- Python XlsxWriter 教程
- Python XlsxWriter - 首页
- Python XlsxWriter - 概述
- Python XlsxWriter - 环境设置
- Python XlsxWriter - Hello World
- Python XlsxWriter - 重要类
- Python XlsxWriter - 单元格表示法和范围
- Python XlsxWriter - 已定义名称
- Python XlsxWriter - 公式和函数
- Python XlsxWriter - 日期和时间
- Python XlsxWriter - 表格
- Python XlsxWriter - 应用筛选
- Python XlsxWriter - 字体和颜色
- Python XlsxWriter - 数字格式
- Python XlsxWriter - 边框
- Python XlsxWriter - 超链接
- Python XlsxWriter - 条件格式
- Python XlsxWriter - 添加图表
- Python XlsxWriter - 图表格式
- Python XlsxWriter - 图表图例
- Python XlsxWriter - 条形图
- Python XlsxWriter - 折线图
- Python XlsxWriter - 饼图
- Python XlsxWriter - 迷你图
- Python XlsxWriter - 数据验证
- Python XlsxWriter - 大纲和分组
- Python XlsxWriter - 冻结和分割窗格
- Python XlsxWriter - 隐藏/保护工作表
- Python XlsxWriter - 文本框
- Python XlsxWriter - 插入图片
- Python XlsxWriter - 页面设置
- Python XlsxWriter - 页眉和页脚
- Python XlsxWriter - 单元格批注
- Python XlsxWriter - 使用 Pandas
- Python XlsxWriter - VBA宏
- Python XlsxWriter 有用资源
- Python XlsxWriter - 快速指南
- Python XlsxWriter - 有用资源
- Python XlsxWriter - 讨论
Python XlsxWriter - 应用筛选
在 Excel 中,您可以使用逻辑表达式根据条件设置表格数据的筛选器。在 XlsxWriter 的工作表类中,我们有autofilter()方法用于此目的。此方法的必填参数是单元格范围。这会在标题行中创建下拉选择器。要应用某些条件,我们有两种方法可用 - filter_column() 或 filter_column_list()。
应用列的筛选条件
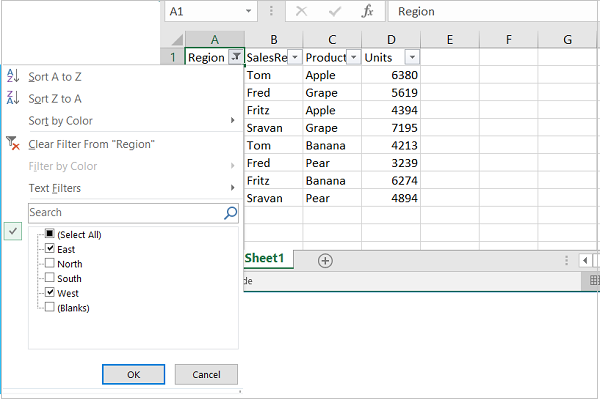
在以下示例中,范围 A1:D51(即单元格 0,0 到 50,3)中的数据用作autofilter()方法的范围参数。筛选条件'Region == East' 使用filter_column()方法设置在第 0 列(带有 Region 标题的列)上。
示例
通过将工作表对象的set_row()方法的隐藏选项设置为 true,隐藏数据范围内不满足筛选条件的所有行。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814]
)
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
ws.filter_column(0, 'Region == East')
row = 1
for row_data in (data):
region = row_data[0]
if region != 'East':
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
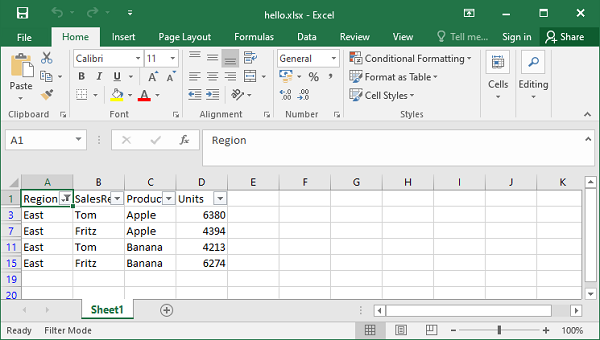
当我们使用 Excel 打开工作表时,我们会发现只有 Region='East' 的行可见,其他行被隐藏(您可以通过清除筛选器再次显示它们)。
列参数可以是零索引列号或字符串列名。Python 中允许的所有逻辑运算符都可以在条件中使用(==, !=, <, >, <=, >=)。筛选条件可以定义在多个列上,并且可以通过and或or运算符组合它们。使用逻辑运算符的条件示例如下:
ws.filter_column('A', 'x > 2000')
ws.filter_column('A', 'x != 2000')
ws.filter_column('A', 'x > 2000 and x<5000')
请注意,条件参数中的“x”只是一个形式占位符,可以是任何合适的字符串,因为它在内部会被忽略。
ws.filter_column('A', 'price > 2000')
ws.filter_column('A', 'x != 2000')
ws.filter_column('A', 'marks > 60 and x<75')
XlsxWriter 还允许在包含字符串数据的列的筛选条件中使用通配符“*”和“?”。
ws.filter_column('A', name=K*') #starts with K
ws.filter_column('A', name=*K*') #contains K
ws.filter_column('A', name=?K*') # second character as K
ws.filter_column('A', name=*K??') #any two characters after K
示例
在以下示例中,对 A 列的第一个筛选器要求区域为 West,第二个筛选器对 D 列的条件为“units > 5000”。不满足条件“region = West”或“units > 5000”的行将被隐藏。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814])
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
ws.filter_column('A', 'x == West')
ws.filter_column('D', 'x > 5000')
row = 1
for row_data in (data[1:]):
region = row_data[0]
volume = int(row_data[3])
if region == 'West' or volume > 5000:
pass
else:
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
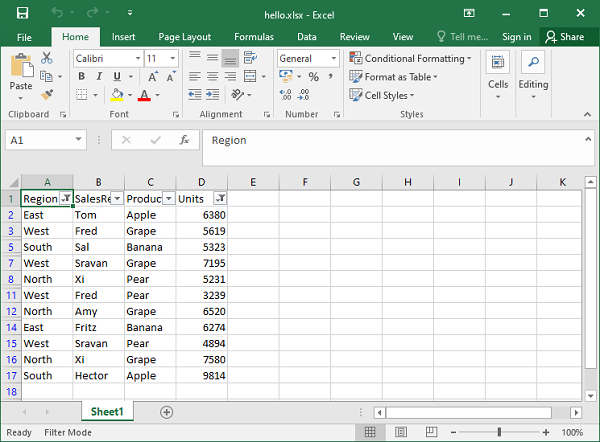
在 Excel 中,可以在 A 列和 D 列标题上看到筛选图标。筛选后的数据如下所示:
应用列列表筛选器
filter_column_list()方法可用于表示 Excel 2007 样式中具有多个所选条件的筛选器。
ws.filter_column_list(col,list)
第二个参数是与给定列中的数据匹配的值列表。例如:
ws.filter_column_list('C', ['March', 'April', 'May'])
它将筛选数据,以便 C 列中的值与列表中的任何项目匹配。
示例
在以下示例中,filter_column_list()方法用于筛选区域等于 East 或 West 的行。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814]
)
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
l1= ['East', 'West']
ws.filter_column_list('A', l1)
row = 1
for row_data in (data[1:]):
region = row_data[0]
if region not in l1:
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
A 列显示已应用自动筛选。显示所有区域为 East 或 West 的行,其余行被隐藏。
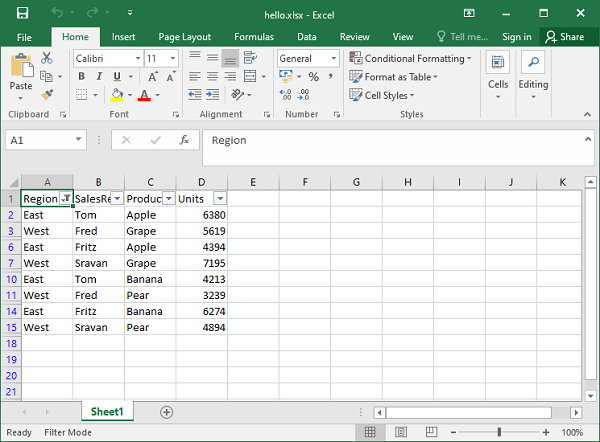
在 Excel 软件中,单击区域标题中的筛选器选择器箭头,我们应该看到已应用区域等于 East 或 West 的筛选器。