- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python库
- ML - 应用
- ML - 生命周期
- ML - 必备技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 限制
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值,中位数,众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- 机器学习中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- 机器学习中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- 机器学习中的聚类算法
- ML - 聚类算法
- ML - 基于中心点的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- 机器学习中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后剔除法
- ML - 向前特征构建
- ML - 高相关性过滤器
- ML - 低方差过滤器
- ML - 缺失值比率
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流程
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 轮次
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄漏
- ML - 机器学习的盈利模式
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
机器学习 - HDBSCAN聚类
HDBSCAN聚类的运作方式
HDBSCAN使用互达性图构建层次聚类,这是一个图,其中每个数据点都是一个节点,它们之间的边根据相似性或距离的度量进行加权。如果两个点的互达距离低于给定的阈值,则通过连接这两个点来构建该图。
两个点之间的互达距离是它们的达距离的最大值,这是衡量一个点从另一个点到达的难易程度的指标。两个点之间的达距离定义为它们的距离和沿其路径的任何点的最小密度的最大值。
然后使用最小生成树 (MST) 算法从互达性图中提取层次聚类。MST 的叶节点对应于单个数据点,而内部节点对应于不同大小和形状的聚类。
然后,HDBSCAN算法将压缩树算法应用于MST以提取聚类。压缩树是MST的紧凑表示,仅包含树的内部节点。然后在特定级别切割压缩树以获得聚类,切割的级别由用户定义的最小聚类大小或基于聚类稳定性的启发式方法确定。
Python实现
HDBSCAN作为一个Python库可用,可以使用pip安装。该库提供HDBSCAN算法的实现以及一些用于数据预处理和可视化的有用函数。
安装
要安装HDBSCAN,请打开终端窗口并键入以下命令:
pip install hdbscan
用法
要使用HDBSCAN,首先导入hdbscan库:
import hdbscan
接下来,我们使用scikit-learn中的make_blobs()函数生成一个样本数据集:
# generate random dataset with 1000 samples and 3 clusters X, y = make_blobs(n_samples=1000, centers=3, random_state=42)
现在,创建一个HDBSCAN类的实例并将其拟合到数据:
clusterer = hdbscan.HDBSCAN(min_cluster_size=10, metric='euclidean') # fit the data to the clusterer clusterer.fit(X)
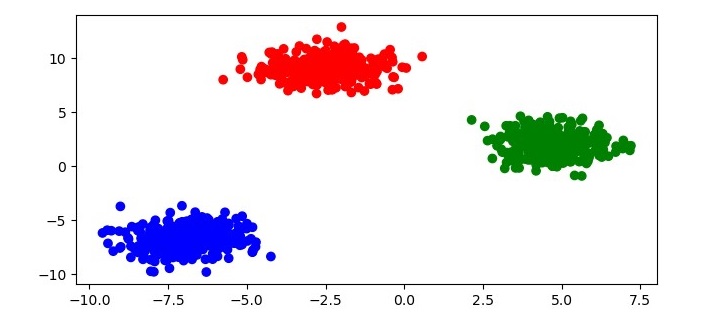
这将把HDBSCAN应用于数据集并将每个点分配到一个聚类。为了可视化聚类结果,您可以绘制数据,并根据其聚类标签对每个点进行着色:
# get the cluster labels labels = clusterer.labels_ # create a colormap for the clusters colors = np.array([x for x in 'bgrcmykbgrcmykbgrcmykbgrcmyk']) colors = np.hstack([colors] * 20) # plot the data with each point colored according to its cluster label plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], c=colors[labels]) plt.show()
此代码将生成数据的散点图,每个点根据其聚类标签着色如下:
HDBSCAN还提供了一些可以调整的参数来微调聚类结果:
min_cluster_size - 聚类的最小大小。不属于任何聚类的点标记为噪声。
min_samples - 被认为是核心点的点邻域中的最小样本数。
cluster_selection_epsilon - 用于聚类选择的邻域半径。
metric - 用于衡量点之间相似性的距离度量。
HDBSCAN聚类的优势
HDBSCAN比其他聚类算法具有几个优势:
更好地处理不同密度的聚类 - HDBSCAN可以识别不同密度的聚类,这是许多数据集中常见的问题。
能够检测不同形状和大小的聚类 - HDBSCAN可以识别不一定是球形的聚类,这是许多数据集中另一个常见的问题。
无需指定聚类数量 - HDBSCAN不需要用户指定聚类数量,这在先验很难确定。
对噪声具有鲁棒性 - HDBSCAN对噪声数据具有鲁棒性,可以将异常值识别为噪声点。