- 生成式AI教程
- 生成式AI - 首页
- 生成式AI基础
- 生成式AI基础
- 生成式AI发展
- 机器学习与生成式AI
- 生成式AI模型
- 判别式模型与生成式模型
- 生成式AI模型类型
- 概率分布
- 概率密度函数
- 最大似然估计
- 生成式AI网络
- GAN的工作原理?
- GAN - 架构
- 条件GAN
- StyleGAN和CycleGAN
- 训练GAN
- GAN应用
- 生成式AI Transformer
- 生成式AI中的Transformer
- 生成式AI中Transformer的架构
- Transformer中的输入嵌入
- 多头注意力机制
- 位置编码
- 前馈神经网络
- Transformer中的残差连接
- 生成式AI自编码器
- 生成式AI中的自编码器
- 自编码器类型及应用
- 使用Python实现自编码器
- 变分自编码器
- 生成式AI和ChatGPT
- 一个生成式AI模型
- 生成式AI杂项
- 生成式AI在制造业中的应用
- 生成式AI为开发者赋能
- 生成式AI在网络安全中的应用
- 生成式AI在软件测试中的应用
- 生成式AI在营销中的应用
- 生成式AI在教育中的应用
- 生成式AI在医疗保健中的应用
- 生成式AI为学生赋能
- 生成式AI在工业中的应用
- 生成式AI在电影制作中的应用
- 生成式AI在音乐创作中的应用
- 生成式AI在烹饪中的应用
- 生成式AI在媒体中的应用
- 生成式AI在通信中的应用
- 生成式AI在摄影中的应用
- 生成式AI资源
- 生成式AI - 有用资源
- 生成式AI - 讨论
判别式模型与生成式模型
人类思维启发了机器学习 (ML) 和深度学习 (DL) 技术,即我们如何从经验中学习,以便在现在和将来做出更好的选择。这些技术是研究中最具活力和不断变化的领域,虽然我们已经在许多方面使用它们,但可能性是无限的。
这些进步使机器能够从过去的数据中学习,甚至可以从未见过的数据输入中进行预测。为了从原始数据中提取有意义的见解,机器依赖于数学、模型/算法和数据处理方法。我们可以通过两种方式提高机器效率;一种是增加数据量,另一种是开发新的、更强大的算法。
获取新的数据很容易,因为每天都会生成数万亿字节的数据。但是要处理如此庞大的数据,我们需要构建新的模型/算法或扩展现有模型/算法。数学是这些模型/算法的支柱,这些模型/算法可以大致分为两类,即判别式模型和生成式模型。
在本章中,我们将研究判别式和生成式机器学习模型,以及它们之间的核心区别。
什么是判别式模型?
判别式模型是机器学习模型,顾名思义,它专注于使用概率估计和最大似然法对几类数据的决策边界进行建模。这些主要用于监督学习的模型也被称为条件模型。
判别式模型受异常值的影响不大。尽管这使它们比生成式模型更好,但也导致了误分类问题,这可能是一个很大的缺点。
从数学角度来看,训练分类器的过程包括估计:
- 表示为f : X → Y 的函数,或
- 概率P(Y│X)。
然而,判别式分类器:
- 假设概率P(Y|X)的特定函数形式,以及
- 直接从训练数据集中估计概率P(Y|X)的参数。
流行的判别式模型
下面讨论了一些广泛使用的判别式模型的示例:
逻辑回归
逻辑回归是一种用于二元分类任务的统计技术。它使用逻辑函数对因变量和一个或多个自变量之间的关系进行建模。它产生0到1之间的输出。
逻辑回归可用于各种分类问题,如癌症检测、糖尿病预测、垃圾邮件检测等。
支持向量机
支持向量机 (SVM) 是一种强大而灵活的监督式机器学习算法,可应用于回归和分类场景。支持向量使用决策边界将n维数据空间划分为多个类别。
K近邻 (KNN)
KNN 是一种监督式机器学习算法,它使用特征相似性来预测新数据点的值。分配给新数据点的值取决于它们与训练集中的点的匹配程度。
决策树、神经网络、条件随机场 (CRF)、随机森林是其他一些常用的判别式模型的例子。
什么是生成式模型?
生成式模型是机器学习模型,顾名思义,其目标是捕捉数据的潜在分布,并生成与原始训练数据相媲美的新数据。这些主要用于无监督学习的模型被归类为能够生成新的数据实例的一类统计模型。
与判别式模型相比,生成式模型唯一的缺点是它们容易受到异常值的影响。
如上所述,从数学角度来看,训练分类器包括估计:
- 表示为f : X → Y 的函数,或
- 概率P(Y│X)。
然而,生成式分类器:
- 假设概率的特定函数形式,例如P(Y), P(X|Y)
- 直接从训练数据集中估计概率的参数,例如P(X│Y), P(Y)。
- 使用贝叶斯定理计算后验概率P(Y|X)。
流行的生成式模型
下面重点介绍一些广泛使用的生成式模型的示例:
贝叶斯网络
贝叶斯网络,也称为贝叶斯网络,是一种概率图模型,它使用有向无环图 (DAG) 来表示变量之间的关系。它在医疗保健、金融和自然语言处理等各个领域都有许多应用,用于决策、风险评估和预测等任务。
生成对抗网络 (GAN)
这些基于深度神经网络架构,包含两个主要组件:生成器和判别器。生成器训练并创建新的数据实例,而判别器将这些生成的数据评估为真实或虚假实例。
变分自编码器 (VAE)
这些模型是一种自编码器,经过训练可以学习输入数据的概率潜在表示。它通过从学习到的概率分布中采样来学习生成类似于输入数据的新样本。VAE 可用于诸如根据文本描述生成图像(如DALL-E-3所示)或创作类似人类的文本响应(如ChatGPT)之类的任务。
自回归模型、朴素贝叶斯、马尔可夫随机场、隐马尔可夫模型 (HMM)、潜在狄利克雷分配 (LDA) 是其他一些常用的生成式模型的例子。
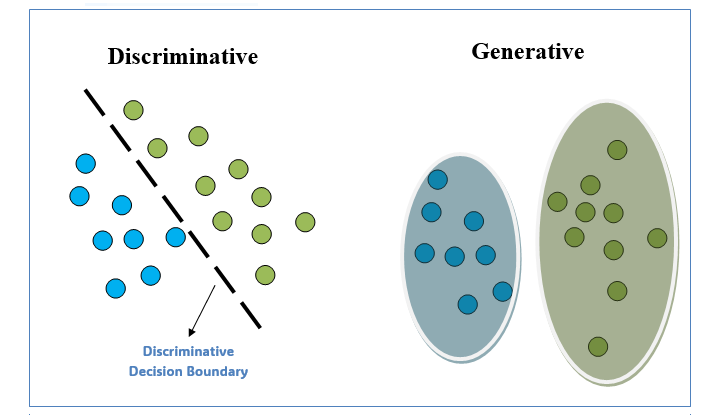
判别式模型和生成式模型的区别
数据科学家和机器学习专家需要了解这两种模型之间的区别,才能为特定任务选择最合适的模型。
下表描述了判别式模型和生成式模型之间的核心区别:
| 特征 | 判别式模型 | 生成式模型 |
|---|---|---|
| 目标 | 专注于直接从数据中学习不同类别之间的边界。它们的主要目标是根据学习到的决策边界准确地对输入数据进行分类。 | 旨在了解潜在的数据分布并生成类似于训练数据的新数据点。它们专注于对数据生成过程进行建模,使它们能够创建合成数据实例。 |
| 概率分布 | 从训练数据集中估计概率P(Y|X)的参数。 | 使用贝叶斯定理计算后验概率P(Y|X)。 |
| 处理异常值 | 对异常值相对稳健 | 容易受到异常值的影响 |
| 属性 | 它们不具有生成属性。 | 它们具有判别属性。 |
| 应用 | 通常用于分类任务,例如图像识别和情感分析。 | 通常用于数据生成、异常检测和数据增强等任务,超越传统的分类任务。 |
| 示例 | 逻辑回归、支持向量机、决策树、神经网络等。 | 变分自编码器 (VAE)、生成对抗网络 (GAN)、朴素贝叶斯等。 |
结论
判别式模型创建类别之间的边界,这使得它们成为分类任务的理想选择。相比之下,生成式模型了解潜在的数据分布并生成新的样本,这使得它们适合于数据生成和异常检测等任务。
我们还解释了判别式模型和生成式模型之间的一些核心区别。这些差异使数据科学家和机器学习专家能够为特定任务选择最合适的方法,并提高机器学习系统的效率。