- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习与无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法(KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于质心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 向前特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比例
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动化工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚(Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄漏
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 决策树算法
决策树算法是一种基于层次树的算法,用于根据一组规则对结果进行分类或预测。它的工作原理是根据输入特征的值将数据分成子集。该算法递归地分割数据,直到到达每个子集中的数据属于同一类或目标变量具有相同值的地步。生成的树是一组可以用来预测或对新数据进行分类的决策规则。
决策树算法的工作原理是在每个节点选择最佳特征来分割数据。最佳特征是提供最大信息增益或最大熵减小的特征。信息增益是衡量在特定特征处分割数据所获得的信息量,而熵是衡量数据中随机性或无序性的量度。该算法使用这些度量来确定在每个节点分割数据的最佳特征。
下面是一个二叉树的例子,用于预测一个人是否健康,提供了年龄、饮食习惯和运动习惯等各种信息:
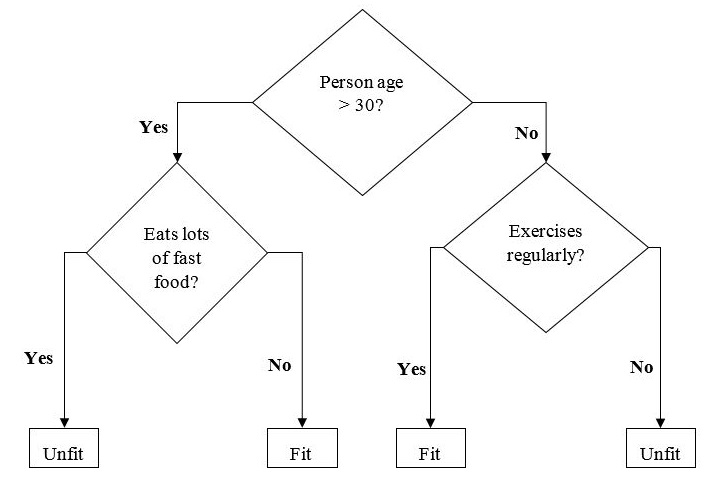
在上图的决策树中,问题是决策节点,最终结果是叶子节点。
决策树算法的类型
决策树算法主要有两种类型:
分类树 - 分类树用于将数据分类到不同的类别或范畴。它的工作原理是根据输入特征的值将数据分成子集,并将每个子集分配给不同的类别。
回归树 - 回归树用于预测数值或连续变量。它的工作原理是根据输入特征的值将数据分成子集,并将每个子集分配一个数值。
Python实现
让我们使用一个名为Iris数据集的流行数据集在Python中实现决策树算法,用于分类任务。它包含150个鸢尾花样本,每个样本具有四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度。这些花属于三个类别:setosa、versicolor和virginica。
首先,我们将导入必要的库并加载数据集:
import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier # Load the iris dataset iris = load_iris() # Split the dataset into training and testing sets X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
然后,我们创建一个决策树分类器的实例,并在训练集上对其进行训练:
# Create a Decision Tree classifier dtc = DecisionTreeClassifier() # Fit the classifier to the training data dtc.fit(X_train, y_train)
现在,我们可以使用训练好的分类器对测试集进行预测:
# Make predictions on the testing data y_pred = dtc.predict(X_test)
我们可以通过计算其准确率来评估分类器的性能:
# Calculate the accuracy of the classifier
accuracy = np.sum(y_pred == y_test) / len(y_test)
print("Accuracy:", accuracy)
我们可以使用Matplotlib库可视化决策树:
import matplotlib.pyplot as plt from sklearn.tree import plot_tree # Visualize the Decision Tree using Matplotlib plt.figure(figsize=(20,10)) plot_tree(dtc, filled=True, feature_names=iris.feature_names, class_names=iris.target_names) plt.show()
可以使用`sklearn.tree`模块中的`plot_tree`函数来绘制决策树。我们可以传入训练好的决策树分类器,`filled`参数用于用颜色填充节点,`feature_names`参数用于标记特征,`class_names`参数用于标记目标类别。我们还指定`figsize`参数来设置图形的大小,并调用`show`函数来显示绘图。
完整的实现示例
以下是使用iris数据集在python中实现决策树分类算法的完整实现示例:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Load the iris dataset
iris = load_iris()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
# Create a Decision Tree classifier
dtc = DecisionTreeClassifier()
# Fit the classifier to the training data
dtc.fit(X_train, y_train)
# Make predictions on the testing data
y_pred = dtc.predict(X_test)
# Calculate the accuracy of the classifier
accuracy = np.sum(y_pred == y_test) / len(y_test)
print("Accuracy:", accuracy)
# Visualize the Decision Tree using Matplotlib
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(20,10))
plot_tree(dtc, filled=True, feature_names=iris.feature_names,
class_names=iris.target_names)
plt.show()
输出
这将创建一个决策树图,如下所示:
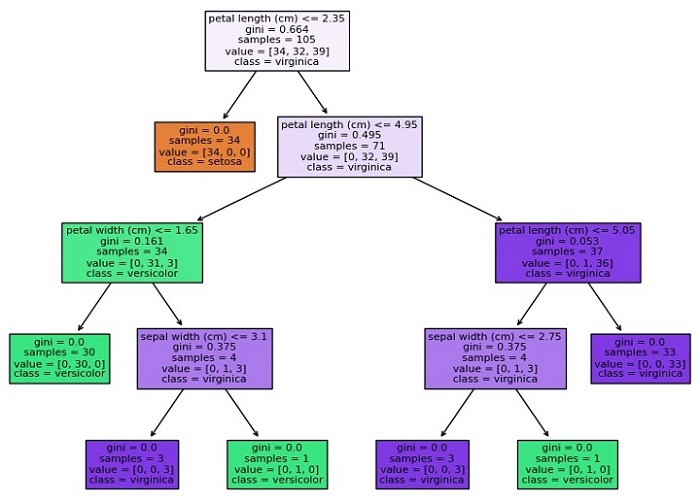
Accuracy: 0.9777777777777777
正如你所看到的,该图显示了决策树的结构,每个节点代表基于特征值做出的决策,每个叶节点代表一个类别或数值。每个节点的颜色表示该节点中样本的主要类别或值,底部的数字表示到达该节点的样本数量。