- 生成式AI教程
- 生成式AI - 首页
- 生成式AI基础
- 生成式AI基础
- 生成式AI发展历程
- 机器学习与生成式AI
- 生成式AI模型
- 判别式模型与生成式模型
- 生成式AI模型类型
- 概率分布
- 概率密度函数
- 最大似然估计
- 生成式AI网络
- GAN的工作原理?
- GAN - 架构
- 条件GAN
- StyleGAN和CycleGAN
- 训练GAN
- GAN应用
- 生成式AI Transformer
- Transformer在生成式AI中的应用
- Transformer在生成式AI中的架构
- Transformer中的输入嵌入
- 多头注意力机制
- 位置编码
- 前馈神经网络
- Transformer中的残差连接
- 生成式AI自编码器
- 自编码器在生成式AI中的应用
- 自编码器类型及应用
- 使用Python实现自编码器
- 变分自编码器
- 生成式AI和ChatGPT
- 一个生成式AI模型
- 生成式AI杂项
- 生成式AI在制造业中的应用
- 生成式AI在开发人员中的应用
- 生成式AI在网络安全中的应用
- 生成式AI在软件测试中的应用
- 生成式AI在市场营销中的应用
- 生成式AI在教育领域的应用
- 生成式AI在医疗保健领域的应用
- 生成式AI在学生中的应用
- 生成式AI在工业中的应用
- 生成式AI在电影领域的应用
- 生成式AI在音乐领域的应用
- 生成式AI在烹饪领域的应用
- 生成式AI在媒体领域的应用
- 生成式AI在通信领域的应用
- 生成式AI在摄影领域的应用
- 生成式AI资源
- 生成式AI - 有用资源
- 生成式AI - 讨论
Transformer中的多头注意力机制
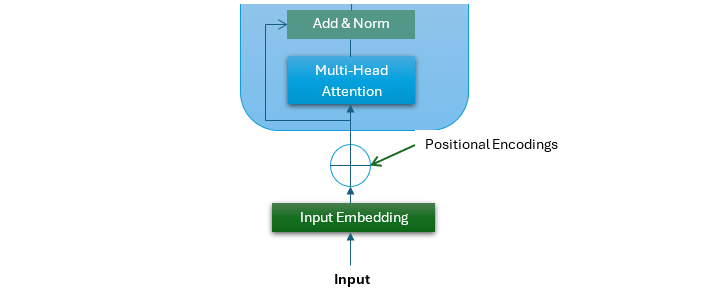
位置编码是Transformer架构中一个至关重要的组成部分。位置编码的输出进入Transformer架构的第一个子层。这个子层是一个多头注意力机制。
多头注意力机制是Transformer模型的一个关键特性,它帮助模型更有效地处理顺序数据。它允许模型同时查看输入序列的不同部分。
在本章中,我们将探讨多头注意力机制的结构、优点和Python实现。
什么是自注意力机制?
自注意力机制,也称为缩放点积注意力,是基于Transformer的模型的一个重要组成部分。它允许模型关注输入序列中彼此相关的不同标记。这是通过计算输入值的加权和来实现的。这里的权重基于标记之间的相似性。
自注意力机制
以下是自注意力机制涉及的步骤:
- 创建查询、键和值 - 自注意力机制将输入序列中的每个标记转换为三个向量,即查询 (Q)、键 (K) 和值 (V)。
- 计算注意力分数 - 接下来,自注意力机制通过获取查询 (Q) 和键 (K) 矩阵的点积来计算注意力分数。注意力分数显示每个单词对当前正在处理的单词的重要性。
- 应用Softmax函数 - 在此步骤中,应用Softmax函数将这些注意力分数转换为概率,这确保注意力权重之和为1。
- 值的加权和 - 在最后一步中,使用Softmax注意力分数来计算值向量的加权和以产生输出。
在数学上,自注意力机制可以用以下等式概括:
$$\mathrm{Self-Attention(Q,K,V) \: = \: softmax \left(\frac{QK^{T}}{\sqrt{d_{k}}}\right)V}$$
什么是多头注意力?
多头注意力扩展了自注意力机制的概念,允许模型同时关注输入序列的不同部分。多头注意力不是运行单个注意力函数,而是并行运行多个自注意力机制或“头”。这种方法使模型能够更好地理解输入序列中的各种关系和依赖关系。
请查看下图,它是原始Transformer架构的一部分。它代表了多头子层的结构。
多头注意力的步骤
以下是多头注意力机制中涉及的关键步骤:
- 应用多个头 - 首先,输入嵌入被线性投影到多个查询 (Q)、键 (K) 和值 (V) 矩阵集中(每个头一个集合)。
- 执行并行自注意力 - 接下来,每个头在其各自的投影上并行执行自注意力机制。
- 连接 - 现在,所有头的输出被连接起来。
- 组合信息 - 在最后一步中,组合来自所有头的信息。这是通过将连接的输出传递到最终的线性层来完成的。
在数学上,多头注意力机制可以用以下等式概括:
$$\mathrm{MultiHead(Q,K,V) \: = \: Concat(head_{1}, \: \dotso \: ,head_{h})W^{\circ}}$$
其中每个头计算如下:
$$\mathrm{head_{i}\:=\: Attention(QW_{i}^{Q}, \: KW_{i}^{K}, \: VW_{i}^{V} )\:=\: softmax\left(\frac{QW_{i}^{Q} (KW_{i}^{K})^{T}}{\sqrt{d_{k}}}\right)VW_{i}^{V}}$$
多头注意力的优点
增强的表示 - 通过同时关注输入序列的不同部分,多头注意力使模型能够更好地理解输入序列中的各种关系和依赖关系。
并行处理 - 通过启用并行处理,与RNN等顺序模型相比,多头注意力机制显着提高了模型训练效率。
示例
以下Python脚本将实现多头注意力机制。
import numpy as np
class MultiHeadAttention:
def __init__(self, d_model, num_heads):
self.d_model = d_model
self.num_heads = num_heads
assert d_model % num_heads == 0
self.depth = d_model // num_heads
# Initializing weight matrices for queries, keys, and values
self.W_q = np.random.randn(d_model, d_model) * np.sqrt(2 / d_model)
self.W_k = np.random.randn(d_model, d_model) * np.sqrt(2 / d_model)
self.W_v = np.random.randn(d_model, d_model) * np.sqrt(2 / d_model)
# Initializing weight matrix for output
self.W_o = np.random.randn(d_model, d_model) * np.sqrt(2 / d_model)
def split_heads(self, x, batch_size):
"""
Split the last dimension into (num_heads, depth).
Transpose the result to shape (batch_size, num_heads, seq_len, depth)
"""
x = np.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return np.transpose(x, (0, 2, 1, 3))
def scaled_dot_product_attention(self, q, k, v):
"""
Compute scaled dot product attention.
"""
matmul_qk = np.matmul(q, k)
scaled_attention_logits = matmul_qk / np.sqrt(self.depth)
scaled_attention_logits -= np.max(scaled_attention_logits, axis=-1, keepdims=True)
attention_weights = np.exp(scaled_attention_logits)
attention_weights /= np.sum(attention_weights, axis=-1, keepdims=True)
output = np.matmul(attention_weights, v)
return output, attention_weights
def call(self, inputs):
q, k, v = inputs
batch_size = q.shape[0]
# The Linear transformations
q = np.dot(q, self.W_q)
k = np.dot(k, self.W_k)
v = np.dot(v, self.W_v)
# Split heads
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
# The Scaled dot-product attention
attention_output, attention_weights = self.scaled_dot_product_attention(q, k.transpose(0, 1, 3, 2), v)
# Combining heads
attention_output = np.transpose(attention_output, (0, 2, 1, 3))
concat_attention = np.reshape(attention_output, (batch_size, -1, self.d_model))
# Linear transformation for output
output = np.dot(concat_attention, self.W_o)
return output, attention_weights
# An Example usage
d_model = 512
num_heads = 8
batch_size = 2
seq_len = 10
# Creating an instance of MultiHeadAttention
multi_head_attn = MultiHeadAttention(d_model, num_heads)
# Example input (batch_size, sequence_length, embedding_dim)
Q = np.random.randn(batch_size, seq_len, d_model)
K = np.random.randn(batch_size, seq_len, d_model)
V = np.random.randn(batch_size, seq_len, d_model)
# Performing multi-head attention
output, attention_weights = multi_head_attn.call([Q, K, V])
print("Input Query (Q):\n", Q)
print("Multi-Head Attention Output:\n", output)
输出
实现上述脚本后,我们将得到以下输出。
Input Query (Q): [[[ 1.38223113 -0.41160481 1.00938637 ... -0.23466982 -0.20555623 0.80305284] [ 0.64676968 -0.83592083 2.45028238 ... -0.1884722 -0.25315478 0.18875416] [-0.52094419 -0.03697595 -0.61598294 ... 1.25611974 -0.35473911 0.15091853] ... [ 1.15939786 -0.5304271 -0.45396363 ... 0.8034571 0.66646109 -1.28586743] [ 0.6622964 -0.62871864 0.61371113 ... -0.59802729 -0.66135327 -0.24437055] [ 0.83111283 -0.81060387 -0.30858598 ... -0.74773536 -1.3032037 3.06236077]] [[-0.88579467 -0.15480352 0.76149486 ... -0.5033709 1.20498808 -0.55297549] [-1.11233207 0.7560376 -1.41004173 ... -2.12395203 2.15102493 0.09244935] [ 0.33003584 1.67364745 -0.30474183 ... 1.65907682 -0.61370707 0.58373516] ... [-2.07447136 -1.04964997 -0.15290381 ... -0.19912739 -1.02747937 0.20710549] [ 0.38910395 -1.04861089 -1.66583867 ... 0.21530474 -1.45005951 0.04472527] [-0.4718725 -0.45374148 -0.59990784 ... -1.9545574 0.11470969 1.03736175]]] Multi-Head Attention Output: [[[ 0.36106079 -2.04297889 0.34937837 ... 0.11306262 0.53263072 -1.32641213] [ 1.09494311 -0.56658386 0.24210239 ... 1.1671274 -0.02322074 0.90110388] [ 0.45854972 -0.54493138 -0.63421376 ... 1.12479291 0.02585155 -0.08487499] ... [ 0.18252303 -0.17292067 0.46922657 ... -0.41311278 -1.17954406 -0.17005412] [-0.7849032 -2.12371221 -0.80403028 ... -2.35884088 0.15292393 -0.05569091] [ 1.07844261 0.18249226 0.81735183 ... 1.16346645 -1.71611237 -1.09860234]] [[ 0.58842816 -0.04493786 -1.72007093 ... -2.37506208 -1.83098896 2.84016717] [ 0.36608434 0.11709812 0.79108595 ... -1.6308595 -0.96052828 0.40893208] [-1.42113667 0.67459219 -0.8731377 ... -1.47390056 -0.42947079 1.04828361] ... [ 1.14151388 -1.5437165 -1.23405718 ... 0.29237056 0.56595327 -0.19385628] [-2.33028535 0.7245296 1.01725021 ... -0.9380485 -1.78988485 0.9938851 ] [-0.88115094 3.03051907 0.39447342 ... -1.89168756 0.94973626 0.61657539] ]]
结论
多头注意力子层是Transformer架构的关键组成部分。它通过允许模型同时查看输入序列的不同部分来帮助模型更有效地处理顺序数据。
在本章中,我们全面概述了多头注意力机制、其优点以及如何使用Python实现它。