- SQL 教程
- SQL - 首页
- SQL - 概述
- SQL - RDBMS 概念
- SQL - 数据库
- SQL - 语法
- SQL - 数据类型
- SQL - 运算符
- SQL - 表达式
- SQL 数据库
- SQL - 创建数据库
- SQL - 删除数据库
- SQL - 选择数据库
- SQL - 重命名数据库
- SQL - 显示数据库
- SQL - 备份数据库
- SQL 表
- SQL - 创建表
- SQL - 显示表
- SQL - 重命名表
- SQL - 截断表
- SQL - 克隆表
- SQL - 临时表
- SQL - 修改表
- SQL - 删除表
- SQL - 删除表数据
- SQL - 约束
- SQL 查询
- SQL - 插入查询
- SQL - 选择查询
- SQL - Select Into
- SQL - Insert Into Select
- SQL - 更新查询
- SQL - 删除查询
- SQL - 排序结果
- SQL 视图
- SQL - 创建视图
- SQL - 更新视图
- SQL - 删除视图
- SQL - 重命名视图
- SQL 运算符和子句
- SQL - Where 子句
- SQL - Top 子句
- SQL - Distinct 子句
- SQL - Order By 子句
- SQL - Group By 子句
- SQL - Having 子句
- SQL - AND & OR
- SQL - BOOLEAN (BIT) 运算符
- SQL - LIKE 运算符
- SQL - IN 运算符
- SQL - ANY, ALL 运算符
- SQL - EXISTS 运算符
- SQL - CASE
- SQL - NOT 运算符
- SQL - 不等于
- SQL - IS NULL
- SQL - IS NOT NULL
- SQL - NOT NULL
- SQL - BETWEEN 运算符
- SQL - UNION 运算符
- SQL - UNION vs UNION ALL
- SQL - INTERSECT 运算符
- SQL - EXCEPT 运算符
- SQL - 别名
- SQL 连接
- SQL - 使用连接
- SQL - 内连接
- SQL - 左连接
- SQL - 右连接
- SQL - 交叉连接
- SQL - 全连接
- SQL - 自连接
- SQL - 删除连接
- SQL - 更新连接
- SQL - 左连接 vs 右连接
- SQL - Union vs Join
- SQL 键
- SQL - 唯一键
- SQL - 主键
- SQL - 外键
- SQL - 组合键
- SQL - 候选键
- SQL 索引
- SQL - 索引
- SQL - 创建索引
- SQL - 删除索引
- SQL - 显示索引
- SQL - 唯一索引
- SQL - 聚集索引
- SQL - 非聚集索引
- 高级 SQL
- SQL - 通配符
- SQL - 注释
- SQL - 注入
- SQL - 托管
- SQL - Min & Max
- SQL - 空值函数
- SQL - 检查约束
- SQL - 默认约束
- SQL - 存储过程
- SQL - NULL 值
- SQL - 事务
- SQL - 子查询
- SQL - 处理重复数据
- SQL - 使用序列
- SQL - 自动递增
- SQL - 日期和时间
- SQL - 游标
- SQL - 公共表表达式
- SQL - Group By vs Order By
- SQL - IN vs EXISTS
- SQL - 数据库调优
- SQL 函数参考
- SQL - 日期函数
- SQL - 字符串函数
- SQL - 聚合函数
- SQL - 数值函数
- SQL - 文本和图像函数
- SQL - 统计函数
- SQL - 逻辑函数
- SQL - 游标函数
- SQL - JSON 函数
- SQL - 转换函数
- SQL - 数据类型函数
- SQL 有用资源
- SQL - 问答
- SQL - 快速指南
- SQL - 有用函数
- SQL - 有用资源
- SQL - 讨论
SQL - 非聚集索引

SQL 非聚集索引
SQL **非聚集** 索引类似于聚集索引。当在某列上定义时,它会创建一个特殊的表,该表包含索引列的副本以及指向表中实际数据位置的指针。但是,与聚集索引不同,非聚集索引无法物理排序索引列。
以下是 SQL 中非聚集索引的一些关键点:
- 非聚集索引是一种用于数据库的索引类型,用于加快数据库查询的执行时间。
- 这些索引需要的存储空间比聚集索引少,因为它们不存储实际的数据行。
- 我们可以在单个表上创建多个非聚集索引。
MySQL 没有非聚集索引的概念。PRIMARY KEY(如果存在)和第一个 NOT NULL UNIQUE KEY(如果不存在 PRIMARY KEY)在 MySQL 中被视为聚集索引;所有其他索引都被称为二级索引,并且是隐式定义的。
为了更好地理解,请查看以下说明非聚集索引工作原理的图:
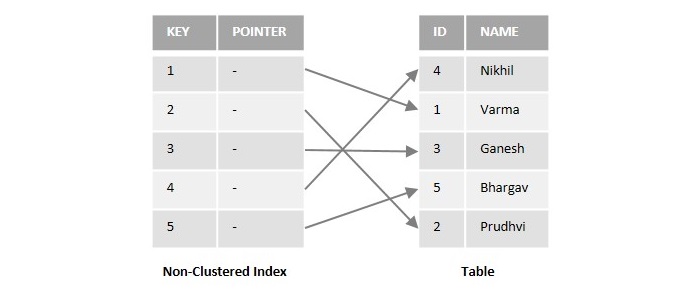
假设我们有一个示例数据库表,其中包含两列,名为 **ID** 和 **NAME**。如果我们在上述表中名为 **ID** 的列上创建非聚集索引,它将存储 ID 列的副本以及指向表中实际数据特定位置的指针。
语法
以下是 SQL Server 中创建 **非聚集** 索引的语法:
CREATE NONCLUSTERED INDEX index_name ON table_name (column_name)
这里,
- **index_name**:保存非聚集索引的名称。
- **table_name**:保存要创建非聚集索引的表的名称。
- **column_name**:保存要为其定义非聚集索引的列的名称。
示例
让我们使用以下查询创建一个名为 **CUSTOMERS** 的表:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (20, 2), );
让我们使用以下查询将一些值插入到上面创建的表中:
INSERT INTO CUSTOMERS VALUES (7, 'Muffy', '24', 'Indore', 5500), (1, 'Ramesh', '32', 'Ahmedabad', 2000), (6, 'Komal', '22', 'Hyderabad', 9000), (2, 'Khilan', '25', 'Delhi', 1500), (4, 'Chaitali', '25', 'Mumbai', 6500), (5, 'Hardik','27', 'Bhopal', 8500), (3, 'Kaushik', '23', 'Kota', 2000);
该表已成功在 SQL 数据库中创建。
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
现在,让我们使用以下查询在名为 **ID** 的 **单个列** 上创建非聚集索引:
CREATE NONCLUSTERED INDEX NON_CLU_ID ON customers (ID ASC);
输出
执行上述查询后,输出将显示如下:
Commands Completed Successfully.
验证
让我们使用以下查询检索在 CUSTOMERS 表上创建的所有索引:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
正如我们观察到的,我们可以在索引列表中找到名为 ID 的列。
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | 位于 PRIMARY 上的非聚集索引 | ID |
现在,使用以下查询再次检索 CUSTOMERS 表以检查表是否已排序:
SELECT * FROM CUSTOMERS;
正如我们观察到的,非聚集索引不会物理排序行,而是从表数据创建单独的键值结构。
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
在多列上创建非聚集索引
不用创建新表,让我们考虑之前创建的 CUSTOMERS 表。现在,尝试使用以下查询在表的 **多个列**(例如 ID、AGE 和 SALARY)上创建非聚集索引:
CREATE NONCLUSTERED INDEX NON_CLUSTERED_ID ON CUSTOMERS (ID, AGE, SALARY);
输出
以下查询将为 ID、AGE 和 SALARY 创建三个单独的非聚集索引。
Commands Completed Successfully.
验证
让我们使用以下查询检索在 CUSTOMERS 表上创建的所有索引:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
正如我们观察到的,我们可以在索引列表中找到列名 ID、AGE 和 SALARY 列。
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | 位于 PRIMARY 上的非聚集索引 | ID、AGE、SALARY |
广告