监督神经网络
顾名思义,监督学习是在教师的监督下进行的。这个学习过程是依赖性的。在监督学习下训练ANN时,将输入向量呈现给网络,网络将产生一个输出向量。将此输出向量与所需的/目标输出向量进行比较。如果实际输出与所需的/目标输出向量之间存在差异,则会生成错误信号。根据此错误信号,将调整权重,直到实际输出与所需输出匹配。
感知器
感知器是由弗兰克·罗森布拉特使用麦卡洛克-皮茨模型开发的,是人工神经网络的基本操作单元。它采用监督学习规则,能够将数据分类为两类。
感知器的操作特性:它由一个具有任意数量输入的神经元以及可调节的权重组成,但神经元的输出取决于阈值,为1或0。它还包括一个偏差,其权重始终为1。下图给出了感知器的示意图。
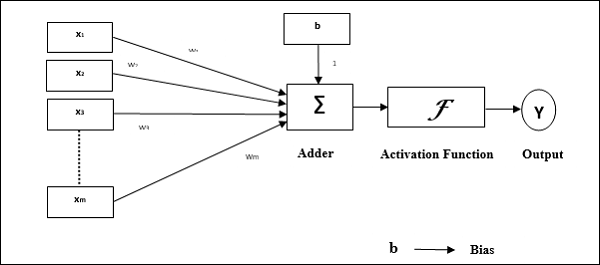
因此,感知器具有以下三个基本元素:
连接 - 它将有一组连接链接,这些链接携带权重,包括一个始终权重为1的偏差。
加法器 - 它在输入乘以各自的权重后对它们进行加法。
激活函数 - 它限制神经元的输出。最基本的激活函数是具有两种可能输出的Heaviside阶跃函数。如果输入为正,则此函数返回1,对于任何负输入则返回0。
训练算法
感知器网络可以针对单个输出单元以及多个输出单元进行训练。
单个输出单元的训练算法
步骤1 - 初始化以下内容以开始训练:
- 权重
- 偏差
- 学习率 $\alpha$
为了简便计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2 - 当停止条件不为真时,继续执行步骤3-8。
步骤3 - 对于每个训练向量x,继续执行步骤4-6。
步骤4 - 按如下方式激活每个输入单元:
$$x_{i}\:=\:s_{i}\:(i\:=\:1\:to\:n)$$
步骤5 - 现在使用以下关系获得净输入:
$$y_{in}\:=\:b\:+\:\displaystyle\sum\limits_{i}^n x_{i}.\:w_{i}$$
这里'b'是偏差,'n'是输入神经元的总数。
步骤6 - 应用以下激活函数以获得最终输出。
$$f(y_{in})\:=\:\begin{cases}1 & if\:y_{in}\:>\:\theta\\0 & if \: -\theta\:\leqslant\:y_{in}\:\leqslant\:\theta\\-1 & if\:y_{in}\:<\:-\theta \end{cases}$$
步骤7 - 按如下方式调整权重和偏差:
情况1 - 如果y ≠ t,则
$$w_{i}(new)\:=\:w_{i}(old)\:+\:\alpha\:tx_{i}$$
$$b(new)\:=\:b(old)\:+\:\alpha t$$
情况2 - 如果y = t,则
$$w_{i}(new)\:=\:w_{i}(old)$$
$$b(new)\:=\:b(old)$$
这里'y'是实际输出,'t'是所需的/目标输出。
步骤8 - 测试停止条件,当权重没有变化时将发生此条件。
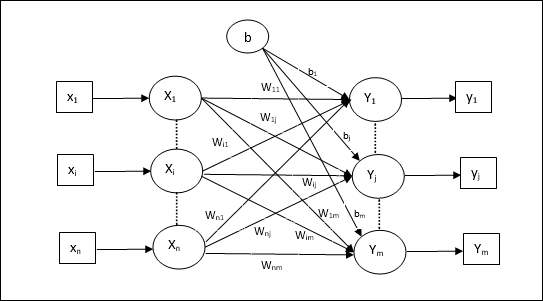
多个输出单元的训练算法
下图是用于多个输出类的感知器架构。
步骤1 - 初始化以下内容以开始训练:
- 权重
- 偏差
- 学习率 $\alpha$
为了简便计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2 - 当停止条件不为真时,继续执行步骤3-8。
步骤3 - 对于每个训练向量x,继续执行步骤4-6。
步骤4 - 按如下方式激活每个输入单元:
$$x_{i}\:=\:s_{i}\:(i\:=\:1\:to\:n)$$
步骤5 - 使用以下关系获得净输入:
$$y_{in}\:=\:b\:+\:\displaystyle\sum\limits_{i}^n x_{i}\:w_{ij}$$
这里'b'是偏差,'n'是输入神经元的总数。
步骤6 - 应用以下激活函数以获得每个输出单元j = 1到m的最终输出:
$$f(y_{in})\:=\:\begin{cases}1 & if\:y_{inj}\:>\:\theta\\0 & if \: -\theta\:\leqslant\:y_{inj}\:\leqslant\:\theta\\-1 & if\:y_{inj}\:<\:-\theta \end{cases}$$
步骤7 - 按如下方式调整x = 1到n和j = 1到m的权重和偏差:
情况1 - 如果yj ≠ tj,则
$$w_{ij}(new)\:=\:w_{ij}(old)\:+\:\alpha\:t_{j}x_{i}$$
$$b_{j}(new)\:=\:b_{j}(old)\:+\:\alpha t_{j}$$
情况2 - 如果yj = tj,则
$$w_{ij}(new)\:=\:w_{ij}(old)$$
$$b_{j}(new)\:=\:b_{j}(old)$$
这里'y'是实际输出,'t'是所需的/目标输出。
步骤8 - 测试停止条件,当权重没有变化时将发生此条件。
自适应线性神经元 (Adaline)
Adaline代表自适应线性神经元,是一个具有单个线性单元的网络。它由Widrow和Hoff于1960年开发。关于Adaline的一些要点如下:
它使用双极激活函数。
它使用delta规则进行训练,以最小化实际输出与所需/目标输出之间的均方误差 (MSE)。
权重和偏差是可调节的。
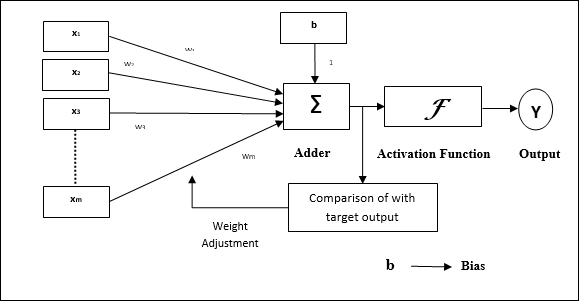
架构
Adaline的基本结构类似于感知器,它具有一个额外的反馈循环,借助该循环,实际输出与所需的/目标输出进行比较。比较后,根据训练算法,将更新权重和偏差。
训练算法
步骤1 - 初始化以下内容以开始训练:
- 权重
- 偏差
- 学习率 $\alpha$
为了简便计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2 - 当停止条件不为真时,继续执行步骤3-8。
步骤3 - 对于每个双极训练对s:t,继续执行步骤4-6。
步骤4 - 按如下方式激活每个输入单元:
$$x_{i}\:=\:s_{i}\:(i\:=\:1\:to\:n)$$
步骤5 - 使用以下关系获得净输入:
$$y_{in}\:=\:b\:+\:\displaystyle\sum\limits_{i}^n x_{i}\:w_{i}$$
这里'b'是偏差,'n'是输入神经元的总数。
步骤6 - 应用以下激活函数以获得最终输出:
$$f(y_{in})\:=\:\begin{cases}1 & if\:y_{in}\:\geqslant\:0 \\-1 & if\:y_{in}\:<\:0 \end{cases}$$
步骤7 - 按如下方式调整权重和偏差:
情况1 - 如果y ≠ t,则
$$w_{i}(new)\:=\:w_{i}(old)\:+\: \alpha(t\:-\:y_{in})x_{i}$$
$$b(new)\:=\:b(old)\:+\: \alpha(t\:-\:y_{in})$$
情况2 - 如果y = t,则
$$w_{i}(new)\:=\:w_{i}(old)$$
$$b(new)\:=\:b(old)$$
这里'y'是实际输出,'t'是所需的/目标输出。
$(t\:-\;y_{in})$是计算出的误差。
步骤8 - 测试停止条件,当权重没有变化或训练期间发生的最高权重变化小于指定的容差时,将发生此条件。
多自适应线性神经元 (Madaline)
Madaline代表多自适应线性神经元,是一个由许多Adaline并行组成的网络。它将有一个输出单元。关于Madaline的一些要点如下:
它就像一个多层感知器,其中Adaline充当输入和Madaline层之间的隐藏单元。
输入和Adaline层之间的权重和偏差(如我们在Adaline架构中看到的)是可调节的。
Adaline和Madaline层具有固定的权重和偏差1。
可以使用Delta规则进行训练。
架构
Madaline的架构由输入层的“n”个神经元、Adaline层的“m”个神经元和Madaline层的1个神经元组成。Adaline层可以被认为是隐藏层,因为它位于输入层和输出层(即Madaline层)之间。
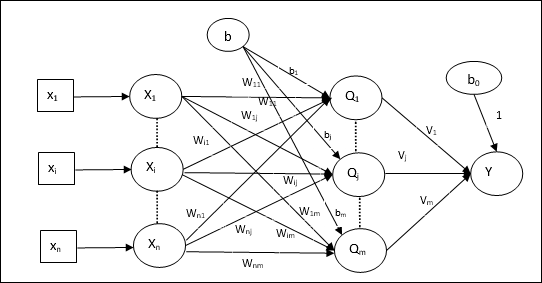
训练算法
到目前为止,我们知道只有输入和Adaline层之间的权重和偏差需要调整,而Adaline和Madaline层之间的权重和偏差是固定的。
步骤1 - 初始化以下内容以开始训练:
- 权重
- 偏差
- 学习率 $\alpha$
为了简便计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2 - 当停止条件不为真时,继续执行步骤3-8。
步骤3 - 对于每个双极训练对s:t,继续执行步骤4-7。
步骤4 - 按如下方式激活每个输入单元:
$$x_{i}\:=\:s_{i}\:(i\:=\:1\:to\:n)$$
步骤5 - 使用以下关系获得每个隐藏层(即Adaline层)的净输入:
$$Q_{inj}\:=\:b_{j}\:+\:\displaystyle\sum\limits_{i}^n x_{i}\:w_{ij}\:\:\:j\:=\:1\:to\:m$$
这里'b'是偏差,'n'是输入神经元的总数。
步骤6 - 应用以下激活函数以获得Adaline和Madaline层的最终输出:
$$f(x)\:=\:\begin{cases}1 & if\:x\:\geqslant\:0 \\-1 & if\:x\:<\:0 \end{cases}$$
隐藏(Adaline)单元的输出
$$Q_{j}\:=\:f(Q_{inj})$$
网络的最终输出
$$y\:=\:f(y_{in})$$
即 $\:\:y_{inj}\:=\:b_{0}\:+\:\sum_{j = 1}^m\:Q_{j}\:v_{j}$
步骤7 - 计算误差并调整权重如下:
情况1 - 如果y ≠ t且t = 1,则
$$w_{ij}(new)\:=\:w_{ij}(old)\:+\: \alpha(1\:-\:Q_{inj})x_{i}$$
$$b_{j}(new)\:=\:b_{j}(old)\:+\: \alpha(1\:-\:Q_{inj})$$
在这种情况下,将更新Qj上的权重,其中净输入接近0,因为t = 1。
情况2 - 如果y ≠ t且t = -1,则
$$w_{ik}(new)\:=\:w_{ik}(old)\:+\: \alpha(-1\:-\:Q_{ink})x_{i}$$
$$b_{k}(new)\:=\:b_{k}(old)\:+\: \alpha(-1\:-\:Q_{ink})$$
在这种情况下,将更新Qk上的权重,其中净输入为正,因为t = -1。
这里'y'是实际输出,'t'是所需的/目标输出。
情况3 - 如果y = t,则
权重不会发生变化。
步骤8 - 测试停止条件,当权重没有变化或训练期间发生的最高权重变化小于指定的容差时,将发生此条件。
反向传播神经网络
反向传播神经网络 (BPN) 是一种多层神经网络,由输入层、至少一个隐藏层和输出层组成。顾名思义,此网络将进行反向传播。通过比较目标输出和实际输出,在输出层计算出的误差将反向传播到输入层。
架构
如示意图所示,BPN的架构具有三个互连层,这些层上具有权重。隐藏层和输出层也具有偏差,其权重始终为1。从图中可以清楚地看出,BPN的工作分为两个阶段。一个阶段将信号从输入层发送到输出层,另一个阶段将误差从输出层反向传播到输入层。
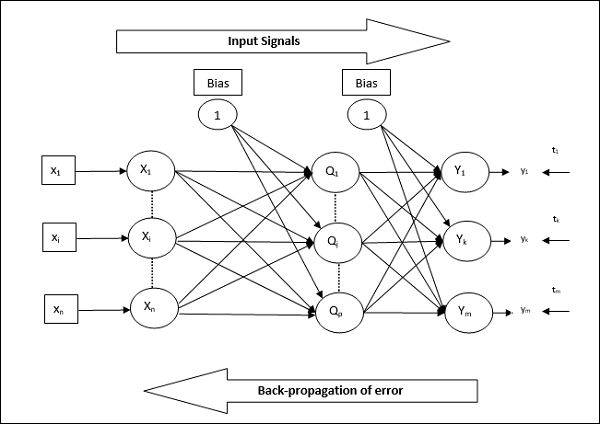
训练算法
为了进行训练,BPN将使用二进制S型激活函数。BPN的训练将包含以下三个阶段。
阶段1 - 前馈阶段
阶段2 - 误差的反向传播
阶段3 - 权重的更新
所有这些步骤将在算法中总结如下
步骤1 - 初始化以下内容以开始训练:
- 权重
- 学习率 $\alpha$
为了简便计算和简化,请取一些小的随机值。
步骤2 - 当停止条件不为真时,继续执行步骤3-11。
步骤3 - 对于每个训练对,继续执行步骤4-10。
阶段1
步骤4 - 每个输入单元接收输入信号xi并将其发送到隐藏单元,对于所有i = 1到n
步骤5 - 使用以下关系计算隐藏单元的净输入:
$$Q_{inj}\:=\:b_{0j}\:+\:\sum_{i=1}^n x_{i}v_{ij}\:\:\:\:j\:=\:1\:to\:p$$
这里b0j是隐藏单元上的偏差,vij是来自输入层i单元的隐藏层j单元上的权重。
现在通过应用以下激活函数计算净输出
$$Q_{j}\:=\:f(Q_{inj})$$
将这些隐藏层单元的输出信号发送到输出层单元。
步骤6 - 使用以下关系计算输出层单元的净输入:
$$y_{ink}\:=\:b_{0k}\:+\:\sum_{j = 1}^p\:Q_{j}\:w_{jk}\:\:k\:=\:1\:to\:m$$
这里b0k是输出单元上的偏差,wjk是来自隐藏层j单元的输出层k单元上的权重。
通过应用以下激活函数计算净输出
$$y_{k}\:=\:f(y_{ink})$$
阶段 2
步骤 7 − 计算误差修正项,对应于每个输出单元接收到的目标模式,如下所示 −
$$\delta_{k}\:=\:(t_{k}\:-\:y_{k})f^{'}(y_{ink})$$
在此基础上,更新权重和偏差,如下所示 −
$$\Delta v_{jk}\:=\:\alpha \delta_{k}\:Q_{ij}$$
$$\Delta b_{0k}\:=\:\alpha \delta_{k}$$
然后,将 $\delta_{k}$ 反馈到隐藏层。
步骤 8 − 现在每个隐藏单元将是来自输出单元的其增量输入之和。
$$\delta_{inj}\:=\:\displaystyle\sum\limits_{k=1}^m \delta_{k}\:w_{jk}$$
误差项可以计算如下 −
$$\delta_{j}\:=\:\delta_{inj}f^{'}(Q_{inj})$$
在此基础上,更新权重和偏差,如下所示 −
$$\Delta w_{ij}\:=\:\alpha\delta_{j}x_{i}$$
$$\Delta b_{0j}\:=\:\alpha\delta_{j}$$
阶段 3
步骤 9 − 每个输出单元 (ykk = 1 到 m) 更新权重和偏差,如下所示 −
$$v_{jk}(new)\:=\:v_{jk}(old)\:+\:\Delta v_{jk}$$
$$b_{0k}(new)\:=\:b_{0k}(old)\:+\:\Delta b_{0k}$$
步骤 10 − 每个隐藏单元 (zjj = 1 到 p) 更新权重和偏差,如下所示 −
$$w_{ij}(new)\:=\:w_{ij}(old)\:+\:\Delta w_{ij}$$
$$b_{0j}(new)\:=\:b_{0j}(old)\:+\:\Delta b_{0j}$$
步骤 11 − 检查停止条件,该条件可以是达到时期数或目标输出与实际输出匹配。
广义 Delta 学习规则
Delta 规则仅适用于输出层。另一方面,广义 Delta 规则,也称为反向传播规则,是一种创建隐藏层期望值的方法。
数学公式
对于激活函数 $y_{k}\:=\:f(y_{ink})$,隐藏层和输出层上的净输入的导数可以由以下公式给出
$$y_{ink}\:=\:\displaystyle\sum\limits_i\:z_{i}w_{jk}$$
以及 $\:\:y_{inj}\:=\:\sum_i x_{i}v_{ij}$
现在需要最小化的误差是
$$E\:=\:\frac{1}{2}\displaystyle\sum\limits_{k}\:[t_{k}\:-\:y_{k}]^2$$
利用链式法则,我们有
$$\frac{\partial E}{\partial w_{jk}}\:=\:\frac{\partial }{\partial w_{jk}}(\frac{1}{2}\displaystyle\sum\limits_{k}\:[t_{k}\:-\:y_{k}]^2)$$
$$=\:\frac{\partial }{\partial w_{jk}}\lgroup\frac{1}{2}[t_{k}\:-\:t(y_{ink})]^2\rgroup$$
$$=\:-[t_{k}\:-\:y_{k}]\frac{\partial }{\partial w_{jk}}f(y_{ink})$$
$$=\:-[t_{k}\:-\:y_{k}]f(y_{ink})\frac{\partial }{\partial w_{jk}}(y_{ink})$$
$$=\:-[t_{k}\:-\:y_{k}]f^{'}(y_{ink})z_{j}$$
现在假设 $\delta_{k}\:=\:-[t_{k}\:-\:y_{k}]f^{'}(y_{ink})$
连接到隐藏单元 zj 的权重可以由以下公式给出 −
$$\frac{\partial E}{\partial v_{ij}}\:=\:- \displaystyle\sum\limits_{k} \delta_{k}\frac{\partial }{\partial v_{ij}}\:(y_{ink})$$
代入 $y_{ink}$ 的值,我们将得到以下结果
$$\delta_{j}\:=\:-\displaystyle\sum\limits_{k}\delta_{k}w_{jk}f^{'}(z_{inj})$$
权重更新可以如下进行 −
对于输出单元 −
$$\Delta w_{jk}\:=\:-\alpha\frac{\partial E}{\partial w_{jk}}$$
$$=\:\alpha\:\delta_{k}\:z_{j}$$
对于隐藏单元 −
$$\Delta v_{ij}\:=\:-\alpha\frac{\partial E}{\partial v_{ij}}$$
$$=\:\alpha\:\delta_{j}\:x_{i}$$