- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 技能要求
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 类别数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于中心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 前向特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精确率和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 时期
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 多项式回归
多项式线性回归是一种回归分析,其中自变量和因变量之间的关系被建模为n次多项式函数。与简单和多元线性回归中的线性关系相比,多项式回归允许捕获变量之间更复杂的关系。
Python 实现
以下是用 Scikit-Learn 中的波士顿房价数据集实现多项式线性回归的示例:
示例
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
import matplotlib.pyplot as plt
# Load the Boston Housing dataset
boston = load_boston()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(boston.data,
boston.target, test_size=0.2, random_state=0)
# Create a polynomial features object with degree 2
poly = PolynomialFeatures(degree=2)
# Transform the input data to include polynomial features
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
# Create a linear regression object
lr_model = LinearRegression()
# Fit the model on the training data
lr_model.fit(X_train_poly, y_train)
# Make predictions on the test data
y_pred = lr_model.predict(X_test_poly)
# Calculate the mean squared error
mse = mean_squared_error(y_test, y_pred)
# Calculate the coefficient of determination
r2 = r2_score(y_test, y_pred)
print('Mean Squared Error:', mse)
print('Coefficient of Determination:', r2)
# Sort the test data by the target variable
sort_idx = X_test[:, 12].argsort()
X_test_sorted = X_test[sort_idx]
y_test_sorted = y_test[sort_idx]
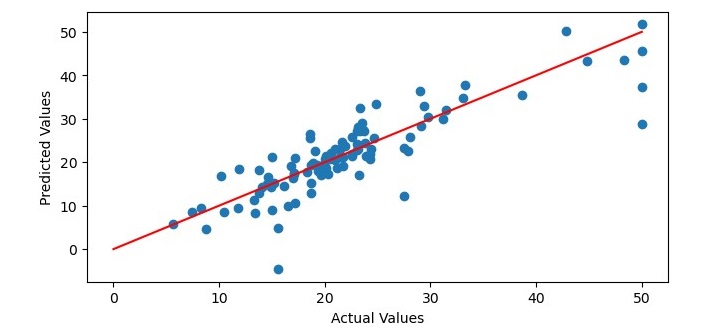
# Plot the predicted values against the actual values
plt.figure(figsize=(7.5, 3.5))
plt.scatter(y_test_sorted, y_pred[sort_idx])
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
# Add a regression line to the plot
x = np.linspace(0, 50, 100)
y = x
plt.plot(x, y, color='red')
# Show the plot
plt.show()
输出
执行程序时,它将生成以下图表作为输出,并在终端上打印均方误差和决定系数:
Mean Squared Error: 25.215797617051855 Coefficient of Determination: 0.6903318065831567
广告