- SQL 教程
- SQL - 首页
- SQL - 概述
- SQL - RDBMS 概念
- SQL - 数据库
- SQL - 语法
- SQL - 数据类型
- SQL - 运算符
- SQL - 表达式
- SQL 数据库
- SQL - 创建数据库
- SQL - 删除数据库
- SQL - 选择数据库
- SQL - 重命名数据库
- SQL - 显示数据库
- SQL - 备份数据库
- SQL 表
- SQL - 创建表
- SQL - 显示表
- SQL - 重命名表
- SQL - 截断表
- SQL - 克隆表
- SQL - 临时表
- SQL - 修改表
- SQL - 删除表
- SQL - 删除表
- SQL - 约束
- SQL 查询
- SQL - 插入查询
- SQL - 选择查询
- SQL - Select Into
- SQL - Insert Into Select
- SQL - 更新查询
- SQL - 删除查询
- SQL - 排序结果
- SQL 视图
- SQL - 创建视图
- SQL - 更新视图
- SQL - 删除视图
- SQL - 重命名视图
- SQL 运算符和子句
- SQL - Where 子句
- SQL - Top 子句
- SQL - Distinct 子句
- SQL - Order By 子句
- SQL - Group By 子句
- SQL - Having 子句
- SQL - AND & OR
- SQL - BOOLEAN (BIT) 运算符
- SQL - LIKE 运算符
- SQL - IN 运算符
- SQL - ANY, ALL 运算符
- SQL - EXISTS 运算符
- SQL - CASE
- SQL - NOT 运算符
- SQL - 不等于
- SQL - IS NULL
- SQL - IS NOT NULL
- SQL - NOT NULL
- SQL - BETWEEN 运算符
- SQL - UNION 运算符
- SQL - UNION vs UNION ALL
- SQL - INTERSECT 运算符
- SQL - EXCEPT 运算符
- SQL - 别名
- SQL 连接
- SQL - 使用连接
- SQL - 内连接
- SQL - 左连接
- SQL - 右连接
- SQL - 交叉连接
- SQL - 全连接
- SQL - 自连接
- SQL - 删除连接
- SQL - 更新连接
- SQL - 左连接 vs 右连接
- SQL - Union vs Join
- SQL 密钥
- SQL - 唯一键
- SQL - 主键
- SQL - 外键
- SQL - 复合键
- SQL - 备用键
- SQL 索引
- SQL - 索引
- SQL - 创建索引
- SQL - 删除索引
- SQL - 显示索引
- SQL - 唯一索引
- SQL - 聚集索引
- SQL - 非聚集索引
- 高级 SQL
- SQL - 通配符
- SQL - 注释
- SQL - 注入
- SQL - 托管
- SQL - Min & Max
- SQL - 空函数
- SQL - 检查约束
- SQL - 默认约束
- SQL - 存储过程
- SQL - NULL 值
- SQL - 事务
- SQL - 子查询
- SQL - 处理重复项
- SQL - 使用序列
- SQL - 自动递增
- SQL - 日期和时间
- SQL - 游标
- SQL - 公共表表达式
- SQL - Group By vs Order By
- SQL - IN vs EXISTS
- SQL - 数据库调整
- SQL 函数参考
- SQL - 日期函数
- SQL - 字符串函数
- SQL - 聚合函数
- SQL - 数值函数
- SQL - 文本和图像函数
- SQL - 统计函数
- SQL - 逻辑函数
- SQL - 游标函数
- SQL - JSON 函数
- SQL - 转换函数
- SQL - 数据类型函数
- SQL 有用资源
- SQL - 问答
- SQL - 快速指南
- SQL - 有用函数
- SQL - 有用资源
- SQL - 讨论
SQL - 自连接

自连接顾名思义,是一种将表中的记录与其自身结合的连接类型。
假设一个组织在组织圣诞派对时,根据一些颜色在员工中选择秘密圣诞老人。它的设计方法是为每个员工分配一种颜色,并让他们从各种颜色的池中选择一种颜色。最后,他们将成为分配此颜色的员工的秘密圣诞老人。
如下图所示,分配的颜色和每个员工选择的颜色信息都输入到一个表中。该表使用自连接通过颜色列连接自身,以将员工与其秘密圣诞老人匹配。
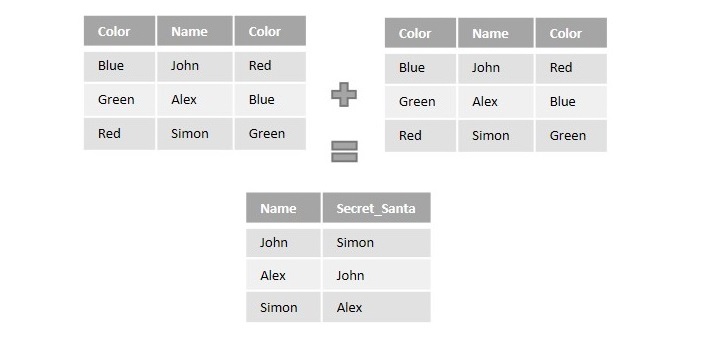
SQL 自连接
SQL 自连接用于将一个表连接到自身,就好像该表是两个表一样。为了执行此操作,至少应使用一次表的别名。
自连接是一种内连接,当需要比较同一表的两个列时执行;可能是在它们之间建立关系。换句话说,当表中同时包含外键和主键时,该表会与自身连接。
与其他连接的查询不同,我们使用 WHERE 子句指定表与自身结合的条件;而不是 ON 子句。
语法
以下是 SQL 自连接的基本语法:
SELECT column_name(s) FROM table1 a, table1 b WHERE a.common_field = b.common_field;
这里,WHERE 子句可以是基于您的需求的任何给定表达式。
示例
自连接只需要一个表,所以,让我们创建一个包含客户详细信息(如姓名、年龄、地址和他们赚取的工资)的 CUSTOMERS 表。
CREATE TABLE CUSTOMERS ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
现在,使用 INSERT 语句如下插入值到此表中:
INSERT INTO CUSTOMERS VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ), (2, 'Khilan', 25, 'Delhi', 1500.00 ), (3, 'Kaushik', 23, 'Kota', 2000.00 ), (4, 'Chaitali', 25, 'Mumbai', 6500.00 ), (5, 'Hardik', 27, 'Bhopal', 8500.00 ), (6, 'Komal', 22, 'Hyderabad', 4500.00 ), (7, 'Muffy', 24, 'Indore', 10000.00 );
该表将被创建为:
| ID | 姓名 | 年龄 | 地址 | 工资 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | 艾哈迈达巴德 | 2000.00 |
| 2 | Khilan | 25 | 德里 | 1500.00 |
| 3 | Kaushik | 23 | 科塔 | 2000.00 |
| 4 | Chaitali | 25 | 孟买 | 6500.00 |
| 5 | Hardik | 27 | 博帕尔 | 8500.00 |
| 6 | Komal | 22 | 海得拉巴 | 4500.00 |
| 7 | Muffy | 24 | 因多尔 | 10000.00 |
现在,让我们使用以下自连接查询连接此表。我们的目标是根据这些客户的收入在他们之间建立关系。我们正在使用 WHERE 子句来做到这一点。
SELECT a.ID, b.NAME as EARNS_HIGHER, a.NAME as EARNS_LESS, a.SALARY as LOWER_SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY < b.SALARY;
输出
显示的结果表将列出所有收入低于其他客户的客户:
| ID | 收入较高 | 收入较低 | 较低工资 |
|---|---|---|---|
| 2 | Ramesh | Khilan | 1500.00 |
| 2 | Kaushik | Khilan | 1500.00 |
| 6 | Chaitali | Komal | 4500.00 |
| 3 | Chaitali | Kaushik | 2000.00 |
| 2 | Chaitali | Khilan | 1500.00 |
| 1 | Chaitali | Ramesh | 2000.00 |
| 6 | Hardik | Komal | 4500.00 |
| 4 | Hardik | Chaitali | 6500.00 |
| 3 | Hardik | Kaushik | 2000.00 |
| 2 | Hardik | Khilan | 1500.00 |
| 1 | Hardik | Ramesh | 2000.00 |
| 3 | Komal | Kaushik | 2000.00 |
| 2 | Komal | Khilan | 1500.00 |
| 1 | Komal | Ramesh | 2000.00 |
| 6 | Muffy | Komal | 4500.00 |
| 5 | Muffy | Hardik | 8500.00 |
| 4 | Muffy | Chaitali | 6500.00 |
| 3 | Muffy | Kaushik | 2000.00 |
| 2 | Muffy | Khilan | 1500.00 |
| 1 | Muffy | Ramesh | 2000.00 |
带有 ORDER BY 子句的自连接
使用自连接将表与自身连接后,还可以使用 ORDER BY 子句按顺序对组合表中的记录进行排序。
语法
以下是它的语法:
SELECT column_name(s) FROM table1 a, table1 b WHERE a.common_field = b.common_field ORDER BY column_name;
示例
让我们使用 WHERE 子句上的自连接将 CUSTOMERS 表与其自身连接;然后,使用 ORDER BY 子句根据指定的列按升序排列记录,如下面的查询所示。
SELECT a.ID, b.NAME as EARNS_HIGHER, a.NAME as EARNS_LESS, a.SALARY as LOWER_SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY < b.SALARY ORDER BY a.SALARY;
输出
结果表显示如下:
| ID | 收入较高 | 收入较低 | 较低工资 |
|---|---|---|---|
| 2 | Ramesh | Khilan | 1500.00 |
| 2 | Kaushik | Khilan | 1500.00 |
| 2 | Chaitali | Khilan | 1500.00 |
| 2 | Hardik | Khilan | 1500.00 |
| 2 | Komal | Khilan | 1500.00 |
| 2 | Muffy | Khilan | 1500.00 |
| 3 | Chaitali | Kaushik | 2000.00 |
| 1 | Chaitali | Ramesh | 2000.00 |
| 3 | Hardik | Kaushik | 2000.00 |
| 1 | Hardik | Ramesh | 2000.00 |
| 3 | Komal | Kaushik | 2000.00 |
| 1 | Komal | Ramesh | 2000.00 |
| 3 | Muffy | Kaushik | 2000.00 |
| 1 | Muffy | Ramesh | 2000.00 |
| 6 | Chaitali | Komal | 4500.00 |
| 6 | Hardik | Komal | 4500.00 |
| 6 | Muffy | Komal | 4500.00 |
| 4 | Hardik | Chaitali | 6500.00 |
| 4 | Muffy | Chaitali | 6500.00 |
| 5 | Muffy | Hardik | 8500.00 |
不仅是工资列,还可以根据姓名的字母顺序、客户 ID 的数字顺序等对记录进行排序。
广告