- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 现实生活中的例子
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习与无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 平均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- 机器学习中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- 机器学习中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- 机器学习中的聚类算法
- ML - 聚类算法
- ML - 基于质心的聚类
- ML - K均值聚类
- ML - K中值聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- 机器学习中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 后向消除
- ML - 前向特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python进行量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 主成分分析
主成分分析 (PCA) 是一种流行的无监督降维技术,用于机器学习,用于将高维数据转换为低维表示。PCA 用于通过发现变量之间潜在的关系来识别数据中的模式和结构。它通常用于图像处理、数据压缩和数据可视化等应用。
PCA 通过识别数据的**主成分 (PC)** 来工作,这些主成分是原始变量的线性组合,捕获了数据中最大的变化。第一个主成分解释了数据中最大的方差,其次是第二个主成分,依此类推。通过将数据的维度降低到仅包含最重要的 PC,PCA 可以简化问题并提高下游机器学习算法的计算效率。
PCA 所涉及的步骤如下:
标准化数据 - PCA 要求数据标准化为均值为零且方差为一的格式。
计算协方差矩阵 - PCA 计算标准化数据的协方差矩阵。
计算协方差矩阵的特征向量和特征值 - 然后,PCA 计算协方差矩阵的特征向量和特征值。
选择主成分 - PCA 根据其相应的特征值选择主成分,特征值指示每个成分解释的数据变化量。
将数据投影到新的特征空间 - PCA 将数据投影到由选定的主成分定义的新特征空间中。
示例
以下是如何使用 scikit-learn 库在 Python 中实现 PCA 的示例:
# Import the necessary libraries
import numpy as np
from sklearn.decomposition import PCA
# Load the iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
# Define the predictor variables (X) and the target variable (y)
X = iris.data
y = iris.target
# Standardize the data
X_standardized = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# Create a PCA object and fit the data
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_standardized)
# Print the explained variance ratio of the selected components
print('Explained variance ratio:', pca.explained_variance_ratio_)
# Plot the transformed data
import matplotlib.pyplot as plt
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
在此示例中,我们加载鸢尾花数据集,标准化数据,并创建一个具有两个成分的 PCA 对象。然后,我们将 PCA 对象拟合到标准化数据,并将数据转换到两个主成分上。我们打印所选成分的解释方差比率,并使用前两个主成分作为 x 和 y 轴绘制转换后的数据。
输出
执行此代码时,它将生成以下绘图作为输出:
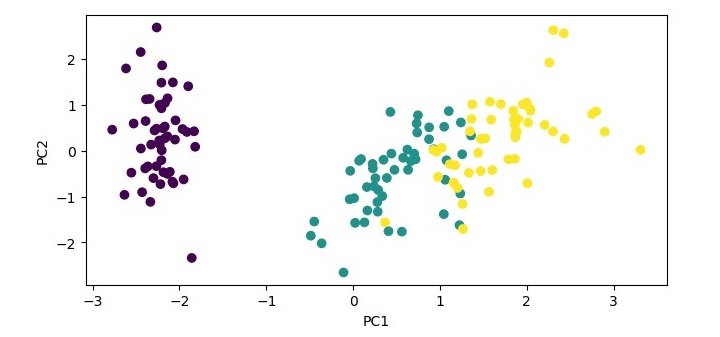
Explained variance ratio: [0.72962445 0.22850762]
PCA 的优点
以下是使用主成分分析的优点:
降低维度 - PCA 对于高维数据集特别有用,因为它可以在保留数据中大部分原始可变性的同时减少特征的数量。
去除相关特征 - PCA 可以识别并去除相关特征,这有助于提高机器学习模型的性能。
提高可解释性 - 减少的特征数量可以使数据更容易解释和理解。
减少过拟合 - 通过降低数据的维度,PCA 可以减少过拟合并提高机器学习模型的泛化能力。
加速计算 - 由于特征数量减少,训练机器学习模型所需的计算速度更快。
PCA 的缺点
以下是使用主成分分析的缺点:
信息丢失 - PCA 通过将其投影到低维空间来降低数据的维度,这可能导致某些信息丢失。
可能对异常值敏感 - PCA 可能对异常值敏感,异常值会对最终的主成分产生重大影响。
可解释性可能会降低 - 虽然 PCA 可以通过减少特征数量来提高可解释性,但最终的主成分可能比原始特征更难以解释。
假设线性 - PCA 假设特征之间的关系是线性的,这可能并不总是正确的。
需要标准化 - PCA 要求数据标准化,这可能并不总是可行或合适的。