- Puppeteer 教程
- Puppeteer - 首页
- Puppeteer - 简介
- Puppeteer - 元素处理
- Puppeteer - Google 使用
- Puppeteer - NodeJS 安装
- Puppeteer VS Code 配置
- Puppeteer - 安装
- Puppeteer - 基本测试
- Puppeteer - 非无头执行
- Puppeteer 与 Selenium 的比较
- Puppeteer 与 Protractor 的比较
- Puppeteer 与 Cypress 的比较
- Puppeteer - 浏览器操作
- Puppeteer - 标签处理
- Puppeteer - 基本命令
- Puppeteer - Firefox
- Puppeteer - Chrome
- Puppeteer - 处理确认警报
- Puppeteer - 处理下拉菜单
- Puppeteer - 定位器
- Puppeteer - XPath 函数
- Puppeteer - XPath 属性
- Puppeteer - XPath 分组
- Puppeteer - 绝对 XPath
- Puppeteer - 相对 XPath
- Puppeteer - XPath 轴
- Puppeteer - 类型选择器
- 名称选择器 & 类名称选择器
- Puppeteer - ID 选择器
- Puppeteer - 属性选择器
- Puppeteer - 处理链接/按钮
- 处理编辑框 & 复选框
- Puppeteer - 处理框架
- Puppeteer - 键盘模拟
- Puppeteer - 获取元素文本
- Puppeteer - 获取元素属性
- Puppeteer - 设备模拟
- Puppeteer - 禁用 JavaScript
- Puppeteer - 同步
- Puppeteer - 捕获屏幕截图
- Puppeteer 有用资源
- Puppeteer - 快速指南
- Puppeteer - 有用资源
- Puppeteer - 讨论
Puppeteer - 绝对 XPath
为了唯一地确定一个元素,我们可以使用HTML标签内的任何属性,或者使用HTML标签上属性的组合。大多数情况下使用id属性,因为它在页面中是唯一的。
但是,如果id属性不存在,我们可以使用其他属性,例如class、name等等。如果id、name、class等属性不存在,我们可以利用仅对该标签可用的独特属性或属性及其值的组合来识别元素。为此,我们必须使用xpath表达式。此外,如果页面上的元素是动态的,那么xpath选择器可以作为选择器的一个不错的选择。
XPath可以分为两种类型——绝对路径和相对路径。绝对XPath以/符号开头,从根节点开始到我们要识别的元素。下面给出了一个例子。
/html/body/div[1]/div/div[1]/a
让我们借助绝对XPath来识别页面上突出显示的徽标,然后单击它。
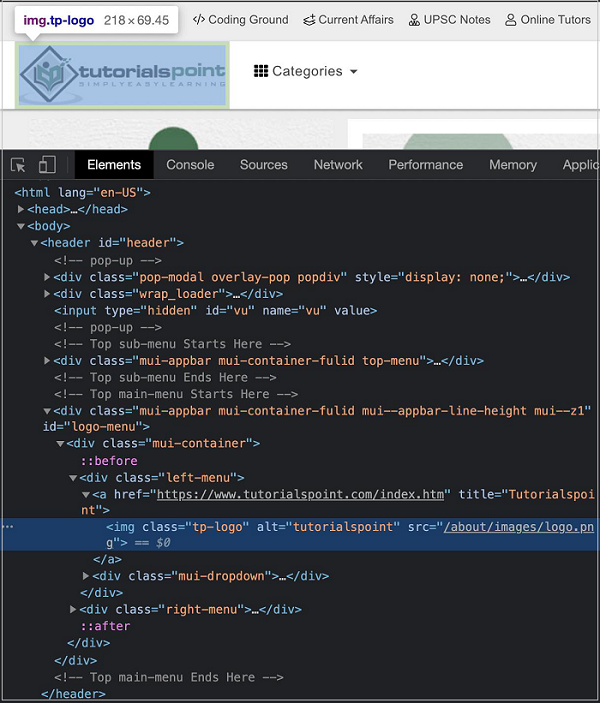
徽标的绝对XPath如下:
html/body/header/div[4]/div[1]/div[1]/a/img.
在这里,我们使用XPath选择器,所以我们必须使用该方法:`page.$x(xpath value)`。此方法的详细信息在Puppeteer定位器章节中讨论。
首先,请按照Puppeteer基本测试章节中的步骤1到步骤2操作,步骤如下:
步骤1 - 在创建node_modules文件夹的目录(Puppeteer和Puppeteer核心已安装的位置)中创建一个新文件。
Puppeteer安装的详细信息在Puppeteer安装章节中讨论。
右键单击创建node_modules文件夹的文件夹,然后单击“新建文件”按钮。
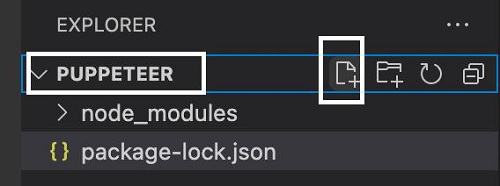
步骤2 - 输入文件名,例如testcase1.js。
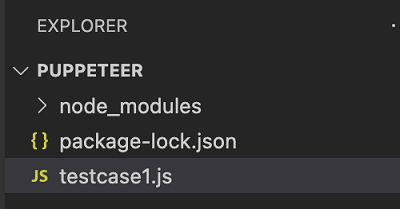
步骤3 - 在创建的testcase1.js文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function selectorAbsoluteXpath(){
//launch browser in headless mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage()
//launch URL
await page.goto('https://tutorialspoint.com/about/about_careers.htm')
//identify element with absolute xpath then click
const b = (await page.$x("/html/body/header/div[4]/div[1]/div[1]/a/img"))[0]
b.click()
//wait for sometime
await page.waitForTimeout(4000)
//obtain URL after click
console.log(await page.url())
}
selectorAbsoluteXpath()
步骤4 - 使用下面提到的命令执行代码。
node <filename>
所以在我们的例子中,我们将运行以下命令:
node testcase1.js

命令成功执行后,单击徽标图像后导航到的页面的URL - https://tutorialspoint.com/index.htm 将打印在控制台中。