- 生成式AI教程
- 生成式AI - 首页
- 生成式AI基础
- 生成式AI基础
- 生成式AI发展史
- 机器学习与生成式AI
- 生成式AI模型
- 判别式模型与生成式模型
- 生成式AI模型类型
- 概率分布
- 概率密度函数
- 最大似然估计
- 生成式AI网络
- GAN的工作原理?
- GAN - 架构
- 条件GAN
- StyleGAN和CycleGAN
- 训练GAN
- GAN应用
- 生成式AI Transformer
- 生成式AI中的Transformer
- 生成式AI中Transformer的架构
- Transformer中的输入嵌入
- 多头注意力机制
- 位置编码
- 前馈神经网络
- Transformer中的残差连接
- 生成式AI自编码器
- 生成式AI中的自编码器
- 自编码器类型及应用
- 使用Python实现自编码器
- 变分自编码器
- 生成式AI与ChatGPT
- 一个生成式AI模型
- 生成式AI杂项
- 生成式AI在制造业中的应用
- 生成式AI为开发者
- 生成式AI在网络安全中的应用
- 生成式AI在软件测试中的应用
- 生成式AI在市场营销中的应用
- 生成式AI在教育领域的应用
- 生成式AI在医疗保健领域的应用
- 生成式AI为学生
- 生成式AI在工业领域的应用
- 生成式AI在电影领域的应用
- 生成式AI在音乐领域的应用
- 生成式AI在烹饪领域的应用
- 生成式AI在媒体领域的应用
- 生成式AI在通信领域的应用
- 生成式AI在摄影领域的应用
- 生成式AI资源
- 生成式AI - 有用资源
- 生成式AI - 讨论
生成式AI中的Transformer架构
基于Transformer的大型语言模型(LLM)在情感分析、机器翻译、文本摘要等各种任务中都优于之前的循环神经网络(RNN)。
Transformer的独特能力源于其架构。本章将用简单的术语解释原始Transformer模型的主要思想,以便更容易理解。
我们将重点关注构成Transformer的关键组件:**编码器**、**解码器**以及连接它们的独特**注意力机制**。
Transformer在生成式AI中如何工作?
让我们了解Transformer的工作原理:
- 首先,当我们向Transformer提供一个句子时,它会特别关注句子中重要的词语。
- 然后,它同时考虑所有单词,而不是一个接一个地考虑,这有助于Transformer找到句子中单词之间的依赖关系。
- 之后,它找到句子中单词之间的关系。例如,假设一个句子是关于恒星和星系的,那么它就知道这些词语是相关的。
- 完成之后,Transformer利用这些知识来理解完整的故事以及单词之间是如何连接的。
- 有了这种理解,Transformer甚至可以预测下一个词可能是什么。
生成式AI中的Transformer架构
Transformer有两个主要组成部分:**编码器**和**解码器**。以下是Transformer的简化架构:
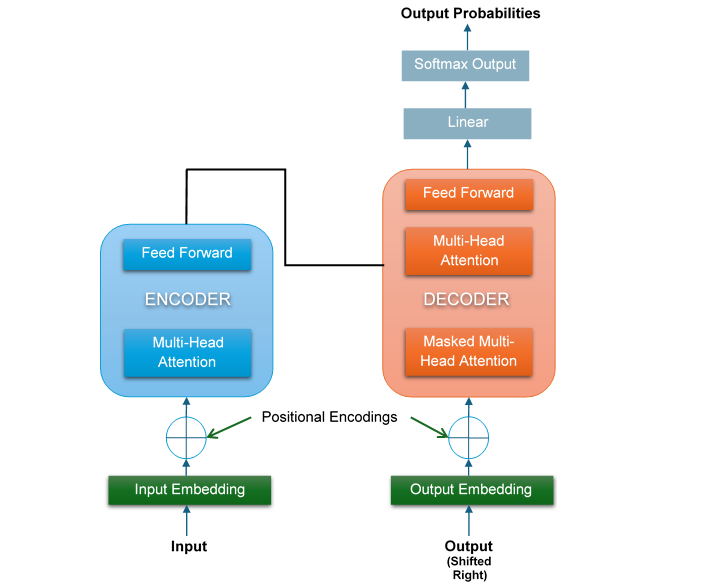
如图所示,在Transformer的左侧,输入进入编码器。输入首先被转换为输入嵌入,然后经过注意力子层和前馈网络(FFN)子层。类似地,在右侧,目标输出进入解码器。
输出也首先被转换为输出嵌入,然后经过两个注意力子层和一个前馈网络(FFN)子层。在这个架构中,没有RNN、LSTM或CNN。递归也被抛弃,并被注意力机制取代。
让我们详细讨论Transformer的两个主要组成部分,即编码器和解码器。
Transformer编码器堆栈的一层
在Transformer中,编码器处理输入序列并将其分解成一些有意义的表示。Transformer模型编码器的层是**层堆栈**,其中每个编码器堆栈层具有以下结构:
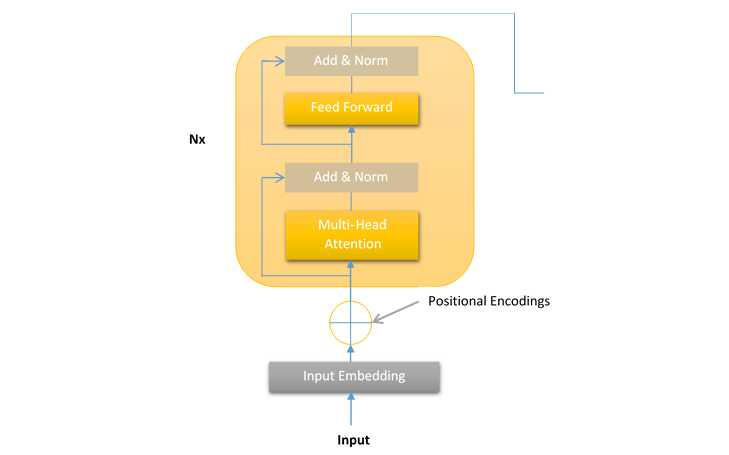
这种编码器层的结构对于Transformer模型的所有层都是相同的。每个编码器堆栈层包含以下两个子层:
- 多头注意力机制
- 前馈网络(FFN)
正如我们在上图中看到的,在两个子层(即多头注意力机制和前馈网络)周围都有一个残差连接。这些残差连接的作用是将子层的未经处理的输入**x**发送到层归一化函数。
这样,每一层的归一化输出就可以计算如下:
层归一化(x + 子层(x))
我们将在后续章节中详细讨论子层(即多头注意力和FNN)、输入嵌入、位置编码、归一化和残差连接。
Transformer解码器堆栈的一层
在Transformer中,解码器接收编码器生成的表示并对其进行处理以生成输出序列。这就像翻译或文本续写。与编码器一样,Transformer模型解码器的层也是**层堆栈**,其中每个解码器堆栈层具有以下结构:
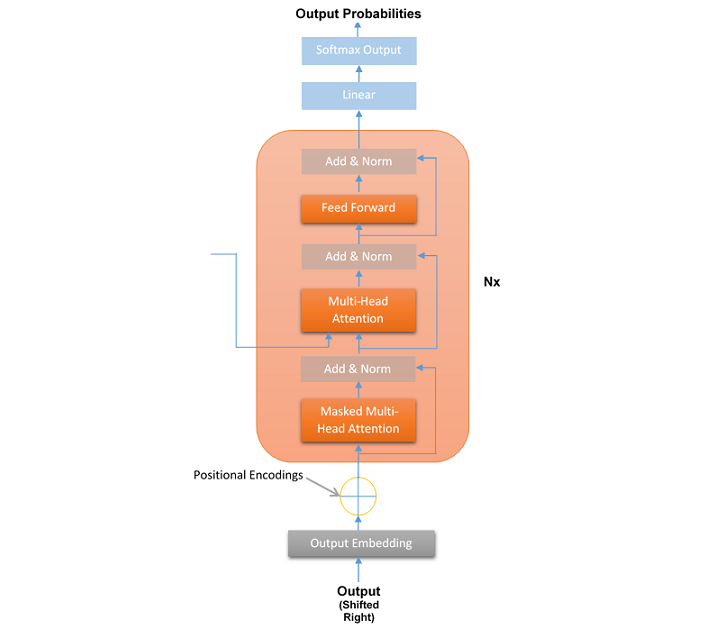
与编码器层一样,解码器层的结构对于Transformer模型的所有N=6层都是相同的。每个解码器堆栈层包含以下三个子层:
- 掩码多头注意力机制
- 多头注意力机制
- 前馈网络(FFN)
与编码器相反,解码器有一个第三个子层称为掩码多头注意力,其中,在给定位置,后续的词语会被掩码。这个子层的优点是Transformer根据其推断进行预测,而无需查看整个序列。
与编码器一样,所有子层周围都有一个残差连接,并且每一层的归一化输出可以计算如下:
层归一化(x + 子层(x))
正如我们在上图中看到的,在所有解码器块之后还有一个最终的线性层。这个线性层的作用是将数据映射到所需的输出词汇量大小。然后将softmax函数应用于映射后的数据,以生成目标词汇量的概率分布。这将产生最终的输出序列。
结论
本章详细解释了生成式AI中Transformer的架构。我们主要关注它的两个主要部分:编码器和解码器。
编码器的作用是通过查看所有单词之间的关系来理解输入序列。它使用自注意力和前馈层来创建输入的详细表示。
解码器接收输入的详细表示并生成输出序列。它使用掩码自注意力来确保按正确的顺序生成序列,并利用编码器-解码器注意力来整合来自编码器的信息。
通过探索编码器和解码器的工作方式,我们看到了Transformer如何从根本上改变了自然语言处理(NLP)领域。正是编码器和解码器的结构使得Transformer在各个行业如此强大和有效,并改变了我们与AI系统交互的方式。