- SQLAlchemy 教程
- SQLAlchemy - 首页
- SQLAlchemy - 简介
- SQLAlchemy Core
- 表达式语言
- 连接数据库
- 创建表
- SQL 表达式
- 执行表达式
- 选择行
- 使用文本 SQL
- 使用别名
- 使用 UPDATE 表达式
- 使用 DELETE 表达式
- 使用多个表
- 使用多表更新
- 参数有序更新
- 多表删除
- 使用连接
- 使用连接词
- 使用函数
- 使用集合操作
- SQLAlchemy ORM
- 声明映射
- 创建会话
- 添加对象
- 使用查询
- 更新对象
- 应用过滤器
- 过滤器运算符
- 返回列表和标量
- 文本 SQL
- 构建关系
- 处理相关对象
- 处理连接
- 常见关系运算符
- 急切加载
- 删除相关对象
- 多对多关系
- 方言
- SQLAlchemy 有用资源
- SQLAlchemy - 快速指南
- SQLAlchemy - 有用资源
- SQLAlchemy - 讨论
SQLAlchemy - 快速指南
SQLAlchemy - 简介
SQLAlchemy 是一个流行的 SQL 工具包和对象关系映射器。它是用Python编写的,并为应用程序开发人员提供了 SQL 的全部功能和灵活性。它是一个开源且跨平台的软件,根据 MIT 许可证发布。
SQLAlchemy 以其对象关系映射器 (ORM) 而闻名,使用它,类可以映射到数据库,从而允许从一开始就以干净解耦的方式开发对象模型和数据库模式。
随着 SQL 数据库的大小和性能开始变得重要,它们的行为越来越不像对象集合。另一方面,随着对象集合中的抽象开始变得重要,它们的行为越来越不像表和行。SQLAlchemy 旨在兼顾这两个原则。
出于这个原因,它采用了数据映射器模式(如 Hibernate)而不是许多其他 ORM 使用的活动记录模式。使用 SQLAlchemy 将以不同的视角看待数据库和 SQL。
Michael Bayer 是 SQLAlchemy 的最初作者。其初始版本于 2006 年 2 月发布。最新版本编号为 1.2.7,最近于 2018 年 4 月发布。
什么是 ORM?
ORM(对象关系映射)是一种编程技术,用于在面向对象编程语言中转换不兼容类型系统之间的数据。通常,面向对象 (OO) 语言(如 Python)中使用的类型系统包含非标量类型。这些不能表示为整数和字符串等基本类型。因此,OO 程序员必须将对象转换为标量数据以与后端数据库交互。但是,大多数数据库产品(如 Oracle、MySQL 等)中的数据类型都是基本类型。
在 ORM 系统中,每个类都映射到底层数据库中的一个表。ORM 代替您编写乏味的数据库接口代码,为您处理这些问题,而您可以专注于系统逻辑的编程。
SQLAlchemy - 环境设置
让我们讨论使用 SQLAlchemy 所需的环境设置。
需要 Python 2.7 或更高版本才能安装 SQLAlchemy。最简单的安装方法是使用 Python 包管理器pip。此实用程序与 Python 的标准分发版捆绑在一起。
pip install sqlalchemy
使用上述命令,我们可以从python.org下载 SQLAlchemy 的最新发布版本并将其安装到您的系统中。
对于 Anaconda 发行的 Python,可以使用以下命令从conda 终端安装 SQLAlchemy:
conda install -c anaconda sqlalchemy
也可以从以下源代码安装 SQLAlchemy:
python setup.py install
SQLAlchemy 旨在与为特定数据库构建的 DBAPI 实现一起使用。它使用方言系统与各种类型的 DBAPI 实现和数据库进行通信。所有方言都需要安装相应的 DBAPI 驱动程序。
以下是被包含的方言:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
要检查 SQLAlchemy 是否已正确安装并了解其版本,请在 Python 提示符下输入以下命令:
>>> import sqlalchemy >>>sqlalchemy.__version__ '1.2.7'
SQLAlchemy Core – 表达式语言
SQLAlchemy core 包括SQL 渲染引擎、DBAPI 集成、事务集成和模式描述服务。SQLAlchemy core 使用 SQL 表达式语言,该语言提供了一种以模式为中心的用法范例,而 SQLAlchemy ORM 是一种以领域为中心的用法模式。
SQL 表达式语言提供了一个使用 Python 结构表示关系数据库结构和表达式的系统。它提供了一个表示关系数据库的基本结构的系统,而无需任何意见,这与 ORM 形成对比,ORM 提供了一种高级且抽象的用法模式,这本身就是表达式语言应用用法的示例。
表达式语言是 SQLAlchemy 的核心组件之一。它允许程序员在 Python 代码中指定 SQL 语句,并将其直接用于更复杂的查询中。表达式语言独立于后端,并全面涵盖了原始 SQL 的各个方面。它比 SQLAlchemy 中的任何其他组件都更接近原始 SQL。
表达式语言直接表示关系数据库的基本结构。由于 ORM 基于表达式语言之上,因此典型的 Python 数据库应用程序可能同时使用两者。应用程序可以单独使用表达式语言,尽管它必须定义自己的系统来将应用程序概念转换为单个数据库查询。
SQLAlchemy 引擎会将表达式语言的语句转换为相应的原始 SQL 查询。我们现在将学习如何创建引擎并借助其帮助执行各种 SQL 查询。
SQLAlchemy Core - 连接数据库
在上一章中,我们讨论了 SQLAlchemy 中的表达式语言。现在让我们继续讨论连接到数据库所涉及的步骤。
Engine 类将池和方言组合在一起,以提供数据库连接和行为的来源。使用create_engine()函数实例化 Engine 类的对象。
create_engine() 函数将数据库作为参数之一。数据库不需要在任何地方定义。标准调用表单必须将 URL 作为第一个位置参数发送,通常是一个字符串,表示数据库方言和连接参数。使用下面给出的代码,我们可以创建一个数据库。
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)
对于MySQL 数据库,请使用以下命令:
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)
要专门提及用于连接的DB-API,URL 字符串采用以下形式:
dialect[+driver]://user:password@host/dbname
例如,如果您使用PyMySQL 驱动程序与 MySQL,请使用以下命令:
mysql+pymysql://<username>:<password>@<host>/<dbname>
echo 标志是设置 SQLAlchemy 日志记录的快捷方式,这是通过 Python 的标准日志记录模块完成的。在随后的章节中,我们将学习所有生成的 SQL。要隐藏详细输出,请将 echo 属性设置为None。create_engine() 函数的其他参数可能是特定于方言的。
create_engine() 函数返回一个Engine 对象。Engine 类的一些重要方法是:
| 序号 | 方法和描述 |
|---|---|
| 1 | connect() 返回连接对象 |
| 2 | execute() 执行 SQL 语句结构 |
| 3 | begin() 返回一个上下文管理器,提供一个建立了事务的连接。操作成功后,事务将被提交,否则将回滚 |
| 4 | dispose() 释放 Engine 使用的连接池 |
| 5 | driver() Engine 使用的方言的驱动程序名称 |
| 6 | table_names() 返回数据库中所有表名的列表 |
| 7 | transaction() 在事务边界内执行给定的函数 |
SQLAlchemy Core - 创建表
现在让我们讨论如何使用创建表函数。
SQL 表达式语言针对表列构建其表达式。SQLAlchemy Column 对象表示数据库表中的一列,该列又由Tableobject表示。元数据包含表和相关对象的定义,例如索引、视图、触发器等。
因此,来自 SQLAlchemy 元数据的 MetaData 类的对象是 Table 对象及其关联的模式结构的集合。它保存 Table 对象的集合以及对 Engine 或 Connection 的可选绑定。
from sqlalchemy import MetaData meta = MetaData()
MetaData 类的构造函数可以具有 bind 和 schema 参数,它们默认为None。
接下来,我们使用Table 结构在上述元数据目录中定义所有表,这类似于常规 SQL CREATE TABLE 语句。
Table 类的一个对象表示数据库中相应的表。构造函数采用以下参数:
| 名称 | 表的名称 |
|---|---|
| 元数据 | 将保存此表的 MetaData 对象 |
| 列 | 一个或多个 Column 类的对象 |
Column 对象表示数据库表中的一列。构造函数采用名称、类型以及其他参数,例如 primary_key、autoincrement 和其他约束。
SQLAlchemy 将 Python 数据匹配到其中定义的最佳通用列数据类型。一些通用数据类型是:
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
要在 college 数据库中创建students 表,请使用以下代码段:
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
create_all() 函数使用 engine 对象创建所有定义的表对象并将信息存储在元数据中。
meta.create_all(engine)
下面给出了完整的代码,它将在其中创建一个 SQLite 数据库 college.db,并在其中创建一个 students 表。
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)
因为 create_engine() 函数的 echo 属性设置为True,所以控制台将显示用于创建表的实际 SQL 查询,如下所示:
CREATE TABLE students ( id INTEGER NOT NULL, name VARCHAR, lastname VARCHAR, PRIMARY KEY (id) )
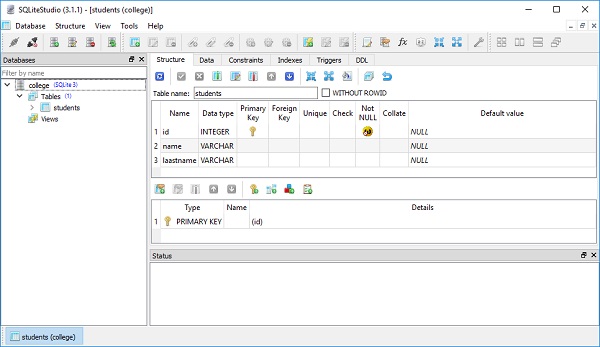
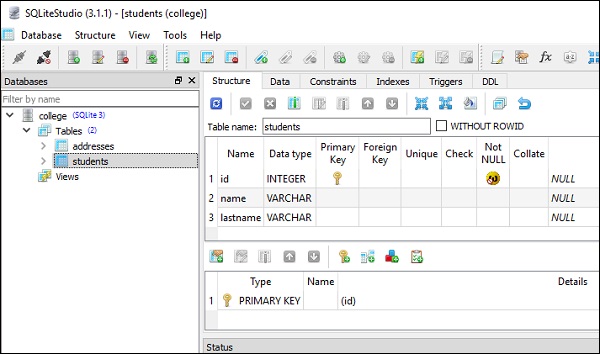
college.db 将在当前工作目录中创建。要检查是否已创建 students 表,您可以使用任何 SQLite GUI 工具(例如SQLiteStudio)打开数据库。
下图显示了在数据库中创建的 students 表:
SQLAlchemy Core - SQL 表达式
在本章中,我们将简要介绍 SQL 表达式及其功能。
SQL 表达式是使用相对于目标表对象的相应方法构建的。例如,INSERT 语句是通过执行 insert() 方法创建的,如下所示:
ins = students.insert()
上述方法的结果是一个插入对象,可以使用str()函数进行验证。以下代码插入学生 ID、姓名、姓氏等详细信息。
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'
可以使用values()方法将值插入特定字段以插入对象。以下给出了相同的代码:
>>> ins = users.insert().values(name = 'Karan') >>> str(ins) 'INSERT INTO users (name) VALUES (:name)'
Python 控制台上回显的 SQL 未显示实际值(在本例中为“Karan”)。相反,SQLALchemy 生成一个绑定参数,该参数在语句的编译形式中可见。
ins.compile().params
{'name': 'Karan'}
类似地,update()、delete()和select()等方法分别创建 UPDATE、DELETE 和 SELECT 表达式。我们将在后面的章节中学习它们。
SQLAlchemy Core - 执行表达式
在上一章中,我们学习了 SQL 表达式。在本章中,我们将深入研究这些表达式的执行。
为了执行生成的 SQL 表达式,我们必须获取表示已积极签出的 DBAPI 连接资源的连接对象,然后提供表达式对象,如下面的代码所示。
conn = engine.connect()
以下 insert() 对象可用于 execute() 方法 -
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor') result = conn.execute(ins)
控制台显示 SQL 表达式执行结果如下 -
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMIT
以下是使用 SQLAlchemy 的核心技术执行 INSERT 查询的完整代码片段 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)
可以通过使用 SQLite Studio 打开数据库来验证结果,如下面的屏幕截图所示 -
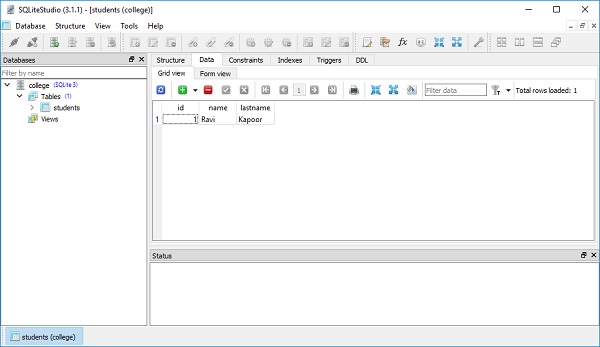
结果变量被称为 ResultProxy 对象。它类似于 DBAPI 游标对象。我们可以使用 ResultProxy.inserted_primary_key 获取从我们的语句中生成的 primary key 值的信息,如下所示 -
result.inserted_primary_key [1]
要使用 DBAPI 的 execute many() 方法发出多个插入操作,我们可以发送一个字典列表,每个字典包含一组要插入的不同参数。
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])
这反映在表的 data view 中,如下图所示 -
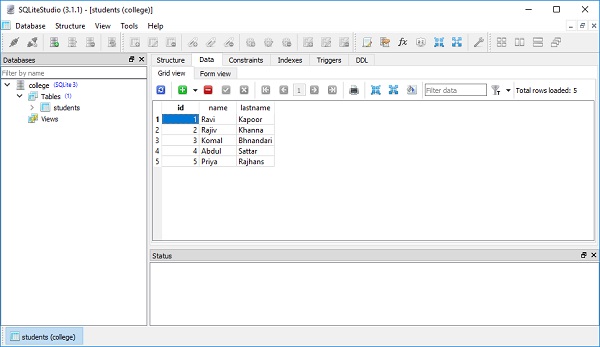
SQLAlchemy Core - 选择行
在本章中,我们将讨论表对象中选择行的概念。
表对象的 select() 方法使我们能够构建 SELECT 表达式。
s = students.select()
select 对象通过str(s) 函数转换为 SELECT 查询,如下所示 -
'SELECT students.id, students.name, students.lastname FROM students'
我们可以将此 select 对象作为参数传递给连接对象的 execute() 方法,如下面的代码所示 -
result = conn.execute(s)
当执行上述语句时,Python shell 会回显以下等效的 SQL 表达式 -
SELECT students.id, students.name, students.lastname FROM students
结果变量等同于 DBAPI 中的游标。我们现在可以使用fetchone() 方法获取记录。
row = result.fetchone()
可以通过for 循环打印表中所有选定的行,如下所示 -
for row in result: print (row)
打印 students 表中所有行的完整代码如下所示 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)
Python shell 中显示的输出如下 -
(1, 'Ravi', 'Kapoor') (2, 'Rajiv', 'Khanna') (3, 'Komal', 'Bhandari') (4, 'Abdul', 'Sattar') (5, 'Priya', 'Rajhans')
可以使用Select.where()应用 SELECT 查询的 WHERE 子句。例如,如果我们想显示 id > 2 的行
s = students.select().where(students.c.id>2) result = conn.execute(s) for row in result: print (row)
这里c 属性是列的别名。shell 上将显示以下输出 -
(3, 'Komal', 'Bhandari') (4, 'Abdul', 'Sattar') (5, 'Priya', 'Rajhans')
这里,我们需要注意的是,select 对象也可以通过 sqlalchemy.sql 模块中的 select() 函数获得。select() 函数需要表对象作为参数。
from sqlalchemy.sql import select s = select([users]) result = conn.execute(s)
SQLAlchemy Core - 使用文本 SQL
对于 SQL 已经知道并且不需要语句支持动态功能的情况,SQLAlchemy 允许您只使用字符串。text() 构造用于组合一个文本语句,该语句基本上不加修改地传递给数据库。
它构建一个新的TextClause,直接表示文本 SQL 字符串,如下面的代码所示 -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)
text() 提供的优势超过普通字符串 -
- 对绑定参数的后端中立支持
- 每个语句的执行选项
- 结果列类型行为
text() 函数需要以命名冒号格式进行绑定参数。无论数据库后端如何,它们都保持一致。要发送参数的值,我们将它们作为附加参数传递给 execute() 方法。
以下示例在文本 SQL 中使用绑定参数 -
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()
text() 函数构建 SQL 表达式如下 -
select students.name, students.lastname from students where students.name between ? and ?
x = 'A' 和 y = 'L' 的值作为参数传递。结果是一个包含名称在 'A' 和 'L' 之间的行的列表 -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]
text() 构造支持使用 TextClause.bindparams() 方法预先建立的绑定值。参数也可以显式地类型化,如下所示 -
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()
您还可以使用and_() 函数组合使用 text() 函数创建的 WHERE 子句中的多个条件。
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()
以上代码获取名称在“A”和“L”之间且 id 大于 2 的行。代码的输出如下所示 -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]
SQLAlchemy Core - 使用别名
SQL 中的别名对应于表的“重命名”版本或 SELECT 语句,只要你说“SELECT * FROM table1 AS a”就会发生这种情况。AS 为表创建了一个新名称。别名允许任何表或子查询由唯一的名称引用。
对于表,这允许在 FROM 子句中多次命名同一个表。它为语句表示的列提供了一个父名称,允许它们相对于此名称进行引用。
在 SQLAlchemy 中,任何 Table、select() 构造或其他可选择对象都可以使用From Clause.alias() 方法转换为别名,该方法会生成一个 Alias 构造。sqlalchemy.sql 模块中的 alias() 函数表示别名,通常使用 AS 关键字应用于 SQL 语句中的任何表或子选择。
from sqlalchemy.sql import alias
st = students.alias("a")
此别名现在可以在 select() 构造中用于引用 students 表 -
s = select([st]).where(st.c.id>2)
这转换为以下 SQL 表达式 -
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2
我们现在可以使用连接对象的 execute() 方法执行此 SQL 查询。完整的代码如下 -
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()
当执行以上代码行时,它会生成以下输出 -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]
使用 UPDATE 表达式
目标表对象上的update() 方法构建等效的 UPDATE SQL 表达式。
table.update().where(conditions).values(SET expressions)
结果 update 对象上的values() 方法用于指定 UPDATE 的 SET 条件。如果保留为 None,则 SET 条件由在语句执行和/或编译期间传递给语句的参数确定。
where 子句是描述 UPDATE 语句的 WHERE 条件的可选表达式。
以下代码片段将 students 表中 'lastname' 列的值从 'Khanna' 更改为 'Kapoor' -
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')
stmt 对象是一个 update 对象,它转换为 -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'
当调用execute() 方法时,将替换绑定参数lastname_1。完整的更新代码如下 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()
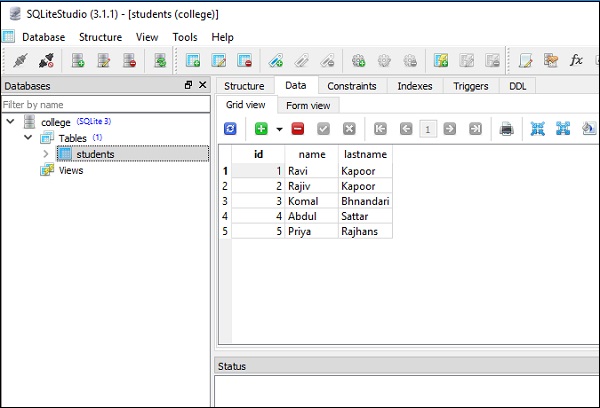
以上代码显示以下输出,其中第二行显示更新操作的效果,如给出的屏幕截图所示 -
[ (1, 'Ravi', 'Kapoor'), (2, 'Rajiv', 'Kapoor'), (3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans') ]
请注意,类似的功能也可以通过使用 sqlalchemy.sql.expression 模块中的update() 函数来实现,如下所示 -
from sqlalchemy.sql.expression import update stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')
使用 DELETE 表达式
在上一章中,我们已经了解了Update 表达式的作用。接下来我们要学习的表达式是Delete。
删除操作可以通过在目标表对象上运行 delete() 方法来实现,如下面的语句所示 -
stmt = students.delete()
对于 students 表,以上代码行构建的 SQL 表达式如下 -
'DELETE FROM students'
但是,这将删除 students 表中的所有行。通常 DELETE 查询与 WHERE 子句指定的逻辑表达式相关联。以下语句显示 where 参数 -
stmt = students.delete().where(students.c.id > 2)
结果 SQL 表达式将包含一个绑定参数,该参数将在语句执行时在运行时替换。
'DELETE FROM students WHERE students.id > :id_1'
以下代码示例将删除 students 表中 lastname 为 'Khanna' 的行 -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()
要验证结果,请在 SQLiteStudio 中刷新 students 表的 data view。
SQLAlchemy Core - 使用多个表
RDBMS 的重要功能之一是在表之间建立关系。可以在相关表上执行 SELECT、UPDATE 和 DELETE 等 SQL 操作。本节使用 SQLAlchemy 描述这些操作。
为此,在我们的 SQLite 数据库 (college.db) 中创建了两个表。students 表与上一节中给出的结构相同;而 addresses 表具有st_id 列,该列使用外键约束映射到students 表中的 id 列。
以下代码将在 college.db 中创建两个表 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
meta.create_all(engine)
以上代码将转换为 students 和 addresses 表的 CREATE TABLE 查询,如下所示 -
CREATE TABLE students ( id INTEGER NOT NULL, name VARCHAR, lastname VARCHAR, PRIMARY KEY (id) ) CREATE TABLE addresses ( id INTEGER NOT NULL, st_id INTEGER, postal_add VARCHAR, email_add VARCHAR, PRIMARY KEY (id), FOREIGN KEY(st_id) REFERENCES students (id) )
以下屏幕截图非常清楚地展示了以上代码 -
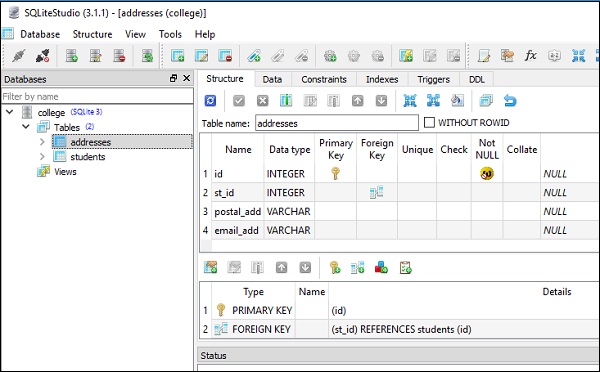
通过执行表对象的insert() 方法来填充这些表中的数据。要在 students 表中插入 5 行,您可以使用以下代码 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])
使用以下代码在 addresses 表中添加行 -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'ravi@gmail.com'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'kapoor@gmail.com'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'komal@gmail.com'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'as@yahoo.com'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'admin@khanna.com'},
])
请注意,addresses 表中的 st_id 列引用 students 表中的 id 列。我们现在可以使用此关系从两个表中获取数据。我们希望从 students 表中获取与 addresses 表中的 st_id 对应的name 和lastname。
from sqlalchemy.sql import select s = select([students, addresses]).where(students.c.id == addresses.c.st_id) result = conn.execute(s) for row in result: print (row)
select 对象将有效地转换为以下 SQL 表达式,该表达式在公共关系上连接两个表 -
SELECT students.id, students.name, students.lastname, addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM students, addresses WHERE students.id = addresses.st_id
这将生成输出,从两个表中提取相应的数据,如下所示 -
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', 'ravi@gmail.com') (1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', 'kapoor@gmail.com') (3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', 'komal@gmail.com') (5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', 'as@yahoo.com') (2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', 'admin@khanna.com')
使用多表更新
在上一章中,我们讨论了如何使用多个表。因此,我们在本章中更进一步,学习多表更新。
使用 SQLAlchemy 的表对象,可以在 update() 方法的 WHERE 子句中指定多个表。PostgreSQL 和 Microsoft SQL Server 支持引用多个表的 UPDATE 语句。这实现了“UPDATE FROM”语法,该语法一次更新一个表。但是,可以在 WHERE 子句中直接的附加“FROM”子句中引用其他表。以下代码行清楚地解释了多表更新的概念。
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'abc@xyz.com'
}).\
where(students.c.id == addresses.c.id)
update 对象等效于以下 UPDATE 查询 -
UPDATE students SET email_add = :addresses_email_add, name = :name FROM addresses WHERE students.id = addresses.id
就 MySQL 方言而言,多个表可以嵌入到由逗号分隔的单个 UPDATE 语句中,如下所示 -
stmt = students.update().\ values(name = 'xyz').\ where(students.c.id == addresses.c.id)
以下代码描述了结果 UPDATE 查询 -
'UPDATE students SET name = :name FROM addresses WHERE students.id = addresses.id'
但是,SQLite 方言不支持 UPDATE 中的多表条件,并显示以下错误 -
NotImplementedError: This backend does not support multiple-table criteria within UPDATE
参数有序更新
原始 SQL 的 UPDATE 查询具有 SET 子句。它由 update() 构造使用源 Table 对象中给定的列顺序呈现。因此,具有特定列的特定 UPDATE 语句每次都会以相同的方式呈现。由于参数本身作为 Python 字典键传递到 Update.values() 方法,因此没有其他可用的固定顺序。
在某些情况下,SET 子句中呈现的参数顺序很重要。在 MySQL 中,提供对列值的更新是基于其他列值的。
以下语句的结果 -
UPDATE table1 SET x = y + 10, y = 20
将与以下结果不同 -
UPDATE table1 SET y = 20, x = y + 10
MySQL 中的 SET 子句是基于每个值评估的,而不是基于每行评估的。为此,使用preserve_parameter_order。Python 2 元组列表作为参数传递给Update.values() 方法 -
stmt = table1.update(preserve_parameter_order = True).\ values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])
List 对象类似于字典,但它是按顺序排列的。这确保“y”列的 SET 子句将首先呈现,然后是“x”列的 SET 子句。
SQLAlchemy Core - 多表删除
在本章中,我们将了解多表删除表达式,它类似于使用多表更新函数。
在许多 DBMS 方言中,可以在 DELETE 语句的 WHERE 子句中引用多个表。对于 PG 和 MySQL,使用“DELETE USING”语法;对于 SQL Server,使用“DELETE FROM”表达式引用多个表。SQLAlchemy 的delete() 构造隐式支持这两种模式,方法是在 WHERE 子句中指定多个表,如下所示 -
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)
在 PostgreSQL 后端上,上述语句的结果 SQL 将呈现为 -
DELETE FROM users USING addresses WHERE users.id = addresses.id AND (addresses.email_address LIKE %(email_address_1)s || '%%')
如果将此方法与不支持此行为的数据库一起使用,编译器将引发 NotImplementedError。
SQLAlchemy Core - 使用连接
在本章中,我们将学习如何在 SQLAlchemy 中使用连接。
连接效果可以通过简单地将两个表放在 select() 构造函数的列子句或where 子句中来实现。现在我们使用 join() 和 outerjoin() 方法。
join() 方法从一个表对象到另一个表对象返回一个连接对象。
join(right, onclause = None, isouter = False, full = False)
上述代码中提到的参数的功能如下:
right - 连接的右侧;这是任何 Table 对象
onclause - 表示连接的 ON 子句的 SQL 表达式。如果保留为 None,它会尝试根据外键关系连接这两个表
isouter - 如果为 True,则呈现 LEFT OUTER JOIN,而不是 JOIN
full - 如果为 True,则呈现 FULL OUTER JOIN,而不是 LEFT OUTER JOIN
例如,以下 join() 方法的使用将自动导致基于外键的连接。
>>> print(students.join(addresses))
这等效于以下 SQL 表达式:
students JOIN addresses ON students.id = addresses.st_id
您可以明确地指定连接条件,如下所示:
j = students.join(addresses, students.c.id == addresses.c.st_id)
如果我们现在使用此连接构建以下 select 构造函数:
stmt = select([students]).select_from(j)
这将导致以下 SQL 表达式:
SELECT students.id, students.name, students.lastname FROM students JOIN addresses ON students.id = addresses.st_id
如果使用表示引擎的连接执行此语句,则将显示属于所选列的数据。完整代码如下:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()
以下是上述代码的输出:
[ (1, 'Ravi', 'Kapoor'), (1, 'Ravi', 'Kapoor'), (3, 'Komal', 'Bhandari'), (5, 'Priya', 'Rajhans'), (2, 'Rajiv', 'Khanna') ]
SQLAlchemy Core - 使用连接
连接是 SQLAlchemy 模块中的函数,它们实现 SQL 表达式 WHERE 子句中使用的关系运算符。运算符 AND、OR、NOT 等用于形成组合表达式,组合两个单独的逻辑表达式。以下是在 SELECT 语句中使用 AND 的一个简单示例:
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30
SQLAlchemy 函数 and_()、or_() 和 not_() 分别实现 AND、OR 和 NOT 运算符。
and_() 函数
它生成由 AND 连接的表达式的连接。以下提供了一个示例以更好地理解:
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)
这转换为:
students.name = :name_1 AND students.id < :id_1
要在 students 表上的 select() 构造函数中使用 and_(),请使用以下代码行:
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
将构建以下性质的 SELECT 语句:
SELECT students.id, students.name, students.lastname FROM students WHERE students.name = :name_1 AND students.id < :id_1
显示上述 SELECT 查询输出的完整代码如下:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())
假设 students 表已填充了先前示例中使用的数据,则将选择以下行:
[(1, 'Ravi', 'Kapoor')]
or_() 函数
它生成由 OR 连接的表达式的连接。我们将使用 or_() 将上述示例中的 stmt 对象替换为以下对象
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))
这将有效地等效于以下 SELECT 查询:
SELECT students.id, students.name, students.lastname FROM students WHERE students.name = :name_1 OR students.id < :id_1
一旦您进行替换并运行上述代码,结果将是两行符合 OR 条件的行:
[(1, 'Ravi', 'Kapoor'), (2, 'Rajiv', 'Khanna')]
asc() 函数
它生成一个升序 ORDER BY 子句。该函数将要应用函数的列作为参数。
from sqlalchemy import asc stmt = select([students]).order_by(asc(students.c.name))
该语句实现以下 SQL 表达式:
SELECT students.id, students.name, students.lastname FROM students ORDER BY students.name ASC
以下代码按 name 列的升序列出 students 表中的所有记录:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)
以上代码产生以下输出:
(4, 'Abdul', 'Sattar') (3, 'Komal', 'Bhandari') (5, 'Priya', 'Rajhans') (2, 'Rajiv', 'Khanna') (1, 'Ravi', 'Kapoor')
desc() 函数
类似地,desc() 函数生成降序 ORDER BY 子句,如下所示:
from sqlalchemy import desc stmt = select([students]).order_by(desc(students.c.lastname))
等效的 SQL 表达式为:
SELECT students.id, students.name, students.lastname FROM students ORDER BY students.lastname DESC
以上代码行的输出为:
(4, 'Abdul', 'Sattar') (5, 'Priya', 'Rajhans') (2, 'Rajiv', 'Khanna') (1, 'Ravi', 'Kapoor') (3, 'Komal', 'Bhandari')
between() 函数
它生成一个 BETWEEN 谓词子句。这通常用于验证特定列的值是否落在某个范围内。例如,以下代码选择 id 列介于 2 和 4 之间的行:
from sqlalchemy import between stmt = select([students]).where(between(students.c.id,2,4)) print (stmt)
生成的 SQL 表达式类似于:
SELECT students.id, students.name, students.lastname FROM students WHERE students.id BETWEEN :id_1 AND :id_2
结果如下:
(2, 'Rajiv', 'Khanna') (3, 'Komal', 'Bhandari') (4, 'Abdul', 'Sattar')
SQLAlchemy Core - 使用函数
本章讨论了 SQLAlchemy 中使用的一些重要函数。
标准 SQL 建议了许多函数,这些函数由大多数方言实现。它们根据传递给它的参数返回单个值。一些 SQL 函数将列作为参数,而一些是通用的。SQLAlchemy API 中的 thefunc 关键字用于生成这些函数。
在 SQL 中,now() 是一个通用函数。以下语句使用 func 呈现 now() 函数:
from sqlalchemy.sql import func result = conn.execute(select([func.now()])) print (result.fetchone())
以上代码的示例结果可能如下所示:
(datetime.datetime(2018, 6, 16, 6, 4, 40),)
另一方面,count() 函数返回从表中选择的行数,由以下 func 用法呈现:
from sqlalchemy.sql import func result = conn.execute(select([func.count(students.c.id)])) print (result.fetchone())
从以上代码中,将获取 students 表中行数的计数。
一些内置的 SQL 函数使用 Employee 表演示,该表包含以下数据:
| ID | 名称 | 分数 |
|---|---|---|
| 1 | 卡玛尔 | 56 |
| 2 | 费尔南德斯 | 85 |
| 3 | 苏尼尔 | 62 |
| 4 | 巴斯卡 | 76 |
max() 函数通过以下 SQLAlchemy 中 func 的用法实现,这将导致 85,即获得的总最高分:
from sqlalchemy.sql import func result = conn.execute(select([func.max(employee.c.marks)])) print (result.fetchone())
类似地,将返回 56(最低分数)的 min() 函数将由以下代码呈现:
from sqlalchemy.sql import func result = conn.execute(select([func.min(employee.c.marks)])) print (result.fetchone())
因此,AVG() 函数也可以通过使用以下代码实现:
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())
SQLAlchemy Core - 使用集合运算
在上一章中,我们学习了 max()、min()、count() 等各种函数,在这里,我们将学习集合运算及其用途。
标准 SQL 及其大多数方言都支持 UNION 和 INTERSECT 等集合运算。SQLAlchemy 通过以下函数来实现它们:
union()
在组合两个或多个 SELECT 语句的结果时,UNION 会从结果集中消除重复项。两个表中的列数和数据类型必须相同。
union() 函数从多个表返回一个 CompoundSelect 对象。以下示例演示了其用法:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()
union 构造转换为以下 SQL 表达式:
SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ? UNION SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ?
从我们的 addresses 表中,以下行表示 union 操作:
[ (1, 1, 'Shivajinagar Pune', 'ravi@gmail.com'), (2, 1, 'ChurchGate Mumbai', 'kapoor@gmail.com'), (3, 3, 'Jubilee Hills Hyderabad', 'komal@gmail.com'), (4, 5, 'MG Road Bangaluru', 'as@yahoo.com') ]
union_all()
UNION ALL 操作无法删除重复项,也无法对结果集中的数据进行排序。例如,在上述查询中,UNION 被替换为 UNION ALL 以查看效果。
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))
相应的 SQL 表达式如下:
SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ?
except_()
SQL EXCEPT 子句/运算符用于组合两个 SELECT 语句,并返回第一个 SELECT 语句中未由第二个 SELECT 语句返回的行。except_() 函数生成带有 EXCEPT 子句的 SELECT 表达式。
在以下示例中,except_() 函数仅返回 addresses 表中在 email_add 字段中包含“gmail.com”的记录,但排除在 postal_add 字段中包含“Pune”的记录。
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))
上述代码的结果是以下 SQL 表达式:
SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.postal_add LIKE ?
假设 addresses 表包含前面示例中使用的数据,它将显示以下输出:
[(2, 1, 'ChurchGate Mumbai', 'kapoor@gmail.com'), (3, 3, 'Jubilee Hills Hyderabad', 'komal@gmail.com')]
intersect()
使用 INTERSECT 运算符,SQL 显示两个 SELECT 语句的公共行。intersect() 函数实现了此行为。
在以下示例中,两个 SELECT 构造函数是 intersect() 函数的参数。一个返回在 email_add 列中包含“gmail.com”的行,另一个返回在 postal_add 列中包含“Pune”的行。结果将是两个结果集的公共行。
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))
实际上,这等效于以下 SQL 语句:
SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id, addresses.st_id, addresses.postal_add, addresses.email_add FROM addresses WHERE addresses.postal_add LIKE ?
两个绑定参数“%gmail.com”和“%Pune”从 addresses 表中的原始数据生成一行,如下所示:
[(1, 1, 'Shivajinagar Pune', 'ravi@gmail.com')]
SQLAlchemy ORM - 声明映射
SQLAlchemy 的对象关系映射 API 的主要目标是促进将用户定义的 Python 类与数据库表关联起来,并将这些类的对象与它们对应表中的行关联起来。对象和行的状态更改会同步匹配。SQLAlchemy 使能够根据用户定义的类及其定义的关系来表达数据库查询。
ORM 建立在 SQL 表达式语言之上。这是一种高级且抽象的用法模式。事实上,ORM 是表达式语言的应用用法。
虽然可以使用对象关系映射器单独构建成功的应用程序,但有时使用 ORM 构建的应用程序可能会直接使用表达式语言,在需要特定数据库交互的情况下。
声明映射
首先,调用 create_engine() 函数来设置一个引擎对象,该对象随后用于执行 SQL 操作。该函数有两个参数,一个是数据库的名称,另一个是 echo 参数,当设置为 True 时将生成活动日志。如果不存在,则将创建数据库。在以下示例中,创建了一个 SQLite 数据库。
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
当调用 Engine.execute() 或 Engine.connect() 等方法时,引擎会建立与数据库的真实 DBAPI 连接。然后它用于发出 SQLORM,它不直接使用引擎;相反,它在幕后由 ORM 使用。
在 ORM 的情况下,配置过程从描述数据库表开始,然后定义将映射到这些表的类。在 SQLAlchemy 中,这两项任务一起执行。这是通过使用声明式系统完成的;创建的类包括描述它们映射到的实际数据库表的指令。
一个基类在声明式系统中存储类的目录和映射表。这称为声明式基类。在通常导入的模块中,通常只有一个此基类的实例。declarative_base() 函数用于创建基类。此函数在 sqlalchemy.ext.declarative 模块中定义。
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
声明基类后,可以根据它定义任意数量的映射类。以下代码定义了一个 Customer 的类。它包含要映射到的表,以及其中列的名称和数据类型。
class Customers(Base): __tablename__ = 'customers' id = Column(Integer, primary_key = True) name = Column(String) address = Column(String) email = Column(String)
声明式中的类必须具有__tablename__属性,并且至少有一个Column是主键的一部分。Declarative 将所有Column对象替换为称为描述符的特殊 Python 访问器。此过程称为检测,它提供了在 SQL 上下文中引用表的方法,并能够从数据库中持久化和加载列的值。
此映射类就像一个普通的 Python 类,根据需要具有属性和方法。
关于声明式系统中类的信息称为表元数据。SQLAlchemy 使用 Table 对象来表示 Declarative 创建的特定表的此信息。Table 对象根据规范创建,并通过构造 Mapper 对象与类关联。此映射器对象不用于直接使用,而是在内部用作映射类和表之间的接口。
每个 Table 对象都是称为 MetaData 的较大集合的成员,并且此对象可通过声明式基类的.metadata属性获得。MetaData.create_all()方法是,将我们的 Engine 作为数据库连接的来源传递进去。对于尚未创建的所有表,它都会向数据库发出 CREATE TABLE 语句。
Base.metadata.create_all(engine)
创建数据库和表以及映射 Python 类的完整脚本如下所示:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)
执行后,Python 控制台将回显以下正在执行的 SQL 表达式:
CREATE TABLE customers ( id INTEGER NOT NULL, name VARCHAR, address VARCHAR, email VARCHAR, PRIMARY KEY (id) )
如果我们使用 SQLiteStudio 图形工具打开 Sales.db,它将在其中显示 customers 表,并具有上述结构。
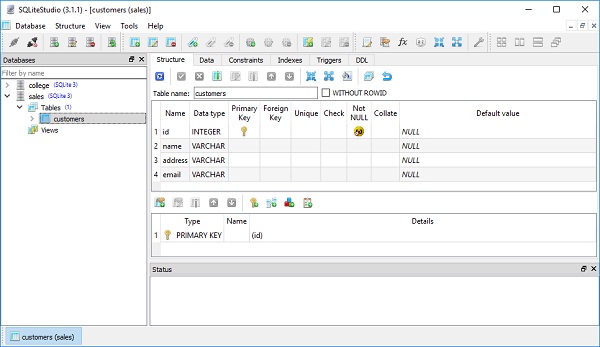
SQLAlchemy ORM - 创建会话
为了与数据库交互,我们需要获取其句柄。会话对象是数据库的句柄。Session 类使用 sessionmaker() 定义——一个可配置的会话工厂方法,它绑定到前面创建的引擎对象。
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind = engine)
然后使用其默认构造函数设置会话对象,如下所示:
session = Session()
下面列出了会话类的一些常用方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | begin() 在此会话上开始一个事务 |
| 2 | add() 将对象放入会话中。其状态在下次刷新操作时持久化到数据库中 |
| 3 | add_all() 将对象的集合添加到会话中 |
| 4 | commit() 刷新所有项和任何正在进行的事务 |
| 5 | delete() 将事务标记为已删除 |
| 6 | execute() 执行 SQL 表达式 |
| 7 | expire() 将实例的属性标记为已过期 |
| 8 | flush() 将所有对象更改刷新到数据库 |
| 9 | invalidate() 使用连接失效关闭会话 |
| 10 | rollback() 回滚当前正在进行的事务 |
| 11 | close() 通过清除所有项目并结束任何正在进行的事务来关闭当前会话 |
SQLAlchemy ORM - 添加对象
在 SQLAlchemy ORM 的前几章中,我们学习了如何声明映射和创建会话。在本章中,我们将学习如何将对象添加到表中。
我们已声明 Customer 类,该类已映射到 customers 表。我们必须声明此类的对象并通过会话对象的 add() 方法将其持久地添加到表中。
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = 'ravi@gmail.com') session.add(c1)
请注意,此事务将处于挂起状态,直到使用 commit() 方法刷新。
session.commit()
以下是将记录添加到 customers 表中的完整脚本:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = 'ravi@gmail.com')
session.add(c1)
session.commit()
要添加多条记录,我们可以使用会话类的 **add_all()** 方法。
session.add_all([ Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = 'komal@gmail.com'), Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = 'nath@gmail.com'), Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = 'smk@gmail.com')] ) session.commit()
SQLiteStudio 的表视图显示记录已持久地添加到 customers 表中。下图显示了结果:
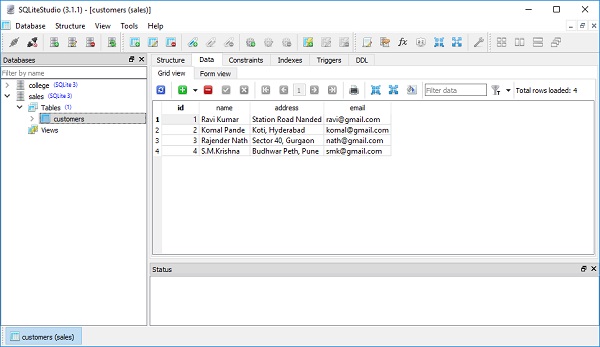
SQLAlchemy ORM - 使用查询
SQLAlchemy ORM 生成的所有 SELECT 语句都由 Query 对象构建。它提供了一个生成式接口,因此连续的调用会返回一个新的 Query 对象,它是前一个对象的副本,并具有与其关联的其他条件和选项。
Query 对象最初是使用 Session 的 query() 方法生成的,如下所示:
q = session.query(mapped class)
以下语句也等效于上述语句:
q = Query(mappedClass, session)
query 对象具有 all() 方法,该方法以对象列表的形式返回结果集。如果我们在 customers 表上执行它:
result = session.query(Customers).all()
此语句实际上等效于以下 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers
可以使用 For 循环遍历结果对象以获取基础 customers 表中的所有记录。以下是显示 Customers 表中所有记录的完整代码:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)
Python 控制台显示如下记录列表:
Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com Name: Komal Pande Address: Koti, Hyderabad Email: komal@gmail.com Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com Name: S.M.Krishna Address: Budhwar Peth, Pune Email: smk@gmail.com
Query 对象还具有以下有用的方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | add_columns() 它将一个或多个列表达式添加到要返回的结果列列表中。 |
| 2 | add_entity() 它将映射实体添加到要返回的结果列列表中。 |
| 3 | count() 它返回此 Query 将返回的行数。 |
| 4 | delete() 它执行批量删除查询。从数据库中删除此查询匹配的行。 |
| 5 | distinct() 它对查询应用 DISTINCT 子句并返回新生成的 Query。 |
| 6 | filter() 它使用 SQL 表达式将给定的过滤条件应用于此 Query 的副本。 |
| 7 | first() 它返回此 Query 的第一个结果,如果结果不包含任何行,则返回 None。 |
| 8 | get() 它根据给定的主键标识符返回一个实例,提供对拥有 Session 的标识映射的直接访问。 |
| 9 | group_by() 它对查询应用一个或多个 GROUP BY 条件并返回新生成的 Query |
| 10 | join() 它针对此 Query 对象的条件创建 SQL JOIN 并生成性地应用,返回新生成的 Query。 |
| 11 | one() 它返回正好一个结果或引发异常。 |
| 12 | order_by() 它对查询应用一个或多个 ORDER BY 条件并返回新生成的 Query。 |
| 13 | update() 它执行批量更新查询并在数据库中更新此查询匹配的行。 |
SQLAlchemy ORM - 更新对象
在本章中,我们将了解如何修改或更新表中的所需值。
要修改任何对象的某个属性的数据,我们必须为其分配新值并提交更改以使更改持久化。
让我们从表中获取一个对象,其主键标识符在我们的 Customers 表中,ID=2。我们可以使用会话的 get() 方法,如下所示:
x = session.query(Customers).get(2)
我们可以使用以下代码显示所选对象的内容:
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)
从我们的 customers 表中,应显示以下输出:
Name: Komal Pande Address: Koti, Hyderabad Email: komal@gmail.com
现在我们需要通过分配如下所示的新值来更新 Address 字段:
x.address = 'Banjara Hills Secunderabad' session.commit()
更改将持久地反映在数据库中。现在,我们通过使用 **first() 方法**获取表中第一行的对应对象,如下所示:
x = session.query(Customers).first()
这将执行以下 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers LIMIT ? OFFSET ?
绑定参数将分别为 LIMIT = 1 和 OFFSET = 0,这意味着将选择第一行。
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)
现在,上面显示第一行的代码的输出如下所示:
Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com
现在更改 name 属性并使用以下代码显示内容:
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)
上面代码的输出为:
Name: Ravi Shrivastava Address: Station Road Nanded Email: ravi@gmail.com
即使显示了更改,但它尚未提交。您可以使用以下代码中的 **rollback() 方法**保留以前的持久位置。
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)
将显示第一条记录的原始内容。
对于批量更新,我们将使用 Query 对象的 update() 方法。让我们尝试在每一行(除了 ID = 2)的 name 中添加前缀“Mr.”。相应的 update() 语句如下:
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)
update() 方法需要两个参数,如下所示:
一个键值对字典,其中键是要更新的属性,值是属性的新内容。
synchronize_session 属性,用于说明更新会话中属性的策略。有效值为 false:不同步会话,fetch:在更新之前执行 select 查询以查找与更新查询匹配的对象;以及 evaluate:评估会话中对象的条件。
表中的四行中有三行将以“Mr.”为前缀。但是,更改尚未提交,因此不会反映在 SQLiteStudio 的表视图中。只有在提交会话时才会刷新它。
SQLAlchemy ORM - 应用过滤器
在本章中,我们将讨论如何应用过滤器以及某些过滤操作及其代码。
由 Query 对象表示的结果集可以通过使用 filter() 方法应用某些条件。filter 方法的一般用法如下:
session.query(class).filter(criteria)
在以下示例中,通过 SELECT 查询在 Customers 表上获得的结果集通过条件 (ID>2) 进行过滤:
result = session.query(Customers).filter(Customers.id>2)
此语句将转换为以下 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id > ?
由于绑定参数 (?) 为 2,因此仅显示 ID 列 > 2 的那些行。完整的代码如下所示:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
Python 控制台显示的输出如下所示:
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: smk@gmail.com
SQLAlchemy ORM - 过滤器运算符
现在,我们将学习过滤器操作及其相应的代码和输出。
等于
通常使用的运算符是 ==,它应用条件来检查相等性。
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
SQLAlchemy 将发送以下 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id = ?
上面代码的输出如下所示:
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: komal@gmail.com
不等于
不等于运算符使用 !=,它提供不等于条件。
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
生成的 SQL 表达式为:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id != ?
上面几行代码的输出如下所示:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: smk@gmail.com
喜欢
like() 方法本身为 SELECT 表达式中的 WHERE 子句生成 LIKE 条件。
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
上面的 SQLAlchemy 代码等效于以下 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.name LIKE ?
上面代码的输出为:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com
在
此运算符检查列值是否属于列表中的一组项目。它由 in_() 方法提供。
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
这里,SQLite 引擎评估的 SQL 表达式将如下所示:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id IN (?, ?)
上面代码的输出如下所示:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com
和
此连接是通过以下方式生成的:**在过滤器中放置多个逗号分隔的条件或使用 and_() 方法**,如下所示:
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
以上两种方法都会产生类似的 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id > ? AND customers.name LIKE ?
上面几行代码的输出为:
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com
或
此连接由 **or_() 方法**实现。
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)
结果,SQLite 引擎获得以下等效的 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id > ? OR customers.name LIKE ?
上面代码的输出如下所示:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: ravi@gmail.com ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: nath@gmail.com ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: smk@gmail.com
返回列表和标量
Query 对象有许多方法会立即发出 SQL 并返回包含已加载数据库结果的值。
以下是返回列表和标量的简要概述:
all()
它返回一个列表。以下是 all() 函数的代码行。
session.query(Customers).all()
Python 控制台显示以下发出的 SQL 表达式:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers
first()
它应用一个限制为 1 并返回第一个结果作为标量。
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers LIMIT ? OFFSET ?
LIMIT 的绑定参数为 1,OFFSET 的绑定参数为 0。
one()
此命令完全获取所有行,如果结果中不存在正好一个对象标识或复合行,则会引发错误。
session.query(Customers).one()
找到多行时:
MultipleResultsFound: Multiple rows were found for one()
未找到行时:
NoResultFound: No row was found for one()
one() 方法适用于期望以不同的方式处理“未找到项目”与“找到多个项目”的系统。
scalar()
它调用 one() 方法,并在成功时返回行的第一列,如下所示:
session.query(Customers).filter(Customers.id == 3).scalar()
这会生成以下 SQL 语句:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE customers.id = ?
SQLAlchemy ORM - 文本 SQL
之前,从 SQLAlchemy 的核心表达式语言的角度解释了使用 text() 函数的文本 SQL。现在我们将从 ORM 的角度讨论它。
通过使用 text() 结构指定其用法,可以在 Query 对象中灵活地使用文字字符串。大多数适用的方法都接受它。例如,filter() 和 order_by()。
在下面给出的示例中,filter() 方法将字符串“id<3”转换为 WHERE id<3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)
生成的原始 SQL 表达式展示了将过滤器转换为 WHERE 子句的过程,如下代码所示:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE id<3
从我们 Customers 表中的示例数据中,将选择两行,并打印 name 列,如下所示:
Ravi Kumar Komal Pande
要使用基于字符串的 SQL 指定绑定参数,请使用冒号,并使用 params() 方法指定值。
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()
在 Python 控制台上显示的有效 SQL 将如下所示:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE id = ?
要使用完全基于字符串的语句,可以将表示完整语句的 text() 结构传递给 from_statement()。
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()
上述代码的结果将是一个基本的 SELECT 语句,如下所示:
SELECT * FROM customers
显然,将选择 customers 表中的所有记录。
text() 结构允许我们将它的文本 SQL 与 Core 或 ORM 映射的列表达式按位置关联。我们可以通过将列表达式作为位置参数传递给 TextClause.columns() 方法来实现这一点。
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()
即使 SQLite 引擎执行了上述代码生成的以下表达式,也将会选择所有行的 id 和 name 列,该表达式显示了 text() 方法中的所有列:
SELECT name, id, name, address, email FROM customers
SQLAlchemy ORM - 建立关系
本节描述了创建另一个表,该表与数据库中已存在的表相关联。customers 表包含客户的主数据。我们现在需要创建 invoices 表,该表可能包含属于某个客户的任意数量的发票。这是一种一对多关系。
使用声明式方式,我们定义此表及其映射类 Invoices,如下所示:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)
这将向 SQLite 引擎发送一个 CREATE TABLE 查询,如下所示:
CREATE TABLE invoices ( id INTEGER NOT NULL, custid INTEGER, invno INTEGER, amount INTEGER, PRIMARY KEY (id), FOREIGN KEY(custid) REFERENCES customers (id) )
我们可以使用 SQLiteStudio 工具检查 sales.db 中是否创建了新表。
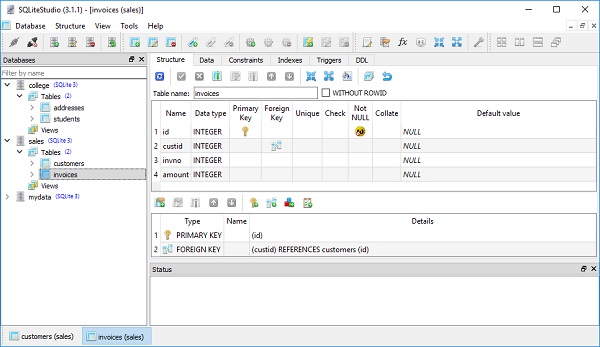
Invoices 类在 custid 属性上应用 ForeignKey 结构。此指令指示此列中的值应约束为 customers 表中 id 列中存在的值。这是关系型数据库的核心功能,也是将不相关的表集合转换为具有丰富重叠关系的“粘合剂”。
第二个指令称为 relationship(),它告诉 ORM Invoice 类应使用属性 Invoice.customer 与 Customer 类链接。relationship() 使用两张表之间的外键关系来确定此链接的性质,确定它是一对多关系。
在 Customer 映射类下的属性 Customer.invoices 上放置了一个额外的 relationship() 指令。relationship.back_populates 参数被分配为引用补充属性名称,以便每个 relationship() 都可以对相同关系进行智能决策,如反向表达所示。在一方面,Invoices.customer 指的是 Invoices 实例,另一方面,Customer.invoices 指的是 Customers 实例的列表。
relationship 函数是 SQLAlchemy ORM 包的关系 API 的一部分。它提供了两个映射类之间的关系。这对应于父子或关联表关系。
以下是发现的基本关系模式:
一对多
一对多关系指的是父级,它借助子表上的外键进行关联。然后在父级上指定 relationship(),将其作为对子级表示的项目集合的引用。relationship.back_populates 参数用于在一对多关系中建立双向关系,其中“反向”端是多对一关系。
多对一
另一方面,多对一关系在父表中放置一个外键来引用子表。relationship() 在父级上声明,其中将创建一个新的标量持有属性。这里同样使用 relationship.back_populates 参数来实现双向行为。
一对一
一对一关系本质上是双向关系。uselist 标志指示在关系的“多”端放置一个标量属性而不是集合。要将一对多转换为一对一类型的关系,请将 uselist 参数设置为 false。
多对多
多对多关系是通过添加一个关联表来建立的,该关联表通过定义具有其外键的属性来关联两个类。它由 relationship() 的 secondary 参数指示。通常,Table 使用与声明式基类关联的 MetaData 对象,以便 ForeignKey 指令可以找到要与其链接的远程表。每个 relationship() 的 relationship.back_populates 参数建立双向关系。关系的两端都包含一个集合。
处理相关对象
在本章中,我们将重点关注 SQLAlchemy ORM 中的相关对象。
现在,当我们创建一个 Customer 对象时,一个空白的发票集合将以 Python 列表的形式存在。
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "gk@gmail.com")
c1.invoices 的 invoices 属性将是一个空列表。我们可以像这样分配列表中的项目:
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]
让我们使用 Session 对象将此对象提交到数据库,如下所示:
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind = engine) session = Session() session.add(c1) session.commit()
这将自动为 customers 和 invoices 表生成 INSERT 查询:
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', 'gk@gmail.com')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)
现在让我们在 SQLiteStudio 的表视图中查看 customers 表和 invoices 表的内容:
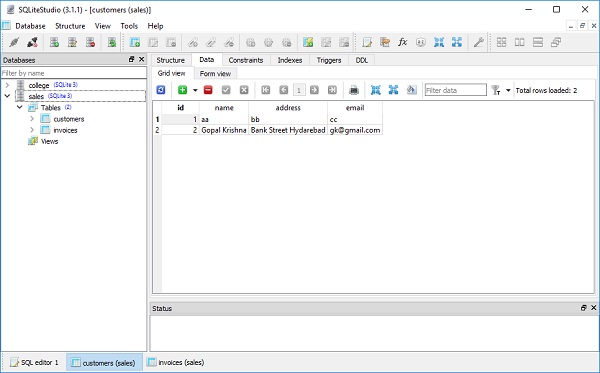
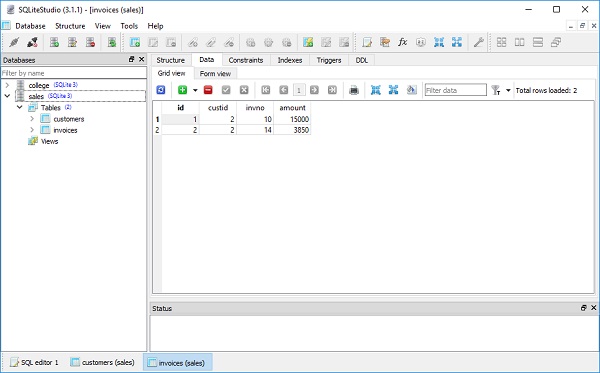
您可以通过在构造函数本身中提供 invoices 的映射属性来构建 Customer 对象,使用以下命令:
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "gpant@gmail.com",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]
或者使用 session 对象的 add_all() 函数添加对象的列表,如下所示:
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "kala@gmail.com",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "abdulr@gmail.com",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()
SQLAlchemy ORM - 使用连接
既然我们有两个表,我们将看看如何同时对这两个表创建查询。要构建 Customer 和 Invoice 之间的简单隐式连接,我们可以使用 Query.filter() 将其相关列等同起来。下面,我们将使用此方法同时加载 Customer 和 Invoice 实体:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))
SQLAlchemy 发出的 SQL 表达式如下:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email, invoices.id AS invoices_id, invoices.custid AS invoices_custid, invoices.invno AS invoices_invno, invoices.amount AS invoices_amount FROM customers, invoices WHERE customers.id = invoices.custid
上述代码行的结果如下:
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000 ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850 ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000 ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000 ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000 ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500 ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000 ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000
可以使用 Query.join() 方法轻松实现实际的 SQL JOIN 语法,如下所示:
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()
连接的 SQL 表达式将显示在控制台上:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers JOIN invoices ON customers.id = invoices.custid WHERE invoices.amount = ?
我们可以使用 for 循环遍历结果:
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)
将 8500 作为绑定参数,将显示以下输出:
4 Govind Kala 8 8500
Query.join() 知道如何在这些表之间连接,因为它们之间只有一个外键。如果没有外键或多个外键,当使用以下其中一种形式时,Query.join() 运行效果更好:
| query.join(Invoice, id == Address.custid) | 显式条件 |
| query.join(Customer.invoices) | 指定从左到右的关系 |
| query.join(Invoice, Customer.invoices) | 相同,带有显式目标 |
| query.join('invoices') | 相同,使用字符串 |
类似地,outerjoin() 函数可用于实现左外连接。
query.outerjoin(Customer.invoices)
subquery() 方法生成一个 SQL 表达式,表示嵌入在别名中的 SELECT 语句。
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()
stmt 对象将包含如下 SQL 语句:
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custid
一旦我们有了语句,它的行为就像 Table 结构一样。语句上的列可以通过名为 c 的属性访问,如下面的代码所示:
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id): print(u.name, count)
上面的 for 循环按名称显示发票计数,如下所示:
Arjun Pandit None Gopal Krishna 2 Govind Pant 2 Govind Kala 2 Abdul Rahman 2
常见关系运算符
在本章中,我们将讨论构建在关系上的运算符。
__eq__()
上述运算符是多对一“等于”比较。此运算符的代码行如下所示:
s = session.query(Customer).filter(Invoice.invno.__eq__(12))
上述代码行的等效 SQL 查询为:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers, invoices WHERE invoices.invno = ?
__ne__()
此运算符是多对一“不等于”比较。此运算符的代码行如下所示:
s = session.query(Customer).filter(Invoice.custid.__ne__(2))
上述代码行的等效 SQL 查询如下所示:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers, invoices WHERE invoices.custid != ?
contains()
此运算符用于一对多集合,以下是 contains() 的代码:
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))
上述代码行的等效 SQL 查询为:
SELECT invoices.id AS invoices_id, invoices.custid AS invoices_custid, invoices.invno AS invoices_invno, invoices.amount AS invoices_amount FROM invoices WHERE (invoices.invno LIKE '%' + ? || '%')
any()
any() 运算符用于集合,如下所示:
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))
上述代码行的等效 SQL 查询如下所示:
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE EXISTS ( SELECT 1 FROM invoices WHERE customers.id = invoices.custid AND invoices.invno = ?)
has()
此运算符用于标量引用,如下所示:
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))
上述代码行的等效 SQL 查询为:
SELECT invoices.id AS invoices_id, invoices.custid AS invoices_custid, invoices.invno AS invoices_invno, invoices.amount AS invoices_amount FROM invoices WHERE EXISTS ( SELECT 1 FROM customers WHERE customers.id = invoices.custid AND customers.name = ?)
SQLAlchemy ORM - 提前加载
提前加载减少了查询次数。SQLAlchemy 提供了通过查询选项调用的提前加载函数,这些函数为 Query 提供了其他说明。这些选项确定如何通过 Query.options() 方法加载各种属性。
子查询加载
我们希望 Customer.invoices 能够提前加载。orm.subqueryload() 选项提供了一个第二个 SELECT 语句,该语句完全加载与刚刚加载的结果关联的集合。名称“subquery”导致 SELECT 语句直接通过 Query 重新使用并作为子查询嵌入到针对相关表的 SELECT 中。
from sqlalchemy.orm import subqueryload c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()
这将产生以下两个 SQL 表达式:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)
要访问两个表中的数据,我们可以使用以下程序:
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))
上述程序的输出如下:
Govind Pant Gulmandi Aurangabad gpant@gmail.com Invoice no : 3, Amount : 10000 Invoice no : 4, Amount : 5000
连接加载
另一个函数称为 orm.joinedload()。这会发出一个 LEFT OUTER JOIN。引导对象以及相关对象或集合将在一步中加载。
from sqlalchemy.orm import joinedload c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()
这会发出以下表达式,输出与上面相同:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)
OUTER JOIN 产生了两个行,但它只返回一个 Customer 实例。这是因为 Query 根据对象标识对返回的实体应用了“唯一化”策略。可以应用连接提前加载而不会影响查询结果。
subqueryload() 更适合加载相关集合,而 joinedload() 更适合多对一关系。
SQLAlchemy ORM - 删除相关对象
在单个表上执行删除操作很容易。您只需从会话中删除映射类的对象并提交操作即可。但是,在多个相关表上执行删除操作有点棘手。
在我们的 sales.db 数据库中,Customer 和 Invoice 类分别映射到 customer 和 invoice 表,它们之间存在一对多类型的关系。我们将尝试删除 Customer 对象并查看结果。
作为快速参考,以下是 Customer 和 Invoice 类的定义:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
我们设置一个会话,并通过使用以下程序查询主键 ID 来获取 Customer 对象:
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind=engine) session = Session() x = session.query(Customer).get(2)
在我们的示例表中,x.name 恰好是“Gopal Krishna”。让我们从会话中删除此 x 并计算此名称出现的次数。
session.delete(x) session.query(Customer).filter_by(name = 'Gopal Krishna').count()
生成的 SQL 表达式将返回 0。
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0
但是,x 的相关 Invoice 对象仍然存在。可以通过以下代码验证:
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()
这里,10 和 14 是属于客户 Gopal Krishna 的发票编号。上述查询的结果为 2,这意味着相关对象尚未删除。
SELECT count(*) AS count_1 FROM ( SELECT invoices.id AS invoices_id, invoices.custid AS invoices_custid, invoices.invno AS invoices_invno, invoices.amount AS invoices_amount FROM invoices WHERE invoices.invno IN (?, ?)) AS anon_1(10, 14) 2
这是因为 SQLAlchemy 不会假设级联删除;我们必须发出删除它的命令。
要更改行为,我们可以在 User.addresses 关系上配置级联选项。让我们关闭正在进行的会话,使用新的 declarative_base() 并重新声明 User 类,包括级联配置在内的地址关系。
关系函数中的 cascade 属性是一个逗号分隔的级联规则列表,它决定了 Session 操作如何从父级“级联”到子级。默认情况下,它是 False,这意味着它是“save-update, merge”。
可用的级联如下:
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
常用的选项是“all, delete-orphan”,表示相关对象在所有情况下都应跟随父对象,并在解除关联时被删除。
因此,重新声明的 Customer 类如下所示:
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)
让我们使用下面的程序删除名为 Gopal Krishna 的 Customer,并查看其相关 Invoice 对象的数量:
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind = engine) session = Session() x = session.query(Customer).get(2) session.delete(x) session.query(Customer).filter_by(name = 'Gopal Krishna').count() session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()
现在计数为 0,上面脚本发出的 SQL 如下:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0
多对多关系
两个表之间的多对多关系是通过添加一个关联表来实现的,该表有两个外键——一个来自每个表的主键。此外,映射到这两个表的类具有一个属性,该属性包含一组来自其他关联表的对象,这些对象被分配为 relationship() 函数的 secondary 属性。
为此,我们将创建一个 SQLite 数据库 (mycollege.db),其中包含两个表——department 和 employee。在这里,我们假设一个员工可以属于多个部门,一个部门可以有多个员工。这构成了多对多关系。
映射到 department 和 employee 表的 Employee 和 Department 类的定义如下:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')
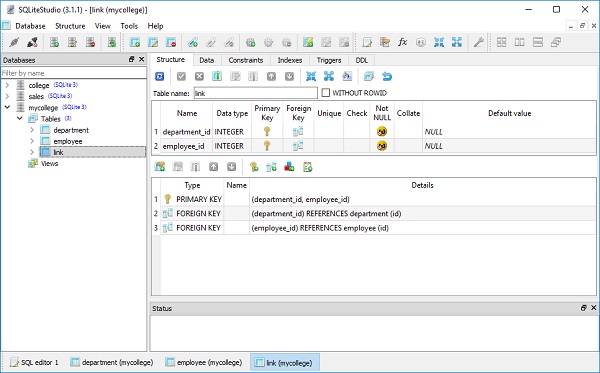
现在我们定义一个 Link 类。它链接到 link 表,分别包含 department_id 和 employee_id 属性,分别引用 department 和 employee 表的主键。
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)
这里,我们需要注意的是,Department 类具有与 Employee 类相关的 employees 属性。relationship 函数的 secondary 属性被分配了一个 link 作为其值。
类似地,Employee 类具有与 Department 类相关的 departments 属性。relationship 函数的 secondary 属性被分配了一个 link 作为其值。
执行以下语句时,将创建所有这三个表:
Base.metadata.create_all(engine)
Python 控制台发出以下 CREATE TABLE 查询:
CREATE TABLE department ( id INTEGER NOT NULL, name VARCHAR, PRIMARY KEY (id) ) CREATE TABLE employee ( id INTEGER NOT NULL, name VARCHAR, PRIMARY KEY (id) ) CREATE TABLE link ( department_id INTEGER NOT NULL, employee_id INTEGER NOT NULL, PRIMARY KEY (department_id, employee_id), FOREIGN KEY(department_id) REFERENCES department (id), FOREIGN KEY(employee_id) REFERENCES employee (id) )
我们可以通过使用 SQLiteStudio 打开 mycollege.db 来检查这一点,如下面的屏幕截图所示:
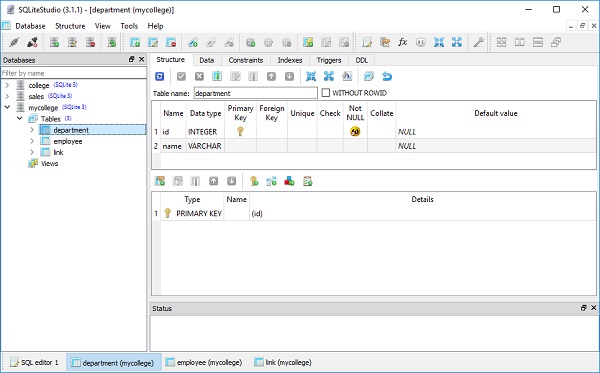
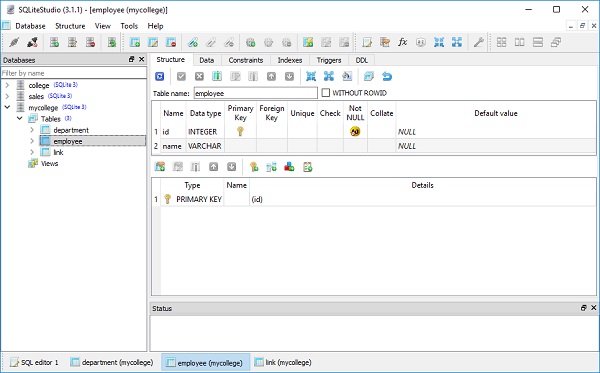
接下来,我们创建三个 Department 类的对象和三个 Employee 类的对象,如下所示:
d1 = Department(name = "Accounts") d2 = Department(name = "Sales") d3 = Department(name = "Marketing") e1 = Employee(name = "John") e2 = Employee(name = "Tony") e3 = Employee(name = "Graham")
每个表都有一个包含 append() 方法的集合属性。我们可以将 Employee 对象添加到 Department 对象的 Employees 集合中。类似地,我们可以将 Department 对象添加到 Employee 对象的 departments 集合属性中。
e1.departments.append(d1) e2.departments.append(d3) d1.employees.append(e3) d2.employees.append(e2) d3.employees.append(e1) e3.departments.append(d2)
现在我们要做的就是设置一个 session 对象,将所有对象添加到其中并提交更改,如下所示:
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind = engine) session = Session() session.add(e1) session.add(e2) session.add(d1) session.add(d2) session.add(d3) session.add(e3) session.commit()
以下 SQL 语句将在 Python 控制台上发出:
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))
要检查上述操作的效果,请使用 SQLiteStudio 并查看 department、employee 和 link 表中的数据:
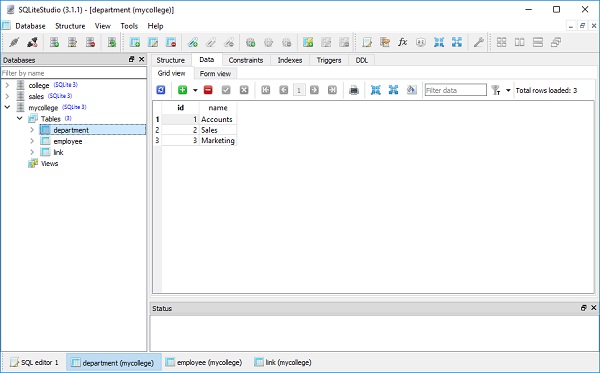
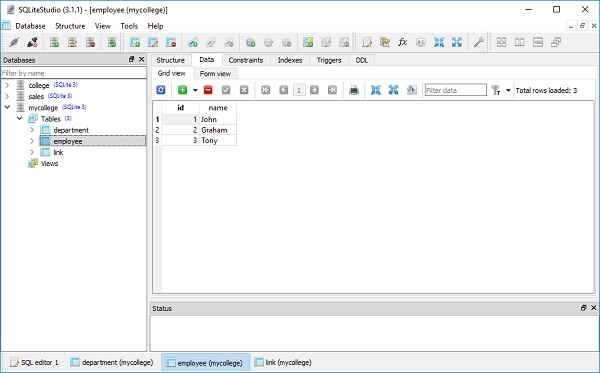
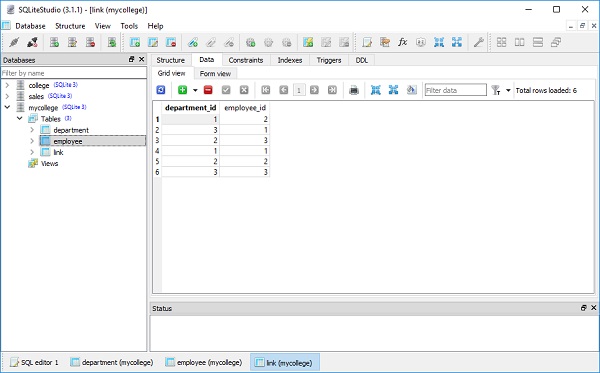
要显示数据,请运行以下查询语句:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))
根据我们示例中填充的数据,输出将显示如下:
Department: Accounts Name: John Department: Accounts Name: Graham Department: Sales Name: Graham Department: Sales Name: Tony Department: Marketing Name: John Department: Marketing Name: Tony
SQLAlchemy - 方言
SQLAlchemy 使用方言系统与各种类型的数据库进行通信。每个数据库都有一个相应的 DBAPI 包装器。所有方言都需要安装相应的 DBAPI 驱动程序。
SQLAlchemy API 中包含以下方言:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
create_engine() 函数生成基于 URL 的 Engine 对象。这些 URL 可以包含用户名、密码、主机名和数据库名称。可能存在用于其他配置的可选关键字参数。在某些情况下,会接受文件路径,而在其他情况下,“数据源名称”会替换“主机”和“数据库”部分。数据库 URL 的典型形式如下:
dialect+driver://username:password@host:port/database
PostgreSQL
PostgreSQL 方言使用psycopg2作为默认的 DBAPI。pg8000 也可用作纯 Python 替代品,如下所示
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
MySQL
MySQL 方言使用mysql-python作为默认的 DBAPI。有许多可用的 MySQL DBAPI,例如 MySQL-connector-python,如下所示:
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')
Oracle
Oracle 方言使用cx_oracle作为默认的 DBAPI,如下所示:
engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
Microsoft SQL Server
SQL Server 方言使用pyodbc作为默认的 DBAPI。pymssql 也可用。
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')
SQLite
SQLite 连接到基于文件的数据库,默认情况下使用 Python 内置模块sqlite3。由于 SQLite 连接到本地文件,因此 URL 格式略有不同。“file”部分是数据库的文件名。对于相对文件路径,这需要三个斜杠,如下所示:
engine = create_engine('sqlite:///foo.db')
对于绝对文件路径,三个斜杠后跟绝对路径,如下所示:
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
要使用 SQLite:memory: 数据库,请指定一个空 URL,如下所示:
engine = create_engine('sqlite://')
结论
在本教程的第一部分,我们学习了如何使用表达式语言执行 SQL 语句。表达式语言将 SQL 结构嵌入到 Python 代码中。在第二部分中,我们讨论了 SQLAlchemy 的对象关系映射功能。ORM API 将 SQL 表与 Python 类映射。