- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 技能要求
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 现实案例
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- 机器学习中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- 机器学习中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- 机器学习中的聚类算法
- ML - 聚类算法
- ML - 基于中心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- 机器学习中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 后向消除法
- ML - 前向特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 时期
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的盈利化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 数据分布
在机器学习中,数据分布指的是数据点在一个数据集中分布或分散的方式。了解数据集中数据的分布非常重要,因为它会对机器学习算法的性能产生重大影响。
数据分布可以通过几个统计量来描述,包括均值、中位数、众数、标准差和方差。这些度量有助于描述数据的集中趋势、离散程度和形状。
下面列出了一些机器学习中常见的数据分布类型:
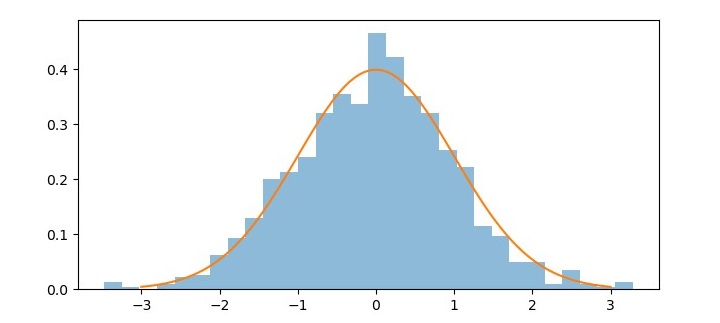
正态分布
正态分布,也称为高斯分布,是一种在机器学习和统计学中广泛使用的连续概率分布。它是一个钟形曲线,描述了一个随机变量的概率分布,该变量围绕均值对称。正态分布有两个参数,均值 (μ) 和标准差 (σ)。
在机器学习中,正态分布通常用于模拟线性回归和其他统计模型中误差项的分布。它也用作各种假设检验和置信区间的基础。
正态分布的一个重要特性是经验法则,也称为 68-95-99.7 法则。该法则指出,大约 68% 的观测值落在均值的一个标准差内,95% 的观测值落在均值的两个标准差内,99.7% 的观测值落在均值的三个标准差内。
Python 提供了各种库,可用于处理正态分布。其中一个库是 **scipy.stats**,它提供了用于计算正态分布的概率密度函数 (PDF)、累积分布函数 (CDF)、百分位函数 (PPF) 和随机变量的函数。
示例
以下是如何使用 **scipy.stats** 生成和可视化正态分布的示例:
import numpy as np from scipy.stats import norm import matplotlib.pyplot as plt # Generate a random sample of 1000 values from a normal distribution mu = 0 # Mean sigma = 1 # Standard deviation sample = np.random.normal(mu, sigma, 1000) # Calculate the PDF for the normal distribution x = np.linspace(mu - 3*sigma, mu + 3*sigma, 100) pdf = norm.pdf(x, mu, sigma) # Plot the histogram of the random sample and the PDF of the normal distribution plt.figure(figsize=(7.5, 3.5)) plt.hist(sample, bins=30, density=True, alpha=0.5) plt.plot(x, pdf) plt.show()
在这个例子中,我们首先使用 **np.random.normal** 从均值为 0、标准差为 1 的正态分布中生成 1000 个随机值的样本。然后,我们使用 norm.pdf 计算正态分布的 PDF,并使用 **np.linspace** 生成一个包含 100 个从 μ -3σ 到 μ +3σ 的均匀间隔值的数组。
最后,我们使用 **plt.hist** 绘制随机样本的直方图,并使用 **plt.plot** 在上面叠加正态分布的 PDF。
输出
生成的图表显示了正态分布的钟形曲线以及近似于正态分布的随机样本的直方图。
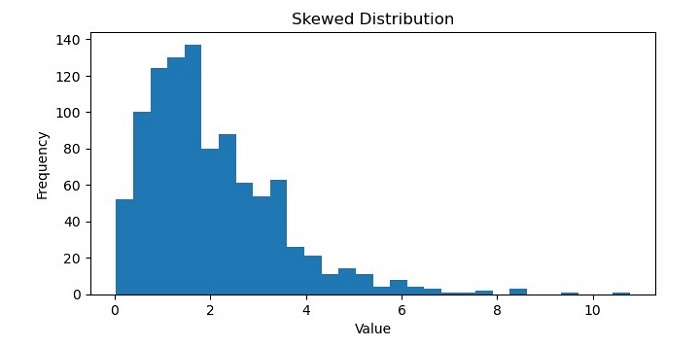
偏态分布
在机器学习中,偏态分布指的是数据集在其均值或平均值周围分布不均匀。在偏态分布中,大多数数据点倾向于聚集在分布的一端,而另一端的数据点较少。
偏态分布有两种类型:左偏和右偏。左偏分布,也称为负偏分布,在分布的左侧有一个长尾,大多数数据点在右侧。相反,右偏分布,也称为正偏分布,在分布的右侧有一个长尾,大多数数据点在左侧。
偏态分布可能出现在许多不同类型的数据集中,例如财务数据、社交媒体指标或医疗记录。在机器学习中,识别并正确处理偏态分布非常重要,因为它们会影响某些算法和模型的性能。例如,在某些情况下,偏态数据会导致预测偏差和结果不准确,可能需要进行归一化或数据转换等预处理技术来提高模型的性能。
示例
以下是如何使用 Python 的 NumPy 和 Matplotlib 库生成和绘制偏态分布的示例:
import numpy as np
import matplotlib.pyplot as plt
# Generate a skewed distribution using NumPy's random function
data = np.random.gamma(2, 1, 1000)
# Plot a histogram of the data to visualize the distribution
plt.figure(figsize=(7.5, 3.5))
plt.hist(data, bins=30)
# Add labels and title to the plot
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Skewed Distribution')
# Show the plot
plt.show()
输出
执行此代码后,您将获得以下图表作为输出:
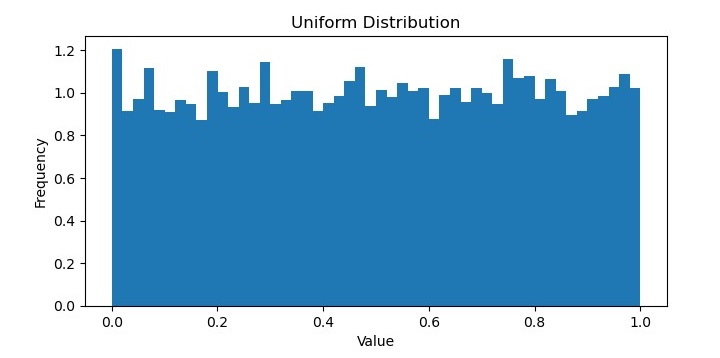
均匀分布
在机器学习中,均匀分布指的是所有可能的结果都等可能发生的概率分布。换句话说,数据集中每个值都有相同的被观察到的概率,并且数据点没有围绕特定值聚集。
均匀分布通常用作与其他分布进行比较的基线,因为它表示数据的随机和无偏采样。它在某些类型的应用中也很有用,例如生成随机数或从集合中无偏地选择项目。
在概率论中,连续均匀分布的概率密度函数定义为:
$$f\left ( x \right )=\left\{\begin{matrix} 1 & for\: a\leq x\leq b \\ 0 & otherwise \\ \end{matrix}\right.$$
其中 a 和 b 分别是分布的最小值和最大值。均匀分布的均值为 $\frac{a+b}{2} $,方差为 $\frac{\left ( b-a \right )^{2}}{12}$
示例
在 Python 中,NumPy 库提供了用于从均匀分布生成随机数的函数,例如 **numpy.random.uniform()**。这些函数将分布的最小值和最大值作为参数,可用于生成具有均匀分布的数据集。
以下是如何使用 Python 的 NumPy 库生成均匀分布的示例:
import numpy as np
import matplotlib.pyplot as plt
# Generate 10,000 random numbers from a uniform distribution between 0 and 1
uniform_data = np.random.uniform(low=0, high=1, size=10000)
# Plot the histogram of the uniform data
plt.figure(figsize=(7.5, 3.5))
plt.hist(uniform_data, bins=50, density=True)
# Add labels and title to the plot
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Uniform Distribution')
# Show the plot
plt.show()
输出
它将生成以下图表作为输出:
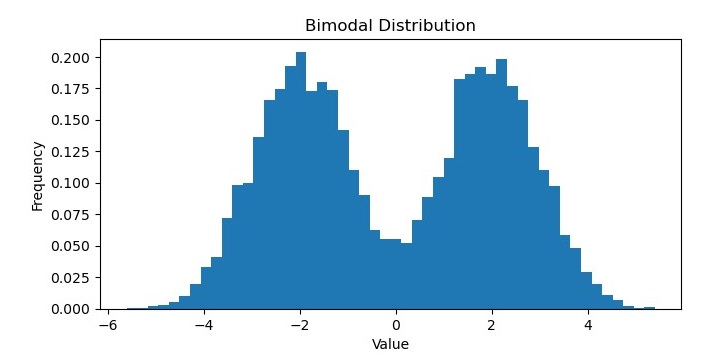
双峰分布
在机器学习中,双峰分布是一种具有两个不同众数或峰值的概率分布。换句话说,分布有两个数据值最有可能出现的位置,它们之间存在一个数据不太可能出现的谷或槽。
双峰分布可能出现在各种类型的数据中,例如生物识别测量、经济指标或社交媒体指标。它们可以表示数据集中不同的子群体,或随时间推移的不同行为模式或趋势。
可以使用各种统计方法识别和分析双峰分布,例如直方图、核密度估计或假设检验。在某些情况下,双峰分布可以拟合到特定的概率分布,例如高斯混合模型,该模型允许分别对底层子群体进行建模。
示例
在 Python 中,NumPy、SciPy 和 Matplotlib 等库提供了用于生成和可视化双峰分布的函数。
例如,以下代码生成并绘制了一个双峰分布:
import numpy as np
import matplotlib.pyplot as plt
# Generate 10,000 random numbers from a bimodal distribution
bimodal_data = np.concatenate((np.random.normal(loc=-2, scale=1, size=5000),
np.random.normal(loc=2, scale=1, size=5000)))
# Plot the histogram of the bimodal data
plt.figure(figsize=(7.5, 3.5))
plt.hist(bimodal_data, bins=50, density=True)
# Add labels and title to the plot
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Bimodal Distribution')
# Show the plot
plt.show()
输出
执行此代码后,您将获得以下图表作为输出: