- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 所需技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 现实生活中的例子
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- 机器学习中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- 机器学习中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- 机器学习中的聚类算法
- ML - 聚类算法
- ML - 基于中心点的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- 机器学习中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 后向消除法
- ML - 前向特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 纪元
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄漏
- ML - 机器学习的盈利化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 备忘单
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - K均值聚类
K均值算法可以概括为以下步骤:
初始化 - 选择 K 个随机数据点作为初始中心点。
分配 - 将每个数据点分配到最近的中心点。
重新计算 - 通过取每个簇中所有数据点的平均值来重新计算中心点。
重复 - 重复步骤 2-3,直到中心点不再移动或达到最大迭代次数。
K均值算法是一种简单高效的算法,可以处理大型数据集。但是,它也有一些局限性,例如它对初始中心点的敏感性、它倾向于收敛到局部最优解,以及它假设所有簇的方差相等。
Python 实现
Python 有几个库提供了各种机器学习算法的实现,包括 K均值聚类。让我们看看如何使用 scikit-learn 库在 Python 中实现 K均值算法。
步骤 1 - 导入所需库
要在 Python 中实现 K均值算法,我们首先需要导入所需的库。我们将分别使用 numpy 和 matplotlib 库进行数据处理和可视化,以及 scikit-learn 库用于 K均值算法。
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans
步骤 2 - 生成数据
为了测试 K均值算法,我们需要生成一些示例数据。在本例中,我们将生成 300 个具有两个特征的随机数据点。我们也将可视化数据。
X = np.random.rand(300,2) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], s=20, cmap='summer'); plt.show()
步骤 3 - 初始化 K均值
接下来,我们需要通过指定簇数 (K) 和最大迭代次数来初始化 K均值算法。
kmeans = KMeans(n_clusters=3, max_iter=100)
步骤 4 - 训练模型
初始化 K均值算法后,我们可以通过将数据拟合到算法中来训练模型。
kmeans.fit(X)
步骤 5 - 可视化簇
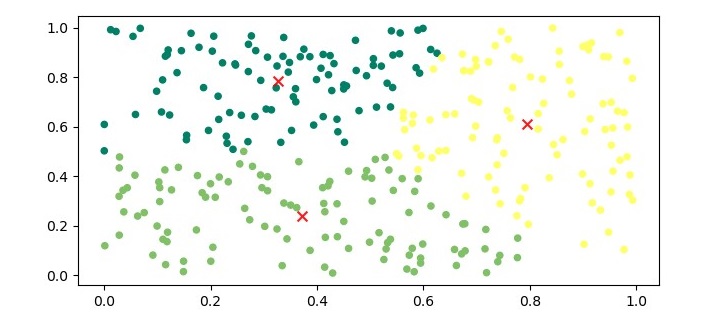
为了可视化簇,我们可以绘制数据点并根据其分配的簇对其进行着色。
plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, s=20, cmap='summer') plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker='x', c='r', s=50, alpha=0.9) plt.show()
上述代码的输出将是一个图,其中数据点根据其分配的簇着色,并且中心点以红色“x”符号标记。
完整实现示例
以下是 Python 中 K均值聚类算法的完整实现示例:
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans X = np.random.rand(300,2) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], s=20, cmap='summer'); plt.show() kmeans = KMeans(n_clusters=3, max_iter=100) kmeans.fit(X) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, s=20, cmap='summer') plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker='x', c='r', s=50, alpha=0.9) plt.show()
输出
执行此代码时,它将生成以下图作为输出:
K均值聚类的应用
K均值聚类是一种用途广泛的算法,在多个领域都有各种应用。在这里,我们重点介绍了一些重要的应用:
图像分割
K均值聚类可用于根据像素的颜色或纹理将图像分割成不同的区域。此技术广泛应用于计算机视觉应用中,例如物体识别、图像检索和医学影像。
客户细分
K均值聚类可用于根据客户的购买行为或人口统计特征将客户细分成不同的群体。此技术广泛应用于营销应用中,例如客户留存、忠诚度计划和目标广告。
异常检测
K均值聚类可用于通过识别不属于任何簇的数据点来检测数据集中是否存在异常。此技术广泛应用于欺诈检测、网络入侵检测和预测性维护。
基因组数据分析
K均值聚类可用于分析基因表达数据,以识别不同组的共同调控或共同表达的基因。此技术广泛应用于生物信息学应用中,例如药物发现、疾病诊断和个性化医疗。