- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 所需技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 局限性
- ML - 现实生活中的例子
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 平均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于中心点的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 后向消除法
- ML - 前向特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精确率和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 时期
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习中的数据可视化
数据可视化是机器学习 (ML) 的一个重要方面,因为它有助于分析和传达数据中的模式、趋势和见解。数据可视化涉及创建数据的图形表示,这有助于识别可能无法从原始数据中显而易见的模式和关系。
什么是数据可视化?
数据可视化是对数据和信息的图形表示。借助数据可视化,我们可以看到数据的外观以及数据的属性之间存在何种关联。它是快速查看特征是否对应于输出的最快方法。
数据可视化在机器学习中的重要性
数据可视化在机器学习中发挥着重要作用。我们可以在机器学习中以多种方式使用它。以下是数据可视化在机器学习中的一些用途:
- 探索数据 - 数据可视化是探索和理解数据的必不可少的工具。可视化可以帮助识别模式、相关性和异常值,还可以帮助检测数据质量问题,例如缺失值和不一致性。
- 特征选择 - 数据可视化可以帮助为ML模型选择相关的特征。通过可视化数据及其与目标变量的关系,您可以识别与目标变量高度相关的特征,并排除预测能力较弱的无关特征。
- 模型评估 - 数据可视化可用于评估ML模型的性能。ROC曲线、精确率-召回率曲线和混淆矩阵等可视化技术可以帮助理解模型的准确率、精确率、召回率和F1分数。
- 传达见解 - 数据可视化是向可能没有技术背景的利益相关者传达见解和结果的有效方法。散点图、折线图和条形图等可视化可以帮助以易于理解的格式传达复杂信息。
用于数据可视化的流行Python库
以下是机器学习中用于数据可视化最流行的Python库。这些库提供了广泛的可视化技术和自定义选项,以满足不同的需求和偏好。
1. Matplotlib
Matplotlib是用于数据可视化最流行的Python包之一。它是一个跨平台库,用于根据数组中的数据绘制二维图。它提供了一个面向对象的API,有助于使用Python GUI工具包(如PyQt、WxPython或Tkinter)将绘图嵌入应用程序中。它也可用于Python和IPython shell、Jupyter Notebook以及Web应用程序服务器。
2. Seaborn
Seaborn是一个开源的、基于BSD许可的Python库,它提供用于使用Python编程语言可视化数据的高级API。
3. Plotly
Plotly是一家位于蒙特利尔的科技计算公司,参与开发数据分析和可视化工具,如Dash和Chart Studio。它还为Python、R、MATLAB、Javascript和其他计算机编程语言开发了开源图形应用程序编程接口 (API) 库。
4. Bokeh
Bokeh是Python的一个数据可视化库。与Matplotlib和Seaborn不同,它们也是Python数据可视化包,Bokeh使用HTML和JavaScript呈现其绘图。因此,它被证明对开发基于Web的仪表板非常有用。
数据可视化的类型
机器学习数据的数据可视化可以分为以下两类:
- 单变量图
- 多变量图
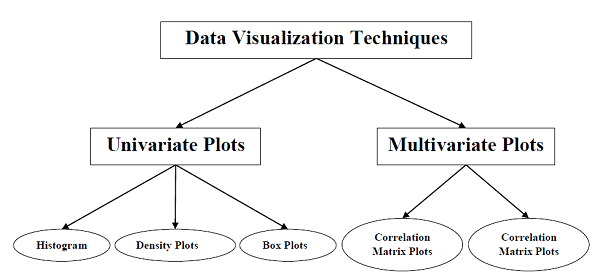
让我们详细了解上述两种类型的数据可视化图。
单变量图:独立理解属性
最简单类型的可视化是单变量或“单变量”可视化。借助单变量可视化,我们可以独立地理解数据集的每个属性。以下是使用Python实现单变量可视化的一些技术:
我们将在各自的章节中详细学习上述技术。让我们简要了解一下这些技术。
直方图
直方图将数据分组到箱中,并且是快速了解数据集中每个属性分布的最快方法。以下是直方图的一些特征:
- 它为我们提供了为可视化创建的每个箱中观察值的计数。
- 从箱的形状,我们可以很容易地观察到分布,即它是高斯分布、偏态分布还是指数分布。
- 直方图还有助于我们看到可能的异常值。
示例
以下代码是创建直方图的Python脚本示例。在这里,我们将使用NumPy数组上的hist()函数生成直方图,并使用matplotlib进行绘图。
import matplotlib.pyplot as plt
import numpy as np
# Generate some random data
data = np.random.randn(1000)
# Create the histogram
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
plt.xlabel('Values')
plt.ylabel('Frequency')
plt.title('Histogram Example')
plt.show()
输出

由于随机数生成,当您执行上述程序时,您可能会注意到输出之间存在细微差异。
密度图
密度图是另一种快速简便的技术,用于获取每个属性的分布。它也类似于直方图,但在每个箱子的顶部绘制一条平滑的曲线。我们可以将其称为抽象的直方图。
示例
在下面的示例中,Python脚本将为鸢尾花数据集的属性分布生成密度图。
import seaborn as sns
import matplotlib.pyplot as plt
# Load a sample dataset
df = sns.load_dataset("iris")
# Create the density plot
sns.kdeplot(data=df, x="sepal_length", fill=True)
# Add labels and title
plt.xlabel("Sepal Length")
plt.ylabel("Density")
plt.title("Density Plot of Sepal Length")
# Show the plot
plt.show()
输出

从上面的输出中,可以很容易地理解密度图和直方图之间的区别。
箱线图
箱线图,简称箱图,是另一种用于查看每个属性分布的有用技术。以下是此技术的特点:
- 它是单变量的,并总结了每个属性的分布。
- 它绘制一条代表中间值(即中位数)的线。
- 它在25%和75%处绘制一个箱体。
- 它还绘制须线,这将使我们了解数据的离散程度。
- 须线外的点表示异常值。异常值将是中间数据离散程度的1.5倍。
示例
在下面的示例中,Python脚本将为鸢尾花数据集的属性分布生成箱线图。
import matplotlib.pyplot as plt
# Sample data
data = [10, 15, 18, 20, 22, 25, 28, 30, 32, 35]
# Create a figure and axes
fig, ax = plt.subplots()
# Create the boxplot
ax.boxplot(data)
# Set the title
ax.set_title('Box and Whisker Plot')
# Show the plot
plt.show()
输出

多变量图:多个变量之间的交互
另一种可视化类型是多变量或“多元”可视化。借助多元可视化,我们可以理解数据集的多个属性之间的交互。以下是Python中实现多元可视化的一些技术:
相关矩阵图
相关性是两个变量之间变化的指示。我们可以绘制相关矩阵图来显示哪个变量相对于另一个变量具有高或低相关性。
示例
在下面的示例中,Python脚本将生成一个相关矩阵图。它可以借助Pandas DataFrame上的corr()函数生成,并借助Matplotlib pyplot进行绘制。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Sample data
data = {'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1],
'C': [2, 3, 1, 4, 5]}
df = pd.DataFrame(data)
# Calculate the correlation matrix
c_matrix = df.corr()
# Create a heatmap
sns.heatmap(c_matrix, annot=True, cmap='coolwarm')
plt.title("Correlation Matrix")
plt.show()
输出

从上面相关矩阵的输出中,我们可以看到它是对称的,即左下角与右上角相同。
散点矩阵图
散点矩阵图使用二维空间中的点来显示一个变量受另一个变量影响的程度或它们之间的关系。从概念上讲,散点图非常类似于线形图,它们都使用水平和垂直轴来绘制数据点。
示例
在下面的示例中,Python脚本将为鸢尾花数据集生成并绘制散点矩阵。它可以借助Pandas DataFrame上的scatter_matrix()函数生成,并借助pyplot进行绘制。
import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets # Load the iris dataset iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) # Create the scatter matrix plot pd.plotting.scatter_matrix(df, diagonal='hist', figsize=(8, 7)) plt.show()
输出

在接下来的几章中,我们将了解机器学习中一些流行且广泛使用的可视化技术。