- 生成式AI教程
- 生成式AI - 首页
- 生成式AI基础
- 生成式AI基础
- 生成式AI发展历程
- 机器学习与生成式AI
- 生成式AI模型
- 判别式模型与生成式模型
- 生成式AI模型的类型
- 概率分布
- 概率密度函数
- 最大似然估计
- 生成式AI网络
- GAN的工作原理?
- GAN - 架构
- 条件GAN
- StyleGAN和CycleGAN
- 训练GAN
- GAN应用
- 生成式AI Transformer
- 生成式AI中的Transformer
- 生成式AI中Transformer的架构
- Transformer中的输入嵌入
- 多头注意力机制
- 位置编码
- 前馈神经网络
- Transformer中的残差连接
- 生成式AI自编码器
- 生成式AI中的自编码器
- 自编码器的类型和应用
- 使用Python实现自编码器
- 变分自编码器
- 生成式AI与ChatGPT
- 一个生成式AI模型
- 生成式AI杂项
- 生成式AI在制造业中的应用
- 生成式AI为开发者
- 生成式AI在网络安全中的应用
- 生成式AI在软件测试中的应用
- 生成式AI在市场营销中的应用
- 生成式AI在教育领域的应用
- 生成式AI在医疗保健领域的应用
- 生成式AI为学生
- 生成式AI在工业领域的应用
- 生成式AI在电影制作中的应用
- 生成式AI在音乐创作中的应用
- 生成式AI在烹饪领域的应用
- 生成式AI在媒体领域的应用
- 生成式AI在通信领域的应用
- 生成式AI在摄影领域的应用
- 生成式AI资源
- 生成式AI - 有用资源
- 生成式AI - 讨论
Transformer中的前馈神经网络
Transformer模型已经改变了自然语言处理(NLP)以及其他基于序列的任务领域。正如我们在前面的章节中讨论的那样,Transformer主要依赖于多头注意力和自注意力机制,但还有一个关键组件同样有助于该模型的成功。这个关键组件就是前馈神经网络 (FFNN)。
FFNN 子层帮助 Transformer 捕获输入数据序列中的复杂模式和关系。阅读本章以了解 FFNN 子层、其在 Transformer 中的作用以及如何使用 Python 编程语言在 Transformer 架构中实现 FFNN。
前馈神经网络 (FFNN) 子层
在 Transformer 架构中,FFNN 子层位于多头注意力子层之上。它的输入是前一层后层归一化的输出 $\mathrm{d_{model} \: = \: 512}$。FFNN 是 Transformer 的一个简单但功能强大的组件,它独立地对序列的每个位置进行操作。
在下图中,它是 Transformer 架构的编码器堆栈,您可以看到 FFNN 子层的位置(用黑圈突出显示)−
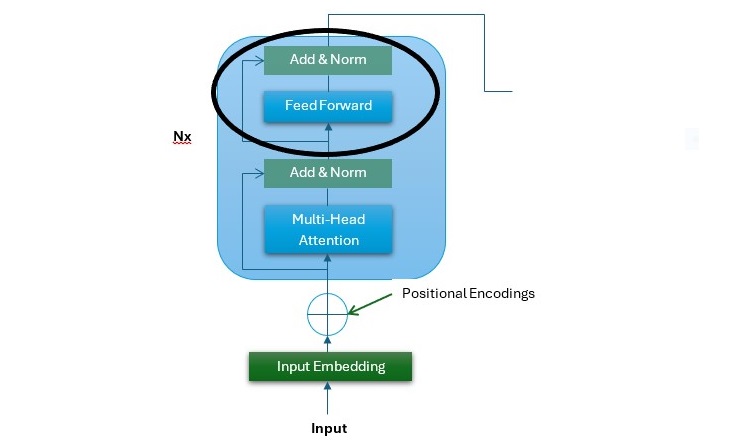
以下几点描述了 FFNN 子层 −
- Transformer 编码器和解码器中的 FFNN 子层是全连接的。
- FFNN 是一个位置感知网络,其中每个位置都被单独处理,但方式相似。
- FFNN 包含两个线性变换,并在它们之间应用激活函数。最常见的激活函数之一是 ReLU。
- FFNN 子层的输入和输出都是 $\mathrm{d_{model} \: = \: 512}$。
- 与输入和输出层相比,FFNN 子层的内部层更大,为 $\mathrm{d_{ff} \: = \: 2048}$。
FFNN 子层的数学表示
FFNN 子层可以用如下数学公式表示 −
第一次线性变换
$$\mathrm{X_{1} \: = \: XW_{1} \: + \: b_{1}}$$
这里,X 是 FFNN 子层的输入。$\mathrm{W_{1}}$ 是第一次线性变换的权重矩阵,$\mathrm{b_{1}}$ 是偏差向量。
ReLU 激活函数
ReLU 激活函数通过在网络中引入非线性来使网络能够学习复杂的模式。
$$\mathrm{X_{2} \: = \: max(0, X_{1})}$$
第二次线性变换
$$\mathrm{Output \: = \: X_{2}W_{2} \: + \: b_{2}}$$
这里,$\mathrm{W_{2}}$ 是第二次线性变换的权重矩阵,$\mathrm{b_{2}}$ 是偏差向量。
让我们结合以上步骤来总结 FFNN 子层 −
$$\mathrm{Output \: = \: max(0, XW_{1} \: + \: b_{1})W_{2} \: + \: b_{2}}$$
FFNN 子层在 Transformer 中的重要性
以下是 FFNN 子层在 Transformer 中的作用和重要性 −
特征变换
FFNN 子层对输入数据序列执行复杂的变换。借助它,模型可以从数据序列中学习详细和高级的特征。
位置独立性
正如我们在上一章中讨论的那样,自注意力机制检查输入数据序列中各个位置之间的关系。但是,另一方面,FFNN 子层独立地作用于输入数据序列中的每个位置。此功能增强了多头注意力子层生成的表示。
前馈神经网络的 Python 实现
下面是一个分步的 Python 实现指南,演示了如何在 Transformer 架构中实现前馈神经网络子层 −
步骤 1:初始化 FFNN 参数
在 Transformer 架构中,FFNN 子层由两个线性变换以及它们之间的 ReLU 激活函数组成。在此步骤中,我们将初始化这些变换的权重矩阵和偏差向量 −
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
步骤 2:创建示例输入数据
在此步骤中,我们将创建一些示例输入数据以通过我们的 FFNN。在 Transformer 架构中,输入通常是形状为 (batch_size, seq_len, d_model) 的张量。
# Example input dimensions batch_size = 64 # Number of sequences in a batch seq_len = 10 # Length of each sequence d_model = 512 # Dimensionality of the model (input/output dimension) # Random input tensor with shape (batch_size, seq_len, d_model) x = np.random.rand(batch_size, seq_len, d_model)
步骤 3:实例化和使用 FFNN
最后,我们将实例化 'FeedForwardNN' 类并使用上述示例输入张量执行前向传递 −
# Create FFNN instance
ffnn = FeedForwardNN(d_model, d_ff=2048) # Set d_ff as desired dimensionality for inner layer
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
完整的实现示例
将上述三个步骤组合起来以获得完整的实现示例 −
# Step 1 - Initializing Parameters for FFNN
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
# Step 2 - Creating Example Input Data
# Example input dimensions
batch_size = 64 # Number of sequences in a batch
seq_len = 10 # Length of each sequence
d_model = 512 # Dimensionality of the model (input/output dimension)
# Random input tensor with shape (batch_size, seq_len, d_model)
x = np.random.rand(batch_size, seq_len, d_model)
# Step 3 - Instantiating and Using the FFNN
# Create FFNN instance
# Set d_ff as desired dimensionality for inner layer
ffnn = FeedForwardNN(d_model, d_ff=2048)
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
输出
运行上述脚本后,它应该打印输出张量的形状以验证计算 −
Output shape: (64, 10, 512)
结论
前馈神经网络 (FFNN) 子层是 Transformer 架构中的一个重要组成部分。它增强了模型捕获输入数据序列中复杂模式和关系的能力。
FFNN 通过独立应用逐位置变换来补充自注意力机制。这使得 Transformer 成为用于自然语言处理和其他基于序列的任务的强大模型。
在本章中,我们全面概述了 FFNN 子层、其在 Transformer 中的作用和重要性,以及逐步指导说明如何在 Transformer 中实现 FFNN 的 Python 实现。与多头注意力机制一样,了解和使用 FFNN 对于充分利用 NLP 应用中的 Transformer 模型也很重要。