- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习与无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于质心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 向前特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的商业化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 随机森林
随机森林是一种机器学习算法,它使用决策树的集合来进行预测。该算法由 Leo Breiman 于 2001 年首次提出。该算法背后的关键思想是创建大量的决策树,每个决策树都训练于不同的数据子集。然后将这些单个树的预测结果组合起来,以产生最终预测。
随机森林算法的工作原理
我们可以通过以下步骤来理解随机森林算法的工作原理:
步骤 1 - 首先,从给定的数据集中选择随机样本。
步骤 2 - 接下来,该算法将为每个样本构建一棵决策树。然后它将从每棵决策树中获取预测结果。
步骤 3 - 在此步骤中,将对每个预测结果进行投票。
步骤 4 - 最后,选择得票最多的预测结果作为最终预测结果。
下图说明了随机森林算法的工作原理:
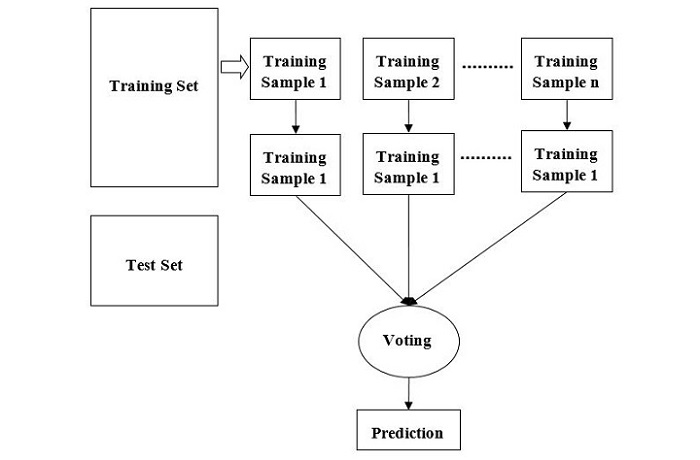
随机森林是一种灵活的算法,可用于分类和回归任务。在分类任务中,该算法使用各个树预测结果的众数来进行最终预测。在回归任务中,该算法使用各个树预测结果的平均值。
随机森林算法的优点
随机森林算法比其他机器学习算法具有几个优点。一些关键优势包括:
对过拟合的鲁棒性 - 随机森林算法以其对过拟合的鲁棒性而闻名。这是因为该算法使用决策树的集合,这有助于减少数据中异常值和噪声的影响。
高精度 - 随机森林算法以其高精度而闻名。这是因为该算法结合了多个决策树的预测结果,这有助于减少可能存在偏差或不准确的单个决策树的影响。
处理缺失数据 - 随机森林算法可以处理缺失数据,无需进行插补。这是因为该算法只考虑每个数据点可用的特征,并且不需要所有数据点的所有特征都存在。
非线性关系 - 随机森林算法可以处理特征和目标变量之间的非线性关系。这是因为该算法使用决策树,可以模拟非线性关系。
特征重要性 - 随机森林算法可以提供有关模型中每个特征重要性的信息。此信息可用于识别数据中最重要的特征,并可用于特征选择和特征工程。
在 Python 中实现随机森林算法
让我们来看一下在 Python 中实现随机森林算法的方法。我们将使用 scikit-learn 库来实现该算法。scikit-learn 库是一个流行的机器学习库,它提供了广泛的机器学习算法和工具。
步骤 1 - 导入库
我们将从导入必要的库开始。我们将使用 pandas 库进行数据操作,并使用 scikit-learn 库来实现随机森林算法。
import pandas as pd from sklearn.ensemble import RandomForestClassifier
步骤 2 - 加载数据
接下来,我们将数据加载到 pandas 数据框中。在本教程中,我们将使用著名的 Iris 数据集,这是一个用于分类任务的经典数据集。
# Loading the iris dataset
iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learningdatabases/iris/iris.data', header=None)
iris.columns = ['sepal_length', 'sepal_width', 'petal_length','petal_width', 'species']
步骤 3 - 数据预处理
在我们使用数据训练模型之前,我们需要对其进行预处理。这包括分离特征和目标变量,并将数据分成训练集和测试集。
# Separating the features and target variable X = iris.iloc[:, :-1] y = iris.iloc[:, -1] # Splitting the data into training and testing sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35, random_state=42)
步骤 4 - 训练模型
接下来,我们将使用训练数据训练我们的随机森林分类器。
# Creating the Random Forest classifier object rfc = RandomForestClassifier(n_estimators=100) # Training the model on the training data rfc.fit(X_train, y_train)
步骤 5 - 进行预测
训练完模型后,我们可以使用它对测试数据进行预测。
# Making predictions on the test data y_pred = rfc.predict(X_test)
步骤 6 - 评估模型
最后,我们将使用各种指标(如准确率、精确率、召回率和 F1 分数)来评估模型的性能。
# Importing the metrics library
from sklearn.metrics import accuracy_score, precision_score,
recall_score, f1_score
# Calculating the accuracy, precision, recall, and F1-score
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1-score:", f1)
完整的实现示例
以下是使用 iris 数据集在 python 中实现随机森林算法的完整实现示例:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# Loading the iris dataset
iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learningdatabases/iris/iris.data', header=None)
iris.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
# Separating the features and target variable
X = iris.iloc[:, :-1]
y = iris.iloc[:, -1]
# Splitting the data into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.35, random_state=42)
# Creating the Random Forest classifier object
rfc = RandomForestClassifier(n_estimators=100)
# Training the model on the training data
rfc.fit(X_train, y_train)
# Making predictions on the test data
y_pred = rfc.predict(X_test)
# Importing the metrics library
from sklearn.metrics import accuracy_score, precision_score,
recall_score, f1_score
# Calculating the accuracy, precision, recall, and F1-score
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1-score:", f1)
输出
这将给出我们随机森林分类器的性能指标,如下所示:
Accuracy: 0.9811320754716981 Precision: 0.9821802935010483 Recall: 0.9811320754716981 F1-score: 0.9811157396063056