- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 快速入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 局限性
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- 机器学习中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- 机器学习中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K 近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- 机器学习中的聚类算法
- ML - 聚类算法
- ML - 基于中心的聚类
- ML - K 均值聚类
- ML - K 中值聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- 机器学习中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后消除法
- ML - 前向特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q 学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P 值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的商业化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 向后消除法
向后消除法是一种在机器学习中使用的特征选择技术,用于为预测模型选择最重要的特征。在这种技术中,我们首先考虑所有特征,然后迭代地去除最不重要的特征,直到我们得到提供最佳性能的最佳特征子集。
Python 实现
要在 Python 中实现向后消除法,您可以按照以下步骤操作:
导入必要的库:pandas、numpy 和 statsmodels.api。
import pandas as pd import numpy as np import statsmodels.api as sm
将您的数据集加载到 Pandas DataFrame 中。我们将使用 Pima-Indians-Diabetes 数据集。
diabetes = pd.read_csv(r'C:\Users\Leekha\Desktop\diabetes.csv')
定义预测变量 (X) 和目标变量 (y)。
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, -1].values
向预测变量添加一列 1 来表示截距。
X = np.append(arr = np.ones((len(X), 1)).astype(int), values = X, axis = 1)
使用 statsmodels 库中的普通最小二乘法 (OLS) 来拟合包含所有预测变量的多元线性回归模型。
X_opt = X[:, [0, 1, 2, 3, 4, 5]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
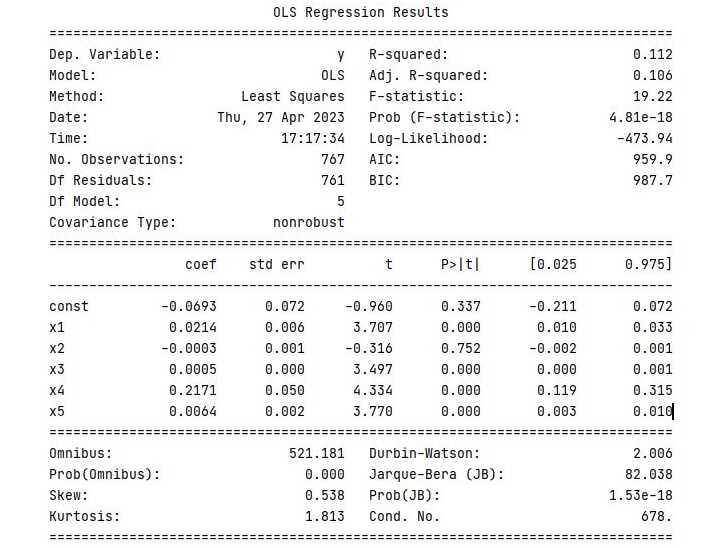
检查每个预测变量的 p 值,并去除 p 值最高的那个(即最不重要的)。
regressor_OLS.summary()
重复步骤 5 和 6,直到所有剩余预测变量的 p 值都低于显著性水平(例如,0.05)。
X_opt = X[:, [0, 1, 3, 4, 5]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 3, 4, 5]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 3, 5]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 3]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary()
p 值低于显著性水平的最终预测变量子集是模型的最佳特征集。
示例
以下是 Python 中向后消除法的完整实现:
# Importing the necessary libraries import pandas as pd import numpy as np import statsmodels.api as sm # Load the diabetes dataset diabetes = pd.read_csv(r'C:\Users\Leekha\Desktop\diabetes.csv') # Define the predictor variables (X) and the target variable (y) X = diabetes.iloc[:, :-1].values y = diabetes.iloc[:, -1].values # Add a column of ones to the predictor variables to represent the intercept X = np.append(arr = np.ones((len(X), 1)).astype(int), values = X, axis = 1) # Fit the multiple linear regression model with all the predictor variables X_opt = X[:, [0, 1, 2, 3, 4, 5, 6, 7, 8]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() # Check the p-values of each predictor variable and remove the one # with the highest p-value (i.e., the least significant) regressor_OLS.summary() # Repeat the above step until all the remaining predictor variables # have a p-value below the significance level (e.g., 0.05) X_opt = X[:, [0, 1, 2, 3, 5, 6, 7, 8]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 1, 3, 5, 6, 7, 8]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 1, 3, 5, 7, 8]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary() X_opt = X[:, [0, 1, 3, 5, 7]] regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit() regressor_OLS.summary()
输出
执行此程序时,将产生以下输出:
广告