- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习与无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于中心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 后退消除法
- ML - 前向特征构造
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练与测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精确率和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 时期
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的货币化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - 特征提取
特征提取通常用于图像处理、语音识别、自然语言处理和其他应用,在这些应用中,原始数据是高维的并且难以处理。
示例
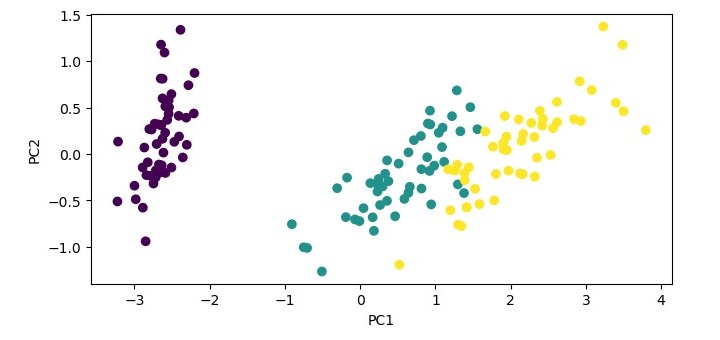
以下是如何使用主成分分析 (PCA) 对鸢尾花数据集进行特征提取的 Python 示例:
# Import necessary libraries and dataset
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Load the dataset
iris = load_iris()
# Perform feature extraction using PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(iris.data)
# Visualize the transformed data
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
在此代码中,我们首先导入必要的库,包括用于使用 PCA 进行特征提取的 sklearn 和用于可视化转换数据的 matplotlib。
接下来,我们使用 load_iris() 加载鸢尾花数据集。然后,我们使用 PCA() 进行特征提取并将组件数量设置为 2 (n_components=2)。这将输入数据的维度从 4 个特征减少到 2 个主成分。
然后,我们使用 fit_transform() 转换输入数据并将转换后的数据存储在 X_pca 中。最后,我们使用 plt.scatter() 可视化转换后的数据,并根据目标值对数据点进行着色。我们将轴标记为 PC1 和 PC2,它们分别代表第一和第二主成分,并使用 plt.show() 显示绘图。
输出
执行给定程序时,它将生成以下绘图作为输出:
特征提取的优势
以下是使用特征提取的优势:
降维 - 特征提取通过将数据转换为一组新的特征来降低输入数据的维度。这使得数据更容易可视化、处理和分析。
性能提升 - 特征提取可以通过创建一组更有意义的特征来提高机器学习算法的性能,这些特征捕获了输入数据中的基本信息。
特征选择 - 特征提取可用于执行特征选择,方法是选择对机器学习模型信息量最大的最相关特征子集。
降噪 - 特征提取还可以帮助减少数据中的噪声,方法是过滤掉不相关的特征或组合相关的特征。
特征提取的缺点
以下是使用特征提取的缺点:
信息丢失 - 特征提取可能导致信息丢失,因为它涉及减少输入数据的维度。转换后的数据可能不包含原始数据中的所有信息,并且在此过程中可能会丢失一些信息。
过拟合 - 如果转换后的特征过于复杂或选择的特征数量过多,特征提取也可能导致过拟合。
复杂度 - 特征提取在计算上可能代价高昂且耗时,尤其是在处理大型数据集或复杂的特征提取技术(如深度学习)时。
领域专业知识 - 特征提取需要领域专业知识才能有效地选择和转换特征。它需要了解数据和手头的问题才能选择对机器学习模型信息量最大的正确特征。