- PostgreSQL 教程
- PostgreSQL - 首页
- PostgreSQL - 概述
- PostgreSQL - 环境设置
- PostgreSQL - 语法
- PostgreSQL - 数据类型
- PostgreSQL - 创建数据库
- PostgreSQL - 选择数据库
- PostgreSQL - 删除数据库
- PostgreSQL - 创建表
- PostgreSQL - 删除表
- PostgreSQL - 模式
- PostgreSQL - 插入查询
- PostgreSQL - 选择查询
- PostgreSQL - 运算符
- PostgreSQL - 表达式
- PostgreSQL - WHERE 子句
- PostgreSQL - AND & OR 子句
- PostgreSQL - 更新查询
- PostgreSQL - 删除查询
- PostgreSQL - LIKE 子句
- PostgreSQL - LIMIT 子句
- PostgreSQL - ORDER BY 子句
- PostgreSQL - GROUP BY
- PostgreSQL - WITH 子句
- PostgreSQL - HAVING 子句
- PostgreSQL - DISTINCT 关键字
- 高级 PostgreSQL
- PostgreSQL - 约束
- PostgreSQL - 连接
- PostgreSQL - UNION 子句
- PostgreSQL - NULL 值
- PostgreSQL - 别名语法
- PostgreSQL - 触发器
- PostgreSQL - 索引
- PostgreSQL - ALTER TABLE 命令
- TRUNCATE TABLE 命令
- PostgreSQL - 视图
- PostgreSQL - 事务
- PostgreSQL - 锁
- PostgreSQL - 子查询
- PostgreSQL - 自动递增
- PostgreSQL - 权限
- 日期/时间函数和运算符
- PostgreSQL - 函数
- PostgreSQL - 常用函数
- PostgreSQL 接口
- PostgreSQL - C/C++
- PostgreSQL - Java
- PostgreSQL - PHP
- PostgreSQL - Perl
- PostgreSQL - Python
- PostgreSQL 资源
- PostgreSQL 快速指南
- PostgreSQL - 资源
- PostgreSQL - 讨论
PostgreSQL 快速指南
PostgreSQL - 概述
PostgreSQL 是一个功能强大的开源对象关系数据库系统。它拥有超过 15 年的活跃开发阶段和久经考验的架构,因其可靠性、数据完整性和正确性而享有盛誉。
本教程将帮助您快速入门 PostgreSQL,并使您能够轻松进行 PostgreSQL 编程。
什么是 PostgreSQL?
PostgreSQL(发音为 **post-gress-Q-L**)是由全球志愿者团队开发的开源关系数据库管理系统 (DBMS)。PostgreSQL 不受任何公司或其他私人实体控制,其源代码可免费获得。
PostgreSQL 简史
PostgreSQL 最初名为 Postgres,由加州大学伯克利分校 (UCB) 的计算机科学教授 Michael Stonebraker 创建。Stonebraker 于 1986 年开始开发 Postgres,作为其前身 Ingres(现为 Computer Associates 所有)的后续项目。
**1977-1985** − 开发了一个名为 INGRES 的项目。
关系数据库的概念验证
1980 年成立 Ingres 公司
1994 年被 Computer Associates 收购
**1986-1994** − POSTGRES
在 INGRES 的概念基础上进行开发,重点关注面向对象和查询语言 - Quel
INGRES 的代码库未用作 POSTGRES 的基础
商业化为 Illustra(被 Informix 收购,后被 IBM 收购)
**1994-1995** − Postgres95
1994 年增加了对 SQL 的支持
1995 年发布为 Postgres95
1996 年重新发布为 PostgreSQL 6.0
成立 PostgreSQL 全球开发团队
PostgreSQL 的主要特性
PostgreSQL 运行在所有主要的 操作系统上,包括 Linux、UNIX(AIX、BSD、HP-UX、SGI IRIX、Mac OS X、Solaris、Tru64)和 Windows。它支持文本、图像、声音和视频,并包括用于 C/C++、Java、Perl、Python、Ruby、Tcl 和开放数据库连接 (ODBC) 的编程接口。
PostgreSQL 支持大部分 SQL 标准,并提供许多现代特性,包括以下内容:
- 复杂的 SQL 查询
- SQL 子查询
- 外键
- 触发器
- 视图
- 事务
- 多版本并发控制 (MVCC)
- 流复制(从 9.0 版本开始)
- 热备用(从 9.0 版本开始)
您可以查看 PostgreSQL 的官方文档以了解上述特性。PostgreSQL 可以通过多种方式由用户扩展。例如,通过添加新的:
- 数据类型
- 函数
- 运算符
- 聚合函数
- 索引方法
过程语言支持
PostgreSQL 支持四种标准的过程语言,允许用户使用任何一种语言编写自己的代码,并由 PostgreSQL 数据库服务器执行。这些过程语言包括 - PL/pgSQL、PL/Tcl、PL/Perl 和 PL/Python。此外,还支持其他非标准的过程语言,如 PL/PHP、PL/V8、PL/Ruby、PL/Java 等。
PostgreSQL - 环境设置
要开始理解 PostgreSQL 的基础知识,首先让我们安装 PostgreSQL。本章介绍如何在 Linux、Windows 和 Mac OS 平台上安装 PostgreSQL。
在 Linux/Unix 上安装 PostgreSQL
按照以下步骤在您的 Linux 机器上安装 PostgreSQL。在继续安装之前,请确保您已以 **root** 用户身份登录。
从 EnterpriseDB 选择您想要的 PostgreSQL 版本号和尽可能精确的平台。
我为我的 64 位 CentOS-6 机器下载了 **postgresql-9.2.4-1-linux-x64.run**。现在,让我们按如下方式执行它:
[root@host]# chmod +x postgresql-9.2.4-1-linux-x64.run [root@host]# ./postgresql-9.2.4-1-linux-x64.run ------------------------------------------------------------------------ Welcome to the PostgreSQL Setup Wizard. ------------------------------------------------------------------------ Please specify the directory where PostgreSQL will be installed. Installation Directory [/opt/PostgreSQL/9.2]:
启动安装程序后,它会询问您一些基本问题,例如安装位置、将使用数据库的用户密码、端口号等。因此,请将所有这些值保留为默认值,除了密码,您可以根据自己的选择提供密码。它将在您的 Linux 机器上安装 PostgreSQL,并显示以下消息:
Please wait while Setup installs PostgreSQL on your computer. Installing 0% ______________ 50% ______________ 100% ######################################### ----------------------------------------------------------------------- Setup has finished installing PostgreSQL on your computer.
按照以下安装后步骤创建您的数据库:
[root@host]# su - postgres Password: bash-4.1$ createdb testdb bash-4.1$ psql testdb psql (8.4.13, server 9.2.4) test=#
如果 postgres 服务器未运行,您可以使用以下命令启动/重启它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
如果您的安装正确,您将看到 PotsgreSQL 提示符 **test=#**,如上所示。
在 Windows 上安装 PostgreSQL
按照以下步骤在您的 Windows 机器上安装 PostgreSQL。安装期间请确保已关闭第三方杀毒软件。
从 EnterpriseDB 选择您想要的 PostgreSQL 版本号和尽可能精确的平台。
我为我的在 32 位模式下运行的 Windows PC 下载了 postgresql-9.2.4-1-windows.exe,因此让我们以管理员身份运行 **postgresql-9.2.4-1-windows.exe** 来安装 PostgreSQL。选择您想要安装它的位置。默认情况下,它安装在 Program Files 文件夹中。
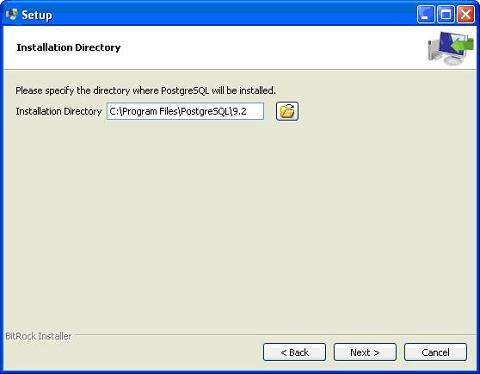
安装过程的下一步是选择存储数据的目录。默认情况下,它存储在“data”目录下。
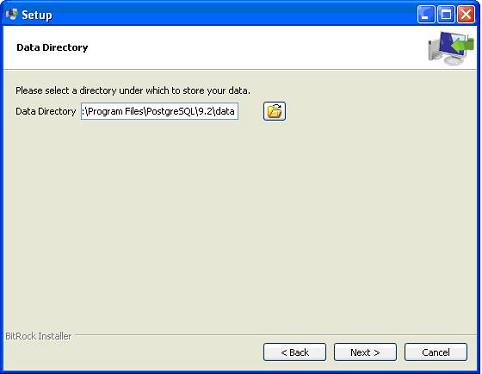
接下来,安装程序会要求输入密码,您可以使用您喜欢的密码。
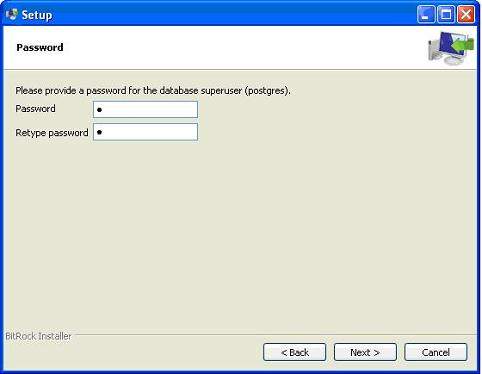
下一步;将端口保留为默认值。
在下一步中,当询问“区域设置”时,我选择了“English, United States”。
在您的系统上安装 PostgreSQL 需要一些时间。安装过程完成后,您将看到以下屏幕。取消选中复选框并单击“完成”按钮。
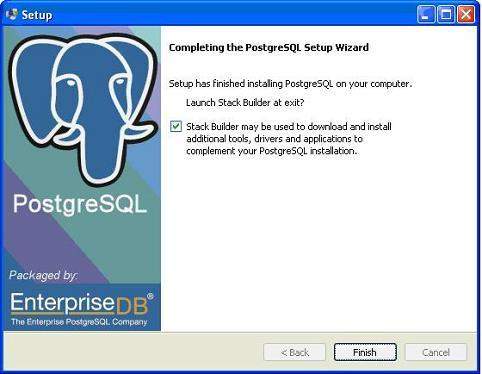
安装过程完成后,您可以从您的程序菜单下的 PostgreSQL 9.2 访问 pgAdmin III、StackBuilder 和 PostgreSQL shell。
在 Mac 上安装 PostgreSQL
按照以下步骤在您的 Mac 机器上安装 PostgreSQL。在继续安装之前,请确保您已以 **管理员** 身份登录。
从 EnterpriseDB 选择适用于 Mac OS 的最新 PostgreSQL 版本号。
我为我的运行 OS X 10.8.3 版本的 Mac OS 下载了 **postgresql-9.2.4-1-osx.dmg**。现在,让我们在访达中打开 dmg 镜像并双击它,这将在以下窗口中为您提供 PostgreSQL 安装程序:
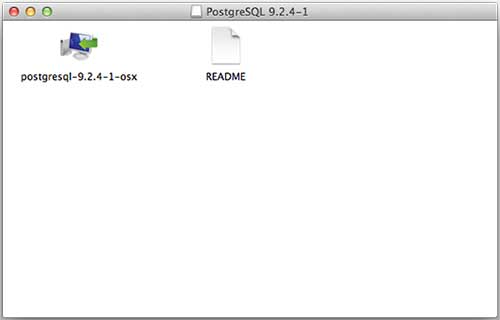
接下来,单击 **postgres-9.2.4-1-osx** 图标,这将显示一条警告消息。接受警告并继续进行安装。它将要求输入管理员密码,如下面的窗口所示:
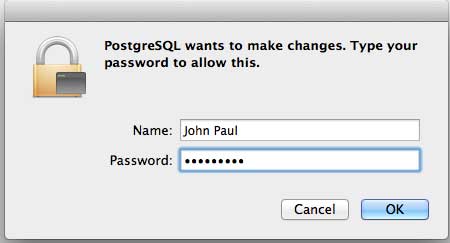
输入密码,继续安装,此步骤之后,重新启动您的 Mac 机器。如果您没有看到以下窗口,请再次启动安装。

启动安装程序后,它会询问您一些基本问题,例如安装位置、将使用数据库的用户密码、端口号等。因此,请将所有这些值保留为默认值,除了密码,您可以根据自己的选择提供密码。它将在您的 Mac 机器上的应用程序文件夹中安装 PostgreSQL,您可以检查:
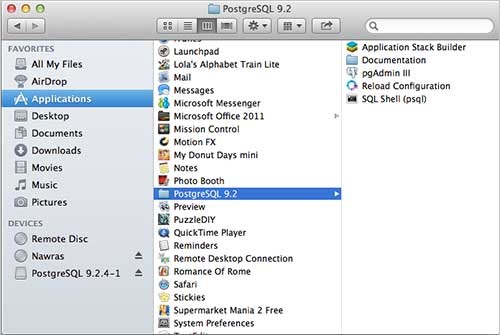
现在,您可以启动任何程序来开始使用。让我们从 SQL Shell 开始。启动 SQL Shell 时,只需使用它显示的所有默认值,除了输入您在安装时选择的密码。如果一切顺利,那么您将进入 postgres 数据库,并将显示 **postgress#** 提示符,如下所示:
恭喜!现在您的环境已准备好开始 PostgreSQL 数据库编程。
PostgreSQL - 语法
本章提供 PostgreSQL SQL 命令列表,以及每个命令的精确语法规则。这组命令取自 psql 命令行工具。现在您已经安装了 Postgres,打开 psql 如下:
Program Files → PostgreSQL 9.2 → SQL Shell(psql)。
使用 psql,您可以使用 \help 命令生成完整的命令列表。对于特定命令的语法,请使用以下命令:
postgres-# \help <command_name>
SQL 语句
SQL 语句由标记组成,每个标记可以表示关键字、标识符、带引号的标识符、常量或特殊字符符号。下表使用简单的 SELECT 语句来说明一个基本的完整 SQL 语句及其组成部分。
| SELECT | id, name | FROM | states | |
|---|---|---|---|---|
| 标记类型 | 关键字 | 标识符 | 关键字 | 标识符 |
| 描述 | 命令 | id 和 name 列 | 子句 | 表名 |
PostgreSQL SQL 命令
ABORT
中止当前事务。
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE
更改聚合函数的定义。
ALTER AGGREGATE name ( type ) RENAME TO new_name ALTER AGGREGATE name ( type ) OWNER TO new_owner
ALTER CONVERSION
更改转换的定义。
ALTER CONVERSION name RENAME TO new_name ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE
更改数据库特定参数。
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT }
ALTER DATABASE name RESET parameter
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO new_owner
ALTER DOMAIN
更改域特定参数的定义。
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT }
ALTER DOMAIN name { SET | DROP } NOT NULL
ALTER DOMAIN name ADD domain_constraint
ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION
更改函数的定义。
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP
更改用户组。
ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [, ... ] ALTER GROUP groupname RENAME TO new_name
ALTER INDEX
更改索引的定义。
ALTER INDEX name OWNER TO new_owner ALTER INDEX name SET TABLESPACE indexspace_name ALTER INDEX name RENAME TO new_name
ALTER LANGUAGE
更改过程语言的定义。
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR
更改运算符的定义。
ALTER OPERATOR name ( { lefttype | NONE }, { righttype | NONE } )
OWNER TO new_owner
ALTER OPERATOR CLASS
更改运算符类的定义。
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA
更改模式的定义。
ALTER SCHEMA name RENAME TO new_name ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE
更改序列生成器的定义。
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE
更改表的定义。
ALTER TABLE [ ONLY ] name [ * ] action [, ... ] ALTER TABLE [ ONLY ] name [ * ] RENAME [ COLUMN ] column TO new_column ALTER TABLE name RENAME TO new_name
其中 *action* 是以下行之一:
ADD [ COLUMN ] column_type [ column_constraint [ ... ] ]
DROP [ COLUMN ] column [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] column TYPE type [ USING expression ]
ALTER [ COLUMN ] column SET DEFAULT expression
ALTER [ COLUMN ] column DROP DEFAULT
ALTER [ COLUMN ] column { SET | DROP } NOT NULL
ALTER [ COLUMN ] column SET STATISTICS integer
ALTER [ COLUMN ] column SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ADD table_constraint
DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
CLUSTER ON index_name
SET WITHOUT CLUSTER
SET WITHOUT OIDS
OWNER TO new_owner
SET TABLESPACE tablespace_name
ALTER TABLESPACE
更改表空间的定义。
ALTER TABLESPACE name RENAME TO new_name ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER
更改触发器的定义。
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE
更改类型的定义。
ALTER TYPE name OWNER TO new_owner
ALTER USER
更改数据库用户帐户。
ALTER USER name [ [ WITH ] option [ ... ] ]
ALTER USER name RENAME TO new_name
ALTER USER name SET parameter { TO | = } { value | DEFAULT }
ALTER USER name RESET parameter
其中option可以是:
[ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | VALID UNTIL 'abstime'
ANALYZE
收集关于数据库的统计信息。
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
BEGIN
开始事务块。
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
其中transaction_mode 是:
ISOLATION LEVEL {
SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED
}
READ WRITE | READ ONLY
CHECKPOINT
强制事务日志检查点。
CHECKPOINT
CLOSE
关闭游标。
CLOSE name
CLUSTER
根据索引对表进行聚类。
CLUSTER index_name ON table_name CLUSTER table_name CLUSTER
COMMENT
定义或更改对象的注释。
COMMENT ON {
TABLE object_name |
COLUMN table_name.column_name |
AGGREGATE agg_name (agg_type) |
CAST (source_type AS target_type) |
CONSTRAINT constraint_name ON table_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
FUNCTION func_name (arg1_type, arg2_type, ...) |
INDEX object_name |
LARGE OBJECT large_object_oid |
OPERATOR op (left_operand_type, right_operand_type) |
OPERATOR CLASS object_name USING index_method |
[ PROCEDURAL ] LANGUAGE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
}
IS 'text'
COMMIT
提交当前事务。
COMMIT [ WORK | TRANSACTION ]
COPY
在文件和表之间复制数据。
COPY table_name [ ( column [, ...] ) ]
FROM { 'filename' | STDIN }
[ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY table_name [ ( column [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE QUOTE column [, ...] ]
CREATE AGGREGATE
定义新的聚合函数。
CREATE AGGREGATE name ( BASETYPE = input_data_type, SFUNC = sfunc, STYPE = state_data_type [, FINALFUNC = ffunc ] [, INITCOND = initial_condition ] )
CREATE CAST
定义新的转换。
CREATE CAST (source_type AS target_type) WITH FUNCTION func_name (arg_types) [ AS ASSIGNMENT | AS IMPLICIT ] CREATE CAST (source_type AS target_type) WITHOUT FUNCTION [ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CONSTRAINT TRIGGER
定义新的约束触发器。
CREATE CONSTRAINT TRIGGER name AFTER events ON table_name constraint attributes FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
CREATE CONVERSION
定义新的转换。
CREATE [DEFAULT] CONVERSION name FOR source_encoding TO dest_encoding FROM func_name
CREATE DATABASE
创建一个新的数据库。
CREATE DATABASE name [ [ WITH ] [ OWNER [=] db_owner ] [ TEMPLATE [=] template ] [ ENCODING [=] encoding ] [ TABLESPACE [=] tablespace ] ]
CREATE DOMAIN
定义新的域。
CREATE DOMAIN name [AS] data_type [ DEFAULT expression ] [ constraint [ ... ] ]
其中constraint是:
[ CONSTRAINT constraint_name ]
{ NOT NULL | NULL | CHECK (expression) }
CREATE FUNCTION
定义新的函数。
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] )
RETURNS ret_type
{ LANGUAGE lang_name
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
[ WITH ( attribute [, ...] ) ]
CREATE GROUP
定义新的用户组。
CREATE GROUP name [ [ WITH ] option [ ... ] ] Where option can be: SYSID gid | USER username [, ...]
CREATE INDEX
定义新的索引。
CREATE [ UNIQUE ] INDEX name ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [, ...] )
[ TABLESPACE tablespace ]
[ WHERE predicate ]
CREATE LANGUAGE
定义新的过程语言。
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name HANDLER call_handler [ VALIDATOR val_function ]
CREATE OPERATOR
定义新的运算符。
CREATE OPERATOR name ( PROCEDURE = func_name [, LEFTARG = left_type ] [, RIGHTARG = right_type ] [, COMMUTATOR = com_op ] [, NEGATOR = neg_op ] [, RESTRICT = res_proc ] [, JOIN = join_proc ] [, HASHES ] [, MERGES ] [, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ] [, LTCMP = less_than_op ] [, GTCMP = greater_than_op ] )
CREATE OPERATOR CLASS
定义新的运算符类。
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ]
| FUNCTION support_number func_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]
CREATE RULE
定义新的重写规则。
CREATE [ OR REPLACE ] RULE name AS ON event
TO table [ WHERE condition ]
DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
CREATE SCHEMA
定义新的模式。
CREATE SCHEMA schema_name [ AUTHORIZATION username ] [ schema_element [ ... ] ] CREATE SCHEMA AUTHORIZATION username [ schema_element [ ... ] ]
CREATE SEQUENCE
定义新的序列生成器。
CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
CREATE TABLE
定义新的表。
CREATE [ [ GLOBAL | LOCAL ] {
TEMPORARY | TEMP } ] TABLE table_name ( {
column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ]
} [, ... ]
)
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace ]
其中column_constraint是:
[ CONSTRAINT constraint_name ] {
NOT NULL |
NULL |
UNIQUE [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |
CHECK (expression) |
REFERENCES ref_table [ ( ref_column ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ]
}
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
而table_constraint是:
[ CONSTRAINT constraint_name ]
{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
CHECK ( expression ) |
FOREIGN KEY ( column_name [, ... ] )
REFERENCES ref_table [ ( ref_column [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
CREATE TABLE AS
根据查询结果定义新的表。
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name
[ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]
AS query
CREATE TABLESPACE
定义新的表空间。
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
CREATE TRIGGER
定义新的触发器。
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] }
ON table [ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE func_name ( arguments )
CREATE TYPE
定义新的数据类型。
CREATE TYPE name AS
( attribute_name data_type [, ... ] )
CREATE TYPE name (
INPUT = input_function,
OUTPUT = output_function
[, RECEIVE = receive_function ]
[, SEND = send_function ]
[, ANALYZE = analyze_function ]
[, INTERNALLENGTH = { internal_length | VARIABLE } ]
[, PASSEDBYVALUE ]
[, ALIGNMENT = alignment ]
[, STORAGE = storage ]
[, DEFAULT = default ]
[, ELEMENT = element ]
[, DELIMITER = delimiter ]
)
CREATE USER
定义新的数据库用户帐户。
CREATE USER name [ [ WITH ] option [ ... ] ]
其中option可以是:
SYSID uid | [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | IN GROUP group_name [, ...] | VALID UNTIL 'abs_time'
CREATE VIEW
定义新的视图。
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE
释放预处理语句。
DEALLOCATE [ PREPARE ] plan_name
DECLARE
定义游标。
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR query
[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
DELETE
删除表中的行。
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE
删除聚合函数。
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
DROP CAST
删除转换。
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
DROP CONVERSION
删除转换。
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE
删除数据库。
DROP DATABASE name
DROP DOMAIN
删除域。
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
DROP FUNCTION
删除函数。
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP
删除用户组。
DROP GROUP name
DROP INDEX
删除索引。
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
DROP LANGUAGE
删除过程语言。
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
DROP OPERATOR
删除运算符。
DROP OPERATOR name ( { left_type | NONE }, { right_type | NONE } )
[ CASCADE | RESTRICT ]
DROP OPERATOR CLASS
删除运算符类。
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP RULE
删除重写规则。
DROP RULE name ON relation [ CASCADE | RESTRICT ]
DROP SCHEMA
删除模式。
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE
删除序列。
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE
删除表。
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE
删除表空间。
DROP TABLESPACE tablespace_name
DROP TRIGGER
删除触发器。
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE
删除数据类型。
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER
删除数据库用户帐户。
DROP USER name
DROP VIEW
删除视图。
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
END
提交当前事务。
END [ WORK | TRANSACTION ]
EXECUTE
执行预处理语句。
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN
显示语句的执行计划。
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH
使用游标从查询中检索行。
FETCH [ direction { FROM | IN } ] cursor_name
其中direction可以为空或:
NEXT PRIOR FIRST LAST ABSOLUTE count RELATIVE count count ALL FORWARD FORWARD count FORWARD ALL BACKWARD BACKWARD count BACKWARD ALL
GRANT
定义访问权限。
GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
INSERT
在表中创建新行。
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
LISTEN
监听通知。
LISTEN name
LOAD
加载或重新加载共享库文件。
LOAD 'filename'
LOCK
锁定表。
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
其中lock_mode是:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
MOVE
定位游标。
MOVE [ direction { FROM | IN } ] cursor_name
NOTIFY
生成通知。
NOTIFY name
PREPARE
准备执行语句。
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX
重建索引。
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RELEASE SAVEPOINT
销毁先前定义的保存点。
RELEASE [ SAVEPOINT ] savepoint_name
RESET
将运行时参数的值恢复为默认值。
RESET name RESET ALL
REVOKE
删除访问权限。
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
ROLLBACK
中止当前事务。
ROLLBACK [ WORK | TRANSACTION ]
ROLLBACK TO SAVEPOINT
回滚到保存点。
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT
在当前事务中定义新的保存点。
SAVEPOINT savepoint_name
SELECT
从表或视图中检索行。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
其中from_item可以是:[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ] ( select ) [ AS ] alias [ ( column_alias [, ...] ) ] function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ] function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] ) from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
SELECT INTO
根据查询结果定义新的表。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SET
更改运行时参数。
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
SET CONSTRAINTS
设置当前事务的约束检查模式。
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
SET SESSION AUTHORIZATION
设置当前会话的会话用户标识符和当前用户标识符。
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION username SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT RESET SESSION AUTHORIZATION
SET TRANSACTION
设置当前事务的特性。
SET TRANSACTION transaction_mode [, ...] SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
其中transaction_mode 是:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
SHOW
显示运行时参数的值。
SHOW name SHOW ALL
START TRANSACTION
开始事务块。
START TRANSACTION [ transaction_mode [, ...] ]
其中transaction_mode 是:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
TRUNCATE
清空表。
TRUNCATE [ TABLE ] name
UNLISTEN
停止监听通知。
UNLISTEN { name | * }
UPDATE
更新表中的行。
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...]
[ FROM from_list ]
[ WHERE condition ]
VACUUM
垃圾回收并可选地分析数据库。
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table ] VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
PostgreSQL - 数据类型
本章将讨论PostgreSQL中使用的数据类型。创建表时,为每一列指定数据类型,即要存储在表字段中的数据类型。
这带来了诸多好处:
一致性 - 对相同数据类型的列进行的操作会产生一致的结果,并且通常速度最快。
验证 - 正确使用数据类型意味着对数据的格式进行验证,并拒绝超出数据类型范围的数据。
紧凑性 - 由于列可以存储单一类型的值,因此以紧凑的方式存储。
性能 - 正确使用数据类型可以最有效地存储数据。存储的值可以快速处理,从而提高性能。
PostgreSQL 支持广泛的数据类型。此外,用户可以使用CREATE TYPE SQL 命令创建自己的自定义数据类型。PostgreSQL 中有不同类型的数据类型类别。如下所述。
数值类型
数值类型包括两字节、四字节和八字节整数、四字节和八字节浮点数以及可选精度小数。下表列出了可用的类型。
| 名称 | 存储大小 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 | 小范围整数 | -32768 到 +32767 |
| integer | 4 字节 | 整数的典型选择 | -2147483648 到 +2147483647 |
| bigint | 8 字节 | 大范围整数 | -9223372036854775808 到 9223372036854775807 |
| decimal | 可变 | 用户指定的精度,精确 | 小数点前最多 131072 位;小数点后最多 16383 位 |
| numeric | 可变 | 用户指定的精度,精确 | 小数点前最多 131072 位;小数点后最多 16383 位 |
| real | 4 字节 | 可变精度,不精确 | 6 位小数精度 |
| double precision | 8 字节 | 可变精度,不精确 | 15 位小数精度 |
| smallserial | 2 字节 | 小的自动递增整数 | 1 到 32767 |
| serial | 4 字节 | 自动递增整数 | 1 到 2147483647 |
| bigserial | 8 字节 | 大的自动递增整数 | 1 到 9223372036854775807 |
货币类型
money类型存储具有固定小数精度的货币金额。可以将numeric、int 和 bigint数据类型的赋值转换为money。由于可能出现舍入误差,因此不建议使用浮点数处理货币。
| 名称 | 存储大小 | 描述 | 范围 |
|---|---|---|---|
| money | 8 字节 | 货币金额 | -92233720368547758.08 到 +92233720368547758.07 |
字符类型
下表列出了PostgreSQL中可用的通用字符类型。
| 序号 | 名称和描述 |
|---|---|
| 1 | character varying(n), varchar(n) 带限制的可变长度 |
| 2 | character(n), char(n) 固定长度,用空格填充 |
| 3 | text 无限可变长度 |
二进制数据类型
bytea数据类型允许像下表一样存储二进制字符串。
| 名称 | 存储大小 | 描述 |
|---|---|---|
| bytea | 1 或 4 字节加上实际的二进制字符串 | 可变长度二进制字符串 |
日期/时间类型
PostgreSQL 支持完整的 SQL 日期和时间类型集,如下表所示。日期是根据格里高利历计算的。这里,所有类型的分辨率均为1 微秒/14 位,除了date类型,其分辨率为天。
| 名称 | 存储大小 | 描述 | 最小值 | 最大值 |
|---|---|---|---|---|
| timestamp [(p)] [without time zone ] | 8 字节 | 日期和时间(无时区) | 公元前 4713 年 | 公元 294276 年 |
| TIMESTAMPTZ | 8 字节 | 日期和时间,带时区 | 公元前 4713 年 | 公元 294276 年 |
| date | 4 字节 | 日期(没有一天中的时间) | 公元前 4713 年 | 公元 5874897 年 |
| time [ (p)] [ without time zone ] | 8 字节 | 一天中的时间(无日期) | 00:00:00 | 24:00:00 |
| time [ (p)] with time zone | 12 字节 | 仅一天中的时间,带时区 | 00:00:00+1459 | 24:00:00-1459 |
| interval [fields ] [(p) ] | 12 字节 | 时间间隔 | -178000000 年 | 178000000 年 |
布尔类型
PostgreSQL 提供标准 SQL 类型布尔值。布尔数据类型可以具有true、false和第三种状态unknown,后者由 SQL 空值表示。
| 名称 | 存储大小 | 描述 |
|---|---|---|
| boolean | 1 字节 | true 或 false 状态 |
枚举类型
枚举类型是由静态、有序的值集组成的数据类型。它们等效于许多编程语言中支持的枚举类型。
与其他类型不同,枚举类型需要使用 CREATE TYPE 命令创建。此类型用于存储静态、有序的值集。例如,指南针方向,即北、南、东和西,或一周中的日子,如下所示:
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
创建后,枚举类型可以像其他任何类型一样使用。
几何类型
几何数据类型表示二维空间对象。最基本的类型(点)构成所有其他类型的基础。
| 名称 | 存储大小 | 表示 | 描述 |
|---|---|---|---|
| point | 16 字节 | 平面上的点 | (x,y) |
| line | 32 字节 | 无限线(未完全实现) | ((x1,y1),(x2,y2)) |
| 线段 | 32 字节 | 有限线段 | ((x1,y1),(x2,y2)) |
| 矩形框 | 32 字节 | 矩形框 | ((x1,y1),(x2,y2)) |
| 路径 | 16+16n 字节 | 闭合路径(类似于多边形) | ((x1,y1),...) |
| 路径 | 16+16n 字节 | 开放路径 | [(x1,y1),...] |
| 多边形 | 40+16n | 多边形(类似于闭合路径) | ((x1,y1),...) |
| 圆形 | 24 字节 | 圆形 | <(x,y),r>(中心点和半径) |
网络地址类型
PostgreSQL 提供数据类型来存储 IPv4、IPv6 和 MAC 地址。最好使用这些类型而不是纯文本类型来存储网络地址,因为这些类型提供输入错误检查和专门的操作符和函数。
| 名称 | 存储大小 | 描述 |
|---|---|---|
| cidr | 7 或 19 字节 | IPv4 和 IPv6 网络 |
| inet | 7 或 19 字节 | IPv4 和 IPv6 主机和网络 |
| macaddr | 6 字节 | MAC 地址 |
位串类型
位串类型用于存储位掩码。它们是 0 或 1。有两种 SQL 位类型:bit(n) 和 bit varying(n),其中 n 是一个正整数。
文本搜索类型
此类型支持全文搜索,即搜索自然语言文档集合以找到最匹配查询的文档的活动。为此,有两种数据类型:
| 序号 | 名称和描述 |
|---|---|
| 1 | tsvector 这是一个已排序的唯一单词列表,这些单词已规范化以合并同一单词的不同变体,称为“词素”。 |
| 2 | tsquery 这存储要搜索的词素,并结合它们来遵守布尔运算符 &(AND)、|(OR)和!(NOT)。可以使用括号来强制执行运算符的分组。 |
UUID 类型
UUID(通用唯一标识符)写为一系列小写十六进制数字,分成几组,用连字符分隔,具体来说是一组八位数字,后跟三组四位数字,然后是一组十二位数字,总共 32 位数字代表 128 位。
UUID 示例:- 550e8400-e29b-41d4-a716-446655440000
XML 类型
XML 数据类型可用于存储 XML 数据。要存储 XML 数据,首先必须使用以下函数 xmlparse 创建 XML 值:
XMLPARSE (DOCUMENT '<?xml version="1.0"?> <tutorial> <title>PostgreSQL Tutorial </title> <topics>...</topics> </tutorial>') XMLPARSE (CONTENT 'xyz<foo>bar</foo><bar>foo</bar>')
JSON 类型
json 数据类型可用于存储 JSON(JavaScript 对象表示法)数据。此类数据也可以存储为 text,但 json 数据类型具有检查每个存储值是否为有效 JSON 值的优势。还有一些相关的支持函数可用,可以直接用于处理 JSON 数据类型,如下所示。
| 示例 | 示例结果 |
|---|---|
| array_to_json('{{1,5},{99,100}}'::int[]) | [[1,5],[99,100]] |
| row_to_json(row(1,'foo')) | {"f1":1,"f2":"foo"} |
数组类型
PostgreSQL 提供了将表列定义为可变长度多维数组的机会。可以创建任何内置或用户定义的基本类型、枚举类型或复合类型的数组。
数组声明
数组类型可以声明为
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer[], scheme text[][] );
或使用关键字“ARRAY”作为
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer ARRAY[4], scheme text[][] );
插入值
数组值可以作为字面常量插入,将元素值用大括号括起来,并用逗号分隔。下面显示一个示例:
INSERT INTO monthly_savings
VALUES (‘Manisha’,
‘{20000, 14600, 23500, 13250}’,
‘{{“FD”, “MF”}, {“FD”, “Property”}}’);
访问数组
下面显示了访问数组的示例。以下命令将选择储蓄在第二季度比第四季度多的个人。
SELECT name FROM monhly_savings WHERE saving_per_quarter[2] > saving_per_quarter[4];
修改数组
修改数组的示例如下所示。
UPDATE monthly_savings SET saving_per_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Manisha';
或使用 ARRAY 表达式语法:
UPDATE monthly_savings SET saving_per_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Manisha';
搜索数组
搜索数组的示例如下所示。
SELECT * FROM monthly_savings WHERE saving_per_quarter[1] = 10000 OR saving_per_quarter[2] = 10000 OR saving_per_quarter[3] = 10000 OR saving_per_quarter[4] = 10000;
如果已知数组的大小,则可以使用上述搜索方法。否则,以下示例显示如何在大小未知时进行搜索。
SELECT * FROM monthly_savings WHERE 10000 = ANY (saving_per_quarter);
复合类型
此类型表示字段名称及其数据类型的列表,即表行或记录的结构。
复合类型的声明
以下示例显示如何声明复合类型
CREATE TYPE inventory_item AS ( name text, supplier_id integer, price numeric );
此数据类型可用于创建表,如下所示:
CREATE TABLE on_hand ( item inventory_item, count integer );
复合值输入
复合值可以作为字面常量插入,将字段值用括号括起来,并用逗号分隔。下面显示一个示例:
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
这对于上面定义的 inventory_item 有效。只要表达式中有多个字段,ROW 关键字实际上就是可选的。
访问复合类型
要访问复合列的字段,请使用句点后跟字段名称,这与从表名称中选择字段非常相似。例如,要从我们的 on_hand 示例表中选择一些子字段,查询将如下所示:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
您甚至可以使用表名(例如在多表查询中),如下所示:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
范围类型
范围类型表示使用数据范围的数据类型。范围类型可以是离散范围(例如,从 1 到 10 的所有整数值)或连续范围(例如,上午 10:00 到上午 11:00 之间的任何时间点)。
可用的内置范围类型包括以下范围:
int4range - 整数范围
int8range - bigint 范围
numrange - 数值范围
tsrange - 无时区时间戳范围
tstzrange - 有时区时间戳范围
daterange - 日期范围
可以创建自定义范围类型以使新的范围类型可用,例如使用 inet 类型作为基类的 IP 地址范围,或使用 float 数据类型作为基类的浮点范围。
范围类型分别使用 [ ] 和 ( ) 字符支持包含和排除范围边界。例如,“[4,9)”表示从 4 开始(包括 4)到 9(不包括 9)的所有整数。
对象标识符类型
对象标识符 (OID) 由 PostgreSQL 内部用作各种系统表的主键。如果指定了 WITH OIDS 或启用了 default_with_oids 配置变量,则在这种情况下,OID 将添加到用户创建的表中。下表列出了几个别名类型。OID 别名类型除了专门的输入和输出例程之外,没有自己的操作。
| 名称 | 参考文献 | 描述 | 值示例 |
|---|---|---|---|
| oid | any | 数值对象标识符 | 564182 |
| regproc | pg_proc | 函数名 | sum |
| regprocedure | pg_proc | 带有参数类型的函数 | sum(int4) |
| regoper | pg_operator | 运算符名称 | + |
| regoperator | pg_operator | 带有参数类型的运算符 | *(integer,integer) 或 -(NONE,integer) |
| regclass | pg_class | 关系名 | pg_type |
| regtype | pg_type | 数据类型名称 | integer |
| regconfig | pg_ts_config | 文本搜索配置 | English |
| regdictionary | pg_ts_dict | 文本搜索字典 | simple |
伪类型
PostgreSQL 类型系统包含许多特殊用途的条目,统称为伪类型。伪类型不能用作列数据类型,但可以用作函数的参数或结果类型。
下表列出了现有的伪类型。
| 序号 | 名称和描述 |
|---|---|
| 1 | any 指示函数接受任何输入数据类型。 |
| 2 | anyelement 指示函数接受任何数据类型。 |
| 3 | anyarray 指示函数接受任何数组数据类型。 |
| 4 | anynonarray 指示函数接受任何非数组数据类型。 |
| 5 | anyenum 指示函数接受任何枚举数据类型。 |
| 6 | anyrange 指示函数接受任何范围数据类型。 |
| 7 | cstring 指示函数接受或返回以 null 结尾的 C 字符串。 |
| 8 | internal 指示函数接受或返回服务器内部数据类型。 |
| 9 | language_handler 过程语言调用处理程序声明为返回 language_handler。 |
| 10 | fdw_handler 外部数据包装器处理程序声明为返回 fdw_handler。 |
| 11 | record 标识返回未指定行类型的函数。 |
| 12 | trigger 触发器函数声明为返回 trigger。 |
| 13 | void 指示函数不返回值。 |
PostgreSQL - 创建数据库
本章讨论如何在 PostgreSQL 中创建新的数据库。PostgreSQL 提供两种创建新数据库的方法:
- 使用 CREATE DATABASE,这是一个 SQL 命令。
- 使用 createdb,这是一个命令行可执行文件。
使用 CREATE DATABASE
此命令将在 PostgreSQL shell 提示符下创建数据库,但您应该具有创建数据库的适当权限。默认情况下,新数据库将通过克隆标准系统数据库 template1 来创建。
语法
CREATE DATABASE 语句的基本语法如下:
CREATE DATABASE dbname;
其中 dbname 是要创建的数据库的名称。
示例
以下是一个简单的示例,它将在您的 PostgreSQL 模式中创建 testdb
postgres=# CREATE DATABASE testdb; postgres-#
使用 createdb 命令
PostgreSQL 命令行可执行文件 createdb 是 SQL 命令 CREATE DATABASE 的包装器。此命令与 SQL 命令 CREATE DATABASE 之间的唯一区别在于,前者可以直接从命令行运行,并且它允许将注释添加到数据库中,所有这些都可以在一个命令中完成。
语法
createdb 的语法如下所示:
createdb [option...] [dbname [description]]
参数
下表列出了参数及其说明。
| 序号 | 参数和说明 |
|---|---|
| 1 | dbname 要创建的数据库的名称。 |
| 2 | description 指定要与新创建的数据库关联的注释。 |
| 3 | options createdb 接受的命令行参数。 |
选项
下表列出了 createdb 接受的命令行参数:
| 序号 | 选项和说明 |
|---|---|
| 1 | -D tablespace 指定数据库的默认表空间。 |
| 2 | -e 回显 createdb 生成并发送到服务器的命令。 |
| 3 | -E encoding 指定在此数据库中使用的字符编码方案。 |
| 4 | -l locale 指定在此数据库中使用的区域设置。 |
| 5 | -T template 指定用于构建此数据库的模板数据库。 |
| 6 | --help 显示关于 createdb 命令行参数的帮助信息,然后退出。 |
| 7 | -h host 指定服务器运行所在的机器的主机名。 |
| 8 | -p port 指定服务器监听连接的 TCP 端口或本地 Unix 域套接字文件扩展名。 |
| 9 | -U username 连接使用的用户名。 |
| 10 | -w 从不提示输入密码。 |
| 11 | -W 强制 createdb 在连接到数据库之前提示输入密码。 |
打开命令提示符并转到安装 PostgreSQL 的目录。转到 bin 目录并执行以下命令以创建数据库。
createdb -h localhost -p 5432 -U postgres testdb password ******
上述命令将提示您输入 PostgreSQL 管理员用户的密码,默认为 **postgres**。因此,请提供密码并继续创建您的新数据库。
使用上述任何一种方法创建数据库后,您可以使用 **\l**(即反斜杠 el 命令)在数据库列表中检查它,如下所示:
postgres-# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
PostgreSQL - 选择数据库
本章解释了访问数据库的各种方法。假设我们已在上一章中创建了一个数据库。您可以使用以下任一方法选择数据库:
- 数据库 SQL 提示符
- 操作系统命令提示符
数据库 SQL 提示符
假设您已经启动了 PostgreSQL 客户端,并且您已到达以下 SQL 提示符:
postgres=#
您可以使用 **\l**(即反斜杠 el 命令)检查可用的数据库列表,如下所示:
postgres-# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
现在,键入以下命令来连接/选择所需的数据库;这里,我们将连接到 *testdb* 数据库。
postgres=# \c testdb; psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
操作系统命令提示符
您可以在登录数据库时,直接在命令提示符处选择您的数据库。以下是一个简单的示例:
psql -h localhost -p 5432 -U postgress testdb Password for user postgress: **** psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
您现在已登录到 PostgreSQL testdb 并准备好执行 testdb 中的命令。要退出数据库,可以使用命令 \q。
PostgreSQL - 删除数据库
本章将讨论如何在 PostgreSQL 中删除数据库。删除数据库有两种方法:
- 使用 DROP DATABASE,这是一个 SQL 命令。
- 使用 *dropdb*,一个命令行可执行文件。
在使用此操作之前请务必小心,因为删除现有数据库会导致数据库中存储的完整信息丢失。
使用 DROP DATABASE
此命令删除数据库。它删除数据库的目录条目并删除包含数据的目录。只有数据库所有者才能执行此命令。当您或其他任何人连接到目标数据库时,无法执行此命令(连接到 postgres 或任何其他数据库来发出此命令)。
语法
DROP DATABASE 的语法如下:
DROP DATABASE [ IF EXISTS ] name
参数
此表列出了参数及其说明。
| 序号 | 参数和说明 |
|---|---|
| 1 | IF EXISTS 如果数据库不存在,则不抛出错误。在这种情况下会发出通知。 |
| 2 | name 要删除的数据库的名称。 |
我们无法删除有任何打开连接的数据库,包括我们自己从 *psql* 或 *pgAdmin III* 的连接。如果我们要删除当前连接的数据库,则必须切换到另一个数据库或 *template1*。因此,使用程序 *dropdb* 可能更方便,它是一个围绕此命令的包装器。
示例
以下是一个简单的示例,它将从您的 PostgreSQL 模式中删除 **testdb**:
postgres=# DROP DATABASE testdb; postgres-#
使用 dropdb 命令
PostgresSQL 命令行可执行文件 **dropdb** 是 SQL 命令 *DROP DATABASE* 的命令行包装器。通过此实用程序删除数据库与通过其他访问服务器的方法之间没有有效区别。dropdb 会销毁现有的 PostgreSQL 数据库。执行此命令的用户必须是数据库超级用户或数据库所有者。
语法
*dropdb* 的语法如下:
dropdb [option...] dbname
参数
下表列出了参数及其说明。
| 序号 | 参数和说明 |
|---|---|
| 1 | dbname 要删除的数据库的名称。 |
| 2 | option dropdb 接受的命令行参数。 |
选项
下表列出了 dropdb 接受的命令行参数:
| 序号 | 选项和说明 |
|---|---|
| 1 | -e 显示发送到服务器的命令。 |
| 2 | -i 在执行任何破坏性操作之前发出验证提示。 |
| 3 | -V 打印 dropdb 版本并退出。 |
| 4 | --if-exists 如果数据库不存在,则不抛出错误。在这种情况下会发出通知。 |
| 5 | --help 显示关于 dropdb 命令行参数的帮助信息,然后退出。 |
| 6 | -h host 指定服务器运行所在的机器的主机名。 |
| 7 | -p port 指定服务器监听连接的 TCP 端口或本地 UNIX 域套接字文件扩展名。 |
| 8 | -U username 连接使用的用户名。 |
| 9 | -w 从不提示输入密码。 |
| 10 | -W 强制 dropdb 在连接到数据库之前提示输入密码。 |
| 11 |
--maintenance-db=dbname 指定要连接到的数据库的名称,以便删除目标数据库。 |
示例
以下示例演示了从操作系统命令提示符删除数据库:
dropdb -h localhost -p 5432 -U postgress testdb Password for user postgress: ****
上述命令删除数据库 **testdb**。在这里,我使用了 **postgres**(位于 template1 的 pg_roles 下)用户名来删除数据库。
PostgreSQL - 创建表
PostgreSQL CREATE TABLE 语句用于在任何给定的数据库中创建一个新表。
语法
CREATE TABLE 语句的基本语法如下:
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
CREATE TABLE 是一个关键字,告诉数据库系统创建一个新表。表的唯一名称或标识符位于 CREATE TABLE 语句之后。最初,当前数据库中的空表由发出命令的用户拥有。
然后,在括号中,列出定义表中每一列及其数据类型的列表。下面的示例将使语法更加清晰。
示例
以下是一个示例,它创建一个 COMPANY 表,其中 ID 为主键,NOT NULL 是约束条件,表示在创建此表中的记录时这些字段不能为 NULL:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
让我们再创建一个表,我们将在后续章节的练习中使用它:
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
您可以使用 **\d** 命令验证您的表是否已成功创建,此命令将用于列出附加数据库中的所有表。
testdb-# \d
上述 PostgreSQL 语句将产生以下结果:
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
使用 **\d *tablename*** 来描述每个表,如下所示:
testdb-# \d company
上述 PostgreSQL 语句将产生以下结果:
Table "public.company"
Column | Type | Modifiers
-----------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
join_date | date |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
PostgreSQL - 删除表
PostgreSQL DROP TABLE 语句用于删除表定义以及与该表关联的所有数据、索引、规则、触发器和约束。
使用此命令时必须小心,因为一旦删除表,表中所有信息也将永远丢失。
语法
DROP TABLE 语句的基本语法如下:
DROP TABLE table_name;
示例
我们在上一章中创建了 DEPARTMENT 和 COMPANY 表。首先,验证这些表(使用 **\d** 列出表):
testdb-# \d
这将产生以下结果:
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
这意味着 DEPARTMENT 和 COMPANY 表存在。所以让我们删除它们,如下所示:
testdb=# drop table department, company;
这将产生以下结果:
DROP TABLE testdb=# \d relations found. testdb=#
返回的消息 DROP TABLE 指示删除命令已成功执行。
PostgreSQL - 模式
**模式**是表的命名集合。模式还可以包含视图、索引、序列、数据类型、运算符和函数。模式类似于操作系统级别的目录,只是模式不能嵌套。PostgreSQL 语句 CREATE SCHEMA 创建一个模式。
语法
CREATE SCHEMA 的基本语法如下:
CREATE SCHEMA name;
其中 *name* 是模式的名称。
在模式中创建表的语法
在模式中创建表的语法如下:
CREATE TABLE myschema.mytable ( ... );
示例
让我们来看一个创建模式的例子。连接到数据库 *testdb* 并创建一个模式 *myschema*,如下所示:
testdb=# create schema myschema; CREATE SCHEMA
消息“CREATE SCHEMA”表示模式已成功创建。
现在,让我们在上述模式中创建一个表,如下所示:
testdb=# create table myschema.company( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
这将创建一个空表。您可以使用以下命令验证创建的表:
testdb=# select * from myschema.company;
这将产生以下结果:
id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
删除模式的语法
要删除空模式(其中的所有对象都已删除),请使用以下命令:
DROP SCHEMA myschema;
要删除模式及其包含的所有对象,请使用以下命令:
DROP SCHEMA myschema CASCADE;
使用模式的优点
它允许许多用户使用一个数据库而不会相互干扰。
它将数据库对象组织成逻辑组,使它们更易于管理。
可以将第三方应用程序放入单独的模式中,这样它们就不会与其他对象的名称冲突。
PostgreSQL - INSERT 查询
PostgreSQL **INSERT INTO** 语句允许用户将新行插入表中。可以一次插入一行,也可以作为查询结果插入多行。
语法
INSERT INTO 语句的基本语法如下:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
这里,column1, column2,...columnN 是要向其中插入数据的表的列名。
目标列名可以按任何顺序列出。VALUES 子句或查询提供的值是从左到右与显式或隐式列列表关联的。
如果要为表的所有列添加值,则可能不需要在 SQL 查询中指定列名。但是,请确保值的顺序与表中的列顺序相同。SQL INSERT INTO 语法如下:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
输出
下表总结了输出消息及其含义:
| 序号 | 输出消息和说明 |
|---|---|
| 1 | INSERT oid 1 如果只插入一行,则返回此消息。oid 是插入行的数字 OID。 |
| 2 | INSERT 0 # 如果插入多行,则返回此消息。# 是插入的行数。 |
示例
让我们在 **testdb** 中创建 COMPANY 表,如下所示:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL, JOIN_DATE DATE );
以下示例将一行插入 COMPANY 表:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
以下示例是插入一行;这里省略了 *salary* 列,因此它将具有默认值:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,JOIN_DATE) VALUES (2, 'Allen', 25, 'Texas', '2007-12-13');
以下示例对 JOIN_DATE 列使用 DEFAULT 子句,而不是指定值:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (3, 'Teddy', 23, 'Norway', 20000.00, DEFAULT );
以下示例使用多行 VALUES 语法插入多行:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00, '2007-12-13' ), (5, 'David', 27, 'Texas', 85000.00, '2007-12-13');
所有上述语句都将在 COMPANY 表中创建以下记录。下一章将教你如何从表中显示所有这些记录。
ID NAME AGE ADDRESS SALARY JOIN_DATE ---- ---------- ----- ---------- ------- -------- 1 Paul 32 California 20000.0 2001-07-13 2 Allen 25 Texas 2007-12-13 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 2007-12-13 5 David 27 Texas 85000.0 2007-12-13
PostgreSQL - SELECT 查询
PostgreSQL **SELECT** 语句用于从数据库表中提取数据,它以结果表的形式返回数据。这些结果表称为结果集。
语法
SELECT 语句的基本语法如下:
SELECT column1, column2, columnN FROM table_name;
这里,column1, column2...是表的字段,您想提取其值。如果要提取字段中所有可用的字段,则可以使用以下语法:
SELECT * FROM table_name;
示例
考虑表 COMPANY,其记录如下:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将提取 CUSTOMERS 表中可用的客户的 ID、Name 和 Salary 字段:
testdb=# SELECT ID, NAME, SALARY FROM COMPANY ;
这将产生以下结果:
id | name | salary ----+-------+-------- 1 | Paul | 20000 2 | Allen | 15000 3 | Teddy | 20000 4 | Mark | 65000 5 | David | 85000 6 | Kim | 45000 7 | James | 10000 (7 rows)
如果要提取 CUSTOMERS 表的所有字段,则使用以下查询:
testdb=# SELECT * FROM COMPANY;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
PostgreSQL - 运算符
什么是 PostgreSQL 中的运算符?
操作符是 PostgreSQL 语句中,主要用于 WHERE 子句中执行操作(例如比较和算术运算)的保留字或字符。
操作符用于指定 PostgreSQL 语句中的条件,并作为语句中多个条件的连接词。
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
PostgreSQL 算术运算符
假设变量a的值为 2,变量b的值为 3,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 - 将运算符两侧的值相加 | a + b 的结果为 5 |
| - | 减法 - 从左操作数中减去右操作数 | a - b 的结果为 -1 |
| * | 乘法 - 将运算符两侧的值相乘 | a * b 的结果为 6 |
| / | 除法 - 将左操作数除以右操作数 | b / a 的结果为 1 |
| % | 取模 - 将左操作数除以右操作数并返回余数 | b % a 的结果为 1 |
| ^ | 指数 - 返回右操作数的指数值 | a ^ b 的结果为 8 |
| |/ | 平方根 | |/ 25.0 的结果为 5 |
| ||/ | 立方根 | ||/ 27.0 的结果为 3 |
| ! | 阶乘 | 5 ! 的结果为 120 |
| !! | 阶乘(前缀运算符) | !! 5 的结果为 120 |
PostgreSQL 比较运算符
假设变量 a 的值为 10,变量 b 的值为 20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a = b) 为假。 |
| != | 检查两个操作数的值是否不相等,如果不相等则条件为真。 | (a != b) 为真。 |
| <> | 检查两个操作数的值是否不相等,如果不相等则条件为真。 | (a <> b) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (a > b) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (a < b) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 | (a >= b) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 | (a <= b) 为真。 |
PostgreSQL 逻辑运算符
以下是 PostgreSQL 中所有可用逻辑运算符的列表。
| 序号 | 运算符和说明 |
|---|---|
| 1 | AND AND 运算符允许在 PostgreSQL 语句的 WHERE 子句中存在多个条件。 |
| 2 | NOT NOT 运算符反转与其一起使用的逻辑运算符的含义。例如 NOT EXISTS、NOT BETWEEN、NOT IN 等。这是否定运算符。 |
| 3 | OR OR 运算符用于组合 PostgreSQL 语句 WHERE 子句中的多个条件。 |
PostgreSQL 位串运算符
位运算符对位进行操作,并执行逐位运算。& 和 | 的真值表如下:
| p | q | p & q | p | q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
假设 A = 60;B = 13;现在它们的二进制格式如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
~A = 1100 0011
PostgreSQL 支持的位运算符列在下面的表中:
| 运算符 | 描述 | 示例 |
|---|---|---|
| & | 二进制 AND 运算符如果位同时存在于两个操作数中,则将其复制到结果中。 | (A & B) 的结果为 12,即 0000 1100 |
| | | 二进制 OR 运算符如果位存在于任一操作数中,则将其复制。 | (A | B) 的结果为 61,即 0011 1101 |
| ~ | 二进制反码运算符是一元运算符,其作用是“反转”位。 | (~A ) 的结果为 -61,由于是有符号二进制数,因此其二进制补码形式为 1100 0011。 |
| << | 二进制左移运算符。左操作数的值向左移动由右操作数指定的位数。 | A << 2 的结果为 240,即 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动由右操作数指定的位数。 | A >> 2 的结果为 15,即 0000 1111 |
| # | 按位异或。 | A # B 的结果为 49,即 00110001 |
PostgreSQL - 表达式
表达式是由一个或多个值、运算符和 PostgreSQL 函数组合而成,并计算出一个值的组合。
PostgreSQL 表达式类似于公式,它们是用查询语言编写的。你也可以用它来查询数据库中的特定数据集。
语法
考虑 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION | EXPRESSION];
PostgreSQL 表达式有不同类型,如下所述:
PostgreSQL - 布尔表达式
PostgreSQL 布尔表达式根据匹配单个值来获取数据。语法如下:
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHTING EXPRESSION;
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
这是一个显示 PostgreSQL 布尔表达式用法的简单示例:
testdb=# SELECT * FROM COMPANY WHERE SALARY = 10000;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+----------+-------- 7 | James | 24 | Houston | 10000 (1 row)
PostgreSQL - 数值表达式
这些表达式用于在任何查询中执行任何数学运算。语法如下:
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
这里 numerical_expression 用于数学表达式或任何公式。以下是一个显示 SQL 数值表达式用法的简单示例:
testdb=# SELECT (15 + 6) AS ADDITION ;
上述 PostgreSQL 语句将产生以下结果:
addition
----------
21
(1 row)
有一些内置函数,如 avg()、sum()、count(),用于对表或特定表列执行所谓的聚合数据计算。
testdb=# SELECT COUNT(*) AS "RECORDS" FROM COMPANY;
上述 PostgreSQL 语句将产生以下结果:
RECORDS
---------
7
(1 row)
PostgreSQL - 日期表达式
日期表达式返回当前系统的日期和时间值,这些表达式用于各种数据操作。
testdb=# SELECT CURRENT_TIMESTAMP;
上述 PostgreSQL 语句将产生以下结果:
now ------------------------------- 2013-05-06 14:38:28.078+05:30 (1 row)
PostgreSQL - WHERE 子句
PostgreSQL WHERE 子句用于在从单个表获取数据或与多个表连接时指定条件。
只有在满足给定条件时,它才会返回表中的特定值。您可以使用 WHERE 子句过滤掉结果集中不需要包含的行。
WHERE 子句不仅用于 SELECT 语句,还用于 UPDATE、DELETE 语句等,我们将在后续章节中进行检查。
语法
包含 WHERE 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
您可以使用比较或逻辑运算符(如 >、<、=、LIKE、NOT 等)来指定search_condition。以下示例将使这个概念更清晰。
示例
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一些显示 PostgreSQL 逻辑运算符用法的简单示例。以下 SELECT 语句将列出所有 AGE 大于或等于 25 AND 薪水大于或等于 65000.00 的记录:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
以下 SELECT 语句列出所有 AGE 大于或等于 25 OR 薪水大于或等于 65000.00 的记录:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
以下 SELECT 语句列出所有 AGE 不为 NULL 的记录,这意味着所有记录,因为没有记录的 AGE 等于 NULL:
testdb=# SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 语句列出所有 NAME 以 'Pa' 开头的记录,之后的内容无关紧要。
testdb=# SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
上述 PostgreSQL 语句将产生以下结果:
id | name | age |address | salary ----+------+-----+-----------+-------- 1 | Paul | 32 | California| 20000
以下 SELECT 语句列出 AGE 值为 25 或 27 的所有记录:
testdb=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
以下 SELECT 语句列出 AGE 值既不是 25 也不是 27 的所有记录:
testdb=# SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (4 rows)
以下 SELECT 语句列出 AGE 值在 25 和 27 之间的记录:
testdb=# SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
以下 SELECT 语句使用 SQL 子查询,子查询查找 AGE 字段的 SALARY > 65000 的所有记录,然后 WHERE 子句与 EXISTS 运算符一起使用,列出外部查询的 AGE 存在于子查询返回的结果中的所有记录:
testdb=# SELECT AGE FROM COMPANY
WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
上述 PostgreSQL 语句将产生以下结果:
age ----- 32 25 23 25 27 22 24 (7 rows)
以下 SELECT 语句使用 SQL 子查询,子查询查找 AGE 字段的 SALARY > 65000 的所有记录,然后 WHERE 子句与 > 运算符一起使用,列出外部查询的 AGE 大于子查询返回的结果中 AGE 的所有记录:
testdb=# SELECT * FROM COMPANY
WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+------+-----+------------+-------- 1 | Paul | 32 | California | 20000
AND 和 OR 连接运算符
PostgreSQL 的AND 和OR 运算符用于组合多个条件,以缩小 PostgreSQL 语句中选择的数据范围。这两个运算符称为连接运算符。
这些运算符提供了一种方法,可以在同一个 PostgreSQL 语句中使用不同的运算符进行多次比较。
AND 运算符
AND 运算符允许在 PostgreSQL 语句的 WHERE 子句中存在多个条件。使用 AND 运算符时,只有当所有条件都为真时,整个条件才被认为是真。例如 [condition1] AND [condition2] 只有在 condition1 和 condition2 都为真时才为真。
语法
带有 WHERE 子句的 AND 运算符的基本语法如下:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
您可以使用 AND 运算符组合 N 个条件。对于 PostgreSQL 语句要执行的操作(无论是事务还是查询),所有由 AND 分隔的条件都必须为 TRUE。
示例
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 语句列出所有 AGE 大于或等于 25 AND 薪水大于或等于 65000.00 的记录:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
OR 运算符
OR 运算符也用于组合 PostgreSQL 语句 WHERE 子句中的多个条件。使用 OR 运算符时,只要任何一个条件为真,整个条件就都被认为是真。例如 [condition1] OR [condition2] 如果 condition1 或 condition2 为真,则为真。
语法
带有 WHERE 子句的 OR 运算符的基本语法如下:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] OR [condition2]...OR [conditionN]
您可以使用 OR 运算符组合 N 个条件。对于 PostgreSQL 语句要执行的操作(无论是事务还是查询),只有任何一个由 OR 分隔的条件必须为 TRUE。
示例
考虑COMPANY表,它具有以下记录:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 语句列出所有 AGE 大于或等于 25 OR 薪水大于或等于 65000.00 的记录:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
PostgreSQL - UPDATE 查询
PostgreSQL 的UPDATE 查询用于修改表中现有记录。您可以将 WHERE 子句与 UPDATE 查询一起使用以更新选定的行。否则,所有行都将被更新。
语法
带有 WHERE 子句的 UPDATE 查询的基本语法如下:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
您可以使用 AND 或 OR 运算符组合 N 个条件。
示例
考虑表COMPANY,它具有以下记录:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将更新 ID 为 6 的客户的 ADDRESS:
testdb=# UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
现在,COMPANY 表将具有以下记录:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 3 | Teddy | 23 | Norway | 15000 (7 rows)
如果要修改COMPANY表中所有ADDRESS和SALARY列的值,则无需使用WHERE子句,UPDATE查询如下所示:
testdb=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
现在,COMPANY表将包含以下记录:
id | name | age | address | salary ----+-------+-----+---------+-------- 1 | Paul | 32 | Texas | 20000 2 | Allen | 25 | Texas | 20000 4 | Mark | 25 | Texas | 20000 5 | David | 27 | Texas | 20000 6 | Kim | 22 | Texas | 20000 7 | James | 24 | Texas | 20000 3 | Teddy | 23 | Texas | 20000 (7 rows)
PostgreSQL - DELETE 查询
PostgreSQL 的DELETE查询用于删除表中已存在的记录。可以使用WHERE子句与DELETE查询一起删除选定的行。否则,所有记录都将被删除。
语法
带有WHERE子句的DELETE查询的基本语法如下:
DELETE FROM table_name WHERE [condition];
您可以使用 AND 或 OR 运算符组合 N 个条件。
示例
考虑表COMPANY,它具有以下记录:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将删除ID为7的客户:
testdb=# DELETE FROM COMPANY WHERE ID = 2;
现在,COMPANY表将包含以下记录:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (6 rows)
如果要从COMPANY表中删除所有记录,则无需在DELETE查询中使用WHERE子句,方法如下:
testdb=# DELETE FROM COMPANY;
现在,COMPANY表没有任何记录,因为所有记录都已被DELETE语句删除。
PostgreSQL - LIKE 子句
PostgreSQL 的LIKE运算符用于使用通配符将文本值与模式匹配。如果搜索表达式可以与模式表达式匹配,则LIKE运算符将返回true,即1。
与LIKE运算符一起使用的两个通配符是:
- 百分号 (%)
- 下划线 (_)
百分号代表零个、一个或多个数字或字符。下划线代表单个数字或字符。这些符号可以组合使用。
如果这两个符号中的任何一个都没有与LIKE子句一起使用,则LIKE的作用类似于等于运算符。
语法
% 和 _ 的基本语法如下:
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
可以使用AND或OR运算符组合N个条件。此处XXXX可以是任何数值或字符串值。
示例
以下是一些示例,这些示例显示了具有不同LIKE子句以及'%'和'_'运算符的WHERE部分:
| 序号 | 语句 & 说明 |
|---|---|
| 1 | WHERE SALARY::text LIKE '200%' 查找以200开头的任何值 |
| 2 | WHERE SALARY::text LIKE '%200%' 查找任何位置包含200的任何值 |
| 3 | WHERE SALARY::text LIKE '_00%' 查找在第二位和第三位具有00的任何值 |
| 4 | WHERE SALARY::text LIKE '2_%_%' 查找以2开头且至少3个字符长的任何值 |
| 5 | WHERE SALARY::text LIKE '%2' 查找以2结尾的任何值 |
| 6 | WHERE SALARY::text LIKE '_2%3' 查找第二位为2且以3结尾的任何值 |
| 7 | WHERE SALARY::text LIKE '2___3' 查找五位数中以2开头并以3结尾的任何值 |
Postgres LIKE 仅进行字符串比较。因此,我们需要像上面的示例一样显式地将整数列转换为字符串。
让我们来看一个真实的例子,考虑表COMPANY,其记录如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将显示COMPANY表中AGE以2开头的所有记录:
testdb=# SELECT * FROM COMPANY WHERE AGE::text LIKE '2%';
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 (7 rows)
以下是一个示例,它将显示COMPANY表中ADDRESS文本内包含连字符(-)的所有记录:
testdb=# SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';
这将产生以下结果:
id | name | age | address | salary ----+------+-----+-------------------------------------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 (2 rows)
PostgreSQL - LIMIT 子句
PostgreSQL 的LIMIT子句用于限制SELECT语句返回的数据量。
语法
带有LIMIT子句的SELECT语句的基本语法如下:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows]
当LIMIT子句与OFFSET子句一起使用时的语法如下:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows] OFFSET [row num]
LIMIT和OFFSET允许您仅检索由查询其余部分生成的行的部分。
示例
考虑表 COMPANY,其记录如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它根据要从表中提取的行数限制表中的行:
testdb=# SELECT * FROM COMPANY LIMIT 4;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 (4 rows)
但是,在某些情况下,您可能需要从特定偏移量处提取一组记录。这是一个示例,它从第三个位置开始提取三条记录:
testdb=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
PostgreSQL - ORDER BY 子句
PostgreSQL 的ORDER BY子句用于根据一个或多个列对数据进行升序或降序排序。
语法
ORDER BY子句的基本语法如下:
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
可以在ORDER BY子句中使用多个列。确保用于排序的任何列都应在列列表中可用。
示例
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将根据SALARY按升序排序结果:
testdb=# SELECT * FROM COMPANY ORDER BY AGE ASC;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 6 | Kim | 22 | South-Hall | 45000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 1 | Paul | 32 | California | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
以下是一个示例,它将根据NAME和SALARY按升序排序结果:
testdb=# SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+--------------+-------- 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 10 | James | 45 | Texas | 5000 9 | James | 44 | Norway | 5000 7 | James | 24 | Houston | 10000 6 | Kim | 22 | South-Hall | 45000 4 | Mark | 25 | Rich-Mond | 65000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 3 | Teddy | 23 | Norway | 20000 (10 rows)
以下是一个示例,它将根据NAME按降序排序结果:
testdb=# SELECT * FROM COMPANY ORDER BY NAME DESC;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 3 | Teddy | 23 | Norway | 20000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 5 | David | 27 | Texas | 85000 2 | Allen | 25 | Texas | 15000 (10 rows)
PostgreSQL - GROUP BY
PostgreSQL 的GROUP BY子句与SELECT语句一起使用,用于将表中具有相同数据的那些行组合在一起。这样做是为了消除输出中的冗余和/或计算应用于这些组的聚合。
GROUP BY子句位于SELECT语句中的WHERE子句之后,位于ORDER BY子句之前。
语法
GROUP BY子句的基本语法如下所示。GROUP BY子句必须位于WHERE子句中的条件之后,如果使用了ORDER BY子句,则必须位于ORDER BY子句之前。
SELECT column-list FROM table_name WHERE [ conditions ] GROUP BY column1, column2....columnN ORDER BY column1, column2....columnN
可以在GROUP BY子句中使用多个列。确保用于分组的任何列都应在列列表中可用。
示例
考虑表 COMPANY,其记录如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
如果要了解每个客户的工资总额,则GROUP BY查询如下所示:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
这将产生以下结果:
name | sum -------+------- Teddy | 20000 Paul | 20000 Mark | 65000 David | 85000 Allen | 15000 Kim | 45000 James | 10000 (7 rows)
现在,让我们使用以下INSERT语句在COMPANY表中创建三个更多记录:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
现在,我们的表具有以下具有重复名称的记录:
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
再次,让我们使用相同的语句按NAME列对所有记录进行分组,如下所示:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
这将产生以下结果:
name | sum -------+------- Allen | 15000 David | 85000 James | 20000 Kim | 45000 Mark | 65000 Paul | 40000 Teddy | 20000 (7 rows)
让我们将ORDER BY子句与GROUP BY子句一起使用,如下所示:
testdb=# SELECT NAME, SUM(SALARY)
FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
这将产生以下结果:
name | sum -------+------- Teddy | 20000 Paul | 40000 Mark | 65000 Kim | 45000 James | 20000 David | 85000 Allen | 15000 (7 rows)
PostgreSQL - WITH 子句
在PostgreSQL中,WITH查询提供了一种编写辅助语句以用于更大查询的方法。它有助于将复杂的大型查询分解成更简单的形式,这些形式更易于阅读。这些语句通常称为公用表表达式或CTE,可以认为是仅为一个查询存在的临时表的定义。
WITH查询作为CTE查询,在子查询多次执行时特别有用。它在临时表中同样有用。它只计算一次聚合,并允许我们在查询中通过其名称(可能多次)引用它。
WITH子句必须在查询中使用之前定义。
语法
WITH查询的基本语法如下:
WITH
name_for_summary_data AS (
SELECT Statement)
SELECT columns
FROM name_for_summary_data
WHERE conditions <=> (
SELECT column
FROM name_for_summary_data)
[ORDER BY columns]
其中name_for_summary_data是赋予WITH子句的名称。name_for_summary_data可以与现有的表名相同,并且将优先使用。
可以在WITH中使用数据修改语句(INSERT、UPDATE或DELETE)。这允许您在同一个查询中执行多个不同的操作。
递归WITH
递归WITH或分层查询是一种CTE的形式,其中CTE可以引用自身,即WITH查询可以引用其自身的输出,因此称为递归。示例
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
现在,让我们使用WITH子句编写一个查询来从上表中选择记录,如下所示:
With CTE AS (Select ID , NAME , AGE , ADDRESS , SALARY FROM COMPANY ) Select * From CTE;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
现在,让我们使用RECURSIVE关键字以及WITH子句编写一个查询,以查找小于20000的工资总和,如下所示:
WITH RECURSIVE t(n) AS ( VALUES (0) UNION ALL SELECT SALARY FROM COMPANY WHERE SALARY < 20000 ) SELECT sum(n) FROM t;
上述 PostgreSQL 语句将产生以下结果:
sum ------- 25000 (1 row)
让我们使用数据修改语句以及WITH子句编写一个查询,如下所示。
首先,创建一个与COMPANY表类似的COMPANY1表。示例中的查询有效地将行从COMPANY移动到COMPANY1。WITH中的DELETE删除COMPANY中指定的行,通过其RETURNING子句返回其内容;然后主查询读取该输出并将其插入到COMPANY1表中:
CREATE TABLE COMPANY1(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
WITH moved_rows AS (
DELETE FROM COMPANY
WHERE
SALARY >= 30000
RETURNING *
)
INSERT INTO COMPANY1 (SELECT * FROM moved_rows);
上述 PostgreSQL 语句将产生以下结果:
INSERT 0 3
现在,COMPANY和COMPANY1表中的记录如下:
testdb=# SELECT * FROM COMPANY; id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 (4 rows) testdb=# SELECT * FROM COMPANY1; id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 (3 rows)
PostgreSQL - HAVING 子句
HAVING子句允许我们挑选出函数结果满足某些条件的特定行。
WHERE子句对选定的列设置条件,而HAVING子句对GROUP BY子句创建的组设置条件。
语法
HAVING子句在SELECT查询中的位置如下:
SELECT FROM WHERE GROUP BY HAVING ORDER BY
HAVING子句必须位于查询中的GROUP BY子句之后,如果使用了ORDER BY子句,则也必须位于ORDER BY子句之前。以下是包含HAVING子句的SELECT语句的语法:
SELECT column1, column2 FROM table1, table2 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2
示例
考虑表 COMPANY,其记录如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一个示例,它将显示名称计数小于2的记录:
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
这将产生以下结果:
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
现在,让我们使用以下INSERT语句在COMPANY表中创建三个更多记录:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
现在,我们的表具有以下具有重复名称的记录:
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
以下是一个示例,它将显示名称计数大于1的记录:
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
这将产生以下结果:
name ------- Paul James (2 rows)
PostgreSQL - DISTINCT 关键字
PostgreSQL 的DISTINCT关键字与SELECT语句一起使用,以消除所有重复记录并仅获取唯一记录。
表中可能存在多个重复记录的情况。在获取此类记录时,获取唯一记录比获取重复记录更有意义。
语法
消除重复记录的DISTINCT关键字的基本语法如下:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
示例
考虑表 COMPANY,其记录如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
让我们向此表添加两条更多记录,如下所示:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
现在,COMPANY表中的记录将是:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 32 | California | 20000 9 | Allen | 25 | Texas | 15000 (9 rows)
首先,让我们看看以下SELECT查询如何返回重复的工资记录:
testdb=# SELECT name FROM COMPANY;
这将产生以下结果:
name ------- Paul Allen Teddy Mark David Kim James Paul Allen (9 rows)
现在,让我们在上面的SELECT查询中使用DISTINCT关键字并查看结果:
testdb=# SELECT DISTINCT name FROM COMPANY;
这将产生以下结果,其中我们没有任何重复条目:
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
PostgreSQL - 约束
约束是表上数据列上强制执行的规则。这些用于防止将无效数据输入到数据库中。这确保了数据库中数据的准确性和可靠性。
约束可以是列级或表级。列级约束仅应用于一列,而表级约束应用于整个表。为列定义数据类型本身就是一个约束。例如,类型为DATE的列将列约束为有效日期。
以下是PostgreSQL中常用的约束。
NOT NULL 约束 - 确保列不能具有NULL值。
UNIQUE 约束 - 确保列中的所有值都不同。
主键 - 唯一标识数据库表中的每一行/记录。
外键 - 基于其他表中的列约束数据。
CHECK 约束 - CHECK约束确保列中的所有值都满足某些条件。
排他约束 (EXCLUSION Constraint) − 排他约束确保,如果使用指定的运算符比较指定列或表达式上的任意两行,则并非所有这些比较都将返回 TRUE。
非空约束 (NOT NULL Constraint)
默认情况下,列可以保存 NULL 值。如果您不希望列具有 NULL 值,则需要在此列上定义此约束,指定该列不允许 NULL 值。NOT NULL 约束始终被写为列约束。
NULL 不等于无数据;相反,它表示未知数据。
示例
例如,以下 PostgreSQL 语句创建一个名为 COMPANY1 的新表,并添加五列,其中三列 ID、NAME 和 AGE 指定不接受 NULL 值 −
CREATE TABLE COMPANY1( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
唯一约束 (UNIQUE Constraint)
唯一约束防止两条记录在特定列中具有相同的值。例如,在 COMPANY 表中,您可能希望防止两个或更多人具有相同的年龄。
示例
例如,以下 PostgreSQL 语句创建一个名为 COMPANY3 的新表,并添加五列。这里,AGE 列设置为 UNIQUE,因此您不能有两条具有相同年龄的记录 −
CREATE TABLE COMPANY3( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL UNIQUE, ADDRESS CHAR(50), SALARY REAL DEFAULT 50000.00 );
主键约束 (PRIMARY KEY Constraint)
主键约束唯一标识数据库表中的每条记录。可以有多个 UNIQUE 列,但表中只有一个主键。设计数据库表时,主键非常重要。主键是唯一的 ID。
我们使用它们来引用表行。在创建表之间的关系时,主键成为其他表中的外键。由于“长期存在的编码疏忽”,主键可以在 SQLite 中为 NULL。其他数据库并非如此。
主键是表中的一个字段,它唯一标识数据库表中的每一行/记录。主键必须包含唯一值。主键列不能具有 NULL 值。
一个表只能有一个主键,它可以由单个或多个字段组成。当多个字段用作主键时,它们被称为组合键 (composite key)。
如果表在任何字段上定义了主键,则您不能有两条记录具有该字段的相同值。
示例
您已经在上面的各种示例中看到了我们使用 ID 作为主键创建 COMAPNY4 表的情况 −
CREATE TABLE COMPANY4( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
外键约束 (FOREIGN KEY Constraint)
外键约束指定列(或一组列)中的值必须与另一个表某一行的值匹配。我们说这保持了两个相关表之间的参照完整性。它们被称为外键,因为约束是外部的;也就是说,在表之外。外键有时也称为引用键。
示例
例如,以下 PostgreSQL 语句创建一个名为 COMPANY5 的新表,并添加五列。
CREATE TABLE COMPANY6( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
例如,以下 PostgreSQL 语句创建一个名为 DEPARTMENT1 的新表,并添加三列。EMP_ID 列是外键,并引用 COMPANY6 表的 ID 字段。
CREATE TABLE DEPARTMENT1( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT references COMPANY6(ID) );
检查约束 (CHECK Constraint)
检查约束允许使用条件来检查输入记录的值。如果条件计算结果为 false,则记录违反约束,不会被输入到表中。
示例
例如,以下 PostgreSQL 语句创建一个名为 COMPANY5 的新表,并添加五列。这里,我们使用 SALARY 列添加一个 CHECK,这样您就不能有任何 SALARY 为零。
CREATE TABLE COMPANY5( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL CHECK(SALARY > 0) );
排他约束 (EXCLUSION Constraint)
排他约束确保,如果使用指定的运算符比较指定列或表达式上的任意两行,则这些运算符比较中至少有一个将返回 false 或 null。
示例
例如,以下 PostgreSQL 语句创建一个名为 COMPANY7 的新表,并添加五列。这里,我们添加了一个 EXCLUDE 约束 −
CREATE TABLE COMPANY7( ID INT PRIMARY KEY NOT NULL, NAME TEXT, AGE INT , ADDRESS CHAR(50), SALARY REAL, EXCLUDE USING gist (NAME WITH =, AGE WITH <>) );
这里,USING gist 是要构建和用于强制执行的索引类型。
您需要每个数据库执行一次命令 CREATE EXTENSION btree_gist。这将安装 btree_gist 扩展,该扩展在普通标量数据类型上定义排他约束。
由于我们强制执行年龄必须相同,让我们通过将记录插入表中来看一下 −
INSERT INTO COMPANY7 VALUES(1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY7 VALUES(2, 'Paul', 32, 'Texas', 20000.00 ); INSERT INTO COMPANY7 VALUES(3, 'Paul', 42, 'California', 20000.00 );
对于前两个 INSERT 语句,记录被添加到 COMPANY7 表中。对于第三个 INSERT 语句,将显示以下错误 −
ERROR: conflicting key value violates exclusion constraint "company7_name_age_excl" DETAIL: Key (name, age)=(Paul, 42) conflicts with existing key (name, age)=(Paul, 32).
删除约束 (Dropping Constraints)
要删除约束,您需要知道它的名称。如果知道名称,则很容易删除。否则,您需要找出系统生成的名称。psql 命令 \d 表名在这里可能会有所帮助。通用语法如下 −
ALTER TABLE table_name DROP CONSTRAINT some_name;
PostgreSQL - 连接 (JOINS)
PostgreSQL 的连接 (Joins) 子句用于组合数据库中两个或多个表中的记录。连接是一种通过使用每个表共有的值来组合两个表中的字段的方法。
PostgreSQL 中的连接类型如下 −
- 交叉连接 (CROSS JOIN)
- 内部连接 (INNER JOIN)
- 左外部连接 (LEFT OUTER JOIN)
- 右外部连接 (RIGHT OUTER JOIN)
- 全外部连接 (FULL OUTER JOIN)
在我们继续之前,让我们考虑两个表,COMPANY 和 DEPARTMENT。我们已经看到用于填充 COMPANY 表的 INSERT 语句。所以让我们假设 COMPANY 表中存在以下记录 −
id | name | age | address | salary | join_date ----+-------+-----+-----------+--------+----------- 1 | Paul | 32 | California| 20000 | 2001-07-13 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13 5 | David | 27 | Texas | 85000 | 2007-12-13 2 | Allen | 25 | Texas | | 2007-12-13 8 | Paul | 24 | Houston | 20000 | 2005-07-13 9 | James | 44 | Norway | 5000 | 2005-07-13 10 | James | 45 | Texas | 5000 | 2005-07-13
另一个表是 DEPARTMENT,具有以下定义 −
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
以下是用于填充 DEPARTMENT 表的 INSERT 语句列表 −
INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (1, 'IT Billing', 1 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (2, 'Engineering', 2 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (3, 'Finance', 7 );
最后,DEPARTMENT 表中存在以下记录列表 −
id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7
交叉连接 (CROSS JOIN)
交叉连接将第一个表的每一行与第二个表的每一行匹配。如果输入表分别具有 x 和 y 列,则结果表将具有 x+y 列。由于 CROSS JOIN 有可能生成非常大的表,因此必须注意仅在适当的时候使用它们。
以下是 CROSS JOIN 的语法 −
SELECT ... FROM table1 CROSS JOIN table2 ...
基于上述表格,我们可以编写一个 CROSS JOIN 如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY CROSS JOIN DEPARTMENT;
上述查询将产生以下结果 −
emp_id| name | dept
------|-------|--------------
1 | Paul | IT Billing
1 | Teddy | IT Billing
1 | Mark | IT Billing
1 | David | IT Billing
1 | Allen | IT Billing
1 | Paul | IT Billing
1 | James | IT Billing
1 | James | IT Billing
2 | Paul | Engineering
2 | Teddy | Engineering
2 | Mark | Engineering
2 | David | Engineering
2 | Allen | Engineering
2 | Paul | Engineering
2 | James | Engineering
2 | James | Engineering
7 | Paul | Finance
7 | Teddy | Finance
7 | Mark | Finance
7 | David | Finance
7 | Allen | Finance
7 | Paul | Finance
7 | James | Finance
7 | James | Finance
内部连接 (INNER JOIN)
内部连接通过基于连接谓词组合两个表(table1 和 table2)的列值来创建一个新的结果表。查询比较 table1 的每一行与 table2 的每一行,以查找满足连接谓词的所有行对。当满足连接谓词时,table1 和 table2 的每一对匹配行的列值将组合到结果行中。
内部连接是最常见的连接类型,也是默认的连接类型。您可以选择使用 INNER 关键字。
以下是 INNER JOIN 的语法 −
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_filed = table2.common_field;
基于上述表格,我们可以编写一个 INNER JOIN 如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查询将产生以下结果 −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
左外部连接 (LEFT OUTER JOIN)
外部连接是内部连接的扩展。SQL 标准定义了三种类型的外部连接:LEFT、RIGHT 和 FULL,PostgreSQL 支持所有这些类型。
对于左外部连接,首先执行内部连接。然后,对于 T1 中不满足与 T2 中任何行连接条件的每一行,将添加一个连接行,其中 T2 的列中包含 null 值。因此,连接表始终至少包含 T1 中每一行的一行。
以下是 LEFT OUTER JOIN 的语法 −
SELECT ... FROM table1 LEFT OUTER JOIN table2 ON conditional_expression ...
基于上述表格,我们可以编写一个内部连接如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查询将产生以下结果 −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
右外部连接 (RIGHT OUTER JOIN)
首先,执行内部连接。然后,对于 T2 中不满足与 T1 中任何行连接条件的每一行,将添加一个连接行,其中 T1 的列中包含 null 值。这是左连接的反向;结果表将始终包含 T2 中每一行的一行。
以下是 RIGHT OUTER JOIN 的语法 −
SELECT ... FROM table1 RIGHT OUTER JOIN table2 ON conditional_expression ...
基于上述表格,我们可以编写一个内部连接如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY RIGHT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查询将产生以下结果 −
emp_id | name | dept
--------+-------+--------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
全外部连接 (FULL OUTER JOIN)
首先,执行内部连接。然后,对于 T1 中不满足与 T2 中任何行连接条件的每一行,将添加一个连接行,其中 T2 的列中包含 null 值。此外,对于 T2 中不满足与 T1 中任何行连接条件的每一行,将添加一个在 T1 的列中包含 null 值的连接行。
以下是 FULL OUTER JOIN 的语法 −
SELECT ... FROM table1 FULL OUTER JOIN table2 ON conditional_expression ...
基于上述表格,我们可以编写一个内部连接如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY FULL OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查询将产生以下结果 −
emp_id | name | dept
--------+-------+---------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
PostgreSQL - UNION 子句
PostgreSQL 的UNION 子句/运算符用于组合两个或多个 SELECT 语句的结果,而不返回任何重复的行。
要使用 UNION,每个 SELECT 必须选择相同数量的列,具有相同数量的列表达式,相同的数据类型,并且顺序相同,但长度不必相同。
语法
UNION 的基本语法如下 −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
这里,给定的条件可以是基于您需求的任何给定表达式。
示例
考虑以下两个表,(a) COMPANY 表如下 −
testdb=# SELECT * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) 另一个表是 DEPARTMENT 表,如下所示 −
testdb=# SELECT * from DEPARTMENT; id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
现在让我们使用 SELECT 语句以及 UNION 子句将这两个表连接起来,如下所示 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
这将产生以下结果:
emp_id | name | dept
--------+-------+--------------
5 | David | Engineering
6 | Kim | Finance
2 | Allen | Engineering
3 | Teddy | Engineering
4 | Mark | Finance
1 | Paul | IT Billing
7 | James | Finance
(7 rows)
UNION ALL 子句
UNION ALL 运算符用于组合两个 SELECT 语句的结果,包括重复的行。适用于 UNION 的相同规则也适用于 UNION ALL 运算符。
语法
UNION ALL 的基本语法如下 −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION ALL SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
这里,给定的条件可以是基于您需求的任何给定表达式。
示例
现在,让我们在 SELECT 语句中连接上述两个表,如下所示 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION ALL
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
这将产生以下结果:
emp_id | name | dept
--------+-------+--------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
(14 rows)
PostgreSQL - NULL 值
PostgreSQL 中的NULL 用于表示缺失值。表中的 NULL 值是字段中看起来为空的值。
具有 NULL 值的字段是没有值的字段。理解 NULL 值不同于零值或包含空格的字段非常重要。
语法
在创建表时使用NULL 的基本语法如下 −
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
这里,NOT NULL 表示列应始终接受给定数据类型的显式值。有两列我们没有使用 NOT NULL。因此,这意味着这些列可以为 NULL。
具有 NULL 值的字段是在记录创建期间留空的一个字段。
示例
选择数据时,NULL 值可能会导致问题,因为当将未知值与任何其他值进行比较时,结果始终是未知的,并且不包含在最终结果中。考虑以下表,COMPANY 表包含以下记录 −
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
让我们使用 UPDATE 语句将一些可为空的值设置为 NULL,如下所示 −
testdb=# UPDATE COMPANY SET ADDRESS = NULL, SALARY = NULL where ID IN(6,7);
现在,COMPANY 表应该包含以下记录 −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | | 7 | James | 24 | | (7 rows)
接下来,让我们看看IS NOT NULL 运算符的使用,以列出 SALARY 不为 NULL 的所有记录 −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NOT NULL;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (5 rows)
以下是IS NULL 运算符的使用,它将列出 SALARY 为 NULL 的所有记录 −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM COMPANY
WHERE SALARY IS NULL;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | address | salary ----+-------+-----+---------+-------- 6 | Kim | 22 | | 7 | James | 24 | | (2 rows)
PostgreSQL - 别名语法 (ALIAS Syntax)
您可以通过赋予另一个名称来临时重命名表或列,这称为别名 (ALIAS)。使用表别名意味着在特定的 PostgreSQL 语句中重命名表。重命名是临时的更改,实际的表名不会在数据库中更改。
列别名用于为了特定 PostgreSQL 查询的目的而重命名表的列。
语法
表 (table) 别名的基本语法如下 −
SELECT column1, column2.... FROM table_name AS alias_name WHERE [condition];
列 (column) 别名的基本语法如下 −
SELECT column_name AS alias_name FROM table_name WHERE [condition];
示例
考虑以下两个表,(a) COMPANY 表如下 −
testdb=# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) 另一个表是 DEPARTMENT 表,如下所示 −
id | dept | emp_id ----+--------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
现在,以下是表别名 (TABLE ALIAS) 的用法,我们分别使用 C 和 D 作为 COMPANY 和 DEPARTMENT 表的别名 −
testdb=# SELECT C.ID, C.NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
上述 PostgreSQL 语句将产生以下结果:
id | name | age | dept ----+-------+-----+------------ 1 | Paul | 32 | IT Billing 2 | Allen | 25 | Engineering 7 | James | 24 | Finance 3 | Teddy | 23 | Engineering 4 | Mark | 25 | Finance 5 | David | 27 | Engineering 6 | Kim | 22 | Finance (7 rows)
让我们看看列别名 (COLUMN ALIAS) 的用法示例,其中 COMPANY_ID 是 ID 列的别名,COMPANY_NAME 是 name 列的别名 −
testdb=# SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
上述 PostgreSQL 语句将产生以下结果:
company_id | company_name | age | dept
------------+--------------+-----+------------
1 | Paul | 32 | IT Billing
2 | Allen | 25 | Engineering
7 | James | 24 | Finance
3 | Teddy | 23 | Engineering
4 | Mark | 25 | Finance
5 | David | 27 | Engineering
6 | Kim | 22 | Finance
(7 rows)
PostgreSQL - 触发器 (TRIGGERS)
PostgreSQL 的触发器 (Triggers) 是数据库回调函数,当发生指定的数据库事件时,它们会自动执行/调用。
以下是关于 PostgreSQL 触发器的重要几点 −
可以指定 PostgreSQL 触发器来触发
在对行进行操作之前(在检查约束并尝试 INSERT、UPDATE 或 DELETE 之前)
操作完成后(在检查约束并完成 INSERT、UPDATE 或 DELETE 之后)
代替操作(在视图上进行插入、更新或删除的情况下)
标记为 FOR EACH ROW 的触发器会为操作修改的每一行调用一次。相反,标记为 FOR EACH STATEMENT 的触发器对于任何给定操作只执行一次,无论它修改多少行。
WHEN 子句和触发器动作都可以使用 NEW.column-name 和 OLD.column-name 形式的引用访问正在插入、删除或更新的行元素,其中 column-name 是触发器关联的表的列名。
如果提供了 WHEN 子句,则只有当 WHEN 子句为真时,才会执行指定的 PostgreSQL 语句。如果没有提供 WHEN 子句,则会对所有行执行 PostgreSQL 语句。
如果为同一事件定义了多个相同类型的触发器,则它们将按名称的字母顺序触发。
BEFORE、AFTER 或 INSTEAD OF 关键字决定触发器动作相对于关联行的插入、修改或删除的执行时间。
当与触发器关联的表被删除时,触发器会自动删除。
要修改的表必须与附加触发器的表或视图位于同一数据库中,并且必须只使用 tablename,而不是 database.tablename。
指定 CONSTRAINT 选项时,会创建一个 *约束触发器*。这与常规触发器相同,只是可以使用 SET CONSTRAINTS 调整触发器触发的时机。当约束触发器实现的约束被违反时,预计会引发异常。
语法
创建触发器的基本语法如下:
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name ON table_name [ -- Trigger logic goes here.... ];
这里,event_name 可以是提到的表 table_name 上的 *INSERT、DELETE、UPDATE* 和 *TRUNCATE* 数据库操作。您可以在表名之后选择性地指定 FOR EACH ROW。
以下是创建在表的指定的列之一或多列上进行 UPDATE 操作的触发器的语法:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name ON table_name [ -- Trigger logic goes here.... ];
示例
让我们考虑一个案例,我们想要为 COMPANY 表中插入的每条记录保留审计跟踪,我们将新建该表如下(如果您已经拥有 COMPANY 表,请将其删除)。
testdb=# CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
为了保留审计跟踪,我们将创建一个名为 AUDIT 的新表,每当在 COMPANY 表中为新记录添加条目时,日志消息都会插入到该表中:
testdb=# CREATE TABLE AUDIT( EMP_ID INT NOT NULL, ENTRY_DATE TEXT NOT NULL );
这里,ID 是 AUDIT 记录 ID,EMP_ID 是 ID(将来自 COMPANY 表),DATE 将保留在 COMPANY 表中创建记录的时间戳。现在,让我们在 COMPANY 表上创建一个触发器,如下所示:
testdb=# CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
其中 auditlogfunc() 是一个 PostgreSQL 过程,其定义如下:
CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$example_table$ LANGUAGE plpgsql;
现在,我们将开始实际工作。让我们开始在 COMPANY 表中插入记录,这应该会导致在 AUDIT 表中创建审计日志记录。让我们在 COMPANY 表中创建一条记录,如下所示:
testdb=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 );
这将在 COMPANY 表中创建一条记录,如下所示:
id | name | age | address | salary ----+------+-----+--------------+-------- 1 | Paul | 32 | California | 20000
同时,将在 AUDIT 表中创建一条记录。此记录是我们为 COMPANY 表上的 INSERT 操作创建的触发器的结果。类似地,您可以根据您的需求在 UPDATE 和 DELETE 操作上创建触发器。
emp_id | entry_date
--------+-------------------------------
1 | 2013-05-05 15:49:59.968+05:30
(1 row)
列出触发器
您可以使用以下方法从 pg_trigger 表中列出当前数据库中的所有触发器:
testdb=# SELECT * FROM pg_trigger;
上面给出的 PostgreSQL 语句将列出所有触发器。
如果您想列出特定表上的触发器,则使用 AND 子句和表名,如下所示:
testdb=# SELECT tgname FROM pg_trigger, pg_class WHERE tgrelid=pg_class.oid AND relname='company';
上面给出的 PostgreSQL 语句也将只列出一条条目,如下所示:
tgname ----------------- example_trigger (1 row)
删除触发器
以下是 DROP 命令,可用于删除现有触发器:
testdb=# DROP TRIGGER trigger_name;
PostgreSQL - 索引
索引是数据库搜索引擎可以用来加快数据检索速度的特殊查找表。简单地说,索引是指向表中数据的指针。数据库中的索引与书后面的索引非常相似。
例如,如果您想引用书中讨论某个主题的所有页面,您必须首先参考索引,索引按字母顺序列出所有主题,然后参考一个或多个具体的页码。
索引有助于加快 SELECT 查询和 WHERE 子句的速度;但是,它会减慢数据输入、UPDATE 和 INSERT 语句的速度。创建或删除索引不会影响数据。
创建索引涉及 CREATE INDEX 语句,该语句允许您命名索引,指定表以及要索引的列或列,并指示索引是升序还是降序。
索引也可以是唯一的,类似于 UNIQUE 约束,因为它可以防止在有索引的列或列组合中插入重复条目。
CREATE INDEX 命令
CREATE INDEX 的基本语法如下:
CREATE INDEX index_name ON table_name;
索引类型
PostgreSQL 提供了几种索引类型:B 树、哈希、GiST、SP-GiST 和 GIN。每种索引类型都使用不同的算法,最适合不同类型的查询。默认情况下,CREATE INDEX 命令创建 B 树索引,这适合最常见的情况。
单列索引
单列索引是仅基于一个表列创建的索引。基本语法如下:
CREATE INDEX index_name ON table_name (column_name);
多列索引
多列索引是在表的多个列上定义的。基本语法如下:
CREATE INDEX index_name ON table_name (column1_name, column2_name);
无论创建单列索引还是多列索引,都要考虑在查询的 WHERE 子句中经常用作筛选条件的列。
如果只有一个列被使用,则单列索引应该是最佳选择。如果在 WHERE 子句中经常有两个或多个列用作筛选器,则多列索引将是最佳选择。
唯一索引
唯一索引不仅用于性能,还用于数据完整性。唯一索引不允许将任何重复值插入到表中。基本语法如下:
CREATE UNIQUE INDEX index_name on table_name (column_name);
部分索引
部分索引是在表的子集上构建的索引;子集由条件表达式(称为部分索引的谓词)定义。索引仅包含满足谓词的那些表行的条目。基本语法如下:
CREATE INDEX index_name on table_name (conditional_expression);
隐式索引
隐式索引是在创建对象时由数据库服务器自动创建的索引。主键约束和唯一约束会自动创建索引。
示例
以下是一个示例,我们将为 COMPANY 表的 salary 列创建索引:
# CREATE INDEX salary_index ON COMPANY (salary);
现在,让我们使用 \d company 命令列出 COMPANY 表上可用的所有索引。
# \d company
这将产生以下结果,其中 *company_pkey* 是在创建表时创建的隐式索引。
Table "public.company"
Column | Type | Modifiers
---------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
"salary_index" btree (salary)
您可以使用 \di 命令列出整个数据库的索引:
DROP INDEX 命令
可以使用 PostgreSQL DROP 命令删除索引。删除索引时应谨慎,因为性能可能会变慢或变快。
基本语法如下:
DROP INDEX index_name;
您可以使用以下语句删除以前创建的索引:
# DROP INDEX salary_index;
何时应避免使用索引?
尽管索引旨在增强数据库的性能,但在某些情况下应避免使用索引。以下指南指示何时应重新考虑使用索引:
不应在小型表上使用索引。
具有频繁、大量批量更新或插入操作的表。
不应在包含大量 NULL 值的列上使用索引。
不应为经常被操作的列建立索引。
PostgreSQL - ALTER TABLE 命令
PostgreSQL ALTER TABLE 命令用于在现有表中添加、删除或修改列。
您还可以使用 ALTER TABLE 命令在现有表上添加和删除各种约束。
语法
在现有表中添加新列的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name ADD column_name datatype;
在现有表中删除列的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name DROP COLUMN column_name;
更改表中列的数据类型的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
在表中向列添加NOT NULL 约束的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
在表中添加UNIQUE CONSTRAINT 的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
在表中添加CHECK CONSTRAINT 的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
在表中添加PRIMARY KEY 约束的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
从表中删除约束的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name DROP CONSTRAINT MyUniqueConstraint;
如果您使用的是 MySQL,则代码如下:
ALTER TABLE table_name DROP INDEX MyUniqueConstraint;
从表中删除 PRIMARY KEY 约束的 ALTER TABLE 的基本语法如下:
ALTER TABLE table_name DROP CONSTRAINT MyPrimaryKey;
如果您使用的是 MySQL,则代码如下:
ALTER TABLE table_name DROP PRIMARY KEY;
示例
假设我们的 COMPANY 表包含以下记录:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
以下是向现有表中添加新列的示例:
testdb=# ALTER TABLE COMPANY ADD GENDER char(1);
现在,COMPANY 表已更改,SELECT 语句的输出如下:
id | name | age | address | salary | gender ----+-------+-----+-------------+--------+-------- 1 | Paul | 32 | California | 20000 | 2 | Allen | 25 | Texas | 15000 | 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 5 | David | 27 | Texas | 85000 | 6 | Kim | 22 | South-Hall | 45000 | 7 | James | 24 | Houston | 10000 | (7 rows)
以下是从现有表中删除 gender 列的示例:
testdb=# ALTER TABLE COMPANY DROP GENDER;
现在,COMPANY 表已更改,SELECT 语句的输出如下:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
PostgreSQL - TRUNCATE TABLE 命令
PostgreSQL TRUNCATE TABLE 命令用于删除现有表中的所有数据。您还可以使用 DROP TABLE 命令删除整个表,但这会从数据库中删除整个表结构,如果您希望存储一些数据,则需要重新创建该表。
它对每个表具有与 DELETE 相同的效果,但因为它实际上并没有扫描表,所以速度更快。此外,它会立即回收磁盘空间,而不需要后续的 VACUUM 操作。这对于大型表最有用。
语法
TRUNCATE TABLE 的基本语法如下:
TRUNCATE TABLE table_name;
示例
假设 COMPANY 表包含以下记录:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是截断的示例:
testdb=# TRUNCATE TABLE COMPANY;
现在,COMPANY 表已截断,SELECT 语句的输出如下:
testdb=# SELECT * FROM CUSTOMERS; id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
PostgreSQL - 视图
视图是伪表。也就是说,它们不是真实的表;然而,它们对 SELECT 看起来像普通的表。视图可以表示真实表的一个子集,从普通表中选择某些列或某些行。视图甚至可以表示连接的表。由于视图被分配了单独的权限,因此您可以使用它们来限制表访问,以便用户只能看到表的特定行或列。
视图可以包含表的所有行或一个或多个表中选定的行。视图可以从一个或多个表创建,这取决于用于创建视图的已编写 PostgreSQL 查询。
视图是一种虚拟表,允许用户执行以下操作:
以用户或用户类发现自然或直观的方式来组织数据。
限制对数据的访问,以便用户只能看到有限的数据而不是完整的表。
汇总来自各个表的数据,可用于生成报表。
由于视图不是普通的表,因此您可能无法对视图执行 DELETE、INSERT 或 UPDATE 语句。但是,您可以创建一个规则来纠正这个问题,以便在视图上使用 DELETE、INSERT 或 UPDATE。
创建视图
PostgreSQL 视图使用 **CREATE VIEW** 语句创建。PostgreSQL 视图可以从单个表、多个表或另一个视图创建。
基本的 CREATE VIEW 语法如下:
CREATE [TEMP | TEMPORARY] VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE [condition];
您可以在 SELECT 语句中包含多个表,方法与在普通的 PostgreSQL SELECT 查询中使用它们的方式非常相似。如果存在可选的 TEMP 或 TEMPORARY 关键字,则视图将在临时空间中创建。临时视图会在当前会话结束时自动删除。
示例
假设 COMPANY 表具有以下记录:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
现在,以下是如何从 COMPANY 表创建视图的示例。此视图将仅包含 COMPANY 表中的几列:
testdb=# CREATE VIEW COMPANY_VIEW AS SELECT ID, NAME, AGE FROM COMPANY;
现在,您可以像查询实际表一样查询 COMPANY_VIEW。以下是一个示例:
testdb=# SELECT * FROM COMPANY_VIEW;
这将产生以下结果:
id | name | age ----+-------+----- 1 | Paul | 32 2 | Allen | 25 3 | Teddy | 23 4 | Mark | 25 5 | David | 27 6 | Kim | 22 7 | James | 24 (7 rows)
删除视图
要删除视图,只需使用带有 **view_name** 的 DROP VIEW 语句即可。基本的 DROP VIEW 语法如下:
testdb=# DROP VIEW view_name;
以下命令将删除我们在上一节中创建的 COMPANY_VIEW 视图:
testdb=# DROP VIEW COMPANY_VIEW;
PostgreSQL - 事务
事务是对数据库执行的工作单元。事务是按逻辑顺序完成的工作单元或序列,无论是由用户手动执行,还是由某种数据库程序自动执行。
事务是对数据库传播一个或多个更改。例如,如果您正在创建记录、更新记录或从表中删除记录,那么您正在对表执行事务。控制事务以确保数据完整性和处理数据库错误非常重要。
实际上,您会将许多 PostgreSQL 查询组合成一个组,并将它们一起作为事务的一部分执行。
事务的属性
事务具有以下四个标准属性,通常用首字母缩略词 ACID 来表示:
**原子性** - 确保工作单元中的所有操作都成功完成;否则,事务将在故障点中止,之前的操作将回滚到其以前的状态。
**一致性** - 确保数据库在成功提交的事务后正确更改状态。
**隔离性** - 使事务能够独立于彼此并对彼此透明地运行。
**持久性** - 确保已提交事务的结果或效果在系统故障的情况下仍然存在。
事务控制
以下命令用于控制事务:
**BEGIN TRANSACTION** - 开始事务。
**COMMIT** - 保存更改,或者您可以使用 **END TRANSACTION** 命令。
**ROLLBACK** - 回滚更改。
事务控制命令仅与 DML 命令 INSERT、UPDATE 和 DELETE 一起使用。在创建表或删除表时不能使用它们,因为这些操作会在数据库中自动提交。
BEGIN TRANSACTION 命令
可以使用 BEGIN TRANSACTION 或简单的 BEGIN 命令启动事务。此类事务通常持续到遇到下一个 COMMIT 或 ROLLBACK 命令为止。但是,如果数据库关闭或发生错误,事务也会回滚。
以下是启动事务的简单语法:
BEGIN; or BEGIN TRANSACTION;
COMMIT 命令
COMMIT 命令是用于将事务调用的更改保存到数据库的事务命令。
COMMIT 命令将自上次 COMMIT 或 ROLLBACK 命令以来所有事务保存到数据库。
COMMIT 命令的语法如下:
COMMIT; or END TRANSACTION;
ROLLBACK 命令
ROLLBACK 命令是用于撤消尚未保存到数据库的事务的事务命令。
ROLLBACK 命令只能用于撤消自发出上次 COMMIT 或 ROLLBACK 命令以来的事务。
ROLLBACK 命令的语法如下:
ROLLBACK;
示例
假设 COMPANY 表具有以下记录:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
现在,让我们开始一个事务并删除表中 age = 25 的记录,最后我们使用 ROLLBACK 命令撤消所有更改。
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; ROLLBACK;
如果您检查 COMPANY 表,它仍然具有以下记录:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
现在,让我们开始另一个事务并删除表中 age = 25 的记录,最后我们使用 COMMIT 命令提交所有更改。
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; COMMIT;
如果您检查 COMPANY 表,它仍然具有以下记录:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (5 rows)
PostgreSQL - 锁
锁或排他锁或写锁阻止用户修改行或整个表。UPDATE 和 DELETE 修改的行将自动在事务持续时间内被排他锁定。这将防止其他用户更改该行,直到事务提交或回滚。
用户必须等待其他用户的情况只发生在他们试图修改同一行时。如果他们修改不同的行,则无需等待。SELECT 查询永远不需要等待。
数据库自动执行锁定。但是,在某些情况下,必须手动控制锁定。可以使用 LOCK 命令进行手动锁定。它允许指定事务的锁类型和范围。
LOCK 命令的语法
LOCK 命令的基本语法如下:
LOCK [ TABLE ] name IN lock_mode
**name** - 要锁定的现有表的名称(可选地限定模式)。如果在表名前指定 ONLY,则只锁定该表。如果未指定 ONLY,则锁定该表及其所有子表(如果有)。
**lock_mode** - 锁模式指定此锁与哪些锁冲突。如果没有指定锁模式,则使用 ACCESS EXCLUSIVE(最严格的模式)。可能的值为:ACCESS SHARE、ROW SHARE、ROW EXCLUSIVE、SHARE UPDATE EXCLUSIVE、SHARE、SHARE ROW EXCLUSIVE、EXCLUSIVE、ACCESS EXCLUSIVE。
一旦获得,锁将在当前事务的剩余时间内保持。没有 UNLOCK TABLE 命令;锁总是在事务结束时释放。
死锁
当两个事务都在等待对方完成其操作时,可能会发生死锁。虽然 PostgreSQL 可以检测到它们并使用 ROLLBACK 结束它们,但死锁仍然可能带来不便。为了防止您的应用程序遇到此问题,请确保以这样一种方式设计它们,即它们将以相同的顺序锁定对象。
建议锁
PostgreSQL 提供了创建具有应用程序定义含义的锁的方法。这些称为建议锁。由于系统不强制执行其使用,因此应用程序应正确使用它们。建议锁可用于对 MVCC 模型不合适的锁定策略。
例如,建议锁的常见用途是模拟所谓的“平面文件”数据管理系统中典型的悲观锁定策略。虽然存储在表中的标志可以用于相同的目的,但建议锁更快,避免表膨胀,并且在会话结束时由服务器自动清除。
示例
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下示例以 ACCESS EXCLUSIVE 模式锁定 testdb 数据库中的 COMPANY 表。LOCK 语句仅在事务模式下有效:
testdb=#BEGIN; LOCK TABLE company1 IN ACCESS EXCLUSIVE MODE;
上述 PostgreSQL 语句将产生以下结果:
LOCK TABLE
以上消息表明表已锁定,直到事务结束,要结束事务,您必须回滚或提交事务。
PostgreSQL - 子查询
子查询或内部查询或嵌套查询是另一个 PostgreSQL 查询中的查询,并嵌入在 WHERE 子句中。
子查询用于返回将在主查询中用作条件的数据,以进一步限制要检索的数据。
子查询可以与 SELECT、INSERT、UPDATE 和 DELETE 语句以及 =、<、>、>=、<=、IN 等运算符一起使用。
子查询必须遵循以下一些规则:
子查询必须用括号括起来。
除非子查询的多个列用于主查询比较其选择的列,否则子查询的 SELECT 子句中只能有一列。
虽然主查询可以使用 ORDER BY,但在子查询中不能使用 ORDER BY。GROUP BY 可用于执行与子查询中的 ORDER BY 相同的功能。
返回多行的子查询只能与多值运算符一起使用,例如 IN、EXISTS、NOT IN、ANY/SOME、ALL 运算符。
BETWEEN 运算符不能与子查询一起使用;但是,BETWEEN 可在子查询中使用。
带有 SELECT 语句的子查询
子查询最常与 SELECT 语句一起使用。基本语法如下:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
示例
假设 COMPANY 表具有以下记录:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
现在,让我们检查带有 SELECT 语句的以下子查询:
testdb=# SELECT *
FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY
WHERE SALARY > 45000) ;
这将产生以下结果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
带有 INSERT 语句的子查询
子查询也可以与 INSERT 语句一起使用。INSERT 语句使用子查询返回的数据插入另一个表。子查询中的选定数据可以使用任何字符、日期或数字函数进行修改。
基本语法如下:
INSERT INTO table_name [ (column1 [, column2 ]) ] SELECT [ *|column1 [, column2 ] ] FROM table1 [, table2 ] [ WHERE VALUE OPERATOR ]
示例
考虑一个表 COMPANY_BKP,其结构与 COMPANY 表类似,可以使用相同的 CREATE TABLE 语句创建,使用 COMPANY_BKP 作为表名。现在,要将完整的 COMPANY 表复制到 COMPANY_BKP,语法如下:
testdb=# INSERT INTO COMPANY_BKP
SELECT * FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY) ;
带有 UPDATE 语句的子查询
子查询可以与 UPDATE 语句一起使用。使用子查询与 UPDATE 语句时,可以更新表中的单个列或多个列。
基本语法如下:
UPDATE table SET column_name = new_value [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
示例
假设我们有 COMPANY_BKP 表可用,它是 COMPANY 表的备份。
以下示例将 COMPANY 表中所有年龄大于或等于 27 的客户的 SALARY 更新为 0.50 倍:
testdb=# UPDATE COMPANY
SET SALARY = SALARY * 0.50
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE >= 27 );
这将影响两行,最后 COMPANY 表将具有以下记录:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 1 | Paul | 32 | California | 10000 5 | David | 27 | Texas | 42500 (7 rows)
带有 DELETE 语句的子查询
子查询可以与 DELETE 语句一起使用,就像上面提到的任何其他语句一样。
基本语法如下:
DELETE FROM TABLE_NAME [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
示例
假设我们有 COMPANY_BKP 表可用,它是 COMPANY 表的备份。
以下示例删除 COMPANY 表中所有年龄大于或等于 27 的客户的记录:
testdb=# DELETE FROM COMPANY
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE > 27 );
这将影响两行,最后 COMPANY 表将具有以下记录:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 5 | David | 27 | Texas | 42500 (6 rows)
PostgreSQL - 自动递增
PostgreSQL 具有数据类型smallserial、serial 和bigserial;这些不是真正的类型,而只是创建唯一标识符列的符号约定。它们类似于其他一些数据库支持的 AUTO_INCREMENT 属性。
如果您希望serial列具有唯一约束或主键,则现在必须像任何其他数据类型一样指定它。
类型名称serial创建integer类型的列。类型名称bigserial创建一个bigint类型的列。如果预计表在其生命周期内将使用超过231个标识符,则应使用bigserial。类型名称smallserial创建一个smallint类型的列。
语法
SERIAL 数据类型的基本用法如下:
CREATE TABLE tablename ( colname SERIAL );
示例
假设要创建名为COMPANY的表,如下所示:
testdb=# CREATE TABLE COMPANY( ID SERIAL PRIMARY KEY, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
现在,将以下记录插入COMPANY表中:
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Kim', 22, 'South-Hall', 45000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'James', 24, 'Houston', 10000.00 );
这将向COMPANY表插入七个元组,COMPANY表将包含以下记录:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
PostgreSQL - 权限
在数据库中创建对象时,会为其分配一个所有者。所有者通常是执行创建语句的人。对于大多数类型的对象,初始状态是只有所有者(或超级用户)才能修改或删除该对象。要允许其他角色或用户使用它,必须授予权限或许可。
PostgreSQL 中的不同类型的权限包括:
- SELECT(选择)
- INSERT(插入)
- UPDATE(更新)
- DELETE(删除)
- TRUNCATE(截断)
- REFERENCES(引用)
- TRIGGER(触发器)
- CREATE(创建)
- CONNECT(连接)
- TEMPORARY(临时)
- EXECUTE(执行) 和
- USAGE(使用)
根据对象的类型(表、函数等),权限将应用于该对象。要为用户分配权限,可以使用GRANT命令。
GRANT 语法
GRANT命令的基本语法如下:
GRANT privilege [, ...]
ON object [, ...]
TO { PUBLIC | GROUP group | username }
privilege - 值可以是:SELECT、INSERT、UPDATE、DELETE、RULE、ALL。
object - 要授予访问权限的对象的名称。可能的对象包括:表、视图、序列。
PUBLIC - 代表所有用户的简写形式。
GROUP group - 要授予权限的组。
username - 要授予权限的用户名称。PUBLIC是代表所有用户的简写形式。
可以使用REVOKE命令撤销权限。
REVOKE 语法
REVOKE命令的基本语法如下:
REVOKE privilege [, ...]
ON object [, ...]
FROM { PUBLIC | GROUP groupname | username }
privilege - 值可以是:SELECT、INSERT、UPDATE、DELETE、RULE、ALL。
object - 要授予访问权限的对象的名称。可能的对象包括:表、视图、序列。
PUBLIC - 代表所有用户的简写形式。
GROUP group - 要授予权限的组。
username - 要授予权限的用户名称。PUBLIC是代表所有用户的简写形式。
示例
为了理解权限,让我们首先创建一个用户,如下所示:
testdb=# CREATE USER manisha WITH PASSWORD 'password'; CREATE ROLE
消息CREATE ROLE表示已创建用户“manisha”。
考虑表 COMPANY,其记录如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
接下来,让我们向用户“manisha”授予COMPANY表的所有权限,如下所示:
testdb=# GRANT ALL ON COMPANY TO manisha; GRANT
消息GRANT表示所有权限都已分配给用户。
接下来,让我们从用户“manisha”撤销权限,如下所示:
testdb=# REVOKE ALL ON COMPANY FROM manisha; REVOKE
消息REVOKE表示所有权限都已从用户撤销。
您甚至可以删除用户,如下所示:
testdb=# DROP USER manisha; DROP ROLE
消息DROP ROLE表示用户“Manisha”已从数据库中删除。
PostgreSQL - 日期/时间函数和运算符
我们在数据类型章节中讨论了日期/时间数据类型。现在,让我们看看日期/时间运算符和函数。
下表列出了基本算术运算符的行为:
| 运算符 | 示例 | 结果 |
|---|---|---|
| + | date '2001-09-28' + integer '7' | date '2001-10-05' |
| + | date '2001-09-28' + interval '1 hour' | timestamp '2001-09-28 01:00:00' |
| + | date '2001-09-28' + time '03:00' | timestamp '2001-09-28 03:00:00' |
| + | interval '1 day' + interval '1 hour' | interval '1 day 01:00:00' |
| + | timestamp '2001-09-28 01:00' + interval '23 hours' | timestamp '2001-09-29 00:00:00' |
| + | time '01:00' + interval '3 hours' | time '04:00:00' |
| - | - interval '23 hours' | interval '-23:00:00' |
| - | date '2001-10-01' - date '2001-09-28' | integer '3'(天) |
| - | date '2001-10-01' - integer '7' | date '2001-09-24' |
| - | date '2001-09-28' - interval '1 hour' | timestamp '2001-09-27 23:00:00' |
| - | time '05:00' - time '03:00' | interval '02:00:00' |
| - | time '05:00' - interval '2 hours' | time '03:00:00' |
| - | timestamp '2001-09-28 23:00' - interval '23 hours' | timestamp '2001-09-28 00:00:00' |
| - | interval '1 day' - interval '1 hour' | interval '1 day -01:00:00' |
| - | timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00' | interval '1 day 15:00:00' |
| * | 900 * interval '1 second' | interval '00:15:00' |
| * | 21 * interval '1 day' | interval '21 days' |
| * | double precision '3.5' * interval '1 hour' | interval '03:30:00' |
| / | interval '1 hour' / double precision '1.5' | interval '00:40:00' |
以下是所有重要的日期和时间相关函数列表。
| 序号 | 函数和说明 |
|---|---|
| 1 | AGE()
相减 |
| 2 | CURRENT_DATE/TIME()
当前日期和时间 |
| 3 | DATE_PART()
获取子字段(等效于extract) |
| 4 | EXTRACT()
获取子字段 |
| 5 | ISFINITE()
测试有限的日期、时间和区间(不是 +/-infinity) |
| 6 | JUSTIFY
调整区间 |
AGE(timestamp, timestamp), AGE(timestamp)
| 序号 | 函数和说明 |
|---|---|
| 1 | AGE(timestamp, timestamp) 当使用TIMESTAMP形式的第二个参数调用时,AGE()会相减,产生一个使用年和月的“符号”结果,类型为INTERVAL。 |
| 2 | AGE(timestamp) 当只使用TIMESTAMP作为参数调用时,AGE()会从current_date(午夜)相减。 |
函数AGE(timestamp, timestamp)的示例:
testdb=# SELECT AGE(timestamp '2001-04-10', timestamp '1957-06-13');
上述 PostgreSQL 语句将产生以下结果:
age ------------------------- 43 years 9 mons 27 days
函数AGE(timestamp)的示例:
testdb=# select age(timestamp '1957-06-13');
上述 PostgreSQL 语句将产生以下结果:
age -------------------------- 55 years 10 mons 22 days
CURRENT_DATE/TIME()
PostgreSQL提供许多函数,这些函数返回与当前日期和时间相关的数值。以下是一些函数:
| 序号 | 函数和说明 |
|---|---|
| 1 | CURRENT_DATE 返回当前日期。 |
| 2 | CURRENT_TIME 返回带时区的数值。 |
| 3 | CURRENT_TIMESTAMP 返回带时区的数值。 |
| 4 | CURRENT_TIME(precision) 可以选择一个精度参数,这将导致结果四舍五入到秒字段中的那么多小数位。 |
| 5 | CURRENT_TIMESTAMP(precision) 可以选择一个精度参数,这将导致结果四舍五入到秒字段中的那么多小数位。 |
| 6 | LOCALTIME 返回不带时区的数值。 |
| 7 | LOCALTIMESTAMP 返回不带时区的数值。 |
| 8 | LOCALTIME(precision) 可以选择一个精度参数,这将导致结果四舍五入到秒字段中的那么多小数位。 |
| 9 | LOCALTIMESTAMP(precision) 可以选择一个精度参数,这将导致结果四舍五入到秒字段中的那么多小数位。 |
使用上表中函数的示例:
testdb=# SELECT CURRENT_TIME;
timetz
--------------------
08:01:34.656+05:30
(1 row)
testdb=# SELECT CURRENT_DATE;
date
------------
2013-05-05
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP;
now
-------------------------------
2013-05-05 08:01:45.375+05:30
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP(2);
timestamptz
------------------------------
2013-05-05 08:01:50.89+05:30
(1 row)
testdb=# SELECT LOCALTIMESTAMP;
timestamp
------------------------
2013-05-05 08:01:55.75
(1 row)
PostgreSQL还提供返回当前语句的开始时间以及函数调用时实际当前时间的函数。这些函数包括:
| 序号 | 函数和说明 |
|---|---|
| 1 | transaction_timestamp() 它等效于CURRENT_TIMESTAMP,但名称清楚地反映了它返回的内容。 |
| 2 | statement_timestamp() 它返回当前语句的开始时间。 |
| 3 | clock_timestamp() 它返回实际的当前时间,因此其值即使在单个SQL命令内也会发生变化。 |
| 4 | timeofday() 它返回实际的当前时间,但作为格式化的文本字符串而不是带有时区的timestamp值。 |
| 5 | now() 它是transaction_timestamp()的传统PostgreSQL等效项。 |
DATE_PART(text, timestamp), DATE_PART(text, interval), DATE_TRUNC(text, timestamp)
| 序号 | 函数和说明 |
|---|---|
| 1 | DATE_PART('field', source) 这些函数获取子字段。field参数需要是一个字符串值,而不是名称。 有效的字段名称包括:century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year。 |
| 2 | DATE_TRUNC('field', source) 此函数在概念上类似于数字的trunc函数。source是类型为timestamp或interval的值表达式。field选择将输入值截断到哪个精度。返回值的类型为timestamp或interval。 field的有效值包括:microseconds, milliseconds, second, minute, hour, day, week, month, quarter, year, decade, century, millennium |
以下是DATE_PART('field', source)函数的示例:
testdb=# SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
testdb=# SELECT date_part('hour', INTERVAL '4 hours 3 minutes');
date_part
-----------
4
(1 row)
以下是DATE_TRUNC('field', source)函数的示例:
testdb=# SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-02-16 20:00:00
(1 row)
testdb=# SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-01-01 00:00:00
(1 row)
EXTRACT(field from timestamp), EXTRACT(field from interval)
EXTRACT(field FROM source)函数从日期/时间值中检索子字段,例如年份或小时。source必须是类型为timestamp、time或interval的值表达式。field是标识符或字符串,用于选择从源值中提取哪个字段。EXTRACT函数返回类型为double precision的值。
以下是有效的字段名称(类似于DATE_PART函数字段名称):century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year。
以下是EXTRACT('field', source)函数的示例:
testdb=# SELECT EXTRACT(CENTURY FROM TIMESTAMP '2000-12-16 12:21:13');
date_part
-----------
20
(1 row)
testdb=# SELECT EXTRACT(DAY FROM TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
ISFINITE(date), ISFINITE(timestamp), ISFINITE(interval)
| 序号 | 函数和说明 |
|---|---|
| 1 | ISFINITE(date) 测试有限日期。 |
| 2 | ISFINITE(timestamp) 测试有限时间戳。 |
| 3 | ISFINITE(interval) 测试有限区间。 |
以下是ISFINITE()函数的示例:
testdb=# SELECT isfinite(date '2001-02-16'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(timestamp '2001-02-16 21:28:30'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(interval '4 hours'); isfinite ---------- t (1 row)
JUSTIFY_DAYS(interval), JUSTIFY_HOURS(interval), JUSTIFY_INTERVAL(interval)
| 序号 | 函数和说明 |
|---|---|
| 1 | JUSTIFY_DAYS(interval) 调整区间,使30天的时间段表示为月份。返回interval类型 |
| 2 | JUSTIFY_HOURS(interval) 调整区间,使24小时的时间段表示为天。返回interval类型 |
| 3 | JUSTIFY_INTERVAL(interval) 使用JUSTIFY_DAYS和JUSTIFY_HOURS调整区间,并进行额外的符号调整。返回interval类型 |
以下是ISFINITE()函数的示例:
testdb=# SELECT justify_days(interval '35 days'); justify_days -------------- 1 mon 5 days (1 row) testdb=# SELECT justify_hours(interval '27 hours'); justify_hours ---------------- 1 day 03:00:00 (1 row) testdb=# SELECT justify_interval(interval '1 mon -1 hour'); justify_interval ------------------ 29 days 23:00:00 (1 row)
PostgreSQL - 函数
PostgreSQL函数,也称为存储过程,允许您在一个数据库内的单个函数中执行通常需要多个查询和往返操作的操作。函数允许数据库重用,因为其他应用程序可以直接与您的存储过程交互,而不是中间层或重复代码。
函数可以用您选择的语言创建,例如SQL、PL/pgSQL、C、Python等。
语法
创建函数的基本语法如下:
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
其中:
function-name 指定函数的名称。
[OR REPLACE]选项允许修改现有函数。
函数必须包含return语句。
RETURN子句指定您将从函数返回的数据类型。return_datatype可以是基本类型、复合类型或域类型,也可以引用表列的类型。
function-body包含可执行部分。
AS关键字用于创建独立函数。
plpgsql是实现函数的语言的名称。在这里,我们为PostgreSQL使用此选项,它可以是SQL、C、内部或用户定义的过程语言的名称。为了向后兼容性,名称可以用单引号括起来。
示例
以下示例说明了创建和调用独立函数。此函数返回COMPANY表中的记录总数。我们将使用COMPANY表,该表包含以下记录:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
函数totalRecords()如下:
CREATE OR REPLACE FUNCTION totalRecords () RETURNS integer AS $total$ declare total integer; BEGIN SELECT count(*) into total FROM COMPANY; RETURN total; END; $total$ LANGUAGE plpgsql;
执行上述查询后,结果将是:
testdb# CREATE FUNCTION
现在,让我们执行对该函数的调用并检查COMPANY表中的记录
testdb=# select totalRecords();
执行上述查询后,结果将是:
totalrecords
--------------
7
(1 row)
PostgreSQL - 常用函数
PostgreSQL内置函数,也称为聚合函数,用于对字符串或数值数据进行处理。
以下是所有 PostgreSQL 通用内置函数的列表:
PostgreSQL COUNT 函数 − PostgreSQL COUNT 聚合函数用于计算数据库表中的行数。
PostgreSQL MAX 函数 − PostgreSQL MAX 聚合函数允许我们选择特定列的最高(最大)值。
PostgreSQL MIN 函数 − PostgreSQL MIN 聚合函数允许我们选择特定列的最低(最小)值。
PostgreSQL AVG 函数 − PostgreSQL AVG 聚合函数选择特定表列的平均值。
PostgreSQL SUM 函数 − PostgreSQL SUM 聚合函数允许选择数值列的总和。
PostgreSQL 数组函数 − PostgreSQL 数组聚合函数将输入值(包括空值)连接到一个数组中。
PostgreSQL 数值函数 − 在 SQL 中操作数字所需 PostgreSQL 函数的完整列表。
PostgreSQL 字符串函数 − 在 PostgreSQL 中操作字符串所需 PostgreSQL 函数的完整列表。
PostgreSQL - C/C++ 接口
本教程将使用libpqxx库,它是 PostgreSQL 的官方 C++ 客户端 API。libpqxx 的源代码可在 BSD 许可下获得,因此您可以自由下载、传递给他人、更改、出售、将其包含在您自己的代码中,以及与您选择的任何人共享您的更改。
安装
libpqxx 的最新版本可从以下链接下载 下载 Libpqxx。下载最新版本并按照以下步骤操作:
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz tar xvfz libpqxx-4.0.tar.gz cd libpqxx-4.0 ./configure make make install
在开始使用 C/C++ PostgreSQL 接口之前,请在您的 PostgreSQL 安装目录中找到pg_hba.conf文件并添加以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 服务器未运行,您可以使用以下命令启动/重启它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
C/C++ 接口 API
以下是重要的接口例程,可以满足您从 C/C++ 程序与 PostgreSQL 数据库交互的需求。如果您正在寻找更复杂的应用程序,您可以查看 libpqxx 官方文档,或者可以使用商业 API。
| 序号 | API 和描述 |
|---|---|
| 1 | pqxx::connection C( const std::string & dbstring ) 这是一个 typedef,用于连接到数据库。在这里,dbstring 提供连接到数据库所需的参数,例如 dbname = testdb user = postgres password=pass123 hostaddr=127.0.0.1 port=5432。 如果连接成功设置,则它将创建具有连接对象的 C,该对象提供各种有用的公共函数。 |
| 2 | C.is_open() is_open() 方法是连接对象的公共方法,并返回布尔值。如果连接处于活动状态,则此方法返回 true,否则返回 false。 |
| 3 | C.disconnect() 此方法用于断开打开的数据库连接。 |
| 4 | pqxx::work W( C ) 这是一个 typedef,用于使用连接 C 创建事务对象,最终用于以事务模式执行 SQL 语句。 如果事务对象创建成功,则将其分配给变量 W,该变量将用于访问与事务对象相关的公共方法。 |
| 5 |
W.exec(const std::string & sql) 事务对象的此公共方法将用于执行 SQL 语句。 |
| 6 |
W.commit() 事务对象的此公共方法将用于提交事务。 |
| 7 |
W.abort() 事务对象的此公共方法将用于回滚事务。 |
| 8 | pqxx::nontransaction N( C ) 这是一个 typedef,用于使用连接 C 创建非事务对象,最终用于以非事务模式执行 SQL 语句。 如果事务对象创建成功,则将其分配给变量 N,该变量将用于访问与非事务对象相关的公共方法。 |
| 9 | N.exec(const std::string & sql) 非事务对象的此公共方法将用于执行 SQL 语句并返回结果对象,该对象实际上是一个持有所有返回记录的迭代器。 |
连接到数据库
以下 C 代码段显示如何连接到在本地机器的端口 5432 上运行的现有数据库。在这里,我使用反斜杠 \ 来进行续行。
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
}
现在,让我们编译并运行上述程序以连接到我们的数据库testdb,该数据库已存在于您的模式中,并且可以使用用户postgres和密码pass123访问。
您可以根据您的数据库设置使用用户 ID 和密码。请记住按顺序保留 -lpqxx 和 -lpq!否则,链接器将抱怨缺少名称以“PQ.”开头的函数。
$g++ test.cpp -lpqxx -lpq $./a.out Opened database successfully: testdb
创建表
以下 C 代码段将用于在先前创建的数据库中创建表:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Table created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
编译并执行上述程序后,它将在您的 testdb 数据库中创建 COMPANY 表,并显示以下语句:
Opened database successfully: testdb Table created successfully
INSERT 操作
以下 C 代码段显示了如何在上面示例中创建的 COMPANY 表中创建记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
编译并执行上述程序后,它将在 COMPANY 表中创建给定的记录,并显示以下两行:
Opened database successfully: testdb Records created successfully
SELECT 操作
以下 C 代码段显示了如何获取和显示上面示例中创建的 COMPANY 表中的记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
编译并执行上述程序后,将产生以下结果:
Opened database successfully: testdb ID = 1 Name = Paul Age = 32 Address = California Salary = 20000 ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 Operation done successfully
UPDATE 操作
以下 C 代码段显示了如何使用 UPDATE 语句更新任何记录,然后获取和显示 COMPANY 表中更新的记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL UPDATE statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records updated successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
编译并执行上述程序后,将产生以下结果:
Opened database successfully: testdb Records updated successfully ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
DELETE 操作
以下 C 代码段显示了如何使用 DELETE 语句删除任何记录,然后获取和显示 COMPANY 表中剩余的记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL DELETE statement */
sql = "DELETE from COMPANY where ID = 2";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records deleted successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
编译并执行上述程序后,将产生以下结果:
Opened database successfully: testdb Records deleted successfully ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
PostgreSQL - JAVA 接口
安装
在我们的 Java 程序中开始使用 PostgreSQL 之前,我们需要确保机器上已设置 PostgreSQL JDBC 和 Java。您可以查看 Java 教程,了解如何在您的机器上安装 Java。现在让我们检查如何设置 PostgreSQL JDBC 驱动程序。
从 postgresql-jdbc 存储库下载最新版本的postgresql-(VERSION).jdbc.jar。
将下载的 jar 文件postgresql-(VERSION).jdbc.jar添加到您的类路径中,或者您可以将其与 -classpath 选项一起使用,如下面的示例中所述。
以下部分假设您对 Java JDBC 概念略知一二。如果您没有,建议您花半小时时间学习 JDBC 教程,以便熟悉下面解释的概念。
连接到数据库
以下 Java 代码显示了如何连接到现有数据库。如果数据库不存在,则会创建它,最后返回数据库对象。
import java.sql.Connection;
import java.sql.DriverManager;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"postgres", "123");
} catch (Exception e) {
e.printStackTrace();
System.err.println(e.getClass().getName()+": "+e.getMessage());
System.exit(0);
}
System.out.println("Opened database successfully");
}
}
在编译和运行上述程序之前,请在您的 PostgreSQL 安装目录中找到pg_hba.conf文件并添加以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 服务器未运行,您可以使用以下命令启动/重新启动它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
现在,让我们编译并运行上述程序以连接到 testdb。在这里,我们使用postgres作为用户 ID,使用123作为密码来访问数据库。您可以根据您的数据库配置和设置更改此设置。我们还假设当前版本的 JDBC 驱动程序postgresql-9.2-1002.jdbc3.jar在当前路径中可用。
C:\JavaPostgresIntegration>javac PostgreSQLJDBC.java C:\JavaPostgresIntegration>java -cp c:\tools\postgresql-9.2-1002.jdbc3.jar;C:\JavaPostgresIntegration PostgreSQLJDBC Open database successfully
创建表
以下 Java 程序将用于在先前打开的数据库中创建表。确保您的目标数据库中不存在此表。
import java.sql.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "CREATE TABLE COMPANY " +
"(ID INT PRIMARY KEY NOT NULL," +
" NAME TEXT NOT NULL, " +
" AGE INT NOT NULL, " +
" ADDRESS CHAR(50), " +
" SALARY REAL)";
stmt.executeUpdate(sql);
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Table created successfully");
}
}
编译并执行程序后,它将在testdb数据库中创建 COMPANY 表,并显示以下两行:
Opened database successfully Table created successfully
INSERT 操作
以下 Java 程序显示了如何在上面示例中创建的 COMPANY 表中创建记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (1, 'Paul', 32, 'California', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (2, 'Allen', 25, 'Texas', 15000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
stmt.executeUpdate(sql);
stmt.close();
c.commit();
c.close();
} catch (Exception e) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Records created successfully");
}
}
编译并执行上述程序后,它将在 COMPANY 表中创建给定的记录,并显示以下两行:
Opened database successfully Records created successfully
SELECT 操作
以下 Java 程序显示了如何获取和显示上面示例中创建的 COMPANY 表中的记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
编译并执行程序后,将产生以下结果:
Opened database successfully ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE 操作
以下 Java 代码显示了如何使用 UPDATE 语句更新任何记录,然后获取和显示 COMPANY 表中更新的记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
编译并执行程序后,将产生以下结果:
Opened database successfully ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
DELETE 操作
以下 Java 代码显示了如何使用 DELETE 语句删除任何记录,然后获取和显示 COMPANY 表中剩余的记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC6 {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "DELETE from COMPANY where ID = 2;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
编译并执行程序后,将产生以下结果:
Opened database successfully ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
PostgreSQL - PHP 接口
安装
PostgreSQL 扩展在最新版本的 PHP 5.3.x 中默认启用。可以使用--without-pgsql在编译时禁用它。您仍然可以使用 yum 命令安装 PHP -PostgreSQL 接口:
yum install php-pgsql
在开始使用 PHP PostgreSQL 接口之前,请在您的 PostgreSQL 安装目录中找到pg_hba.conf文件并添加以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 服务器未运行,您可以使用以下命令启动/重新启动它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Windows 用户必须启用 php_pgsql.dll 才能使用此扩展。此 DLL 包含在最新版本的 PHP 5.3.x 的 Windows 发行版中。
有关详细的安装说明,请查看我们的 PHP 教程及其官方网站。
PHP 接口 API
以下是重要的 PHP 例程,可以满足您从 PHP 程序与 PostgreSQL 数据库交互的需求。如果您正在寻找更复杂的应用程序,您可以查看 PHP 官方文档。
| 序号 | API 和描述 |
|---|---|
| 1 | resource pg_connect ( string $connection_string [, int $connect_type ] ) 这将打开到由 connection_string 指定的 PostgreSQL 数据库的连接。 如果将 PGSQL_CONNECT_FORCE_NEW 作为 connect_type 传递,则即使 connection_string 与现有连接相同,在第二次调用 pg_connect() 时也会创建一个新连接。 |
| 2 | bool pg_connection_reset ( resource $connection ) 此例程重置连接。它对错误恢复很有用。成功时返回 TRUE,失败时返回 FALSE。 |
| 3 | int pg_connection_status ( resource $connection ) 此例程返回指定连接的状态。返回 PGSQL_CONNECTION_OK 或 PGSQL_CONNECTION_BAD。 |
| 4 | string pg_dbname ([ resource $connection ] ) 此函数返回给定 PostgreSQL 连接资源所连接的数据库名称。 |
| 5 | resource pg_prepare ([ resource $connection ], string $stmtname, string $query ) 此函数提交创建预处理语句的请求,并等待其完成。 |
| 6 | resource pg_execute ([ resource $connection ], string $stmtname, array $params ) 此函数发送执行带有给定参数的预处理语句的请求,并等待结果。 |
| 7 | resource pg_query ([ resource $connection ], string $query ) 此函数在指定的数据库连接上执行查询。 |
| 8 | array pg_fetch_row ( resource $result [, int $row ] ) 此函数从与指定结果资源关联的结果集中获取一行数据。 |
| 9 | array pg_fetch_all ( resource $result ) 此函数返回一个数组,其中包含结果资源中的所有行(记录)。 |
| 10 | int pg_affected_rows ( resource $result ) 此函数返回 INSERT、UPDATE 和 DELETE 查询影响的行数。 |
| 11 | int pg_num_rows ( resource $result ) 此函数返回 PostgreSQL 结果资源中的行数,例如 SELECT 语句返回的行数。 |
| 12 | bool pg_close ([ resource $connection ] ) 此函数关闭与给定连接资源关联的非持久性 PostgreSQL 数据库连接。 |
| 13 | string pg_last_error ([ resource $connection ] ) 此函数返回给定连接的最后一条错误消息。 |
| 14 | string pg_escape_literal ([ resource $connection ], string $data ) 此函数转义字面量,以便将其插入文本字段。 |
| 15 | string pg_escape_string ([ resource $connection ], string $data ) 此函数转义字符串,以便用于数据库查询。 |
连接数据库
以下 PHP 代码演示了如何连接到本地机器上的现有数据库,最终将返回一个数据库连接对象。
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
?>
现在,让我们运行上述程序打开我们的数据库 **testdb**: 如果数据库成功打开,则会显示以下消息:
Opened database successfully
创建表
以下 PHP 程序将用于在先前创建的数据库中创建表:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Table created successfully\n";
}
pg_close($db);
?>
执行上述程序后,它将在您的 **testdb** 中创建 COMPANY 表,并显示以下消息:
Opened database successfully Table created successfully
INSERT 操作
以下 PHP 程序演示了如何在我们上面示例中创建的 COMPANY 表中创建记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Records created successfully\n";
}
pg_close($db);
?>
执行上述程序后,它将在 COMPANY 表中创建给定的记录,并显示以下两行:
Opened database successfully Records created successfully
SELECT 操作
以下 PHP 程序演示了如何从我们上面示例中创建的 COMPANY 表中获取和显示记录:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
执行上述程序后,将产生以下结果。请注意,字段按创建表时使用的顺序返回。
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE 操作
以下 PHP 代码演示了如何使用 UPDATE 语句更新任何记录,然后从我们的 COMPANY 表中获取和显示更新后的记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
UPDATE COMPANY set SALARY = 25000.00 where ID=1;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record updated successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
执行上述程序后,将产生以下结果:
Opened database successfully Record updated successfully ID = 2 NAME = Allen ADDRESS = 25 SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
DELETE 操作
以下 PHP 代码演示了如何使用 DELETE 语句删除任何记录,然后从我们的 COMPANY 表中获取和显示剩余的记录:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
DELETE from COMPANY where ID=2;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record deleted successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
执行上述程序后,将产生以下结果:
Opened database successfully Record deleted successfully ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
PostgreSQL - Perl 接口
安装
PostgreSQL 可以使用 Perl DBI 模块与 Perl 集成,这是一个用于 Perl 编程语言的数据库访问模块。它定义了一组方法、变量和约定,这些方法、变量和约定提供了一个标准的数据库接口。
以下是您在 Linux/Unix 机器上安装 DBI 模块的简单步骤:
$ wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.625.tar.gz $ tar xvfz DBI-1.625.tar.gz $ cd DBI-1.625 $ perl Makefile.PL $ make $ make install
如果您需要为 DBI 安装 SQLite 驱动程序,则可以按如下方式安装:
$ wget http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/DBD-Pg-2.19.3.tar.gz $ tar xvfz DBD-Pg-2.19.3.tar.gz $ cd DBD-Pg-2.19.3 $ perl Makefile.PL $ make $ make install
在开始使用 Perl PostgreSQL 接口之前,请在您的 PostgreSQL 安装目录中找到 **pg_hba.conf** 文件并添加以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 服务器未运行,您可以使用以下命令启动/重新启动它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
DBI 接口 API
以下是重要的 DBI 函数,这些函数足以满足您从 Perl 程序使用 SQLite 数据库的要求。如果您正在寻找更复杂的应用程序,则可以查阅 Perl DBI 官方文档。
| 序号 | API 和描述 |
|---|---|
| 1 | DBI→connect($data_source, "userid", "password", \%attr) 建立到请求的 $data_source 的数据库连接或会话。如果连接成功,则返回数据库句柄对象。 数据源具有如下形式:**DBI:Pg:dbname=$database;host=127.0.0.1;port=5432** Pg 是 PostgreSQL 驱动程序名称,testdb 是数据库名称。 |
| 2 | $dbh→do($sql) 此函数准备并执行单个 SQL 语句。返回受影响的行数,或在出错时返回 undef。返回值 -1 表示行数未知、不适用或不可用。这里 $dbh 是 DBI→connect() 调用返回的句柄。 |
| 3 | $dbh→prepare($sql) 此函数准备稍后由数据库引擎执行的语句,并返回对语句句柄对象的引用。 |
| 4 | $sth→execute() 此函数执行执行准备好的语句所需的任何处理。如果发生错误,则返回 undef。成功的执行始终返回 true,无论受影响的行数是多少。这里 $sth 是 $dbh→prepare($sql) 调用返回的语句句柄。 |
| 5 | $sth→fetchrow_array() 此函数获取下一行数据,并将其作为包含字段值的列表返回。空字段在列表中返回为 undef 值。 |
| 6 | $DBI::err 这等效于 $h→err,其中 $h 是任何句柄类型,例如 $dbh、$sth 或 $drh。这将返回上次调用的驱动程序方法的本机数据库引擎错误代码。 |
| 7 | $DBI::errstr 这等效于 $h→errstr,其中 $h 是任何句柄类型,例如 $dbh、$sth 或 $drh。这将返回上次调用的 DBI 方法的本机数据库引擎错误消息。 |
| 8 | $dbh->disconnect() 此函数关闭先前由 DBI→connect() 调用打开的数据库连接。 |
连接数据库
以下 Perl 代码演示了如何连接到现有数据库。如果数据库不存在,则会创建它,最终将返回一个数据库对象。
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
现在,让我们运行上述程序打开我们的数据库 **testdb**;如果数据库成功打开,则会显示以下消息:
Open database successfully
创建表
以下 Perl 程序将用于在先前创建的数据库中创建表:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL););
my $rv = $dbh->do($stmt);
if($rv < 0) {
print $DBI::errstr;
} else {
print "Table created successfully\n";
}
$dbh->disconnect();
执行上述程序后,它将在您的 **testdb** 中创建 COMPANY 表,并显示以下消息:
Opened database successfully Table created successfully
INSERT 操作
以下 Perl 程序演示了如何在我们上面示例中创建的 COMPANY 表中创建记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 ));
my $rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ););
$rv = $dbh->do($stmt) or die $DBI::errstr;
print "Records created successfully\n";
$dbh->disconnect();
执行上述程序后,它将在 COMPANY 表中创建给定的记录,并显示以下两行:
Opened database successfully Records created successfully
SELECT 操作
以下 Perl 程序演示了如何从我们上面示例中创建的 COMPANY 表中获取和显示记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
my $rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序后,将产生以下结果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE 操作
以下 Perl 代码演示了如何使用 UPDATE 语句更新任何记录,然后从我们的 COMPANY 表中获取和显示更新后的记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(UPDATE COMPANY set SALARY = 25000.00 where ID=1;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
}else{
print "Total number of rows updated : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序后,将产生以下结果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
DELETE 操作
以下 Perl 代码演示了如何使用 DELETE 语句删除任何记录,然后从我们的 COMPANY 表中获取和显示剩余的记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(DELETE from COMPANY where ID=2;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
} else{
print "Total number of rows deleted : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序后,将产生以下结果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
PostgreSQL - Python 接口
安装
PostgreSQL 可以使用 psycopg2 模块与 Python 集成。psycopg2 是 Python 编程语言的 PostgreSQL 数据库适配器。psycopg2 的编写目标是体积小、速度快且稳定可靠。您不需要单独安装此模块,因为它默认情况下与 Python 2.5.x 及更高版本一起提供。
如果您的机器上没有安装它,则可以使用 yum 命令按如下方式安装:
$yum install python-psycopg2
要使用 psycopg2 模块,您必须首先创建一个表示数据库的 Connection 对象,然后您可以选择创建一个 cursor 对象,这将帮助您执行所有 SQL 语句。
Python psycopg2 模块 API
以下是重要的 psycopg2 模块函数,这些函数足以满足您从 Python 程序使用 PostgreSQL 数据库的要求。如果您正在寻找更复杂的应用程序,则可以查阅 Python psycopg2 模块的官方文档。
| 序号 | API 和描述 |
|---|---|
| 1 | psycopg2.connect(database="testdb", user="postgres", password="cohondob", host="127.0.0.1", port="5432") 此 API 打开到 PostgreSQL 数据库的连接。如果数据库成功打开,则返回一个连接对象。 |
| 2 | connection.cursor() 此函数创建一个 **游标**,它将在您使用 Python 进行数据库编程的整个过程中使用。 |
| 3 | cursor.execute(sql [, 可选参数]) 此函数执行 SQL 语句。SQL 语句可以是参数化的(即,使用占位符而不是 SQL 字面量)。psycopg2 模块使用 %s 符号支持占位符。 例如:cursor.execute("insert into people values (%s, %s)", (who, age)) |
| 4 | cursor.executemany(sql, seq_of_parameters) 此函数针对在序列 sql 中找到的所有参数序列或映射执行 SQL 命令。 |
| 5 | cursor.callproc(procname[, parameters]) 此函数执行具有给定名称的存储数据库过程。参数序列必须包含过程期望的每个参数的一个条目。 |
| 6 | cursor.rowcount 此只读属性返回上次 last execute*() 修改、插入或删除的数据库行总数。 |
| 7 | connection.commit() 此方法提交当前事务。如果您不调用此方法,则自上次调用 commit() 以来所做的任何操作都无法从其他数据库连接中看到。 |
| 8 | connection.rollback() 此方法回滚自上次调用 commit() 以来对数据库的任何更改。 |
| 9 | connection.close() 此方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您在先调用 commit() 之前关闭数据库连接,则您的更改将会丢失! |
| 10 | cursor.fetchone() 此方法获取查询结果集的下一行,返回单个序列,或者当没有更多数据可用时返回 None。 |
| 11 | cursor.fetchmany([size=cursor.arraysize]) 此函数获取查询结果的下一组行,返回一个列表。当没有更多行可用时,将返回一个空列表。此方法尝试获取与 size 参数指示的相同数量的行。 |
| 12 | cursor.fetchall() 此函数获取查询结果的所有(剩余)行,返回一个列表。当没有行可用时,将返回一个空列表。 |
连接数据库
以下 Python 代码演示了如何连接到现有数据库。如果数据库不存在,则会创建它,最终将返回一个数据库对象。
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database="testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully"
在这里,您还可以提供数据库 **testdb** 作为名称,如果数据库成功打开,则会显示以下消息:
Open database successfully
创建表
以下 Python 程序将用于在先前创建的数据库中创建表:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
执行上述程序后,它将在您的 **test.db** 中创建 COMPANY 表,并显示以下消息:
Opened database successfully Table created successfully
INSERT 操作
以下 Python 程序演示了如何在我们上面示例中创建的 COMPANY 表中创建记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print "Records created successfully";
conn.close()
执行上述程序后,它将在 COMPANY 表中创建给定的记录,并显示以下两行:
Opened database successfully Records created successfully
SELECT 操作
以下Python程序展示了如何从我们在上面示例中创建的COMPANY表中获取和显示记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序后,将产生以下结果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE 操作
以下Python代码展示了如何使用UPDATE语句更新任何记录,然后从我们的COMPANY表中获取和显示更新后的记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID = 1")
conn.commit()
print "Total number of rows updated :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序后,将产生以下结果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
DELETE 操作
以下Python代码展示了如何使用DELETE语句删除任何记录,然后从我们的COMPANY表中获取和显示剩余的记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序后,将产生以下结果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully