- 大数据分析教程
- 大数据分析 - 首页
- 大数据分析 - 概述
- 大数据分析 - 特征
- 大数据分析 - 数据生命周期
- 大数据分析 - 架构
- 大数据分析 - 方法论
- 大数据分析 - 核心交付成果
- 大数据采用与规划注意事项
- 大数据分析 - 关键利益相关者
- 大数据分析 - 数据分析师
- 大数据分析 - 数据科学家
- 大数据分析有用资源
- 大数据分析 - 快速指南
- 大数据分析 - 资源
- 大数据分析 - 讨论
大数据分析 - 架构
什么是大数据架构?
大数据架构专门设计用于管理数据摄取、数据处理和分析数据量太大或过于复杂的数据。大规模数据无法由传统的关联数据库进行存储、处理和管理。解决方案是将技术组织成大数据架构的结构。大数据架构能够管理和处理数据。
大数据架构的关键方面
以下是大数据架构的一些关键方面:
- 存储和处理100 GB大小的大型数据。
- 聚合和转换各种非结构化数据以进行分析和报告。
- 实时访问、处理和分析流数据。
大数据架构图
下图显示了大数据架构及其不同组件的顺序排列。一个组件的结果作为另一个组件的输入,此流程一直持续到处理数据的输出。以下是大数据架构图:
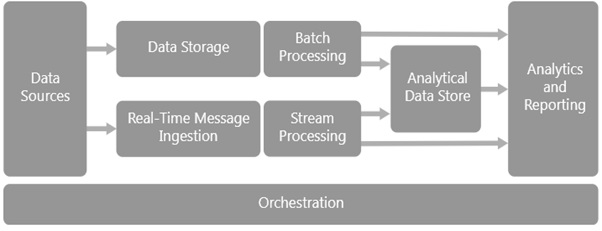
大数据架构的组件
以下是大数据架构的不同组件:
数据源
所有大数据解决方案都始于一个或多个数据源。大数据架构可容纳各种数据源并有效地管理各种数据类型。大数据架构中的一些常见数据源包括事务数据库、日志、机器生成数据、社交媒体和网络数据、流数据、外部数据源、基于云的数据、NOSQL数据库、数据仓库、文件系统、API和Web服务。
这些只是一些实例;实际上,数据环境很广阔并且不断变化,随着时间的推移,新的来源和技术不断发展。大数据架构的主要挑战是成功地集成、处理和分析来自各种来源的数据,以便获得相关的见解并推动决策。
数据存储
数据存储是大数据架构中用于存储和管理大量数据的系统。大数据包括处理大量结构化、半结构化和非结构化数据;由于可扩展性和性能限制,传统的关联数据库通常被证明不足。
分布式文件存储通常存储用于批处理操作的数据,这些存储能够以各种格式存储大量文件。人们通常将这种类型的存储称为数据湖。为此,您可以使用 Azure Data Lake Storage 或 Azure 存储中的 Blob 容器。在大数据架构中,下图显示了数据存储的关键方法:
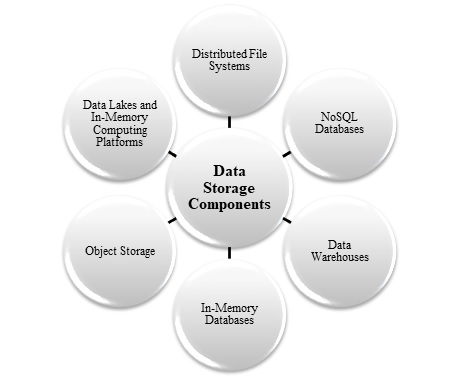
数据存储系统的选择取决于不同的方面,包括数据类型、性能要求、可扩展性和财务限制。不同的大数据架构使用这些存储系统的混合来有效地满足不同的用例和目标。
批处理
使用长时间运行的批处理作业处理数据以过滤、聚合和准备数据以进行分析,这些作业通常涉及读取和处理源文件,然后将输出写入新文件。批处理是大数据架构的一个基本组成部分,它允许使用预定的批次有效地处理大量数据。它包括以预定的间隔而不是实时地批量收集、处理和分析数据。
批处理对于不需要立即响应的操作(例如数据分析、报告和基于批次的数据库转换)特别有用。您可以在 Azure Data Lake Analytics 中运行 U-SQL 作业,在 HDInsight Hadoop 群集中使用 Hive、Pig 或自定义 Map/Reduce 作业,或在 HDInsight Spark 群集中使用 Java、Scala 或 Python 程序。
大数据架构在实时消息摄取中发挥着重要作用,因为它需要在数据流生成或接收时实时捕获和处理数据流。此功能帮助企业处理高速数据源,例如传感器馈送、日志文件、社交媒体更新、点击流和物联网设备等。
实时消息摄取
实时消息摄取系统对于提取重要见解、识别异常并立即响应事件至关重要。下图显示了在大数据架构中用于实时消息摄取的不同方法:
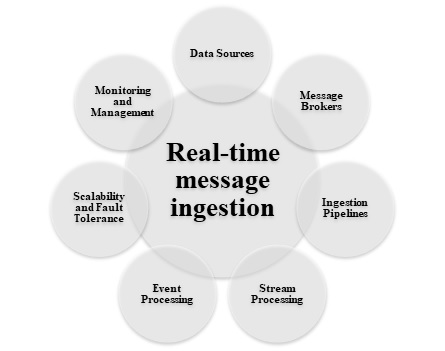
该架构包含一种用于捕获和存储实时消息以进行流处理的方法;如果解决方案包含实时源。这可能是一个数据存储系统,其中传入的消息被放入一个文件夹以供处理。但是,消息摄取存储对于不同的方法至关重要,因为它充当消息的缓冲区,并有助于扩展处理、可靠交付和其他消息队列语义。一些有效的解决方案是 Azure 事件中心、Azure IoT 中心和 Kafka。
流处理
流处理是一种数据处理类型,它会持续处理数据记录,这些记录会实时生成或接收。它使企业能够快速分析、转换和响应数据流,从而获得及时的见解、警报和操作。流处理是大数据架构的一个关键组成部分,尤其是在处理传感器数据、日志、社交媒体更新、金融交易和物联网设备遥测等大量数据源时。
下图说明了流处理在大数据架构中的工作原理:
在收集实时消息后,一个提议的解决方案通过过滤、聚合和准备数据来处理数据,以便进行分析。随后,处理后的流数据存储在输出接收器中。Azure 流分析提供了一种托管的流处理服务,该服务基于在无界流上持续执行 SQL 查询。此外,我们可以在 HDInsight 群集上使用开源 Apache 流式技术(如 Storm 和 Spark Streaming)。
分析数据存储
在大数据分析中,分析数据存储 (ADS) 是一个定制的数据库或数据存储系统,旨在处理复杂的分析查询和海量数据。ADS 旨在促进临时查询、数据探索、报告和高级分析任务,使其成为大数据系统中业务智能和分析的重要组成部分。下图总结了大数据分析中分析数据存储的关键特征:
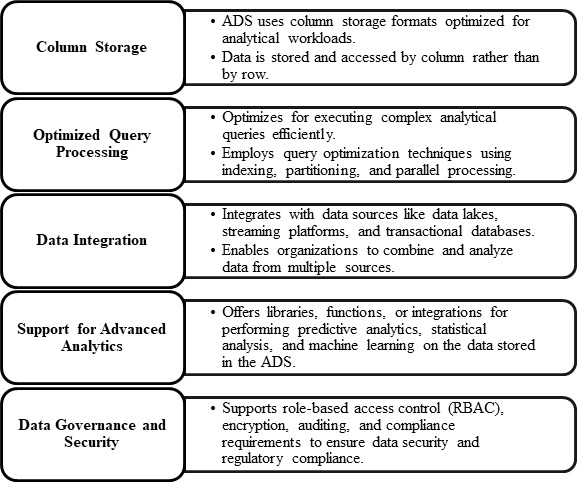
分析工具可以查询结构化数据。低延迟 NoSQL 技术(如 HBase 或交互式 Hive 数据库)可以通过从分布式数据存储系统中的数据文件中提取信息来呈现数据。Azure Synapse Analytics 是一种用于大规模基于云的数据仓库的托管解决方案。您可以使用 HDInsight 中的 Hive、HBase 和 Spark SQL 来服务和分析数据。
分析和报告
大数据分析和报告是从海量和复杂信息中提取见解、模式和趋势的过程,以帮助决策、战略规划和运营改进。它包括用于分析数据和以有用和实用方式呈现结果的不同策略、工具和方法。
下图简要介绍了大数据分析中不同的分析和报告方法:

大多数大数据解决方案旨在通过分析和报告从数据中提取见解。为了使用户能够分析数据,架构可能包含一个数据建模层,例如 Azure Analysis Services 中的多维 OLAP 多维数据集或表格数据模型。它还可以通过利用 Microsoft Power BI 或 Excel 中找到的建模和可视化功能来提供自助式商业智能。数据科学家或分析师可能会在他们的分析和报告过程中进行交互式数据探索。
编排
在大数据分析中,编排是指协调和管理用于执行数据使用的不同任务、流程和资源。为了确保大数据分析工作流高效且可靠地运行,有必要自动化数据和处理流程的流向、安排作业、管理依赖关系并监控任务性能。
下图包含编排中使用的不同步骤:
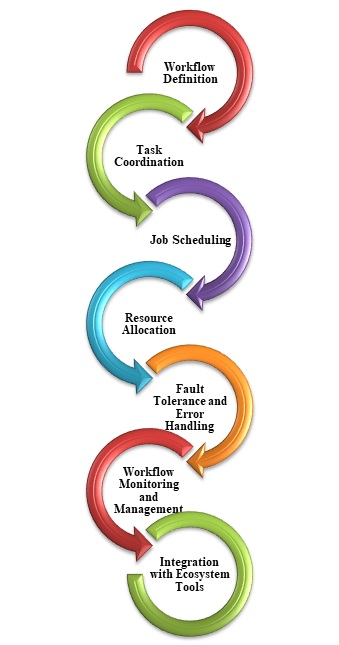
转换源数据、跨不同源和接收器传输数据、将处理后的数据加载到分析数据存储中或将结果直接输出到报表或仪表板的工作流构成了大多数大数据解决方案。要自动化这些活动,请使用 Azure Data Factory、Apache Oozie 或 Sqoop 等编排工具。