- 大数据分析教程
- 大数据分析 - 首页
- 大数据分析 - 概述
- 大数据分析 - 特征
- 大数据分析 - 数据生命周期
- 大数据分析 - 架构
- 大数据分析 - 方法论
- 大数据分析 - 核心交付成果
- 大数据采用及规划考虑
- 大数据分析 - 主要利益相关者
- 大数据分析 - 数据分析师
- 大数据分析 - 数据科学家
- 大数据分析有用资源
- 大数据分析 - 快速指南
- 大数据分析 - 资源
- 大数据分析 - 讨论
大数据分析 - 数据生命周期
生命周期是一个过程,它表示大数据分析中涉及的一个或多个活动的顺序流程。在学习大数据分析生命周期之前,让我们先了解传统的数据挖掘生命周期。
传统数据挖掘生命周期
为了为组织系统地组织工作提供框架;该框架支持整个业务流程,并提供宝贵的业务洞察力,以便做出战略决策,在竞争激烈的世界中生存,并最大限度地提高利润。
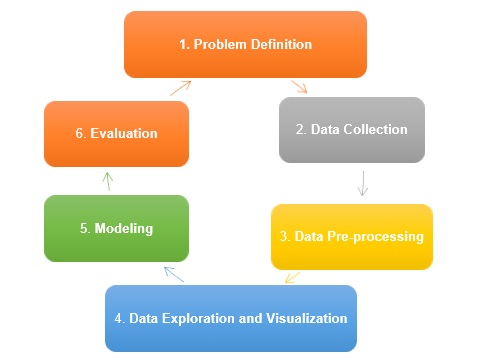
传统数据挖掘生命周期包括以下阶段:
- 问题定义 - 这是数据挖掘过程的初始阶段;它包括需要发现或解决的问题定义。问题定义始终包括需要实现的业务目标以及需要探索的数据,以识别模式、业务趋势和流程流程,以实现定义的目标。
- 数据收集 - 下一步是数据收集。此阶段涉及从数据库、网络日志或社交媒体平台等不同来源提取数据,这些数据需要进行分析和进行商业智能。收集到的数据被认为是原始数据,因为它包含杂质,并且可能不是所需的格式和结构。
- 数据预处理 - 数据收集后,我们对其进行清理和预处理,以去除噪声、缺失值插补、数据转换、特征选择,并将数据转换为所需的格式,然后才能开始分析。
- 数据探索和可视化 - 完成数据的预处理后,我们对其进行探索以了解其特征,并识别模式和趋势。此阶段还包括使用散点图、直方图或热图等数据可视化方法,以图形形式显示数据。
- 建模 - 此阶段包括创建数据模型来解决在阶段 1 中定义的实际问题。这可能包括有效的机器学习算法;训练模型,并评估其性能。
- 评估 - 数据挖掘的最后阶段是评估模型的性能,并确定它是否符合步骤 1 中的业务目标。如果模型性能不佳,则可能需要再次进行数据探索或特征选择。
CRISP-DM方法论
CRISP-DM代表跨行业标准数据挖掘流程;这是一种方法,它描述了数据挖掘专家用来解决传统BI数据挖掘中问题的常用方法。它仍在传统BI数据挖掘团队中使用。下图对此进行了说明。它描述了CRISP-DM周期的主要阶段以及它们是如何相互关联的。
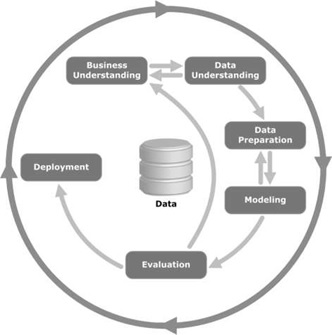
CRISP-DM于1996年推出,次年作为欧盟在ESPRIT资助计划下的一个项目启动。该项目由五家公司牵头:SPSS、Teradata、戴姆勒股份公司、NCR公司和OHRA(一家保险公司)。该项目最终被纳入SPSS。
CRISP-DM生命周期的阶段 | CRISP-DM生命周期的步骤
- 业务理解 - 此阶段包括从业务角度定义问题、项目目标和要求,然后将其转换为数据挖掘。制定初步计划以实现目标。
- 数据理解 - 数据理解阶段最初从数据收集开始,以识别数据质量、发现数据洞察力或检测有趣的子集,以形成对隐藏信息的假设。
- 数据准备 - 数据准备阶段涵盖所有活动,以从初始原始数据构建最终数据集(将馈送到建模工具的数据)。数据准备任务可能会多次执行,并且不会按照任何规定的顺序执行。任务包括表、记录和属性选择以及数据的转换和清理,以用于建模工具。
- 建模 - 在此阶段,选择和应用不同的建模技术;可能有多种技术可用于处理相同类型的数据;专家总是选择有效且高效的技术。
- 评估 - 建立建议模型后;在最终部署模型之前,务必对其进行彻底评估,并审查为构建模型而执行的步骤,以确保模型实现预期的业务目标。
- 部署 - 模型的创建通常不是项目的结束。即使模型的目的是提高对数据的了解,获得的知识也需要以对客户有用的方式进行组织和呈现。在许多情况下,将是客户而不是数据分析师来执行部署阶段。即使分析师部署了模型,客户也需要预先了解需要采取哪些行动才能使用创建的模型。
SEMMA方法论
SEMMA是SAS为数据挖掘建模开发的另一种方法。它代表样本、探索、修改、模型和评估。

其阶段的描述如下:
- 样本 - 该过程从数据采样开始,例如,选择用于建模的数据集。数据集应足够大,以包含足够的信息来检索,但又足够小,以便有效使用。此阶段还处理数据分区。
- 探索 - 此阶段涵盖通过发现变量之间预期和意外的关系以及异常值(借助数据可视化)来了解数据。
- 修改 - “修改”阶段包含为数据建模准备选择、创建和转换变量的方法。
- 模型 - 在“模型”阶段,重点是将各种建模(数据挖掘)技术应用于准备好的变量,以创建可能提供所需结果的模型。
- 评估 - 对建模结果的评估显示了创建模型的可靠性和实用性。
CRISM-DM和SEMMA的主要区别在于,SEMMA侧重于建模方面,而CRISP-DM更重视建模之前的周期阶段,例如理解要解决的业务问题,理解和预处理要用作输入的数据,例如机器学习算法。
大数据生命周期
大数据分析是一个涉及管理整个数据生命周期的领域,包括数据收集、清洗、组织、存储、分析和治理。在大数据环境下,传统方法对于分析大批量数据、具有不同值的数据、数据速度等并不是最佳的。
例如,SEMMA方法论摒弃了不同数据源的数据收集和预处理。这些阶段通常构成成功大数据项目的大部分工作。大数据分析涉及识别、获取、处理和分析大量原始数据、非结构化和半结构化数据,其目标是提取有价值的信息,用于趋势识别、增强现有公司数据和进行广泛搜索。
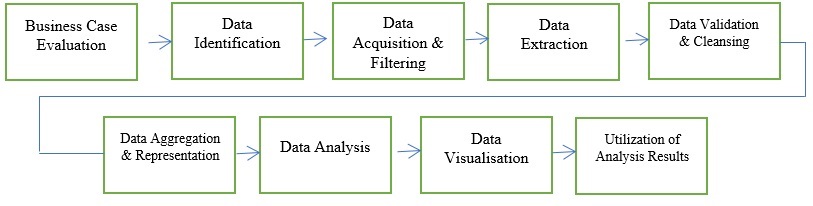
大数据分析生命周期可以分为以下阶段:
- 业务案例评估
- 数据识别
- 数据获取和过滤
- 数据提取
- 数据验证和清洗
- 数据聚合和表示
- 数据分析
- 数据可视化
- 分析结果的利用
大数据分析与传统数据分析的主要区别在于处理的数据的价值、速度和多样性。为了满足大数据分析的特定要求,需要一种有组织的方法。大数据分析生命周期阶段的描述如下:
业务案例评估
大数据分析生命周期始于明确定义的业务案例,该案例概述了进行分析的问题识别、目标和目标。在开始实际的动手分析工作之前,业务案例评估需要创建、评估和批准业务案例。
对大数据分析业务案例的检查为决策者提供了方向,以了解所需业务资源和需要解决的业务问题。案例评估检查正在解决的业务问题定义是否确实是大型数据问题。
数据识别
数据识别阶段侧重于识别分析项目所需的数据集及其来源。识别更大范围的数据源可以提高发现隐藏模式和关系的机会。根据公司正在解决的业务问题的性质,公司可能需要内部或外部数据集和来源。
数据获取和过滤
数据获取过程包括从上一阶段提到的所有来源收集数据。我们将数据进行自动过滤,以去除与研究目标无关的损坏数据或记录。根据数据源的类型,数据可能作为文件的集合出现,例如从第三方数据提供商那里获取的数据,或者作为API集成,例如与Twitter。
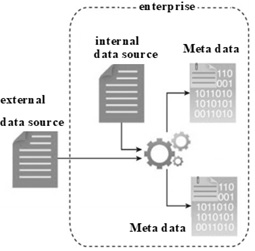
一旦生成或进入企业边界,我们就必须保存内部和外部数据。我们将此数据保存到磁盘,然后使用批处理分析对其进行分析。在实时分析中,我们在将数据保存到磁盘之前先对其进行分析。
数据提取
此阶段侧重于提取不同的数据并将其转换为底层大数据解决方案可用于数据分析的格式。
数据验证和清洗
不正确的数据可能会使分析结果产生偏差和误导。与具有预定义结构并经过验证可以馈入分析的典型企业数据不同;如果在分析之前未验证数据,则大数据分析可能是非结构化的。其复杂性可能使得难以制定一套适当的验证要求。数据验证和清洗负责定义复杂的验证标准并删除任何已知的错误数据。
数据聚合和表示
数据聚合和表示阶段侧重于组合多个数据集以创建连贯的视图。由于以下方面的差异,执行此阶段可能会变得棘手:
数据结构 - 数据格式可能相同,但数据模型可能不同。
语义 - 在两个数据集中标签不同的变量可能表示相同的意思,例如“姓氏”和“姓”。
数据分析
数据分析阶段负责执行实际的分析工作,通常包括一种或多种类型的分析。特别是如果数据分析是探索性的,我们可以迭代地继续这个阶段,直到我们发现正确的模式或关联。
数据可视化
数据可视化阶段以图形方式可视化数据,以便业务用户有效地解读结果。最终结果有助于执行可视化分析,使他们能够发现他们尚未提出的问题的答案。
分析结果的利用
向业务人员提供可用于支持业务决策的结果,例如通过仪表板。所有提到的九个阶段都是大数据分析生命周期的主要阶段。
以下阶段也应考虑在内:
研究
分析其他公司在相同情况下所做的事情。这包括寻找对贵公司合理的解决方案,即使这需要根据贵公司的资源和要求调整其他解决方案。在这个阶段,应该定义未来阶段的方法。
人力资源评估
一旦问题定义明确,就可以继续分析现有员工是否能够成功完成项目。传统的BI团队可能无法为所有阶段提供最佳解决方案,因此在项目开始之前,应该考虑是否有必要外包部分项目或招聘更多人员。
数据采集
此部分在大数据生命周期中至关重要;它定义了交付最终数据产品所需的哪种类型的配置文件。数据收集是一个非平凡的步骤;它通常涉及从不同来源收集非结构化数据。例如,这可能涉及编写爬虫程序以从网站检索评论。这涉及处理文本,可能使用不同的语言,通常需要大量时间才能完成。
数据清洗
例如,一旦数据从网络检索到,就需要将其存储为易于使用的格式。继续以评论为例,假设数据是从不同的网站检索的,每个网站的数据显示方式都不同。
假设一个数据源以星级评分的形式提供评论,因此可以将其解读为响应变量$\mathrm{y\:\epsilon \:\lbrace 1,2,3,4,5\rbrace}$的映射。另一个数据源使用箭头系统提供评论,一个用于点赞,另一个用于点踩。这意味着响应变量的形式为$\mathrm{y\:\epsilon \:\lbrace positive,negative \rbrace}$。
为了组合这两个数据源,必须做出决定以使这两个响应表示等效。这可能涉及将第一个数据源响应表示转换为第二种形式,将一颗星视为负面,五颗星视为正面。此过程通常需要大量时间才能高质量地交付。
数据存储
数据处理完毕后,有时需要将其存储在数据库中。大数据技术在这方面提供了许多替代方案。最常见的替代方案是使用Hadoop文件系统进行存储,该系统为用户提供了SQL的有限版本,称为HIVE查询语言。从用户的角度来看,这允许大多数分析任务以与传统BI数据仓库中类似的方式完成。其他需要考虑的存储选项包括MongoDB、Redis和SPARK。
生命周期的这个阶段与人力资源的知识有关,涉及他们实施不同架构的能力。传统数据仓库的修改版本仍在大型应用程序中使用。例如,Teradata和IBM提供可以处理TB级数据的SQL数据库;PostgreSQL和MySQL等开源解决方案仍在大型应用程序中使用。
尽管不同存储在后台的工作方式存在差异,但从客户端来看,大多数解决方案都提供了SQL API。因此,对SQL有良好的理解仍然是大数据分析的关键技能。这个阶段先验地似乎是最重要的主题,实际上并非如此。它甚至不是一个必要的阶段。可以实现一个使用实时数据的大数据解决方案,因此在这种情况下,我们只需要收集数据来开发模型,然后实时地实现它。因此根本不需要正式存储数据。
探索性数据分析
一旦数据被清理并以可以从中检索见解的方式存储,数据探索阶段是必须的。此阶段的目标是理解数据,这通常使用统计技术以及绘制数据来完成。这是一个评估问题定义是否有意义或是否可行的良好阶段。
建模和评估的数据准备
此阶段涉及重塑先前检索到的清理数据,并使用统计预处理进行缺失值插补、异常值检测、归一化、特征提取和特征选择。
建模
前一阶段应该已经产生了几个用于训练和测试的数据集,例如预测模型。此阶段涉及尝试不同的模型,并期望解决手头的业务问题。实际上,通常希望模型能够提供一些对业务的见解。最后,选择最佳模型或模型组合,评估其在遗漏数据集上的性能。
实施
在这个阶段,开发的数据产品被集成到公司的數據管道中。这包括在数据产品运行时设置验证方案以跟踪其性能。例如,在实施预测模型的情况下,此阶段将涉及将模型应用于新数据,并且一旦响应可用,就评估模型。