- SQLAlchemy 教程
- SQLAlchemy - 首页
- SQLAlchemy - 简介
- SQLAlchemy Core
- 表达式语言
- 连接数据库
- 创建表
- SQL 表达式
- 执行表达式
- 选择行
- 使用文本SQL
- 使用别名
- 使用UPDATE表达式
- 使用DELETE表达式
- 使用多表
- 使用多表更新
- 参数有序更新
- 多表删除
- 使用连接
- 使用连接词
- 使用函数
- 使用集合操作
- SQLAlchemy ORM
- 声明映射
- 创建会话
- 添加对象
- 使用查询
- 更新对象
- 应用过滤器
- 过滤器运算符
- 返回列表和标量
- 文本SQL
- 构建关系
- 处理相关对象
- 使用连接
- 常见关系运算符
- 提前加载
- 删除相关对象
- 多对多关系
- 方言
- SQLAlchemy 有用资源
- SQLAlchemy - 快速指南
- SQLAlchemy - 有用资源
- SQLAlchemy - 讨论
SQLAlchemy ORM - 声明映射
SQLAlchemy 的对象关系映射 (ORM) API 的主要目标是方便将用户定义的 Python 类与数据库表关联起来,并将这些类的对象与相应表中的行关联起来。对象的狀態变化和行的变化会同步匹配。SQLAlchemy 允许用用户定义的类及其定义的关系来表达数据库查询。
ORM 建立在 SQL 表达式语言之上。它是一种高级且抽象的用法模式。事实上,ORM 是表达式语言的一种应用用法。
虽然可以使用对象关系映射 (ORM) 独家构建成功的应用程序,但有时使用 ORM 构建的应用程序可能需要直接使用表达式语言来处理特定的数据库交互。
声明映射
首先,调用 `create_engine()` 函数来设置一个引擎对象,该对象随后用于执行 SQL 操作。该函数有两个参数,一个是数据库的名称,另一个是 `echo` 参数,当设置为 `True` 时将生成活动日志。如果数据库不存在,则会创建它。在下面的示例中,创建了一个 SQLite 数据库。
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
当调用 `Engine.execute()` 或 `Engine.connect()` 等方法时,引擎会建立与数据库的实际 DBAPI 连接。然后它用于发出 SQL,ORM 并不直接使用引擎;而是由 ORM 在幕后使用。
在 ORM 的情况下,配置过程从描述数据库表开始,然后定义将映射到这些表的类。在 SQLAlchemy 中,这两个任务一起执行。这是通过使用声明式系统完成的;创建的类包含描述它们映射到的实际数据库表的指令。
在声明式系统中,一个基类存储类的目录和映射的表。这被称为声明式基类。在一个常用的导入模块中,通常只有一个基类的实例。`declarative_base()` 函数用于创建基类。此函数定义在 `sqlalchemy.ext.declarative` 模块中。
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
一旦声明了基类,就可以根据它定义任意数量的映射类。下面的代码定义了一个客户类。它包含要映射到的表,以及表中列的名称和数据类型。
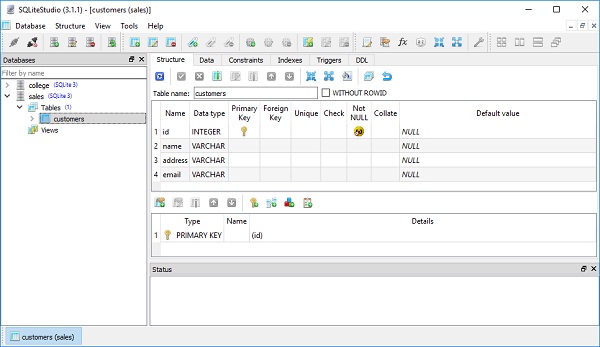
class Customers(Base): __tablename__ = 'customers' id = Column(Integer, primary_key = True) name = Column(String) address = Column(String) email = Column(String)
声明式类必须具有 `__tablename__` 属性,并且至少有一个属于主键的 `Column`。声明式系统用特殊的 Python 访问器(称为描述符)替换所有 `Column` 对象。此过程称为 instrumentation(工具化),它提供了一种在 SQL 上下文中引用表的方法,并支持从数据库持久化和加载列的值。
像普通的 Python 类一样,这个映射类根据需要具有属性和方法。
关于声明式系统中类的信息称为表元数据。SQLAlchemy 使用 `Table` 对象来表示声明式系统为特定表创建的此信息。`Table` 对象是根据规范创建的,并通过构造 `Mapper` 对象与类关联。这个映射器对象不会直接使用,而是作为映射类和表之间的内部接口使用。
每个 `Table` 对象都是更大的集合(称为 `MetaData`)的成员,并且可以通过声明式基类的 `.metadata` 属性获得此对象。`MetaData.create_all()` 方法接收引擎作为数据库连接的来源。对于所有尚未创建的表,它都会向数据库发出 CREATE TABLE 语句。
Base.metadata.create_all(engine)
创建数据库和表以及映射 Python 类的完整脚本如下所示:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)
执行后,Python 控制台将回显以下正在执行的 SQL 表达式:
CREATE TABLE customers ( id INTEGER NOT NULL, name VARCHAR, address VARCHAR, email VARCHAR, PRIMARY KEY (id) )
如果我们使用 SQLiteStudio 图形工具打开 Sales.db,它将显示其中带有上述结构的 customers 表。