
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Python 展示统计学中的帕累托分布
帕累托分布是一种幂律概率分布,通常用于描述可测量的现象,例如社会、科学、地球物理或精算数据。它以意大利经济学家、社会学家和土木工程师维尔弗雷多·帕累托的名字命名。帕累托分布常用于模拟各种数据集的分布,例如城市规模、网站流量和科学出版物的引用。
帕累托法则,也称为 80/20 法则,表明在每种场景或系统中,20% 的投入会导致 80% 的产出。Python 提供了各种用于处理概率分布的库,例如 scipy.stats 库。为了在 Python 中计算帕累托分布,可以使用 scipy.stats 库中的 pareto 函数,并将其形状参数 alpha 和尺度参数 xm 作为参数。
语法
以下语法用于从帕累托分布生成 500 个随机数:
import numpy as np from scipy.stats import pareto data = pareto.rvs(alpha_value, 500, scale_value) print(np.mean(data))
算法
步骤 1 - 导入库。
步骤 2 - 定义形状参数 (alpha) 和尺度参数 (xm)
步骤 3 - 给出生成随机数的特定大小,并使用 'pareto.rvs' 函数。
步骤 4 - 打印生成的随机数。
方法 1:这里我们使用 scipy.stats 库
示例 1
要从 alpha = 2 和 xm = 1 的帕累托分布生成 500 个随机数,我们可以使用以下代码:
import numpy as np from scipy.stats import pareto data = pareto.rvs(2, size=500, scale=1) print(np.mean(data))
输出
1.9138055526628364
此代码根据数字运算和质数定义的帕累托分布生成 500 个随机数。计算并打印生成的数字的平均值(均值)。这对于组织分布统计数据并在 Python 中执行初步分析很有用。
示例 2
要从 alpha = 3 和 xm = 2 的帕累托分布生成 700 个随机数,我们可以使用以下代码:
import numpy as np from scipy.stats import pareto data = pareto.rvs(3, size=700, scale=2) print(np.median(data))
输出
2.517223926313278
此代码使用帕累托分布生成 700 个随机数,其中大小参数设置为 3,尺度参数设置为 2。计算并打印生成的数字的中位数(中间得分)。这可以用来检查生成的数字的中间数字。
示例 3
要从 alpha = 5 和 xm = 1 的帕累托分布生成 1000 个随机数,我们可以使用以下代码:
import numpy as np from scipy.stats import pareto data = pareto.rvs(5, size=1000, scale=1) print(np.median(data))
输出
1.1557246772718455
在此代码中,从帕累托分布生成 1000 个随机数,大小参数设置为 3,尺度参数设置为 2。在此之后,计算并打印生成的数字的中位数。这给出了生成的数字的中位数。
方法 2:这里我们使用 Numpy 库
示例 1
要从 alpha = 2 和 xm = 1 的帕累托分布生成 500 个随机数,我们可以使用以下代码:
import numpy as np alpha = 2 xm = 1 size = 500 data = np.random.pareto(alpha, size) + xm print(np.mean(data))
输出
1.8557392857152564
此代码根据数字运算和质数定义的帕累托分布生成 500 个随机数。它计算并打印生成的数字的平均值(均值)。
示例 2
要从 alpha = 4 和 xm = 2 的帕累托分布生成 500 个随机数,我们可以使用以下代码:
import numpy as np alpha = 4 xm = 2 size = 500 data = np.random.pareto(alpha, size) + xm print(np.mean(data))
输出
2.33759634002971
此代码根据数字运算和质数定义的帕累托分布生成 500 个随机数。它计算并打印生成的数字的平均值(均值)。
示例 3
要从 alpha = 4 和 xm = 2 的帕累托分布生成 700 个随机数,我们可以使用以下代码:
import numpy as np alpha = 4 xm = 2 size = 700 data = np.random.pareto(alpha, size) + xm print(np.median(data))
输出
2.202691921458917
在此代码中,帕累托分布的 alpha 参数设置为 4,尺度 (xm) 设置为 2。在此之后,生成 700 个随机数,这些随机数根据帕累托分布确定。计算并打印生成的数字的中位数。这给出了生成的数字的中位数。
注意 - 以上所有程序/代码每次都会给出不同的输出,因为它们在程序中生成随机数。
示例 4
在此程序/示例中,我们分别使用 pdf 和 cdf 方法计算帕累托分布的概率密度函数 (PDF) 和累积分布函数 (CDF),并使用 matplotlib 绘制 PDF 和 CDF 以可视化分布。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import pareto
alpha = 2 # define shape parameter
xm = 1 # define scale parameter
# Generate random numbers from a Pareto distribution
random_numbers = pareto.rvs(alpha, scale=xm, size=1000)
data = np.linspace(pareto.ppf(0.10, alpha, scale=xm), pareto.ppf(0.90, alpha, scale=xm), 100)
pdf = pareto.pdf(data, alpha, scale=xm) # Calculate the PDF
cdf = pareto.cdf(data, alpha, scale=xm) # Calculate the CDF
# Plotting the PDF and CDF
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(data, pdf, 'r', lw=2, label='PDF')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.title('Pareto Distribution PDF')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(data, cdf, 'b', lw=2, label='CDF')
plt.xlabel('x')
plt.ylabel('Cumulative Probability')
plt.title('Pareto Distribution CDF')
plt.legend()
plt.show()
输出
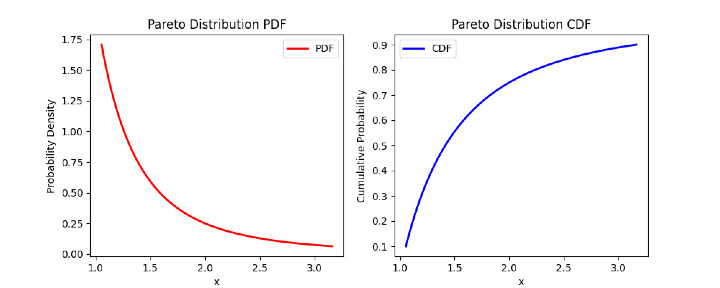
结论
总之,帕累托分布是一种有效的统计工具,用于模拟具有少量极值和大量较小值的事件。帕累托分布在各个领域都有广泛的应用,因为它可以模拟收入差距、城市规模和其他经济因素。通过使用 Python 模块(如 scipy.stats、Numpy 和 matplotlib),我们可以快速计算、拟合、可视化和分析帕累托分布,并获得对这些情况的重要见解。

699 次查看
