, b)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Kumar Mahesh
函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的**形式参数**。
形式参数在函数内部的行为类似于其他局部变量,并在进入函数时创建,并在退出函数时销毁。
调用函数时,参数可以通过两种方式传递给函数:
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 调用类型 & 描述 |
|---|---|
| 1 |
按值调用
此方法将参数的实际值复制到函数的形式参数中。在这种情况下,对函数内部参数所做的更改不会影响参数。 |
| 2 |
按引用调用
此方法将参数的地址复制到形式参数中。在函数内部,该地址用于访问调用中使用的实际参数。这意味着对参数所做的更改会影响参数。 |
默认情况下,Go 使用按值调用传递参数。一般来说,这意味着函数内的代码无法更改用于调用函数的参数。上面的程序在调用 max() 函数时使用了相同的方法。
函数用法
函数可以按以下方式使用
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 函数用法 & 描述 |
|---|---|
| 1 |
函数作为值
可以动态创建函数,并将其用作值。 |
| 2 |
函数闭包
函数闭包是匿名函数,可用于动态编程。 |
| 3 |
方法
方法是具有接收者的特殊函数。 |
Go - 作用域规则
在任何编程中,作用域都是程序的一个区域,其中可以定义变量,并且超出该区域就不能访问该变量。在Go编程语言中,可以在三个地方声明变量:
在函数或代码块内(**局部**变量)
在所有函数之外(**全局**变量)
在函数参数定义中(**形式**参数)
让我们了解一下什么是**局部**变量和**全局**变量,以及什么是**形式**参数。
局部变量
在函数或代码块内声明的变量称为局部变量。只有函数或代码块内的语句才能使用它们。局部变量对于函数外部的函数是未知的。以下示例使用局部变量。这里所有变量 a、b 和 c 对 main() 函数都是局部的。
package main
import "fmt"
func main() {
/* local variable declaration */
var a, b, c int
/* actual initialization */
a = 10
b = 20
c = a + b
fmt.Printf ("value of a = %d, b = %d and c = %d\n", a, b, c)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
value of a = 10, b = 20 and c = 30
全局变量
全局变量在函数外部定义,通常位于程序顶部。全局变量在程序的整个生命周期中保持其值,并且可以在为程序定义的任何函数内部访问它们。
任何函数都可以访问全局变量。也就是说,全局变量在其声明后即可在整个程序中使用。以下示例使用全局变量和局部变量:
package main
import "fmt"
/* global variable declaration */
var g int
func main() {
/* local variable declaration */
var a, b int
/* actual initialization */
a = 10
b = 20
g = a + b
fmt.Printf("value of a = %d, b = %d and g = %d\n", a, b, g)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
value of a = 10, b = 20 and g = 30
程序可以为局部变量和全局变量使用相同的名称,但函数内部局部变量的值优先。例如:
package main
import "fmt"
/* global variable declaration */
var g int = 20
func main() {
/* local variable declaration */
var g int = 10
fmt.Printf ("value of g = %d\n", g)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
value of g = 10
形式参数
形式参数在该函数内被视为局部变量,并且它们优先于全局变量。例如:
package main
import "fmt"
/* global variable declaration */
var a int = 20;
func main() {
/* local variable declaration in main function */
var a int = 10
var b int = 20
var c int = 0
fmt.Printf("value of a in main() = %d\n", a);
c = sum( a, b);
fmt.Printf("value of c in main() = %d\n", c);
}
/* function to add two integers */
func sum(a, b int) int {
fmt.Printf("value of a in sum() = %d\n", a);
fmt.Printf("value of b in sum() = %d\n", b);
return a + b;
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
value of a in main() = 10 value of a in sum() = 10 value of b in sum() = 20 value of c in main() = 30
初始化局部变量和全局变量
局部变量和全局变量初始化为其默认值 0;而指针初始化为 nil。
| 数据类型 | 初始默认值 |
|---|---|
| 32 位或 64 位 | 0 |
| 预定义的与体系结构无关的浮点类型如下: | 0 |
| 指针 | nil |
Go - 字符串
字符串在 Go 编程中被广泛使用,是只读的字节切片。在 Go 编程语言中,字符串是**切片**。Go 平台提供了各种用于操作字符串的库。
- unicode
- regexp
- strings
创建字符串
创建字符串最直接的方法是编写:
var greeting = "Hello world!"
每当编译器在你的代码中遇到字符串字面量时,它都会创建一个字符串对象,其值为在这种情况下为“Hello world!”。
字符串字面量包含称为 rune 的有效 UTF-8 序列。字符串包含任意字节。
package main
import "fmt"
func main() {
var greeting = "Hello world!"
fmt.Printf("normal string: ")
fmt.Printf("%s", greeting)
fmt.Printf("\n")
fmt.Printf("hex bytes: ")
for i := 0; i < len(greeting); i++ {
fmt.Printf("%x ", greeting[i])
}
fmt.Printf("\n")
const sampleText = "\xbd\xb2\x3d\xbc\x20\xe2\x8c\x98"
/*q flag escapes unprintable characters, with + flag it escapses non-ascii
characters as well to make output unambigous
*/
fmt.Printf("quoted string: ")
fmt.Printf("%+q", sampleText)
fmt.Printf("\n")
}
这将产生以下结果:
normal string: Hello world! hex bytes: 48 65 6c 6c 6f 20 77 6f 72 6c 64 21 quoted string: "\xbd\xb2=\xbc \u2318"
**注意** − 字符串字面量是不可变的,因此一旦创建,就不能更改字符串字面量。
字符串长度
len(str) 方法返回字符串字面量中包含的字节数。
package main
import "fmt"
func main() {
var greeting = "Hello world!"
fmt.Printf("String Length is: ")
fmt.Println(len(greeting))
}
这将产生以下结果:
String Length is : 12
连接字符串
strings 包包含一个用于连接多个字符串的**join**方法:
strings.Join(sample, " ")
Join 将数组的元素连接起来以创建一个单个字符串。第二个参数是分隔符,它放在数组的元素之间。
让我们看下面的例子:
package main
import ("fmt" "math" )"fmt" "strings")
func main() {
greetings := []string{"Hello","world!"}
fmt.Println(strings.Join(greetings, " "))
}
这将产生以下结果:
Hello world!
Go - 数组
Go 编程语言提供了一种称为**数组**的数据结构,它可以存储大小固定的相同类型元素的顺序集合。数组用于存储数据集合,但通常将数组视为相同类型的变量集合更有用。
无需声明单个变量,例如 number0、number1……和 number99,你声明一个数组变量,例如 numbers,并使用 numbers[0]、numbers[1]……和 numbers[99] 来表示单个变量。数组中的特定元素通过索引访问。
所有数组都由连续的内存位置组成。最低地址对应于第一个元素,最高地址对应于最后一个元素。

声明数组
要在 Go 中声明数组,程序员应指定元素的类型和数组所需的元素数量,如下所示:
var variable_name [SIZE] variable_type
这称为一维数组。**arraySize**必须是一个大于零的整数常量,而**type**可以是任何有效的 Go 数据类型。例如,要声明一个名为**balance**的 10 个元素的 float32 类型数组,请使用以下语句:
var balance [10] float32
这里,**balance**是一个变量数组,最多可以容纳 10 个浮点数。
初始化数组
你可以使用以下方法在 Go 中逐个初始化数组或使用单个语句:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
大括号 {} 中的值的数量不能大于我们在方括号 [] 中为数组声明的元素数量。
如果省略数组的大小,则会创建一个足够大的数组来容纳初始化。因此,如果你编写:
var balance = []float32{1000.0, 2.0, 3.4, 7.0, 50.0}
你将创建与在前面示例中创建的完全相同的数组。以下是如何分配数组单个元素的示例:
balance[4] = 50.0
上述语句将数组中第 5 个元素赋值为 50.0。所有数组的第一个元素的索引均为 0,也称为基索引,数组的最后一个索引将为数组的总大小减 1。以下是我们上面讨论的相同数组的图形表示:

访问数组元素
通过索引数组名称来访问元素。这是通过在数组名称后方括号中放置元素的索引来完成的。例如:
float32 salary = balance[9]
上述语句将从数组中获取第 10 个元素并将该值赋给 salary 变量。以下示例将使用所有上述三个概念,即声明、赋值和访问数组:
package main
import "fmt"
func main() {
var n [10]int /* n is an array of 10 integers */
var i,j int
/* initialize elements of array n to 0 */
for i = 0; i < 10; i++ {
n[i] = i + 100 /* set element at location i to i + 100 */
}
/* output each array element's value */
for j = 0; j < 10; j++ {
fmt.Printf("Element[%d] = %d\n", j, n[j] )
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Element[0] = 100 Element[1] = 101 Element[2] = 102 Element[3] = 103 Element[4] = 104 Element[5] = 105 Element[6] = 106 Element[7] = 107 Element[8] = 108 Element[9] = 109
Go 数组详解
与数组相关的重要的概念,Go 程序员应该清楚:
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 概念 & 描述 |
|---|---|
| 1 |
多维数组
Go 支持多维数组。多维数组最简单的形式是二维数组。 |
| 2 | 将数组传递给函数
你可以通过指定数组的名称而不指定索引来将指向数组的指针传递给函数。 |
Go - 指针
Go 中的指针很容易学习,也很有趣。一些 Go 编程任务使用指针更容易完成,而其他任务(例如按引用调用)则必须使用指针才能完成。因此,学习指针成为一名完美的 Go 程序员是必要的。
如你所知,每个变量都是一个内存位置,并且每个内存位置都有其定义的地址,可以使用 ampersand (&) 运算符访问它,该运算符表示内存中的地址。考虑以下示例,它将打印已定义变量的地址:
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("Address of a variable: %x\n", &a )
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Address of a variable: 10328000
所以你了解了什么是内存地址以及如何访问它。现在让我们看看什么是指针。
什么是指针?
指针是一个变量,其值是另一个变量的地址,即内存位置的直接地址。与任何变量或常量一样,您必须在使用指针存储任何变量地址之前声明它。指针变量声明的一般形式如下:
var var_name *var-type
这里,type是指针的基本类型;它必须是有效的C数据类型,而var-name是指针变量的名称。用于声明指针的星号 * 与用于乘法的星号相同。但是,在此语句中,星号用于将变量指定为指针。以下是有效的指针声明:
var ip *int /* pointer to an integer */ var fp *float32 /* pointer to a float */
所有指针的实际数据类型,无论是整数、浮点数还是其他类型,都是相同的,一个代表内存地址的长十六进制数。不同数据类型指针之间的唯一区别在于指针指向的变量或常量的类型。
如何使用指针?
我们经常对指针执行一些重要的操作:(a) 定义指针变量,(b) 将变量的地址赋给指针,以及 (c) 访问指针变量中存储的地址处的值。
所有这些操作都是使用一元运算符 * 执行的,它返回位于其操作数指定的地址处的变量的值。下面的例子演示了如何执行这些操作:
package main
import "fmt"
func main() {
var a int = 20 /* actual variable declaration */
var ip *int /* pointer variable declaration */
ip = &a /* store address of a in pointer variable*/
fmt.Printf("Address of a variable: %x\n", &a )
/* address stored in pointer variable */
fmt.Printf("Address stored in ip variable: %x\n", ip )
/* access the value using the pointer */
fmt.Printf("Value of *ip variable: %d\n", *ip )
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Address of var variable: 10328000 Address stored in ip variable: 10328000 Value of *ip variable: 20
Go语言中的空指针
如果您没有确切的地址要赋值,Go编译器会将空值赋给指针变量。这是在变量声明时完成的。赋值为 nil 的指针称为空指针。
空指针是一个常量,其值为零,在几个标准库中定义。考虑以下程序:
package main
import "fmt"
func main() {
var ptr *int
fmt.Printf("The value of ptr is : %x\n", ptr )
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
The value of ptr is 0
在大多数操作系统中,程序不允许访问地址为 0 的内存,因为该内存由操作系统保留。但是,内存地址 0 具有特殊的意义;它表示指针并非意图指向可访问的内存位置。但是按照约定,如果指针包含 nil(零)值,则假定它不指向任何内容。
您可以使用 if 语句检查空指针,如下所示:
if(ptr != nil) /* succeeds if p is not nil */ if(ptr == nil) /* succeeds if p is null */
Go 指针详解
指针有很多但容易理解的概念,它们对 Go 编程非常重要。Go 程序员应该清楚指针的以下概念:
| 变量名可以由字母、数字和下划线组成。它必须以字母或下划线开头。大小写字母是不同的,因为 Go 区分大小写。基于上一章解释的基本类型,将存在以下基本变量类型: | 概念 & 描述 |
|---|---|
| 1 |
Go - 指针数组
您可以定义数组来保存多个指针。 |
| 2 |
Go - 指向指针的指针
Go允许您拥有指向指针的指针,以此类推。 |
| 3 |
在 Go 中将指针传递给函数
通过引用或通过地址传递参数都可以使被调用函数在调用函数中更改传递的参数。 |
Go - 结构体
Go 数组允许您定义可以保存多个相同类型数据项的变量。结构体是 Go 编程中另一种用户定义的数据类型,它允许您组合不同类型的数据项。
结构体用于表示记录。假设您要跟踪图书馆中的书籍。您可能想要跟踪每本书的以下属性:
- 标题
- 作者
- 主题
- 图书 ID
在这种情况下,结构体非常有用。
定义结构体
要定义结构体,必须使用type和struct语句。struct 语句定义了一种新的数据类型,其中包含程序的多个成员。type 语句将名称与类型绑定,在本例中类型为 struct。struct 语句的格式如下:
type struct_variable_type struct {
member definition;
member definition;
...
member definition;
}
定义结构体类型后,可以使用以下语法声明该类型的变量。
variable_name := structure_variable_type {value1, value2...valuen}
访问结构体成员
要访问结构体的任何成员,我们使用成员访问运算符 (.)。成员访问运算符被编码为结构体变量名称和我们想要访问的结构体成员之间的句点。您将使用struct关键字定义结构体类型的变量。下面的例子解释了如何使用结构体:
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* Declare Book1 of type Book */
var Book2 Books /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "Go Programming"
Book1.author = "Mahesh Kumar"
Book1.subject = "Go Programming Tutorial"
Book1.book_id = 6495407
/* book 2 specification */
Book2.title = "Telecom Billing"
Book2.author = "Zara Ali"
Book2.subject = "Telecom Billing Tutorial"
Book2.book_id = 6495700
/* print Book1 info */
fmt.Printf( "Book 1 title : %s\n", Book1.title)
fmt.Printf( "Book 1 author : %s\n", Book1.author)
fmt.Printf( "Book 1 subject : %s\n", Book1.subject)
fmt.Printf( "Book 1 book_id : %d\n", Book1.book_id)
/* print Book2 info */
fmt.Printf( "Book 2 title : %s\n", Book2.title)
fmt.Printf( "Book 2 author : %s\n", Book2.author)
fmt.Printf( "Book 2 subject : %s\n", Book2.subject)
fmt.Printf( "Book 2 book_id : %d\n", Book2.book_id)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Book 1 title : Go Programming Book 1 author : Mahesh Kumar Book 1 subject : Go Programming Tutorial Book 1 book_id : 6495407 Book 2 title : Telecom Billing Book 2 author : Zara Ali Book 2 subject : Telecom Billing Tutorial Book 2 book_id : 6495700
结构体作为函数参数
您可以像传递任何其他变量或指针一样传递结构体作为函数参数。您将像在上面的例子中一样访问结构体变量:
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* Declare Book1 of type Book */
var Book2 Books /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "Go Programming"
Book1.author = "Mahesh Kumar"
Book1.subject = "Go Programming Tutorial"
Book1.book_id = 6495407
/* book 2 specification */
Book2.title = "Telecom Billing"
Book2.author = "Zara Ali"
Book2.subject = "Telecom Billing Tutorial"
Book2.book_id = 6495700
/* print Book1 info */
printBook(Book1)
/* print Book2 info */
printBook(Book2)
}
func printBook( book Books ) {
fmt.Printf( "Book title : %s\n", book.title);
fmt.Printf( "Book author : %s\n", book.author);
fmt.Printf( "Book subject : %s\n", book.subject);
fmt.Printf( "Book book_id : %d\n", book.book_id);
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Book title : Go Programming Book author : Mahesh Kumar Book subject : Go Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700
指向结构体的指针
您可以像定义指向任何其他变量的指针一样定义指向结构体的指针,如下所示:
var struct_pointer *Books
现在,您可以将结构体变量的地址存储在上面定义的指针变量中。要查找结构体变量的地址,请在结构体名称前加上 & 运算符,如下所示:
struct_pointer = &Book1;
要使用指向该结构体的指针访问结构体的成员,必须使用 "." 运算符,如下所示:
struct_pointer.title;
让我们使用结构体指针重写上面的例子:
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* Declare Book1 of type Book */
var Book2 Books /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "Go Programming"
Book1.author = "Mahesh Kumar"
Book1.subject = "Go Programming Tutorial"
Book1.book_id = 6495407
/* book 2 specification */
Book2.title = "Telecom Billing"
Book2.author = "Zara Ali"
Book2.subject = "Telecom Billing Tutorial"
Book2.book_id = 6495700
/* print Book1 info */
printBook(&Book1)
/* print Book2 info */
printBook(&Book2)
}
func printBook( book *Books ) {
fmt.Printf( "Book title : %s\n", book.title);
fmt.Printf( "Book author : %s\n", book.author);
fmt.Printf( "Book subject : %s\n", book.subject);
fmt.Printf( "Book book_id : %d\n", book.book_id);
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Book title : Go Programming Book author : Mahesh Kumar Book subject : Go Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700
Go - 切片
Go 切片是对 Go 数组的抽象。Go 数组允许您定义可以保存多个相同类型数据项的变量,但它没有提供任何内置方法来动态增加其大小或获取其自身的子数组。切片克服了这个限制。它提供了数组上所需的许多实用函数,并且广泛用于 Go 编程。
定义切片
要定义切片,您可以声明它为数组而不指定其大小。或者,您可以使用make函数创建切片。
var numbers []int /* a slice of unspecified size */
/* numbers == []int{0,0,0,0,0}*/
numbers = make([]int,5,5) /* a slice of length 5 and capacity 5*/
len() 和 cap() 函数
切片是对数组的抽象。它实际上使用数组作为底层结构。len()函数返回切片中存在的元素,而cap()函数返回切片的容量(即它可以容纳多少个元素)。下面的例子解释了切片的使用:
package main
import "fmt"
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
len = 3 cap = 5 slice = [0 0 0]
空切片
如果切片声明时没有输入,则默认情况下将其初始化为空。其长度和容量为零。例如:
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
if(numbers == nil){
fmt.Printf("slice is nil")
}
}
func printSlice(x []int){
fmt.Printf("len = %d cap = %d slice = %v\n", len(x), cap(x),x)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
len = 0 cap = 0 slice = [] slice is nil
子切片
切片允许指定下界和上界,以使用[下界:上界]获取其子切片。例如:
package main
import "fmt"
func main() {
/* create a slice */
numbers := []int{0,1,2,3,4,5,6,7,8}
printSlice(numbers)
/* print the original slice */
fmt.Println("numbers ==", numbers)
/* print the sub slice starting from index 1(included) to index 4(excluded)*/
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* missing lower bound implies 0*/
fmt.Println("numbers[:3] ==", numbers[:3])
/* missing upper bound implies len(s)*/
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int,0,5)
printSlice(numbers1)
/* print the sub slice starting from index 0(included) to index 2(excluded) */
number2 := numbers[:2]
printSlice(number2)
/* print the sub slice starting from index 2(included) to index 5(excluded) */
number3 := numbers[2:5]
printSlice(number3)
}
func printSlice(x []int){
fmt.Printf("len = %d cap = %d slice = %v\n", len(x), cap(x),x)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
len = 9 cap = 9 slice = [0 1 2 3 4 5 6 7 8] numbers == [0 1 2 3 4 5 6 7 8] numbers[1:4] == [1 2 3] numbers[:3] == [0 1 2] numbers[4:] == [4 5 6 7 8] len = 0 cap = 5 slice = [] len = 2 cap = 9 slice = [0 1] len = 3 cap = 7 slice = [2 3 4]
append() 和 copy() 函数
可以使用append()函数增加切片的容量。使用copy()函数,源切片的内容将复制到目标切片。例如:
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
/* append allows nil slice */
numbers = append(numbers, 0)
printSlice(numbers)
/* add one element to slice*/
numbers = append(numbers, 1)
printSlice(numbers)
/* add more than one element at a time*/
numbers = append(numbers, 2,3,4)
printSlice(numbers)
/* create a slice numbers1 with double the capacity of earlier slice*/
numbers1 := make([]int, len(numbers), (cap(numbers))*2)
/* copy content of numbers to numbers1 */
copy(numbers1,numbers)
printSlice(numbers1)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
len = 0 cap = 0 slice = [] len = 1 cap = 2 slice = [0] len = 2 cap = 2 slice = [0 1] len = 5 cap = 8 slice = [0 1 2 3 4] len = 5 cap = 16 slice = [0 1 2 3 4]
Go - 范围
range关键字用于for循环中迭代数组、切片、通道或映射的项。对于数组和切片,它返回项的索引作为整数。对于映射,它返回下一个键值对的键。Range 要么返回一个值,要么返回两个值。如果 range 表达式的左侧只使用一个值,则它是下表中的第一个值。
| Range 表达式 | 第一个值 | 第二个值(可选) |
|---|---|---|
| 数组或切片 a [n]E | 索引 i int | a[i] E |
| 字符串 s string 类型 | 索引 i int | rune int |
| map m map[K]V | 键 k K | 值 m[k] V |
| 通道 c chan E | 元素 e E | 无 |
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
以下段落显示了如何使用 range:
package main
import "fmt"
func main() {
/* create a slice */
numbers := []int{0,1,2,3,4,5,6,7,8}
/* print the numbers */
for i:= range numbers {
fmt.Println("Slice item",i,"is",numbers[i])
}
/* create a map*/
countryCapitalMap := map[string] string {"France":"Paris","Italy":"Rome","Japan":"Tokyo"}
/* print map using keys*/
for country := range countryCapitalMap {
fmt.Println("Capital of",country,"is",countryCapitalMap[country])
}
/* print map using key-value*/
for country,capital := range countryCapitalMap {
fmt.Println("Capital of",country,"is",capital)
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Slice item 0 is 0 Slice item 1 is 1 Slice item 2 is 2 Slice item 3 is 3 Slice item 4 is 4 Slice item 5 is 5 Slice item 6 is 6 Slice item 7 is 7 Slice item 8 is 8 Capital of France is Paris Capital of Italy is Rome Capital of Japan is Tokyo Capital of France is Paris Capital of Italy is Rome Capital of Japan is Tokyo
Go - 映射
Go 提供了另一种重要的数据类型,称为映射,它将唯一的键映射到值。键是您以后用来检索值的物件。给定一个键和一个值,您可以将值存储在 Map 对象中。存储值后,您可以使用其键检索它。
定义映射
必须使用make函数创建映射。
/* declare a variable, by default map will be nil*/ var map_variable map[key_data_type]value_data_type /* define the map as nil map can not be assigned any value*/ map_variable = make(map[key_data_type]value_data_type)
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
下面的例子说明了如何创建和使用映射:
package main
import "fmt"
func main() {
var countryCapitalMap map[string]string
/* create a map*/
countryCapitalMap = make(map[string]string)
/* insert key-value pairs in the map*/
countryCapitalMap["France"] = "Paris"
countryCapitalMap["Italy"] = "Rome"
countryCapitalMap["Japan"] = "Tokyo"
countryCapitalMap["India"] = "New Delhi"
/* print map using keys*/
for country := range countryCapitalMap {
fmt.Println("Capital of",country,"is",countryCapitalMap[country])
}
/* test if entry is present in the map or not*/
capital, ok := countryCapitalMap["United States"]
/* if ok is true, entry is present otherwise entry is absent*/
if(ok){
fmt.Println("Capital of United States is", capital)
} else {
fmt.Println("Capital of United States is not present")
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Capital of India is New Delhi Capital of France is Paris Capital of Italy is Rome Capital of Japan is Tokyo Capital of United States is not present
delete() 函数
delete() 函数用于从映射中删除条目。它需要映射和要删除的相应键。例如:
package main
import "fmt"
func main() {
/* create a map*/
countryCapitalMap := map[string] string {"France":"Paris","Italy":"Rome","Japan":"Tokyo","India":"New Delhi"}
fmt.Println("Original map")
/* print map */
for country := range countryCapitalMap {
fmt.Println("Capital of",country,"is",countryCapitalMap[country])
}
/* delete an entry */
delete(countryCapitalMap,"France");
fmt.Println("Entry for France is deleted")
fmt.Println("Updated map")
/* print map */
for country := range countryCapitalMap {
fmt.Println("Capital of",country,"is",countryCapitalMap[country])
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Original Map Capital of France is Paris Capital of Italy is Rome Capital of Japan is Tokyo Capital of India is New Delhi Entry for France is deleted Updated Map Capital of India is New Delhi Capital of Italy is Rome Capital of Japan is Tokyo
Go - 递归
递归是重复项以自相似方式的过程。同样的概念也适用于编程语言。如果程序允许在同一个函数内调用一个函数,那么它被称为递归函数调用。请看下面的例子:
func recursion() {
recursion() /* function calls itself */
}
func main() {
recursion()
}
Go 编程语言支持递归。也就是说,它允许函数调用自身。但在使用递归时,程序员需要注意定义函数的退出条件,否则它将变成无限循环。
Go 语言中递归的例子
递归函数对于解决许多数学问题非常有用,例如计算数字的阶乘、生成斐波那契数列等。
示例 1:使用 Go 语言中的递归计算阶乘
下面的例子使用递归函数计算给定数字的阶乘:
package main
import "fmt"
func factorial(i int)int {
if(i <= 1) {
return 1
}
return i * factorial(i - 1)
}
func main() {
var i int = 15
fmt.Printf("Factorial of %d is %d", i, factorial(i))
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Factorial of 15 is 1307674368000
示例 2:使用 Go 语言中的递归生成斐波那契数列
下面的例子显示了如何使用递归函数生成给定数字的斐波那契数列:
package main
import "fmt"
func fibonaci(i int) (ret int) {
if i == 0 {
return 0
}
if i == 1 {
return 1
}
return fibonaci(i-1) + fibonaci(i-2)
}
func main() {
var i int
for i = 0; i < 10; i++ {
fmt.Printf("%d ", fibonaci(i))
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
0 1 1 2 3 5 8 13 21 34
Go - 类型转换
类型转换是一种将变量从一种数据类型转换为另一种数据类型的方法。例如,如果您想将长整型值存储到简单的整型中,那么您可以将长整型类型转换为整型。您可以使用强制转换运算符将值从一种类型转换为另一种类型。其语法如下:
type_name(expression)
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
考虑下面的例子,其中强制转换运算符导致一个整型变量除以另一个整型变量的操作作为浮点数运算来执行。
package main
import "fmt"
func main() {
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
fmt.Printf("Value of mean : %f\n",mean)
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Value of mean : 3.400000
Go - 接口
Go 编程提供了一种称为接口的另一种数据类型,它表示一组方法签名。struct 数据类型实现这些接口以对接口的方法签名具有方法定义。
语法
/* define an interface */
type interface_name interface {
method_name1 [return_type]
method_name2 [return_type]
method_name3 [return_type]
...
method_namen [return_type]
}
/* define a struct */
type struct_name struct {
/* variables */
}
/* implement interface methods*/
func (struct_name_variable struct_name) method_name1() [return_type] {
/* method implementation */
}
...
func (struct_name_variable struct_name) method_namen() [return_type] {
/* method implementation */
}
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
package main
import (
"fmt"
"math"
)
/* define an interface */
type Shape interface {
area() float64
}
/* define a circle */
type Circle struct {
x,y,radius float64
}
/* define a rectangle */
type Rectangle struct {
width, height float64
}
/* define a method for circle (implementation of Shape.area())*/
func(circle Circle) area() float64 {
return math.Pi * circle.radius * circle.radius
}
/* define a method for rectangle (implementation of Shape.area())*/
func(rect Rectangle) area() float64 {
return rect.width * rect.height
}
/* define a method for shape */
func getArea(shape Shape) float64 {
return shape.area()
}
func main() {
circle := Circle{x:0,y:0,radius:5}
rectangle := Rectangle {width:10, height:5}
fmt.Printf("Circle area: %f\n",getArea(circle))
fmt.Printf("Rectangle area: %f\n",getArea(rectangle))
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Circle area: 78.539816 Rectangle area: 50.000000
Go - 错误处理
Go 编程提供了一个相当简单的错误处理框架,其中内置了以下声明的错误接口类型:
type error interface {
Error() string
}
函数通常将错误作为最后一个返回值返回。使用errors.New构造基本的错误消息,如下所示:
func Sqrt(value float64)(float64, error) {
if(value < 0){
return 0, errors.New("Math: negative number passed to Sqrt")
}
return math.Sqrt(value), nil
}
使用返回值和错误消息。
result, err:= Sqrt(-1)
if err != nil {
fmt.Println(err)
}
静态类型变量声明向编译器保证存在一个具有给定类型和名称的可用变量,以便编译器可以在不需要变量的完整详细信息的情况下继续进行进一步的编译。变量声明只在编译时才有意义,编译器在程序链接时需要实际的变量声明。
package main
import "errors"
import "fmt"
import "math"
func Sqrt(value float64)(float64, error) {
if(value < 0){
return 0, errors.New("Math: negative number passed to Sqrt")
}
return math.Sqrt(value), nil
}
func main() {
result, err:= Sqrt(-1)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(result)
}
result, err = Sqrt(9)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(result)
}
}
尝试以下示例,其中变量已在 main 函数内声明了类型并进行了初始化:
Math: negative number passed to Sqrt 3