- 生成式 AI 教程
- 生成式 AI - 首页
- 生成式 AI 基础
- 生成式 AI 基础
- 生成式 AI 演变
- 机器学习和生成式 AI
- 生成式 AI 模型
- 判别式模型与生成式模型
- 生成式 AI 模型类型
- 概率分布
- 概率密度函数
- 最大似然估计
- 生成式 AI 网络
- GAN 是如何工作的?
- GAN - 架构
- 条件 GAN
- StyleGAN 和 CycleGAN
- 训练 GAN
- GAN 应用
- 生成式 AI Transformer
- Transformer 在生成式 AI 中的应用
- Transformer 在生成式 AI 中的架构
- Transformer 中的输入嵌入
- 多头注意力机制
- 位置编码
- 前馈神经网络
- Transformer 中的残差连接
- 生成式 AI 自编码器
- 自编码器在生成式 AI 中的应用
- 自编码器类型及应用
- 使用 Python 实现自编码器
- 变分自编码器
- 生成式 AI 和 ChatGPT
- 一个生成式 AI 模型
- 生成式 AI 杂项
- 生成式 AI 在制造业中的应用
- 生成式 AI 为开发者
- 生成式 AI 用于网络安全
- 生成式 AI 用于软件测试
- 生成式 AI 用于营销
- 生成式 AI 用于教育工作者
- 生成式 AI 用于医疗保健
- 生成式 AI 用于学生
- 生成式 AI 用于行业
- 生成式 AI 用于电影
- 生成式 AI 用于音乐
- 生成式 AI 用于烹饪
- 生成式 AI 用于媒体
- 生成式 AI 用于通信
- 生成式 AI 用于摄影
- 生成式 AI 资源
- 生成式 AI - 有用资源
- 生成式 AI - 讨论
生成对抗网络 (GAN) 是如何工作的?
生成对抗网络 (GAN) 是一种强大的生成建模方法。GAN 基于深度神经网络架构,可以生成看起来像原始训练数据的新复杂输出。
GAN 通常利用卷积神经网络 (CNN) 等架构。事实上,像 ChatGPT 一样,其他基于深度学习的大型语言模型 (LLM) 都是 GAN 的一个显著应用。本章涵盖了您需要了解的有关 GAN 及其工作原理的所有内容。
什么是生成对抗网络?
生成对抗网络 (GAN) 是一种用于无监督学习的人工智能框架。GAN 由两个神经网络组成:一个**生成器**和一个**判别器**。GAN 使用对抗训练来生成类似于实际数据的合成数据。
GAN 可以分为**三个组成部分** -
- **生成** - 该组件专注于通过理解数据集中的潜在模式来学习如何生成新数据。
- **对抗** - 简单来说,“对抗”意味着将两件事置于对立面。在 GAN 中,生成的数据与来自数据集的真实数据进行比较。这是使用一个训练有素的模型来区分真实数据和虚假数据完成的。此模型称为判别器。
- **网络** - 为了实现学习过程,GAN 使用深度神经网络。
在深入了解 GAN 的工作原理之前,让我们首先讨论其两个主要部分:生成器模型和判别器模型。
生成器模型
生成器模型的目标是生成新的数据样本,这些样本旨在类似于来自数据集的真实数据。
- 它将随机输入数据作为输入,并将其转换为合成数据样本。
- 转换后,生成器的另一个目标是在呈现给判别器时生成与真实数据相同的数据。
- 生成器实现为神经网络模型。根据生成的数据类型,它使用全连接层(如 Dense)或卷积层。
判别器模型
判别器模型的目标是评估输入数据并试图区分来自数据集的真实数据样本和生成器模型生成的虚假数据样本。
- 它接收输入数据并预测它是真实的还是虚假的。
- 判别器模型的另一个目标是正确地将输入数据的来源分类为真实或虚假。
- 与生成器模型类似,判别器模型也实现为神经网络模型。它也使用 Dense 或卷积层。
在 GAN 的训练过程中,生成器和判别器都同时进行训练,但方式相反,即相互竞争。
GAN 是如何工作的?
要了解 GAN 的工作原理,首先请查看此图表,该图表显示了 GAN 的不同组件如何发挥作用以生成与真实数据非常相似的新数据样本 -
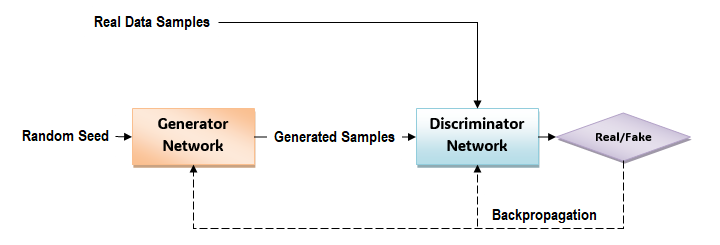
GAN 有两个主要组件:一个**生成器网络**和一个**判别器网络**。下面是 GAN 工作原理中涉及的步骤 -
初始化
GAN 由两个神经网络组成:生成器(假设为**G**)和判别器(假设为**D**)。
- 生成器的目标是生成新的数据样本(如图像或文本),这些样本与来自数据集的真实数据非常相似。
- 判别器扮演评论家的角色,其目标是区分真实数据和生成器生成的数据。
训练循环
训练循环包括交替训练生成器和判别器。
训练判别器
在训练判别器时,对于每次迭代 -
- 首先,从数据集中选择一批真实数据样本。
- 接下来,使用当前的生成器生成一批虚假数据样本。
- 生成后,在真实数据和虚假数据样本上训练判别器。
- 最后,判别器通过调整其权重以最小化其分类误差来学习区分真实数据和虚假数据。
训练生成器
在训练生成器时,对于每次迭代 -
- 首先,使用生成器生成一批虚假数据样本。
- 接下来,训练生成器以生成判别器分类为真实数据的虚假数据。为此,我们需要将虚假数据通过判别器,并根据判别器的分类误差更新生成器的权重。
- 最后,生成器将通过调整其权重以最大化判别器在对生成的样本进行分类时的误差来学习生成更逼真的虚假数据。
对抗训练
随着训练的进行,生成器和判别器都以对抗的方式提高其性能,即相互对立。
生成器在创建类似于真实数据的虚假数据方面变得更好,而判别器在区分真实数据和虚假数据方面变得更好。
借助生成器和判别器之间这种对抗关系,这两个网络都尝试持续改进,直到生成器生成与真实数据相同的数据。
评估
训练完成后,生成器可用于生成类似于来自数据集的真实数据的新数据样本。
我们可以通过目视检查样本或使用定量度量(如相似度得分或分类器准确率)来评估生成数据的质量。
微调和优化
根据应用,您可以微调训练好的 GAN 模型以提高其性能或将其适应特定任务或数据集。
结论
生成对抗网络 (GAN) 是最突出和最广泛使用的生成模型之一。在本章中,我们解释了 GAN 的基础知识以及它如何使用神经网络生成类似于实际数据的合成数据。
GAN 工作原理中涉及的步骤包括:初始化、训练循环、训练判别器、训练生成器、对抗训练、评估以及微调和优化。