- 机器学习基础
- ML - 首页
- ML - 简介
- ML - 入门
- ML - 基本概念
- ML - 生态系统
- ML - Python 库
- ML - 应用
- ML - 生命周期
- ML -所需技能
- ML - 实现
- ML - 挑战与常见问题
- ML - 局限性
- ML - 真实案例
- ML - 数据结构
- ML - 数学基础
- ML - 人工智能
- ML - 神经网络
- ML - 深度学习
- ML - 获取数据集
- ML - 分类数据
- ML - 数据加载
- ML - 数据理解
- ML - 数据准备
- ML - 模型
- ML - 监督学习
- ML - 无监督学习
- ML - 半监督学习
- ML - 强化学习
- ML - 监督学习 vs. 无监督学习
- 机器学习数据可视化
- ML - 数据可视化
- ML - 直方图
- ML - 密度图
- ML - 箱线图
- ML - 相关矩阵图
- ML - 散点矩阵图
- 机器学习统计学
- ML - 统计学
- ML - 均值、中位数、众数
- ML - 标准差
- ML - 百分位数
- ML - 数据分布
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假设
- ML中的回归分析
- ML - 回归分析
- ML - 线性回归
- ML - 简单线性回归
- ML - 多元线性回归
- ML - 多项式回归
- ML中的分类算法
- ML - 分类算法
- ML - 逻辑回归
- ML - K近邻算法 (KNN)
- ML - 朴素贝叶斯算法
- ML - 决策树算法
- ML - 支持向量机
- ML - 随机森林
- ML - 混淆矩阵
- ML - 随机梯度下降
- ML中的聚类算法
- ML - 聚类算法
- ML - 基于质心的聚类
- ML - K均值聚类
- ML - K中心点聚类
- ML - 均值漂移聚类
- ML - 层次聚类
- ML - 基于密度的聚类
- ML - DBSCAN聚类
- ML - OPTICS聚类
- ML - HDBSCAN聚类
- ML - BIRCH聚类
- ML - 亲和传播
- ML - 基于分布的聚类
- ML - 凝聚层次聚类
- ML中的降维
- ML - 降维
- ML - 特征选择
- ML - 特征提取
- ML - 向后逐步回归
- ML - 向前特征构造
- ML - 高相关性过滤
- ML - 低方差过滤
- ML - 缺失值比例
- ML - 主成分分析
- 强化学习
- ML - 强化学习算法
- ML - 利用与探索
- ML - Q学习
- ML - REINFORCE算法
- ML - SARSA强化学习
- ML - 演员-评论家方法
- 深度强化学习
- ML - 深度强化学习
- 量子机器学习
- ML - 量子机器学习
- ML - 使用Python的量子机器学习
- 机器学习杂项
- ML - 性能指标
- ML - 自动工作流
- ML - 提升模型性能
- ML - 梯度提升
- ML - 自举汇聚 (Bagging)
- ML - 交叉验证
- ML - AUC-ROC曲线
- ML - 网格搜索
- ML - 数据缩放
- ML - 训练和测试
- ML - 关联规则
- ML - Apriori算法
- ML - 高斯判别分析
- ML - 成本函数
- ML - 贝叶斯定理
- ML - 精度和召回率
- ML - 对抗性
- ML - 堆叠
- ML - 时期
- ML - 感知器
- ML - 正则化
- ML - 过拟合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 数据泄露
- ML - 机器学习的商业化
- ML - 数据类型
- 机器学习 - 资源
- ML - 快速指南
- ML - 速查表
- ML - 面试问题
- ML - 有用资源
- ML - 讨论
监督式机器学习
什么是监督式机器学习?
监督学习,也称为监督式机器学习,是一种使用标记数据集训练模型以预测结果的机器学习类型。标记数据集是指包含输入数据(特征)及其对应的输出数据(目标)的数据集。
监督学习算法的主要目标是在执行多个训练数据实例后,学习输入数据样本和相应输出之间的关联。
监督学习是如何工作的?
在监督式机器学习中,模型使用包含输入-输出对的数据集进行训练。
监督学习算法分析数据集并学习输入数据(特征)和正确输出(标签/目标)之间的关系。在训练过程中,模型通过最小化损失函数来估计算法的参数。损失函数衡量模型预测值与实际目标值之间的差异。
模型迭代地更新其参数,直到损失/误差被充分最小化。
训练完成后,模型参数将具有最佳值。模型已经学习到输入和目标之间的最佳映射/关系。现在,模型可以预测新的和未见过的输入数据的数值。
监督学习算法的类型
监督式机器学习分为两种类型的任务:分类和回归。
1. 分类
基于分类的任务的关键目标是预测给定输入数据的类别输出标签或响应,例如真假、男女、是或否等。众所周知,类别输出响应意味着无序和离散的值;因此,每个输出响应都属于一个特定的类别或范畴。
一些流行的分类算法包括决策树、随机森林、支持向量机 (SVM)、逻辑回归等。
2. 回归
基于回归的任务的关键目标是预测输出标签或响应,这些响应是给定输入数据的连续数值。基本上,回归模型使用输入数据特征(自变量)及其对应的连续数值输出值(因变量或结果变量)来学习输入和相应输出之间的特定关联。
一些流行的回归算法包括线性回归、多项式回归、Lasso回归等。
监督学习的算法
监督学习是机器学习中重要的模型之一。本章将详细讨论它。
监督学习有多种算法。一些广泛使用的监督学习算法如下所示:
让我们详细讨论上述每种监督式机器学习算法。
1. 线性回归
线性回归 是一种试图找到输入特征和输出值之间线性关系以预测未来事件的算法。该算法广泛用于进行股票分析、天气预报等。
2. K近邻算法
K近邻算法 (kNN) 是一种统计技术,可用于解决分类和回归问题。该算法通过数学计算与训练数据中其他点的最近距离来对新数据进行分类或预测值。
让我们讨论一下使用kNN对未知物体进行分类的情况。考虑如下所示的物体分布图:

来源
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
该图显示了三种类型的物体,分别用红色、蓝色和绿色标记。当您在上述数据集上运行kNN分类器时,每种类型的物体的边界将如下所示:

来源
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
现在,考虑一个您想要将其分类为红色、绿色或蓝色的新未知物体。这在下面的图中有所描述。

从视觉上看,未知数据点属于蓝色物体的类别。数学上,可以通过测量该未知点与数据集中每个其他点的距离来得出这个结论。当您这样做时,您会知道它的许多邻居都是蓝色的。红色和绿色物体之间的平均距离肯定大于蓝色物体之间的平均距离。因此,这个未知物体可以被分类为属于蓝色类别。
kNN算法也可用于回归问题。kNN算法在大多数ML库中都以现成的形式提供。
3. 决策树
决策树 是一种树状结构,用于决策和分析可能的结果。该算法根据特征将数据分割成子集,其中每个父节点表示内部决策,叶节点表示最终预测。
一个简单的流程图格式的决策树如下所示:

您可以编写代码根据此流程图对输入数据进行分类。流程图不言自明且简单。在这种情况下,您正在尝试对收到的电子邮件进行分类,以决定何时阅读它。
实际上,决策树可能很大且很复杂。有多种算法可用于创建和遍历这些树。作为一名机器学习爱好者,您需要理解和掌握创建和遍历决策树的技术。
4. 朴素贝叶斯
朴素贝叶斯 用于创建分类器。假设您想从一个水果篮中分类(分类)不同种类的水果。您可以使用水果的颜色、大小和形状等特征;例如,任何颜色为红色、形状为圆形且直径约为 10 厘米的水果都可以被认为是苹果。因此,为了训练模型,您将使用这些特征并测试给定特征匹配所需约束的概率。然后将不同特征的概率结合起来,得出给定水果是苹果的概率。朴素贝叶斯通常只需要少量训练数据即可进行分类。
5. 逻辑回归
逻辑回归 是一种统计算法,用于估计事件发生的概率。
看下面的图表。它显示了XY平面中数据点的分布。

从图中,我们可以直观地检查红色和绿色点的分离。您可以画一条边界线来区分这些点。现在,要对新的数据点进行分类,您只需要确定该点位于线的哪一侧。
6. 支持向量机
支持向量机 (SVM) 算法通常可用于分类和回归。对于分类任务,该算法创建一个超平面来将数据分成不同的类别。而对于回归,该算法则尝试拟合一条误差最小的回归线。
请看以下数据分布。这里的三类数据无法线性分离。边界曲线是非线性的。在这种情况下,找到曲线的方程就变得非常复杂。
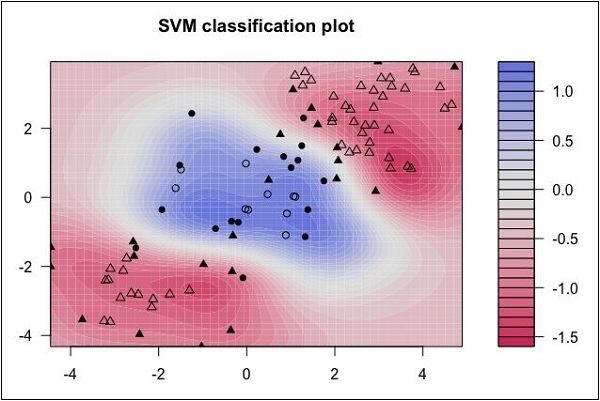
支持向量机 (SVM) 在确定此类情况下的分离边界方面非常有用。
7. 随机森林
随机森林 也是一种监督学习算法,它灵活适用于分类和回归。该算法结合了多个决策树,并将其合并以提高预测的准确性。
下图说明了随机森林算法的工作原理:

8. 梯度提升
梯度提升 将弱学习器(决策树)组合起来,创建一个强大的模型。它构建新的模型来纠正先前模型的错误。该算法的目标是最小化损失函数。它可以有效地用于分类和回归任务。
监督学习的优势
监督学习算法是机器学习模型中最流行的一种。一些好处包括:
- 监督学习的目标定义明确,这提高了预测的准确性。
- 使用监督学习训练的模型在预测和分类方面非常有效,因为它们使用标记数据集。
- 它具有高度的通用性,即可以应用于各种问题,例如垃圾邮件检测、股票价格等。
监督学习的劣势
尽管监督学习是最常用的,但它也面临一些挑战。其中一些是:
- 监督学习需要大量的标记数据才能有效地训练模型。收集如此庞大的数据实际上非常困难;它既昂贵又费时。
- 如果测试数据与训练数据不同,监督学习无法准确预测。
- 准确标记数据很复杂,需要专业知识和努力。
监督学习的应用
监督学习模型广泛应用于各个行业的许多应用中,包括以下方面:
- **图像识别** - 模型在标记的图像数据集上进行训练,其中每个图像都与一个标签相关联。模型被输入数据,这允许它学习模式和特征。一旦训练完成,现在可以使用新的、未见过的数据来测试模型。这广泛用于人脸识别和目标检测等应用中。
- **预测分析** - 监督学习算法用于训练标记的历史数据,允许模型学习输入特征和输出之间的模式和关系,以识别趋势并做出准确的预测。企业使用这种方法来做出数据驱动的决策并增强战略规划。