- SEO 教程
- SEO - 首页
- SEO - 什么是 SEO?
- SEO - 策略与方法
- SEO - 页面内优化技巧
- SEO - 页面外优化技巧
- SEO - 网站域名
- SEO - 相关文件名
- SEO - 设计与布局
- SEO - 优化关键词
- SEO - 长尾关键词
- SEO - 标题标签
- SEO - 元描述
- SEO - 优化元标签
- SEO - 针对 Google 优化
- SEO - robots.txt
- SEO - URL 结构
- SEO - 标题
- SEO - 重定向
- SEO - 权威性和信任度
- SEO - PDF 文件
- SEO - 优化锚文本
- SEO - 优化图片
- SEO - 重复内容
- SEO - Meta Robots 标签
- SEO - Nofollow 链接
- SEO - XML 网站地图
- SEO - 规范 URL
- SEO - UI/UX 的作用
- SEO - 关键词差距分析
- SEO - 获取高质量反向链接
- SEO - 添加 Schema 标记
- SEO - 作者权威
- SEO - 修复断链
- SEO - 内部页面链接
- SEO - 清理不良链接
- SEO - 获取权威反向链接
- SEO - 核心 Web 指标
- SEO - 更新旧内容
- SEO - 填补内容空白
- SEO - 链接建设
- SEO - 特色片段
- SEO - 从 Google 中删除 URL
- SEO - 内容为王
- SEO - 验证网站
- SEO - 多媒体类型
- SEO - Google 段落排名
- SEO - 最大化社交分享
- SEO - 首次链接优先规则
- SEO - 优化页面加载时间
- SEO - 聘请专家
- SEO - 学习 EAT 原则
- SEO - 移动端 SEO 技巧
- SEO - 避免负面策略
- SEO - 其他技巧
- SEO - 持续站点审计
- SEO - 总结
- SEO 有用资源
- SEO - 快速指南
- SEO - 有用资源
- SEO - 讨论
SEO - 重复内容
重复内容:它是什么?
在单独的网站或单个网页的不同部分中发现的内容相同或非常相似,称为重复内容。如果网站包含大量相同的内容,其搜索引擎排名可能会受到影响。该术语指的是具有特定网站地址 (URL) 的位置;因此,当相同内容存在于多个网络地址时,就会存在重复内容。
重复内容的后果
搜索引擎结果中存在多种后果;有时,当发布包含相同内容的网站时,甚至还会受到经济处罚。复制材料最常见的问题包括:
在 SERP 中显示的网页存在不适当的复制版本。
出乎意料的是,原始网站在搜索引擎结果页面 (SERP) 中排名较低或存在索引问题。
关键站点指标(如流量、排名或 E-A-T 标准)发生变化或下降。
由于优先级信号冲突,搜索引擎算法可能会对有效网站采取其他意想不到的措施。

为什么避免重复内容至关重要?
对于搜索引擎来说,相同的内容可能会导致三个具体问题:
缺乏技术算法 - 他们需要更多技术专业知识来决定要索引哪些版本以及要排除哪些版本。由于各种算法因素,他们通常在 SERP 中显示重复或复制的内容材料,而不是原始内容。
统计问题 - 他们需要帮助分配连接统计信息,例如信任度、权威性、锚文本、链接权重等,在不同网站上的多个内容版本之间。当内容在多个网站上变得相似时,评估和排名因素会受到干扰,消费者以及网站所有者都会受到影响。
不同版本之间的混淆 - 他们难以确定要优先考虑哪些版本或版本以进行搜索引擎结果。由于优先级失败,他们经常会依次显示相同的内容。
当重复内容公开可用时,网站所有者可能会遇到排名和访问量下降的情况。这些经济损失通常源于两个主要问题:
资本损失 - 由于竞争网站必须在重复内容、链接权重、资本投资和链接和广告带来的回报和利润之间做出选择,因此链接和广告的回报和利润可能会大大减少。与所有入站链接都指向单个内容项目相反,通过链接到多个已发布的材料而不是一个,入站链接将链接资本分配到重复项之间。因此,由于入站链接是排名组件,因此数据片段的在线曝光可能会受到影响。
SERP 排名降低 - 搜索引擎算法很少显示多个版本的类似数据以提供最佳的搜索体验;因此,他们被迫选择最可能的版本以产生最准确的结果。结果,每个副本都变得不那么引人注目。并且原始内容也因此受到这种在线限制或曝光的影响。

重复内容问题:它们是如何产生的?
网站所有者通常不会有意创建重复内容。话虽如此,它仍然可能存在。根据某些预测,互联网的四分之一可能包含重复内容。
以下是一些最常见的无意中生成重复数据的情况:
URL 变体
URL 参数(如流量管理参数、点击率跟踪器、分析源代码和某些统计代码)可能会导致重复内容问题。除了参数本身之外,这些参数在 URL 本身中出现的顺序也可能构成问题。
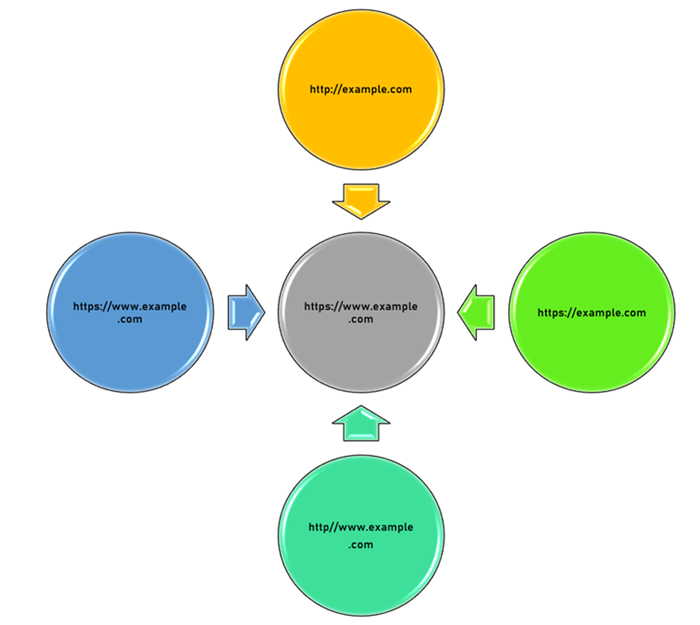
协议和子域名
如果相同的内容同时出现在网站的“www.example.com”和“example.com”版本中,则您已复制每个网页。对于同时具有 http:// 和 https:// 版本的网站,情况也是如此。
产品规格
内容、日志条目和书面内容中包含产品详细信息部分。如果许多销售相同产品的网站都使用制造商对这些商品的描述,则相同的内容最终会出现在互联网上的多个位置。

解决重复内容冲突
结构
建议从广泛查看网站的结构作为起点。无论您是在处理新的、最新的还是更新的文档,第一步都是使用站点抓取工具标记所有页面,并为每个页面提供唯一的 H1 和核心关键词。
301 重定向代码
在许多情况下,设置 301 链接重定向以将“重复”网页连接到原始内容网页是最有效的避免重复内容的方法。
rel=canonical 属性
使用 rel="canonical" 功能是处理重复内容的另一种选择。这会通知搜索引擎爬虫特定网站必须被视为特定 URL 的重复。
<meta name="robots" content="noindex,follow">
通常与参数“noindex, follow”结合使用,meta robots 标签在遇到重复内容时可能很有用。任何必须阻止搜索引擎索引的网站都可以在其 HTML 头部包含此 meta robots 标签。
验证网站重定向是否正确完成
网站的各个版本都应该指向同一个地址。
如果我的内容未受版权保护会发生什么?
如果有人复制了您的作品,而您仍然需要使用规范标签将其标记为原始作品,则这是一个问题。测试这些:
使用 Search Console 找出网站被索引的频率。
联系未经许可使用您内容的网站管理员,请求确认或删除复制内容。
为了确保您发布的内容被认可为数据的“原始来源”,请在您发布的每个新内容部分上使用自我引用的规范标签。
结论
为您的网站创建独特、高质量的内容是防止重复内容的第一步。但是,减少其他人可能窃取您提供的服务的风险的程序可能具有挑战性——仔细考虑网页设计并专注于用户在您网站上的体验是防止重复内容问题的最有效方法。如果内容重复是由于技术原因造成的,则提到的策略应降低您网站的风险。