- Python机器学习
- 首页
- 基础
- Python 生态系统
- 机器学习方法
- ML 项目的数据加载
- 用统计学理解数据
- 用可视化理解数据
- 准备数据
- 数据特征选择
- ML 算法 - 分类
- 介绍
- 逻辑回归
- 支持向量机 (SVM)
- 决策树
- 朴素贝叶斯
- 随机森林
- ML 算法 - 回归
- 随机森林
- 线性回归
- ML 算法 - 聚类
- 概述
- K均值算法
- 均值漂移算法
- 层次聚类
- ML 算法 - KNN 算法
- 寻找最近邻
- 性能指标
- 自动工作流
- 提高 ML 模型的性能
- 提高 ML 模型的性能(续…)
- Python机器学习 - 资源
- Python机器学习 - 快速指南
- Python机器学习 - 资源
- Python机器学习 - 讨论
聚类算法 - 层次聚类
层次聚类的介绍
层次聚类是另一种无监督学习算法,用于将具有相似特征的未标记数据点分组在一起。层次聚类算法分为以下两类:
凝聚层次算法 - 在凝聚层次算法中,每个数据点都被视为一个单独的簇,然后依次合并或聚集(自下而上的方法)成对的簇。簇的层次结构表示为树状图或树结构。
分裂层次算法 - 另一方面,在分裂层次算法中,所有数据点都被视为一个大的簇,并且聚类的过程涉及将一个大的簇划分为多个小的簇(自上而下的方法)。
执行凝聚层次聚类的步骤
我们将解释最常用和最重要的层次聚类,即凝聚层次聚类。执行此操作的步骤如下:
步骤 1 - 将每个数据点视为单个簇。因此,我们开始时将有 K 个簇。数据点的数量开始时也将为 K。
步骤 2 - 现在,在此步骤中,我们需要通过连接两个最接近的数据点来形成一个大的簇。这将导致总共 K-1 个簇。
步骤 3 - 现在,要形成更多簇,我们需要连接两个最接近的簇。这将导致总共 K-2 个簇。
步骤 4 - 现在,要形成一个大的簇,重复上述三个步骤,直到 K 变为 0,即没有更多数据点可以连接。
步骤 5 - 最后,在形成一个大的簇后,将使用树状图根据问题将其划分为多个簇。
树状图在凝聚层次聚类中的作用
正如我们在上一步中所讨论的,一旦形成大的簇,树状图的作用就开始了。树状图将用于根据我们的问题将簇拆分为多个相关数据点的簇。可以通过以下示例来理解:
示例 1
为了理解,让我们从导入所需的库开始,如下所示:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
接下来,我们将绘制在此示例中使用的所有数据点:
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize=(10, 7)) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1], label='True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom') plt.show()
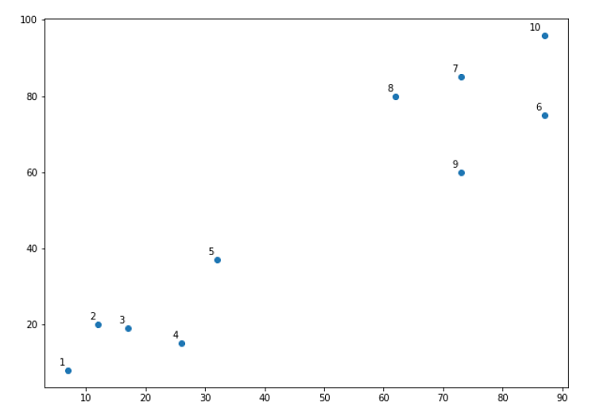
从上图中,很容易看出我们的数据点中有两个簇,但在现实世界的数据中,可能会有数千个簇。接下来,我们将使用 Scipy 库绘制数据点的树状图:
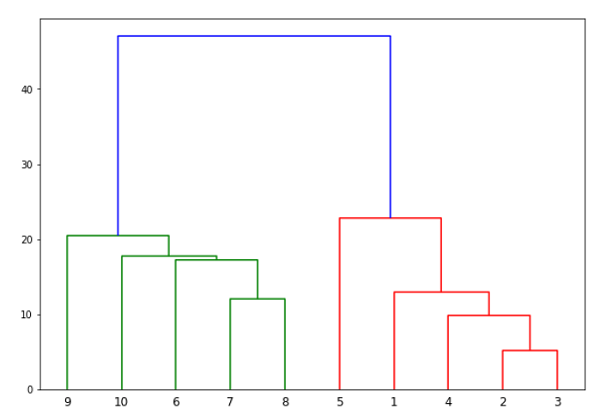
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize=(10, 7)) dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True) plt.show()
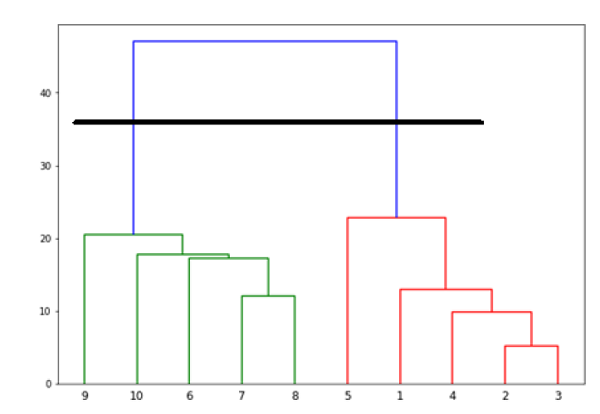
现在,一旦形成大的簇,就会选择最长的垂直距离。然后,如以下图表所示,通过它绘制一条垂直线。由于水平线在两点与蓝线相交,因此簇的数量将为两个。
接下来,我们需要导入用于聚类的类并调用其 fit_predict 方法来预测簇。我们正在导入 sklearn.cluster 库的 AgglomerativeClustering 类:
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(X)
接下来,使用以下代码绘制簇:
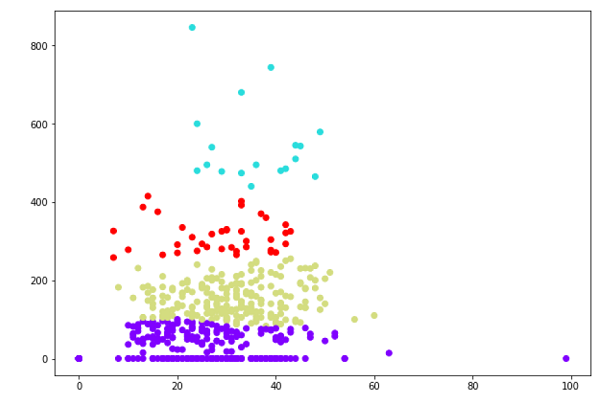
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')
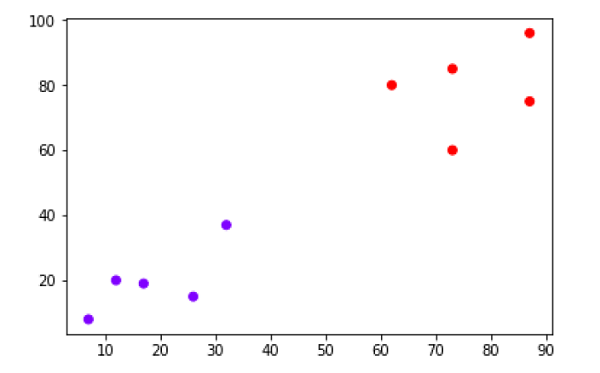
上图显示了我们数据点中的两个簇。
示例 2
正如我们从上面讨论的简单示例中理解了树状图的概念,让我们继续另一个示例,其中我们使用层次聚类创建皮马印第安人糖尿病数据集中的数据点的簇:
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head()
| 序号。 | 孕期 | 葡萄糖 | 血压 | 皮肤厚度 | 胰岛素 | 体重指数 | 糖尿病谱系 | 年龄 | 类别 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
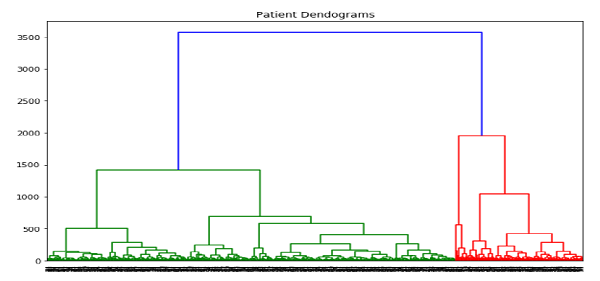
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward') cluster.fit_predict(patient_data) plt.figure(figsize=(10, 7)) plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')