- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 现实生活中的例子
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习与无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 平均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML 中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML 中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K 近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML 中的聚类算法
- ML - 聚类算法
- ML - 基于中心点的聚类
- ML - K 均值聚类
- ML - K 中值聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN 聚类
- ML - OPTICS 聚类
- ML - HDBSCAN 聚类
- ML - BIRCH 聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML 中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 向前特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q 学习
- ML - REINFORCE 算法
- ML - SARSA 强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用 Python 的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC 曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori 算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P 值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 逻辑回归
逻辑回归是一种常用的用于二元分类问题的算法,其中目标变量是具有两个类别的分类变量。它对给定输入特征的目标变量的概率进行建模,并预测概率最高的类别。
逻辑回归是一种广义线性模型,其中目标变量遵循伯努利分布。该模型由输入特征的线性函数组成,该函数使用逻辑函数进行转换以生成 0 到 1 之间的概率值。
线性函数基本上用作另一个函数(例如以下关系中的 g)的输入:
$$h_{\theta }\left ( x \right )=g\left ( \theta ^{T}x \right )\, 其中\: 0\leq h_{\theta }\leq 1$$
这里,g 是逻辑或 sigmoid 函数,可以表示如下:
$$g\left ( z \right )=\frac{1}{1+e^{-z}}\: 其中\: z=\theta ^{T}x$$
可以使用以下图形表示 sigmoid 曲线。我们可以看到 y 轴的值介于 0 和 1 之间,并在 0.5 处穿过轴。
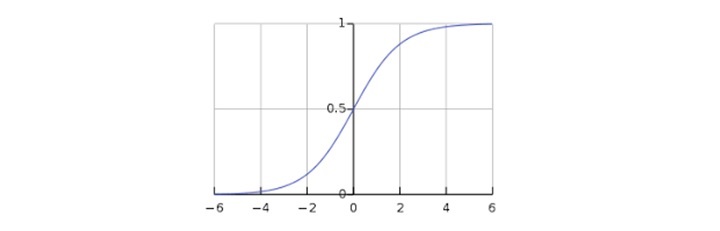
这些类别可以分为正类或负类。如果输出介于 0 和 1 之间,则输出属于正类的概率。在我们的实现中,如果假设函数的输出≥ 0.5,则将其解释为正类,否则解释为负类。
Python 实现
现在,我们将使用 Python 实现上述逻辑回归的概念。为此,我们使用名为“iris”的多元花卉数据集。iris 数据集是机器学习中一个众所周知的数据集,包含三种不同鸢尾花物种的花萼长度、花萼宽度、花瓣长度和花瓣宽度的测量值。我们将使用逻辑回归来预测给定鸢尾花测量值的鸢尾花物种。
现在让我们检查使用 iris 数据集在 Python 中实现逻辑回归的步骤:
加载数据集
首先,我们需要将 iris 数据集加载到我们的 Python 环境中。我们可以使用 scikitlearn 库加载数据集,如下所示:
from sklearn.datasets import load_iris iris = load_iris() X = iris.data # input features y = iris.target # target variable
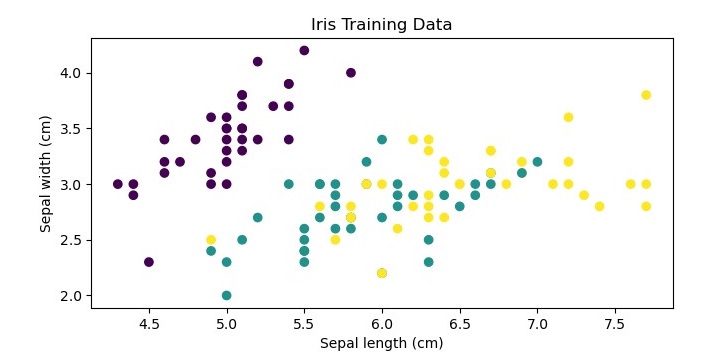
绘制训练数据
这是一个可选步骤,但为了更清楚地了解数据集,我们正在绘制训练数据,如下所示:
import matplotlib.pyplot as plt
# plot the training data
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
plt.xlabel('Sepal length (cm)')
plt.ylabel('Sepal width (cm)')
plt.title('Iris Training Data')
plt.show()
分割数据集
接下来,我们需要将数据集分割成训练集和测试集。我们将使用 70% 的数据进行训练,30% 的数据进行测试。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
创建逻辑回归模型
我们可以使用 scikit-learn 中的 LogisticRegression 类来创建一个逻辑回归模型。我们将使用 L2 正则化并将正则化强度设置为 1。
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(penalty='l2', C=1.0, random_state=42)
训练模型
我们可以使用 fit() 方法在训练集上训练模型。
clf.fit(X_train, y_train)
进行预测
训练完模型后,我们可以使用 predict() 方法在测试集上使用它进行预测。
y_pred = clf.predict(X_test)
评估模型
最后,我们可以使用准确率、精确率、召回率和 F1 分数等指标来评估模型的性能。
from sklearn.metrics import accuracy_score, precision_score,
recall_score, f1_score
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Precision:', precision_score(y_test, y_pred, average='macro'))
print('Recall:', recall_score(y_test, y_pred, average='macro'))
print('F1-score:', f1_score(y_test, y_pred, average='macro'))
在这里,我们使用平均参数并将值设置为“macro”来分别计算每个类别的指标,然后取平均值。
完整的实现示例
下面是使用 iris 数据集在 python 中实现逻辑回归的完整实现示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# load the iris dataset
iris = load_iris()
X = iris.data # input features
y = iris.target # target variable
# plot the training data
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
plt.xlabel('Sepal length (cm)')
plt.ylabel('Sepal width (cm)')
plt.title('Iris Training Data')
plt.show()
# split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# create the logistic regression model
clf = LogisticRegression(penalty='l2', C=1.0, random_state=42)
# train the model on the training set
clf.fit(X_train, y_train)
# make predictions on the test set
y_pred = clf.predict(X_test)
# evaluate the performance of the model
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Precision:', precision_score(y_test, y_pred, average='macro'))
print('Recall:', recall_score(y_test, y_pred, average='macro'))
print('F1-score:', f1_score(y_test, y_pred, average='macro'))
输出
执行此代码时,它将生成以下绘图作为输出:
Accuracy: 1.0 Precision: 1.0 Recall: 1.0 F1-score: 1.0