- Python 数据科学教程
- Python 数据科学 - 首页
- Python 数据科学 - 入门
- Python 数据科学 - 环境设置
- Python 数据科学 - Pandas
- Python 数据科学 - Numpy
- Python 数据科学 - SciPy
- Python 数据科学 - Matplotlib
- Python 数据处理
- Python 数据操作
- Python 数据清洗
- Python 处理 CSV 数据
- Python 处理 JSON 数据
- Python 处理 XLS 数据
- Python 关系型数据库
- Python NoSQL 数据库
- Python 日期和时间
- Python 数据整理
- Python 数据聚合
- Python 读取 HTML 页面
- Python 处理非结构化数据
- Python 词语标记化
- Python 词干提取和词形还原
- Python 数据可视化
- Python 图表属性
- Python 图表样式
- Python 箱线图
- Python 热力图
- Python 散点图
- Python 气泡图
- Python 3D 图表
- Python 时间序列
- Python 地理数据
- Python 图数据
Python - 时间序列
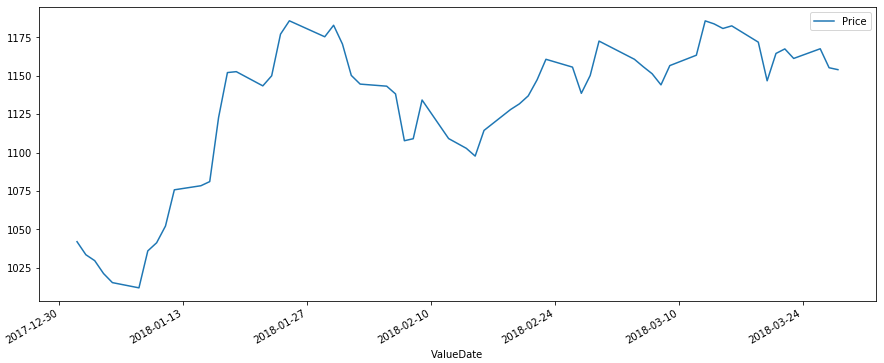
时间序列是一系列数据点,其中每个数据点都与一个时间戳相关联。一个简单的例子是股票市场中某只股票在给定日期的不同时间点的价格。另一个例子是某一地区一年中不同月份的降雨量。
在下面的示例中,我们获取特定股票代码在某一季度每天的股票价格值。我们将这些值捕获为 csv 文件,然后使用 pandas 库将其组织到数据框中。然后,我们通过将额外的 Valuedate 列重新创建为索引并删除旧的 valuedate 列,将日期字段设置为数据框的索引。
示例数据
以下是给定季度不同日期股票价格的示例数据。数据保存在名为 stock.csv 的文件中。
ValueDate Price 01-01-2018, 1042.05 02-01-2018, 1033.55 03-01-2018, 1029.7 04-01-2018, 1021.3 05-01-2018, 1015.4 ... ... ... ... 23-03-2018, 1161.3 26-03-2018, 1167.6 27-03-2018, 1155.25 28-03-2018, 1154
创建时间序列
from datetime import datetime
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('path_to_file/stock.csv')
df = pd.DataFrame(data, columns = ['ValueDate', 'Price'])
# Set the Date as Index
df['ValueDate'] = pd.to_datetime(df['ValueDate'])
df.index = df['ValueDate']
del df['ValueDate']
df.plot(figsize=(15, 6))
plt.show()
其输出如下所示:
广告