- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 所需技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于质心的聚类
- ML - K-Means 聚类
- ML - K-Medoids 聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 向前特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄漏
- ML - 机器学习的商业化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - K-Medoids 聚类
K-Medoids 聚类 - 算法
K-medoids 聚类算法可以总结如下:
初始化 k 个 medoids - 从数据集中选择 k 个随机数据点作为初始 medoids。
将数据点分配给 medoids - 将每个数据点分配给最近的 medoid。
更新 medoids - 对于每个集群,选择最小化到集群中所有其他数据点的距离总和的数据点,并将其设置为新的 medoid。
重复步骤 2 和 3 直到收敛或达到最大迭代次数。
Python 实现
要在 Python 中实现 K-medoids 聚类,我们可以使用 scikit-learn 库。scikit-learn 库提供了KMedoids 类,可用于对数据集执行 K-medoids 聚类。
首先,我们需要导入所需的库:
from sklearn_extra.cluster import KMedoids from sklearn.datasets import make_blobs import matplotlib.pyplot as plt
接下来,我们使用 scikit-learn 中的 make_blobs() 函数生成样本数据集:
X, y = make_blobs(n_samples=500, centers=3, random_state=42)
在这里,我们生成一个包含 500 个数据点和 3 个集群的数据集。
接下来,我们初始化 KMedoids 类并拟合数据:
kmedoids = KMedoids(n_clusters=3, random_state=42) kmedoids.fit(X)
在这里,我们将集群数量设置为 3,并使用 random_state 参数确保可重复性。
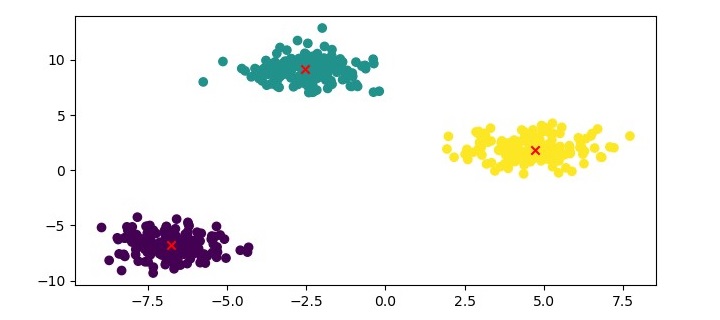
最后,我们可以使用散点图可视化聚类结果:
plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], c=kmedoids.labels_, cmap='viridis') plt.scatter(kmedoids.cluster_centers_[:, 0], kmedoids.cluster_centers_[:, 1], marker='x', color='red') plt.show()
示例
以下是 Python 中的完整实现:
from sklearn_extra.cluster import KMedoids from sklearn.datasets import make_blobs import matplotlib.pyplot as plt # Generate sample data X, y = make_blobs(n_samples=500, centers=3, random_state=42) # Cluster the data using KMedoids kmedoids = KMedoids(n_clusters=3, random_state=42) kmedoids.fit(X) # Plot the results plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], c=kmedoids.labels_, cmap='viridis') plt.scatter(kmedoids.cluster_centers_[:, 0], kmedoids.cluster_centers_[:, 1], marker='x', color='red') plt.show()
输出
在这里,我们将数据点绘制为散点图,并根据其集群标签对其进行着色。我们还将 medoids 绘制为红色十字。
K-Medoids 聚类 - 优点
以下是使用 K-medoids 聚类的优点:
对异常值和噪声具有鲁棒性 - K-medoids 聚类比 K-means 聚类对异常值和噪声更具鲁棒性,因为它使用代表性数据点(称为 medoid)来表示集群的中心。
可以处理非欧几里得距离度量 - K-medoids 聚类可以与任何距离度量一起使用,包括非欧几里得距离度量,例如曼哈顿距离和余弦相似度。
计算效率高 - K-medoids 聚类的计算复杂度为 O(k*n^2),低于 K-means 聚类的计算复杂度。
K-Medoids 聚类 - 缺点
使用 K-medoids 聚类的缺点如下:
对 k 的选择敏感 - K-medoids 聚类的性能可能对 k(集群数量)的选择敏感。
不适用于高维数据 - K-medoids 聚类可能在高维数据上表现不佳,因为 medoid 选择过程变得计算成本很高。