- Python 基础
- Python - 首页
- Python - 概述
- Python - 历史
- Python - 特性
- Python vs C++
- Python - Hello World 程序
- Python - 应用领域
- Python - 解释器
- Python - 环境搭建
- Python - 虚拟环境
- Python - 基本语法
- Python - 变量
- Python - 数据类型
- Python - 类型转换
- Python - Unicode 系统
- Python - 字面量
- Python - 运算符
- Python - 算术运算符
- Python - 比较运算符
- Python - 赋值运算符
- Python - 逻辑运算符
- Python - 位运算符
- Python - 成员运算符
- Python - 身份运算符
- Python - 运算符优先级
- Python - 注释
- Python - 用户输入
- Python - 数字
- Python - 布尔值
- Python 控制语句
- Python - 控制流
- Python - 决策
- Python - if 语句
- Python - if else
- Python - 嵌套 if
- Python - match-case 语句
- Python - 循环
- Python - for 循环
- Python - for-else 循环
- Python - while 循环
- Python - break 语句
- Python - continue 语句
- Python - pass 语句
- Python - 嵌套循环
- Python 函数与模块
- Python - 函数
- Python - 默认参数
- Python - 关键字参数
- Python - 仅关键字参数
- Python - 位置参数
- Python - 仅位置参数
- Python - 可变参数
- Python - 变量作用域
- Python - 函数注解
- Python - 模块
- Python - 内置函数
- Python 字符串
- Python - 字符串
- Python - 字符串切片
- Python - 修改字符串
- Python - 字符串连接
- Python - 字符串格式化
- Python - 转义字符
- Python - 字符串方法
- Python - 字符串练习
- Python 列表
- Python - 列表
- Python - 访问列表元素
- Python - 修改列表元素
- Python - 添加列表元素
- Python - 删除列表元素
- Python - 遍历列表
- Python - 列表推导式
- Python - 列表排序
- Python - 复制列表
- Python - 合并列表
- Python - 列表方法
- Python - 列表练习
- Python 元组
- Python - 元组
- Python - 访问元组元素
- Python - 更新元组
- Python - 解包元组
- Python - 遍历元组
- Python - 合并元组
- Python - 元组方法
- Python - 元组练习
- Python 集合
- Python - 集合
- Python - 访问集合元素
- Python - 添加集合元素
- Python - 删除集合元素
- Python - 遍历集合
- Python - 合并集合
- Python - 复制集合
- Python - 集合运算符
- Python - 集合方法
- Python - 集合练习
- Python 字典
- Python - 字典
- Python - 访问字典元素
- Python - 修改字典元素
- Python - 添加字典元素
- Python - 删除字典元素
- Python - 字典视图对象
- Python - 遍历字典
- Python - 复制字典
- Python - 嵌套字典
- Python - 字典方法
- Python - 字典练习
- Python 数组
- Python - 数组
- Python - 访问数组元素
- Python - 添加数组元素
- Python - 删除数组元素
- Python - 遍历数组
- Python - 复制数组
- Python - 反转数组
- Python - 排序数组
- Python - 合并数组
- Python - 数组方法
- Python - 数组练习
- Python 文件处理
- Python - 文件处理
- Python - 写入文件
- Python - 读取文件
- Python - 重命名和删除文件
- Python - 目录
- Python - 文件方法
- Python - OS 文件/目录方法
- Python - OS 路径方法
- 面向对象编程
- Python - OOPs 概念
- Python - 类与对象
- Python - 类属性
- Python - 类方法
- Python - 静态方法
- Python - 构造函数
- Python - 访问修饰符
- Python - 继承
- Python - 多态
- Python - 方法重写
- Python - 方法重载
- Python - 动态绑定
- Python - 动态类型
- Python - 抽象
- Python - 封装
- Python - 接口
- Python - 包
- Python - 内部类
- Python - 匿名类和对象
- Python - 单例类
- Python - 包装器类
- Python - 枚举
- Python - 反射
- Python 错误与异常
- Python - 语法错误
- Python - 异常
- Python - try-except 块
- Python - try-finally 块
- Python - 抛出异常
- Python - 异常链
- Python - 嵌套 try 块
- Python - 用户自定义异常
- Python - 日志记录
- Python - 断言
- Python - 内置异常
- Python 多线程
- Python - 多线程
- Python - 线程生命周期
- Python - 创建线程
- Python - 启动线程
- Python - 连接线程
- Python - 线程命名
- Python - 线程调度
- Python - 线程池
- Python - 主线程
- Python - 线程优先级
- Python - 守护线程
- Python - 线程同步
- Python 同步
- Python - 线程间通信
- Python - 线程死锁
- Python - 中断线程
- Python 网络编程
- Python - 网络编程
- Python - Socket 编程
- Python - URL 处理
- Python - 泛型
- Python 库
- NumPy 教程
- Pandas 教程
- SciPy 教程
- Matplotlib 教程
- Django 教程
- OpenCV 教程
- Python 杂项
- Python - 日期与时间
- Python - 数学
- Python - 迭代器
- Python - 生成器
- Python - 闭包
- Python - 装饰器
- Python - 递归
- Python - 正则表达式
- Python - PIP
- Python - 数据库访问
- Python - 弱引用
- Python - 序列化
- Python - 模板
- Python - 输出格式化
- Python - 性能测量
- Python - 数据压缩
- Python - CGI 编程
- Python - XML 处理
- Python - GUI 编程
- Python - 命令行参数
- Python - 文档字符串
- Python - JSON
- Python - 发送邮件
- Python - 扩展
- Python - 工具/实用程序
- Python - GUIs
- Python 高级概念
- Python - 抽象基类
- Python - 自定义异常
- Python - 高阶函数
- Python - 对象内部
- Python - 内存管理
- Python - 元类
- Python - 使用元类进行元编程
- Python - 模拟和存根
- Python - 猴子补丁
- Python - 信号处理
- Python - 类型提示
- Python - 自动化教程
- Python - Humanize 包
- Python - 上下文管理器
- Python - 协程
- Python - 描述符
- Python - 诊断和修复内存泄漏
- Python - 不可变数据结构
- Python 有用资源
- Python - 问答
- Python - 在线测验
- Python 快速指南
- Python - 参考
- Python - 速查表
- Python - 项目
- Python - 有用资源
- Python - 讨论
- Python 编译器
- NumPy 编译器
- Matplotlib 编译器
- SciPy 编译器
Python 快速指南
Python - 概述
Python 是一种高级多范式编程语言。由于 Python 是一种基于解释器的语言,因此与其他一些主流语言相比,它更容易学习。Python 是一种动态类型语言,具有非常直观的数据类型。
Python 是一种开源的跨平台编程语言。它可在所有主要的 Linux、Windows 和 Mac OS 操作系统平台上根据Python 软件基金会许可证(与 GNU 通用公共许可证兼容)使用。
Python 的设计理念强调简洁、可读性和明确性。Python 以其“包含电池”的方法而闻名,因为 Python 软件附带了全面的标准函数和模块库。
Python 的设计理念记录在Python 之禅中。它包含 19 条格言,例如:
- 优美胜于丑陋
- 明了胜于晦涩
- 简洁胜于复杂
- 复杂胜于凌乱
要获取完整的 Python 之禅文档,请在 Python shell 中输入import this:
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
Python 支持命令式、结构化以及面向对象的编程方法。它也提供函数式编程的功能。
Python - 历史
荷兰程序员Guido Van Rossum 创建了 Python 编程语言。在 80 年代后期,他曾在荷兰名为Centrum Wiskunde & Informatica (CWI) 的计算机科学研究所从事 ABC 语言的开发工作。1991 年,Van Rossum 构思并发布了 Python 作为 ABC 语言的继任者。
对于许多不了解 Python 的人来说,“Python”这个词与一种蛇有关。然而,Rossum 将选择“Python”这个名字归功于 BBC 的热门喜剧系列“蒙提·派森的飞行马戏团”。
作为 Python 的首席架构师,开发者社区授予他“终身仁慈独裁者”(BDFL)的称号。然而,在 2018 年,Rossum 放弃了这个称号。此后,Python 参考实现的开发和分发由非营利组织Python 软件基金会负责。
Python 历史上重要的阶段:
Python 0.9.0
Python 的第一个公开版本是 0.9。它于 1991 年 2 月发布。它包含对核心面向对象编程原则的支持。
Python 1.0
1994 年 1 月发布了 1.0 版本,其中包含函数式编程工具,以及对复数等的支持。
Python 2.0
下一个主要版本——Python 2.0 于 2000 年 10 月发布。它包含许多新特性,如列表推导式、垃圾收集和 Unicode 支持。
Python 3.0
Python 3.0是Python的一个完全改版版本,于2008年12月发布。此次改版的首要目标是消除Python 2.x版本中出现的大量差异。Python 3向后移植到Python 2.6。它还包含一个名为python2to3的实用程序,用于促进Python 2代码到Python 3的自动转换。
Python 2.x生命周期结束
即使在Python 3发布之后,Python软件基金会也继续支持Python 2分支,并发布增量微版本,直到2019年。但是,它决定在2020年底停止支持,当时Python 2.7.17是该分支中的最后一个版本。
当前版本
与此同时,Python的3.x分支中集成了越来越多的功能。截至目前,Python 3.11.2是2023年2月发布的当前稳定版本。
Python 3.11的新功能
Python 3.11最重要的功能之一是速度的显著提高。根据Python的官方文档,此版本的速度比前一个版本(3.10)快高达60%。它还指出,标准基准测试套件显示执行速度提高了25%。
Python 3.11改进了异常消息。发生异常时,它不会生成冗长的回溯信息,而是直接显示导致错误的确切表达式。
根据PEP 678的建议,
add_note()方法被添加到BaseException类中。您可以在except子句中调用此方法并传递自定义错误消息。它还在
maths模块中添加了cbroot()函数。它返回给定数字的立方根。标准库中添加了一个新的模块
tomllib。可以使用tomllib模块函数解析TOML(Tom's Obvious Minimal Language)。
Python - 特性
在本章中,让我们重点介绍一些使Python广受欢迎的重要特性。
Python易于学习
这是Python流行的最重要原因之一。Python的关键字集有限。其特性如简单的语法、使用缩进避免大括号的混乱以及不需要预先声明变量的动态类型,帮助初学者快速轻松地学习Python。
Python是基于解释器的
任何编程语言中的指令都必须转换为机器代码才能由处理器执行。编程语言要么基于编译器,要么基于解释器。
对于编译器,会生成整个源程序的机器语言版本。即使只有一个错误语句,转换也会失败。因此,对于初学者来说,开发过程很繁琐。C系列语言(包括C、C++、Java、C#等)都是基于编译器的。
Python是一种基于解释器的语言。解释器一次从源代码中获取一条指令,将其转换为机器代码并执行它。在第一次出现错误之前的指令将被执行。凭借此功能,更容易调试程序,因此对于初级程序员来说,它有助于逐步增强信心。因此,Python是一种对初学者友好的语言。
Python是交互式的
标准Python发行版带有一个交互式shell,其工作原理是REPL(读取-评估-打印-循环)。shell显示Python提示符>>>。您可以键入任何有效的Python表达式并按Enter键。Python解释器会立即返回响应,并且提示符将返回以读取下一个表达式。
>>> 2*3+1
7
>>> print ("Hello World")
Hello World
交互模式特别有用,可以熟悉库并测试其功能。您可以在编写程序之前在交互模式下尝试小的代码片段。
Python是多范式的
Python是一种完全面向对象的语言。Python程序中的所有内容都是对象。但是,Python可以方便地封装其面向对象特性,用作命令式或过程式语言——例如C。Python还提供了一些类似于函数式编程的功能。此外,还开发了一些第三方工具来支持其他编程范式,例如面向方面编程和逻辑编程。
Python的标准库
尽管它只有很少的关键字(只有35个),但Python软件却附带了一个由大量模块和包组成的标准库。因此,Python对编程需求(如序列化、数据压缩、互联网数据处理等等)提供了开箱即用的支持。Python以其“自带电池”的方式而闻名。
Python是开源的和跨平台的
Python的标准发行版可以从https://pythonlang.cn/downloads/免费下载,没有任何限制。您可以下载适用于各种操作系统的预编译二进制文件。此外,源代码也是免费提供的,这就是它属于开源类别的原因。
Python软件(以及文档)是在Python软件基金会许可下发布的。这是一个BSD风格的宽松软件许可证,并且与GNU GPL(通用公共许可证)兼容。
Python是一种跨平台语言。预编译的二进制文件可用于各种操作系统平台,例如Windows、Linux、Mac OS、Android OS。Python的参考实现称为CPython,是用C语言编写的。您可以下载源代码并为您的操作系统平台进行编译。
Python程序首先编译成一个中间平台无关的字节码。然后,解释器中的虚拟机执行字节码。这种行为使Python成为一种跨平台语言,因此Python程序可以轻松地从一个操作系统平台移植到另一个操作系统平台。
Python用于GUI应用程序
Python的标准发行版有一个优秀的图形库,称为TKinter。它是对广受欢迎的GUI工具包TCL/Tk的Python移植。您可以在Python中构建具有吸引力的用户友好型GUI应用程序。GUI工具包通常是用C/C++编写的。许多工具包已被移植到Python。例如PyQt、WxWidgets、PySimpleGUI等。
Python的数据库连接
几乎任何类型的数据库都可以用作Python应用程序的后端。DB-API是一组数据库驱动程序软件规范,用于让Python与关系数据库通信。使用许多第三方库,Python也可以与MongoDB等NoSQL数据库一起工作。
Python是可扩展的
可扩展性是指添加新功能或修改现有功能的能力。如前所述,CPython(Python的参考实现)是用C语言编写的。因此,可以轻松地用C语言编写模块/库并将它们合并到标准库中。Python还有其他实现,例如Jython(用Java编写)和IPython(用C#编写)。因此,可以使用Java和C#分别编写和合并这些实现中的新功能。
Python活跃的开发者社区
由于Python的流行和开源性质,大量的Python开发者经常在在线论坛和会议上互动。Python软件基金会也拥有庞大的成员基础,参与该组织的使命是“推广、保护和发展Python编程语言”。
Python也享有重要的机构支持。主要的IT公司谷歌、微软和Meta通过准备文档和其他资源做出了巨大贡献。
Python vs C++
Python和C++都是最流行的编程语言之一。它们都有各自的优点和缺点。在本章中,我们将了解它们的特性。
编译型与解释型
与C语言一样,C++也是一种基于编译器的语言。编译器将整个代码转换为特定于所用操作系统的机器语言代码和处理器架构。
Python是基于解释器的语言。解释器逐行执行源代码。
跨平台性
当在Linux上编译C++源代码(例如hello.cpp)时,它只能在任何其他运行Linux操作系统的计算机上运行。如果需要在其他操作系统上运行,则需要重新编译。
Python解释器不会生成编译后的代码。源代码在每次在任何操作系统上运行时都会转换为字节码,无需任何更改或额外步骤。
可移植性
Python代码很容易从一个操作系统移植到另一个操作系统。C++代码不可移植,因为如果操作系统发生更改,则必须重新编译。
开发速度
C++程序编译成机器代码。因此,它的执行速度比基于解释器的语言快。
Python解释器不会生成机器代码。中间字节码到机器语言的转换在每次程序执行时都会进行。
如果程序需要频繁使用,则C++比Python更高效。
易于学习
与C++相比,Python具有更简单的语法。其代码更易于阅读。一开始编写C++代码看起来很 daunting,因为语法规则很复杂,例如使用大括号和分号来结束语句。
Python不使用大括号来标记语句块。相反,它使用缩进。相同缩进级别的语句构成一个块。这使得Python程序更易于阅读。
静态类型与动态类型
C++是一种静态类型语言。存储数据的变量类型需要在开始时声明。未声明的变量不能使用。一旦声明变量的类型,就只能将该类型的数值存储在其中。
Python是一种动态类型语言。它不需要在赋值之前声明变量。由于变量可以存储任何类型的数据,因此它被称为动态类型。
面向对象概念
C++和Python都实现了面向对象编程的概念。C++比Python更接近OOP理论。C++支持数据封装的概念,因为变量的可见性可以定义为公共的、私有的和受保护的。
Python没有定义可见性的规定。与C++不同,Python不支持方法重载。因为它被动态类型化,所以默认情况下所有方法都是多态的。
C++实际上是C的扩展。可以说,在C中添加了额外的关键字以便它支持OOP。因此,我们可以在C++中编写C类型的过程式程序。
Python是一种完全面向对象的语言。Python的数据模型是这样的,即使您可以采用过程式方法,Python内部也会使用面向对象的方法。
垃圾回收
C++使用指针的概念。C++程序中未使用的内存不会自动清除。在C++中,垃圾回收过程是手动进行的。因此,C++程序可能会遇到与内存相关的异常行为。
Python具有自动垃圾回收机制。因此,Python程序更健壮,并且不太容易出现与内存相关的错误。
应用领域
因为C++程序直接编译成机器代码,所以它更适合系统编程、编写设备驱动程序、嵌入式系统和操作系统实用程序。
Python程序适合应用程序编程。它目前的应用领域主要是数据科学、机器学习、API开发等。
下表总结了C++和Python的比较:
| 标准 | C++ | Python |
|---|---|---|
| 执行 | 基于编译器 | 基于解释器 |
| 类型 | 静态类型 | 动态类型 |
| 可移植性 | 不可移植 | 高度可移植 |
| 垃圾回收 | 手动 | 自动 |
| 语法 | 繁琐 | 简单 |
| 性能 | 执行速度更快 | 执行速度较慢 |
| 应用领域 | 嵌入式系统、设备驱动程序 | 机器学习、Web应用程序 |
Python - Hello World 程序
“Hello World”程序是用通用编程语言编写的基本计算机代码,用作测试程序。它不要求任何输入,并在输出控制台上显示“Hello World”消息。它用于测试编译和运行程序所需的软件是否已正确安装。
使用Python解释器显示“Hello World”消息非常容易。从操作系统的命令终端启动解释器,并从Python提示符发出print语句,如下所示:
PS C:\Users\mlath> python
Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print ("Hello World")
Hello World
同样,在Linux系统中也会打印“Hello World”消息。
mvl@GNVBGL3:~$ python3
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print ("Hello World")
Hello World
Python解释器也可以在脚本模式下工作。打开任何文本编辑器,输入以下文本并保存为Hello.py
print ("Hello World")
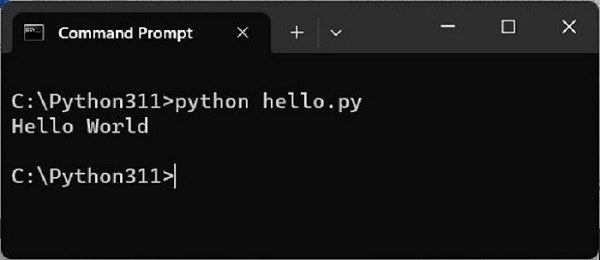
对于Windows操作系统,打开命令提示符终端(CMD)并运行程序,如下所示:
C:\Python311>python hello.py Hello World
终端显示“Hello World”消息。
在Ubuntu Linux系统上工作时,您需要遵循相同的步骤,保存代码并从Linux终端运行。我们使用vi编辑器保存程序。
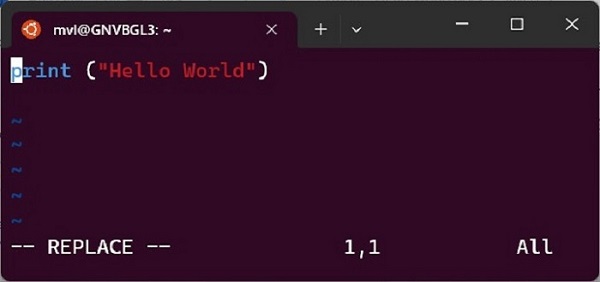
从Linux终端运行程序
mvl@GNVBGL3:~$ python3 hello.py Hello World
在Linux中,您可以将Python程序转换为可执行脚本。代码中的第一条语句应该是shebang。它必须包含Python可执行文件的路径。在Linux中,Python安装在/usr/bin目录中,可执行文件的名称为python3。因此,我们将此语句添加到hello.py文件中
#!/usr/bin/python3
print ("Hello World")
您还需要使用chmod +x命令授予文件可执行权限
mvl@GNVBGL3:~$ chmod +x hello.py
然后,您可以使用以下命令行运行程序:
mvl@GNVBGL3:~$ ./hello.py
输出如下所示:
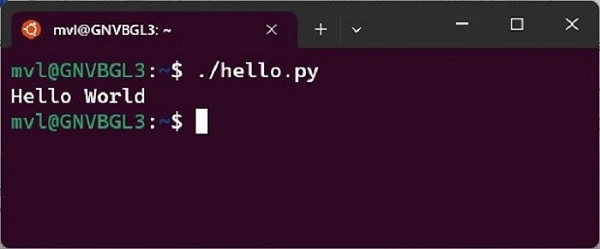
因此,我们可以使用解释器模式和脚本模式在Python中编写和运行“Hello World”程序。
Python - 应用领域
Python是一种通用编程语言。它适用于开发各种软件应用程序。在过去几年中,Python成为以下应用领域开发人员的首选语言:
用于数据科学的Python
Python在流行度排行榜上最近的迅速崛起,很大程度上是由于它的数据科学库。Python已成为数据科学家的必备技能。如今,实时Web应用程序、移动应用程序和其他设备会生成海量数据。Python的数据科学库帮助公司从这些数据中生成业务洞察。
NumPy、Pandas和Matplotlib等库广泛用于将数学算法应用于数据并生成可视化效果。Anaconda和ActiveState等商业和社区Python发行版捆绑了数据科学所需的所有必要库。
用于机器学习的Python
Scikit-learn和TensorFlow等Python库有助于根据过去的数据构建预测趋势(如客户满意度、股票预测值等)的模型。机器学习应用程序包括(但不限于)医学诊断、统计套利、篮子分析、销售预测等。
用于Web开发的Python
Python的Web框架促进了快速的Web应用程序开发。Django、Pyramid、Flask在Web开发人员社区中非常流行。等等,使开发和部署简单和复杂的Web应用程序变得非常容易。
最新版本的Python提供异步编程支持。现代Web框架利用此功能来开发快速高效的Web应用程序和API。
用于计算机视觉和图像处理的Python
OpenCV是一个广泛流行的用于捕获和处理图像的库。图像处理算法从图像中提取信息,重建图像和视频数据。计算机视觉使用图像处理进行人脸检测和模式识别。OpenCV是一个C++库。它的Python移植由于其快速开发特性而被广泛使用。
计算机视觉的一些应用领域包括机器人技术、工业监控和自动化、生物识别技术等。
用于嵌入式系统和物联网的Python
Micropython(https://micropython.org/)是一个轻量级版本,尤其适用于Arduino等微控制器。许多自动化产品、机器人技术、物联网和信息亭应用程序都是围绕Arduino构建的,并使用Micropython进行编程。Raspberry Pi也是非常流行的低成本单板计算机,用于此类应用程序。
用于作业调度和自动化的Python
Python在自动化CRON(Command Run ON)作业方面找到了其最早的应用之一。某些任务(如定期数据备份)可以用Python脚本编写,并安排由操作系统调度程序自动调用。
许多软件产品(如Maya)嵌入Python API来编写自动化脚本(类似于Excel宏)。
在线尝试Python
如果您是Python新手,建议您在继续在计算机上安装Python软件之前,通过尝试许多在线资源之一来熟悉该语言的语法和功能。
您可以从Python官方网站的主页启动Python交互式shell https://pythonlang.cn/。
在Python提示符(>>>)前面,可以输入和评估任何有效的Python表达式。
Tutorialspoint网站也有一个Coding Ground部分:
(https://tutorialspoint.com/codingground.htm)
在这里,您可以找到各种语言(包括Python)的在线编译器。访问https://tutorialspoint.com/execute_python_online.php。您可以试验Python解释器的交互模式和脚本模式。
Python - 解释器
Python是一种基于解释器的语言。在Linux系统中,Python的可执行文件安装在/usr/bin/目录中。对于Windows,可执行文件(python.exe)位于安装文件夹中(例如C:\python311)。本章将介绍Python解释器的工作原理、其交互模式和脚本模式。
Python代码一次执行一条语句。Python解释器有两个组成部分。翻译器检查语句的语法。如果正确,它会生成中间字节码。有一个Python虚拟机,然后将字节码转换为本机二进制代码并执行它。下图说明了该机制
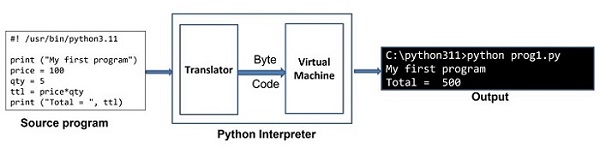
Python解释器具有交互模式和脚本模式。
交互模式
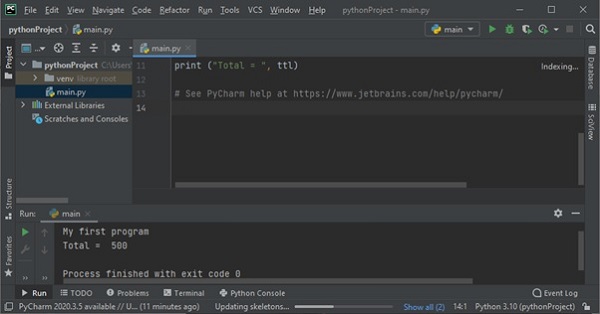
当从命令行终端启动时没有任何附加选项,Python提示符>>>出现,并且Python解释器的工作原理是REPL(读取、评估、打印、循环)。在Python提示符前面输入的每个命令都会被读取、翻译和执行。一个典型的交互会话如下所示。
>>> price = 100
>>> qty = 5
>>> ttl = price*qty
>>> ttl
500
>>> print ("Total = ", ttl)
Total = 500
要关闭交互式会话,请输入行尾字符(对于Linux为ctrl+D,对于Windows为ctrl+Z)。您也可以在Python提示符前键入quit()并按Enter键返回到操作系统提示符。
标准Python发行版附带的交互式shell不具备行编辑、历史搜索、自动完成等功能。您可以使用其他高级交互式解释器软件,例如IPython和bpython。
脚本模式
无需像在交互式环境中那样一次输入并获得一条指令的结果,而是可以将一组指令保存在文本文件中,确保其具有.py扩展名,并将名称用作Python命令的命令行参数。
使用任何文本编辑器(例如Linux上的vim或Windows上的Notepad)将以下几行保存为prog1.py。
print ("My first program")
price = 100
qty = 5
ttl = price*qty
print ("Total = ", ttl)
使用此名称作为命令行参数启动Python。
C:\Users\Acer>python prog1.py My first program Total = 500
请注意,即使Python执行整个脚本,它仍然是一次执行一条语句。
对于Java等基于编译器的语言,除非整个代码没有错误,否则不会将源代码转换为字节码。另一方面,在Python中,语句会一直执行到遇到第一个错误为止。
让我们故意在上述代码中引入一个错误。
print ("My first program")
price = 100
qty = 5
ttl = prive*qty #Error in this statement
print ("Total = ", ttl)
请注意拼写错误的变量prive而不是price。尝试像以前一样再次执行脚本:
C:\Users\Acer>python prog1.py My first program Traceback (most recent call last): File "C:\Python311\prog1.py", line 4, in <module> ttl = prive*qty ^^^^^ NameError: name 'prive' is not defined. Did you mean: 'price'?
请注意,错误语句之前的语句已执行,然后出现错误消息。因此,现在很清楚Python脚本是以解释方式执行的。
除了像上面那样执行Python脚本之外,脚本本身也可以在Linux中像shell脚本一样成为自执行脚本。您必须在脚本顶部添加一行shebang。shebang指示哪个可执行文件用于解释脚本中的Python语句。脚本的第一行以#!开头,后跟Python可执行文件的路径。
修改prog1.py脚本如下:
#! /usr/bin/python3.11
print ("My first program")
price = 100
qty = 5
ttl = price*qty
print ("Total = ", ttl)
要将脚本标记为自执行脚本,请使用chmod命令
user@ubuntu20:~$ chmod +x prog1.py
您现在可以直接执行脚本,而无需将其用作命令行参数。
user@ubuntu20:~$ ./hello.py
IPython
IPython(代表Interactive Python)是一个增强的、功能强大的Python交互式环境,与标准Python shell相比,它具有许多功能。IPython最初由Fernando Perez于2001年开发。
IPython具有以下重要特性:
IPython的对象自省能力,可以在运行时检查对象的属性。
它的语法高亮显示有助于识别语言元素,例如关键字、变量等。
交互历史被内部存储,可以重现。
关键字、变量和函数名称的制表符完成是最重要的功能之一。
IPython的Magic命令系统可用于控制Python环境和执行操作系统任务。
它是Jupyter笔记本和其他Jupyter项目的前端工具的主要内核。
使用PIP安装程序实用程序安装IPython。
pip3 install ipython
从命令行启动IPython
C:\Users\Acer>ipython Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32 Type 'copyright', 'credits' or 'license' for more information IPython 8.4.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
与标准解释器中的常规>>>提示符不同,您会注意到两个主要的IPython提示符,如下所述:
In[1]出现在任何输入表达式之前。
Out[1]出现在输出出现之前。
In [1]: price = 100 In [2]: quantity = 5 In [3]: ttl = price*quantity In [4]: ttl Out[4]: 500 In [5]:
制表符完成是IPython提供的最有用的增强功能之一。当您在对象前面的点之后按制表键时,IPython会弹出相应的合适方法列表。
在以下示例中,定义了一个字符串。在“.”符号后按制表键,作为响应,将显示字符串类的属性。您可以导航到所需的一个。

IPython通过在对象前面加上“?”来提供任何对象的信息(自省)。它包括类文档字符串、函数定义和构造函数详细信息。例如,要探索上面定义的字符串对象var,请在输入提示符中输入var?。
In [5]: var = "Hello World" In [6]: var? Type: str String form: Hello World Length: 11 Docstring: str(object='') -> str str(bytes_or_buffer[, encoding[, errors]]) -> str Create a new string object from the given object. If encoding or errors is specified, then the object must expose a data buffer that will be decoded using the given encoding and error handler. Otherwise, returns the result of object.__str__() (if defined) or repr(object). encoding defaults to sys.getdefaultencoding(). errors defaults to 'strict'.
IPython的magic函数非常强大。行magic允许您在IPython中运行DOS命令。让我们在IPython控制台中运行dir命令
In [8]: !dir *.exe
Volume in drive F has no label.
Volume Serial Number is E20D-C4B9
Directory of F:\Python311
07-02-2023 16:55 103,192 python.exe
07-02-2023 16:55 101,656 pythonw.exe
2 File(s) 204,848 bytes
0 Dir(s) 105,260,306,432 bytes free
Jupyter Notebook是一个基于Web的界面,用于Python、Julia、R和许多其他编程环境。对于Python,它使用IPython作为其主要内核。
Python - 环境搭建
学习Python的第一步是在您的机器上安装它。如今,大多数计算机,特别是安装了Linux操作系统的计算机,都预装了Python。但是,它可能不是最新版本。
在本节中,我们将学习如何在Linux、Windows和Mac OS上安装最新版本的Python,Python 3.11.2。
所有操作系统的最新版本的Python都可以在PSF的官方网站上下载。
在Ubuntu Linux上安装Python
要检查是否已安装Python,请打开Linux终端并输入以下命令:
user@ubuntu20:~$ python3 --version
在Ubuntu Linux中,安装Python最简单的方法是使用apt(高级打包工具)。始终建议更新所有已配置存储库中的软件包列表。
user@ubuntu20:~$ sudo apt update
即使更新后,根据您使用的Ubuntu版本,最新版本的Python也可能无法安装。要克服这个问题,请添加deadsnakes存储库。
user@ubuntu20:~$ sudo apt-get install software-properties-common user@ubuntu20:~$ sudo add-apt-repository ppa:deadsnakes/ppa
再次更新软件包列表。
user@ubuntu20:~$ sudo apt update
要安装最新的Python 3.11版本,请在终端中输入以下命令:
user@ubuntu20:~$ sudo apt-get install python3.11
检查它是否已正确安装。
user@ubuntu20:~$ python3.11
Python 3.11.2 (main, Feb 8 2023, 14:49:24) [GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print ("Hello World")
Hello World
>>>
在Windows上安装Python
需要注意的是,Python 3.10及更高版本无法安装在Windows 7或更早的操作系统上。
推荐的安装Python的方法是使用官方安装程序。主页上提供了最新稳定版本的链接。它也可以在https://pythonlang.cn/downloads/windows/.找到。
您可以找到适用于32位和64位架构的可嵌入包和安装程序。
让我们下载64位Windows安装程序:
(https://pythonlang.cn/ftp/python/3.11.2/python-3.11.2-amd64.exe)
双击已下载文件的所在位置以启动安装。

虽然您可以直接单击“立即安装”按钮继续,但建议选择路径相对较短的安装文件夹,并选中第二个复选框以更新PATH变量。
接受安装向导中其余步骤的默认设置以完成安装。
打开 Windows 命令提示符终端并运行 Python 以检查安装是否成功。
C:\Users\Acer>python Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
Python 的标准库包含一个名为 **IDLE** 的可执行模块,它是 **集成开发和学习环境 (Integrated Development and Learning Environment)** 的缩写。从 Windows 开始菜单中找到并启动它。
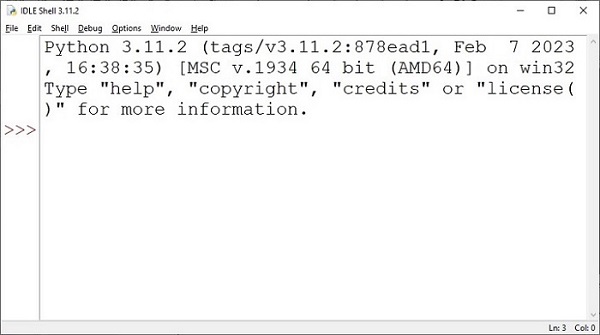
IDLE 包含 Python shell(交互式解释器)和一个可自定义的多窗口文本编辑器,具有语法高亮、智能缩进、自动完成等功能。它是跨平台的,因此在 Windows、macOS 和 Linux 上的工作方式相同。它还有一个调试器,可以设置断点、单步执行以及查看全局和局部命名空间。
在 macOS 上安装 Python
早期版本的 macOS 预装了 Python 2.7。但是,由于该版本不再受支持,因此已被停用。因此,您需要自行安装 Python。
在 Mac 计算机上,可以通过两种方法安装 Python:
使用官方安装程序
使用 homebrew 手动安装
您可以在官方网站的下载页面上找到 macOS 64 位通用 2 安装程序:
https://pythonlang.cn/ftp/python/3.11.2/python-3.11.2-macos11.pkg
安装过程与 Windows 上大致相同。通常,在向导步骤中接受默认选项即可完成工作。
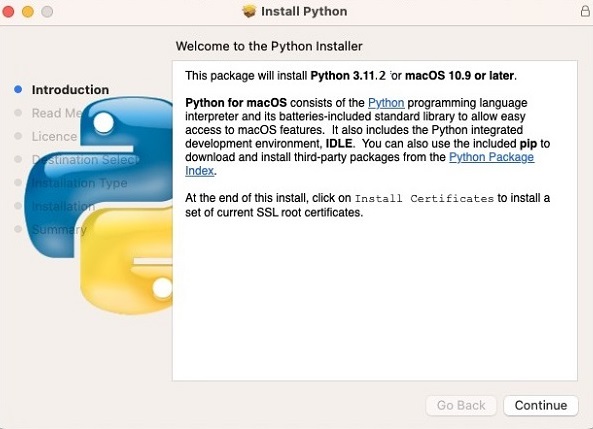
此安装向导还会安装常用的实用程序,例如 PIP 和 IDLE。
或者,您可以选择从命令行安装。如果您尚未安装 Mac 的包管理器 **Homebrew**,则需要先安装它。您可以按照以下说明进行安装:https://docs.brew.sh.cn/Installation。
之后,打开终端并输入以下命令:
brew update && brew upgrade brew install python3
现在将安装最新版本的 Python。
从源代码安装 Python
如果您是一位经验丰富的开发人员,并且精通 C++ 和 Git 工具,则可以按照本节中的说明构建 Python 可执行文件以及标准库中的模块。
您必须拥有您正在使用的操作系统的 C 编译器。在 Ubuntu 和 macOS 中,可以使用 **gcc** 编译器。对于 Windows,您应该安装 Visual Studio 2017 或更高版本。
在 Linux/Mac 上构建 Python 的步骤
从 Python 的官方网站或其 GitHub 存储库下载最新版本的源代码。
下载源代码压缩包:https://pythonlang.cn/ftp/python/3.11.2/Python3.11.2.tgz
使用以下命令解压文件:
tar -xvzf /home/python/Python-3.11.2.tgz
或者,克隆 Python 的 GitHub 存储库的主分支。(您应该已安装 git)
git clone -b main https://github.com/python/cpython
源代码中包含一个 configure 脚本。运行此脚本将创建 Makefile。
./configure --enable-optimizations
然后,使用 make 工具构建文件,然后使用 make install 将最终文件放入 /usr/bin/ 目录。
make make install
Python 已成功从源代码构建。
如果您使用的是 Windows,请确保已安装 **Visual Studio 2017** 和 **Git for Windows**。使用与上述相同的命令克隆 Python 源代码存储库。
在放置源代码的文件夹中打开 Windows 命令提示符。运行以下批处理文件
PCbuild\get_externals.bat
这将下载源代码依赖项(OpenSSL、Tk 等)。
打开 Visual Studio 和 **PCbuild/sbuild.sln** 解决方案,并构建(按 F10)调试文件夹显示 **python_d.exe**,这是 Python 可执行文件的调试版本。
要从命令提示符构建,请使用以下命令:
PCbuild\build.bat -e -d -p x64
因此,在本节中,您学习了如何从预构建的二进制文件以及从源代码安装 Python。
设置 PATH
安装 Python 软件后,应能够从文件系统的任何位置访问它。为此,需要更新 **PATH** 环境变量。系统 PATH 是一个由分号 (;) 分隔的文件夹名称组成的字符串。每当从命令行调用可执行程序时,操作系统都会在 PATH 变量中列出的文件夹中搜索它。我们需要将 Python 的安装文件夹添加到 PATH 字符串。
对于 Windows 操作系统,如果您在安装向导的第一个屏幕上启用了“将 python.exe 添加到系统路径”选项,则路径将自动更新。要手动执行此操作,请从“高级系统设置”中打开“环境变量”部分。
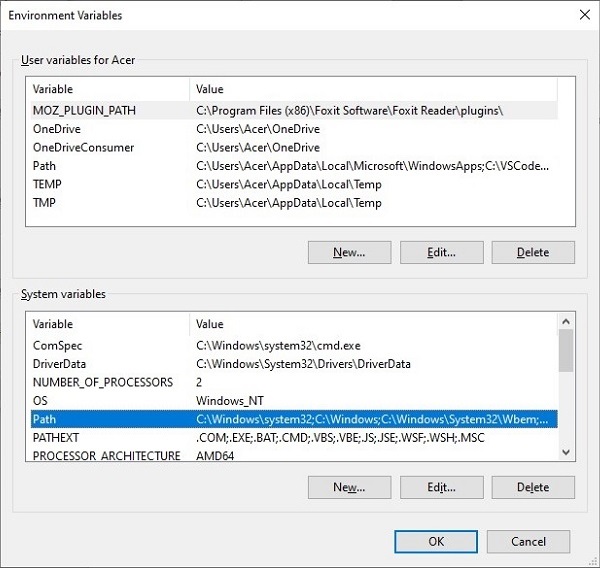
编辑 Path 变量,并添加一个新条目。输入已安装 Python 的安装文件夹的名称,然后按确定。
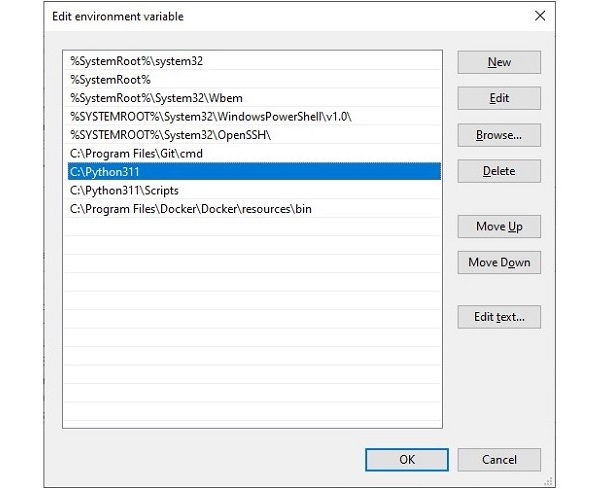
要在 Linux 中为特定会话添加 Python 目录到路径,请执行以下操作:
**在 bash shell (Linux) 中** - 输入 **export PATH="$PATH:/usr/bin/python3.11"** 并按 Enter。
Python 命令行选项
我们知道,只需调用 Python 可执行文件即可从终端调用交互式 Python 解释器。请注意,启动交互式会话不需要任何附加参数或选项。
user@ubuntu20:~$ python3.11
Python 3.11.2 (main, Feb 8 2023, 14:49:24) [GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print ("Hello World")
Hello World
>>>
Python 解释器还响应以下命令行选项:
-c <command>
解释器执行字符串中一个或多个语句,用换行符 (;) 分隔。
user@ubuntu20:~$ python3 -c "a=2;b=3;print(a+b)" 5
-m <module-name>
解释器将命名模块的内容作为 __main__ 模块执行。由于参数是模块名称,因此您不得提供文件扩展名 (.py)。
考虑以下示例。这里,标准库中的 timeit 模块具有命令行界面。-s 选项设置模块的参数。
C:\Users\Acer>python -m timeit -s "text = 'sample string'; char = 'g' 'char in text'" 5000000 loops, best of 5: 49.4 nsec per loop
<script>
解释器执行包含在具有 .py 扩展名的脚本中的 Python 代码,该扩展名必须是文件系统路径(绝对或相对)。
假设当前目录中存在一个名为 hello.py 的文本文件,其中包含 print ("Hello World") 语句。以下是脚本选项的命令行用法。
C:\Users\Acer>python hello.py Hello World
? 或 -h 或 −help
此命令行选项打印所有命令行选项和相应环境变量的简短描述并退出。
-V 或 --version
此命令行选项打印 Python 版本号
C:\Users\Acer>python -V Python 3.11.2 C:\Users\Acer>python --version Python 3.11.2
Python 环境变量
操作系统使用路径环境变量来搜索任何可执行文件(不仅仅是 Python 可执行文件)。特定于 Python 的环境变量允许您配置 Python 的行为。例如,要检查哪些文件夹位置才能导入模块。通常,Python 解释器会在当前文件夹中搜索模块。您可以设置一个或多个备用文件夹位置。
Python 环境变量可以暂时设置为当前会话,也可以像路径变量一样持久地添加到系统属性中。
PYTHONPATH
如上所述,如果您希望解释器除了当前文件夹外还要在其他文件夹中搜索模块,则一个或多个此类文件夹位置将存储为 PYTHONPATH 变量。
首先,将 **hello.py** 脚本保存在与 Python 安装文件夹不同的文件夹中,例如 **c:\modulepath\hello.py**
要使模块全局可用于解释器,请设置 PYTHONPATH
C:\Users\Acer>set PYTHONPATH= c:\modulepath C:\Users\Acer>echo %PYTHONPATH% c:\modulepath
现在,即使是从 c:\modulepath 目录以外的任何目录,您也可以导入该模块。
>>> import hello Hello World >>>
PYTHONHOME
设置此变量以更改标准 Python 库的位置。默认情况下,在 Linux 中搜索库的位置为 **/usr/local/pythonversion**,在 Windows 中为 **instalfolder\lib**。例如,**c:\python311\lib**。
PYTHONSTARTUP
通常,此变量设置为一个 Python 脚本,您希望每次启动 Python 解释器时自动执行该脚本。
让我们创建一个简单的脚本,如下所示,并将其另存为 Python 安装文件夹中的 **startup.py**:
print ("Example of Start up file")
print ("Hello World")
现在设置 PYTHONSTARTUP 变量并为其分配此文件的名称。之后启动 Python 解释器。在您获得提示符之前,它会显示此脚本的输出。
F:\311_2>set PYTHONSTARTUP=startup.py F:\311_2>echo %PYTHONSTARTUP% startup.py F:\311_2>python Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. Example of Start up file Hello World >>>
PYTHONCASEOK
此环境变量仅可在 Windows 和 macOS 上使用,而不能在 Linux 上使用。它会导致 Python 忽略 import 语句中的大小写。
PYTHONVERBOSE
如果此变量设置为非空字符串,则等效于指定 python -v 命令。每次初始化模块时,它都会打印一条消息,显示位置(文件名或内置模块)。如果设置为整数(例如 2),则等效于指定两次 -v。(python --v)。
PYTHONDONTWRITEBYTECODE
通常,导入的模块会被编译成 **.pyc** 文件。如果此变量设置为非空字符串,则在导入源模块时不会创建 .pyc 文件。
PYTHONWARNINGS
Python 的警告消息将重定向到标准错误流 **sys.stderr**。此环境变量等效于 python -W 选项。此变量允许以下值:
PYTHONWARNINGS=default # 每个调用位置警告一次
PYTHONWARNINGS=error # 转换为异常
PYTHONWARNINGS=always # 每次都警告
PYTHONWARNINGS=module # 每个调用模块警告一次
PYTHONWARNINGS=once # 每个 Python 进程警告一次
PYTHONWARNINGS=ignore # 从不警告
Python - 虚拟环境
在本节中,您将了解 Python 中的虚拟环境是什么,如何创建和使用虚拟环境来构建 Python 应用程序。
当您在计算机上安装 Python 软件时,可以从文件系统的任何位置使用它。这是系统范围的安装。
在使用 Python 开发应用程序时,可能需要使用 pip 实用程序安装一个或多个库(例如,**pip3 install somelib**)。此外,一个应用程序(例如 App1)可能需要特定版本的库(例如 **somelib 1.0**)。同时,另一个 Python 应用程序(例如 App2)可能需要同一库的新版本(例如 **somelib 2.0**)。因此,通过安装新版本,App1 的功能可能会因同一库的两个不同版本之间的冲突而受损。
可以通过在同一台机器上提供两个隔离的 Python 环境来避免此冲突。这些称为虚拟环境。虚拟环境是一个单独的目录结构,包含隔离的安装,其中包含 Python 解释器、标准库和其他模块的本地副本。
下图显示了使用虚拟环境的优势。使用全局 Python 安装,可以创建多个虚拟环境,每个环境都具有同一库的不同版本,从而避免冲突。
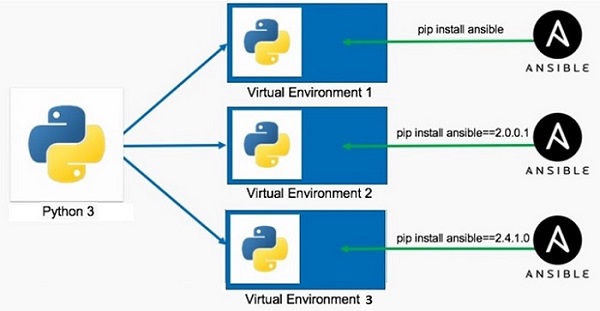
标准 Python 发行版中的 **venv** 模块支持此功能。使用以下命令创建新的虚拟环境。
C:\Users\Acer>md\pythonapp C:\Users\Acer>cd\pythonapp C:\pythonapp>python -m venv myvenv
这里,**myvenv** 是将创建新的 Python 虚拟环境的文件夹,显示以下目录结构:
Directory of C:\pythonapp\myvenv 22-02-2023 09:53 <DIR> . 22-02-2023 09:53 <DIR> .. 22-02-2023 09:53 <DIR> Include 22-02-2023 09:53 <DIR> Lib 22-02-2023 09:53 77 pyvenv.cfg 22-02-2023 09:53 <DIR> Scripts
用于激活和停用虚拟环境以及 Python 解释器的本地副本的实用程序将放置在 scripts 文件夹中。
Directory of C:\pythonapp\myvenv\scripts 22-02-2023 09:53 <DIR> . 22-02-2023 09:53 <DIR> .. 22-02-2023 09:53 2,063 activate 22-02-2023 09:53 992 activate.bat 22-02-2023 09:53 19,611 Activate.ps1 22-02-2023 09:53 393 deactivate.bat 22-02-2023 09:53 106,349 pip.exe 22-02-2023 09:53 106,349 pip3.10.exe 22-02-2023 09:53 106,349 pip3.exe 22-02-2023 09:53 242,408 python.exe 22-02-2023 09:53 232,688 pythonw.exe
要启用此新的虚拟环境,请执行 Scripts 文件夹中的 **activate.bat**。
C:\pythonapp>myvenv\scripts\activate (myvenv) C:\pythonapp>
请注意括号中的虚拟环境名称。Scripts 文件夹包含 Python 解释器的本地副本。您可以在此虚拟环境中启动 Python 会话。
要确认此 Python 会话是否在虚拟环境中,请检查 **sys.path**。
(myvenv) C:\pythonapp>python Python 3.10.1 (tags/v3.10.1:2cd268a, Dec 6 2021, 19:10:37) [MSC v.1929 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.path ['', 'C:\\Python310\\python310.zip', 'C:\\Python310\\DLLs', 'C:\\Python310\\lib', 'C:\\Python310', 'C:\\pythonapp\\myvenv', 'C:\\pythonapp\\myvenv\\lib\\site-packages'] >>>
此虚拟环境的 scripts 文件夹还包含 pip 实用程序。如果您从 PyPI 安装软件包,则该软件包仅在此虚拟环境中有效。要停用此环境,请运行deactivate.bat。
Python - 基本语法
在 Python 中,“语法”指的是构成语句或表达式的规则。Python 语言以其简洁明了的语法而闻名。与其他语言相比,它还具有有限的关键字集和更简单的标点符号规则。本章,让我们了解 Python 的基本语法。
Python 程序由预定义的关键字和标识符组成,这些标识符代表函数、类、模块等。Python 对在 Python 源代码中形成标识符、编写语句和注释有明确的规则。
Python 关键字
一组预定义的关键字是任何编程语言最重要的方面。这些关键字是保留字。它们具有预定义的含义,必须仅用于其预定义的目的以及根据预定义的语法规则。编程逻辑是用这些关键字编码的。
截至 Python 3.11 版本,Python 中有 35 (三十五) 个关键字。要获取 Python 关键字列表,请在 Python shell 中输入以下 help 命令。
>>> help("keywords")
Here is a list of the Python keywords. Enter any keyword to get more
help.
| 1. False | 10. class | 19. from | 28. or |
| 2. None | 11. continue | 20. global | 29. pass |
| 3. True | 12. def | 21. if | 30. raise |
| 4. and | 13. del | 22. import | 31. return |
| 5. as | 14. elif | 23. in | 32. try |
| 6. assert | 15. else | 24. is | 33. while |
| 7. async | 16. except | 25. lambda | 34. with |
| 8. await | 17. finally | 26. nonlocal | 35. yield |
| 9. break | 18. for | 27. not |
所有关键字都是字母的,所有关键字(除了 False、None 和 True)都小写。关键字列表也由关键字模块中定义的 kwlist 属性给出。
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
如何验证任何单词是否是关键字?大多数 Python IDE 提供彩色语法高亮显示功能,其中关键字以特定颜色表示。
下面是在 VS Code 中的 Python 代码示例。关键字(if 和 else)、标识符和常量以不同的颜色方案显示。
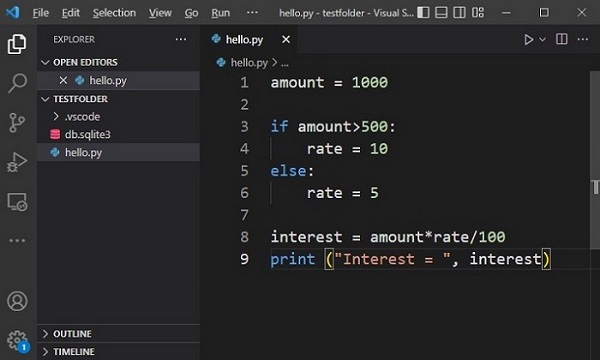
keyword 模块还有一个 iskeyword() 函数。对于有效的关键字,它返回 True,否则返回 False。
>>> import keyword
>>> keyword.iskeyword("else")
True
>>> keyword.iskeyword("Hello")
False
Python 关键字可以大致分为以下几类:
| 值关键字 | True, False, None |
| 运算符关键字 | and, or, not, in, is |
| 条件流程关键字 | if, elif, else |
| 循环控制关键字 | for, while, break, continue |
| 结构关键字 | def, class, with, pass, lambda |
| 返回关键字 | return, yield |
| 导入关键字 | import, from, as |
| 异常处理关键字 | try, except, raise, finally, assert |
| 异步编程关键字 | async, await |
| 变量作用域关键字 | del, global, nonlocal |
我们将在本教程中逐步学习每个关键字的用法。
Python 标识符
Python 程序中除关键字之外的各种元素称为标识符。标识符是用户为源代码中的变量、函数、类、模块、包等赋予的名称。Python 制定了某些规则来形成标识符。这些规则是:
标识符应以字母(小写或大写)或下划线 (_) 开头。后面可以跟一个或多个字母数字字符或下划线。
不允许使用任何关键字作为标识符,因为关键字具有预定义的含义。
按照惯例,类的名称以大写字母开头。其他元素(如变量或函数)以小写字母开头。
根据另一个 Python 约定,变量名前面的单个下划线用于指示私有变量。
在标识符开头使用两个下划线表示该变量是强私有的。
两个前导和尾随下划线在语言本身中用于特殊目的。例如,__add__,__init__
根据上述规则,以下是一些有效的标识符:
- Student
- score
- aTotal
- sum_age
- __count
- TotalValue
- price1
- cost_of_item
- __init__
以下也给出一些无效的标识符形式:
- 1001
- Name of student
- price-1
- ft.in
需要注意的是,标识符区分大小写。因此,Name 和 name 是两个不同的标识符。
Python 缩进
在代码中使用缩进是 Python 语法的重要特征之一。在程序中,您可能需要将多个语句组合在一起作为一个块。例如,如果条件为真/假,则有多个语句。不同的编程语言有不同的方法来标记类、函数、条件和循环等构造中语句组的作用域和范围。C、C++、Java 等使用花括号来标记块。Python 使用统一的缩进标记语句块,从而提高了代码的可读性。
要标记块的开头,请键入 ":" 符号并按 Enter 键。任何 Python 感知的编辑器(如 IDLE 或 VS Code)都会转到下一行,留下额外的空格(称为缩进)。块中的后续语句遵循相同的缩进级别。要指示块的结束,请通过按退格键取消缩进空格。以下示例说明了在 Python 中使用缩进的情况。
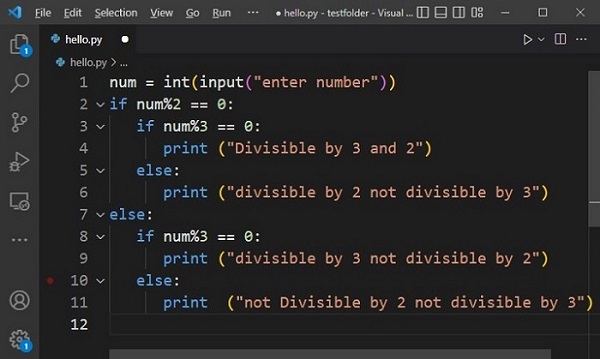
在这个阶段,您可能不理解代码是如何工作的。但不用担心。只需查看冒号符号后缩进级别是如何增加的。
Python 语句
Python 中的语句是 Python 解释器可以执行的任何指令。语句包含一个或多个关键字、运算符、标识符、用于标记块开头的 : 符号或作为续行符的反斜杠 \。
语句可以是简单的赋值语句,例如 amount = 1000,也可以是复合语句,其中多个语句分组在一起构成统一缩进的块,如条件或循环结构。
您可以在交互式 shell 的 Python 提示符前面或编辑器窗口中输入语句。通常,Python 解释器将以 Enter 键(称为换行符)结尾的文本识别为语句。因此,编辑器中的每一行都是一个语句,除非它以注释字符 (#) 开头。
print ("My first program")
price = 100
qty = 5
ttl = price*qty
print ("Total = ", ttl)
以上代码中的每一行都是一个语句。有时,Python 语句可能会跨越多行。为此,请使用反斜杠 (\) 作为续行符。长字符串可以方便地拆分为多行,如下所示:
name = "Ravi"
string = "Hello {} \
Welcome to Python Tutorial \
from TutorialsPoint".format(name)
print (string)
该字符串(包含嵌入式字符串变量名)跨越多行,以提高可读性。输出将为:
Hello Ravi Welcome to Python Tutorial from TutorialsPoint
续行符还有助于以更易读的方式编写冗长的算术表达式。
例如,方程式 $\frac{(a+b)\times (c−d)}{(a−b)\times (c+d)}$ 在 Python 中编码如下:
a=10 b=5 c=5 d=10 expr = (a+b)*(c-d)/ \ (a-b)*(c+d) print (expr)
如果列表、元组或字典对象中的项目跨越多行,则不需要使用反斜杠符号 (\)。
Subjects = ["English", "French", "Sanskrit", "Physics", "Maths", "Computer Sci", "History"]
Python 还允许使用分号在一个编辑器行中放置多个语句。查看以下示例:
a=10; b=5; c=5; d=10 if a>10: b=20; c=50
Python - 变量
在本章中,您将学习什么是 Python 中的变量以及如何使用它们。
属于不同数据类型的数据项存储在计算机的内存中。计算机的内存位置内部以二进制形式表示数字或地址。数据也以二进制形式存储,因为计算机的工作原理是基于二进制表示。在下图中,字符串May和数字18显示为存储在内存位置中。
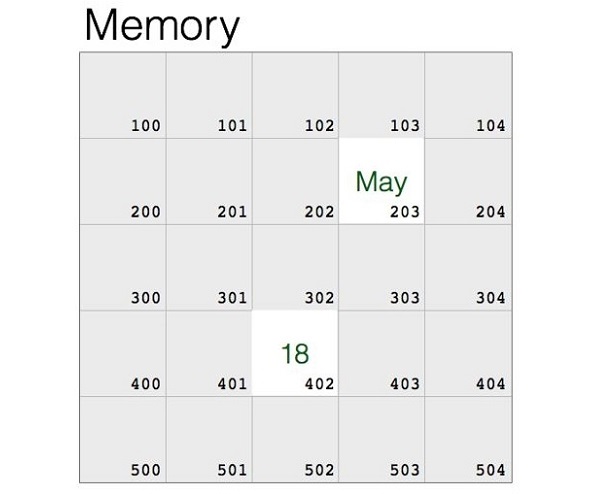
如果您了解汇编语言,您将转换这些数据项和内存地址,并发出机器语言指令。然而,这并非对每个人都容易。诸如 Python 解释器之类的语言翻译器执行这种类型的转换。它将对象存储在随机选择的内存位置中。Python 的内置id()函数返回存储对象的位置。
>>> "May"
>>> id("May")
2167264641264
>>> 18
18
>>> id(18)
140714055169352
一旦数据存储在内存中,就应该重复访问它以执行某个过程。显然,从其 ID 获取数据很麻烦。像 Python 这样的高级语言使得可以为内存位置提供合适的别名或标签。
在上面的示例中,让我们将 May 的位置标记为 month,将存储 18 的位置标记为 age。Python 使用赋值运算符 (=) 将对象与标签绑定。
>>> month="May" >>> age=18
数据对象 (May) 和其名称 (month) 具有相同的 id()。18 和 age 的 id() 也相同。
>>> id(month) 2167264641264 >>> id(age) 140714055169352
标签是一个标识符。它通常被称为变量。Python 变量是一个符号名称,它是对对象的引用或指针。
命名约定
变量名由用户指定,并遵循形成标识符的规则。
Python 变量名应以字母(小写或大写)或下划线 (_) 开头。后面可以跟一个或多个字母数字字符或下划线。
不允许使用任何关键字作为 Python 变量,因为关键字具有预定义的含义。
Python 中的变量名区分大小写。因此,age 和 Age 不能互换使用。
您应该选择助记的变量名,以便它指示目的。它不应过于简短,也不应过于冗长。
如果变量名包含多个单词,我们应该使用以下命名模式:
驼峰式命名法 - 第一个字母是小写,但每个后续单词的第一个字母是大写。例如:kmPerHour、pricePerLitre
帕斯卡命名法 - 每个单词的第一个字母都是大写。例如:KmPerHour、PricePerLitre
蛇形命名法 - 使用单个下划线 (_) 字符分隔单词。例如:km_per_hour、price_per_litre
一旦您使用变量来标识数据对象,就可以重复使用它而无需其 id() 值。在这里,我们有一个矩形的变量高度和宽度。我们可以用这些变量计算面积和周长。
>>> width=10 >>> height=20 >>> area=width*height >>> area 200 >>> perimeter=2*(width+height) >>> perimeter 60
编写脚本或程序时,变量的使用特别有利。以下脚本也使用上述变量。
#! /usr/bin/python3.11
width = 10
height = 20
area = width*height
perimeter = 2*(width+height)
print ("Area = ", area)
print ("Perimeter = ", perimeter)
使用 .py 扩展名保存上述脚本,并从命令行执行。结果将为:
Area = 200 Perimeter = 60
赋值语句
在 C/C++ 和 Java 等语言中,需要在为变量赋值之前声明变量及其类型。Python 中不需要这种变量的预先声明。
Python 使用 = 符号作为赋值运算符。变量标识符的名称出现在 = 符号的左侧。对其右侧的表达式进行求值,并将值赋给变量。以下是赋值语句的示例:
>>> counter = 10
>>> counter = 10 # integer assignment
>>> price = 25.50 # float assignment
>>> city = "Hyderabad" # String assignment
>>> subjects = ["Physics", "Maths", "English"] # List assignment
>>> mark_list = {"Rohit":50, "Kiran":60, "Lata":70} # dictionary
assignment
Python 的内置print()函数显示一个或多个变量的值。
>>> print (counter, price, city)
10 25.5 Hyderabad
>>> print (subjects)
['Physics', 'Maths', 'English']
>>> print (mark_list)
{'Rohit': 50, 'Kiran': 60, 'Lata': 70}
= 符号右侧任何表达式的值都将赋给左侧的变量。
>>> x = 5 >>> y = 10 >>> z = x+y
但是,不允许 = 运算符左侧的表达式和右侧的变量。
>>> x = 5 >>> y = 10 >>> x+y=z File "<stdin>", line 1 x+y=z ^^^ SyntaxError: cannot assign to expression here. Maybe you meant '==' instead of '='?
虽然 z=x+y 和 x+y=z 在数学上是等价的,但在这里并非如此。这是因为 = 是等式符号,而在 Python 中它是赋值运算符。
多重赋值
在 Python 中,您可以在单个语句中初始化多个变量。在以下情况下,三个变量具有相同的值。
>>> a=10 >>> b=10 >>> c=10
您可以使用以下单个赋值语句来执行此操作,而不是单独的赋值:
>>> a=b=c=10 >>> print (a,b,c) 10 10 10
在以下情况下,我们有三个具有不同值的变量。
>>> a=10 >>> b=20 >>> c=30
这些单独的赋值语句可以组合成一个。您需要在 = 运算符的左侧给出逗号分隔的变量名,在右侧给出逗号分隔的值。
>>> a,b,c = 10,20,30 >>> print (a,b,c) 10 20 30
变量的概念在 Python 中的工作方式与在 C/C++ 中不同。
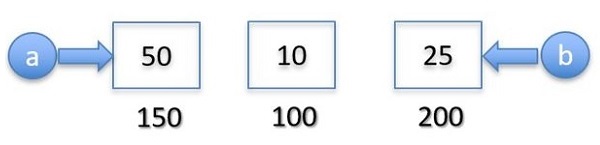
在 C/C++ 中,变量是命名的内存位置。如果 a=10 并且 b=10,则两者都是两个不同的内存位置。让我们假设它们的内存地址分别为 100 和 200。

如果为“a”赋予不同的值(例如 50),则地址 100 中的 10 将被覆盖。
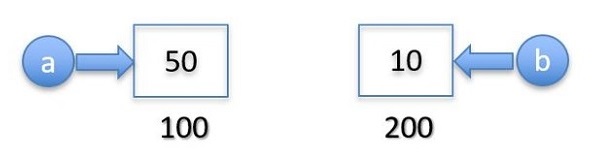
Python 变量引用的是对象本身,而不是内存位置。一个对象只在内存中存储一次。多个变量实际上是同一个对象的多个标签。
语句 a=50 在内存中的某个位置创建一个新的 **int** 对象 50,而对象 10 仍然被 "b" 引用。

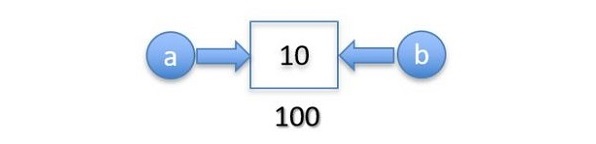
此外,如果你将另一个值赋给 b,对象 10 将保持未被引用状态。
Python 的垃圾回收机制会释放任何未被引用的对象占用的内存。
Python 的身份运算符 **is** 如果两个操作数具有相同的 id() 值,则返回 True。
>>> a=b=10 >>> a is b True >>> id(a), id(b) (140731955278920, 140731955278920)
Python - 数据类型
计算机是一种数据处理设备。计算机将数据存储在其内存中,并根据给定的程序对其进行处理。数据是对某个对象的事实的一种表示。
一些数据的例子:
**学生数据** - 姓名、性别、班级、分数、年龄、费用等。
**图书馆书籍数据** - 书名、作者、出版商、价格、页数、出版年份等。
**办公室员工数据** - 姓名、职位、薪水、部门、分公司等。
数据类型表示一种值,并决定可以对其执行哪些操作。数值、非数值和布尔值(true/false)数据是最明显的数据类型。但是,每种编程语言都有其自身的分类,这在很大程度上反映了其编程理念。
Python 根据下图所示的不同数据类型来识别数据:
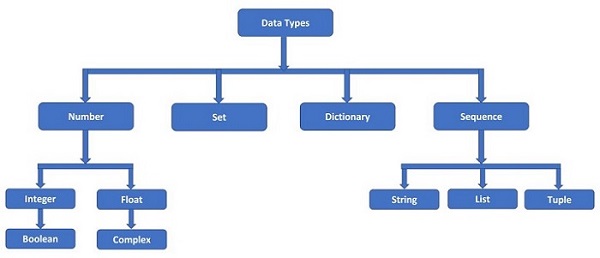
Python 的数据模型定义了四种主要数据类型:数字、序列、集合和字典(也称为映射)。
数字类型
任何具有数值的数据项都是数字。Python 中有四种标准的数字数据类型:整数、浮点数、布尔值和复数。它们在 Python 库中都有内置的类,分别称为 **int、float、bool** 和 **complex**。
在 Python 中,数字是其对应类的对象。例如,整数 123 是 **int** 类的对象。类似地,9.99 是一个浮点数,它是 float 类的对象。
Python 的标准库有一个内置函数 **type()**,它返回给定对象的类。在这里,它用于检查整数和浮点数的类型。
>>> type(123) <class 'int'> >>> type(9.99) <class 'float'>
浮点数的小数部分也可以用 **科学计数法** 表示。数字 -0.000123 等效于其科学计数法 1.23E-4(或 1.23e-4)。
复数由两部分组成:**实部** 和 **虚部**。它们由 '+' 或 '-' 符号分隔。虚部后缀为 'j',它是虚数单位。-1 的平方根 ($\sqrt{−1}$) 定义为虚数。Python 中的复数表示为 x+yj,其中 x 是实部,y 是虚部。因此,5+6j 是一个复数。
>>> type(5+6j) <class 'complex'>
布尔值只有两个可能的值,分别由关键字 **True** 和 **False** 表示。它们分别对应于整数 1 和 0。
>>> type (True) <class 'bool'> >>> type(False) <class 'bool'>
使用 Python 的算术运算符,可以执行加法、减法等运算。
序列类型
序列是一种集合数据类型。它是一个有序的项目集合。序列中的项目具有从 0 开始的位置索引。它在概念上类似于 C 或 C++ 中的数组。Python 中定义了三种序列类型:字符串、列表和元组。
Python 中的字符串
字符串是由一个或多个 Unicode 字符组成的序列,用单引号、双引号或三引号(也称为反引号)括起来。只要字符序列相同,单引号、双引号或三引号就没有区别。因此,以下字符串表示方式是等效的。
>>> 'Welcome To TutorialsPoint' 'Welcome To TutorialsPoint' >>> "Welcome To TutorialsPoint" 'Welcome To TutorialsPoint' >>> '''Welcome To TutorialsPoint''' 'Welcome To TutorialsPoint'
Python 中的字符串是 **str** 类的对象。可以使用 **type()** 函数进行验证。
>>> type("Welcome To TutorialsPoint")
<class 'str'>
如果要将一些用双引号括起来的文本嵌入到字符串中,则字符串本身应该用单引号括起来。要嵌入用单引号括起来的文本,字符串应该用双引号括起来。
>>> 'Welcome to "Python Tutorial" from TutorialsPoint' 'Welcome to "Python Tutorial" from TutorialsPoint' >>> "Welcome to 'Python Tutorial' from TutorialsPoint" "Welcome to 'Python Tutorial' from TutorialsPoint"
由于字符串是一个序列,因此其中的每个字符都具有从 0 开始的位置索引。要使用三引号构成字符串,可以使用三个单引号或三个双引号——这两个版本是类似的。
>>> '''Welcome To TutorialsPoint''' 'Welcome To TutorialsPoint' >>> """Welcome To TutorialsPoint""" 'Welcome To TutorialsPoint'
三引号字符串可用于构成多行字符串。
>>> ''' ... Welcome To ... Python Tutorial ... from TutorialsPoint ... ''' '\nWelcome To\nPython Tutorial \nfrom TutorialsPoint\n'
字符串是一种非数值数据类型。显然,我们不能对其执行算术运算。但是,可以执行诸如 **切片** 和 **连接** 等操作。Python 的 str 类定义了许多用于字符串处理的有用方法。我们将在后续关于字符串的章节中学习这些方法。
Python 中的列表
在 Python 中,列表是任何类型数据项的有序集合。数据项用逗号 (,) 分隔,并用方括号 (**[]**) 括起来。列表也是一个序列,因此。
列表中的每个项目都有一个索引,用于指明其在集合中的位置。索引从 0 开始。
Python 中的列表看起来类似于 C 或 C++ 中的数组。但是,两者之间存在一个重要的区别。在 C/C++ 中,数组是同类型数据的同质集合。Python 列表中的项目可以是不同类型的。
>>> [2023, "Python", 3.11, 5+6j, 1.23E-4]
Python 中的列表是 **list** 类的对象。我们可以使用 type() 函数进行检查。
>>> type([2023, "Python", 3.11, 5+6j, 1.23E-4]) <class 'list'>
如前所述,列表中的项目可以是任何数据类型。这意味着列表对象也可以是另一个列表中的项目。在这种情况下,它将成为嵌套列表。
>>> [['One', 'Two', 'Three'], [1,2,3], [1.0, 2.0, 3.0]]
列表项也可以是元组、字典、集合或用户定义类的对象。
列表作为序列,它支持与字符串一样切片和连接操作。使用 Python 内置列表类中提供的方法/函数,我们可以添加、删除或更新项目,并按所需顺序对项目进行排序或重新排列。我们将在后续章节中学习这些方面。
Python 中的元组
在 Python 中,元组是任何类型数据项的有序集合。数据项用逗号 (,) 分隔,并用圆括号 () 括起来。元组也是一个序列,因此元组中的每个项目都有一个索引,用于指明其在集合中的位置。索引从 0 开始。
>>> (2023, "Python", 3.11, 5+6j, 1.23E-4)
在 Python 中,元组是 **tuple** 类的对象。我们可以使用 type() 函数进行检查。
>>> type((2023, "Python", 3.11, 5+6j, 1.23E-4)) <class 'tuple'>
与列表一样,元组中的项目也可以是列表、元组本身或任何其他 Python 类的对象。
>>> (['One', 'Two', 'Three'], 1,2.0,3, (1.0, 2.0, 3.0))
要形成元组,圆括号是可选的。用逗号分隔的数据项,没有任何包围符号,默认情况下被视为元组。
>>> 2023, "Python", 3.11, 5+6j, 1.23E-4 (2023, 'Python', 3.11, (5+6j), 0.000123)
列表和元组这两种序列类型看起来很相似,只是分隔符不同,列表使用方括号 ([]),而元组使用圆括号。但是,列表和元组之间存在一个主要
区别。列表是可变对象,而元组是 **不可变** 的。不可变对象意味着一旦它存储在内存中,就不能更改。
让我们尝试理解可变性的概念。我们有一个具有相同数据项的列表和元组对象。
>>> l1=[1,2,3] >>> t1=(1,2,3)
两者都是序列,因此两者中的每个项目都有一个索引。两者中索引号为 1 的项目都是 2。
>>> l1[1] 2 >>> t1[1] 2
让我们尝试将列表和元组中索引号为 1 的项目的值从 2 更改为 20。
>>> l1[1] 2 >>> t1[1] 2 >>> l1[1]=20 >>> l1 [1, 20, 3] >>> t1[1]=20 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
错误消息 **'tuple' object does not support item assignment** 告诉您,一旦形成元组对象,就不能对其进行修改。这称为不可变对象。
元组的不可变性还意味着 Python 的 tuple 类不具有在元组中添加、删除或排序项目的功能。但是,由于它是一个序列,我们可以执行切片和连接操作。
字典类型
Python 的字典是 **映射** 类型的一个例子。映射对象将一个对象的价值与另一个对象映射。在语言字典中,我们有单词及其相应含义的配对。配对的两部分是键(单词)和值(含义)。类似地,Python 字典也是 **键:值** 对的集合。这些对用逗号分隔,并放在花括号 {} 中。为了在键和值之间建立映射,在两者之间使用分号 ':' 符号。
>>> {1:'one', 2:'two', 3:'three'}
字典中的每个键必须唯一,并且应该是数字、字符串或元组。值对象可以是任何类型,并且可以与多个键映射(它们不必唯一)。
在 Python 中,字典是内置 **dict** 类的对象。我们可以使用 type() 函数进行检查。
>>> type({1:'one', 2:'two', 3:'three'})
<class 'dict'>
Python 的字典不是序列。它是一个项目集合,但每个项目(键:值对)不像字符串、列表或元组那样由位置索引标识。因此,不能对字典执行切片操作。字典是可变对象,因此可以使用 dict 类中定义的相应功能执行添加、修改或删除操作。这些操作将在后续章节中解释。
集合类型
集合是 Python 对数学中定义的集合的实现。Python 中的集合是一个集合,但它不是像字符串、列表或元组那样有索引或有序的集合。集合中不能出现多个相同的对象,而在列表和元组中,同一个对象可以出现多次。
集合中用逗号分隔的项目放在花括号中。集合中的项目可以是不同数据类型的。
>>> {2023, "Python", 3.11, 5+6j, 1.23E-4}
{(5+6j), 3.11, 0.000123, 'Python', 2023}
请注意,集合中的项目可能不遵循输入时的顺序。Python 会优化项目的位置,以便根据数学中定义的集合执行操作。
Python 的集合是内置 **set** 类的对象,可以使用 type() 函数进行检查。
>>> type({2023, "Python", 3.11, 5+6j, 1.23E-4})
<class 'set'>
集合只能存储不可变对象,例如数字(int、float、complex 或 bool)、字符串或元组。如果你试图将列表或字典放入集合中,Python 将引发 **TypeError**。
>>> {['One', 'Two', 'Three'], 1,2,3, (1.0, 2.0, 3.0)}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
**哈希** 是计算机科学中的一种机制,它可以更快地在计算机内存中搜索对象。**只有不可变对象才是可哈希的**。
即使集合不允许可变项,集合本身也是可变的。因此,可以使用内置 set 类中的方法对集合对象执行添加/删除/更新操作。Python 还有一组运算符来执行集合操作。这些方法和运算符将在后面的章节中解释。
Python - 类型转换
在制造业中,铸造是将液态或熔融金属浇入模具中,然后使其冷却以获得所需形状的过程。在编程中,强制类型转换是指将一个类型的对象转换为另一种类型。在这里,我们将学习 Python 中的类型转换。
在Python中,存在不同的数据类型,例如数字、序列、映射等。你可能会遇到这种情况:你拥有某种类型的数据,但想以另一种形式使用它。例如,用户输入了一个字符串,但你想将其用作数字。Python的类型转换机制允许你做到这一点。
Python中的隐式转换
转换分为两种类型——**隐式**和**显式**。
当任何语言的编译器/解释器自动将一种类型对象转换为另一种类型时,这称为隐式转换。Python是一种强类型语言。它不允许在不相关的类型之间进行自动类型转换。例如,字符串不能转换为任何数字类型。但是,整数可以转换为浮点数。其他语言,例如JavaScript,是一种弱类型语言,其中整数会被强制转换为字符串以进行连接。
请注意,每种类型的内存需求不同。例如,Python中的整数对象占用4个字节的内存,而浮点数对象由于其小数部分需要8个字节。因此,Python解释器不会自动将浮点数转换为整数,因为这会导致数据丢失。另一方面,通过将其小数部分设置为0,可以轻松地将整数转换为浮点数。
当对一个整数和一个浮点数操作数进行任何算术运算时,就会发生隐式整数到浮点数的转换。
我们有一个整数和一个浮点变量
>>> a=10 # int object >>> b=10.5 # float object
为了执行它们的加法,整数对象10被升级为10.0。它是一个浮点数,但等效于其之前的数值。现在我们可以执行两个浮点数的加法。
>>> c=a+b >>> print (c) 20.5
在隐式类型转换中,字节大小较小的对象会被升级以匹配运算中其他对象的字节大小。例如,布尔对象在与浮点数对象相加之前,首先被升级为整数,然后升级为浮点数。在下面的示例中,我们尝试将布尔对象添加到浮点数中。
>>> a=True >>> b=10.5 >>> c=a+b >>> print (c) 11.5
请注意,True 等于 1,False 等于 0。
尽管自动或隐式转换仅限于**int**到**float**的转换,但可以使用Python的内置函数执行显式转换,例如将字符串转换为整数。
int() 函数
Python的内置int()函数将整数字面量转换为整数对象,将浮点数转换为整数,如果字符串本身具有有效的整数字面量表示形式,则将字符串转换为整数。
使用int()函数并传入int对象作为参数等效于直接声明一个**int**对象。
>>> a = int(10) >>> a 10
与以下相同:
>>> a = 10 >>> a 10 >>> type(a) <class 'int>
如果int()函数的参数是浮点数对象或浮点表达式,它将返回一个int对象。例如:
>>> a = int(10.5) #converts a float object to int >>> a 10 >>> a = int(2*3.14) #expression results float, is converted to int >>> a 6 >>> type(a) <class 'int'>
如果给定布尔对象作为参数,int()函数也会返回整数1。
>>> a=int(True) >>> a 1 >>> type(a) <class 'int'>
字符串转换为整数
int()函数仅当字符串包含有效的整数表示形式时,才从字符串对象返回整数。
>>> a = int("100")
>>> a
100
>>> type(a)
<class 'int'>
>>> a = ("10"+"01")
>>> a = int("10"+"01")
>>> a
1001
>>> type(a)
<class 'int'>
但是,如果字符串包含非整数表示形式,Python将引发ValueError。
>>> a = int("10.5")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '10.5'
>>> a = int("Hello World")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'Hello World'
int()函数还可以从二进制、八进制和十六进制字符串返回整数。为此,函数需要一个base参数,该参数必须分别为2、8或16。字符串应该具有有效的二进制/八进制/十六进制表示形式。
二进制字符串转换为整数
字符串应仅由1和0组成,基数应为2。
>>> a = int("110011", 2)
>>> a
51
二进制数110011的十进制等效值为51。
八进制字符串转换为整数
字符串应仅包含0到7的数字,基数应为8。
>>> a = int("20", 8)
>>> a
16
八进制20的十进制等效值为16。
十六进制字符串转换为整数
字符串应仅包含十六进制符号,即0-9和A、B、C、D、E或F。基数应为16。
>>> a = int("2A9", 16)
>>> a
681
十六进制2A9的十进制等效值为681。
你可以使用Windows、Ubuntu或智能手机上的计算器应用程序轻松验证这些转换。
float() 函数
float()是Python中的内置函数。如果参数是浮点字面量、整数或具有有效浮点表示形式的字符串,它将返回一个浮点数对象。
使用float()函数并传入float对象作为参数等效于直接声明一个float对象。
>>> a = float(9.99) >>> a 9.99 >>> type(a) <class 'float'>
与以下相同:
>>> a = 9.99 >>> a 9.99 >>> type(a) <class 'float'>
如果float()函数的参数是整数,则返回值是一个浮点数,其小数部分设置为0。
>>> a = float(100) >>> a 100.0 >>> type(a) <class 'float'>
如果字符串包含有效的浮点数,float()函数将从字符串返回浮点数对象;否则,将引发ValueError。
>>> a = float("9.99")
>>> a
9.99
>>> type(a)
<class 'float'>
>>> a = float("1,234.50")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: could not convert string to float: '1,234.50'
这里出现ValueError的原因是字符串中存在逗号。
为了进行字符串到浮点数的转换,浮点数的科学计数法也被认为是有效的。
>>> a = float("1.00E4")
>>> a
10000.0
>>> type(a)
<class 'float'>
>>> a = float("1.00E-4")
>>> a
0.0001
>>> type(a)
<class 'float'>
str() 函数
我们看到了Python如何从相应的字符串表示中获取整数或浮点数。str()函数则相反。它用引号(')包围整数或浮点数对象以返回一个str对象。str()函数返回字符串。
任何Python对象的表示。在本节中,我们将看到Python中str()函数的不同示例。
str()函数具有三个参数。第一个必需参数(或自变量)是我们要获取其字符串表示的对象。其他两个运算符encoding和errors是可选的。
我们将在Python控制台中执行str()函数,以轻松验证返回的对象是一个字符串,并带有包围的引号(') 。
整数转换为字符串
>>> a = str(10) >>> a '10' >>> type(a) <class 'str'>
浮点数转换为字符串
str()函数将具有两种浮点数表示法的浮点数对象转换为字符串对象:标准表示法(用小数点分隔整数和小数部分)和科学计数法。
>>> a=str(11.10) >>> a '11.1' >>> type(a) <class 'str'> >>> a = str(2/5) >>> a '0.4' >>> type(a) <class 'str'>
在第二种情况下,除法表达式作为参数传递给str()函数。请注意,表达式首先被求值,然后结果被转换为字符串。
使用E或e以及正负幂的科学计数法表示的浮点数将使用str()函数转换为字符串。
>>> a=str(10E4) >>> a '100000.0' >>> type(a) <class 'str'> >>> a=str(1.23e-4) >>> a '0.000123' >>> type(a) <class 'str'>
当布尔常量作为参数输入时,它会被(')包围,以便True变为'True'。列表和元组对象也可以作为参数传递给str()函数。生成的字符串是被(')包围的列表/元组。
>>> a=str('True')
>>> a
'True'
>>> a=str([1,2,3])
>>> a
'[1, 2, 3]'
>>> a=str((1,2,3))
>>> a
'(1, 2, 3)'
>>> a=str({1:100, 2:200, 3:300})
>>> a
'{1: 100, 2: 200, 3: 300}'
序列类型的转换
列表、元组和字符串是Python的序列类型。它们是有序或索引的项目集合。
可以使用**list()**函数将字符串和元组转换为列表对象。类似地,**tuple()**函数将字符串或列表转换为元组。
我们将创建这三种序列类型的对象,并研究它们的相互转换。
>>> a=[1,2,3,4,5]
>>> b=(1,2,3,4,5)
>>> c="Hello"
### list() separates each character in the string and builds the list
>>> obj=list(c)
>>> obj
['H', 'e', 'l', 'l', 'o']
### The parentheses of tuple are replaced by square brackets
>>> obj=list(b)
>>> obj
[1, 2, 3, 4, 5]
### tuple() separates each character from string and builds a tuple of
characters
>>> obj=tuple(c)
>>> obj
('H', 'e', 'l', 'l', 'o')
### square brackets of list are replaced by parentheses.
>>> obj=tuple(a)
>>> obj
(1, 2, 3, 4, 5)
### str() function puts the list and tuple inside the quote symbols.
>>> obj=str(a)
>>> obj
'[1, 2, 3, 4, 5]'
>>> obj=str(b)
>>> obj
'(1, 2, 3, 4, 5)'
因此,Python的显式类型转换功能允许在内置函数的帮助下将一种数据类型转换为另一种数据类型。
Python - Unicode 系统
软件应用程序通常需要以多种不同的语言(例如英语、法语、日语、希伯来语或印地语)显示输出消息。Python的字符串类型使用Unicode标准来表示字符。它使程序能够处理所有这些不同的字符。
字符是文本中最小的组成部分。'A'、'B'、'C'等都是不同的字符。'È'和'Í'也是如此。
根据Unicode标准,字符由码点表示。码点值是0到0x10FFFF范围内的整数。
码点序列在内存中表示为一组码元,映射到8位字节。将Unicode字符串转换为字节序列的规则称为字符编码。
存在三种类型的编码:UTF-8、UTF-16和UTF-32。UTF代表**Unicode转换格式**。
从Python 3.0开始,内置支持Unicode。**str**类型包含Unicode字符,因此使用单引号、双引号或三引号字符串语法创建的任何字符串都存储为Unicode。Python源代码的默认编码为UTF-8。
因此,字符串可能包含Unicode字符的字面表示(3/4)或其Unicode值(\u00BE)。
var = "3/4" print (var) var = "\u00BE" print (var)
以上代码将产生以下**输出**:
'3/4' 3/4
在下面的示例中,字符串'10'使用1和0的Unicode值存储,它们分别是\u0031和u0030。
var = "\u0031\u0030" print (var)
它将产生以下**输出**:
10
字符串以人类可读的格式显示文本,而字节以二进制数据存储字符。编码将数据从字符字符串转换为一系列字节。解码将字节转换回人类可读的字符和符号。重要的是不要
混淆这两种方法。encode是字符串方法,而decode是Python字节对象的方。
在下面的示例中,我们有一个字符串变量,其中包含ASCII字符。ASCII是Unicode字符集的子集。encode()方法用于将其转换为字节对象。
string = "Hello"
tobytes = string.encode('utf-8')
print (tobytes)
string = tobytes.decode('utf-8')
print (string)
decode()方法将字节对象转换回str对象。使用的编码方法是utf-8。
b'Hello' Hello
在下面的示例中,卢比符号(₹)使用其Unicode值存储在变量中。我们将字符串转换为字节,然后转换回str。
string = "\u20B9"
print (string)
tobytes = string.encode('utf-8')
print (tobytes)
string = tobytes.decode('utf-8')
print (string)
执行上述代码时,将产生以下**输出**:
₹ b'\xe2\x82\xb9' ₹
Python - 字面量
在计算机科学中,字面量是在源代码中表示固定值的表示法。例如,在赋值语句中。
x = 10
这里10是一个字面量,因为表示10的数值直接存储在内存中。但是,
y = x*2
这里,即使表达式计算结果为20,它也没有直接包含在源代码中。你也可以使用内置的int()函数声明一个int对象:
x = int(10)
但是,这也是一种间接的实例化方式,而不是字面量。
你可以使用字面量表示法来创建任何内置数据类型的对象。
整数字面量
任何仅包含数字符号(0到9)的表示法都会创建一个**int**类型的对象。使用赋值运算符,可以将如此声明的对象由变量引用。
请看下面的**示例**:
x = 10 y = -25 z = 0
Python允许将整数表示为八进制数或十六进制数。仅包含八个数字符号(0到7)但以0o或0O为前缀的数字表示是八进制数。
x = 0O34
类似地,一系列十六进制符号(0到9以及a到f),以0x或0X为前缀,表示十六进制形式的整数。
x = 0X1C
但是,需要注意的是,即使使用八进制或十六进制字面量表示法,Python在内部仍将其视为**int**类型。
# Using Octal notation
x = 0O34
print ("0O34 in octal is", x, type(x))
# Using Hexadecimal notation
x = 0X1c
print ("0X1c in Hexadecimal is", x, type(x))
运行此代码时,将产生以下**输出**:
0O34 in octal is 28 <class 'int'> 0X1c in Hexadecimal is 28 <class 'int'>
浮点字面量
浮点数由整数部分和小数部分组成。按照惯例,小数点符号(.)在浮点数的字面量表示中分隔这两个部分。例如,
x = 25.55 y = 0.05 z = -12.2345
对于过大或过小的浮点数,如果小数点前或后的位数过多,则使用科学计数法进行紧凑的字面表示。整数部分之后跟着 E 或 e 符号,后面跟着正整数或负整数。
例如,数字 1.23E05 等于 123000.00。类似地,1.23e-2 等于 0.0123
# Using normal floating point notation
x = 1.23
print ("1.23 in normal float literal is", x, type(x))
# Using Scientific notation
x = 1.23E5
print ("1.23E5 in scientific notation is", x, type(x))
x = 1.23E-2
print ("1.23E-2 in scientific notation is", x, type(x))
在这里,您将得到以下输出:
1.23 in normal float literal is 1.23 <class 'float'> 1.23E5 in scientific notation is 123000.0 <class 'float''> 1.23E-2 in scientific notation is 0.0123 <class 'float''>
复数字面量
复数由实部和虚部组成。虚部是任何数字(整数或浮点数)乘以“-1”的平方根。
($\sqrt{−1}$)。在字面表示中,($\sqrt{−1}$) 用 "j" 或 "J" 表示。因此,复数的字面表示形式为 x+yj。
#Using literal notation of complex number
x = 2+3j
print ("2+3j complex literal is", x, type(x))
y = 2.5+4.6j
print ("2.5+4.6j complex literal is", x, type(x))
这段代码将产生以下输出:
2+3j complex literal is (2+3j) <class 'complex'> 2.5+4.6j complex literal is (2+3j) <class 'complex'>
字符串字面量
字符串对象是 Python 中的序列数据类型之一。它是 Unicode 代码点的不可变序列。代码点是一个数字,根据 Unicode 标准对应于一个字符。字符串是 Python 内置类 'str' 的对象。
字符串字面量是用单引号 ('hello')、双引号 ("hello") 或三引号 ('''hello''' 或 """hello""") 将一系列字符括起来来编写的。
var1='hello'
print ("'hello' in single quotes is:", var1, type(var1))
var2="hello"
print ('"hello" in double quotes is:', var1, type(var1))
var3='''hello'''
print ("''''hello'''' in triple quotes is:", var1, type(var1))
var4="""hello"""
print ('"""hello""" in triple quotes is:', var1, type(var1))
在这里,您将得到以下输出:
'hello' in single quotes is: hello <class 'str'> "hello" in double quotes is: hello <class 'str'> ''''hello'''' in triple quotes is: hello <class 'str'> """hello""" in triple quotes is: hello <class 'str'>
如果需要将双引号作为字符串的一部分嵌入,则字符串本身应放在单引号中。另一方面,如果要嵌入单引号文本,则字符串应放在双引号中。
var1='Welcome to "Python Tutorial" from TutorialsPoint' print (var1) var2="Welcome to 'Python Tutorial' from TutorialsPoint" print (var2)
它将产生以下**输出**:
Welcome to "Python Tutorial" from TutorialsPoint Welcome to 'Python Tutorial' from TutorialsPoint
列表字面量
Python 中的列表对象是其他数据类型对象的集合。列表是有序的项目集合,这些项目不一定是相同类型的。集合中的各个对象通过从零开始的索引访问。
列表对象的字面表示是用一个或多个项目完成的,这些项目用逗号分隔,并用方括号 [] 括起来。
L1=[1,"Ravi",75.50, True] print (L1, type(L1))
它将产生以下**输出**:
[1, 'Ravi', 75.5, True] <class 'list'>
元组字面量
Python 中的元组对象是其他数据类型对象的集合。元组是有序的项目集合,这些项目不一定是相同类型的。集合中的各个对象通过从零开始的索引访问。
元组对象的字面表示是用一个或多个项目完成的,这些项目用逗号分隔,并用圆括号 () 括起来。
T1=(1,"Ravi",75.50, True) print (T1, type(T1))
它将产生以下**输出**:
[1, 'Ravi', 75.5, True] <class tuple>
Python 序列的默认分隔符是圆括号,这意味着没有圆括号的逗号分隔序列也相当于元组的声明。
T1=1,"Ravi",75.50, True print (T1, type(T1))
在这里,您也将得到相同的输出:
[1, 'Ravi', 75.5, True] <class tuple>
字典字面量
与列表或元组一样,字典也是一种集合数据类型。但是,它不是序列。它是一个无序的项目集合,每个项目都是一个键值对。值通过 ":" 符号绑定到键。用逗号分隔的一个或多个键值对放在花括号内,形成一个字典对象。
capitals={"USA":"New York", "France":"Paris", "Japan":"Tokyo",
"India":"New Delhi"}
numbers={1:"one", 2:"Two", 3:"three",4:"four"}
points={"p1":(10,10), "p2":(20,20)}
键应该是不可变的对象。数字、字符串或元组可以用作键。一个集合中键不能出现多次。如果一个键出现多次,则只保留最后一个。值可以是任何数据类型。一个值可以分配给多个键。例如:
staff={"Krishna":"Officer", "Rajesh":"Manager", "Ragini":"officer", "Anil":"Clerk", "Kavita":"Manager"}
Python - 运算符
在 Python 以及任何编程语言中,运算符都是预定义的符号(有时是关键字),用于对一个或多个操作数执行某些最常用的操作。
运算符类型
Python 语言支持以下类型的运算符:
算术运算符
比较(关系)运算符
赋值运算符
逻辑运算符
位运算符
成员运算符
身份运算符
让我们逐一看看这些运算符。
Python - 算术运算符
在 Python 中,数字是最常用的数据类型。Python 使用与大家熟悉的算术基本运算相同的符号,即 "+" 表示加法,“-” 表示减法,“*” 表示乘法(大多数编程语言使用 "*" 代替数学/代数中使用的 "x"),“/” 表示除法(同样代替数学中使用的 "÷")。
此外,Python 还定义了更多算术运算符。它们是 "%"(模运算)、"**"(指数运算)和 "//"(地板除)。
算术运算符是二元运算符,因为它们作用于两个操作数。Python 完全支持混合算术。也就是说,这两个操作数可以是两种不同的数字类型。在这种情况下,Python 会扩展较窄的操作数。整数对象比浮点数对象窄,浮点数比复数对象窄。因此,整数和浮点数的算术运算结果是浮点数。浮点数和复数的结果是复数,类似地,整数和复数对象的运算结果是复数对象。
让我们用例子来学习这些运算符。
Python - 加法运算符 (+)
这个运算符读作加号,是一个基本的算术运算符。它将两侧的两个数值操作数相加并返回加法结果。
在下面的示例中,两个整型变量是 "+" 运算符的操作数。
a=10
b=20
print ("Addition of two integers")
print ("a =",a,"b =",b,"addition =",a+b)
它将产生以下**输出**:
Addition of two integers a = 10 b = 20 addition = 30
整数和浮点数相加的结果是浮点数。
a=10
b=20.5
print ("Addition of integer and float")
print ("a =",a,"b =",b,"addition =",a+b)
它将产生以下**输出**:
Addition of integer and float a = 10 b = 20.5 addition = 30.5
将浮点数加到复数的结果是复数。
a=10+5j
b=20.5
print ("Addition of complex and float")
print ("a=",a,"b=",b,"addition=",a+b)
它将产生以下**输出**:
Addition of complex and float a= (10+5j) b= 20.5 addition= (30.5+5j)
Python - 减法运算符 (-)
这个运算符,称为减号,从第一个操作数中减去第二个操作数。如果第二个操作数较大,则结果数为负数。
第一个例子显示了两个整数的减法。
a=10
b=20
print ("Subtraction of two integers:")
print ("a =",a,"b =",b,"a-b =",a-b)
print ("a =",a,"b =",b,"b-a =",b-a)
结果:
Subtraction of two integers a = 10 b = 20 a-b = -10 a = 10 b = 20 b-a = 10
整数和浮点数的减法遵循相同的原理。
a=10
b=20.5
print ("subtraction of integer and float")
print ("a=",a,"b=",b,"a-b=",a-b)
print ("a=",a,"b=",b,"b-a=",b-a)
它将产生以下**输出**:
subtraction of integer and float a= 10 b= 20.5 a-b= -10.5 a= 10 b= 20.5 b-a= 10.5
在涉及复数和浮点数的减法中,参与运算的是实部。
a=10+5j
b=20.5
print ("subtraction of complex and float")
print ("a=",a,"b=",b,"a-b=",a-b)
print ("a=",a,"b=",b,"b-a=",b-a)
它将产生以下**输出**:
subtraction of complex and float a= (10+5j) b= 20.5 a-b= (-10.5+5j) a= (10+5j) b= 20.5 b-a= (10.5-5j)
Python - 乘法运算符 (*)
*(星号)符号在 Python 中定义为乘法运算符(在许多语言中也是如此)。它返回其两侧两个操作数的乘积。如果任何一个操作数为负,则结果也为负。如果两个都是负数,则结果为正数。更改操作数的顺序不会更改结果
a=10
b=20
print ("Multiplication of two integers")
print ("a =",a,"b =",b,"a*b =",a*b)
它将产生以下**输出**:
Multiplication of two integers a = 10 b = 20 a*b = 200
在乘法中,浮点操作数可以具有标准小数点表示法或科学计数法。
a=10
b=20.5
print ("Multiplication of integer and float")
print ("a=",a,"b=",b,"a*b=",a*b)
a=-5.55
b=6.75E-3
print ("Multiplication of float and float")
print ("a =",a,"b =",b,"a*b =",a*b)
它将产生以下**输出**:
Multiplication of integer and float a = 10 b = 20.5 a-b = -10.5 Multiplication of float and float a = -5.55 b = 0.00675 a*b = -0.037462499999999996
对于涉及一个复数操作数的乘法运算,另一个操作数会乘以复数的实部和虚部。
a=10+5j
b=20.5
print ("Multiplication of complex and float")
print ("a =",a,"b =",b,"a*b =",a*b)
它将产生以下**输出**:
Multiplication of complex and float a = (10+5j) b = 20.5 a*b = (205+102.5j)
Python - 除法运算符 (/)
"/" 符号通常称为正斜杠。除法运算符的结果是分子(左操作数)除以分母(右操作数)。如果任何一个操作数为负,则结果数为负。由于无穷大无法存储在内存中,如果分母为 0,则 Python 会引发 ZeroDivisionError。
在 Python 中,除法运算符的结果始终是浮点数,即使两个操作数都是整数。
a=10
b=20
print ("Division of two integers")
print ("a=",a,"b=",b,"a/b=",a/b)
print ("a=",a,"b=",b,"b/a=",b/a)
它将产生以下**输出**:
Division of two integers a= 10 b= 20 a/b= 0.5 a= 10 b= 20 b/a= 2.0
在除法中,浮点操作数可以具有标准小数点表示法或科学计数法。
a=10
b=-20.5
print ("Division of integer and float")
print ("a=",a,"b=",b,"a/b=",a/b)
a=-2.50
b=1.25E2
print ("Division of float and float")
print ("a=",a,"b=",b,"a/b=",a/b)
它将产生以下**输出**:
Division of integer and float a= 10 b= -20.5 a/b= -0.4878048780487805 Division of float and float a= -2.5 b= 125.0 a/b= -0.02
当其中一个操作数是复数时,会发生另一个操作数与复数对象的两部分(实部和虚部)之间的除法。
a=7.5+7.5j
b=2.5
print ("Division of complex and float")
print ("a =",a,"b =",b,"a/b =",a/b)
print ("a =",a,"b =",b,"b/a =",b/a)
它将产生以下**输出**:
Division of complex and float a = (7.5+7.5j) b = 2.5 a/b = (3+3j) a = (7.5+7.5j) b = 2.5 b/a = (0.16666666666666666-0.16666666666666666j)
如果分子为 0,则除法的结果始终为 0,除非分母为 0,在这种情况下,Python 会引发 ZeroDivisionError,并显示“除以零”错误消息。
a=0
b=2.5
print ("a=",a,"b=",b,"a/b=",a/b)
print ("a=",a,"b=",b,"b/a=",b/a)
它将产生以下**输出**:
a= 0 b= 2.5 a/b= 0.0
Traceback (most recent call last):
File "C:\Users\mlath\examples\example.py", line 20, in <module>
print ("a=",a,"b=",b,"b/a=",b/a)
~^~
ZeroDivisionError: float division by zero
Python - 模运算符 (%)
Python 将 "%" 符号定义为模运算符。它返回分母除以分子后的余数。它也可以称为余数运算符。模运算符的结果是在整数商之后剩下的数字。例如,当 10 除以 3 时,商为 3,余数为 1。因此,10%3(通常读作 10 模 3)的结果为 1。
如果两个操作数都是整数,则模值为整数。如果分子完全可被整除,则余数为 0。如果分子小于分母,则模等于分子。如果分母为 0,则 Python 会引发 ZeroDivisionError。
a=10
b=2
print ("a=",a, "b=",b, "a%b=", a%b)
a=10
b=4
print ("a=",a, "b=",b, "a%b=", a%b)
print ("a=",a, "b=",b, "b%a=", b%a)
a=0
b=10
print ("a=",a, "b=",b, "a%b=", a%b)
print ("a=", a, "b=", b, "b%a=",b%a)
它将产生以下**输出**:
a= 10 b= 2 a%b= 0
a= 10 b= 4 a%b= 2
a= 10 b= 4 b%a= 4
a= 0 b= 10 a%b= 0
Traceback (most recent call last):
File "C:\Users\mlath\examples\example.py", line 13, in <module>
print ("a=", a, "b=", b, "b%a=",b%a)
~^~
ZeroDivisionError: integer modulo by zero
如果任何一个操作数是浮点数,则模值始终是浮点数。
a=10
b=2.5
print ("a=",a, "b=",b, "a%b=", a%b)
a=10
b=1.5
print ("a=",a, "b=",b, "a%b=", a%b)
a=7.7
b=2.5
print ("a=",a, "b=",b, "a%b=", a%b)
a=12.4
b=3
print ("a=",a, "b=",b, "a%b=", a%b)
它将产生以下**输出**:
a= 10 b= 2.5 a%b= 0.0 a= 10 b= 1.5 a%b= 1.0 a= 7.7 b= 2.5 a%b= 0.20000000000000018 a= 12.4 b= 3 a%b= 0.40000000000000036
Python 不接受复数用作模运算中的操作数。它会抛出 TypeError: unsupported operand type(s) for %。
Python - 指数运算符 (**)
Python 使用 **(双星号)作为指数运算符(有时称为乘方运算符)。因此,对于 a**b,可以说 a 的 b 次方,甚至 a 的 b 次幂。
如果在指数表达式中,两个操作数都是整数,则结果也是整数。如果其中一个是浮点数,则结果是浮点数。类似地,如果其中一个操作数是复数,则指数运算符返回复数。
如果底数为 0,则结果为 0;如果指数为 0,则结果始终为 1。
a=10
b=2
print ("a=",a, "b=",b, "a**b=", a**b)
a=10
b=1.5
print ("a=",a, "b=",b, "a**b=", a**b)
a=7.7
b=2
print ("a=",a, "b=",b, "a**b=", a**b)
a=1+2j
b=4
print ("a=",a, "b=",b, "a**b=", a**b)
a=12.4
b=0
print ("a=",a, "b=",b, "a**b=", a**b)
print ("a=",a, "b=",b, "b**a=", b**a)
它将产生以下**输出**:
a= 10 b= 2 a**b= 100 a= 10 b= 1.5 a**b= 31.622776601683793 a= 7.7 b= 2 a**b= 59.290000000000006 a= (1+2j) b= 4 a**b= (-7-24j) a= 12.4 b= 0 a**b= 1.0 a= 12.4 b= 0 b**a= 0.0
Python - 地板除运算符 (//)
地板除也称为整数除法。Python 使用 //(双正斜杠)符号来实现此目的。与返回余数的模运算不同,地板除给出所涉及操作数除法的商。
如果两个操作数都是正数,则地板除运算符返回一个去除小数部分的数字。例如,9.8 除以 2 的地板除结果为 4(纯除法为 4.9,去除小数部分,结果为 4)。
但是,如果其中一个操作数为负数,则结果将远离零舍入(朝负无穷大)。-9.8 除以 2 的地板除结果为 -5(纯除法为 -4.9,远离 0 舍入)。
a=9
b=2
print ("a=",a, "b=",b, "a//b=", a//b)
a=9
b=-2
print ("a=",a, "b=",b, "a//b=", a//b)
a=10
b=1.5
print ("a=",a, "b=",b, "a//b=", a//b)
a=-10
b=1.5
print ("a=",a, "b=",b, "a//b=", a//b)
它将产生以下**输出**:
a= 9 b= 2 a//b= 4 a= 9 b= -2 a//b= -5 a= 10 b= 1.5 a//b= 6.0 a= -10 b= 1.5 a//b= -7.0
Python - 复数算术运算
当两个操作数都是复数对象时,算术运算符的行为略有不同。
复数的加法和减法是各自实部和虚部的简单加法/减法。
a=2.5+3.4j
b=-3+1.0j
print ("Addition of complex numbers - a=",a, "b=",b, "a+b=", a+b)
print ("Subtraction of complex numbers - a=",a, "b=",b, "a-b=", a-b)
它将产生以下**输出**:
Addition of complex numbers - a= (2.5+3.4j) b= (-3+1j) a+b= (-0.5+4.4j) Subtraction of complex numbers - a= (2.5+3.4j) b= (-3+1j) a-b= (5.5+2.4j)
复数的乘法类似于代数中两个二项式的乘法。如果 "a+bj" 和 "x+yj" 是两个复数,则它们的乘法由以下公式给出:
(a+bj)*(x+yj) = ax+ayj+xbj+byj2 = (ax-by)+(ay+xb)j
例如:
a=6+4j b=3+2j c=a*b c=(18-8)+(12+12)j c=10+24j
以下程序确认结果:
a=6+4j
b=3+2j
print ("Multplication of complex numbers - a=",a, "b=",b, "a*b=", a*b)
要了解两个复数的除法是如何进行的,我们应该使用复数的共轭。Python 的复数对象有一个 conjugate() 方法,它返回一个虚部符号反转的复数。
>>> a=5+6j >>> a.conjugate() (5-6j)
要除以两个复数,请将分子和分母都除以分母的共轭。
a=6+4j b=3+2j c=a/b c=(6+4j)/(3+2j) c=(6+4j)*(3-2j)/3+2j)*(3-2j) c=(18-12j+12j+8)/(9-6j+6j+4) c=26/13 c=2+0j
要验证,请运行以下代码:
a=6+4j
b=3+2j
print ("Division of complex numbers - a=",a, "b=",b, "a/b=", a/b)
Python 中的 Complex 类不支持模运算符 (%) 和地板除运算符 (//)。
Python - 赋值运算符
=(等于)符号在 Python 中定义为赋值运算符。其右侧的 Python 表达式的值将分配给其左侧的单个变量。编程中(尤其是在 Python 中)的 = 符号不应与它在数学中的用法混淆,在数学中它表示符号两侧的表达式相等。
除了简单的赋值运算符外,Python 还提供了一些赋值运算符用于高级用途。它们被称为累积或增强赋值运算符。在本节中,我们将学习使用 Python 中定义的增强赋值运算符。
考虑以下Python语句:
a=10 b=5 a=a+b print (a)
起初,至少对于编程新手但懂数学的人来说,“a=a+b”这个语句看起来很奇怪。a怎么可能等于“a+b”?然而,需要再次强调的是,这里的“=”符号是赋值运算符,而不是用来表示左边和右边的相等。
因为它是一个赋值操作,右侧的表达式计算结果为15,该值被赋值给a。
在语句“a+=b”中,两个运算符“+”和“=”可以组合成一个“+=”运算符。它被称为加法赋值运算符。它在一个语句中执行两个操作数“a”和“b”的加法,并将结果赋值给左边的操作数“a”。
+=运算符是一个增强型运算符。它也称为累加运算符,因为它将“b”添加到“a”中,并将结果重新赋值给变量a。
Python对所有算术和比较运算符都有增强型赋值运算符。
Python - 增强型加法运算符(+=)
此运算符在一个语句中组合了加法和赋值。由于Python支持混合算术运算,两个操作数可以是不同类型。但是,如果右操作数的类型更宽,则左操作数的类型会更改为右操作数的类型。
下面的例子将有助于理解“+=”运算符是如何工作的:
a=10
b=5
print ("Augmented addition of int and int")
a+=b #equivalent to a=a+b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented addition of int and float")
a+=b #equivalent to a=a+b
print ("a=",a, "type(a):", type(a))
a=10.50
b=5+6j
print ("Augmented addition of float and complex")
a+=b #equivalent to a=a+b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented addition of int and int a= 15 type(a): <class 'int'> Augmented addition of int and float a= 15.5 type(a): <class 'float'> Augmented addition of float and complex a= (15.5+6j) type(a): <class 'complex'>
Python - 增强型减法运算符(-=)
使用-=符号在一个语句中执行减法和赋值操作。“a-=b”语句执行“a=a-b”赋值。操作数可以是任何数字类型。Python对大小较小的对象执行隐式类型转换。
a=10
b=5
print ("Augmented subtraction of int and int")
a-=b #equivalent to a=a-b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented subtraction of int and float")
a-=b #equivalent to a=a-b
print ("a=",a, "type(a):", type(a))
a=10.50
b=5+6j
print ("Augmented subtraction of float and complex")
a-=b #equivalent to a=a-b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented subtraction of int and int a= 5 type(a): <class 'int'> Augmented subtraction of int and float a= 4.5 type(a): <class 'float'> Augmented subtraction of float and complex a= (5.5-6j) type(a): <class 'complex'>
Python - 增强型乘法运算符(*=)
*=运算符的工作原理类似。“a*=b”执行乘法和赋值操作,等效于“a=a*b”。对于两个复数的增强型乘法,适用上一章中讨论的乘法规则。
a=10
b=5
print ("Augmented multiplication of int and int")
a*=b #equivalent to a=a*b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented multiplication of int and float")
a*=b #equivalent to a=a*b
print ("a=",a, "type(a):", type(a))
a=6+4j
b=3+2j
print ("Augmented multiplication of complex and complex")
a*=b #equivalent to a=a*b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented multiplication of int and int a= 50 type(a): <class 'int'> Augmented multiplication of int and float a= 55.0 type(a): <class 'float'> Augmented multiplication of complex and complex a= (10+24j) type(a): <class 'complex'>
Python - 增强型除法运算符(/=)
组合符号"/="充当除法和赋值运算符,因此“a/=b”等效于“a=a/b”。int或float操作数的除法运算结果为float。两个复数的除法返回一个复数。下面是增强型除法运算符的示例。
a=10
b=5
print ("Augmented division of int and int")
a/=b #equivalent to a=a/b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented division of int and float")
a/=b #equivalent to a=a/b
print ("a=",a, "type(a):", type(a))
a=6+4j
b=3+2j
print ("Augmented division of complex and complex")
a/=b #equivalent to a=a/b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented division of int and int a= 2.0 type(a): <class 'float'> Augmented division of int and float a= 1.8181818181818181 type(a): <class 'float'> Augmented division of complex and complex a= (2+0j) type(a): <class 'complex'>
Python - 增强型取模运算符(%=)
要在单个语句中执行取模和赋值操作,请使用%=运算符。与取模运算符一样,它的增强版本也不支持复数。
a=10
b=5
print ("Augmented modulus operator with int and int")
a%=b #equivalent to a=a%b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented modulus operator with int and float")
a%=b #equivalent to a=a%b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented modulus operator with int and int a= 0 type(a): <class 'int'> Augmented modulus operator with int and float a= 4.5 type(a): <class 'float'>
Python - 增强型指数运算符(**=)
**=运算符计算“a”的“b”次幂,并将值重新赋值给“a”。下面是一些例子:
a=10
b=5
print ("Augmented exponent operator with int and int")
a**=b #equivalent to a=a**b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented exponent operator with int and float")
a**=b #equivalent to a=a**b
print ("a=",a, "type(a):", type(a))
a=6+4j
b=3+2j
print ("Augmented exponent operator with complex and complex")
a**=b #equivalent to a=a**b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented exponent operator with int and int a= 100000 type(a): <class 'int'> Augmented exponent operator with int and float a= 316227.7660168379 type(a): <class 'float'> Augmented exponent operator with complex and complex a= (97.52306038414744-62.22529992036203j) type(a): <class 'complex'>
Python - 增强型地板除运算符(//=)
要在单个语句中执行地板除和赋值,请使用//=运算符。“a//=b”等效于“a=a//b”。此运算符不能与复数一起使用。
a=10
b=5
print ("Augmented floor division operator with int and int")
a//=b #equivalent to a=a//b
print ("a=",a, "type(a):", type(a))
a=10
b=5.5
print ("Augmented floor division operator with int and float")
a//=b #equivalent to a=a//b
print ("a=",a, "type(a):", type(a))
它将产生以下**输出**:
Augmented floor division operator with int and int a= 2 type(a): <class 'int'> Augmented floor division operator with int and float a= 1.0 type(a): <class 'float'>
Python - 比较运算符
Python中的比较运算符在Python的条件语句(**if, else**和**elif**)和循环语句(while和for循环)中非常重要。像算术运算符一样,比较运算符(也称为关系运算符,“<”代表小于,“>”代表大于)也是众所周知的。
Python使用另外两个运算符,将“=”符号与这两个运算符组合。“<=”符号表示小于或等于。“>=”符号表示大于或等于。
Python还有另外两个比较运算符,形式为“==”和“!=”。它们分别表示等于和不等于运算符。因此,Python中共有六个比较运算符。
| < | 小于 | a |
| > | 大于 | a>b |
| <= | 小于或等于 | a<=b |
| >= | 大于或等于 | a>=b |
| == | 等于 | a==b |
| != | 不等于 | a!=b |
比较运算符本质上是二元的,需要两个操作数。包含比较运算符的表达式称为布尔表达式,始终返回True或False。
a=5 b=7 print (a>b) print (a<b)
它将产生以下**输出**:
False True
两个操作数可以是Python字面量、变量或表达式。由于Python支持混合算术运算,您可以使用任何数字类型的操作数。
以下代码演示了Python的**比较运算符与整数**的使用:
print ("Both operands are integer")
a=5
b=7
print ("a=",a, "b=",b, "a>b is", a>b)
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
Both operands are integer a= 5 b= 7 a>b is False a= 5 b= 7 a<b is True a= 5 b= 7 a==b is False a= 5 b= 7 a!=b is True
浮点数比较
在下面的示例中,比较了一个整数和一个浮点型操作数。
print ("comparison of int and float")
a=10
b=10.0
print ("a=",a, "b=",b, "a>b is", a>b)
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
comparison of int and float a= 10 b= 10.0 a>b is False a= 10 b= 10.0 a<b is False a= 10 b= 10.0 a==b is True a= 10 b= 10.0 a!=b is False
复数比较
虽然复数对象是Python中的数字数据类型,但它的行为与其他类型不同。Python不支持<和>运算符,但它支持等于(==)和不等于(!=)运算符。
print ("comparison of complex numbers")
a=10+1j
b=10.-1j
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
comparison of complex numbers a= (10+1j) b= (10-1j) a==b is False a= (10+1j) b= (10-1j) a!=b is True
使用小于或大于运算符会得到TypeError。
print ("comparison of complex numbers")
a=10+1j
b=10.-1j
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a>b is",a>b)
它将产生以下**输出**:
comparison of complex numbers
Traceback (most recent call last):
File "C:\Users\mlath\examples\example.py", line 5, in <module>
print ("a=",a, "b=",b,"a<b is",a<b)
^^^
TypeError: '<' not supported between instances of 'complex' and
'complex
布尔值比较
Python中的布尔对象实际上是整数:True是1,False是0。实际上,Python将任何非零数字视为True。在Python中,可以比较布尔对象。“False < True”为True!
print ("comparison of Booleans")
a=True
b=False
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a>b is",a>b)
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
comparison of Booleans a= True b= False a<b is False a= True b= False a>b is True a= True b= False a==b is False a= True b= False a!=b is True
序列类型比较
在Python中,只能对类似的序列对象进行比较。字符串对象只能与另一个字符串进行比较。列表不能与元组进行比较,即使两者具有相同的项目。
print ("comparison of different sequence types")
a=(1,2,3)
b=[1,2,3]
print ("a=",a, "b=",b,"a<b is",a<b)
它将产生以下**输出**:
comparison of different sequence types
Traceback (most recent call last):
File "C:\Users\mlath\examples\example.py", line 5, in <module>
print ("a=",a, "b=",b,"a<b is",a<b)
^^^
TypeError: '<' not supported between instances of 'tuple' and 'list'
序列对象通过词法排序机制进行比较。比较从第0个索引处的项目开始。如果它们相等,则比较移动到下一个索引,直到某个索引处的项目不相等,或者其中一个序列用尽。如果一个序列是另一个序列的初始子序列,则较短的序列是较小的(较小的)序列。
哪个操作数更大取决于它们不相等的索引处项目的数值差异。例如,“BAT”>“BAR”为True,因为T在Unicode顺序中位于R之后。
如果两个序列的所有项目都比较相等,则认为这两个序列相等。
print ("comparison of strings")
a='BAT'
b='BALL'
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a>b is",a>b)
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
comparison of strings a= BAT b= BALL a<b is False a= BAT b= BALL a>b is True a= BAT b= BALL a==b is False a= BAT b= BALL a!=b is True
在下面的示例中,比较了两个元组对象:
print ("comparison of tuples")
a=(1,2,4)
b=(1,2,3)
print ("a=",a, "b=",b,"a<b is",a<b)
print ("a=",a, "b=",b,"a>b is",a>b)
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
a= (1, 2, 4) b= (1, 2, 3) a<b is False a= (1, 2, 4) b= (1, 2, 3) a>b is True a= (1, 2, 4) b= (1, 2, 3) a==b is False a= (1, 2, 4) b= (1, 2, 3) a!=b is True
字典对象比较
对于Python的字典,未定义使用“<”和“>”运算符。对于这些操作数,报告TypeError: '<' not supported between instances of 'dict' and 'dict'。
相等性比较检查两个字典项目的长度是否相同。字典的长度是其中键值对的数量。
Python字典只是按长度进行比较。元素较少的字典被认为小于元素较多的字典。
print ("comparison of dictionary objects")
a={1:1,2:2}
b={2:2, 1:1, 3:3}
print ("a=",a, "b=",b,"a==b is",a==b)
print ("a=",a, "b=",b,"a!=b is",a!=b)
它将产生以下**输出**:
comparison of dictionary objects
a= {1: 1, 2: 2} b= {2: 2, 1: 1, 3: 3} a==b is False
a= {1: 1, 2: 2} b= {2: 2, 1: 1, 3: 3} a!=b is True
Python - 逻辑运算符
使用Python中的逻辑运算符,我们可以形成复合布尔表达式。这些逻辑运算符的每个操作数本身就是一个布尔表达式。例如,
age>16 and marks>80 percentage<50 or attendance<75
除了关键字False之外,Python还将None、所有类型的数字零以及空序列(字符串、元组、列表)、空字典和空集合解释为False。所有其他值都被视为True。
Python中有三个逻辑运算符。它们是“and”、“or”和“not”。它们必须是小写。
“and”运算符
为了使复合布尔表达式为True,两个操作数都必须为True。如果任何一个或两个操作数计算结果为False,则表达式返回False。下表显示了各种情况。
| a | b | a and b |
|---|---|---|
| F | F | F |
| F | T | F |
| T | F | F |
| T | T | T |
“or”运算符
相反,“or”运算符如果任何一个操作数为True,则返回True。为了使复合布尔表达式为False,两个操作数都必须为False,如下表所示:
| a | b | a or b |
|---|---|---|
| F | F | F |
| F | T | T |
| T | F | F |
| T | T | T |
“not”运算符
这是一个一元运算符。它反转其后跟的布尔操作数的状态。因此,not True变为False,not False变为True。
| a | not (a) |
|---|---|
| F | T |
| T | F |
Python解释器如何评估逻辑运算符?
表达式“x and y”首先评估“x”。如果“x”为false,则返回其值;否则,评估“y”并返回结果值。
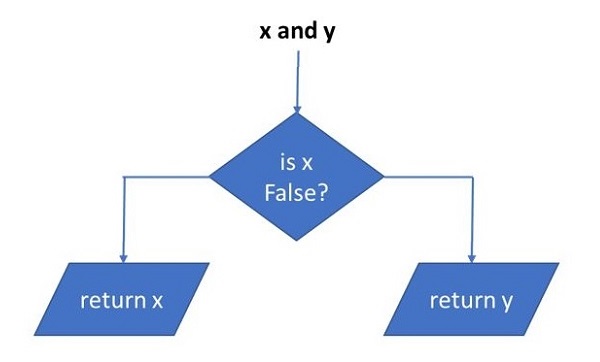
表达式“x or y”首先评估“x”;如果“x”为true,则返回其值;否则,评估“y”并返回结果值。
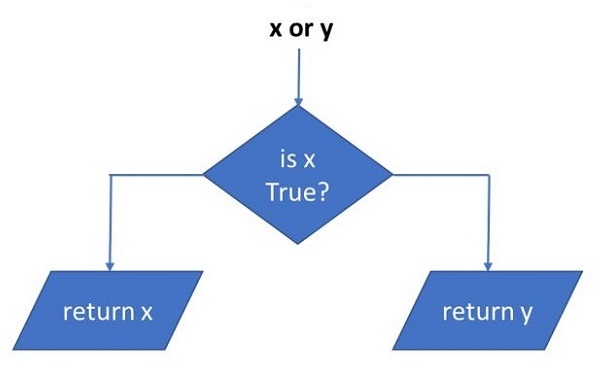
下面给出了一些逻辑运算符的用例:
x = 10
y = 20
print("x > 0 and x < 10:",x > 0 and x < 10)
print("x > 0 and y > 10:",x > 0 and y > 10)
print("x > 10 or y > 10:",x > 10 or y > 10)
print("x%2 == 0 and y%2 == 0:",x%2 == 0 and y%2 == 0)
print ("not (x+y>15):", not (x+y)>15)
它将产生以下**输出**:
x > 0 and x < 10: False x > 0 and y > 10: True x > 10 or y > 10: True x%2 == 0 and y%2 == 0: True not (x+y>15): False
我们可以使用非布尔操作数与逻辑运算符。在这里,我们需要注意到任何非零数字和非空序列都被评估为True。因此,逻辑运算符的相同真值表适用。
在下面的示例中,数值操作数用于逻辑运算符。“x”、“y”的值为True,“z”为False
x = 10
y = 20
z = 0
print("x and y:",x and y)
print("x or y:",x or y)
print("z or x:",z or x)
print("y or z:", y or z)
它将产生以下**输出**:
x and y: 20 x or y: 10 z or x: 10 y or z: 20
在下面的示例中,字符串变量被视为True,空元组被视为False:
a="Hello"
b=tuple()
print("a and b:",a and b)
print("b or a:",b or a)
它将产生以下**输出**:
a and b: () b or a: Hello
最后,下面的两个列表对象是非空的。因此,x and y返回后者,x or y返回前者。
x=[1,2,3]
y=[10,20,30]
print("x and y:",x and y)
print("x or y:",x or y)
它将产生以下**输出**:
x and y: [10, 20, 30] x or y: [1, 2, 3]
Python - 位运算符
Python的按位运算符通常与整数类型对象一起使用。但是,它不是将对象作为一个整体对待,而是将其视为位字符串。对字符串中的每个位执行不同的操作。
Python有六个按位运算符-&、|、^、~、<<和>>。所有这些运算符(除了~)本质上都是二元的,因为它们作用于两个操作数。每个操作数都是一个二进制数字(位)1或0。
Python - 按位与运算符(&)
按位与运算符有点类似于逻辑与运算符。只有当两个位操作数都是1(即True)时,它才返回True。所有组合如下:
0 & 0 is 0 1 & 0 is 0 0 & 1 is 0 1 & 1 is 1
当使用整数作为操作数时,两者都转换为等效的二进制数,&操作对每个数字的对应位进行操作,从最低有效位开始,向最高有效位移动。
让我们取两个整数60和13,并将它们分别赋值给变量a和b。
a=60
b=13
print ("a:",a, "b:",b, "a&b:",a&b)
它将产生以下**输出**:
a: 60 b: 13 a&b: 12
为了了解Python如何执行该操作,请获取每个变量的二进制等效值。
print ("a:", bin(a))
print ("b:", bin(b))
它将产生以下**输出**:
a: 0b111100 b: 0b1101
为了方便起见,对每个数字使用标准的8位格式,因此“a”是00111100,“b”是00001101。让我们手动对这两个数字的每个对应位执行与运算。
0011 1100
&
0000 1101
-------------
0000 1100
将结果二进制数转换回整数。您将得到12,这是前面获得的结果。
>>> int('00001100',2)
12
Python - 按位或运算符(|)
“|”符号(称为**管道**)是按位或运算符。如果任何位操作数为1,则结果为1,否则为0。
0 | 0 is 0 0 | 1 is 1 1 | 0 is 1 1 | 1 is 1
取相同的值a=60,b=13。“|”运算的结果为61。获取它们的二进制等效值。
a=60
b=13
print ("a:",a, "b:",b, "a|b:",a|b)
print ("a:", bin(a))
print ("b:", bin(b))
它将产生以下**输出**:
a: 60 b: 13 a|b: 61 a: 0b111100 b: 0b1101
要手动执行“|”运算,请使用8位格式。
0011 1100
|
0000 1101
-------------
0011 1101
将二进制数转换回整数以核对结果:
>>> int('00111101',2)
61
Python - 二进制异或运算符(^)
XOR 代表异或 (exclusive OR)。这意味着对两个比特进行或运算的结果,只有当且仅当其中一个比特为 1 时,结果才为 1。
0 ^ 0 is 0 0 ^ 1 is 1 1 ^ 0 is 1 1 ^ 1 is 0
让我们对 a=60 和 b=13 进行异或运算。
a=60
b=13
print ("a:",a, "b:",b, "a^b:",a^b)
它将产生以下**输出**:
a: 60 b: 13 a^b: 49
现在我们手动执行按位异或。
0011 1100
^
0000 1101
-------------
0011 0001
int() 函数显示 00110001 为 49。
>>> int('00110001',2)
49
Python – 二进制非运算符 (~)
此运算符是逻辑非运算符的二进制等效运算符。它翻转每个比特,使 1 替换为 0,0 替换为 1,并返回原始数字的补码。Python 使用 2 的补码方法。对于正整数,它只需反转比特即可获得。对于负数 -x,它使用 (x-1) 的比特模式并对所有比特进行补码(从 1 切换到 0 或从 0 切换到 1)。因此:(对于 8 位表示)
-1 is complement(1 - 1) = complement(0) = "11111111"
-10 is complement(10 - 1) = complement(9) = complement("00001001") = "11110110".
对于 a=60,其补码为 −
a=60
print ("a:",a, "~a:", ~a)
它将产生以下**输出**:
a: 60 ~a: -61
Python – 左移运算符 (<<)
左移运算符将最高有效位向右移动“<<”符号右侧的数字位数。因此,“x << 2” 会将二进制表示的 x 的最高两位向右移动。让我们对 60 进行左移。
a=60
print ("a:",a, "a<<2:", a<<2)
它将产生以下**输出**:
a: 60 a<<2: 240
这是如何发生的?让我们使用 60 的二进制等效值,并将其左移 2 位。
0011 1100
<<
2
-------------
1111 0000
将二进制转换为整数。它是 240。
>>> int('11110000',2)
240
Python – 右移运算符 (>>)
右移运算符将最低有效位向左移动“>>”符号右侧的数字位数。因此,“x >> 2” 会将二进制表示的 x 的最低两位向左移动。让我们对 60 进行右移。
a=60
print ("a:",a, "a>>2:", a>>2)
它将产生以下**输出**:
a: 60 a>>2: 15
以下是 60 的手动右移操作 −
0011 1100
>>
2
-------------
0000 1111
使用 int() 函数将上述二进制数转换为整数。它是 15。
>>> int('00001111',2)
15
Python - 成员运算符
Python 中的成员运算符帮助我们确定给定容器类型对象中是否存在某个项,或者换句话说,某个项是否是给定容器类型对象的成员。
Python 有两个成员运算符:“in”和“not in”。两者都返回布尔结果。“in”运算符的结果与“not in”运算符的结果相反。
您可以使用 in 运算符检查子字符串是否出现在较大的字符串中,任何项是否出现在列表或元组中,或者子列表或子元组是否包含在列表或元组中。
在下面的示例中,检查不同的子字符串是否属于字符串 var="TutorialsPoint"。Python 基于其 Unicode 值区分字符。因此,“To”与“to”不同。还要注意,如果“in”运算符返回 True,“not in”运算符则计算为 False。
var = "TutorialsPoint" a = "P" b = "tor" c = "in" d = "To" print (a, "in", var, ":", a in var) print (b, "not in", var, ":", b not in var) print (c, "in", var, ":", c in var) print (d, "not in", var, ":", d not in var)
它将产生以下**输出**:
P in TutorialsPoint : True tor not in TutorialsPoint : False in in TutorialsPoint : True To not in TutorialsPoint : True
您可以使用“in/not in”运算符检查项在列表或元组中的成员资格。
var = [10,20,30,40] a = 20 b = 10 c = a-b d = a/2 print (a, "in", var, ":", a in var) print (b, "not in", var, ":", b not in var) print (c, "in", var, ":", c in var) print (d, "not in", var, ":", d not in var)
它将产生以下**输出**:
20 in [10, 20, 30, 40] : True 10 not in [10, 20, 30, 40] : False 10 in [10, 20, 30, 40] : True 10.0 not in [10, 20, 30, 40] : False
在最后一种情况下,“d”是浮点数,但它仍然与列表中的 10(一个**int**)比较为 True。即使以其他格式(如二进制、八进制或十六进制)表示的数字也被给出,成员运算符也会说明它是否在序列中。
>>> 0x14 in [10, 20, 30, 40] True
但是,如果您尝试检查列表或元组中是否存在两个连续的数字,“in”运算符将返回 False。如果列表/元组本身包含连续数字作为序列,则它返回 True。
var = (10,20,30,40) a = 10 b = 20 print ((a,b), "in", var, ":", (a,b) in var) var = ((10,20),30,40) a = 10 b = 20 print ((a,b), "in", var, ":", (a,b) in var)
它将产生以下**输出**:
(10, 20) in (10, 20, 30, 40) : False (10, 20) in ((10, 20), 30, 40) : True
Python 的成员运算符也适用于集合对象。
var = {10,20,30,40}
a = 10
b = 20
print (b, "in", var, ":", b in var)
var = {(10,20),30,40}
a = 10
b = 20
print ((a,b), "in", var, ":", (a,b) in var)
它将产生以下**输出**:
20 in {40, 10, 20, 30} : True
(10, 20) in {40, 30, (10, 20)} : True
允许将 in 和 not in 运算符与字典对象一起使用。但是,Python 只检查键的集合,而不是值的集合。
var = {1:10, 2:20, 3:30}
a = 2
b = 20
print (a, "in", var, ":", a in var)
print (b, "in", var, ":", b in var)
它将产生以下**输出**:
2 in {1: 10, 2: 20, 3: 30} : True
20 in {1: 10, 2: 20, 3: 30} : False
Python - 身份运算符
Python 具有两个身份运算符 is 和 is not。两者都返回相反的布尔值。“is”运算符如果两个操作数对象共享相同的内存位置,则计算结果为 True。可以使用“id()”函数获得对象的内存位置。如果两个变量的 id() 相同,“is”运算符返回 True(因此,is not 返回 False)。
a="TutorialsPoint"
b=a
print ("id(a), id(b):", id(a), id(b))
print ("a is b:", a is b)
print ("b is not a:", b is not a)
它将产生以下**输出**:
id(a), id(b): 2739311598832 2739311598832 a is b: True b is not a: False
列表和元组对象的处理方式不同,这在最初看起来可能很奇怪。在下面的示例中,两个列表“a”和“b”包含相同的项。但它们的 id() 不同。
a=[1,2,3]
b=[1,2,3]
print ("id(a), id(b):", id(a), id(b))
print ("a is b:", a is b)
print ("b is not a:", b is not a)
它将产生以下**输出**:
id(a), id(b): 1552612704640 1552567805568 a is b: False b is not a: True
列表或元组仅包含各个项的内存位置,而不是项本身。因此,“a”包含在特定位置的 10、20 和 30 整数对象的地址,这可能与“b”的不同。
print (id(a[0]), id(a[1]), id(a[2])) print (id(b[0]), id(b[1]), id(b[2]))
它将产生以下**输出**:
140734682034984 140734682035016 140734682035048 140734682034984 140734682035016 140734682035048
由于“a”和“b”的两个位置不同,“**is**”运算符即使这两个列表包含相同的数字,也返回 False。
Python - 注释
计算机程序中的注释是一段文本,旨在作为源代码中的解释性或描述性注释,编译器/解释器在生成机器语言代码时不应考虑它。在源程序中大量使用注释,使所有相关人员更容易理解算法的语法、用法和逻辑等。
在 Python 脚本中,符号 # 表示注释行的开始。它在编辑器中有效到行尾。如果 # 是行的第一个字符,则整行都是注释。如果在行中间使用,则其之前的文本是有效的 Python 表达式,而其后的文本则被视为注释。
# this is a comment
print ("Hello World")
print ("How are you?") #also a comment but after a statement.
在 Python 中,没有规定编写多行注释或块注释。(如 C/C++ 中,/* .. */ 内的多行被视为多行注释)。
每行都应在开头使用“#”符号标记为注释。许多 Python IDE 都有快捷键可以将一段语句标记为注释。
如果三引号多行字符串不是函数或类的文档字符串,它也被视为注释。
'''
First line in the comment
Second line in the comment
Third line in the comment
'''
print ("Hello World")
Python - 用户输入
每个计算机应用程序都应具有在运行时接受用户数据的规定。这使应用程序具有交互性。根据其开发方式,应用程序可以以在控制台**(sys.stdin)**中输入的文本、图形布局或基于 Web 的界面形式接受用户输入。在本章中,我们将学习 Python 如何从控制台接受用户输入,并在控制台上显示输出。
Python 解释器以交互模式和脚本模式工作。虽然交互模式非常适合快速评估,但效率较低。对于重复执行相同的指令集,应使用脚本模式。
让我们编写一个简单的 Python 脚本开始。
#! /usr/bin/python3.11
name = "Kiran"
city = "Hyderabad"
print ("Hello My name is", name)
print ("I am from", city)
将上述代码保存为 hello.py 并从命令行运行它。以下是输出
C:\python311> python var1.py Hello My name is Kiran I am from Hyderabad
程序只是打印其中的两个变量的值。如果重复运行程序,每次都会显示相同的输出。要将程序用于另一个名称和城市,您可以编辑代码,将名称更改为“Ravi”,将城市更改为“Chennai”。每次需要分配不同的值时,都必须编辑程序、保存和运行,这不是理想的方法。
input() 函数
显然,您需要某种机制来在运行时(程序运行时)为变量分配不同的值。Python 的**input()**函数完成了这项工作。
Python 的标准库具有 input() 函数。
>>> var = input()
当解释器遇到它时,它会等待用户从标准输入流(键盘)输入数据,直到按下 Enter 键。字符序列可以存储在字符串变量中以供进一步使用。
读取 Enter 键后,程序将继续执行下一条语句。让我们更改程序以将用户输入存储在 name 和 city 变量中。
#! /usr/bin/python3.11
name = input()
city = input()
print ("Hello My name is", name)
print ("I am from ", city)
运行时,您会发现光标正在等待用户的输入。输入 name 和 city 的值。使用输入的数据,将显示输出。
Ravi Chennai Hello My name is Ravi I am from Chennai
现在,程序中没有为变量分配任何特定值。每次运行时,都可以输入不同的值。因此,您的程序已成为真正的交互式程序。
在 input() 函数内,您可以提供**提示**文本,该文本将在您运行代码时出现在光标之前。
#! /usr/bin/python3.11
name = input("Enter your name : ")
city = input("enter your city : ")
print ("Hello My name is", name)
print ("I am from ", city)
运行程序时,会显示提示消息,基本上帮助用户知道输入什么。
Enter your name: Praveen Rao enter your city: Bengaluru Hello My name is Praveen Rao I am from Bengaluru
数字输入
让我们编写一个 Python 代码,从用户处接受矩形的宽度和高度并计算面积。
#! /usr/bin/python3.11
width = input("Enter width : ")
height = input("Enter height : ")
area = width*height
print ("Area of rectangle = ", area)
运行程序,输入宽度和高度。
Enter width: 20 Enter height: 30 Traceback (most recent call last): File "C:\Python311\var1.py", line 5, in <module> area = width*height TypeError: can't multiply sequence by non-int of type 'str'
为什么这里会出现**TypeError**?原因是,Python 总是将用户输入读取为字符串。因此,width="20" 和 height="30" 是字符串,显然您不能执行两个字符串的乘法。
为了克服这个问题,我们将使用**int()**,这是 Python 标准库中的另一个内置函数。它将字符串对象转换为整数。
要从用户处接受整数输入,请将输入读取为字符串,并使用 int() 函数将其类型转换为整数 −
w= input("Enter width : ")
width=int(w)
h= input("Enter height : ")
height=int(h)
您可以将输入和类型转换语句组合在一个语句中 −
#! /usr/bin/python3.11
width = int(input("Enter width : "))
height = int(input("Enter height : "))
area = width*height
print ("Area of rectangle = ", area)
现在您可以向程序中的两个变量输入任何整数值 −
Enter width: 20 Enter height: 30 Area of rectangle = 600
Python 的**float()**函数将字符串转换为浮点数对象。以下程序接受用户输入并将其解析为浮点变量 rate,并计算用户也输入的金额的利息。
#! /usr/bin/python3.11
amount = float(input("Enter Amount : "))
rate = float(input("Enter rate of interest : "))
interest = amount*rate/100
print ("Amount: ", amount, "Interest: ", interest)
程序要求用户输入金额和利率;并显示结果如下 −
Enter Amount: 12500 Enter rate of interest: 6.5 Amount: 12500.0 Interest: 812.5
print() 函数
Python 的 print() 函数是一个内置函数。它是最常用的函数,它在 Python 的控制台或标准输出**(sys.stdout)**上显示括号中给出的 Python 表达式的值。
print ("Hello World ")
括号内可以有任意数量的 Python 表达式。它们必须用逗号分隔。列表中的每个项都可以是任何 Python 对象或有效的 Python 表达式。
#! /usr/bin/python3.11
a = "Hello World"
b = 100
c = 25.50
d = 5+6j
print ("Message: a)
print (b, c, b-c)
print(pow(100, 0.5), pow(c,2))
第一次调用 print() 显示字符串文字和字符串变量。第二个打印两个变量的值及其差值。**pow()**函数计算数字的平方根和变量的平方值。
Message Hello World 100 25.5 74.5 10.0 650.25
如果 print() 函数的括号中有多个用逗号分隔的对象,则这些值用空格“ ”分隔。要使用任何其他字符作为分隔符,请为 print() 函数定义**sep**参数。此参数应位于要打印的表达式列表之后。
在 print() 函数的以下输出中,变量用逗号分隔。
#! /usr/bin/python3.11 city="Hyderabad" state="Telangana" country="India" print(city, state, country, sep=',')
sep=',' 的效果可以在结果中看到 −
Hyderabad,Telangana,India
print() 函数默认在末尾发出换行符 ('\n')。结果,下一个 print() 语句的输出出现在控制台的下一行。
city="Hyderabad"
state="Telangana"
print("City:", city)
print("State:", state)
显示两行作为输出 −
City: Hyderabad State: Telangana
为了使这两行出现在同一行,请在第一个 print() 函数中定义**end**参数并将其设置为空格字符串“ ”。
city="Hyderabad"
state="Telangana"
country="India"
print("City:", city, end=" ")
print("State:", state)
两个 print() 函数的输出都连续出现。
City: Hyderabad State: Telangana
Python - 数字
大多数情况下,您在所做的一切中都会处理数字。显然,任何计算机应用程序都处理数字。因此,包括 Python 在内的编程语言都内置支持存储和处理数字数据。
在本章中,我们将详细学习 Python 数字类型的属性。
三种数字类型,整数**(int)**、浮点数**(float)**和**复数**,内置于 Python 解释器中。Python 还具有内置的布尔数据类型**bool**。它可以被视为 int 类型的子类型,因为它的两个可能值 True 和 False 分别表示整数 1 和 0。
Python – 整数
在Python中,任何没有小数部分的数字都是整数。(注意,如果一个数字的小数部分为0,并不意味着它就是一个整数。例如,数字10.0不是整数,它是一个小数部分为0的浮点数,其数值为10。)整数可以是零、正整数或负整数。例如,1234、0、-55。
创建整数对象有三种方法:字面量表示法、任何计算结果为整数的表达式,以及使用int()函数。
字面量是在源代码中直接表示常量的表示法。例如:
>>> a =10
但是,请看下面整数变量c的赋值。
a=10
b=20
c=a+b
print ("a:", a, "type:", type(a))
它将产生以下**输出**:
a: 10 type: <class 'int'>
这里,c确实是一个整数变量,但是表达式a+b首先被计算,其值间接地赋值给c。
创建整数对象的第三种方法是使用int()函数的返回值。它将浮点数或字符串转换为整数。
>>> a=int(10.5)
>>> b=int("100")
您可以将整数表示为二进制、八进制或十六进制数。但是,在内部,对象存储为整数。
二进制数
仅由二进制数字(1和0)组成并以0b为前缀的数字是二进制数。如果将二进制数赋给变量,它仍然是int变量。
要以二进制形式表示整数,请直接将其存储为字面量,或使用int()函数,其中基数设置为2。
a=0b101
print ("a:",a, "type:",type(a))
b=int("0b101011",2)
print ("b:",b, "type:",type(b))
它将产生以下**输出**:
a: 5 type: <class 'int'> b: 43 type: <class 'int'>
Python中还有一个bin()函数。它返回整数的二进制字符串等价物。
a=43
b=bin(a)
print ("Integer:",a, "Binary equivalent:",b)
它将产生以下**输出**:
Integer: 43 Binary equivalent: 0b101011
八进制数
八进制数仅由数字0到7组成。为了指定整数使用八进制表示法,需要在其前面加上0o(小写O)或0O(大写O)。八进制数的字面量表示如下:
a=0O107 print (a, type(a))
它将产生以下**输出**:
71 <class 'int'>
请注意,该对象在内部存储为整数。八进制数107的十进制等价物是71。
由于八进制数系统有8个符号(0到7),其基数为8。因此,在使用int()函数将八进制字符串转换为整数时,需要将base参数设置为8。
a=int('20',8)
print (a, type(a))
它将产生以下**输出**:
16 <class 'int'>
八进制30的十进制等价物是16。
在下面的代码中,从八进制表示法获得了两个int对象,并执行了它们的加法运算。
a=0O56
print ("a:",a, "type:",type(a))
b=int("0O31",8)
print ("b:",b, "type:",type(b))
c=a+b
print ("addition:", c)
它将产生以下**输出**:
a: 46 type: <class 'int'> b: 25 type: <class 'int'> addition: 71
要获取整数的八进制字符串,请使用oct()函数。
a=oct(71) print (a, type(a))
十六进制数
顾名思义,十六进制数系统中有16个符号。它们是0-9和A到F。前10个数字与十进制数字相同。字母A、B、C、D、E和F分别相当于11、12、13、14、15和16。可以使用这些字母符号的大写或小写。
对于十六进制表示法的整数的字面量表示,请在其前面加上0x或0X。
a=0XA2 print (a, type(a))
它将产生以下**输出**:
162 <class 'int'>
要将十六进制字符串转换为整数,请在int()函数中将基数设置为16。
a=int('0X1e', 16)
print (a, type(a))
尝试运行以下代码片段。它接收一个十六进制字符串,并返回整数。
num_string = "A1"
number = int(num_string, 16)
print ("Hexadecimal:", num_string, "Integer:",number)
它将产生以下**输出**:
Hexadecimal: A1 Integer: 161
但是,如果字符串包含任何十六进制符号表之外的符号(例如X001),则会引发以下错误:
Traceback (most recent call last):
File "C:\Python311\var1.py", line 4, in <module>
number = int(num_string, 16)
ValueError: invalid literal for int() with base 16: 'X001'
Python的标准库具有hex()函数,您可以使用它来获取整数的十六进制等价物。
a=hex(161) print (a, type(a))
它将产生以下**输出**:
0xa1 <class 'str'>
尽管整数可以表示为二进制、八进制或十六进制,但在内部它仍然是整数。因此,在执行算术运算时,表示法无关紧要。
a=10 #decimal
b=0b10 #binary
c=0O10 #octal
d=0XA #Hexadecimal
e=a+b+c+d
print ("addition:", e)
它将产生以下**输出**:
addition: 30
Python——浮点数
浮点数具有整数部分和小数部分,由小数点符号(.)分隔。默认情况下,该数字为正数,对于负数,请在其前面加上减号(-)符号。
浮点数是Python的float类的对象。要存储float对象,您可以使用字面量表示法,使用算术表达式的值,或使用float()函数的返回值。
使用字面量是最直接的方法。只需将带小数部分的数字赋给变量。以下每个语句都声明了一个float对象。
>>> a=9.99 >>> b=0.999 >>> c=-9.99 >>> d=-0.999
在Python中,对浮点数的小数点后可以有多少位数字没有限制。但是,为了缩短表示法,使用E或e符号。E代表10的幂。例如,E4是10的4次幂(或10的4次方),e-3是10的-3次幂。
在科学计数法中,数字具有系数和指数部分。系数应为大于或等于1但小于10的浮点数。因此,1.23E+3、9.9E-5和1E10是使用科学计数法的浮点数的示例。
>>> a=1E10 >>> a 10000000000.0 >>> b=9.90E-5 >>> b 9.9e-05 >>> 1.23E3 1230.0
形成float对象的第二种方法是间接的,使用表达式的结果。这里,两个浮点数的商被赋给一个变量,该变量引用一个float对象。
a=10.33
b=2.66
c=a/b
print ("c:", c, "type", type(c))
它将产生以下**输出**:
c: 3.8834586466165413 type <class 'float'>
Python的float()函数返回一个float对象,如果其内容合适,则解析数字或字符串。如果括号中没有给出参数,则返回0.0,对于int参数,则添加小数部分0。
>>> a=float() >>> a 0.0 >>> a=float(10) >>> a 10.0
即使整数以二进制、八进制或十六进制表示,float()函数也会返回小数部分为0的浮点数。
a=float(0b10) b=float(0O10) c=float(0xA) print (a,b,c, sep=",")
它将产生以下**输出**:
2.0,8.0,10.0
float()函数从包含浮点数的字符串中检索浮点数,该浮点数可以是标准小数点格式,也可以是科学计数法。
a=float("-123.54")
b=float("1.23E04")
print ("a=",a,"b=",b)
它将产生以下**输出**:
a= -123.54 b= 12300.0
在数学中,无穷大是一个抽象的概念。从物理上讲,无限大的数字永远无法存储在任何数量的内存中。但是,对于大多数计算机硬件配置,10的400次幂的非常大的数字由Inf表示。如果将“Infinity”用作float()函数的参数,它将返回Inf。
a=1.00E400
print (a, type(a))
a=float("Infinity")
print (a, type(a))
它将产生以下**输出**:
inf <class 'float'> inf <class 'float'>
另一个这样的实体是Nan(代表非数字)。它表示任何未定义或无法表示的值。
>>> a=float('Nan')
>>> a
Nan
Python——复数
在本节中,我们将详细了解Python中的复数数据类型。复数在电磁学、电子学、光学和量子理论的数学方程式和定律中得到了应用。傅里叶变换使用复数。它们用于计算波函数、设计滤波器、数字电子中的信号完整性、射电天文学等。
复数由实部和虚部分组成,由"+"或"-"分隔。实部可以是任何浮点数(或它本身是一个复数)。虚部也是一个浮点数/复数,但乘以一个虚数。
在数学中,虚数“i”定义为-1的平方根($\sqrt{−1}$)。因此,复数表示为“x+yi”,其中x是实部,“y”是虚部的系数。
通常,为了避免与在电力理论中作为电流的用法混淆,使用符号“j”代替“i”来表示虚数。Python也使用“j”作为虚数。因此,“x+yj”是Python中复数的表示法。
与int或float数据类型一样,可以使用字面量表示法或使用complex()函数来形成复数对象。以下所有语句都构成一个复数对象。
>>> a=5+6j >>> a (5+6j) >>> type(a) <class 'complex'> >>> a=2.25-1.2J >>> a (2.25-1.2j) >>> type(a) <class 'complex'> >>> a=1.01E-2+2.2e3j >>> a (0.0101+2200j) >>> type(a) <class 'complex'>
请注意,实部以及虚部的系数必须是浮点数,它们可以以标准小数点表示法或科学计数法表示。
Python的complex()函数有助于形成复数类型的对象。该函数接收实部和虚部的参数,并返回复数。
complex()函数有两个版本,分别有两个参数和一个参数。使用带两个参数的complex()是很直接的。它使用第一个参数作为实部,第二个参数作为虚部的系数。
a=complex(5.3,6)
b=complex(1.01E-2, 2.2E3)
print ("a:", a, "type:", type(a))
print ("b:", b, "type:", type(b))
它将产生以下**输出**:
a: (5.3+6j) type: <class 'complex'> b: (0.0101+2200j) type: <class 'complex'>
在上面的示例中,我们使用了x和y作为浮点参数。它们甚至可以是复数数据类型。
a=complex(1+2j, 2-3j) print (a, type(a))
它将产生以下**输出**:
(4+4j) <class 'complex'>
对上面的例子感到惊讶吗?将“x”设为1+2j,将“y”设为2-3j。尝试手动计算“x+yj”,你就会明白了。
complex(1+2j, 2-3j) =(1+2j)+(2-3j)*j =1+2j +2j+3 =4+4j
如果只为complex()函数使用一个数值参数,它将将其视为实部的值;虚部设置为0。
a=complex(5.3)
print ("a:", a, "type:", type(a))
它将产生以下**输出**:
a: (5.3+0j) type: <class 'complex'>
如果其唯一参数是具有复数表示的字符串,则complex()函数还可以将字符串解析为复数。
在下面的代码片段中,提示用户输入一个复数。它用作参数。由于Python将输入读取为字符串,因此该函数从中提取复数对象。
a= "5.5+2.3j"
b=complex(a)
print ("Complex number:", b)
它将产生以下**输出**:
Complex number: (5.5+2.3j)
Python的内置complex类有两个属性real和imag——它们从对象中返回实部和虚部的系数。
a=5+6j
print ("Real part:", a.real, "Coefficient of Imaginary part:", a.imag)
它将产生以下**输出**:
Real part: 5.0 Coefficient of Imaginary part: 6.0
complex类还定义了一个conjugate()方法。它返回另一个复数,其虚数部分的符号相反。例如,x+yj的共轭是x-yj。
>>> a=5-2.2j >>> a.conjugate() (5+2.2j)
Python - 布尔值
在Python中,bool是int类型的子类型。bool对象有两个可能的值,它用Python关键字True和False初始化。
>>> a=True >>> b=False >>> type(a), type(b) (<class 'bool'>, <class 'bool'>)
bool对象被接受为类型转换函数的参数。对于True作为参数,int()函数返回1,float()返回1.0;而对于False,它们分别返回0和0.0。我们有一个单参数版本的complex()函数。
如果参数是复数对象,则将其作为实部,并将虚数系数设置为0。
a=int(True)
print ("bool to int:", a)
a=float(False)
print ("bool to float:", a)
a=complex(True)
print ("bool to complex:", a)
运行此代码后,您将得到以下输出:
bool to int: 1 bool to float: 0.0 bool to complex: (1+0j)
Python - 控制流
默认情况下,计算机程序中的指令以顺序方式执行,从上到下,或从开始到结束。但是,这种顺序执行的程序只能执行简单的任务。我们希望程序具有决策能力,以便它根据不同的条件执行不同的步骤。
包括Python在内的多数编程语言都提供了控制指令执行流程的功能。通常,有两种类型的控制流语句。
决策——程序能够根据某个布尔表达式的值决定要执行哪个可选指令组。
下图说明了决策语句的工作方式:
循环或迭代——大多数过程都需要重复执行一组指令。在编程术语中,这称为循环。如果流程不是指向下一步,而是重定向到任何之前的步骤,则构成一个循环。
下图说明了循环的工作方式:
如果控制无条件地返回,则会形成无限循环,这是不希望的,因为其余代码将永远不会被执行。
在条件循环中,语句块的重复迭代会持续到满足某个条件为止。
Python - 决策
Python的决策功能在其关键字中——if、else和elif。if关键字需要一个布尔表达式,后跟冒号符号。
冒号(:)符号开始一个缩进块。如果if语句中的布尔表达式为True,则执行具有相同缩进级别的语句。如果表达式不为True(False),解释器将绕过缩进块,并继续执行较早缩进级别的语句。
Python——if语句
下图说明了Pythonif语句的工作方式:
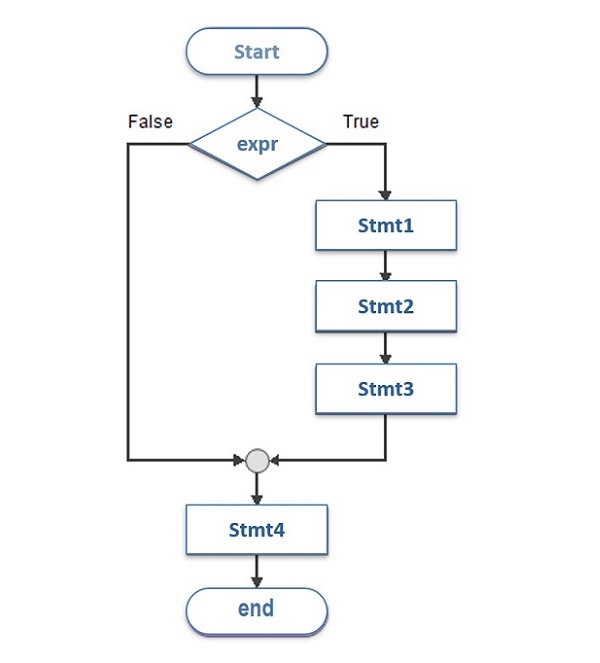
语法
上述流程图中的逻辑由以下语法表达:
if expr==True: stmt1 stmt2 stmt3 .. .. Stmt4
if语句类似于其他语言中的if语句。if语句包含一个布尔表达式,使用该表达式比较数据,并根据比较结果做出决定。
如果布尔表达式计算结果为 True,则执行 if 语句内的语句块。在 Python 中,代码块中的语句在“:”符号后统一缩进。如果布尔表达式的计算结果为 False,则执行代码块结束后的第一组代码。
示例
让我们考虑一个例子:如果客户的购买金额 >1000,则有权享受 10% 的折扣;否则,不适用任何折扣。此流程图显示了该过程。
在 Python 中,我们首先将折扣变量设置为 0,并接受用户输入的金额。
接下来是条件语句 if amt > 1000。使用冒号 ":" 开始条件代码块,在其中计算适用的折扣。显然,无论是否打折,下一条语句都会默认打印 amount-discount。如果适用折扣,则会减去折扣金额,否则为 0。
discount = 0
amount = 1200
if amount > 1000:
discount = amount * 10 / 100
print("amount = ",amount - discount)
这里金额为 1200,因此扣除 120 的折扣。执行代码后,您将得到以下输出:
amount = 1080.0
将变量 amount 更改为 800,然后再次运行代码。这次不适用任何折扣。您将得到以下输出:
amount = 800
Python - if-else 语句
除了if 语句之外,还可以选择使用 else 关键字。如果布尔表达式(在 if 语句中)不为真,它提供了要执行的另一组语句。此流程图显示了如何使用 else 代码块。
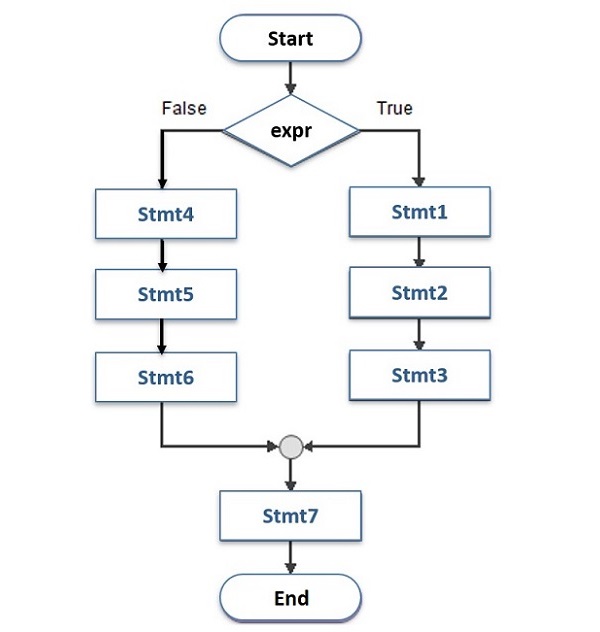
如果 expr 为 True,则执行 stmt1、2、3 代码块,然后默认流程继续执行 stmt7。但是,如果 expr 为 False,则执行代码块 stmt4、5、6,然后继续默认流程。
语法
上述流程图的 Python 实现如下:
if expr==True: stmt1 stmt2 stmt3 else: stmt4 stmt5 stmt6 Stmt7
示例
让我们通过以下示例了解 else 子句的用法。变量 age 可以取不同的值。如果表达式“age > 18”为真,则显示“您有资格投票”的消息;否则,应显示“无资格”消息。下面的流程图说明了此逻辑。
它的 Python 实现很简单。
age=25
print ("age: ", age)
if age>=18:
print ("eligible to vote")
else:
print ("not eligible to vote")
首先,将整数变量“age”设置为 25。
然后使用if 语句和表达式“age > 18”,后跟冒号“:”开始一个代码块;如果“age >= 18”为真,则此代码块将被执行。
要提供else 代码块,请使用“else:”;当“age >= 18”为假时,包含消息“无资格”的后续缩进代码块将被执行。
执行此代码后,您将得到以下输出:
age: 25 eligible to vote
要测试else 代码块,请将age更改为 12,然后再次运行代码。
age: 12 not eligible to vote
Python - elif 语句
elif 语句允许您检查多个表达式的真假,并在其中一个条件计算结果为 TRUE 时执行一段代码。
与else 语句类似,elif 语句是可选的。但是,与 else 不同的是,else 最多只能有一个语句;而if 语句之后可以有任意数量的elif 语句。
语法
if expression1: statement(s) elif expression2: statement(s) elif expression3: statement(s) else: statement(s)
示例
让我们借助以下示例了解 elif 的工作原理。
前面示例中使用的折扣结构已修改为不同的折扣等级:
金额超过 10000 元,享受 20% 的折扣;
金额在 5000-10000 元之间,享受 10% 的折扣;
金额在 1000-5000 元之间,享受 5% 的折扣;
金额小于 1000 元,不享受折扣。
下面的流程图说明了这些条件:
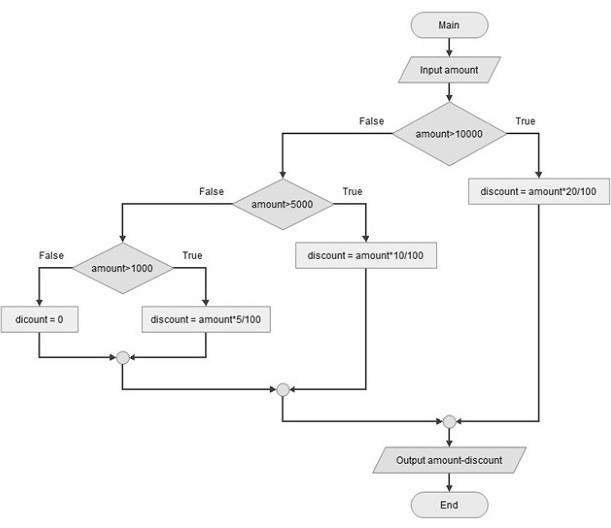
示例
我们可以使用if-else 语句编写上述逻辑的 Python 代码:
amount = int(input('Enter amount: '))
if amount > 10000:
discount = amount * 20 / 100
else:
if amount > 5000:
discount = amount * 10 / 100
else:
if amount > 1000:
discount = amount * 5 / 100
else:
dicount = 0
print('amount: ',amount - discount)
虽然代码可以完美运行,但如果您查看每个 if 和 else 语句的缩进级别不断增加,如果还有更多条件,则会难以管理。
elif 语句使代码更易于阅读和理解。
elif 是“else if”的缩写。它允许将逻辑排列在第一个 if 语句之后的 elif 语句级联中。如果第一个if 语句计算结果为假,则会逐一评估后续的 elif 语句,如果满足任何一个条件,则退出级联。
级联中的最后一个是else 代码块,当所有前面的 if/elif 条件都失败时,它将出现。
amount = 800
print('amount = ',amount)
if amount > 10000:
discount = amount * 20 / 100
elif amount > 5000:
discount = amount * 10 / 100
elif amount > 1000:
discount = amount * 5 / 100
else:
discount=0
print('payable amount = ',amount - discount)
设置amount 来测试所有可能的条件:800、2500、7500 和 15000。输出将相应变化:
amount: 800 payable amount = 800 amount: 2500 payable amount = 2375.0 amount: 7500 payable amount = 6750.0 amount: 15000 payable amount = 12000.0
嵌套 if 语句
可能存在这样的情况:在某个条件结果为真之后,您想检查另一个条件。在这种情况下,可以使用嵌套if 结构。
在嵌套 if 结构中,可以在另一个 if...elif...else 结构中使用 if...elif...else 结构。
语法
嵌套if...elif...else 结构的语法如下:
if expression1:
statement(s)
if expression2:
statement(s)
elif expression3:
statement(s)3
else
statement(s)
elif expression4:
statement(s)
else:
statement(s)
示例
现在让我们来看一段 Python 代码来了解它的工作原理:
# !/usr/bin/python3
num=8
print ("num = ",num)
if num%2==0:
if num%3==0:
print ("Divisible by 3 and 2")
else:
print ("divisible by 2 not divisible by 3")
else:
if num%3==0:
print ("divisible by 3 not divisible by 2")
else:
print ("not Divisible by 2 not divisible by 3")
执行上述代码时,它会产生以下输出:
num = 8 divisible by 2 not divisible by 3 num = 15 divisible by 3 not divisible by 2 num = 12 Divisible by 3 and 2 num = 5 not Divisible by 2 not divisible by 3
Python - match-case 语句
在 3.10 版本之前,Python 缺乏类似于 C 或 C++ 中 switch-case 的功能。在 Python 3.10 中,引入了一种称为 match-case 的模式匹配技术,它类似于“switch case”结构。
match 语句接受一个表达式,并将它的值与作为一个或多个 case 代码块给出的后续模式进行比较。它的用法更类似于 Rust 或 Haskell 等语言中的模式匹配,而不是 C 或 C++ 中的 switch 语句。只有第一个匹配的模式才会被执行。还可以从值中提取组件(序列元素或对象属性)到变量中。
语法
match-case 的基本用法是将变量与一个或多个值进行比较。
match variable_name: case 'pattern 1' : statement 1 case 'pattern 2' : statement 2 ... case 'pattern n' : statement n
示例
下面的代码包含一个名为 weekday() 的函数。它接收一个整数参数,将其与所有可能的星期几数字值匹配,并返回相应的星期几名称。
def weekday(n):
match n:
case 0: return "Monday"
case 1: return "Tuesday"
case 2: return "Wednesday"
case 3: return "Thursday"
case 4: return "Friday"
case 5: return "Saturday"
case 6: return "Sunday"
case _: return "Invalid day number"
print (weekday(3))
print (weekday(6))
print (weekday(7))
输出
执行后,此代码将产生以下输出:
Thursday Sunday Invalid day number
函数中的最后一个 case 语句使用 "_" 作为要比较的值。它用作通配符 case,如果所有其他 case 都为假,则将执行它。
组合 case
有时,可能存在这样的情况:对于多个 case,需要采取类似的操作。为此,您可以使用由 "|" 符号表示的 OR 运算符组合 case。
示例
def access(user):
match user:
case "admin" | "manager": return "Full access"
case "Guest": return "Limited access"
case _: return "No access"
print (access("manager"))
print (access("Guest"))
print (access("Ravi"))
输出
上面的代码定义了一个名为 access() 的函数,它有一个字符串参数,表示用户的名称。对于 admin 或 manager 用户,系统授予完全访问权限;对于 Guest,访问权限有限;对于其余用户,则无访问权限。
Full access Limited access No access
列表作为参数
由于 Python 可以将表达式与任何字面量匹配,因此您可以使用列表作为 case 值。此外,对于列表中数量可变的项目,可以使用 "*" 运算符将其解析为序列。
示例
def greeting(details):
match details:
case [time, name]:
return f'Good {time} {name}!'
case [time, *names]:
msg=''
for name in names:
msg+=f'Good {time} {name}!\n'
return msg
print (greeting(["Morning", "Ravi"]))
print (greeting(["Afternoon","Guest"]))
print (greeting(["Evening", "Kajal", "Praveen", "Lata"]))
输出
执行后,此代码将产生以下输出:
Good Morning Ravi! Good Afternoon Guest! Good Evening Kajal! Good Evening Praveen! Good Evening Lata!
在“case”子句中使用“if”
通常,Python 将表达式与字面量 case 进行匹配。但是,它允许您在 case 子句中包含 if 语句,用于对匹配变量进行条件计算。
在下面的示例中,函数参数是金额和期限的列表,需要计算金额小于或大于 10000 的利息。条件包含在case 子句中。
示例
def intr(details):
match details:
case [amt, duration] if amt<10000:
return amt*10*duration/100
case [amt, duration] if amt>=10000:
return amt*15*duration/100
print ("Interest = ", intr([5000,5]))
print ("Interest = ", intr([15000,3]))
输出
执行后,此代码将产生以下输出:
Interest = 2500.0 Interest = 6750.0
Python - for 循环
Python 中的for 循环能够迭代任何序列(例如列表或字符串)的项目。
语法
for iterating_var in sequence: statements(s)
如果序列包含表达式列表,则先对其进行计算。然后,序列中的第一个项目(位于第 0 个索引处)将分配给迭代变量 iterating_var。
接下来,执行语句块。列表中的每个项目都将分配给 iterating_var,并且语句块将一直执行,直到整个序列耗尽。
下面的流程图说明了for 循环的工作原理:
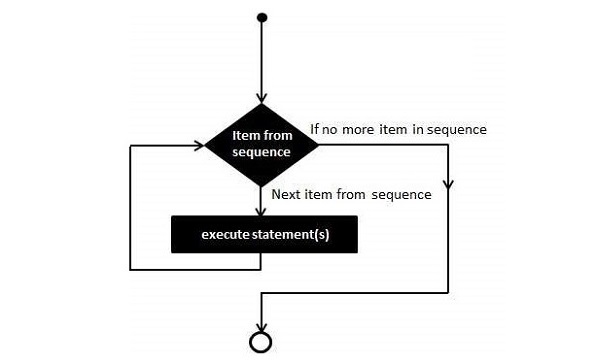
由于循环针对序列中的每个成员元素执行,因此无需显式验证控制循环的布尔表达式(如while 循环)。
列表、元组或字符串等序列对象称为可迭代对象,因为 for 循环会迭代集合。任何迭代器对象都可以由for 循环迭代。
字典的 items()、keys() 和 values() 方法返回的视图对象也是可迭代的,因此我们可以使用它们运行for 循环。
Python 的内置 range() 函数返回一个迭代器对象,该对象流式传输一系列数字。我们可以使用 range 运行 for 循环。
将“for”与字符串一起使用
字符串是由 Unicode 字母组成的序列,每个字母都有一个位置索引。以下示例比较每个字符,并显示它是否不是元音('a'、'e'、'i'、'o' 或 'u')。
示例
zen = '''
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
'''
for char in zen:
if char not in 'aeiou':
print (char, end='')
输出
执行后,此代码将产生以下输出:
Btfl s bttr thn gly. Explct s bttr thn mplct. Smpl s bttr thn cmplx. Cmplx s bttr thn cmplctd.
将“for”与元组一起使用
Python 的元组对象也是一个索引序列,因此我们可以使用for 循环遍历其项目。
示例
在下面的示例中,for 循环遍历包含整数的元组,并返回所有数字的总和。
numbers = (34,54,67,21,78,97,45,44,80,19)
total = 0
for num in numbers:
total+=num
print ("Total =", total)
输出
执行后,此代码将产生以下输出:
Total = 539
将“for”与列表一起使用
Python 的列表对象也是一个索引序列,因此我们可以使用for 循环遍历其项目。
示例
在下面的示例中,for 循环遍历包含整数的列表,只打印能被 2 整除的整数。
numbers = [34,54,67,21,78,97,45,44,80,19]
total = 0
for num in numbers:
if num%2 == 0:
print (num)
输出
执行后,此代码将产生以下输出:
34 54 78 44 80
将“for”与范围对象一起使用
Python 的内置 range() 函数返回一个范围对象。Python 的范围对象是一个迭代器,每次迭代都会生成一个整数。该对象包含从 start 到 stop 的整数,由 step 参数分隔。
语法
range() 函数具有以下语法:
range(start, stop, step)
参数
Start - 范围的起始值。可选。默认为 0。
Stop - 范围达到 stop-1。
Step - 范围内的整数以 step 值递增。可选,默认为 1。
返回值
range() 函数返回一个范围对象。它可以解析为列表序列。
示例
numbers = range(5) ''' start is 0 by default, step is 1 by default, range generated from 0 to 4 ''' print (list(numbers)) # step is 1 by default, range generated from 10 to 19 numbers = range(10,20) print (list(numbers)) # range generated from 1 to 10 increment by step of 2 numbers = range(1, 10, 2) print (list(numbers))
输出
执行后,此代码将产生以下输出:
[0, 1, 2, 3, 4] [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] [1, 3, 5, 7, 9]
示例
获得范围后,我们可以使用for 循环。
for num in range(5): print (num, end=' ') print() for num in range(10,20): print (num, end=' ') print() for num in range(1, 10, 2): print (num, end=' ')
输出
执行后,此代码将产生以下输出:
0 1 2 3 4 10 11 12 13 14 15 16 17 18 19 1 3 5 7 9
示例:数字的阶乘
阶乘是从 1 到该数字(例如 n)的所有数字的乘积。它也可以定义为 1、2 到 n 的乘积。
Factorial of a number n! = 1 * 2 * . . . . . * n
我们使用 range() 函数获取从 1 到 n-1 的数字序列,并执行累积乘法以获得阶乘值。
fact=1
N = 5
for x in range(1, N+1):
fact=fact*x
print ("factorial of {} is {}".format(N, fact))
输出
执行后,此代码将产生以下输出:
factorial of 5 is 120
在上程序中,更改 N 的值以获得不同数字的阶乘值。
将“for”循环与序列索引一起使用
要迭代序列,我们可以使用 range() 函数获取索引列表。
Indices = range(len(sequence))
然后我们可以形成一个for 循环,如下所示:
numbers = [34,54,67,21,78]
indices = range(len(numbers))
for index in indices:
print ("index:",index, "number:",numbers[index])
执行后,此代码将产生以下输出:
index: 0 number: 34 index: 1 number: 54 index: 2 number: 67 index: 3 number: 21 index: 4 number: 78
将“for”与字典一起使用
与列表、元组或字符串不同,Python 中的字典数据类型不是序列,因为项目没有位置索引。但是,仍然可以使用不同的技术遍历字典。
在字典对象上运行简单的for 循环会遍历其中使用的键。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers:
print (x)
执行后,此代码将产生以下输出:
10 20 30 40
一旦能够获取键,就可以使用方括号运算符或get() 方法轻松访问其关联的值。请查看以下示例:
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers:
print (x,":",numbers[x])
它将产生以下**输出**:
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
dict 类的 items()、keys() 和 values() 方法分别返回视图对象 dict_items、dict_keys 和 dict_values。这些对象是迭代器,因此我们可以在其上运行 for 循环。
dict_items 对象是键值元组的列表,可以在其上运行 for 循环,如下所示:
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers.items():
print (x)
它将产生以下**输出**:
(10, 'Ten') (20, 'Twenty') (30, 'Thirty') (40, 'Forty')
这里,“x”是来自 dict_items 迭代器的元组元素。我们可以进一步将此元组解包到两个不同的变量中。查看以下代码:
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x,y in numbers.items():
print (x,":", y)
它将产生以下**输出**:
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
同样,可以迭代 dict_keys 对象中的键集合。请查看以下示例:
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers.keys():
print (x, ":", numbers[x])
它将产生相同的输出:
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
Python - for-else 循环
Python 支持将“else”语句与“for”循环语句一起使用。“else”语句如果与“for”循环一起使用,则在控制权转移到主执行线之前序列耗尽时,将执行“else”语句。
下面的流程图说明了如何将else 语句与for 循环一起使用:
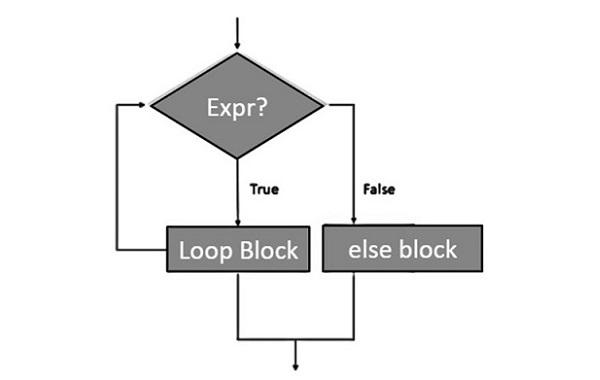
示例
以下示例演示了else语句与for语句的组合。在计数小于5之前,会打印迭代计数。当计数变为5时,else块中的打印语句会在控制权传递到主程序中的下一条语句之前执行。
for count in range(6):
print ("Iteration no. {}".format(count))
else:
print ("for loop over. Now in else block")
print ("End of for loop")
执行后,此代码将产生以下输出:
Iteration no. 1 Iteration no. 2 Iteration no. 3 Iteration no. 4 Iteration no. 5 for loop over. Now in else block End of for loop
嵌套循环
Python编程语言允许在一个循环内使用另一个循环。以下部分显示了一些示例来说明这个概念。
语法
for iterating_var in sequence:
for iterating_var in sequence:
statements(s)
statements(s)
Python编程语言中嵌套while循环语句的语法如下:
while expression:
while expression:
statement(s)
statement(s)
关于循环嵌套的最后一点说明是,您可以将任何类型的循环放在任何其他类型的循环内。例如,for循环可以放在while循环内,反之亦然。
示例
下面的程序使用嵌套for循环来显示1-10的乘法表。
#!/usr/bin/python3
for i in range(1,11):
for j in range(1,11):
k=i*j
print ("{:3d}".format(k), end=' ')
print()
print()函数内循环具有end=' ',它附加空格而不是默认换行符。因此,数字将显示在一行中。
最后一个print()将在内部for循环结束时执行。
执行上述代码时,它会产生以下输出:
1 2 3 4 5 6 7 8 9 10 2 4 6 8 10 12 14 16 18 20 3 6 9 12 15 18 21 24 27 30 4 8 12 16 20 24 28 32 36 40 5 10 15 20 25 30 35 40 45 50 6 12 18 24 30 36 42 48 54 60 7 14 21 28 35 42 49 56 63 70 8 16 24 32 40 48 56 64 72 80 9 18 27 36 45 54 63 72 81 90 10 20 30 40 50 60 70 80 90 100
Python - while循环
通常,计算机程序中步骤的执行流程是从开始到结束。但是,如果流程不是转向下一步,而是重定向到任何较早的步骤,则构成一个循环。
Python编程语言中的while循环语句会重复执行目标语句,只要给定的布尔表达式为真。
语法
Python编程语言中while循环的语法如下:
while expression: statement(s)
while关键字后跟一个布尔表达式,然后是冒号符号,以开始一个缩进的语句块。在这里,statement(s)可以是单个语句,也可以是具有统一缩进的语句块。条件可以是任何表达式,真值是任何非零值。只要布尔表达式为真,循环就会迭代。
一旦表达式变为假,程序控制就会传递到紧跟在循环后面的行。
如果它未能变为假,循环将继续运行,并且不会停止,除非强制停止。这样的循环称为无限循环,这在计算机程序中是不希望的。
下面的流程图说明了while循环:
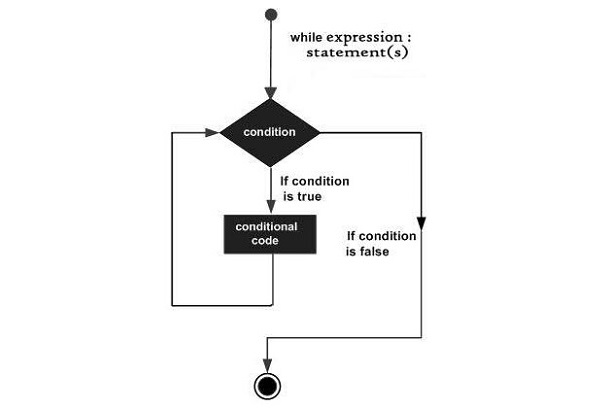
示例1
在Python中,在编程结构之后以相同数量的字符空格缩进的所有语句都被认为是单个代码块的一部分。Python使用缩进作为其语句分组的方法。
count=0
while count<5:
count+=1
print ("Iteration no. {}".format(count))
print ("End of while loop")
我们将计数变量初始化为0,循环运行直到“count<5”。在每次迭代中,都会递增并检查计数。如果它不是5,则进行下一次重复。在循环块内,打印计数的瞬时值。当while条件变为假时,循环终止,并执行下一条语句,这里是“while循环结束”消息。
输出
执行后,此代码将产生以下输出:
Iteration no. 1 Iteration no. 2 Iteration no. 3 Iteration no. 4 Iteration no. 5 End of while loop
示例2
这是另一个使用while循环的示例。对于每次迭代,程序都会请求用户输入并持续重复,直到用户输入非数字字符串。isnumeric()函数在输入为整数时返回true,否则返回false。
var='0'
while var.isnumeric()==True:
var=input('enter a number..')
if var.isnumeric()==True:
print ("Your input", var)
print ("End of while loop")
输出
执行后,此代码将产生以下输出:
enter a number..10 Your input 10 enter a number..100 Your input 100 enter a number..543 Your input 543 enter a number..qwer End of while loop
无限循环
如果条件永远不会变为FALSE,则循环将变成无限循环。使用while循环时必须谨慎,因为这种条件可能永远不会解析为FALSE值。这会导致一个永不结束的循环。这样的循环称为无限循环。
无限循环可能在客户端/服务器编程中很有用,其中服务器需要持续运行,以便客户端程序可以根据需要与其进行通信。
示例3
让我们来看一个例子,了解无限循环如何在Python中工作:
#!/usr/bin/python3
var = 1
while var == 1 : # This constructs an infinite loop
num = int(input("Enter a number :"))
print ("You entered: ", num)
print ("Good bye!")
输出
执行后,此代码将产生以下输出:
Enter a number :20
You entered: 20
Enter a number :29
You entered: 29
Enter a number :3
You entered: 3
Enter a number :11
You entered: 11
Enter a number :22
You entered: 22
Enter a number :Traceback (most recent call last):
File "examples\test.py", line 5, in
num = int(input("Enter a number :"))
KeyboardInterrupt
上面的例子进入了一个无限循环,你需要使用CTRL+C来退出程序。
while-else循环
Python支持将else语句与while循环语句关联。
如果else语句与while循环一起使用,则当条件在控制转移到主执行线之前变为false时,将执行else语句。
下面的流程图显示了如何将else与while语句一起使用:
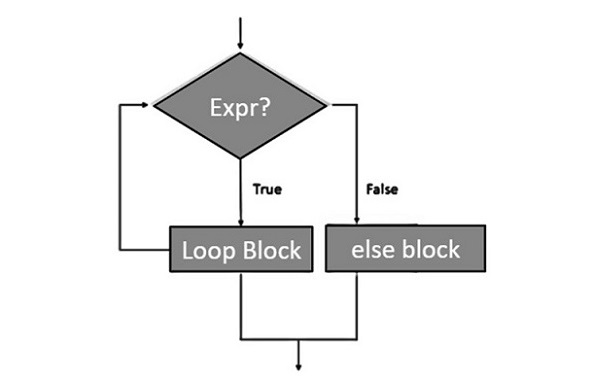
示例
以下示例演示了else语句与while语句的组合。在计数小于5之前,会打印迭代计数。当计数变为5时,else块中的打印语句会在控制权传递到主程序中的下一条语句之前执行。
count=0
while count<5:
count+=1
print ("Iteration no. {}".format(count))
else:
print ("While loop over. Now in else block")
print ("End of while loop")
输出
执行后,此代码将产生以下输出:
Iteration no. 1 Iteration no. 2 Iteration no. 3 Iteration no. 4 Iteration no. 5 While loop over. Now in else block End of while loop
Python - break语句
循环控制语句
循环控制语句会改变其正常的执行顺序。当执行离开作用域时,在该作用域中创建的所有自动对象都将被销毁。
Python支持以下控制语句:
| 序号 | 控制语句及描述 |
|---|---|
| 1 | break语句 终止循环语句并将执行转移到紧跟在循环后面的语句。 |
| 2 | continue语句 导致循环跳过其主体的其余部分,并在重新迭代之前立即重新测试其条件。 |
| 3 | pass语句 Python中的pass语句用于在语法上需要语句但不需要执行任何命令或代码时。 |
让我们简要地了解一下循环控制语句。
Python − break语句
break语句用于提前终止当前循环。放弃循环后,将在下一条语句处恢复执行,就像C中的传统break语句一样。
break最常见的用途是当触发某些外部条件需要快速退出循环时。break语句可以用于while和for循环。
如果您使用的是嵌套循环,则break语句将停止执行最内层循环并开始执行代码块后面的下一行代码。
语法
Python中break语句的语法如下:
break
流程图
它的流程图如下:
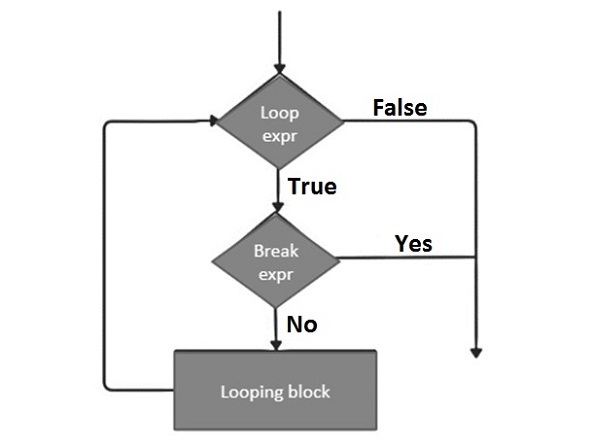
示例1
现在让我们来看一个例子,了解“break”语句如何在Python中工作:
#!/usr/bin/python3
print ('First example')
for letter in 'Python': # First Example
if letter == 'h':
break
print ('Current Letter :', letter)
print ('Second example')
var = 10 # Second Example
while var > 0:
print ('Current variable value :', var)
var = var -1
if var == 5:
break
print ("Good bye!")
执行上述代码时,它会产生以下输出:
First example Current Letter : P Current Letter : y Current Letter : t Second example Current variable value : 10 Current variable value : 9 Current variable value : 8 Current variable value : 7 Current variable value : 6 Good bye!
示例2
下面的程序演示了在遍历列表的for循环中使用break。用户输入一个数字,该数字将在列表中搜索。如果找到它,则循环将以“已找到”消息终止。
#!/usr/bin/python3
no=int(input('any number: '))
numbers=[11,33,55,39,55,75,37,21,23,41,13]
for num in numbers:
if num==no:
print ('number found in list')
break
else:
print ('number not found in list')
上述程序将产生以下输出:
any number: 33 number found in list any number: 5 number not found in list
示例3:检查质数
请注意,当遇到break语句时,Python会放弃循环中剩余的语句,包括else块。
以下示例利用此特性来查找数字是否为质数。根据定义,如果一个数除了1和它本身之外不能被任何其他数整除,则它是质数。
以下代码在从2到所需数字-1的数字上运行for循环。如果它能被循环变量的任何值整除,则该数字不是质数,因此程序将从循环中中断。如果该数字不能被2和x-1之间的任何数字整除,则else块将打印该数字为质数的消息。
num = 37
print ("Number: ", num)
for x in range(2,num):
if num%x==0:
print ("{} is not prime".format(num))
break
else:
print ("{} is prime".format(num))
输出
为num分配不同的值以检查它是否是质数。
Number: 37 37 is prime Number: 49 49 is not prime
Python - continue语句
Python中的continue语句将控制权返回到当前循环的开头。遇到时,循环开始下一次迭代,而不执行当前迭代中剩余的语句。
continue语句可用于while和for循环。
语法
continue
流程图
continue语句的流程图如下:
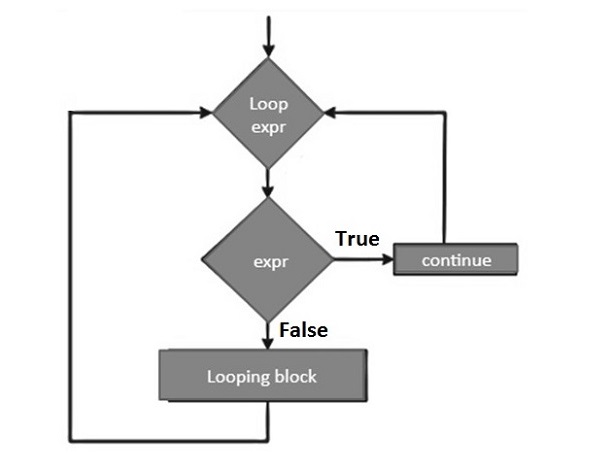
continue语句恰好与break相反。它跳过当前循环中剩余的语句并开始下一次迭代。
示例1
现在让我们来看一个例子,了解continue语句如何在Python中工作:
for letter in 'Python': # First Example
if letter == 'h':
continue
print ('Current Letter :', letter)
var = 10 # Second Example
while var > 0:
var = var -1
if var == 5:
continue
print ('Current variable value :', var)
print ("Good bye!")
执行上述代码时,它会产生以下输出:
Current Letter : P Current Letter : y Current Letter : t Current Letter : o Current Letter : n Current variable value : 9 Current variable value : 8 Current variable value : 7 Current variable value : 6 Current variable value : 4 Current variable value : 3 Current variable value : 2 Current variable value : 1 Current variable value : 0 Good bye!
示例2:检查质因数
以下代码使用continue来查找给定数字的质因数。为了找到质因数,我们需要从2开始连续除以给定数字,递增除数并继续相同的过程,直到输入减少到1。
查找质因数的算法如下:
接受用户输入(n)
将除数(d)设置为2
执行以下操作,直到n>1
检查给定数字(n)是否能被除数(d)整除。
如果n%d==0
a. 打印d作为因数
将n的新值设置为n/d
从4重复
如果不是
将d递增1
从3重复
以下是用于此目的的Python代码:
num = 60
print ("Prime factors for: ", num)
d=2
while num>1:
if num%d==0:
print (d)
num=num/d
continue
d=d+1
执行后,此代码将产生以下输出:
Prime factors for: 60 2 2 3 5
在上面的程序中为num分配不同的值(例如75),并测试其质因数的结果。
Prime factors for: 75 3 5 5
Python - pass语句
当语法上需要语句但不需要执行任何命令或代码时,使用pass语句。
pass语句是空操作;执行时不会发生任何事情。pass语句在代码最终将出现但尚未编写的地方(即在存根中)也很有用。
语法
pass
示例
以下代码显示了如何在Python中使用pass语句:
for letter in 'Python':
if letter == 'h':
pass
print ('This is pass block')
print ('Current Letter :', letter)
print ("Good bye!")
执行上述代码时,它会产生以下输出:
Current Letter : P Current Letter : y Current Letter : t This is pass block Current Letter : h Current Letter : o Current Letter : n Good bye!
Python - 函数
函数是一块组织良好的、可重用的代码,用于执行单个相关的操作。函数为您的应用程序提供了更好的模块化和高度的代码重用。
构建处理逻辑的自顶向下方法涉及定义独立的可重用函数块。可以通过传递所需数据(称为参数或参数)从任何其他函数调用函数。被调用的函数将其结果返回到调用环境。
Python函数的类型
Python提供以下类型的函数:
内置函数
在内置模块中定义的函数
用户定义函数
Python的标准库包含许多内置函数。一些Python的内置函数是print()、int()、len()、sum()等。这些函数始终可用,因为它们在您启动Python解释器时就会加载到计算机的内存中。
标准库还捆绑了许多模块。每个模块都定义了一组函数。这些函数并非随时可用。您需要从各自的模块将其导入内存。
除了内置函数和内置模块中的函数之外,您还可以创建自己的函数。这些函数称为用户定义的函数。
Python定义函数
您可以定义自定义函数以提供所需的功能。以下是Python中定义函数的一些简单规则。
函数块以关键字def开头,后跟函数名和括号(()。
任何输入参数或参数都应放在这些括号内。您也可以在这些括号内定义参数。
函数的第一条语句可以是可选语句;函数的文档字符串或文档字符串。
每个函数内的代码块以冒号(:)开头并缩进。
语句return [expression]退出函数,可以选择将表达式传递回调用方。没有参数的return语句与return None相同。
语法
def functionname( parameters ): "function_docstring" function_suite return [expression]
默认情况下,参数具有位置行为,您需要按定义的顺序通知它们。
定义函数后,您可以通过从另一个函数调用它或直接从Python提示符调用它来执行它。
示例
以下示例演示如何定义函数 greetings()。括号为空,因此没有任何参数。
第一行是文档字符串。函数块以 return 语句结束。调用此函数时,将打印Hello world 消息。
def greetings():
"This is docstring of greetings function"
print ("Hello World")
return
greetings()
调用函数
定义函数仅为其赋予名称,指定要包含在函数中的参数并构造代码块。
一旦函数的基本结构确定,就可以通过从另一个函数调用它或直接从 Python 提示符调用它来执行它。以下是调用 printme() 函数的示例:
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme("I'm first call to user defined function!")
printme("Again second call to the same function")
执行上述代码时,它会产生以下输出:
I'm first call to user defined function! Again second call to the same function
按引用传递与按值传递
Python 的函数调用机制与 C 和 C++ 的不同。主要有两种函数调用机制:按值调用和按引用调用。
将变量传递给函数时,函数对其做了什么?如果对其变量的任何更改都没有反映在实际参数中,则它使用按值调用机制。另一方面,如果更改被反映出来,则它成为按引用调用机制。
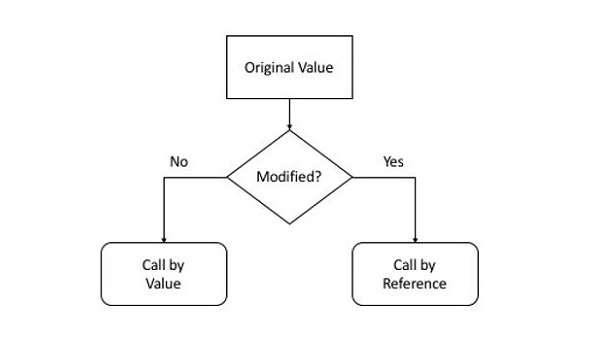
C/C++ 函数被称为按值调用。当调用 C/C++ 中的函数时,实际参数的值将复制到表示形式参数的变量中。如果函数修改了形式参数的值,则不会反映传递给它的变量。
Python 使用按引用传递机制。由于 Python 中的变量是内存中对象的标签或引用,因此用作实际参数和形式参数的变量实际上都引用内存中的同一个对象。我们可以通过检查传递变量之前和之后的 id() 来验证这一事实。
def testfunction(arg):
print ("ID inside the function:", id(arg))
var="Hello"
print ("ID before passing:", id(var))
testfunction(var)
如果执行上述代码,则传递之前和函数内部的 id() 相同。
ID before passing: 1996838294128 ID inside the function: 1996838294128
这种行为还取决于传递的对象是可变的还是不可变的。Python 数值对象是不可变的。当传递数值对象,然后函数更改形式参数的值时,它实际上会在内存中创建一个新对象,而原始变量保持不变。
def testfunction(arg):
print ("ID inside the function:", id(arg))
arg=arg+1
print ("new object after increment", arg, id(arg))
var=10
print ("ID before passing:", id(var))
testfunction(var)
print ("value after function call", var)
它将产生以下**输出**:
ID before passing: 140719550297160 ID inside the function: 140719550297160 new object after increment 11 140719550297192 value after function call 10
现在让我们将可变对象(例如列表或字典)传递给函数。它也是按引用传递的,因为传递前后 lidt 的 id() 相同。但是,如果我们在函数内部修改列表,它的全局表示也会反映出更改。
这里我们传递一个列表,添加一个新项目,然后查看原始列表对象的内容,我们会发现它已经改变了。
def testfunction(arg):
print ("Inside function:",arg)
print ("ID inside the function:", id(arg))
arg=arg.append(100)
var=[10, 20, 30, 40]
print ("ID before passing:", id(var))
testfunction(var)
print ("list after function call", var)
它将产生以下**输出**:
ID before passing: 2716006372544 Inside function: [10, 20, 30, 40] ID inside the function: 2716006372544 list after function call [10, 20, 30, 40, 100]
函数参数
函数的过程通常取决于调用它时提供给它的某些数据。在定义函数时,必须列出收集传递给它的数据的变量。括号中的变量称为形式参数。
调用函数时,必须为每个形式参数提供值。这些称为实际参数。
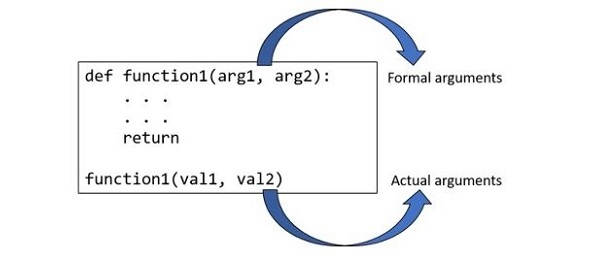
示例
让我们修改 greetings 函数并添加一个名为 name 的参数。调用时传递给它的字符串在函数内部成为 name 变量。
def greetings(name):
"This is docstring of greetings function"
print ("Hello {}".format(name))
return
greetings("Samay")
greetings("Pratima")
greetings("Steven")
它将产生以下**输出**:
Hello Samay Hello Pratima Hello Steven
带返回值的函数
return 关键字作为函数定义中的最后一条语句表示函数块的结束,程序流程返回到调用函数。尽管块中最后一条语句后的缩进减少也暗示了返回,但使用显式 return 是一个好习惯。
除了流程控制之外,函数还可以将表达式的值返回给调用函数。返回表达式的值可以存储在一个变量中以供进一步处理。
示例
让我们定义 add() 函数。它将传递给它的两个值相加并返回总和。返回的值存储在一个名为 result 的变量中。
def add(x,y):
z=x+y
return z
a=10
b=20
result = add(a,b)
print ("a = {} b = {} a+b = {}".format(a, b, result))
它将产生以下输出:
a = 10 b = 20 a+b = 30
函数参数的类型
根据在定义 Python 函数时参数的声明方式,它们被分为以下几类:
位置参数或必填参数
关键字参数
默认参数
仅限位置参数
仅限关键字参数
任意参数或变长参数
在接下来的几章中,我们将详细讨论这些函数参数。
参数顺序
函数可以具有上述任何类型的参数。但是,参数必须按以下顺序声明:
参数列表以仅限位置参数开头,后跟斜杠 (/) 符号。
其后是常规位置参数,这些参数可以也可以不作为关键字参数调用。
然后可能存在一个或多个具有默认值的参数。
接下来是任意位置参数,由以单个星号为前缀的变量表示,该变量被视为元组。这是下一个。
如果函数有任何仅限关键字参数,请在其名称开始之前放置一个星号。一些仅限关键字参数可能具有默认值。
括号中的最后一个参数使用两个星号 ** 来接受任意数量的关键字参数。
下图显示了形式参数的顺序:
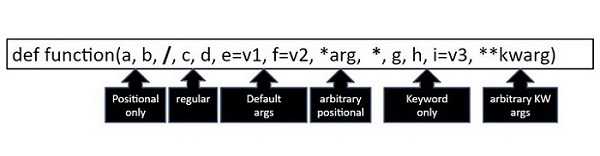
Python - 默认参数
您可以定义一个函数,为一个或多个形式参数分配默认值。如果未向其传递值,Python 将使用此类参数的默认值。如果传递任何值,则默认值将被覆盖。
示例
# Function definition is here
def printinfo( name, age = 35 ):
"This prints a passed info into this function"
print ("Name: ", name)
print ("Age ", age)
return
# Now you can call printinfo function
printinfo( age=50, name="miki" )
printinfo( name="miki" )
它将产生以下**输出**:
Name: miki Age 50 Name: miki Age 35
在上面的示例中,对函数的第二次调用没有向 age 参数传递值,因此使用其默认值 35。
让我们来看另一个为函数参数赋值默认值的例子。percent() 函数定义如下:
def percent(phy, maths, maxmarks=200): val = (phy+maths)*100/maxmarks return val
假设每门科目的分数为 100 分,则 maxmarks 参数设置为 200。因此,调用 percent() 函数时可以省略第三个参数的值。
phy = 60 maths = 70 result = percent(phy,maths)
但是,如果每门科目的最高分数不是 100,则调用 percent() 函数时需要填写第三个参数。
phy = 40 maths = 46 result = percent(phy,maths, 100)
示例
这是一个完整的示例:
def percent(phy, maths, maxmarks=200):
val = (phy+maths)*100/maxmarks
return val
phy = 60
maths = 70
result = percent(phy,maths)
print ("percentage:", result)
phy = 40
maths = 46
result = percent(phy,maths, 100)
print ("percentage:", result)
它将产生以下**输出**:
percentage: 65.0 percentage: 86.0
Python - 关键字参数
关键字参数也称为命名参数。函数定义中的变量用作关键字。调用函数时,您可以明确提及名称及其值。
示例
# Function definition is here
def printinfo( name, age ):
"This prints a passed info into this function"
print ("Name: ", name)
print ("Age ", age)
return
# Now you can call printinfo function
# by positional arguments
printinfo ("Naveen", 29)
# by keyword arguments
printinfo(name="miki", age = 30)
默认情况下,函数按出现顺序为参数赋值。在第二次函数调用中,我们为特定参数分配了值
它将产生以下**输出**:
Name: Naveen Age 29 Name: miki Age 30
让我们借助以下函数定义来更深入地了解关键字参数:
def division(num, den):
quotient = num/den
print ("num:{} den:{} quotient:{}".format(num, den, quotient))
division(10,5)
division(5,10)
由于值是根据位置分配的,因此输出如下:
num:10 den:5 quotient:2.0 num:5 den:10 quotient:0.5
让我们不要使用位置参数传递值,而是使用关键字参数调用函数:
division(num=10, den=5) division(den=5, num=10)
它将产生以下**输出**:
num:10 den:5 quotient:2.0 num:10 den:5 quotient:2.0
使用关键字参数时,不必遵循函数定义中形式参数的顺序。
使用关键字参数是可选的。您可以使用混合调用。您可以不使用关键字为某些参数传递值,而为其他参数使用关键字。
division(10, den=5)
但是,在使用混合调用时,位置参数必须位于关键字参数之前。
尝试使用以下语句调用 division() 函数。
division(num=5, 10)
由于位置参数不能出现在关键字参数之后,因此 Python 会引发以下错误消息:
division(num=5, 10)
^
SyntaxError: positional argument follows keyword argument
Python - 仅关键字参数
您可以使用形式参数列表中的变量作为关键字来传递值。使用关键字参数是可选的。但是,您可以强制函数仅通过关键字提供参数。您应该在仅限关键字参数列表之前放置一个星号 (*)。
假设我们有一个具有三个参数的函数,其中我们希望第二个和第三个参数为仅限关键字参数。为此,请在第一个参数之后放置 *。
内置的 print() 函数是仅限关键字参数的一个示例。您可以将要打印的表达式列表放在括号中。默认情况下,打印的值用空格分隔。您可以使用 sep 参数指定任何其他分隔符。
print ("Hello", "World", sep="-")
它将打印:
Hello-World
sep 参数是仅限关键字的。尝试将其用作非关键字参数。
print ("Hello", "World", "-")
您将获得不同的输出——并非预期的那样。
Hello World -
示例
在以下具有两个参数 amt 和 rate 的用户定义函数 intr() 中。为了使rate 参数仅限关键字,请在其前面放置 "*"。
def intr(amt,*, rate): val = amt*rate/100 return val
要调用此函数,必须通过关键字传递rate 的值。
interest = intr(1000, rate=10)
但是,如果您尝试使用默认位置调用函数的方式,则会收到错误。
interest = intr(1000, 10)
^^^^^^^^^^^^^^
TypeError: intr() takes 1 positional argument but 2 were given
Python - 位置参数
在定义函数时括号中声明的变量列表是形式参数。函数可以定义任意数量的形式参数。
调用函数时:
所有参数都是必需的
实际参数的数量必须等于形式参数的数量。
形式参数是位置参数。它们按定义顺序获取值。
参数的类型必须匹配。
形式参数和实际参数的名称不必相同。
示例
def add(x,y):
z=x+y
print ("x={} y={} x+y={}".format(x,y,z))
a=10
b=20
add(a,b)
它将产生以下**输出**:
x=10 y=20 x+y=30
这里,add() 函数有两个形式参数,两者都是数值型。当整数 10 和 20 传递给它时。变量 a 获取 10,b 获取 20,按声明顺序。add() 函数显示总和。
当参数数量不匹配时,Python 也会引发错误。只给出一个参数并检查结果。
add(b) TypeError: add() missing 1 required positional argument: 'y'
传递超过形式参数数量的参数并检查结果:
add(10, 20, 30) TypeError: add() takes 2 positional arguments but 3 were given
相应实际参数和形式参数的数据类型必须匹配。将 a 更改为字符串值并查看结果。
a="Hello" b=20 add(a,b)
它将产生以下**输出**:
z=x+y
~^~
TypeError: can only concatenate str (not "int") to str
Python - 仅位置参数
可以定义一个函数,其中一个或多个参数不能接受其关键字值。此类参数可以称为仅限位置参数。
Python 的内置 input() 函数是仅限位置参数的一个示例。input 函数的语法是:
input(prompt = "")
Prompt 是一个解释性字符串,供用户参考。例如:
name = input("enter your name ")
但是,您不能在括号内使用 prompt 关键字。
name = input (prompt="Enter your name ")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: input() takes no keyword arguments
要使参数仅限位置,请使用 "/" 符号。此符号之前的全部参数将被视为仅限位置参数。
示例
我们通过在 `intr()` 函数末尾添加“/”,将其两个参数都设置为仅位置参数。
def intr(amt, rate, /): val = amt*rate/100 return val
如果尝试将参数用作关键字参数,Python 会引发以下错误消息:
interest = intr(amt=1000, rate=10)
^^^^^^^^^^^^^^^^^^^^^^^
TypeError: intr() got some positional-only arguments passed as keyword arguments: 'amt, rate'
函数可以这样定义:它既有一些仅关键字参数,也有一些仅位置参数。
def myfunction(x, /, y, *, z): print (x, y, z)
在这个函数中,x 是必需的仅位置参数,y 是常规的位置参数(如果需要,可以用作关键字参数),而 z 是仅关键字参数。
以下函数调用是有效的:
myfunction(10, y=20, z=30) myfunction(10, 20, z=30)
但是,这些调用会引发错误:
myfunction(x=10, y=20, z=30) TypeError: myfunction() got some positional-only arguments passed as keyword arguments: 'x' myfunction(10, 20, 30) TypeError: myfunction() takes 2 positional arguments but 3 were given
Python - 可变参数
您可能希望定义一个能够接受任意数量或可变数量参数的函数。此外,任意数量的参数可能是位置参数或关键字参数。
用单个星号 * 前缀的参数表示任意数量的位置参数。
用两个星号 ** 前缀的参数表示任意数量的关键字参数。
示例
下面是一个任意或可变长度位置参数的示例:
# sum of numbers
def add(*args):
s=0
for x in args:
s=s+x
return s
result = add(10,20,30,40)
print (result)
result = add(1,2,3)
print (result)
用“*”前缀的 args 变量存储传递给它的所有值。这里,args 变成一个元组。我们可以循环遍历它的项目来添加数字。
它将产生以下**输出**:
100 6
也可以在可变数量的值序列之前,拥有一个函数,该函数具有一些必需的参数。
示例
下面的示例包含 avg() 函数。假设学生可以参加任意数量的考试。第一次考试是必须的。他可以参加尽可能多的考试来提高他的分数。该函数计算第一次考试的平均成绩和他其余考试中的最高分数。
该函数有两个参数,第一个是必需参数,第二个用于保存任意数量的值。
#avg of first test and best of following tests def avg(first, *rest): second=max(rest) return (first+second)/2 result=avg(40,30,50,25) print (result)
对 avg() 函数的以下调用将第一个值传递给必需参数 first,其余值传递给名为 rest 的元组。然后我们找到最大值并用它来计算平均值。
它将产生以下**输出**:
45.0
如果参数列表中的变量前面有两个星号,则函数可以接受任意数量的关键字参数。该变量将成为关键字:值对的字典。
示例
以下代码是具有任意关键字参数的函数的示例。addr() 函数有一个参数 **kwargs,它能够接受任意数量的地址元素,例如姓名、城市、电话号码、邮政编码等。在函数中,使用 items() 方法遍历 kw:value 对的 kwargs 字典。
def addr(**kwargs):
for k,v in kwargs.items():
print ("{}:{}".format(k,v))
print ("pass two keyword args")
addr(Name="John", City="Mumbai")
print ("pass four keyword args")
# pass four keyword args
addr(Name="Raam", City="Mumbai", ph_no="9123134567", PIN="400001")
它将产生以下**输出**:
pass two keyword args Name:John City:Mumbai pass four keyword args Name:Raam City:Mumbai ph_no:9123134567 PIN:400001
如果函数使用混合类型的参数,则任意关键字参数应该在位置参数、关键字参数和任意位置参数之后出现在参数列表中。
示例
想象一下,科学和数学是必修科目,此外学生可以选择任意数量的选修科目。
以下代码定义了一个 percent() 函数,其中科学和数学的成绩存储在必需参数中,而可变数量的选修科目的成绩存储在 **可选参数中。
def percent(math, sci, **optional):
print ("maths:", math)
print ("sci:", sci)
s=math+sci
for k,v in optional.items():
print ("{}:{}".format(k,v))
s=s+v
return s/(len(optional)+2)
result=percent(math=80, sci=75, Eng=70, Hist=65, Geo=72)
print ("percentage:", result)
它将产生以下**输出**:
maths: 80 sci: 75 Eng:70 Hist:65 Geo:72 percentage: 72.4
Python - 变量作用域
Python 中的变量是计算机内存中对象的符号名称。Python 基于命名空间的概念来定义各种标识符(如函数、变量等)的上下文。命名空间是当前上下文中定义的符号名称的集合。
Python 提供以下类型的命名空间:
内置命名空间包含内置函数和内置异常。它们在 Python 解释器加载到内存后立即加载,并一直保留到解释器运行结束。
全局命名空间包含主程序中定义的任何名称。这些名称保留在内存中,直到程序运行结束。
局部命名空间包含函数内部定义的名称。它们在函数运行期间可用。
这些命名空间彼此嵌套。下图显示了命名空间之间的关系。
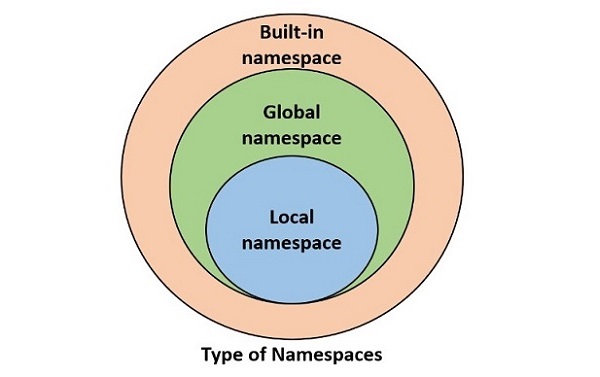
某个变量的生命周期仅限于其定义所在的命名空间。因此,无法从任何外部命名空间访问内部命名空间中存在的变量。
globals() 函数
Python 的标准库包含一个内置函数 globals()。它返回当前在全局命名空间中可用的符号的字典。
直接从 Python 提示符运行 globals() 函数。
>>> globals()
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>}
可以看出,包含所有内置函数和内置异常定义的 builtins 模块已加载。
保存以下包含少量变量和一个函数(其中包含更多变量)的代码。
name = 'TutorialsPoint' marks = 50 result = True def myfunction(): a = 10 b = 20 return a+b print (globals())
从这个脚本内部调用 globals() 返回以下字典对象:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000263E7255250>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:\\Users\\user\\examples\\main.py', '__cached__': None, 'name': 'TutorialsPoint', 'marks': 50, 'result': True, 'myfunction': <function myfunction at 0x00000263E72004A0>}
全局命名空间现在包含程序中的变量及其值以及其中的函数对象(而不是函数中的变量)。
locals() 函数
Python 的标准库包含一个内置函数 locals()。它返回函数命名空间中当前可用符号的字典。
修改上述脚本,以从函数内部打印全局和局部命名空间的字典。
name = 'TutorialsPoint'
marks = 50
result = True
def myfunction():
a = 10
b = 20
c = a+b
print ("globals():", globals())
print ("locals():", locals())
return c
myfunction()
输出显示 locals() 返回一个字典,其中包含函数中当前可用的变量及其值。
globals(): {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000169AE265250>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:\\Users\\mlath\\examples\\main.py', '__cached__': None, 'name': 'TutorialsPoint', 'marks': 50, 'result': True, 'myfunction': <function myfunction at 0x00000169AE2104A0>}
locals(): {'a': 10, 'b': 20, 'c': 30}
由于 globals() 和 locals() 函数都返回字典,因此您可以使用字典的 get() 方法或索引运算符访问相应命名空间中变量的值。
print (globals()['name']) #displays TutorialsPoint
print (locals().get('a')) #displays 10
命名空间冲突
如果全局和局部作用域中都存在同名变量,则 Python 解释器优先考虑局部命名空间中的变量。
marks = 50 # this is a global variable def myfunction(): marks = 70 # this is a local variable print (marks) myfunction() print (marks) # prints global value
它将产生以下**输出**:
70 50
如果尝试从函数内部操作全局变量的值,Python 会引发 UnboundLocalError。
marks = 50 # this is a global variable def myfunction(): marks = marks + 20 print (marks) myfunction() print (marks) # prints global value
它将产生以下**输出**:
marks = marks + 20
^^^^^
UnboundLocalError: cannot access local variable 'marks' where it is not associated with a value
要修改全局变量,您可以使用字典语法更新它,或者在修改之前使用 global 关键字引用它。
var1 = 50 # this is a global variable
var2 = 60 # this is a global variable
def myfunction():
"Change values of global variables"
globals()['var1'] = globals()['var1']+10
global var2
var2 = var2 + 20
myfunction()
print ("var1:",var1, "var2:",var2) #shows global variables with changed values
它将产生以下**输出**:
var1: 60 var2: 80
最后,如果尝试在全局作用域中访问局部变量,Python 会引发 NameError,因为局部作用域中的变量无法在局部作用域之外访问。
var1 = 50 # this is a global variable
var2 = 60 # this is a global variable
def myfunction(x, y):
total = x+y
print ("Total is a local variable: ", total)
myfunction(var1, var2)
print (total) # This gives NameError
它将产生以下输出:
Total is a local variable: 110
Traceback (most recent call last):
File "C:\Users\user\examples\main.py", line 9, in <module>
print (total) # This gives NameError
^^^^^
NameError: name 'total' is not defined
Python - 函数注解
Python 的函数注解功能使您可以添加有关函数定义中声明的参数以及返回数据类型的附加解释性元数据。
虽然您可以使用 Python 的文档字符串功能来记录函数,但如果对函数的原型进行了某些更改,它可能会过时。因此,PEP 3107 引入了注解功能。
Python 解释器在执行函数时不会考虑注解。它们主要用于 Python IDE,为程序员提供详细的文档。
注解是添加到参数或返回数据类型的任何有效的 Python 表达式。注解最简单的例子是规定参数的数据类型。注解是在参数前面加上冒号后作为表达式提到的。
def myfunction(a: int, b: int): c = a+b return c
请记住,Python 是一种动态类型语言,不会在运行时强制执行任何类型检查。因此,使用数据类型作为注解在调用函数时没有任何效果。即使给出非整数参数,Python 也不会检测到任何错误。
def myfunction(a: int, b: int):
c = a+b
return c
print (myfunction(10,20))
print (myfunction("Hello ", "Python"))
它将产生以下**输出**:
30 Hello Python
注解在运行时被忽略,但对于 IDE 和静态类型检查器库(如 mypy)很有用。
您也可以为返回数据类型添加注解。在括号之后和冒号符号之前,加上箭头 (->),然后加上注解。例如:
def myfunction(a: int, b: int) -> int: c = a+b return c
由于在运行时忽略使用数据类型作为注解,因此您可以使用任何充当参数元数据的表达式。因此,函数可以具有任何任意表达式作为注解,如下例所示:
def total(x : 'marks in Physics', y: 'marks in chemistry'): return x+y
如果要同时指定默认参数和注解,则需要将默认参数放在注解表达式之后。默认参数必须出现在参数列表中必需参数之后。
def myfunction(a: "physics", b:"Maths" = 20) -> int: c = a+b return c print (myfunction(10))
Python 中的函数也是一个对象,它的一个属性是 __annotations__。您可以使用 dir() 函数进行检查。
print (dir(myfunction))
这将打印 myfunction 对象的列表,其中包含 __annotations__ 作为其中一个属性。
['__annotations__', '__builtins__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__getstate__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
__annotations__ 属性本身是一个字典,其中参数是键,注解是值。
def myfunction(a: "physics", b:"Maths" = 20) -> int: c = a+b return c print (myfunction.__annotations__)
它将产生以下**输出**:
{'a': 'physics', 'b': 'Maths', 'return': <class 'int'>}
函数可以具有任意位置参数和/或任意关键字参数。也可以为它们提供注解。
def myfunction(*args: "arbitrary args", **kwargs: "arbitrary keyword args") -> int: pass print (myfunction.__annotations__)
它将产生以下**输出**:
{'args': 'arbitrary args', 'kwargs': 'arbitrary keyword args', 'return': <class 'int'>}
如果您需要为函数参数提供多个注解表达式,请以字典对象的格式在参数本身前面提供它。
def division(num: dict(type=float, msg='numerator'), den: dict(type=float, msg='denominator')) -> float: return num/den print (division.__annotations__)
它将产生以下**输出**:
{'num': {'type': <class 'float'>, 'msg': 'numerator'}, 'den': {'type': <class 'float'>, 'msg': 'denominator'}, 'return': <class 'float'>}
Python - 模块
函数是一块组织良好的、可重用的代码,用于执行单个相关的操作。函数为您的应用程序提供了更好的模块化和高度的代码重用。
Python 中的模块概念进一步增强了模块化。您可以将多个相关的函数一起定义并加载所需的函数。模块是一个文件,其中包含函数、类、变量、常量或任何其他 Python 对象的定义。此文件的内容可以提供给任何其他程序。Python 有一个 import 关键字用于此目的。
示例
import math
print ("Square root of 100:", math.sqrt(100))
它将产生以下**输出**:
Square root of 100: 10.0
内置模块
Python 的标准库捆绑了大量的模块。它们被称为内置模块。大多数这些内置模块都是用 C 编写的(因为 Python 的参考实现是用 C 编写的),并预编译到库中。这些模块打包了有用的功能,例如特定于系统的操作系统管理、磁盘 I/O、网络等。
这是一个精选的内置模块列表:
| 序号 | 名称和简要说明 |
|---|---|
1 |
os 此模块为许多操作系统函数提供了一个统一的接口。 |
2 |
string 此模块包含许多用于字符串处理的函数 |
3 |
re 此模块提供了一套强大的正则表达式功能。正则表达式 (RegEx) 允许对字符串中的模式进行强大的字符串搜索和匹配 |
4 |
math 此模块实现了许多浮点数的数学运算。这些函数通常是围绕平台 C 库函数的薄包装器。 |
5 |
cmath 此模块包含许多复数的数学运算。 |
6 |
datetime 此模块提供处理日期和一天中的时间的函数。它包装了 C 运行时库。 |
7 |
gc 此模块提供与内置垃圾收集器的接口。 |
8 |
asyncio 此模块定义了异步处理所需的功能 |
9 |
Collections 此模块提供高级容器数据类型。 |
10 |
Functools 此模块具有高阶函数和对可调用对象的运算。在函数式编程中很有用 |
11 |
operator 对应于标准运算符的函数。 |
12 |
pickle 将 Python 对象转换为字节流并返回。 |
13 |
socket 低级网络接口。 |
14 |
sqlite3 使用 SQLite 3.x 的 DB-API 2.0 实现。 |
15 |
statistics 数学统计函数 |
16 |
typing 对类型提示的支持 |
17 |
venv 创建虚拟环境。 |
18 |
json 编码和解码 JSON 格式。 |
19 |
wsgiref WSGI 实用程序和参考实现。 |
20 |
unittest Python 的单元测试框架。 |
21 |
random 生成伪随机数 |
用户定义模块
任何扩展名为 .py 且包含 Python 代码的文本文件基本上都是一个模块。它可以包含一个或多个函数、变量、常量的定义,以及类的定义。可以通过 import 语句将模块中的任何 Python 对象提供给解释器会话或另一个 Python 脚本。模块还可以包含可运行的代码。
创建模块
创建模块只不过是使用任何编辑器保存 Python 代码。让我们将以下代码保存为 **mymodule.py**
def SayHello(name):
print ("Hi {}! How are you?".format(name))
return
您现在可以在当前 Python 终端导入 mymodule。
>>> import mymodule
>>> mymodule.SayHello("Harish")
Hi Harish! How are you?
您也可以在一个 Python 脚本中导入另一个模块。将以下代码保存为 example.py
import mymodule
mymodule.SayHello("Harish")
从命令终端运行此脚本
C:\Users\user\examples> python example.py Hi Harish! How are you?
import 语句
在 Python 中,提供 **import** 关键字用于从一个模块加载 Python 对象。该对象可以是函数、类、变量等。如果模块包含多个定义,则所有定义都将加载到命名空间中。
让我们将包含三个函数的以下代码保存为 **mymodule.py**。
def sum(x,y): return x+y def average(x,y): return (x+y)/2 def power(x,y): return x**y
**import mymodule** 语句将此模块中的所有函数加载到当前命名空间中。导入模块中的每个函数都是此模块对象的属性。
>>> dir(mymodule) ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'average', 'power', 'sum']
要调用任何函数,请使用模块对象的引用。例如,mymodule.sum()。
import mymodule
print ("sum:",mymodule.sum(10,20))
print ("average:",mymodule.average(10,20))
print ("power:",mymodule.power(10, 2))
它将产生以下**输出**:
sum:30 average:15.0 power:100
from ... import 语句
import 语句会将模块的所有资源加载到当前命名空间中。可以使用此语法从模块导入特定对象。例如:
在 **mymodule** 中的三个函数中,只有两个导入到以下可执行脚本 **example.py** 中
from mymodule import sum, average
print ("sum:",sum(10,20))
print ("average:",average(10,20))
它将产生以下输出:
sum: 30 average: 15.0
请注意,无需在函数名前加模块名称来调用函数。
from...import * 语句
还可以使用以下 import 语句将模块中的所有名称导入到当前命名空间中:
from modname import *
这提供了一种简单的方法,可以将模块中的所有项导入到当前命名空间中;但是,应谨慎使用此语句。
import ... as 语句
您可以为导入的模块分配一个别名。
from modulename as alias
调用函数时,应在函数名前加上 **别名**。
请看下面的**示例**:
import mymodule as x
print ("sum:",x.sum(10,20))
print ("average:", x.average(10,20))
print ("power:", x.power(10, 2))
模块属性
在 Python 中,模块是模块类的对象,因此它具有属性。
以下是模块属性:
__file__ 返回模块的物理名称。
__package__ 返回模块所属的包。
__doc__ 返回模块顶部的文档字符串(如果存在)。
__dict__ 返回模块的整个作用域。
__name__ 返回模块的名称。
示例
假设以下代码保存为 **mymodule.py**
"The docstring of mymodule" def sum(x,y): return x+y def average(x,y): return (x+y)/2 def power(x,y): return x**y
让我们通过在以下脚本中导入它来检查 mymodule 的属性:
import mymodule
print ("__file__ attribute:", mymodule.__file__)
print ("__doc__ attribute:", mymodule.__doc__)
print ("__name__ attribute:", mymodule.__name__)
它将产生以下**输出**:
__file__ attribute: C:\Users\mlath\examples\mymodule.py __doc__ attribute: The docstring of mymodule __name__ attribute: mymodule
__name__ 属性
Python 模块的 __name__ 属性具有重要意义。让我们更详细地探讨一下。
在交互式 shell 中,__name__ 属性返回 '__main__'。
>>> __name__ '__main__'
如果在解释器会话中导入任何模块,它将返回该模块的名称作为该模块的 __name__ 属性。
>>> import math >>> math.__name__ 'math'
从 Python 脚本内部,__name__ 属性返回 '__main__'。
#example.py
print ("__name__ attribute within a script:", __name__)
在命令终端运行此命令:
__name__ attribute within a script: __main__
此属性允许 Python 脚本用作可执行文件或模块。与 C++、Java、C# 等不同,在 Python 中,没有 main() 函数的概念。扩展名为 .py 的 Python 程序脚本可以包含函数定义以及可执行语句。
保存 **mymodule.py**,代码如下:
"The docstring of mymodule"
def sum(x,y):
return x+y
print ("sum:",sum(10,20))
您可以看到 sum() 函数在其定义的同一脚本中被调用。
C:\Users\user\examples> python mymodule.py sum: 30
现在让我们在另一个脚本 **example.py** 中导入此函数。
import mymodule
print ("sum:",mymodule.sum(10,20))
它将产生以下**输出**:
C:\Users\user\examples> python example.py sum: 30 sum: 30
输出 "sum:30" 出现两次。一次是在导入 mymodule 模块时。导入模块中的可执行语句也会运行。第二个输出来自调用脚本,即 **example.py** 程序。
我们想要的结果是,当导入模块时,只导入函数,而不运行其可执行语句。这可以通过检查 __name__ 的值来实现。如果它是 __main__,则表示它正在运行而不是被导入。有条件地包含可执行语句,例如函数调用。
在 **mymodule.py** 中添加 **if** 语句,如下所示:
"The docstring of mymodule"
def sum(x,y):
return x+y
if __name__ == "__main__":
print ("sum:",sum(10,20))
现在,如果运行 **example.py** 程序,您会发现 sum:30 输出只出现一次。
C:\Users\user\examples> python example.py sum: 30
reload() 函数
有时您可能需要重新加载模块,尤其是在使用 Python 的交互式解释器会话时。
假设我们有一个包含以下函数的测试模块 (test.py):
def SayHello(name):
print ("Hi {}! How are you?".format(name))
return
我们可以从 Python 提示符导入模块并调用其函数,如下所示:
>>> import test
>>> test.SayHello("Deepak")
Hi Deepak! How are you?
但是,假设您需要修改 SayHello() 函数,例如:
def SayHello(name, course):
print ("Hi {}! How are you?".format(name))
print ("Welcome to {} Tutorial by TutorialsPoint".format(course))
return
即使您编辑 test.py 文件并保存它,加载到内存中的函数也不会更新。您需要使用 imp 模块中的 reload() 函数重新加载它。
>>> import imp
>>> imp.reload(test)
>>> test.SayHello("Deepak", "Python")
Hi Deepak! How are you?
Welcome to Python Tutorial by TutorialsPoint
Python - 内置函数
截至 Python 3.11.2 版本,Python 中有 71 个内置函数。以下是内置函数的列表:
| 序号 | 函数和说明 |
|---|---|
1 |
abs() 返回数字的绝对值 |
2 |
aiter() 为异步可迭代对象返回异步迭代器 |
3 |
all() 当可迭代对象中的所有元素都为真时返回真 |
4 |
anext() 返回给定异步迭代器的下一个项目 |
5 |
any() 检查可迭代对象的任何元素是否为真 |
6 |
ascii() 返回包含可打印表示形式的字符串 |
7 |
bin() 将整数转换为二进制字符串 |
8 |
bool() 将值转换为布尔值 |
9 |
breakpoint() 此函数会在调用站点将您放入调试器中,并调用 sys.breakpointhook() |
10 |
bytearray() 返回给定字节大小的数组 |
11 |
bytes() 返回不可变的 bytes 对象 |
12 |
callable() 检查对象是否可调用 |
13 |
chr() 从整数返回字符(字符串) |
14 |
classmethod() 为给定函数返回类方法 |
15 |
compile() 返回代码对象 |
16 |
complex() 创建一个复数 |
17 |
delattr() 从对象中删除属性 |
18 |
dict() 创建一个字典 |
19 |
dir() 尝试返回对象的属性 |
20 |
divmod() 返回商和余数的元组 |
21 |
enumerate() 返回一个枚举对象 |
22 |
eval() 在程序中运行代码 |
23 |
exec() 执行动态创建的程序 |
24 |
filter() 从为真的元素构造迭代器 |
25 |
float() 从数字、字符串返回浮点数 |
26 |
format() 返回值的格式化表示形式 |
27 |
frozenset() 返回不可变的 frozenset 对象 |
28 |
getattr() 返回对象的命名属性的值 |
29 |
globals() 返回当前全局符号表的字典 |
30 |
hasattr() 返回对象是否具有命名属性 |
31 |
hash() 返回对象的哈希值 |
32 |
help() 调用内置帮助系统 |
33 |
hex() 将整数转换为十六进制 |
34 |
id() 返回对象的标识 |
35 |
input() 读取并返回一行字符串 |
36 |
int() 从数字或字符串返回整数 |
37 |
isinstance() 检查对象是否是类的实例 |
38 |
issubclass() 检查类是否是另一个类的子类 |
39 |
iter() 返回迭代器 |
40 |
len() 返回对象的长度 |
41 |
list() 在 Python 中创建一个列表 |
42 |
locals() 返回当前局部符号表的字典 |
43 |
map() 应用函数并返回列表 |
44 |
max() 返回最大的项目 |
45 |
memoryview() 返回参数的内存视图 |
46 |
min() 返回最小值 |
47 |
next() 从迭代器检索下一个项目 |
48 |
object() 创建一个无特征的对象 |
49 |
oct() 返回整数的八进制表示形式 |
50 |
open() 返回文件对象 |
51 |
ord() 返回 Unicode 字符的整数 |
52 |
pow() 返回数字的幂 |
53 |
print() 打印给定的对象 |
54 |
property() 返回属性属性 |
55 |
range() 返回整数序列 |
56 |
repr() 返回对象的打印表示形式 |
57 |
reversed() 返回序列的反向迭代器 |
58 |
round() 将数字四舍五入到指定的十进制数 |
59 |
set() 构造并返回一个集合 |
60 |
setattr() 设置对象的属性的值 |
61 |
slice() 返回切片对象 |
62 |
sorted() 从给定的可迭代对象返回排序列表 |
63 |
staticmethod() 将方法转换为静态方法 |
64 |
str() 返回对象的字符串版本 |
65 |
sum() 添加可迭代对象的项目 |
66 |
super() 返回基类的代理对象 |
67 |
tuple() 返回一个元组 |
68 |
type() 返回对象的类型 |
69 |
vars() 返回 __dict__ 属性 |
70 |
zip() 返回元组的迭代器 |
71 |
__import__() import 语句调用的函数 |
内置数学函数
以下数学函数内置于 Python 解释器中,因此您无需从任何模块导入它们。
| 序号 | 函数和说明 |
|---|---|
1 |
abs() 函数返回 x 的绝对值,即 x 和零之间的正距离。 |
2 |
max() 函数返回其参数中最大的一个,或可迭代对象(列表或元组)中的最大数字。 |
3 |
min() 函数返回其参数中最小的一个,即最接近负无穷大的值,或可迭代对象(列表或元组)中的最小数字。 |
4 |
pow() 函数返回 x 的 y 次幂。它等效于 x**y。该函数具有第三个可选参数 mod。如果给出,它将返回 (x**y) % mod 值。 |
5 |
round() 是 Python 的内置函数。它返回 x 四舍五入到小数点后 n 位的结果。 |
6 |
sum() 函数返回任何可迭代对象(列表或元组)中所有数字项的总和。可选的 start 参数默认为 0。如果给出 start 参数,则列表中的数字将添加到 start 值。 |
Python - 字符串
在 Python 中,字符串是不可变的 Unicode 字符序列。根据 Unicode 标准,每个字符都有一个唯一的数值。但是,整个序列本身没有任何数值,即使所有字符都是数字。为了区分字符串与数字和其他标识符,字符序列在其字面表示中包含在单引号、双引号或三引号中。因此,1234 是一个数字(整数),而 '1234' 是一个字符串。
只要字符序列相同,单引号、双引号或三引号都没有关系。因此,以下字符串表示是等效的。
>>> 'Welcome To TutorialsPoint' 'Welcome To TutorialsPoint' >>> "Welcome To TutorialsPoint" 'Welcome To TutorialsPoint' >>> '''Welcome To TutorialsPoint''' 'Welcome To TutorialsPoint' >>> """Welcome To TutorialsPoint""" 'Welcome To TutorialsPoint'
从上面的语句可以看出,Python 内部将字符串存储为用单引号括起来的。
Python 中的字符串是 str 类的对象。可以使用 type() 函数验证。
var = "Welcome To TutorialsPoint" print (type(var))
它将产生以下**输出**:
<class 'str'>
如果要将一些用双引号括起来的文本嵌入到字符串中,则字符串本身应该用单引号括起来。要嵌入用单引号括起来的文本,字符串应该用双引号括起来。
var = 'Welcome to "Python Tutorial" from TutorialsPoint'
print ("var:", var)
var = "Welcome to 'Python Tutorial' from TutorialsPoint"
print ("var:", var)
要使用三引号形成字符串,可以使用三个单引号或三个双引号——这两个版本相似。
var = '''Welcome to TutorialsPoint'''
print ("var:", var)
var = """Welcome to TutorialsPoint"""
print ("var:", var)
三引号字符串可用于构成多行字符串。
var = '''
Welcome To
Python Tutorial
from TutorialsPoint
'''
print ("var:", var)
它将产生以下**输出**:
var: Welcome To Python Tutorial from TutorialsPoint
字符串是一种非数值数据类型。显然,我们不能将算术运算符与字符串操作数一起使用。在这种情况下,Python 会引发 TypeError。
>>> "Hello"-"World" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for -: 'str' and 'str'
Python 字符串切片
在 Python 中,字符串是有序的 Unicode 字符序列。字符串中的每个字符在序列中都有一个唯一的索引。索引从 0 开始。字符串中的第一个字符的索引为 0。索引向字符串结尾递增。
如果字符串变量声明为 var="HELLO PYTHON",则字符串中每个字符的索引如下:

Python 允许您通过其索引访问字符串中的任何单个字符。在这种情况下,0 是下界,11 是字符串的上界。因此,var[0] 返回 H,var[6] 返回 P。如果方括号中的索引超过上界,Python 将引发 IndexError。
>>> var="HELLO PYTHON" >>> var[0] 'H' >>> var[7] 'Y' >>> var[11] 'N' >>> var[12] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: string index out of range
Python 序列类型(因此也是字符串对象)的独特功能之一是它也具有负索引方案。在上面的示例中,使用了正索引方案,其中索引从左到右递增。在负索引的情况下,末尾的字符索引为 -1,索引从右到左递减,因此第一个字符 H 的索引为 -12。

让我们使用负索引来获取 N、Y 和 H 字符。
>>> var[-1] 'N' >>> var[-5] 'Y' >>> var[-12] 'H' >>> var[-13] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: string index out of range
再次强调,如果索引超出范围,则会遇到 IndexError。
因此,我们可以使用正索引或负索引从字符串中检索字符。
>>> var[0], var[-12]
('H', 'H')
>>> var[7], var[-5]
('Y', 'Y')
>>> var[11], var[-1]
('N', 'N')
在 Python 中,字符串是不可变对象。如果对象一旦存储在某个内存位置后就不能就地修改,则该对象是不可变的。您可以借助索引检索字符串中的任何字符,但不能将其替换为另一个字符。在我们的示例中,字符 Y 在 HELLO PYTHON 中的索引为 7。尝试将 Y 替换为 y 并看看会发生什么。
var="HELLO PYTHON" var[7]="y" print (var)
它将产生以下**输出**:
Traceback (most recent call last): File "C:\Users\users\example.py", line 2, in <module> var[7]="y" ~~~^^^ TypeError: 'str' object does not support item assignment
出现 TypeError 是因为字符串是不可变的。
Python 将 ":" 定义为字符串切片运算符。它从原始字符串返回子字符串。其一般用法为:
substr=var[x:y]
":" 运算符需要两个整数操作数(这两个操作数都可以省略,我们将在后续示例中看到)。第一个操作数 x 是所需切片的第一个字符的索引。第二个操作数 y 是所需字符串中最后一个字符下一个字符的索引。因此,var[x:y] 从原始字符串中分离从第 x 个位置到第 (y-1) 个位置的字符。
var="HELLO PYTHON"
print ("var:",var)
print ("var[3:8]:", var[3:8])
它将产生以下**输出**:
var: HELLO PYTHON var[3:8]: LO PY
负索引也可以用于切片。
var="HELLO PYTHON"
print ("var:",var)
print ("var[3:8]:", var[3:8])
print ("var[-9:-4]:", var[-9:-4])
它将产生以下**输出**:
var: HELLO PYTHON var[3:8]: LO PY var[-9:-4]: LO PY
Python 的切片运算符的两个操作数都是可选的。第一个操作数默认为零,这意味着如果我们不提供第一个操作数,则切片从索引为 0 的字符开始,即第一个字符。它将最左边的子字符串切片到“y-1”个字符。
var="HELLO PYTHON"
print ("var:",var)
print ("var[0:5]:", var[0:5])
print ("var[:5]:", var[:5])
它将产生以下**输出**:
var: HELLO PYTHON var[0:5]: HELLO var[:5]: HELLO
同样,y 操作数也是可选的。默认情况下,它是“-1”,这意味着字符串将从第 x 个位置切片到字符串的末尾。
var="HELLO PYTHON"
print ("var:",var)
print ("var[6:12]:", var[6:12])
print ("var[6:]:", var[6:])
它将产生以下输出:
var: HELLO PYTHON var[6:12]: PYTHON var[6:]: PYTHON
自然地,如果两个操作数都没有使用,则切片将等于原始字符串。这是因为“x”为 0,“y”默认为最后一个索引+1(或 -1)。
var="HELLO PYTHON"
print ("var:",var)
print ("var[0:12]:", var[0:12])
print ("var[:]:", var[:])
它将产生以下**输出**:
var: HELLO PYTHON var[0:12]: HELLO PYTHON var[:]: HELLO PYTHON
为了获得原始字符串的子字符串,左操作数必须小于右操作数。如果左操作数较大,Python 不会引发任何错误,而是返回空字符串。
var="HELLO PYTHON"
print ("var:",var)
print ("var[-1:7]:", var[-1:7])
print ("var[7:0]:", var[7:0])
它将产生以下**输出**:
var: HELLO PYTHON var[-1:7]: var[7:0]:
切片返回一个新字符串。您可以很好地对切片字符串执行字符串操作,如连接或切片。
var="HELLO PYTHON"
print ("var:",var)
print ("var[:6][:2]:", var[:6][:2])
var1=var[:6]
print ("slice:", var1)
print ("var1[:2]:", var1[:2])
它将产生以下**输出**:
var: HELLO PYTHON var[:6][:2]: HE slice: HELLO var1[:2]: HE
Python - 修改字符串
在 Python 中,字符串(str 类的对象)是不可变类型的。不可变对象是在内存中创建的对象,不能就地修改。因此,与列表不同,序列中的任何字符都不能被覆盖,我们也不能向其中插入或追加字符,除非我们使用返回新字符串对象的某些字符串方法。
但是,我们可以使用以下技巧之一作为解决方法来修改字符串。
将字符串转换为列表
由于字符串和列表对象都是序列,因此它们是可相互转换的。因此,如果我们将字符串对象转换为列表,通过 insert()、append() 或 remove() 方法修改列表,并将列表转换回字符串,则可以获得修改后的版本。
我们有一个字符串变量 s1,其值为 WORD。使用 list() 内置函数,让我们将其转换为 l1 列表对象,并在索引 3 处插入字符 L。然后,我们使用 str 类中的 join() 方法连接所有字符。
s1="WORD"
print ("original string:", s1)
l1=list(s1)
l1.insert(3,"L")
print (l1)
s1=''.join(l1)
print ("Modified string:", s1)
它将产生以下**输出**:
original string: WORD ['W', 'O', 'R', 'L', 'D'] Modified string: WORLD
使用 Array 模块
要修改字符串,请构造一个数组对象。Python 标准库包含 array 模块。我们可以从字符串变量中获得 Unicode 类型的数组。
import array as ar
s1="WORD"
sar=ar.array('u', s1)
数组中的项目具有基于零的索引。因此,我们可以执行诸如 append、insert、remove 等数组操作。让我们在字符 D 之前插入 L
sar.insert(3,"L")
现在,借助 tounicode() 方法,取回修改后的字符串
import array as ar
s1="WORD"
print ("original string:", s1)
sar=ar.array('u', s1)
sar.insert(3,"L")
s1=sar.tounicode()
print ("Modified string:", s1)
它将产生以下**输出**:
original string: WORD Modified string: WORLD
使用 StringIO 类
Python 的 io 模块定义了用于处理流的类。StringIO 类使用内存文本缓冲区表示文本流。从字符串获得的 StringIO 对象的行为类似于 File 对象。因此,我们可以对其执行读/写操作。StringIO 类的 getvalue() 方法返回一个字符串。
让我们在以下程序中使用此原理来修改字符串。
import io
s1="WORD"
print ("original string:", s1)
sio=io.StringIO(s1)
sio.seek(3)
sio.write("LD")
s1=sio.getvalue()
print ("Modified string:", s1)
它将产生以下**输出**:
original string: WORD Modified string: WORLD
Python - 字符串连接
“+”运算符众所周知的是加法运算符,返回两个数字的和。但是,“+”符号在 Python 中充当字符串连接运算符。它与两个字符串操作数一起工作,并导致两个字符串的连接。
加号符号右侧字符串的字符将附加到其左侧的字符串。连接的结果是一个新字符串。
str1="Hello"
str2="World"
print ("String 1:",str1)
print ("String 2:",str2)
str3=str1+str2
print("String 3:",str3)
它将产生以下**输出**:
String 1: Hello String 2: World String 3: HelloWorld
要在两者之间插入空格,请使用第三个空字符串。
str1="Hello"
str2="World"
blank=" "
print ("String 1:",str1)
print ("String 2:",str2)
str3=str1+blank+str2
print("String 3:",str3)
它将产生以下**输出**:
String 1: Hello String 2: World String 3: Hello World
另一个符号 *,我们通常将其用于两个数字的乘法,也可以与字符串操作数一起使用。在这里,* 在 Python 中充当重复运算符。其中一个操作数必须是整数,另一个操作数必须是字符串。运算符连接字符串的多个副本。例如:
>>> "Hello"*3 'HelloHelloHello'
整数操作数是要连接的字符串操作数的副本数。
字符串运算符(*)重复运算符和(+)连接运算符都可以用在一个表达式中。“*”运算符的优先级高于“+”运算符。
str1="Hello"
str2="World"
print ("String 1:",str1)
print ("String 2:",str2)
str3=str1+str2*3
print("String 3:",str3)
str4=(str1+str2)*3
print ("String 4:", str4)
要形成str3 字符串,Python 首先连接 World 的 3 个副本,然后将其结果附加到 Hello
String 3: HelloWorldWorldWorld
在第二种情况下,字符串 str1 和 str2 在括号内,因此它们的连接首先发生。然后将其结果复制三次。
String 4: HelloWorldHelloWorldHelloWorld
除了 + 和 * 之外,任何其他算术运算符符号都不能与字符串操作数一起使用。
Python - 字符串格式化
字符串格式化是通过将数字表达式的值插入到现有字符串中来动态构建字符串表示的过程。Python 的字符串连接运算符不接受非字符串操作数。因此,Python 提供以下字符串格式化技术:
Python - 转义字符
在 Python 中,如果字符串在引号符号之前以“r”或“R”为前缀,则它将成为原始字符串。因此,'Hello' 是普通字符串,而 r'Hello' 是原始字符串。
>>> normal="Hello" >>> print (normal) Hello >>> raw=r"Hello" >>> print (raw) Hello
在正常情况下,两者之间没有区别。但是,当转义字符嵌入到字符串中时,普通字符串实际上会解释转义序列,而原始字符串不会处理转义字符。
>>> normal="Hello\nWorld" >>> print (normal) Hello World >>> raw=r"Hello\nWorld" >>> print (raw) Hello\nWorld
在上面的示例中,当打印普通字符串时,转义字符 '\n' 将被处理以引入换行符。但是,由于原始字符串运算符 'r',转义字符的效果不会根据其含义进行转换。
换行符 \n 是 Python 识别的转义序列之一。转义序列调用对“\”的替代实现字符子序列。在 Python 中,“\”用作转义字符。下表显示转义序列列表。
除非存在“r”或“R”前缀,否则字符串和字节文字中的转义序列将根据与 Standard C 使用的规则类似的规则进行解释。识别的转义序列为:
| 序号 | 转义序列和含义 |
|---|---|
| 1 | \<newline> 反斜杠和换行符被忽略 |
| 2 | \\ 反斜杠 (\) |
| 3 | \' 单引号 (') |
| 4 | \" 双引号 (") |
| 5 | \a ASCII 响铃 (BEL) |
| 6 | \b ASCII 退格 (BS) |
| 7 | \f ASCII 换页 (FF) |
| 8 | \n ASCII 换行 (LF) |
| 9 | \r ASCII 回车 (CR) |
| 10 | \t ASCII 水平制表符 (TAB) |
| 11 | \v ASCII 垂直制表符 (VT) |
| 12 | \ooo 具有八进制值 ooo 的字符 |
| 13 | \xhh 具有十六进制值 hh 的字符 |
示例
以下代码显示了上表中列出的转义序列的用法:
# ignore \ s = 'This string will not include \ backslashes or newline characters.' print (s) # escape backslash s=s = 'The \\character is called backslash' print (s) # escape single quote s='Hello \'Python\'' print (s) # escape double quote s="Hello \"Python\"" print (s) # escape \b to generate ASCII backspace s='Hel\blo' print (s) # ASCII Bell character s='Hello\a' print (s) # newline s='Hello\nPython' print (s) # Horizontal tab s='Hello\tPython' print (s) # form feed s= "hello\fworld" print (s) # Octal notation s="\101" print(s) # Hexadecimal notation s="\x41" print (s)
它将产生以下**输出**:
This string will not include backslashes or newline characters. The \character is called backslash Hello 'Python' Hello "Python" Helo Hello Hello Python Hello Python hello world A A
Python - 字符串方法
Python 的内置str 类定义了不同的方法。它们有助于操作字符串。由于字符串是不可变对象,因此这些方法返回原始字符串的副本,并在其上执行相应的处理。
字符串方法可以分为以下几类:
Python - 字符串练习
示例1
Python 程序,用于查找给定字符串中元音的个数。
mystr = "All animals are equal. Some are more equal"
vowels = "aeiou"
count=0
for x in mystr:
if x.lower() in vowels: count+=1
print ("Number of Vowels:", count)
它将产生以下**输出**:
Number of Vowels: 18
示例2
Python 程序,用于将包含二进制数字的字符串转换为整数。
mystr = '10101'
def strtoint(mystr):
for x in mystr:
if x not in '01': return "Error. String with non-binary characters"
num = int(mystr, 2)
return num
print ("binary:{} integer: {}".format(mystr,strtoint(mystr)))
它将产生以下**输出**:
binary:10101 integer: 21
将mystr更改为 '10, 101'
binary:10,101 integer: Error. String with non-binary characters
示例3
Python 程序,用于从字符串中删除所有数字。
digits = [str(x) for x in range(10)]
mystr = 'He12llo, Py00th55on!'
chars = []
for x in mystr:
if x not in digits:
chars.append(x)
newstr = ''.join(chars)
print (newstr)
它将产生以下**输出**:
Hello, Python!
练习程序
Python 程序,用于对字符串中的字符进行排序
Python 程序,用于从字符串中删除重复字符
Python 程序,用于列出字符串中唯一字符及其计数
Python 程序,用于查找字符串中单词的个数
Python 程序,用于从字符串中删除所有非字母字符
Python - 列表
列表是 Python 中的内置数据类型之一。Python 列表是由逗号分隔的项目序列,用方括号 [] 括起来。Python 列表中的项目不必是相同的数据类型。
以下是 Python 列表的一些示例:
list1 = ["Rohan", "Physics", 21, 69.75] list2 = [1, 2, 3, 4, 5] list3 = ["a", "b", "c", "d"] list4 = [25.50, True, -55, 1+2j]
在 Python 中,列表是一种序列数据类型。它是项目的排序集合。列表中的每个项目都有一个唯一的索引位置,从 0 开始。
Python 列表类似于 C、C++ 或 Java 中的数组。但是,主要区别在于 C/C++/Java 中,数组元素必须是相同类型。另一方面,Python 列表可以包含不同数据类型的对象。
Python 列表是可变的。可以使用索引访问列表中的任何项目,并且可以修改。可以从列表中删除或添加一个或多个对象。列表可以在多个索引位置具有相同的项目。
Python 列表操作
在 Python 中,列表是一个序列。因此,我们可以使用“+”运算符连接两个列表,并使用“*”运算符连接列表的多个副本。成员运算符“in”和“not in”适用于列表对象。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 连接 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 成员关系 |
Python - 访问列表元素
在 Python 中,列表是一个序列。列表中的每个对象都可以通过其索引访问。索引从 0 开始。列表中最后一个项目的索引是“长度-1”。要访问列表中的值,请使用方括号进行切片,并使用索引或索引来获取该索引处的值。
切片运算符从列表中获取一个或多个项目。在方括号中放入索引以检索其位置处的项目。
obj = list1[i]
示例1
请看下面的例子:
list1 = ["Rohan", "Physics", 21, 69.75]
list2 = [1, 2, 3, 4, 5]
print ("Item at 0th index in list1: ", list1[0])
print ("Item at index 2 in list2: ", list2[2])
它将产生以下**输出**:
Item at 0th index in list1: Rohan Item at index 2 in list2: 3
Python 允许将负索引与任何序列类型一起使用。“-1”索引指的是列表中的最后一个项目。
示例2
让我们看另一个例子:
list1 = ["a", "b", "c", "d"]
list2 = [25.50, True, -55, 1+2j]
print ("Item at 0th index in list1: ", list1[-1])
print ("Item at index 2 in list2: ", list2[-3])
它将产生以下**输出**:
Item at 0th index in list1: d Item at index 2 in list2: True
切片运算符从原始列表中提取子列表。
Sublist = list1[i:j]
参数
i − 子列表中第一个项目的索引
j − 子列表中最后一个项目下一个项目的索引
这将返回从list1 的第 i 个到第 (j-1) 个项目 的切片。
示例3
切片时,“i”和“j”两个操作数都是可选的。如果未使用,“i”为 0,“j”为列表中的最后一个项目。负索引可用于切片。请看下面的例子:
list1 = ["a", "b", "c", "d"]
list2 = [25.50, True, -55, 1+2j]
print ("Items from index 1 to 2 in list1: ", list1[1:3])
print ("Items from index 0 to 1 in list2: ", list2[0:2])
它将产生以下**输出**:
Items from index 1 to 2 in list1: ['b', 'c'] Items from index 0 to 1 in list2: [25.5, True]
示例 4
list1 = ["a", "b", "c", "d"]
list2 = [25.50, True, -55, 1+2j]
list4 = ["Rohan", "Physics", 21, 69.75]
list3 = [1, 2, 3, 4, 5]
print ("Items from index 1 to last in list1: ", list1[1:])
print ("Items from index 0 to 1 in list2: ", list2[:2])
print ("Items from index 2 to last in list3", list3[2:-1])
print ("Items from index 0 to index last in list4", list4[:])
它将产生以下**输出**:
Items from index 1 to last in list1: ['b', 'c', 'd'] Items from index 0 to 1 in list2: [25.5, True] Items from index 2 to last in list3 [3, 4] Items from index 0 to index last in list4 ['Rohan', 'Physics', 21, 69.75]
Python - 修改列表元素
列表是 Python 中一种可变数据类型。这意味着,在对象存储在内存中之后,可以就地修改列表的内容。您可以在列表中给定索引位置分配新值。
语法
list1[i] = newvalue
示例1
在下面的代码中,我们更改了给定列表中索引 2 的值。
list3 = [1, 2, 3, 4, 5]
print ("Original list ", list3)
list3[2] = 10
print ("List after changing value at index 2: ", list3)
它将产生以下**输出**:
Original list [1, 2, 3, 4, 5] List after changing value at index 2: [1, 2, 10, 4, 5]
您可以用另一个子列表替换列表中更多连续的项目。
示例2
在下面的代码中,索引 1 和 2 处的项目被另一个子列表中的项目替换。
list1 = ["a", "b", "c", "d"]
print ("Original list: ", list1)
list2 = ['Y', 'Z']
list1[1:3] = list2
print ("List after changing with sublist: ", list1)
它将产生以下**输出**:
Original list: ['a', 'b', 'c', 'd'] List after changing with sublist: ['a', 'Y', 'Z', 'd']
示例3
如果源子列表的项目多于要替换的切片,则将插入源中的额外项目。请看下面的代码:
list1 = ["a", "b", "c", "d"]
print ("Original list: ", list1)
list2 = ['X','Y', 'Z']
list1[1:3] = list2
print ("List after changing with sublist: ", list1)
它将产生以下**输出**:
Original list: ['a', 'b', 'c', 'd'] List after changing with sublist: ['a', 'X', 'Y', 'Z', 'd']
示例 4
如果用于替换原始列表切片的子列表的项目较少,则将替换匹配的项目,并将原始列表中的其余项目删除。
在下面的代码中,我们尝试用“Z”(比要替换的项目少一个项目)替换“b”和“c”。结果是 Z 替换了 b,c 被删除。
list1 = ["a", "b", "c", "d"]
print ("Original list: ", list1)
list2 = ['Z']
list1[1:3] = list2
print ("List after changing with sublist: ", list1)
它将产生以下**输出**:
Original list: ['a', 'b', 'c', 'd'] List after changing with sublist: ['a', 'Z', 'd']
Python - 添加列表元素
list 类有两个方法,append() 和 insert(),用于向现有列表中添加项目。
示例1
append() 方法将项目添加到现有列表的末尾。
list1 = ["a", "b", "c", "d"]
print ("Original list: ", list1)
list1.append('e')
print ("List after appending: ", list1)
输出
Original list: ['a', 'b', 'c', 'd'] List after appending: ['a', 'b', 'c', 'd', 'e']
示例2
insert() 方法在列表的指定索引处插入项目。
list1 = ["Rohan", "Physics", 21, 69.75]
print ("Original list ", list1)
list1.insert(2, 'Chemistry')
print ("List after appending: ", list1)
list1.insert(-1, 'Pass')
print ("List after appending: ", list1)
输出
Original list ['Rohan', 'Physics', 21, 69.75] List after appending: ['Rohan', 'Physics', 'Chemistry', 21, 69.75] List after appending: ['Rohan', 'Physics', 'Chemistry', 21, 'Pass', 69.75]
我们知道“-1”索引指向列表中的最后一个项目。但是,请注意,原始列表中索引“-1”处的项目是 69.75。在附加“chemistry”后,不会刷新此索引。因此,“Pass”不是插入到更新后的索引“-1”处,而是插入到之前的索引“-1”处。
Python - 删除列表元素
list 类的 remove() 和 pop() 方法都可以从列表中删除项目。它们之间的区别在于 remove() 删除作为参数给出的对象,而 pop() 删除给定索引处的项目。
使用 remove() 方法
以下示例显示了如何使用 remove() 方法删除列表项:
list1 = ["Rohan", "Physics", 21, 69.75]
print ("Original list: ", list1)
list1.remove("Physics")
print ("List after removing: ", list1)
它将产生以下**输出**:
Original list: ['Rohan', 'Physics', 21, 69.75] List after removing: ['Rohan', 21, 69.75]
使用 pop() 方法
以下示例显示了如何使用 pop() 方法删除列表项:
list2 = [25.50, True, -55, 1+2j]
print ("Original list: ", list2)
list2.pop(2)
print ("List after popping: ", list2)
它将产生以下**输出**:
Original list: [25.5, True, -55, (1+2j)] List after popping: [25.5, True, (1+2j)]
使用“del”关键字
Python 具有“del”关键字,用于从内存中删除任何 Python 对象。
示例
我们可以使用“del”从列表中删除项目。请看下面的例子:
list1 = ["a", "b", "c", "d"]
print ("Original list: ", list1)
del list1[2]
print ("List after deleting: ", list1)
它将产生以下**输出**:
Original list: ['a', 'b', 'c', 'd'] List after deleting: ['a', 'b', 'd']
示例
您可以使用切片运算符从列表中删除一系列连续的项目。请看下面的例子:
list2 = [25.50, True, -55, 1+2j]
print ("List before deleting: ", list2)
del list2[0:2]
print ("List after deleting: ", list2)
它将产生以下**输出**:
List before deleting: [25.5, True, -55, (1+2j)] List after deleting: [-55, (1+2j)]
Python - 遍历列表
您可以使用 Python 的for 循环结构遍历列表中的项目。可以使用列表作为迭代器或借助索引来完成遍历。
语法
Python 列表提供一个迭代器对象。要迭代列表,请按如下方式使用 for 语句:
for obj in list: . . . . . .
示例1
请看下面的例子:
lst = [25, 12, 10, -21, 10, 100] for num in lst: print (num, end = ' ')
输出
25 12 10 -21 10 100
示例2
要遍历列表中的项目,请获取整数“0”到“len-1”的范围对象。请看下面的例子:
lst = [25, 12, 10, -21, 10, 100]
indices = range(len(lst))
for i in indices:
print ("lst[{}]: ".format(i), lst[i])
输出
lst[0]: 25 lst[1]: 12 lst[2]: 10 lst[3]: -21 lst[4]: 10 lst[5]: 100
Python - 列表推导式
列表推导是一种非常强大的编程工具。它类似于数学中的集合构造器符号。这是一种简洁的方法,可以通过对现有列表中的每个项目执行某种过程来创建新列表。列表推导比使用for 循环处理列表要快得多。
示例1
假设我们想分离字符串中的每个字母并将所有非元音字母放在列表对象中。我们可以通过如下所示的for 循环来实现:
chars=[]
for ch in 'TutorialsPoint':
if ch not in 'aeiou':
chars.append(ch)
print (chars)
chars 列表对象显示如下:
['T', 't', 'r', 'l', 's', 'P', 'n', 't']
列表推导技术
我们可以通过列表推导技术轻松获得相同的结果。列表推导的一般用法如下:
listObj = [x for x in iterable]
应用此方法,可以使用以下语句构造 chars 列表:
chars = [ char for char in 'TutorialsPoint' if char not in 'aeiou'] print (chars)
chars 列表将如前所示显示:
['T', 't', 'r', 'l', 's', 'P', 'n', 't']
示例2
以下示例使用列表推导来构建一个包含 1 到 10 之间的数字平方的列表
squares = [x*x for x in range(1,11)] print (squares)
squares 列表对象为:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
列表推导中的嵌套循环
在下面的示例中,两个列表中项目的组合以元组的形式添加到第三个列表对象中。
示例3
list1=[1,2,3] list2=[4,5,6] CombLst=[(x,y) for x in list1 for y in list2] print (CombLst)
它将产生以下**输出**:
[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
列表推导中的条件
以下语句将创建一个包含 1 到 20 之间所有偶数的列表。
示例 4
list1=[x for x in range(1,21) if x%2==0] print (list1)
它将产生以下**输出**:
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
Python - 列表排序
list 类的 sort() 方法使用词典排序机制按升序或降序重新排列项目。排序是就地进行的,这意味着重新排列发生在同一列表对象中,并且它不返回新对象。
语法
list1.sort(key, reverse)
参数
Key − 应用于列表中每个项目的函数。返回值用于执行排序。可选
reverse − 布尔值。如果设置为 True,则排序按降序进行。可选
返回值
此方法返回 None。
示例1
现在让我们看一些例子来了解如何在 Python 中排序列表:
list1 = ['physics', 'Biology', 'chemistry', 'maths']
print ("list before sort", list1)
list1.sort()
print ("list after sort : ", list1)
print ("Descending sort")
list2 = [10,16, 9, 24, 5]
print ("list before sort", list2)
list2.sort()
print ("list after sort : ", list2)
它将产生以下**输出**:
list before sort ['physics', 'Biology', 'chemistry', 'maths'] list after sort: ['Biology', 'chemistry', 'maths', 'physics'] Descending sort list before sort [10, 16, 9, 24, 5] list after sort : [5, 9, 10, 16, 24]
示例2
在此示例中,str.lower() 方法用作 sort() 方法中的 key 参数。
list1 = ['Physics', 'biology', 'Biomechanics', 'psychology']
print ("list before sort", list1)
list1.sort(key=str.lower)
print ("list after sort : ", list1)
它将产生以下**输出**:
list before sort ['Physics', 'biology', 'Biomechanics', 'psychology'] list after sort : ['biology', 'Biomechanics', 'Physics', 'psychology']
示例3
让我们使用用户定义的函数作为 sort() 方法中的 key 参数。myfunction() 使用 % 运算符返回余数,根据该余数进行排序。
def myfunction(x):
return x%10
list1 = [17, 23, 46, 51, 90]
print ("list before sort", list1)
list1.sort(key=myfunction)
print ("list after sort : ", list1)
它将产生以下**输出**:
list before sort [17, 23, 46, 51, 90] list after sort: [90, 51, 23, 46, 17]
Python - 复制列表
在 Python 中,变量只是内存中对象的标签或引用。因此,赋值“lst1 = lst”指的是内存中同一个列表对象。请看下面的例子:
lst = [10, 20]
print ("lst:", lst, "id(lst):",id(lst))
lst1 = lst
print ("lst1:", lst1, "id(lst1):",id(lst1))
它将产生以下**输出**:
lst: [10, 20] id(lst): 1677677188288 lst1: [10, 20] id(lst1): 1677677188288
因此,如果我们更新“lst”,它将自动反映在“lst1”中。将 lst[0] 更改为 100
lst[0]=100
print ("lst:", lst, "id(lst):",id(lst))
print ("lst1:", lst1, "id(lst1):",id(lst1))
它将产生以下**输出**:
lst: [100, 20] id(lst): 1677677188288 lst1: [100, 20] id(lst1): 1677677188288
因此,我们可以说“lst1”不是“lst”的物理副本。
使用 List 类的 Copy 方法
Python 的 list 类具有一个 copy() 方法,用于创建列表对象的新的物理副本。
语法
lst1 = lst.copy()
新的列表对象将具有不同的 id() 值。以下示例演示了这一点:
lst = [10, 20]
lst1 = lst.copy()
print ("lst:", lst, "id(lst):",id(lst))
print ("lst1:", lst1, "id(lst1):",id(lst1))
它将产生以下**输出**:
lst: [10, 20] id(lst): 1677678705472 lst1: [10, 20] id(lst1): 1677678706304
即使两个列表具有相同的数据,它们也具有不同的 id() 值,因此它们是两个不同的对象,“lst1”是“lst”的副本。
如果我们尝试修改“lst”,它将不会反映在“lst1”中。请看下面的例子:
lst[0]=100
print ("lst:", lst, "id(lst):",id(lst))
print ("lst1:", lst1, "id(lst1):",id(lst1))
它将产生以下**输出**:
lst: [100, 20] id(lst): 1677678705472 lst1: [10, 20] id(lst1): 1677678706304
Python - 合并列表
在 Python 中,列表被分类为序列类型对象。它是项目的集合,这些项目可能属于不同的数据类型,每个项目都有一个从 0 开始的位置索引。您可以使用不同的方法来连接两个 Python 列表。
所有序列类型对象都支持连接运算符,可以使用它来连接两个列表。
L1 = [10,20,30,40]
L2 = ['one', 'two', 'three', 'four']
L3 = L1+L2
print ("Joined list:", L3)
它将产生以下**输出**:
Joined list: [10, 20, 30, 40, 'one', 'two', 'three', 'four']
您还可以使用带“+=”符号的增强连接运算符将 L2 附加到 L1
L1 = [10,20,30,40]
L2 = ['one', 'two', 'three', 'four']
L1+=L2
print ("Joined list:", L1)
可以使用 extend() 方法获得相同的结果。在这里,我们需要扩展 L1 以便在其内添加来自 L2 的元素。
L1 = [10,20,30,40]
L2 = ['one', 'two', 'three', 'four']
L1.extend(L2)
print ("Joined list:", L1)
要将项目从一个列表添加到另一个列表,经典的迭代解决方案也有效。使用 for 循环遍历第二个列表的项目,并将每个项目附加到第一个列表中。
L1 = [10,20,30,40]
L2 = ['one', 'two', 'three', 'four']
for x in L2:
L1.append(x)
print ("Joined list:", L1)
合并两个列表的一种稍微复杂的方法是使用列表推导,如下面的代码所示:
L1 = [10,20,30,40]
L2 = ['one', 'two', 'three', 'four']
L3 = [y for x in [L1, L2] for y in x]
print ("Joined list:", L3)
Python - 列表方法
Python 的list 类包含以下方法,您可以使用这些方法来添加、更新和删除列表项:
| 序号 | 方法和描述 |
|---|---|
1 |
list.append(obj) 将对象 obj 附加到列表 |
2 |
清除列表的内容 |
3 |
list.copy() 返回列表对象的副本 |
4 |
返回 obj 在列表中出现的次数 |
5 |
将 seq 的内容附加到列表 |
6 |
返回列表中 obj 出现的最低索引 |
7 |
list.insert(index, obj) 在偏移量索引处将对象 obj 插入列表 |
8 |
list.pop(obj=list[-1]) 删除并返回列表中的最后一个对象或 obj |
9 |
list.remove(obj) 从列表中删除对象 obj |
10 |
就地反转列表的对象 |
11 |
list.sort([func]) 对列表的对象进行排序,如果给出,则使用比较函数 func |
Python - 列表练习
示例1
Python 程序用于查找给定列表中唯一的数字。
L1 = [1, 9, 1, 6, 3, 4, 5, 1, 1, 2, 5, 6, 7, 8, 9, 2]
L2 = []
for x in L1:
if x not in L2:
L2.append(x)
print (L2)
它将产生以下**输出**:
[1, 9, 6, 3, 4, 5, 2, 7, 8]
示例2
Python 程序用于查找列表中所有数字的总和。
L1 = [1, 9, 1, 6, 3, 4]
ttl = 0
for x in L1:
ttl+=x
print ("Sum of all numbers Using loop:", ttl)
ttl = sum(L1)
print ("Sum of all numbers sum() function:", ttl)
它将产生以下**输出**:
Sum of all numbers Using loop: 24 Sum of all numbers sum() function: 24
示例3
Python 程序用于创建一个包含 5 个随机整数的列表。
import random L1 = [] for i in range(5): x = random.randint(0, 100) L1.append(x) print (L1)
它将产生以下**输出**:
[77, 3, 20, 91, 85]
练习程序
Python 程序用于从列表中删除所有奇数。
Python 程序用于根据每个单词中的字母数量对字符串列表进行排序。
Python 程序将列表中的非数字项放在单独的列表中。
Python 程序用于创建一个整数列表,表示字符串中的每个字符。
Python 程序用于查找两个列表中共同的数字。
Python - 元组
元组是 Python 中的内置数据类型之一。Python 元组是由逗号分隔的项目组成的序列,用括号 () 括起来。Python 元组中的项目不必是相同的数据类型。
以下是 Python 元组的一些示例:
tup1 = ("Rohan", "Physics", 21, 69.75)
tup2 = (1, 2, 3, 4, 5)
tup3 = ("a", "b", "c", "d")
tup4 = (25.50, True, -55, 1+2j)
在 Python 中,元组是一种序列数据类型。它是项目的排序集合。元组中的每个项目都有一个唯一的位 置索引,从 0 开始。
在C/C++/Java数组中,数组元素必须是相同类型。另一方面,Python元组可以包含不同数据类型的对象。
Python元组和列表都是序列。两者之间的一个主要区别是,Python列表是可变的,而元组是不可变的。虽然可以使用索引访问元组中的任何项目,但不能修改、删除或添加。
Python元组操作
在Python中,元组是一个序列。因此,我们可以使用+运算符连接两个元组,使用*运算符连接元组的多个副本。“in”和“not in”成员运算符适用于元组对象。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 重复 |
| 3 in (1, 2, 3) | True | 成员关系 |
请注意,即使元组中只有一个对象,也必须在其后添加逗号。否则,它将被视为字符串。
Python - 访问元组元素
在Python中,元组是一个序列。列表中的每个对象都可以通过其索引访问。索引从“0”开始。元组中最后一项的索引是“长度-1”。要访问元组中的值,请使用方括号进行切片,并使用索引或索引来获取该索引处的值。
切片运算符从元组中获取一个或多个项目。
obj = tup1(i)
示例1
将索引放在方括号内以检索其位置的项目。
tup1 = ("Rohan", "Physics", 21, 69.75)
tup2 = (1, 2, 3, 4, 5)
print ("Item at 0th index in tup1tup2: ", tup1[0])
print ("Item at index 2 in list2: ", tup2[2])
它将产生以下**输出**:
Item at 0th index in tup1: Rohan Item at index 2 in tup2: 3
示例2
Python允许对任何序列类型使用负索引。“-1”索引指的是元组中的最后一项。
tup1 = ("a", "b", "c", "d")
tup2 = (25.50, True, -55, 1+2j)
print ("Item at 0th index in tup1: ", tup1[-1])
print ("Item at index 2 in tup2: ", tup2[-3])
它将产生以下**输出**:
Item at 0th index in tup1: d Item at index 2 in tup2: True
从元组中提取子元组
切片运算符从原始元组中提取子元组。
Subtup = tup1[i:j]
参数
i − 子元组中第一项的索引
j − 子元组中最后一项的下一个项目的索引
这将返回从tup1的第i个到第(j-1)个项目之间的切片。
示例3
请看下面的例子:
tup1 = ("a", "b", "c", "d")
tup2 = (25.50, True, -55, 1+2j)
print ("Items from index 1 to 2 in tup1: ", tup1[1:3])
print ("Items from index 0 to 1 in tup2: ", tup2[0:2])
它将产生以下**输出**:
Items from index 1 to 2 in tup1: ('b', 'c')
Items from index 0 to 1 in tup2: (25.5, True)
示例 4
在切片时,“i”和“j”两个操作数都是可选的。如果未使用,“i”为0,“j”为元组中的最后一项。切片中可以使用负索引。请参见以下示例:
tup1 = ("a", "b", "c", "d")
tup2 = (25.50, True, -55, 1+2j)
tup4 = ("Rohan", "Physics", 21, 69.75)
tup3 = (1, 2, 3, 4, 5)
print ("Items from index 1 to last in tup1: ", tup1[1:])
print ("Items from index 0 to 1 in tup2: ", tup2[:2])
print ("Items from index 2 to last in tup3", tup3[2:-1])
print ("Items from index 0 to index last in tup4", tup4[:])
它将产生以下**输出**:
Items from index 1 to last in tup1: ('b', 'c', 'd')
Items from index 0 to 1 in tup2: (25.5, True)
Items from index 2 to last in tup3: (3, 4)
Items from index 0 to index last in tup4: ('Rohan', 'Physics', 21, 69.75)
Python - 更新元组
在Python中,元组是一种不可变的数据类型。一旦不可变对象在内存中创建,就不能修改它。
示例1
如果我们尝试使用切片运算符为元组项赋值,Python将引发TypeError异常。请参见以下示例:
tup1 = ("a", "b", "c", "d")
tup1[2] = 'Z'
print ("tup1: ", tup1)
它将产生以下**输出**:
Traceback (most recent call last): File "C:\Users\mlath\examples\main.py", line 2, in <module> tup1[2] = 'Z' ~~~~^^^ TypeError: 'tuple' object does not support item assignment
因此,无法更新元组。因此,元组类不提供用于添加、插入、删除、排序元组对象中项目的的方法,就像列表类一样。
如何更新Python元组?
您可以使用变通方法来更新元组。使用list()函数将元组转换为列表,执行所需的追加/插入/删除操作,然后将列表解析回元组对象。
示例2
在这里,我们将元组转换为列表,更新现有项目,追加新项目并对列表进行排序。然后将列表转换回元组。
tup1 = ("a", "b", "c", "d")
print ("Tuple before update", tup1, "id(): ", id(tup1))
list1 = list(tup1)
list1[2]='F'
list1.append('Z')
list1.sort()
print ("updated list", list1)
tup1 = tuple(list1)
print ("Tuple after update", tup1, "id(): ", id(tup1))
它将产生以下**输出**:
Tuple before update ('a', 'b', 'c', 'd') id(): 2295023084192
updated list ['F', 'Z', 'a', 'b', 'd']
Tuple after update ('F', 'Z', 'a', 'b', 'd') id(): 2295021518128
但是,请注意,更新前和更新后的tup1的id()是不同的。这意味着创建了一个新的元组对象,并且没有就地修改原始元组对象。
Python - 解包元组项目
术语“解包”是指将元组项目解析到各个变量的过程。在Python中,圆括号是序列对象文字表示的默认分隔符。
以下声明元组的语句是相同的。
>>> t1 = (x,y) >>> t1 = x,y >>> type (t1) <class 'tuple'>
示例1
要将元组项目存储到各个变量中,请在赋值运算符的左侧使用多个变量,如下例所示:
tup1 = (10,20,30)
x, y, z = tup1
print ("x: ", x, "y: ", "z: ",z)
它将产生以下**输出**:
x: 10 y: 20 z: 30
这就是元组如何解包到各个变量中的。
使用解包元组
在上面的示例中,赋值运算符左侧的变量数量等于元组中的项目数量。如果数量不相等怎么办?
示例2
如果变量的数量多于或少于元组的长度,Python将引发ValueError异常。
tup1 = (10,20,30) x, y = tup1 x, y, p, q = tup1
它将产生以下**输出**:
x, y = tup1 ^^^^ ValueError: too many values to unpack (expected 2) x, y, p, q = tup1 ^^^^^^^^^^ ValueError: not enough values to unpack (expected 4, got 3)
在这种情况下,使用“*”符号进行解包。在“y”前面加上“*”,如下所示:
tup1 = (10,20,30)
x, *y = tup1
print ("x: ", "y: ", y)
它将产生以下**输出**:
x: y: [20, 30]
元组中的第一个值被赋值给“x”,其余项目被赋值给“y”,它将成为一个列表。
示例3
在这个例子中,元组包含6个值,要解包的变量为3个。我们在第二个变量前加“*”。
tup1 = (10,20,30, 40, 50, 60)
x, *y, z = tup1
print ("x: ",x, "y: ", y, "z: ", z)
它将产生以下**输出**:
x: 10 y: [20, 30, 40, 50] z: 60
这里,值首先解包到“x”和“z”,然后其余值被赋值给“y”作为列表。
示例 4
如果我们在第一个变量前面添加“*”会怎样?
tup1 = (10,20,30, 40, 50, 60)
*x, y, z = tup1
print ("x: ",x, "y: ", y, "z: ", z)
它将产生以下**输出**:
x: [10, 20, 30, 40] y: 50 z: 60
同样,元组的解包方式是各个变量首先获取值,其余值留给列表“x”。
Python - 遍历元组
您可以使用Python的for循环结构遍历元组中的项目。可以使用元组作为迭代器或借助索引来进行遍历。
语法
Python元组提供一个迭代器对象。要迭代元组,请使用for语句,如下所示:
for obj in tuple: . . . . . .
示例1
以下示例显示了一个简单的Pythonfor循环结构:
tup1 = (25, 12, 10, -21, 10, 100) for num in tup1: print (num, end = ' ')
它将产生以下**输出**:
25 12 10 -21 10 100
示例2
要迭代元组中的项目,请获取从“0”到“len-1”的整数范围对象。
tup1 = (25, 12, 10, -21, 10, 100)
indices = range(len(tup1))
for i in indices:
print ("tup1[{}]: ".format(i), tup1[i])
它将产生以下**输出**:
tup1[0]: 25 tup1 [1]: 12 tup1 [2]: 10 tup1 [3]: -21 tup1 [4]: 10 tup1 [5]: 100
Python - 合并元组
在Python中,元组被分类为序列类型对象。它是一组项目,这些项目可能属于不同的数据类型,每个项目都有一个从0开始的位置索引。虽然此定义也适用于列表,但列表和元组有两个主要区别。首先,在列表的情况下,项目用方括号括起来(例如:[10,20,30,40]),而元组是通过将项目放在圆括号中形成的(例如:(10,20,30,40))。
在Python中,元组是一个不可变对象。因此,一旦元组在内存中形成,就不可能修改其内容。
但是,您可以使用不同的方法来连接两个Python元组。
示例1
所有序列类型对象都支持连接运算符,可以使用它来连接两个列表。
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
T3 = T1+T2
print ("Joined Tuple:", T3)
它将产生以下**输出**:
Joined Tuple: (10, 20, 30, 40, 'one', 'two', 'three', 'four')
示例2
您还可以使用增强连接运算符"+="符号将T2附加到T1
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
T1+=T2
print ("Joined Tuple:", T1)
示例3
可以使用extend()方法获得相同的结果。在这里,我们需要将两个元组对象转换为列表,扩展以便将一个列表中的元素添加到另一个列表中,并将连接的列表转换回元组。
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
L1 = list(T1)
L2 = list(T2)
L1.extend(L2)
T1 = tuple(L1)
print ("Joined Tuple:", T1)
示例 4
Python的内置sum()函数也有助于连接元组。我们使用表达式
sum((t1, t2), ())
首先将第一个元组的元素附加到一个空元组,然后附加第二个元组的元素,并返回一个新的元组,该元组是两个元组的连接。
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
T3 = sum((T1, T2), ())
print ("Joined Tuple:", T3)
示例5
合并两个元组的一种稍微复杂的方法是使用列表推导式,如下代码所示:
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
L1, L2 = list(T1), list(T2)
L3 = [y for x in [L1, L2] for y in x]
T3 = tuple(L3)
print ("Joined Tuple:", T3)
示例6
您可以在第二个循环中的项目上运行for循环,将每个项目转换为单个项目元组,并使用"+="运算符将其连接到第一个元组
T1 = (10,20,30,40)
T2 = ('one', 'two', 'three', 'four')
for t in T2:
T1+=(t,)
print (T1)
Python - 元组方法
由于Python中的元组是不可变的,因此元组类没有定义用于添加或删除项目的方法。元组类只定义了两种方法。
| 序号 | 方法和描述 |
|---|---|
| 1 | tuple.count(obj) 返回obj在元组中出现的次数 |
| 2 | tuple.index(obj) 返回obj在元组中第一次出现的最低索引 |
查找元组项的索引
元组类的index()方法返回给定项第一次出现的索引。
语法
tuple.index(obj)
返回值
index()方法返回一个整数,表示“obj”第一次出现的索引。
示例
请看下面的例子:
tup1 = (25, 12, 10, -21, 10, 100)
print ("Tup1:", tup1)
x = tup1.index(10)
print ("First index of 10:", x)
它将产生以下**输出**:
Tup1: (25, 12, 10, -21, 10, 100) First index of 10: 2
计数元组项目
元组类中的count()方法返回给定对象在元组中出现的次数。
语法
tuple.count(obj)
返回值
对象的出现次数。count()方法返回一个整数。
示例
tup1 = (10, 20, 45, 10, 30, 10, 55)
print ("Tup1:", tup1)
c = tup1.count(10)
print ("count of 10:", c)
它将产生以下**输出**:
Tup1: (10, 20, 45, 10, 30, 10, 55) count of 10: 3
示例
即使元组中的项目包含表达式,它们也会被计算以获得计数。
Tup1 = (10, 20/80, 0.25, 10/40, 30, 10, 55)
print ("Tup1:", tup1)
c = tup1.count(0.25)
print ("count of 10:", c)
它将产生以下**输出**:
Tup1: (10, 0.25, 0.25, 0.25, 30, 10, 55) count of 10: 3
Python元组练习
示例1
Python程序用于查找给定元组中唯一的数字:
T1 = (1, 9, 1, 6, 3, 4, 5, 1, 1, 2, 5, 6, 7, 8, 9, 2)
T2 = ()
for x in T1:
if x not in T2:
T2+=(x,)
print ("original tuple:", T1)
print ("Unique numbers:", T2)
它将产生以下**输出**:
original tuple: (1, 9, 1, 6, 3, 4, 5, 1, 1, 2, 5, 6, 7, 8, 9, 2) Unique numbers: (1, 9, 6, 3, 4, 5, 2, 7, 8)
示例2
Python程序用于查找元组中所有数字的总和:
T1 = (1, 9, 1, 6, 3, 4)
ttl = 0
for x in T1:
ttl+=x
print ("Sum of all numbers Using loop:", ttl)
ttl = sum(T1)
print ("Sum of all numbers sum() function:", ttl)
它将产生以下**输出**:
Sum of all numbers Using loop: 24 Sum of all numbers sum() function: 24
示例3
Python程序用于创建一个包含5个随机整数的元组:
import random t1 = () for i in range(5): x = random.randint(0, 100) t1+=(x,) print (t1)
它将产生以下**输出**:
(64, 21, 68, 6, 12)
练习程序
Python程序用于从列表中删除所有重复的数字。
Python程序用于根据每个单词中的字母数量对字符串元组进行排序。
Python程序用于从给定元组中准备一个非数字项目的元组。
Python程序用于创建一个整数元组,表示字符串中的每个字符
Python程序用于查找两个元组中共同的数字。
Python - 集合
集合是Python中内置数据类型之一。在数学中,集合是不同对象的集合。集合数据类型是Python对集合的实现。集合中的对象可以是任何数据类型。
Python中的集合也是一种集合数据类型,例如列表或元组。但是,它不是有序集合,即集合中的项目无法通过其位置索引访问。集合对象是由花括号{}括起来的至少一个不可变对象的集合。
示例1
下面给出一些集合对象的示例:
s1 = {"Rohan", "Physics", 21, 69.75}
s2 = {1, 2, 3, 4, 5}
s3 = {"a", "b", "c", "d"}
s4 = {25.50, True, -55, 1+2j}
print (s1)
print (s2)
print (s3)
print (s4)
它将产生以下**输出**:
{'Physics', 21, 'Rohan', 69.75}
{1, 2, 3, 4, 5}
{'a', 'd', 'c', 'b'}
{25.5, -55, True, (1+2j)}
以上结果表明,赋值中对象的顺序不一定保留在集合对象中。这是因为Python优化了集合的结构以进行集合操作。
除了集合的文字表示(将项目放在花括号内),Python的内置set()函数也构造集合对象。
set() 函数
set()是内置函数之一。它将任何序列对象(列表、元组或字符串)作为参数,并返回一个集合对象
语法
Obj = set(sequence)
参数
sequence − 列表、元组或str类型的对象
返回值
set()函数从序列返回一个集合对象,并丢弃其中的重复元素。
示例2
L1 = ["Rohan", "Physics", 21, 69.75] s1 = set(L1) T1 = (1, 2, 3, 4, 5) s2 = set(T1) string = "TutorialsPoint" s3 = set(string) print (s1) print (s2) print (s3)
它将产生以下**输出**:
{'Rohan', 69.75, 21, 'Physics'}
{1, 2, 3, 4, 5}
{'u', 'a', 'o', 'n', 'r', 's', 'T', 'P', 'i', 't', 'l'}
示例3
集合是不同对象的集合。即使您在集合中重复一个对象,也只保留一个副本。
s2 = {1, 2, 3, 4, 5, 3,0, 1, 9}
s3 = {"a", "b", "c", "d", "b", "e", "a"}
print (s2)
print (s3)
它将产生以下**输出**:
{0, 1, 2, 3, 4, 5, 9}
{'a', 'b', 'd', 'c', 'e'}
示例 4
只有不可变对象才能用于构成集合对象。允许使用任何数字类型、字符串和元组,但不能在集合中放置列表或字典。
s1 = {1, 2, [3, 4, 5], 3,0, 1, 9}
print (s1)
s2 = {"Rohan", {"phy":50}}
print (s2)
它将产生以下**输出**:
s1 = {1, 2, [3, 4, 5], 3,0, 1, 9}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: unhashable type: 'list'
s2 = {"Rohan", {"phy":50}}
^^^^^^^^^^^^^^^^^^^^^
TypeError: unhashable type: 'dict'
Python引发TypeError异常,并显示消息“unhashable types 'list' or 'dict'”。哈希为不可变项目生成一个唯一数字,这使得能够在计算机内存中快速搜索。Python具有内置的hash()函数。列表或字典不支持此函数。
即使集合中不存储可变对象,集合本身也是一个可变对象。Python有特殊的运算符来处理集合,并且集合类中有多种方法来对集合对象的元素执行添加、删除、更新操作。
Python - 访问集合元素
由于集合不是序列数据类型,因此不能像列表或元组那样单独访问其项目,因为它们没有位置索引。集合项目也没有键(如字典)来访问。您只能使用for循环遍历集合项目。
示例1
langs = {"C", "C++", "Java", "Python"}
for lang in langs:
print (lang)
它将产生以下**输出**:
Python C C++ Java
示例2
Python的成员运算符允许您检查集合中是否存在某个项目。请看下面的例子:
langs = {"C", "C++", "Java", "Python"}
print ("PHP" in langs)
print ("Java" in langs)
它将产生以下**输出**:
False True
Python - 添加集合元素
即使集合只包含不可变对象,集合本身也是可变的。我们可以通过以下几种方式添加新元素:
add() 方法
集合类中的 add() 方法添加一个新元素。如果元素已存在于集合中,则集合不变。
语法
set.add(obj)
参数
obj − 任何不可变类型的对象。
示例
请看下面的例子:
lang1 = {"C", "C++", "Java", "Python"}
lang1.add("Golang")
print (lang1)
它将产生以下**输出**:
{'Python', 'C', 'Golang', 'C++', 'Java'}
update() 方法
集合类的 update() 方法包含作为参数给出的集合的元素。如果另一个集合中的元素已经存在一个或多个,则不会包含它们。
语法
set.update(obj)
参数
obj − 集合或序列对象(列表、元组、字符串)
示例
以下示例演示了 update() 方法的工作方式:
lang1 = {"C", "C++", "Java", "Python"}
lang2 = {"PHP", "C#", "Perl"}
lang1.update(lang2)
print (lang1)
它将产生以下**输出**:
{'Python', 'Java', 'C', 'C#', 'PHP', 'Perl', 'C++'}
示例
update() 方法也接受任何序列对象作为参数。这里,元组是 update() 方法的参数。
lang1 = {"C", "C++", "Java", "Python"}
lang2 = ("PHP", "C#", "Perl")
lang1.update(lang2)
print (lang1)
它将产生以下**输出**:
{'Java', 'Perl', 'Python', 'C++', 'C#', 'C', 'PHP'}
示例
在这个例子中,一个集合是由一个字符串构造的,另一个字符串用作 update() 方法的参数。
set1 = set("Hello")
set1.update("World")
print (set1)
它将产生以下**输出**:
{'H', 'r', 'o', 'd', 'W', 'l', 'e'}
union() 方法
集合类的 union() 方法也组合来自两个集合的唯一元素,但它返回一个新的集合对象。
语法
set.union(obj)
参数
obj − 集合或序列对象(列表、元组、字符串)
返回值
union() 方法返回一个集合对象。
示例
以下示例演示了 union() 方法的工作方式:
lang1 = {"C", "C++", "Java", "Python"}
lang2 = {"PHP", "C#", "Perl"}
lang3 = lang1.union(lang2)
print (lang3)
它将产生以下**输出**:
{'C#', 'Java', 'Perl', 'C++', 'PHP', 'Python', 'C'}
示例
如果将序列对象作为参数传递给 union() 方法,Python 会自动先将其转换为集合,然后执行联合操作。
lang1 = {"C", "C++", "Java", "Python"}
lang2 = ["PHP", "C#", "Perl"]
lang3 = lang1.union(lang2)
print (lang3)
它将产生以下**输出**:
{'PHP', 'C#', 'Python', 'C', 'Java', 'C++', 'Perl'}
示例
在这个例子中,一个集合是由一个字符串构造的,另一个字符串用作 union() 方法的参数。
set1 = set("Hello")
set2 = set1.union("World")
print (set2)
它将产生以下**输出**:
{'e', 'H', 'r', 'd', 'W', 'o', 'l'}
Python - 删除集合元素
Python 的集合类提供不同的方法来从集合对象中删除一个或多个元素。
remove() 方法
remove() 方法删除集合中给定的元素(如果存在)。但是,如果它不存在,则会引发 KeyError。
语法
set.remove(obj)
参数
obj − 一个不可变对象
示例
lang1 = {"C", "C++", "Java", "Python"}
print ("Set before removing: ", lang1)
lang1.remove("Java")
print ("Set after removing: ", lang1)
lang1.remove("PHP")
它将产生以下**输出**:
Set before removing: {'C', 'C++', 'Python', 'Java'}
Set after removing: {'C', 'C++', 'Python'}
lang1.remove("PHP")
KeyError: 'PHP'
discard() 方法
集合类中的 discard() 方法类似于 remove() 方法。唯一的区别是,即使要删除的对象不存在于集合中,它也不会引发错误。
语法
set.discard(obj)
参数
obj − 一个不可变对象
示例
lang1 = {"C", "C++", "Java", "Python"}
print ("Set before discarding C++: ", lang1)
lang1.discard("C++")
print ("Set after discarding C++: ", lang1)
print ("Set before discarding PHP: ", lang1)
lang1.discard("PHP")
print ("Set after discarding PHP: ", lang1)
它将产生以下**输出**:
Set before discarding C++: {'Java', 'C++', 'Python', 'C'}
Set after discarding C++: {'Java', 'Python', 'C'}
Set before discarding PHP: {'Java', 'Python', 'C'}
Set after discarding PHP: {'Java', 'Python', 'C'}
pop() 方法
集合类中的 pop() 方法从集合中删除一个任意元素。该方法返回被删除的元素。从空集合中弹出元素会导致 KeyError。
语法
obj = set.pop()
返回值
pop() 方法返回从集合中删除的对象。
示例
lang1 = {"C", "C++"}
print ("Set before popping: ", lang1)
obj = lang1.pop()
print ("object popped: ", obj)
print ("Set after popping: ", lang1)
obj = lang1.pop()
obj = lang1.pop()
它将产生以下**输出**:
Set before popping: {'C++', 'C'}
object popped: C++
Set after popping: {'C'}
Traceback (most recent call last):
obj = lang1.pop()
^^^^^^^^^^^
KeyError: 'pop from an empty set'
在第三次调用 pop() 时,集合为空,因此引发 KeyError。
clear() 方法
集合类中的 clear() 方法删除集合对象中的所有元素,留下一个空集合。
语法
set.clear()
示例
lang1 = {"C", "C++", "Java", "Python"}
print (lang1)
print ("After clear() method")
lang1.clear()
print (lang1)
它将产生以下**输出**:
{'Java', 'C++', 'Python', 'C'}
After clear() method
set()
difference_update() 方法
集合类中的 difference_update() 方法通过删除自身与作为参数给出的另一个集合之间共同的元素来更新集合。
语法
set.difference_update(obj)
参数
obj − 一个集合对象
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1 before running difference_update: ", s1)
s1.difference_update(s2)
print ("s1 after running difference_update: ", s1)
它将产生以下**输出**:
s1 before running difference_update: {1, 2, 3, 4, 5}
s1 after running difference_update: {1, 2, 3}
set()
difference() 方法
difference() 方法类似于 difference_update() 方法,不同之处在于它返回一个包含两个现有集合差的新集合对象。
语法
set.difference(obj)
参数
obj − 一个集合对象
返回值
difference() 方法返回一个新的集合,其中包含在删除 obj 中的元素后剩余的元素。
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1: ", s1, "s2: ", s2)
s3 = s1.difference(s2)
print ("s3 = s1-s2: ", s3)
它将产生以下**输出**:
s1: {1, 2, 3, 4, 5} s2: {4, 5, 6, 7, 8}
s3 = s1-s2: {1, 2, 3}
intersection_update() 方法
intersection_update() 方法的结果是,集合对象只保留自身与作为参数给出的另一个集合对象中共同的元素。
语法
set.intersection_update(obj)
参数
obj − 一个集合对象
返回值
intersection_update() 方法删除不常见的元素,只保留自身和 obj 中共同的元素。
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1: ", s1, "s2: ", s2)
s1.intersection_update(s2)
print ("a1 after intersection: ", s1)
它将产生以下**输出**:
s1: {1, 2, 3, 4, 5} s2: {4, 5, 6, 7, 8}
s1 after intersection: {4, 5}
intersection() 方法
集合类中的 intersection() 方法类似于其 intersection_update() 方法,不同之处在于它返回一个由现有集合中共同元素组成的新集合对象。
语法
set.intersection(obj)
参数
obj − 一个集合对象
返回值
intersection() 方法返回一个集合对象,只保留自身和 obj 中共同的元素。
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1: ", s1, "s2: ", s2)
s3 = s1.intersection(s2)
print ("s3 = s1 & s2: ", s3)
它将产生以下**输出**:
s1: {1, 2, 3, 4, 5} s2: {4, 5, 6, 7, 8}
s3 = s1 & s2: {4, 5}
symmetric_difference_update() 方法
两个集合的对称差是所有不常见元素的集合,拒绝共同元素。symmetric_difference_update() 方法使用自身与作为参数给出的集合之间的对称差来更新集合。
语法
set.symmetric_difference_update(obj)
参数
obj − 一个集合对象
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1: ", s1, "s2: ", s2)
s1.symmetric_difference_update(s2)
print ("s1 after running symmetric difference ", s1)
它将产生以下**输出**:
s1: {1, 2, 3, 4, 5} s2: {4, 5, 6, 7, 8}
s1 after running symmetric difference {1, 2, 3, 6, 7, 8}
symmetric_difference() 方法
集合类中的 symmetric_difference() 方法类似于 symmetric_difference_update() 方法,不同之处在于它返回一个新的集合对象,该对象包含来自两个集合的所有元素,减去共同元素。
语法
set.symmetric_difference(obj)
参数
obj − 一个集合对象
返回值
symmetric_difference() 方法返回一个新集合,其中只包含两个集合对象之间不常见的元素。
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
print ("s1: ", s1, "s2: ", s2)
s3 = s1.symmetric_difference(s2)
print ("s1 = s1^s2 ", s3)
它将产生以下**输出**:
s1: {1, 2, 3, 4, 5} s2: {4, 5, 6, 7, 8}
s1 = s1^s2 {1, 2, 3, 6, 7, 8}
Python - 遍历集合
Python 中的集合既不是序列,也不是映射类型类。因此,集合中的对象不能用索引或键来遍历。但是,您可以使用for循环遍历集合中的每个元素。
示例1
以下示例演示了如何使用for循环遍历集合:
langs = {"C", "C++", "Java", "Python"}
for lang in langs:
print (lang)
它将产生以下**输出**:
C Python C++ Java
示例2
以下示例演示了如何在一个集合的元素上运行for循环,并使用集合类的add()方法添加到另一个集合中。
s1={1,2,3,4,5}
s2={4,5,6,7,8}
for x in s2:
s1.add(x)
print (s1)
它将产生以下**输出**:
{1, 2, 3, 4, 5, 6, 7, 8}
Python - 合并集合
在 Python 中,集合是有序的项目集合。项目可能属于不同类型。但是,集合中的项目必须是不可变对象。这意味着我们只能在集合中包含数字、字符串和元组,而不能包含列表。Python 的集合类有不同的规定来连接集合对象。
使用 "|" 运算符
"|" 符号(管道)定义为并集运算符。它执行 A∪B 操作,并返回 A、B 或两者中都存在的元素的集合。集合不允许重复元素。
s1={1,2,3,4,5}
s2={4,5,6,7,8}
s3 = s1|s2
print (s3)
它将产生以下**输出**:
{1, 2, 3, 4, 5, 6, 7, 8}
使用 union() 方法
集合类具有 union() 方法,该方法执行与 | 运算符相同的操作。它返回一个包含两个集合中所有元素的集合对象,并丢弃重复项。
s1={1,2,3,4,5}
s2={4,5,6,7,8}
s3 = s1.union(s2)
print (s3)
使用 update() 方法
update() 方法也连接两个集合,如同 union() 方法。但是它不返回新的集合对象。而是将第二个集合的元素添加到第一个集合中,不允许重复。
s1={1,2,3,4,5}
s2={4,5,6,7,8}
s1.update(s2)
print (s1)
使用解包运算符
在 Python 中,"*" 符号用作解包运算符。解包运算符在内部将集合中的每个元素分配给一个单独的变量。
s1={1,2,3,4,5}
s2={4,5,6,7,8}
s3 = {*s1, *s2}
print (s3)
Python - 复制集合
集合类中的 copy() 方法创建集合对象的浅拷贝。
语法
set.copy()
返回值
copy() 方法返回一个新的集合,它是现有集合的浅拷贝。
示例
lang1 = {"C", "C++", "Java", "Python"}
print ("lang1: ", lang1, "id(lang1): ", id(lang1))
lang2 = lang1.copy()
print ("lang2: ", lang2, "id(lang2): ", id(lang2))
lang1.add("PHP")
print ("After updating lang1")
print ("lang1: ", lang1, "id(lang1): ", id(lang1))
print ("lang2: ", lang2, "id(lang2): ", id(lang2))
输出
lang1: {'Python', 'Java', 'C', 'C++'} id(lang1): 2451578196864
lang2: {'Python', 'Java', 'C', 'C++'} id(lang2): 2451578197312
After updating lang1
lang1: {'Python', 'C', 'C++', 'PHP', 'Java'} id(lang1): 2451578196864
lang2: {'Python', 'Java', 'C', 'C++'} id(lang2): 2451578197312
Python - 集合运算符
在数学的集合论中,定义了并集、交集、差集和对称差集运算。Python 使用以下运算符实现它们:
并集运算符 (|)
两个集合的并集是一个包含存在于 A 或 B 或两者中的所有元素的集合。例如:
{1,2}∪{2,3}={1,2,3}
下图说明了两个集合的并集。
Python 使用 "|" 符号作为并集运算符。以下示例使用 "|" 运算符并返回两个集合的并集。
示例
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
s3 = s1 | s2
print ("Union of s1 and s2: ", s3)
它将产生以下**输出**:
Union of s1 and s2: {1, 2, 3, 4, 5, 6, 7, 8}
交集运算符 (&)
两个集合 AA 和 BB 的交集,用 A∩B 表示,由 A 和 B 中都存在的元素组成。例如:
{1,2}∩{2,3}={2}
下图说明了两个集合的交集。
Python 使用 "&" 符号作为交集运算符。以下示例使用 & 运算符并返回两个集合的交集。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
s3 = s1 & s2
print ("Intersection of s1 and s2: ", s3)
它将产生以下**输出**:
Intersection of s1 and s2: {4, 5}
差集运算符 (-)
差集(减法)定义如下。集合 A−B 由存在于 A 但不存在于 B 中的元素组成。例如:
If A={1,2,3} and B={3,5}, then A−B={1,2}
下图说明了两个集合的差集:
Python 使用 "-" 符号作为差集运算符。
示例
以下示例使用 "-" 运算符并返回两个集合的差集。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
s3 = s1 - s2
print ("Difference of s1 - s2: ", s3)
s3 = s2 - s1
print ("Difference of s2 - s1: ", s3)
它将产生以下**输出**:
Difference of s1 - s2: {1, 2, 3}
Difference of s2 - s1: {8, 6, 7}
请注意,“s1-s2”与“s2-s1”不同。
对称差集运算符
A 和 B 的对称差用“A Δ B”表示,定义为:
A Δ B = (A − B) ⋃ (B − A)
如果 A = {1, 2, 3, 4, 5, 6, 7, 8} 且 B = {1, 3, 5, 6, 7, 8, 9},则 A Δ B = {2, 4, 9}。
下图说明了两个集合之间的对称差:
Python 使用 "^" 符号作为对称差运算符。
示例
以下示例使用 "^" 运算符并返回两个集合的对称差。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
s3 = s1 - s2
print ("Difference of s1 - s2: ", s3)
s3 = s2 - s1
print ("Difference of s2 - s1: ", s3)
s3 = s1 ^ s2
print ("Symmetric Difference in s1 and s2: ", s3)
它将产生以下**输出**:
Difference of s1 - s2: {1, 2, 3}
Difference of s2 - s1: {8, 6, 7}
Symmetric Difference in s1 and s2: {1, 2, 3, 6, 7, 8}
Python - 集合方法
Python 的集合类中定义了以下方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | add() 向集合中添加元素。 |
| 2 | clear() 删除集合中的所有元素。 |
| 3 | copy() 返回集合的浅拷贝。 |
| 4 | difference() 将两个或多个集合的差集作为新集合返回。 |
| 5 | difference_update() 从集合中删除另一个集合的所有元素。 |
| 6 | discard() 如果元素是集合的成员,则将其从集合中删除。 |
| 7 | intersection() 将两个集合的交集作为新集合返回。 |
| 8 | intersection_update() 使用自身与另一个集合的交集更新集合。 |
| 9 | isdisjoint() 如果两个集合的交集为空,则返回 True。 |
| 10 | issubset() 如果另一个集合包含此集合,则返回 True。 |
| 11 | issuperset() 如果此集合包含另一个集合,则返回 True。 |
| 12 | pop() 删除并返回集合中的任意元素。 |
| 13 | remove() 从集合中删除元素;它必须是成员。 |
| 14 | symmetric_difference() 将两个集合的对称差集作为新集合返回。 |
| 15 | symmetric_difference_update() 使用自身与另一个集合的对称差集更新集合。 |
| 16 | union() 将集合的并集作为新集合返回。 |
| 17 | update() 使用自身与其他集合的并集更新集合。 |
Python - 集合练习
示例1
Python 程序,用于借助集合运算查找两个列表中的公共元素:
l1=[1,2,3,4,5] l2=[4,5,6,7,8] s1=set(l1) s2=set(l2) commons = s1&s2 # or s1.intersection(s2) commonlist = list(commons) print (commonlist)
它将产生以下**输出**:
[4, 5]
示例2
Python 程序,用于检查集合是否为另一个集合的子集:
s1={1,2,3,4,5}
s2={4,5}
if s2.issubset(s1):
print ("s2 is a subset of s1")
else:
print ("s2 is not a subset of s1")
它将产生以下**输出**:
s2 is a subset of s1
示例3
Python 程序,用于获取列表中唯一元素的列表:
T1 = (1, 9, 1, 6, 3, 4, 5, 1, 1, 2, 5, 6, 7, 8, 9, 2) s1 = set(T1) print (s1)
它将产生以下**输出**:
{1, 2, 3, 4, 5, 6, 7, 8, 9}
练习程序
Python 程序,用于查找集合对象的尺寸。
Python 程序,用于基于奇数/偶数将集合分成两部分。
Python 程序,用于从集合中删除所有负数。
Python 程序,用于使用集合中每个数字的绝对值构建另一个集合。
Python 程序,用于从包含不同类型元素的集合中删除所有字符串。
Python - 字典
字典是 Python 中的内置数据类型之一。Python 的字典是映射类型的示例。映射对象将一个对象的 value 与另一个对象映射。
在语言字典中,我们有单词和相应含义的配对。配对的两个部分是键(单词)和值(含义)。类似地,Python 字典也是键值对的集合。这些对用逗号分隔,并放在花括号 {} 中。
为了建立键和值之间的映射,冒号 ":" 符号放在两者之间。
以下是一些 Python 字典对象的示例:
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
示例1
只有数字、字符串或元组可以用作键。它们都是不可变的。您可以使用任何类型的对象作为值。因此,以下字典定义也是有效的:
d1 = {"Fruit":["Mango","Banana"], "Flower":["Rose", "Lotus"]}
d2 = {('India, USA'):'Countries', ('New Delhi', 'New York'):'Capitals'}
print (d1)
print (d2)
它将产生以下**输出**:
{'Fruit': ['Mango', 'Banana'], 'Flower': ['Rose', 'Lotus']}
{'India, USA': 'Countries', ('New Delhi', 'New York'): 'Capitals'}
示例2
Python 不接受列表之类的可变对象作为键,并引发 TypeError。
d1 = {["Mango","Banana"]:"Fruit", "Flower":["Rose", "Lotus"]}
print (d1)
这将引发 TypeError:
Traceback (most recent call last):
File "C:\Users\Sairam\PycharmProjects\pythonProject\main.py", line 8, in <module>
d1 = {["Mango","Banana"]:"Fruit", "Flower":["Rose", "Lotus"]}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: unhashable type: 'list'
示例3
您可以为字典中的多个键赋值,但键在一个字典中不能出现多次。
d1 = {"Banana":"Fruit", "Rose":"Flower", "Lotus":"Flower", "Mango":"Fruit"}
d2 = {"Fruit":"Banana","Flower":"Rose", "Fruit":"Mango", "Flower":"Lotus"}
print (d1)
print (d2)
它将产生以下**输出**:
{'Banana': 'Fruit', 'Rose': 'Flower', 'Lotus': 'Flower', 'Mango': 'Fruit'}
{'Fruit': 'Mango', 'Flower': 'Lotus'}
Python 字典运算符
在 Python 中,定义了以下运算符与字典操作数一起使用。在示例中,使用了以下字典对象。
d1 = {'a': 2, 'b': 4, 'c': 30}
d2 = {'a1': 20, 'b1': 40, 'c1': 60}
| 运算符 | 描述 | 示例 |
|---|---|---|
| dict[key] | 提取/分配与键映射的值 | print (d1['b']) 检索 4 d1['b'] = 'Z' 为键 'b' 分配新值 |
| dict1|dict2 | 两个字典对象的并集,返回新对象 | d3=d1|d2 ; print (d3) {'a': 2, 'b': 4, 'c': 30, 'a1': 20, 'b1': 40, 'c1': 60} |
| dict1|=dict2 | 增强的字典并集运算符 | d1|=d2; print (d1) {'a': 2, 'b': 4, 'c': 30, 'a1': 20, 'b1': 40, 'c1': 60} |
Python - 访问字典元素
使用 "[ ]" 运算符
Python中的字典不是序列,因为字典中的元素没有索引。但是,您仍然可以使用方括号“[ ]”运算符来获取与字典对象中某个键关联的值。
示例1
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
print ("Capital of Gujarat is : ", capitals['Gujarat'])
print ("Capital of Karnataka is : ", capitals['Karnataka'])
它将产生以下**输出**:
Capital of Gujarat is: Gandhinagar Capital of Karnataka is: Bengaluru
示例2
如果方括号内给出的键不存在于字典对象中,Python会引发KeyError。
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
print ("Captial of Haryana is : ", capitals['Haryana'])
它将产生以下**输出**:
print ("Captial of Haryana is : ", capitals['Haryana'])
~~~~~~~~^^^^^^^^^^^
KeyError: 'Haryana'
使用get()方法
Python的dict类中的get()方法返回映射到给定键的值。
语法
Val = dict.get("key")
参数
键 − 用作字典对象中键的不可变对象
返回值
get()方法返回使用给定键映射的对象。
示例3
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
print ("Capital of Gujarat is: ", capitals.get('Gujarat'))
print ("Capital of Karnataka is: ", capitals.get('Karnataka'))
它将产生以下**输出**:
Capital of Gujarat is: Gandhinagar Capital of Karnataka is: Bengaluru
示例 4
与“[ ]”运算符不同,如果找不到键,get()方法不会引发错误;它返回None。
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
print ("Capital of Haryana is : ", capitals.get('Haryana'))
它将产生以下**输出**:
Capital of Haryana is : None
示例5
get()方法接受一个可选的字符串参数。如果给出该参数,并且找不到键,则该字符串将成为返回值。
capitals = {"Maharashtra":"Mumbai", "Gujarat":"Gandhinagar", "Telangana":"Hyderabad", "Karnataka":"Bengaluru"}
print ("Capital of Haryana is : ", capitals.get('Haryana', 'Not found'))
它将产生以下**输出**:
Capital of Haryana is: Not found
Python - 修改字典元素
除了字典的字面表示法(我们将逗号分隔的键:值对放在花括号中),我们还可以使用内置的dict()函数创建字典对象。
空字典
在不带任何参数的情况下使用dict()函数会创建一个空字典对象。这等同于在花括号之间不放置任何内容。
示例
d1 = dict()
d2 = {}
print ('d1: ', d1)
print ('d2: ', d2)
它将产生以下**输出**:
d1: {}
d2: {}
来自元组列表的字典
dict()函数从由两项元组组成的列表或元组构造字典。元组中的第一项被视为键,第二项被视为其值。
示例
d1=dict([('a', 100), ('b', 200)])
d2 = dict((('a', 'one'), ('b', 'two')))
print ('d1: ', d1)
print ('d2: ', d2)
它将产生以下**输出**:
d1: {'a': 100, 'b': 200}
d2: {'a': 'one', 'b': 'two'}
来自关键字参数的字典
dict()函数可以接受任意数量的键值对形式的关键字参数。它返回一个字典对象,其中名称作为键,并将其关联到值。
示例
d1=dict(a= 100, b=200)
d2 = dict(a='one', b='two')
print ('d1: ', d1)
print ('d2: ', d2)
它将产生以下**输出**:
d1: {'a': 100, 'b': 200}
d2: {'a': 'one', 'b': 'two'}
Python - 添加字典元素
使用运算符
“[ ]”运算符(用于访问映射到字典键的值)用于更新现有键值对以及添加新键值对。
语法
dict["key"] = val
如果键已存在于字典对象中,则其值将更新为val。如果键不存在于字典中,则会添加一个新的键值对。
示例
在此示例中,“Laxman”的分数更新为95。
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: ", marks)
marks['Laxman'] = 95
print ("marks dictionary after update: ", marks)
它将产生以下**输出**:
marks dictionary before update: {'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update: {'Savita': 67, 'Imtiaz': 88, 'Laxman': 95, 'David': 49}
示例
但是,字典中没有以'Krishnan'作为键的项,因此添加了一个新的键值对。
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: ", marks)
marks['Krishan'] = 74
print ("marks dictionary after update: ", marks)
它将产生以下**输出**:
marks dictionary before update: {'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update: {'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49, 'Krishan': 74}
使用 update() 方法
您可以通过三种不同的方式使用dict类中的update()方法
使用另一个字典更新
在这种情况下,update()方法的参数是另一个字典。两个字典中共有键的值将被更新。对于新键,将在现有字典中添加键值对。
语法
d1.update(d2)
返回值
现有字典已更新,并向其中添加了新的键值对。
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks1 = {"Sharad": 51, "Mushtaq": 61, "Laxman": 89}
marks.update(marks1)
print ("marks dictionary after update: \n", marks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
使用可迭代对象更新
如果update()方法的参数是由两项元组组成的列表或元组,则会为现有字典中的每一项添加一项,如果键已存在则更新。
语法
d1.update([(k1, v1), (k2, v2)])
返回值
现有字典已更新,并添加了新的键。
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks1 = [("Sharad", 51), ("Mushtaq", 61), ("Laxman", 89)]
marks.update(marks1)
print ("marks dictionary after update: \n", marks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
使用关键字参数更新
update()方法的第三个版本接受name=value格式的关键字参数列表。将添加新的键值对,或更新现有键的值。
语法
d1.update(k1=v1, k2=v2)
返回值
现有字典已更新,并添加了新的键值对。
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks.update(Sharad = 51, Mushtaq = 61, Laxman = 89)
print ("marks dictionary after update: \n", marks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
使用解包运算符
字典对象前缀的“**”符号将其解包成一个元组列表,每个元组包含键和值。两个dict对象被解包并合并在一起,得到一个新的字典。
语法
d3 = {**d1, **d2}
返回值
两个字典合并,并返回一个新的对象。
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks1 = {"Sharad": 51, "Mushtaq": 61, "Laxman": 89}
newmarks = {**marks, **marks1}
print ("marks dictionary after update: \n", newmarks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
使用并集运算符 (|)
Python 引入 "|" (管道符号)作为字典操作数的并集运算符。它更新左侧 dict 对象中现有的键,并添加新的键值对以返回一个新的 dict 对象。
语法
d3 = d1 | d2
返回值
并集运算符在合并两个 dict 操作数后返回一个新的 dict 对象
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks1 = {"Sharad": 51, "Mushtaq": 61, "Laxman": 89}
newmarks = marks | marks1
print ("marks dictionary after update: \n", newmarks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
使用 "|=" 运算符
"|=" 运算符是增强的并集运算符。它通过在右侧操作数中添加新键并更新现有键来对左侧的字典操作数进行就地更新。
语法
d1 |= d2
示例
marks = {"Savita":67, "Imtiaz":88, "Laxman":91, "David":49}
print ("marks dictionary before update: \n", marks)
marks1 = {"Sharad": 51, "Mushtaq": 61, "Laxman": 89}
marks |= marks1
print ("marks dictionary after update: \n", marks)
它将产生以下**输出**:
marks dictionary before update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 91, 'David': 49}
marks dictionary after update:
{'Savita': 67, 'Imtiaz': 88, 'Laxman': 89, 'David': 49, 'Sharad': 51, 'Mushtaq': 61}
Python - 删除字典元素
使用del关键字
Python 的del关键字从内存中删除任何对象。在这里,我们使用它来删除字典中的键值对。
语法
del dict['key']
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
print ("numbers dictionary before delete operation: \n", numbers)
del numbers[20]
print ("numbers dictionary before delete operation: \n", numbers)
它将产生以下**输出**:
numbers dictionary before delete operation:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty', 40: 'Forty'}
numbers dictionary before delete operation:
{10: 'Ten', 30: 'Thirty', 40: 'Forty'}
示例
使用dict对象本身的del关键字将其从内存中删除。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
print ("numbers dictionary before delete operation: \n", numbers)
del numbers
print ("numbers dictionary before delete operation: \n", numbers)
它将产生以下**输出**:
numbers dictionary before delete operation:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty', 40: 'Forty'}
Traceback (most recent call last):
File "C:\Users\mlath\examples\main.py", line 5, in <module>
print ("numbers dictionary before delete operation: \n", numbers)
^^^^^^^
NameError: name 'numbers' is not defined
使用pop()方法
dict类的pop()方法导致从字典中删除具有指定键的元素。
语法
val = dict.pop(key)
返回值
pop()方法在删除键值对后返回指定键的值。
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
print ("numbers dictionary before pop operation: \n", numbers)
val = numbers.pop(20)
print ("nubvers dictionary after pop operation: \n", numbers)
print ("Value popped: ", val)
它将产生以下**输出**:
numbers dictionary before pop operation:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty', 40: 'Forty'}
nubvers dictionary after pop operation:
{10: 'Ten', 30: 'Thirty', 40: 'Forty'}
Value popped: Twenty
使用popitem()方法
dict()类中的popitem()方法不接受任何参数。它弹出最后插入的键值对,并将其作为元组返回。
语法
val = dict.popitem()
返回值
popitem()方法返回一个包含从字典中删除的项的键和值的元组。
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
print ("numbers dictionary before pop operation: \n", numbers)
val = numbers.popitem()
print ("numbers dictionary after pop operation: \n", numbers)
print ("Value popped: ", val)
它将产生以下**输出**:
numbers dictionary before pop operation:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty', 40: 'Forty'}
numbers dictionary after pop operation:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty'}
Value popped: (40, 'Forty')
使用clear()方法
dict类中的clear()方法删除字典对象中的所有元素,并返回一个空对象。
语法
dict.clear()
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
print ("numbers dictionary before clear method: \n", numbers)
numbers.clear()
print ("numbers dictionary after clear method: \n", numbers)
它将产生以下**输出**:
numbers dictionary before clear method:
{10: 'Ten', 20: 'Twenty', 30: 'Thirty', 40: 'Forty'}
numbers dictionary after clear method:
{}
Python - 字典视图对象
dict类的items()、keys()和values()方法返回视图对象。每当其源字典对象的内容发生任何更改时,这些视图都会动态刷新。
items()方法
items()方法返回一个dict_items视图对象。它包含一个元组列表,每个元组由相应的键值对组成。
语法
Obj = dict.items()
返回值
items()方法返回dict_items对象,它是(键,值)元组的动态视图。
示例
在下面的示例中,我们首先使用items()方法获得dict_items()对象,并在更新字典对象时检查它是如何动态更新的。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
obj = numbers.items()
print ('type of obj: ', type(obj))
print (obj)
print ("update numbers dictionary")
numbers.update({50:"Fifty"})
print ("View automatically updated")
print (obj)
它将产生以下**输出**:
type of obj: <class 'dict_items'> dict_items([(10, 'Ten'), (20, 'Twenty'), (30, 'Thirty'), (40, 'Forty')]) update numbers dictionary View automatically updated dict_items([(10, 'Ten'), (20, 'Twenty'), (30, 'Thirty'), (40, 'Forty'), (50, 'Fifty')])
keys()方法
dict类的keys()方法返回dict_keys对象,它是在字典中定义的所有键的列表。它是一个视图对象,因为每当对字典对象执行任何更新操作时,它都会自动更新。
语法
Obj = dict.keys()
返回值
keys()方法返回dict_keys对象,它是字典中键的视图。
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
obj = numbers.keys()
print ('type of obj: ', type(obj))
print (obj)
print ("update numbers dictionary")
numbers.update({50:"Fifty"})
print ("View automatically updated")
print (obj)
它将产生以下**输出**:
type of obj: <class 'dict_keys'> dict_keys([10, 20, 30, 40]) update numbers dictionary View automatically updated dict_keys([10, 20, 30, 40, 50])
values()方法
values()方法返回字典中所有值的视图。该对象是dict_value类型,会自动更新。
语法
Obj = dict.values()
返回值
values()方法返回字典中所有值的dict_values视图。
示例
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
obj = numbers.values()
print ('type of obj: ', type(obj))
print (obj)
print ("update numbers dictionary")
numbers.update({50:"Fifty"})
print ("View automatically updated")
print (obj)
它将产生以下**输出**:
type of obj: <class 'dict_values'> dict_values(['Ten', 'Twenty', 'Thirty', 'Forty']) update numbers dictionary View automatically updated dict_values(['Ten', 'Twenty', 'Thirty', 'Forty', 'Fifty'])
Python - 遍历字典
与列表、元组或字符串不同,Python 中的字典数据类型不是序列,因为项目没有位置索引。但是,仍然可以使用不同的技术遍历字典。
示例1
在字典对象上运行简单的for 循环会遍历其中使用的键。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers:
print (x)
它将产生以下**输出**:
10 20 30 40
示例2
一旦能够获取键,就可以使用方括号运算符或get()方法轻松访问其关联的值。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers:
print (x,":",numbers[x])
它将产生以下**输出**:
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
dict 类的 items()、keys() 和 values() 方法分别返回视图对象 dict_items、dict_keys 和 dict_values。这些对象是迭代器,因此我们可以在其上运行 for 循环。
示例3
dict_items对象是键值元组的列表,可以对其运行for循环,如下所示
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers.items():
print (x)
它将产生以下**输出**:
(10, 'Ten') (20, 'Twenty') (30, 'Thirty') (40, 'Forty')
这里,“x”是来自dict_items迭代器的元组元素。我们可以进一步将这个元组解包到两个不同的变量中。
示例 4
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x,y in numbers.items():
print (x,":", y)
它将产生以下**输出**:
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
示例5
类似地,可以迭代dict_keys对象中的键集合。
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
for x in numbers.keys():
print (x, ":", numbers[x])
dict_keys和dict_values中各自的键和值位于相同的索引处。在下面的示例中,我们有一个for循环,它从0运行到dict的长度,并将循环变量用作索引并打印键及其对应的值。
示例6
numbers = {10:"Ten", 20:"Twenty", 30:"Thirty",40:"Forty"}
l = len(numbers)
for x in range(l):
print (list(numbers.keys())[x], ":", list(numbers.values())[x])
以上两个代码片段产生相同的输出 −
10 : Ten 20 : Twenty 30 : Thirty 40 : Forty
Python - 复制字典
由于Python中的变量仅仅是内存中对象的标签或引用,因此简单的赋值运算符不会创建对象的副本。
示例1
在此示例中,我们有一个字典“d1”,我们将其赋值给另一个变量“d2”。如果更新“d1”,则更改也会反映在“d2”中。
d1 = {"a":11, "b":22, "c":33}
d2 = d1
print ("id:", id(d1), "dict: ",d1)
print ("id:", id(d2), "dict: ",d2)
d1["b"] = 100
print ("id:", id(d1), "dict: ",d1)
print ("id:", id(d2), "dict: ",d2)
输出
id: 2215278891200 dict: {'a': 11, 'b': 22, 'c': 33}
id: 2215278891200 dict: {'a': 11, 'b': 22, 'c': 33}
id: 2215278891200 dict: {'a': 11, 'b': 100, 'c': 33}
id: 2215278891200 dict: {'a': 11, 'b': 100, 'c': 33}
为避免这种情况,并创建字典的浅拷贝,请使用copy()方法而不是赋值。
示例2
d1 = {"a":11, "b":22, "c":33}
d2 = d1.copy()
print ("id:", id(d1), "dict: ",d1)
print ("id:", id(d2), "dict: ",d2)
d1["b"] = 100
print ("id:", id(d1), "dict: ",d1)
print ("id:", id(d2), "dict: ",d2)
输出
当更新“d1”时,“d2”现在不会更改,因为“d2”是字典对象的副本,而不仅仅是引用。
id: 1586671734976 dict: {'a': 11, 'b': 22, 'c': 33}
id: 1586673973632 dict: {'a': 11, 'b': 22, 'c': 33}
id: 1586671734976 dict: {'a': 11, 'b': 100, 'c': 33}
id: 1586673973632 dict: {'a': 11, 'b': 22, 'c': 33}
Python - 嵌套字典
如果一个或多个键的值是另一个字典,则称Python字典具有嵌套结构。嵌套字典通常用于存储复杂的数据结构。
下面的代码片段表示一个嵌套字典
marklist = {
"Mahesh" : {"Phy" : 60, "maths" : 70},
"Madhavi" : {"phy" : 75, "maths" : 68},
"Mitchell" : {"phy" : 67, "maths" : 71}
}
示例1
您还可以构成一个for循环来遍历嵌套字典,就像在上一节中一样。
marklist = {
"Mahesh" : {"Phy" : 60, "maths" : 70},
"Madhavi" : {"phy" : 75, "maths" : 68},
"Mitchell" : {"phy" : 67, "maths" : 71}
}
for k,v in marklist.items():
print (k, ":", v)
它将产生以下**输出**:
Mahesh : {'Phy': 60, 'maths': 70}
Madhavi : {'phy': 75, 'maths': 68}
Mitchell : {'phy': 67, 'maths': 71}
示例2
可以使用[]表示法或get()方法访问内部字典中的值。
print (marklist.get("Madhavi")['maths'])
obj=marklist['Mahesh']
print (obj.get('Phy'))
print (marklist['Mitchell'].get('maths'))
它将产生以下**输出**:
68 60 71
Python - 字典方法
Python中的字典是内置dict类的对象,它定义了以下方法 −
| 序号 | 方法和描述 |
|---|---|
| 1 | 删除字典dict的所有元素。 |
| 2 | 返回字典dict的浅拷贝。 |
| 3 | 使用seq中的键创建一个新字典,并将值设置为value。 |
| 4 | 对于键key,返回value,如果key不在字典中则返回default。 |
| 5 | 如果字典中存在给定的键,则返回true,否则返回false。 |
| 6 | 返回dict的(键,值)元组对列表。 |
| 7 | 返回字典dict的键列表。 |
| 8 | dict.pop() 从集合中删除具有指定键的元素 |
| 9 | dict.popitem() 删除最后插入的键值对 |
| 10 | dict.setdefault(key, default=None) 类似于get(),但如果key不在dict中,则会设置dict[key]=default。 |
| 11 | 将字典dict2的键值对添加到dict中。 |
| 12 | 返回字典dict的值列表。 |
Python - 字典练习
示例1
Python程序,通过从给定字典中提取键来创建一个新字典。
d1 = {"one":11, "two":22, "three":33, "four":44, "five":55}
keys = ['two', 'five']
d2={}
for k in keys:
d2[k]=d1[k]
print (d2)
它将产生以下**输出**:
{'two': 22, 'five': 55}
示例2
Python程序,将字典转换为(k,v)元组列表。
d1 = {"one":11, "two":22, "three":33, "four":44, "five":55}
L1 = list(d1.items())
print (L1)
它将产生以下**输出**:
[('one', 11), ('two', 22), ('three', 33), ('four', 44), ('five', 55)]
示例3
Python程序,删除字典中具有相同值的键。
d1 = {"one":"eleven", "2":2, "three":3, "11":"eleven", "four":44, "two":2}
vals = list(d1.values())#all values
uvals = [v for v in vals if vals.count(v)==1]#unique values
d2 = {}
for k,v in d1.items():
if v in uvals:
d = {k:v}
d2.update(d)
print ("dict with unique value:",d2)
它将产生以下**输出**:
dict with unique value: {'three': 3, 'four': 44}
练习程序
Python程序,按值对字典列表进行排序
Python程序,从给定字典中提取每个键都具有非数值值的字典。
Python程序,根据两项(k,v)元组列表构建字典。
Python程序,使用解包运算符合并两个字典对象。
Python - 数组
Python的标准数据类型list、tuple和string是序列。序列对象是项目的排序集合。每个项目都以从零开始的递增索引为特征。此外,序列中的项目不必是相同类型。换句话说,列表或元组可能包含不同数据类型的项目。
此功能不同于C或C++中数组的概念。在C/C++中,数组也是项目的索引集合,但项目必须是相似的数据类型。在C/C++中,您有整数、浮点数或字符串数组,但您不能有元素一些为整数类型,一些为不同类型的数组。因此,C/C++数组是同质的数据类型集合。
Python的标准库具有array模块。其中的array类允许您构造三种基本类型的数组:整数、浮点数和Unicode字符。
语法
创建数组的语法为:
import array obj = array.array(typecode[, initializer])
参数
typecode − 用于创建数组的typecode字符。
initializer − 从可选值初始化的数组,该值必须是列表、类似字节的对象或适当类型元素的可迭代对象。
返回类型
array()构造函数返回array.array类的对象
示例
import array as arr
# creating an array with integer type
a = arr.array('i', [1, 2, 3])
print (type(a), a)
# creating an array with char type
a = arr.array('u', 'BAT')
print (type(a), a)
# creating an array with float type
a = arr.array('d', [1.1, 2.2, 3.3])
print (type(a), a)
它将产生以下**输出**:
<class 'array.array'> array('i', [1, 2, 3])
<class 'array.array'> array('u', 'BAT')
<class 'array.array'> array('d', [1.1, 2.2, 3.3])
数组是序列类型,其行为与列表非常相似,只是存储在其中的对象类型受到限制。
Python数组类型由单个字符Typecode参数决定。类型代码和数组的预期数据类型如下所示:
| typecode | Python数据类型 | 字节大小 |
|---|---|---|
| 'b' | 带符号整数 | 1 |
| 'B' | 无符号整数 | 1 |
| 'u' | Unicode字符 | 2 |
| 'h' | 带符号整数 | 2 |
| 'H' | 无符号整数 | 2 |
| 'i' | 带符号整数 | 2 |
| 'I' | 无符号整数 | 2 |
| 'l' | 带符号整数 | 4 |
| 'L' | 无符号整数 | 4 |
| 'q' | 带符号整数 | 8 |
| ‘Q’ | 无符号整数 | 8 |
| ‘f’ | 浮点数 | 4 |
| ‘d’ | 浮点数 | 8 |
Python - 访问数组元素
由于数组对象的行为非常类似于序列,因此您可以对其执行索引和切片操作。
示例
import array as arr
a = arr.array('i', [1, 2, 3])
#indexing
print (a[1])
#slicing
print (a[1:])
更改数组项
您可以为数组中的项赋值,就像为列表中的项赋值一样。
示例
import array as arr
a = arr.array('i', [1, 2, 3])
a[1] = 20
print (a[1])
这里,您将得到输出“20”。但是,Python不允许赋值任何与创建数组时使用的 typecode 不同的类型的值。以下赋值将引发 TypeError。
import array as arr
a = arr.array('i', [1, 2, 3])
# assignment
a[1] = 'A'
它将产生以下**输出**:
TypeError: 'str' object cannot be interpreted as an integer
Python - 添加数组元素
append() 方法
append() 方法在给定数组的末尾添加一个新元素。
语法
array.append(v)
参数
v - 新值添加到数组的末尾。新值必须与声明数组对象时使用的 datatype 参数类型相同。
示例
import array as arr
a = arr.array('i', [1, 2, 3])
a.append(10)
print (a)
它将产生以下**输出**:
array('i', [1, 2, 3, 10])
insert() 方法
array 类还定义了 insert() 方法。可以在指定的索引处插入一个新元素。
语法
array.insert(i, v)
参数
i - 要插入新值的索引。
v - 要插入的值。必须是 arraytype 类型。
示例
import array as arr
a = arr.array('i', [1, 2, 3])
a.insert(1,20)
print (a)
它将产生以下**输出**:
array('i', [1, 20, 2, 3])
extend() 方法
array 类中的 extend() 方法将来自另一个相同 typecode 的数组的所有元素附加到当前数组。
语法
array.extend(x)
参数
x - array.array 类的对象
示例
import array as arr
a = arr.array('i', [1, 2, 3, 4, 5])
b = arr.array('i', [6,7,8,9,10])
a.extend(b)
print (a)
它将产生以下**输出**:
array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Python - 删除数组元素
array 类定义了两种方法,我们可以用它们从数组中删除元素。它具有 remove() 和 pop() 方法。
array.remove() 方法
remove() 方法删除数组中给定值的第一次出现。
语法
array.remove(v)
参数
v - 要从数组中删除的值
示例
import array as arr
a = arr.array('i', [1, 2, 1, 4, 2])
a.remove(2)
print (a)
它将产生以下**输出**:
array('i', [1, 1, 4, 2])
array.pop() 方法
pop() 方法删除数组中指定索引处的元素,并返回已删除的元素。
语法
array.pop(i)
参数
i - 要删除的元素的索引。该方法在删除后返回第 i 个位置的元素。
示例
import array as arr
a = arr.array('i', [1, 2, 1, 4, 2])
a.pop(2)
print (a)
它将产生以下**输出**:
array('i', [1, 2, 4, 2])
Python - 遍历数组
由于数组对象的行为类似于序列,因此您可以使用for循环或while循环遍历其元素。
使用 "for" 循环遍历数组
请看下面的例子:
import array as arr
a = arr.array('d', [1, 2, 3])
for x in a:
print (x)
它将产生以下**输出**:
1.0 2.0 3.0
使用 "while" 循环遍历数组
以下示例显示了如何使用while循环遍历数组:
import array as arr
a = arr.array('d', [1, 2, 3])
l = len(a)
idx =0
while idx<l:
print (a[idx])
idx+=1
使用数组索引的 "for" 循环
我们可以使用内置的 len() 函数查找数组的长度。使用它来创建一个 range 对象以获取索引序列,然后在for循环中访问数组元素。
import array as arr
a = arr.array('d', [1, 2, 3])
l = len(a)
for x in range(l):
print (a[x])
您将获得与第一个示例相同的输出。
Python - 复制数组
Python 的内置序列类型,即列表、元组和字符串,是项目的索引集合。但是,与 C/C++、Java 等中的数组不同,它们不是同构的,这意味着这些类型集合中的元素可以是不同类型的。Python 的 array 模块帮助您创建类似于 Java 数组的对象。在本章中,我们将讨论如何将一个数组对象复制到另一个对象。
Python 数组可以是字符串、整数或浮点类型。array 类构造函数的使用方法如下:
import array obj = array.array(typecode[, initializer])
typecode 可以是表示数据类型的字符常量。
我们可以使用赋值运算符将一个数组赋值给另一个数组。
a = arr.array('i', [1, 2, 3, 4, 5])
b=a.copy()
但是,这种赋值不会在内存中创建新的数组。在 Python 中,变量只是一个指向内存中对象的标签或引用。因此,a 是数组的引用,b 也是。检查 a 和 b 的 id()。相同的 id 值证实简单的赋值不会创建副本。
import array as arr
a = arr.array('i', [1, 2, 3, 4, 5])
b=a
print (id(a), id(b))
它将产生以下**输出**:
2771967068656 2771967068656
因为 "a" 和 "b" 指向同一个数组对象,所以 "a" 的任何更改都会反映在 "b" 中:
a[2]=10 print (a,b)
它将产生以下**输出**:
array('i', [1, 2, 10, 4, 5]) array('i', [1, 2, 10, 4, 5])
要创建数组的另一个物理副本,我们使用 Python 库中的另一个模块,名为 copy,并使用该模块中的 deepcopy() 函数。深复制构造一个新的复合对象,然后递归地将原始对象中找到的对象的副本插入到其中。
import array, copy
a = arr.array('i', [1, 2, 3, 4, 5])
import copy
b = copy.deepcopy(a)
现在检查 "a" 和 "b" 的 id()。你会发现 id 不同。
print (id(a), id(b))
它将产生以下**输出**:
2771967069936 2771967068976
这证明创建了一个新的对象 "b",它是 "a" 的实际副本。如果我们更改 "a" 中的元素,它不会反映在 "b" 中。
a[2]=10 print (a,b)
它将产生以下**输出**:
array('i', [1, 2, 10, 4, 5]) array('i', [1, 2, 3, 4, 5])
Python - 反转数组
在本章中,我们将探讨以索引的反向顺序重新排列给定数组的不同方法。在 Python 中,数组不是内置数据类型之一。但是,Python 的标准库具有 array 模块。array 类帮助我们创建一个同构的字符串、整数或浮点数类型集合。
创建数组使用的语法为:
import array obj = array.array(typecode[, initializer])
让我们首先创建一个包含几个int类型对象的数组:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
array 类没有任何内置方法来反转数组。因此,我们必须使用另一个数组。一个空的数组 "b" 声明如下:
b = arr.array('i')
接下来,我们以相反的顺序遍历数组 "a" 中的数字,并将每个元素附加到 "b" 数组:
for i in range(len(a)-1, -1, -1): b.append(a[i])
数组 "b" 现在包含来自原始数组的反向顺序的数字。
示例1
以下是 Python 中反转数组的完整代码:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i')
for i in range(len(a)-1, -1, -1):
b.append(a[i])
print (a, b)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9]) array('i', [9, 20, 6, 4, 15, 5, 10])
我们还可以使用 list 类中的 reverse() 方法反转数组中数字的顺序。List 是 Python 中的内置类型。
我们必须首先使用 array 类的 tolist() 方法将数组的内容传输到列表:
a = arr.array('i', [10,5,15,4,6,20,9])
b = a.tolist()
我们现在可以调用 reverse() 方法:
b.reverse()
如果我们现在将列表转换回数组,我们将得到一个按反向顺序排列的数组。
a = arr.array('i')
a.fromlist(b)
示例2
以下是完整代码:
from array import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b = a.tolist()
b.reverse()
a = arr.array('i')
a.fromlist(b)
print (a)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9])
Python - 排序数组
Python 的 array 模块定义了 array 类。array 类的一个对象类似于 Java 或 C/C++ 中的数组。与 Python 的内置序列不同,数组是字符串、整数或浮点对象的同构集合。
array 类没有任何函数/方法可以对其元素进行排序。但是,我们可以通过以下方法之一实现它:
使用排序算法
使用 List 的 sort() 方法
使用内置的 sorted() 函数
让我们详细讨论每种方法。
使用排序算法
我们将实现经典的冒泡排序算法来获得排序后的数组。为此,我们使用两个嵌套循环并交换元素以按排序顺序重新排列。
使用 Python 代码编辑器保存以下代码:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
for i in range(0, len(a)):
for j in range(i+1, len(a)):
if(a[i] > a[j]):
temp = a[i];
a[i] = a[j];
a[j] = temp;
print (a)
它将产生以下**输出**:
array('i', [4, 5, 6, 9, 10, 15, 20])
使用 List 的 sort() 方法
即使 array 没有sort()方法,Python 的内置 List 类确实有一个 sort 方法。我们将在下一个示例中使用它。
首先,声明一个数组并使用tolist()方法从中获取一个列表对象:
a = arr.array('i', [10,5,15,4,6,20,9])
b=a.tolist()
我们可以轻松地获得排序后的列表,如下所示:
b.sort()
我们需要做的就是将此列表转换回数组对象:
a.fromlist(b)
以下是完整代码:
from array import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b=a.tolist()
b.sort()
a = arr.array('i')
a.fromlist(b)
print (a)
它将产生以下**输出**:
array('i', [4, 5, 6, 9, 10, 15, 20])
使用内置的 sorted() 函数
对数组进行排序的第三种技术是使用 sorted() 函数,这是一个内置函数。
sorted() 函数的语法如下:
sorted(iterable, reverse=False)
该函数返回一个新列表,其中包含来自可迭代对象的所有项,按升序排列。将 reverse 参数设置为 True 以获取项的降序。
sorted() 函数可以与任何可迭代对象一起使用。Python 数组是可迭代的,因为它是一个索引集合。因此,数组可以用作 sorted() 函数的参数。
from array import array as arr
a = arr.array('i', [4, 5, 6, 9, 10, 15, 20])
sorted(a)
print (a)
它将产生以下**输出**:
array('i', [4, 5, 6, 9, 10, 15, 20])
Python - 合并数组
在 Python 中,数组是 Python 内置数据类型(例如字符串、整数或浮点对象)的同构集合。但是,数组本身不是内置类型,而是我们需要使用 Python 内置 array 模块中的 array 类。
第一种方法
要连接两个数组,我们可以通过将一个数组中的每个项目附加到另一个数组来实现。
这里有两个 Python 数组:
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i', [2,7,8,11,3,10])
在数组 "b" 上运行一个for循环。从 "b" 中获取每个数字,并使用以下循环语句将其附加到数组 "a":
for i in range(len(b)): a.append(b[i])
数组 "a" 现在包含来自 "a" 和 "b" 的元素。
以下是完整代码:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i', [2,7,8,11,3,10])
for i in range(len(b)):
a.append(b[i])
print (a, b)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9, 2, 7, 8, 11, 3, 10])
第二种方法
使用另一种方法连接两个数组,首先将数组转换为列表对象:
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i', [2,7,8,11,3,10])
x=a.tolist()
y=b.tolist()
列表对象可以用 '+' 运算符连接。
z=x+y
如果 "z" 列表转换回数组,您将得到一个表示已连接数组的数组:
a.fromlist(z)
以下是完整代码:
from array import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i', [2,7,8,11,3,10])
x=a.tolist()
y=b.tolist()
z=x+y
a=arr.array('i')
a.fromlist(z)
print (a)
第三种方法
我们还可以使用 List 类中的 extend() 方法将一个列表中的元素附加到另一个列表。
首先,将数组转换为列表,然后调用 extend() 方法合并两个列表:
from array import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
b = arr.array('i', [2,7,8,11,3,10])
a.extend(b)
print (a)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9, 2, 7, 8, 11, 3, 10])
Python - 数组方法
array.reverse() 方法
与序列类型一样,array 类也支持 reverse() 方法,该方法可以按相反顺序重新排列元素。
语法
array.reverse()
参数
此方法没有参数。
示例
import array as arr
a = arr.array('i', [1, 2, 3, 4, 5])
a.reverse()
print (a)
它将产生以下**输出**:
array('i', [5, 4, 3, 2, 1])
array 类还定义了以下有用的方法。
array.count() 方法
count() 方法返回给定元素在数组中出现的次数。
语法
array.count(v)
参数
v - 要计算其出现次数的值
返回值
count() 方法返回一个整数,对应于 v 在数组中出现的次数。
示例
import array as arr
a = arr.array('i', [1, 2, 3, 2, 5, 6, 2, 9])
c = a.count(2)
print ("Count of 2:", c)
它将产生以下**输出**:
Count of 2: 3
array.index() 方法
array 类中的 index() 方法查找数组中给定元素第一次出现的 位置。
语法
array.index(v)
参数
v - 要查找其索引的值
示例
a = arr.array('i', [1, 2, 3, 2, 5, 6, 2, 9])
c = a.index(2)
print ("index of 2:", c)
它将产生以下**输出**:
index of 2: 1
array.fromlist() 方法
fromlist() 方法将 Python 列表中的项附加到数组对象。
语法
array.fromlist(l)
参数
i - 列表,其项附加到数组。列表中的所有项必须是相同的 arrtype。
示例
import array as arr
a = arr.array('i', [1, 2, 3, 4, 5])
lst = [6, 7, 8, 9, 10]
c = a.fromlist(lst)
print (a)
它将产生以下**输出**:
array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
array.tofile() 方法
array 类中的 tofile() 方法将数组中的所有项(作为机器值)写入文件对象 f。
语法
array.tofile(f)
参数
f - 使用 open() 函数获得的文件对象。要以 wb 模式打开的文件。
示例
import array as arr
f = open('list.txt','wb')
arr.array("i", [10, 20, 30, 40, 50]).tofile(f)
f.close()
输出
运行上述代码后,将在当前目录中创建一个名为“list.txt”的文件。
array.fromfile() 方法
fromfile() 方法读取二进制文件并将指定数量的项附加到数组对象。
语法
array.fromfile(f, n)
参数
f - 指向以 rb 模式打开的磁盘文件的 File 对象
n - 要附加的项目数
示例
import array as arr
a = arr.array('i', [1, 2, 3, 4, 5])
f = open("list.txt", "rb")
a.fromfile(f, 5)
print (a)
它将产生以下**输出**:
array('i', [1, 2, 3, 4, 5, 10, 20, 30, 40, 50])
Python - 数组练习
示例1
查找 Python 数组中最大数字的 Python 程序:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
print (a)
largest = a[0]
for i in range(1, len(a)):
if a[i]>largest:
largest=a[i]
print ("Largest number:", largest)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9])
Largest number: 20
示例2
将 Python 数组中的所有偶数存储到另一个数组的 Python 程序:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
print (a)
b = arr.array('i')
for i in range(len(a)):
if a[i]%2 == 0:
b.append(a[i])
print ("Even numbers:", b)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9])
Even numbers: array('i', [10, 4, 6, 20])
示例3
查找 Python 数组中所有数字平均值的 Python 程序:
import array as arr
a = arr.array('i', [10,5,15,4,6,20,9])
print (a)
s = 0
for i in range(len(a)):
s+=a[i]
avg = s/len(a)
print ("Average:", avg)
# Using sum() function
avg = sum(a)/len(a)
print ("Average:", avg)
它将产生以下**输出**:
array('i', [10, 5, 15, 4, 6, 20, 9])
Average: 9.857142857142858
Average: 9.857142857142858
练习程序
Python程序找出数组中每个数字与所有数字平均值之间的差值
Python程序将字符串转换为数组
Python程序将数组分成两个,并将偶数存储在一个数组中,奇数存储在另一个数组中。
Python程序对数组执行插入排序。
Python程序存储给定数组中每个字符的Unicode值。
Python - 文件处理
当我们使用任何计算机应用程序时,需要提供一些数据。数据存储在计算机的主内存(RAM)中,直到应用程序运行。此后,RAM中的内存内容将被擦除。
我们希望以一种可以在需要时从持久性介质(如磁盘文件)中检索到的方式存储它。
Python使用内置的input()和print()函数执行标准输入/输出操作。Python程序通过sys模块中定义的标准流对象stdin和stdout与这些IO设备交互。
input()函数从标准输入流设备(即键盘)读取字节。因此,以下两个语句都从用户处读取输入。
name = input() #is equivalent to import sys name = sys.stdin.readline()
另一方面,print()函数将数据发送到标准输出流设备(即显示器)。它是一个方便的函数,模拟stdout对象的write()方法。
print (name) #is equivalent to import sys sys.stdout.write(name)
任何与输入和输出流交互的对象都称为文件对象。Python的内置函数open()返回一个文件对象。
open()函数
此函数创建一个文件对象,该对象将用于调用与其关联的其他支持方法。
语法
file object = open(file_name [, access_mode][, buffering])
以下是参数详细信息:
file_name − file_name参数是一个字符串值,包含要访问的文件的名称。
access_mode − access_mode确定打开文件的模式,即读取、写入、追加等。下表给出了所有可能值的完整列表。这是一个可选参数,默认文件访问模式为读取 (r)。
buffering − 如果将buffering值设置为0,则不进行缓冲。如果buffering值为1,则在访问文件时执行行缓冲。如果将buffering值指定为大于1的整数,则以指定的缓冲区大小执行缓冲操作。如果为负数,则缓冲区大小为系统默认值(默认行为)。
文件打开模式
以下是文件打开模式:
| 序号 | 模式及描述 |
|---|---|
| 1 | r 只读打开文件。文件指针位于文件开头。这是默认模式。 |
| 2 | rb 以二进制格式只读打开文件。文件指针位于文件开头。这是默认模式。 |
| 3 | r+ 打开文件进行读取和写入。文件指针位于文件开头。 |
| 4 | rb+ 以二进制格式打开文件进行读取和写入。文件指针位于文件开头。 |
| 5 | w 只写打开文件。如果文件存在,则覆盖文件。如果文件不存在,则创建一个新文件进行写入。 |
| 6 | b 以二进制模式打开文件 |
| 7 | t 以文本模式打开文件(默认) |
| 8 | + 打开文件以进行更新(读取和写入) |
| 9 | wb 以二进制格式只写打开文件。如果文件存在,则覆盖文件。如果文件不存在,则创建一个新文件进行写入。 |
| 10 | w+ 打开文件进行写入和读取。如果文件存在,则覆盖现有文件。如果文件不存在,则创建一个新文件进行读取和写入。 |
| 11 | wb+ 以二进制格式打开文件进行写入和读取。如果文件存在,则覆盖现有文件。如果文件不存在,则创建一个新文件进行读取和写入。 |
| 12 | a 打开文件进行追加。如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,则创建一个新文件进行写入。 |
| 13 | ab 以二进制格式打开文件进行追加。如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,则创建一个新文件进行写入。 |
| 14 | a+ 打开文件进行追加和读取。如果文件存在,则文件指针位于文件末尾。文件以追加模式打开。如果文件不存在,则创建一个新文件进行读取和写入。 |
| 15 | ab+ 以二进制格式打开文件进行追加和读取。如果文件存在,则文件指针位于文件末尾。文件以追加模式打开。如果文件不存在,则创建一个新文件进行读取和写入。 |
| 16 | x 打开以进行独占创建,如果文件已存在则失败 |
打开文件并拥有一个文件对象后,您可以获取与该文件相关的各种信息。
示例
# Open a file
fo = open("foo.txt", "wb")
print ("Name of the file: ", fo.name)
print ("Closed or not: ", fo.closed)
print ("Opening mode: ", fo.mode)
fo.close()
它将产生以下**输出**:
Name of the file: foo.txt Closed or not: False Opening mode: wb
Python - 写入文件
要在Python中将数据写入文件,需要先打开文件。任何与输入和输出流交互的对象都称为文件对象。Python的内置函数open()返回一个文件对象。
fileObject = open(file_name [, access_mode][, buffering])
使用open()函数获得文件对象后,可以使用write()方法将任何字符串写入文件对象表示的文件。需要注意的是,Python字符串可以包含二进制数据,而不仅仅是文本。
write()方法不会在字符串末尾添加换行符('\n')。
语法
fileObject.write(string)
这里,传递的参数是要写入打开的文件的内容。
示例
# Open a file
fo = open("foo.txt", "w")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opened file
fo.close()
上述方法将创建foo.txt文件,并将给定内容写入该文件,最后关闭该文件。程序本身没有显示任何输出,但是如果您使用任何文本编辑器应用程序(如记事本)打开此文件,它将包含以下内容:
Python is a great language. Yeah its great!!
以二进制模式写入
默认情况下,对文件对象的读/写操作是对文本字符串数据执行的。如果我们想处理其他类型的文件,例如媒体 (mp3)、可执行文件 (exe)、图片 (jpg) 等,我们需要在读/写模式前添加“b”前缀。
以下语句将字符串转换为字节并写入文件。
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()
也可以使用encode()函数将文本字符串转换为字节。
data="Hello World".encode('utf-8')
追加到文件
当以'w'模式打开任何现有文件以存储附加文本时,其早期内容将被擦除。每当以写权限打开文件时,它都被视为新文件。要向现有文件添加数据,请使用'a'表示追加模式。
语法
fileobject = open(file_name,"a")
示例
# Open a file in append mode
fo = open("foo.txt", "a")
text = "TutorialsPoint has a fabulous Python tutorial"
fo.write(text)
# Close opened file
fo.close()
执行上述程序时,不会显示任何输出,但会将新行追加到foo.txt。要验证,请使用文本编辑器打开。
Python is a great language. Yeah its great!! TutorialsPoint has a fabulous Python tutorial
使用w+模式
当打开文件进行写入(使用'w'或'a')时,无法在文件的任何早期字节位置执行写入操作。'w+'模式允许使用write()和read()方法而无需关闭文件。文件对象支持seek()函数将流倒回到任何所需的字节位置。
以下是seek()方法的语法:
fileObject.seek(offset[, whence])
参数
offset − 这是文件中读/写指针的位置。
whence − 这是可选的,默认为0,这意味着绝对文件定位,其他值为1,这意味着相对于当前位置查找,2意味着相对于文件末尾查找。
让我们使用seek()方法来演示如何在文件中同时进行读/写操作。
示例
下面的程序以w+模式(读写模式)打开文件,添加一些数据。然后它在文件中查找特定位置,并用新文本覆盖其早期内容。
# Open a file in read-write mode
fo=open("foo.txt","w+")
fo.write("This is a rat race")
fo.seek(10,0)
data=fo.read(3)
fo.seek(10,0)
fo.write('cat')
fo.close()
输出
如果我们以读取模式打开文件(或在w+模式下查找起始位置),并读取内容,则显示:
This is a cat race
Python - 读取文件
要使用Python以编程方式从文件读取数据,必须先打开它。使用内置的open()函数:
file object = open(file_name [, access_mode][, buffering])
以下是参数详细信息:
file_name − file_name参数是一个字符串值,包含要访问的文件的名称。
access_mode − access_mode确定打开文件的模式,即读取、写入、追加等。这是一个可选参数,默认文件访问模式为读取 (r)。
这两个语句是相同的:
fo = open("foo.txt", "r")
fo = open("foo.txt")
要从打开的文件读取数据,请使用文件对象的read()方法。需要注意的是,Python字符串除了文本数据外还可以包含二进制数据。
语法
fileObject.read([count])
参数
count − 要读取的字节数。
这里,传递的参数是要从打开的文件中读取的字节数。此方法从文件开头开始读取,如果缺少count,则它尝试尽可能多地读取,可能直到文件末尾。
示例
# Open a file
fo = open("foo.txt", "r")
text = fo.read()
print (text)
# Close the opened file
fo.close()
它将产生以下**输出**:
Python is a great language. Yeah its great!!
以二进制模式读取
默认情况下,对文件对象的读/写操作是对文本字符串数据执行的。如果我们想处理其他类型的文件,例如媒体 (mp3)、可执行文件 (exe)、图片 (jpg) 等,我们需要在读/写模式前添加“b”前缀。
假设test.bin文件已经以二进制模式写入。
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()
我们需要使用'rb'模式读取二进制文件。read()方法的返回值在打印之前先解码。
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))
它将产生以下**输出**:
Hello World
从文件中读取整数数据
为了将整数数据写入二进制文件,应使用to_bytes()方法将整数对象转换为字节。
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)
要从二进制文件读回,请使用from_bytes()函数将read()函数的输出转换为整数。
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)
从文件中读取浮点数据
对于浮点数据,我们需要使用Python标准库中的struct模块。
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)
解包read()函数的字符串以从二进制文件中检索浮点数据。
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)
使用r+模式
以 'r' 或 'rb' 模式打开文件进行读取时,无法向其中写入数据。需要先关闭文件才能执行其他操作。为了同时执行读取和写入操作,需要在模式参数中添加 '+' 字符。因此,'w+' 或 'r+' 模式允许在不关闭文件的情况下使用 write() 和 read() 方法。
File 对象还支持 seek() 函数,可以将流回绕到任何所需的字节位置进行读取。
以下是seek()方法的语法:
fileObject.seek(offset[, whence])
参数
offset − 这是文件中读/写指针的位置。
whence − 这是可选的,默认为0,这意味着绝对文件定位,其他值为1,这意味着相对于当前位置查找,2意味着相对于文件末尾查找。
让我们使用 seek() 方法演示如何从特定字节位置读取数据。
示例
此程序以 w+ 模式(读写模式)打开文件,添加一些数据。然后,它在文件中查找特定位置,并用新文本覆盖其之前的內容。
fo=open("foo.txt","r+")
fo.seek(10,0)
data=fo.read(3)
print (data)
fo.close()
它将产生以下**输出**:
rat
Python 同时读写
以 'w' 或 'a' 模式打开文件进行写入时,无法从中读取数据,反之亦然。这样做会抛出 UnSupportedOperation 错误。需要先关闭文件才能执行其他操作。
为了同时执行读取和写入操作,需要在模式参数中添加 '+' 字符。因此,'w+' 或 'r+' 模式允许在不关闭文件的情况下使用 write() 和 read() 方法。File 对象还支持 seek() 函数,可以将流回绕到任何所需的字节位置。
seek() 方法
seek() 方法将文件的当前位置设置为 offset。whence 参数是可选的,默认为 0,表示绝对文件定位;其他值为 1,表示相对于当前位置查找;2 表示相对于文件末尾查找。
此方法没有返回值。请注意,如果使用 'a' 或 'a+' 以追加模式打开文件,则任何 seek() 操作都会在下一次写入时被撤销。
如果仅以追加模式('a')打开文件进行写入,则此方法基本上是无操作的,但对于以启用读取的追加模式('a+')打开的文件,它仍然很有用。
如果使用 't' 在文本模式下打开文件,则只有 tell() 返回的偏移量才是合法的。使用其他偏移量会导致未定义的行为。
请注意,并非所有文件对象都是可查找的。
语法
以下是seek()方法的语法:
fileObject.seek(offset[, whence])
参数
offset − 这是文件中读/写指针的位置。
whence − 这是可选的,默认为0,这意味着绝对文件定位,其他值为1,这意味着相对于当前位置查找,2意味着相对于文件末尾查找。
让我们使用seek()方法来演示如何在文件中同时进行读/写操作。
下面的程序以w+模式(读写模式)打开文件,添加一些数据。然后它在文件中查找特定位置,并用新文本覆盖其早期内容。
示例
# Open a file in read-write mode
fo=open("foo.txt","w+")
fo.write("This is a rat race")
fo.seek(10,0)
data=fo.read(3)
fo.seek(10,0)
fo.write('cat')
fo.seek(0,0)
data=fo.read()
print (data)
fo.close()
输出
This is a cat race
Python - 重命名和删除文件
Python 的 os 模块提供了一些方法,可以帮助你执行文件处理操作,例如重命名和删除文件。
要使用此模块,需要先导入它,然后才能调用任何相关的函数。
rename() 方法
rename() 方法接受两个参数:当前文件名和新文件名。
语法
os.rename(current_file_name, new_file_name)
示例
以下是一个将现有文件 "test1.txt" 重命名为 "test2.txt" 的示例:
#!/usr/bin/python3 import os # Rename a file from test1.txt to test2.txt os.rename( "test1.txt", "test2.txt" )
remove() 方法
可以使用 remove() 方法通过提供要删除的文件名作为参数来删除文件。
语法
os.remove(file_name)
示例
以下是一个删除现有文件 "test2.txt" 的示例:
#!/usr/bin/python3
import os
# Delete file test2.txt
os.remove("text2.txt")
Python - 目录
所有文件都包含在各种目录中,Python 也能轻松处理这些目录。os 模块有几个方法可以帮助你创建、删除和更改目录。
mkdir() 方法
可以使用 os 模块的 mkdir() 方法在当前目录中创建目录。需要为此方法提供一个参数,其中包含要创建的目录的名称。
语法
os.mkdir("newdir")
示例
以下是一个在当前目录中创建名为 test 的目录的示例:
#!/usr/bin/python3
import os
# Create a directory "test"
os.mkdir("test")
chdir() 方法
可以使用 chdir() 方法更改当前目录。chdir() 方法接受一个参数,即要设置为当前目录的目录的名称。
语法
os.chdir("newdir")
示例
以下是一个进入 "/home/newdir" 目录的示例:
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")
getcwd() 方法
getcwd() 方法显示当前工作目录。
语法
os.getcwd()
示例
以下是一个显示当前目录的示例:
#!/usr/bin/python3 import os # This would give location of the current directory os.getcwd()
rmdir() 方法
rmdir() 方法删除作为方法参数传递的目录。
删除目录之前,应先删除其中的所有内容。
语法
os.rmdir('dirname')
示例
以下是一个删除 "/tmp/test" 目录的示例。需要提供目录的完全限定名,否则它会在当前目录中搜索该目录。
#!/usr/bin/python3 import os # This would remove "/tmp/test" directory. os.rmdir( "/tmp/test" )
Python - 文件方法
使用 open() 函数创建文件对象。file 类定义了以下方法,可以使用这些方法执行不同的文件 I/O 操作。这些方法可用于任何类似文件的对象,例如字节流或网络流。
| 序号 | 方法和描述 |
|---|---|
| 1 | 关闭文件。关闭的文件无法再读取或写入。 |
| 2 | 刷新内部缓冲区,类似于 stdio 的 fflush。这在某些类似文件的对象上可能是无操作的。 |
| 3 | 返回由底层实现用来向操作系统请求 I/O 操作的整数文件描述符。 |
| 4 | 如果文件连接到 tty(-like) 设备,则返回 True;否则返回 False。 |
| 5 | 每次调用时返回文件中的下一行。 |
| 6 | 最多从文件中读取 size 个字节(如果在获得 size 个字节之前读取遇到 EOF,则读取更少的字节)。 |
| 7 | 从文件中读取一行。字符串中保留尾随换行符。 |
| 8 | 使用 readline() 读取直到 EOF,并返回包含这些行的列表。如果存在可选的 sizehint 参数,则不读取到 EOF,而是读取总计约 sizehint 字节的整行(可能在四舍五入到内部缓冲区大小后)。 |
| 9 | 设置文件的当前位置 |
| 10 | 返回文件的当前位置 |
| 11 | 截断文件的大小。如果存在可选的 size 参数,则文件将被截断到(最多)该大小。 |
| 12 | 将字符串写入文件。没有返回值。 |
| 13 | 将一系列字符串写入文件。该序列可以是任何产生字符串的可迭代对象,通常是字符串列表。 |
让我们简要了解一下上述方法。
Python - OS 文件/目录方法
os 模块提供大量有用的方法来操作文件。此处列出了大多数有用的方法:
| 序号 | 方法及说明 |
|---|---|
1 |
os.close(fd) 关闭文件描述符 fd。 |
2 |
os.closerange(fd_low, fd_high) 关闭从 fd_low(包含)到 fd_high(不包含)的所有文件描述符,忽略错误。 |
3 |
返回文件描述符 fd 的副本。 |
4 |
强制将文件描述符 fd 的文件写入磁盘。 |
5 |
os.fdopen(fd[, mode[, bufsize]]) 返回连接到文件描述符 fd 的打开文件对象。 |
6 |
强制将文件描述符 fd 的文件写入磁盘。 |
7 |
截断对应于文件描述符 fd 的文件,使其大小最多为 length 字节。 |
8 |
将文件描述符 fd 的当前位置设置为位置 pos,由 how 修改。 |
9 |
打开文件 file 并根据 flags 设置各种标志,并可能根据 mode 设置其模式。 |
10 |
最多从文件描述符 fd 读取 n 个字节。返回包含读取的字节的字符串。如果已到达 fd 引用的文件的末尾,则返回空字符串。 |
11 |
os.tmpfile() 返回以更新模式 (w+b) 打开的新文件对象。 |
12 |
将字符串 str 写入文件描述符 fd。返回实际写入的字节数。 |
Python - 面向对象概念
Python 自诞生之日起就是一个面向对象的语言。因此,创建和使用类和对象非常容易。本章将帮助你成为 Python 面向对象编程支持方面的专家。
如果你以前没有面向对象 (OO) 编程经验,你可能需要参考一个入门课程或至少是一个教程,以便了解基本概念。但是,这里简要介绍一下面向对象编程 (OOP),以帮助你。
面向过程方法
50 年代和 60 年代开发的早期编程语言被称为面向过程(或过程式)语言。
计算机程序通过按逻辑顺序编写一系列指令来描述执行特定任务的过程。更复杂的程序的逻辑被分解成更小但独立且可重用的语句块,称为函数。
每个函数的编写方式都使其能够与程序中的其他函数交互。属于一个函数的数据可以很容易地以参数的形式与其他函数共享,被调用的函数可以将其结果返回给调用函数。
与面向过程方法相关的主要问题如下:
其自上而下的方法使程序难以维护。
它使用大量的全局数据项,这是不希望的。过多的全局数据项会增加内存开销。
它更重视过程,而不考虑同等重要性的数据,并将其视为理所当然,因此它可以在程序中自由移动。
数据在函数间的移动不受限制。在现实生活中,期望函数与其要处理的数据之间存在明确的关联。
Python - 面向对象概念
在现实世界中,我们处理和处理对象,例如学生、员工、发票、汽车等。对象不仅是数据,也不仅仅是函数,而是两者的组合。每个现实世界中的对象都具有与其相关的属性和行为。
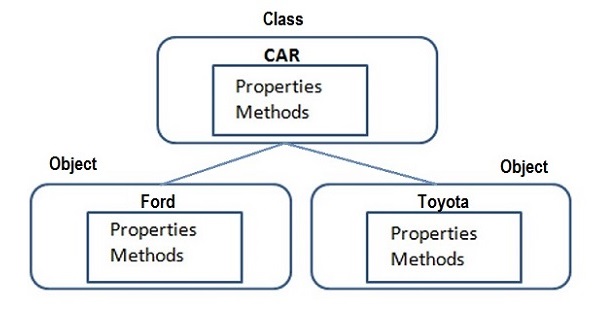
属性
学生的姓名、班级、科目、分数等
员工的姓名、职称、部门、工资等
发票号码、客户、产品代码和名称、价格和数量等
汽车的注册号、车主、公司、品牌、马力、速度等
每个属性都将具有与其关联的值。属性相当于数据。
行为
处理与对象相关的属性。
计算学生的百分比分数
计算应付给员工的奖励
对发票价值征收增值税
测量汽车的速度
行为相当于函数。在现实生活中,属性和行为并非相互独立,而是共存的。
面向对象方法最重要的特征是将属性及其功能定义为一个称为类的单元。它作为所有具有相似属性和行为的对象的蓝图。
在 OOP 中,类定义了其对象具有的属性以及其行为方式。另一方面,对象是类的实例。
面向对象编程范式具有以下特点:
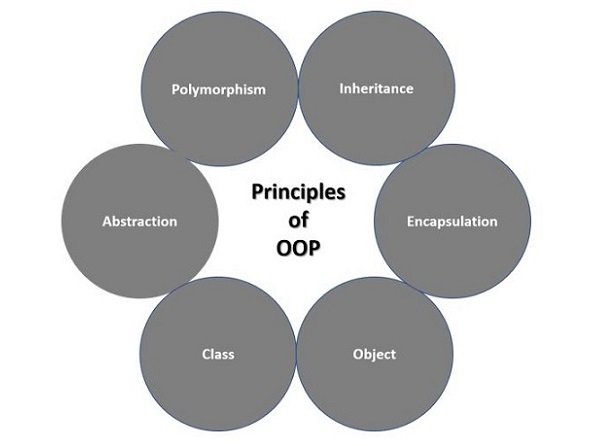
类
对象的自定义原型,定义了一组特征化任何类对象的属性。属性是数据成员(类变量和实例变量)和方法,通过点表示法访问。
对象
某个类的单个对象。例如,属于 Circle 类的对象 obj 是 Circle 类的实例。由其类定义的数据结构的唯一实例。对象包含数据成员(类变量和实例变量)和方法。
封装
类的成员数据仅可供类中定义的函数处理。另一方面,类的函数可以从类上下文之外访问。因此,对象数据对类外部的环境是隐藏的。类函数(也称为方法)封装对象数据,以防止对其进行未经授权的访问。
继承
OOP 的软件建模方法能够扩展现有类的功能来构建新类,而不是从头开始构建。在 OOP 术语中,现有类称为基类或父类,而新类称为子类或子类。
子类继承父类的数据定义和方法。这有助于重用现有功能。子类可以添加更多定义或重新定义基类函数。
多态性
多态性是一个希腊词,意思是具有多种形式。在 OOP 中,多态性发生在每个子类都提供基类中抽象方法的自身实现时。
Python - 对象和类
Python 是一种高度面向对象的语言。在 Python 中,Python 程序中的每个元素都是某个类的对象。程序中使用的数字、字符串、列表、字典等都是相应内置类的对象。
示例
num=20
print (type(num))
num1=55.50
print (type(num1))
s="TutorialsPoint"
print (type(s))
dct={'a':1,'b':2,'c':3}
print (type(dct))
def SayHello():
print ("Hello World")
return
print (type(SayHello))
执行这段代码后,将产生以下输出:
<class 'int'> <class 'float'> <class 'str'> <class 'dict'> <class 'function'>
在 Python 中,Object 类是所有类的基类或父类,包括内置类和用户定义类。
class 关键字用于定义新类。类名紧跟在 class 关键字之后,后面跟着一个冒号,如下所示:
class ClassName: 'Optional class documentation string' class_suite
类包含一个文档字符串,可以通过 ClassName.__doc__ 访问。
class_suite 包含定义类成员、数据属性和函数的所有组件语句。
示例
class Employee(object): 'Common base class for all employees' pass
Python 中的任何类都是 object 类的子类,因此 object 写在括号中。但是,更高版本的 Python 不需要在括号中添加 object。
class Employee: 'Common base class for all employees' pass
要定义此类的对象,请使用以下语法:
e1 = Employee()
Python - 类属性
每个 Python 类都保留以下内置属性,可以使用点运算符像访问其他属性一样访问它们:
__dict__ − 包含类命名空间的字典。
__doc__ − 类文档字符串,如果未定义则为 None。
__name__ − 类名。
__module__ − 定义类的模块名。在交互模式下,此属性为“__main__”。
__bases__ − 一个可能为空的元组,包含基类,顺序与其在基类列表中的出现顺序相同。
对于上述类,让我们尝试访问所有这些属性:
class Employee:
def __init__(self, name="Bhavana", age=24):
self.name = name
self.age = age
def displayEmployee(self):
print ("Name : ", self.name, ", age: ", self.age)
print ("Employee.__doc__:", Employee.__doc__)
print ("Employee.__name__:", Employee.__name__)
print ("Employee.__module__:", Employee.__module__)
print ("Employee.__bases__:", Employee.__bases__)
print ("Employee.__dict__:", Employee.__dict__ )
它将产生以下**输出**:
Employee.__doc__: None
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: (<class 'object'>,)
Employee.__dict__: {'__module__': '__main__', '__init__': <function Employee.__init__ at 0x0000022F866B8B80>, 'displayEmployee': <function Employee.displayEmployee at 0x0000022F866B9760>, '__dict__': <attribute '__dict__' of 'Employee' objects>, '__weakref__': <attribute '__weakref__' of 'Employee' objects>, '__doc__': None}
类变量
在上例 Employee 类中,name 和 age 是实例变量,因为它们的 value 对于每个对象可能不同。类属性或变量的值在该类的所有实例之间共享。类属性表示类所有对象的公共属性。
类属性不是在 __init__() 构造函数内初始化的。它们在类中定义,但在任何方法之外。除了对象之外,还可以通过类名访问它们。换句话说,类属性可用于类及其对象。
示例
让我们在 Employee 类中添加一个名为 empCount 的类变量。对于声明的每个对象,__init__() 方法都会自动调用。此方法初始化实例变量,并将 empCount 加 1。
class Employee:
empCount = 0
def __init__(self, name, age):
self.__name = name
self.__age = age
Employee.empCount += 1
print ("Name: ", self.__name, "Age: ", self.__age)
print ("Employee Number:", Employee.empCount)
e1 = Employee("Bhavana", 24)
e2 = Employee("Rajesh", 26)
e3 = Employee("John", 27)
输出
我们声明了三个对象。每次 empCount 都加 1。
Name: Bhavana Age: 24 Employee Number: 1 Name: Rajesh Age: 26 Employee Number: 2 Name: John Age: 27 Employee Number: 3
Python - 类方法
实例方法访问调用对象的实例变量,因为它获取对调用对象的引用。但它也可以访问类变量,因为它对所有对象都是通用的。
Python 有一个内置函数 classmethod(),它将实例方法转换为类方法,只能通过类引用调用,而不是对象。
语法
classmethod(instance_method)
示例
在 Employee 类中,定义一个带“self”参数(对调用对象的引用)的 showcount() 实例方法。它打印 empCount 的值。接下来,将方法转换为可以通过类引用访问的类方法 counter()。
class Employee:
empCount = 0
def __init__(self, name, age):
self.__name = name
self.__age = age
Employee.empCount += 1
def showcount(self):
print (self.empCount)
counter=classmethod(showcount)
e1 = Employee("Bhavana", 24)
e2 = Employee("Rajesh", 26)
e3 = Employee("John", 27)
e1.showcount()
Employee.counter()
输出
使用对象调用 showcount(),使用类调用 count(),两者都显示员工计数的值。
3 3
使用 @classmethod() 装饰器是定义类方法的首选方法,因为它比首先声明实例方法然后转换为类方法更方便。
@classmethod
def showcount(cls):
print (cls.empCount)
Employee.showcount()
类方法充当备用构造函数。定义一个带有构造新对象所需参数的 newemployee() 类方法。它返回构造的对象,这与 __init__() 方法的作用相同。
@classmethod
def showcount(cls):
print (cls.empCount)
return
@classmethod
def newemployee(cls, name, age):
return cls(name, age)
e1 = Employee("Bhavana", 24)
e2 = Employee("Rajesh", 26)
e3 = Employee("John", 27)
e4 = Employee.newemployee("Anil", 21)
Employee.showcount()
现在有四个 Employee 对象了。
Python - 静态方法
静态方法没有像对对象的引用− self 或对类的引用− cls 这样的强制参数。Python 的标准库函数 staticmethod() 返回一个静态方法。
在下面的 Employee 类中,一个方法被转换为静态方法。现在可以通过其对象或类本身的引用来调用此静态方法。
class Employee:
empCount = 0
def __init__(self, name, age):
self.__name = name
self.__age = age
Employee.empCount += 1
#@staticmethod
def showcount():
print (Employee.empCount)
return
counter = staticmethod(showcount)
e1 = Employee("Bhavana", 24)
e2 = Employee("Rajesh", 26)
e3 = Employee("John", 27)
e1.counter()
Employee.counter()
Python 还具有 @staticmethod 装饰器,它可以方便地返回静态方法。
@staticmethod
def showcount():
print (Employee.empCount)
e1.showcount()
Employee.showcount()
Python - 构造函数
在面向对象编程中,类的对象以一个或多个实例变量或属性为特征,其值对于每个对象都是唯一的。例如,如果 Employee 类具有 name 作为实例属性。它的每个对象 e1 和 e2 可能对 name 变量具有不同的值。
构造函数是类中的实例方法,每当声明类的新的对象时都会自动调用。构造函数的作用是在声明对象后立即为实例变量赋值。
Python 使用一个名为 __init__() 的特殊方法来初始化对象的实例变量,一旦它被声明。
__init__() 方法充当构造函数。它需要一个强制参数 self,它是对对象的引用。
def __init__(self): #initialize instance variables
__init__() 方法以及类中的任何实例方法都具有一个强制参数 self。但是,您可以为第一个参数赋予任何名称,而不一定是 self。
让我们在 Employee 类中定义构造函数以将 name 和 age 初始化为实例变量。然后我们可以访问其对象的这些属性。
示例
class Employee:
'Common base class for all employees'
def __init__(self):
self.name = "Bhavana"
self.age = 24
e1 = Employee()
print ("Name: {}".format(e1.name))
print ("age: {}".format(e1.age))
它将产生以下**输出**:
Name: Bhavana age: 24
参数化构造函数
对于上述 Employee 类,我们声明的每个对象都将为其实例变量 name 和 age 具有相同的值。要声明具有不同属性而不是默认属性的对象,请为 __init__() 方法定义参数。(方法只不过是在类中定义的函数。)
示例
在此示例中,__init__() 构造函数有两个形式参数。我们声明具有不同值的 Employee 对象:
class Employee:
'Common base class for all employees'
def __init__(self, name, age):
self.name = name
self.age = age
e1 = Employee("Bhavana", 24)
e2 = Employee("Bharat", 25)
print ("Name: {}".format(e1.name))
print ("age: {}".format(e1.age))
print ("Name: {}".format(e2.name))
print ("age: {}".format(e2.age))
它将产生以下**输出**:
Name: Bhavana age: 24 Name: Bharat age: 25
您可以为构造函数中的形式参数分配默认值,以便可以传递或不传递参数来实例化对象。
class Employee:
'Common base class for all employees'
def __init__(self, name="Bhavana", age=24):
self.name = name
self.age = age
e1 = Employee()
e2 = Employee("Bharat", 25)
print ("Name: {}".format(e1.name))
print ("age: {}".format(e1.age))
print ("Name: {}".format(e2.name))
print ("age: {}".format(e2.age))
它将产生以下**输出**:
Name: Bhavana age: 24 Name: Bharat age: 25
Python - 实例方法
除了 __init__() 构造函数外,类中还可能定义一个或多个实例方法。具有 self 作为形式参数之一的方法称为实例方法,因为它是由特定对象调用的。
示例
在下面的示例中,已定义 displayEmployee() 方法。它返回调用该方法的 Employee 对象的 name 和 age 属性。
class Employee:
def __init__(self, name="Bhavana", age=24):
self.name = name
self.age = age
def displayEmployee(self):
print ("Name : ", self.name, ", age: ", self.age)
e1 = Employee()
e2 = Employee("Bharat", 25)
e1.displayEmployee()
e2.displayEmployee()
它将产生以下**输出**:
Name : Bhavana , age: 24 Name : Bharat , age: 25
您可以随时添加、删除或修改类和对象的属性:
emp1.salary = 7000 # Add a 'salary' attribute. emp1.name = 'xyz' # Modify 'name' attribute. del emp1.salary # Delete 'salary' attribute.
您可以使用以下函数代替使用普通语句访问属性:
getattr(obj, name[, default]) − 访问对象的属性。
hasattr(obj,name) − 检查属性是否存在。
setattr(obj,name,value) − 设置属性。如果属性不存在,则会创建它。
delattr(obj, name) − 删除属性。
print (hasattr(e1, 'salary')) # Returns true if 'salary' attribute exists print (getattr(e1, 'name')) # Returns value of 'name' attribute setattr(e1, 'salary', 7000) # Set attribute 'salary' at 8 delattr(e1, 'age') # Delete attribute 'age'
它将产生以下**输出**:
False Bhavana
Python - 访问修饰符
像 C++ 和 Java 这样的语言使用访问修饰符来限制对类成员(即变量和方法)的访问。这些语言具有关键字 public、protected 和 private 来指定访问类型。
如果可以在程序的任何位置访问类成员,则称该成员为公共成员。私有成员只能在类内部访问。
通常,方法定义为公共的,实例变量定义为私有的。这种私有实例变量和公共方法的安排确保了封装原则的实现。
受保护的成员可以在类内部以及派生自该类的类中访问。
与这些语言不同,Python 没有规定可以指定类成员可能具有的访问类型。默认情况下,类中的所有变量和方法都是公共的。
示例
在这里,我们有一个带有实例变量 name 和 age 的 Employee 类。此类的对象具有这两个属性。可以直接从类外部访问它们,因为它们是公共的。
class Employee:
'Common base class for all employees'
def __init__(self, name="Bhavana", age=24):
self.name = name
self.age = age
e1 = Employee()
e2 = Employee("Bharat", 25)
print ("Name: {}".format(e1.name))
print ("age: {}".format(e1.age))
print ("Name: {}".format(e2.name))
print ("age: {}".format(e2.age))
它将产生以下**输出**:
Name: Bhavana age: 24 Name: Bharat age: 25
Python 不强制执行访问任何实例变量或方法的限制。但是,Python 规定了一种约定,即在变量/方法名前缀单个或双下划线来模拟受保护和私有访问修饰符的行为。
为了指示实例变量是私有的,请在其前面加上双下划线(例如“__age”)。为了暗示某个实例变量是受保护的,请在其前面加上单个下划线(例如“_salary”)。
示例
让我们修改 Employee 类。添加另一个实例变量 salary。通过分别加前双下划线和单下划线,使 age 私有,salary 受保护。
class Employee:
def __init__(self, name, age, salary):
self.name = name # public variable
self.__age = age # private variable
self._salary = salary # protected variable
def displayEmployee(self):
print ("Name : ", self.name, ", age: ", self.__age, ", salary: ", self._salary)
e1=Employee("Bhavana", 24, 10000)
print (e1.name)
print (e1._salary)
print (e1.__age)
运行此代码时,将产生以下**输出**:
Bhavana
10000
Traceback (most recent call last):
File "C:\Users\user\example.py", line 14, in <module>
print (e1.__age)
^^^^^^^^
AttributeError: 'Employee' object has no attribute '__age'
Python 显示 AttributeError,因为 __age 是私有的,并且不能在类外部使用。
名称改编
Python 不会阻止对私有数据的访问,它只是留给程序员的智慧,不要编写任何从类外部访问它的代码。您仍然可以通过 Python 的名称改编技术访问私有成员。
名称改编是将具有双下划线的成员名称更改为 object._class__variable 形式的过程。如果需要,仍然可以从类外部访问它,但应避免这种做法。
在我们的示例中,私有实例变量“__name”通过将其更改为以下格式来进行改编:
obj._class__privatevar
因此,要访问“e1”对象的“__age”实例变量的值,请将其更改为“e1._Employee__age”。
将上述程序中的 print() 语句更改为:
print (e1._Employee__age)
它现在打印 24,即 e1 的年龄。
Python 属性对象
Python 的标准库有一个内置的 property() 函数。它返回一个属性对象。它充当 Python 类实例变量的接口。
面向对象编程的封装原则要求实例变量应该具有受限的私有访问权限。Python 没有为此目的提供有效的机制。property() 函数提供了一种替代方法。
property() 函数使用在类中定义的 getter、setter 和 delete 方法来为类定义属性对象。
语法
property(fget=None, fset=None, fdel=None, doc=None)
参数
fget − 获取实例变量值的实例方法。
fset − 为实例变量赋值的实例方法。
fdel − 删除实例变量的实例方法
fdoc − 属性的文档字符串。
该函数使用 getter 和 setter 方法返回属性对象。
Getter 和 Setter 方法
getter 方法检索实例变量的值,通常命名为 get_varname,而 setter 方法为实例变量赋值,命名为 set_varname。
让我们在 Employee 类中定义 getter 方法 get_name() 和 get_age(),以及 setter 方法 set_name() 和 set_age()。
示例
class Employee:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self):
return self.__name
def get_age(self):
return self.__age
def set_name(self, name):
self.__name = name
return
def set_age(self, age):
self.__age=age
e1=Employee("Bhavana", 24)
print ("Name:", e1.get_name(), "age:",
e1.get_age())
e1.set_name("Archana")
e1.set_age(21)
print ("Name:", e1.get_name(), "age:", e1.get_age())
它将产生以下**输出**:
Name: Bhavana age: 24 Name: Archana age: 21
getter 和 setter 方法可以检索或为实例变量赋值。property() 函数使用它们将属性对象添加为类属性。
name 属性定义为:
name = property(get_name, set_name, "name")
同样,您可以添加 age 属性:
age = property(get_age, set_age, "age")
属性对象的优点是您可以使用它来检索其关联实例变量的值,以及赋值。
例如:
print (e1.name) displays value of e1.__name e1.name = "Archana" assigns value to e1.__age
示例
包含属性对象及其用法的完整程序如下所示:
class Employee:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self):
return self.__name
def get_age(self):
return self.__age
def set_name(self, name):
self.__name = name
return
def set_age(self, age):
self.__age=age
return
name = property(get_name, set_name, "name")
age = property(get_age, set_age, "age")
e1=Employee("Bhavana", 24)
print ("Name:", e1.name, "age:", e1.age)
e1.name = "Archana"
e1.age = 23
print ("Name:", e1.name, "age:", e1.age)
它将产生以下**输出**:
Name: Bhavana age: 24 Name: Archana age: 23
Python - 继承
继承是面向对象编程方法论最重要的特性之一。它最常用于使用 Java、PHP、Python 等多种语言的软件开发过程中。
您可以通过在新的类名后括号中列出父类来创建一个类,而不是从头开始。
您可以通过在新的类名后括号中列出父类来创建一个类,而不是从头开始。
如果您必须设计一个新类,其大多数属性已经在现有类中定义得很好了,那么为什么要重新定义它们呢?继承允许重用现有类的功能,如果需要,可以扩展它们来设计新类。
当新类与现有类具有“IS A”关系时,继承就会出现。汽车是一种交通工具。公共汽车是一种交通工具;自行车也是一种交通工具。这里的交通工具是父类,而汽车、公共汽车和自行车是子类。
语法
派生类的声明方式与其父类非常相似;但是,在类名之后给出了要从中继承的基类列表:
class SubClassName (ParentClass1[, ParentClass2, ...]): 'Optional class documentation string' class_suite
示例
class Parent: # define parent class
def __init__(self):
self.attr = 100
print ("Calling parent constructor")
def parentMethod(self):
print ('Calling parent method')
def set_attr(self, attr):
self.attr = attr
def get_attr(self):
print ("Parent attribute :", self.attr)
class Child(Parent): # define child class
def __init__(self):
print ("Calling child constructor")
def childMethod(self):
print ('Calling child method')
c = Child() # instance of child
c.childMethod() # child calls its method
c.parentMethod() # calls parent's method
c.set_attr(200) # again call parent's method
c.get_attr() # again call parent's method
输出
执行此代码后,将产生以下输出:
Calling child constructor Calling child method Calling parent method Parent attribute : 200
Python - 多继承
Python中的多继承允许你基于多个父类构建一个类。子类因此继承所有父类的属性和方法。子类可以覆盖从任何父类继承的方法。
语法
class parent1: #statements class parent2: #statements class child(parent1, parent2): #statements
Python的标准库有一个内置的`divmod()`函数,它返回一个包含两个元素的元组。第一个数字是两个参数的商,第二个是两个操作数的余数。
示例
这个例子尝试模拟`divmod()`函数。我们定义了两个类`division`和`modulus`,然后有一个`div_mod`类继承它们。
class division:
def __init__(self, a,b):
self.n=a
self.d=b
def divide(self):
return self.n/self.d
class modulus:
def __init__(self, a,b):
self.n=a
self.d=b
def mod_divide(self):
return self.n%self.d
class div_mod(division,modulus):
def __init__(self, a,b):
self.n=a
self.d=b
def div_and_mod(self):
divval=division.divide(self)
modval=modulus.mod_divide(self)
return (divval, modval)
子类有一个新的方法`div_and_mod()`,它内部调用它继承的类的`divide()`和`mod_divide()`方法来返回商和余数。
x=div_mod(10,3)
print ("division:",x.divide())
print ("mod_division:",x.mod_divide())
print ("divmod:",x.div_and_mod())
输出
division: 3.3333333333333335 mod_division: 1 divmod: (3.3333333333333335, 1)
方法解析顺序 (MRO)
术语“方法解析顺序”与Python中的多继承有关。在Python中,继承可以跨越多个级别。假设A是B的父类,B是C的父类。C类可以覆盖继承的方法,或者它的对象可以调用在其父类中定义的方法。那么,Python如何找到要调用的合适方法呢?
每个Python类都有一个`mro()`方法,它返回Python用于解析要调用的方法的层次顺序。解析顺序是从继承顺序的底部到顶部。
在我们之前的例子中,`div_mod`类继承了`division`和`modulus`类。因此,`mro`方法返回的顺序如下:
[<class '__main__.div_mod'>, <class '__main__.division'>, <class '__main__.modulus'>, <class 'object'>]
Python - 多态
术语“多态性”是指一个函数或方法在不同上下文中采用不同形式。由于Python是一种动态类型语言,因此Python中的多态性很容易实现。
如果父类中的一个方法在其不同的子类中被覆盖为不同的业务逻辑,则基类方法就是一个多态方法。
示例
下面给出一个多态性的例子,我们有`shape`类,它是一个抽象类。它被`circle`和`rectangle`两个类用作父类。这两个类都以不同的方式覆盖了父类的`draw()`方法。
from abc import ABC, abstractmethod
class shape(ABC):
@abstractmethod
def draw(self):
"Abstract method"
return
class circle(shape):
def draw(self):
super().draw()
print ("Draw a circle")
return
class rectangle(shape):
def draw(self):
super().draw()
print ("Draw a rectangle")
return
shapes = [circle(), rectangle()]
for shp in shapes:
shp.draw()
输出
执行此代码后,将产生以下输出:
Draw a circle Draw a rectangle
变量`shp`首先引用`circle`对象并调用`circle`类的`draw()`方法。在下一次迭代中,它引用`rectangle`对象并调用`rectangle`类的`draw()`方法。因此,`shape`类中的`draw()`方法是多态的。
Python - 方法重写
你总是可以覆盖父类的方法。覆盖父类方法的一个原因是你可能希望在子类中实现特殊或不同的功能。
示例
class Parent: # define parent class
def myMethod(self):
print ('Calling parent method')
class Child(Parent): # define child class
def myMethod(self):
print ('Calling child method')
c = Child() # instance of child
c.myMethod() # child calls overridden method
执行上述代码时,它会产生以下输出:
Calling child method
为了理解Python中的继承,让我们来看另一个例子。我们使用下面的`Employee`类作为父类:
class Employee:
def __init__(self,nm, sal):
self.name=nm
self.salary=sal
def getName(self):
return self.name
def getSalary(self):
return self.salary
接下来,我们定义一个`SalesOfficer`类,它使用`Employee`作为父类。它从父类继承了实例变量`name`和`salary`。此外,子类还有一个实例变量`incentive`。
我们将使用内置函数`super()`,它返回父类的引用,并在子类的构造函数`__init__()`方法中调用父类的构造函数。
class SalesOfficer(Employee):
def __init__(self,nm, sal, inc):
super().__init__(nm,sal)
self.incnt=inc
def getSalary(self):
return self.salary+self.incnt
`getSalary()`方法被重写以将奖金添加到薪水中。
示例
声明父类和子类的对象,看看重写的影响。完整的代码如下:
class Employee:
def __init__(self,nm, sal):
self.name=nm
self.salary=sal
def getName(self):
return self.name
def getSalary(self):
return self.salary
class SalesOfficer(Employee):
def __init__(self,nm, sal, inc):
super().__init__(nm,sal)
self.incnt=inc
def getSalary(self):
return self.salary+self.incnt
e1=Employee("Rajesh", 9000)
print ("Total salary for {} is Rs {}".format(e1.getName(),e1.getSalary()))
s1=SalesOfficer('Kiran', 10000, 1000)
print ("Total salary for {} is Rs {}".format(s1.getName(),s1.getSalary()))
执行这段代码后,将产生以下输出:
Total salary for Rajesh is Rs 9000 Total salary for Kiran is Rs 11000
基类可重写方法
下表列出了`object`类(所有Python类的父类)的一些通用功能。你可以在你自己的类中重写这些方法:
| 序号 | 方法,描述 & 示例调用 |
|---|---|
1 |
__init__(self [,args...]) 构造函数(带任何可选参数) 示例调用:obj = className(args) |
2 |
__del__(self) 析构函数,删除一个对象 示例调用:del obj |
3 |
__repr__(self) 可计算的字符串表示 示例调用:repr(obj) |
4 |
__str__(self) 可打印的字符串表示 示例调用:str(obj) |
Python - 方法重载
方法重载是面向对象编程的一个重要特性。Java、C++、C#语言支持方法重载,但在Python中,无法执行方法重载。
当一个类具有多个同名但参数类型和/或返回类型不同的方法时,就是一个方法重载的情况。Python不支持此机制,如下面的代码所示:
示例
class example:
def add(self, a, b):
x = a+b
return x
def add(self, a, b, c):
x = a+b+c
return x
obj = example()
print (obj.add(10,20,30))
print (obj.add(10,20))
输出
第一次调用带三个参数的`add()`方法是成功的。但是,调用类中定义的带两个参数的`add()`方法失败了。
60
Traceback (most recent call last):
File "C:\Users\user\example.py", line 12, in <module>
print (obj.add(10,20))
^^^^^^^^^^^^^^
TypeError: example.add() missing 1 required positional argument: 'c'
输出告诉你Python只考虑`add()`方法的最新定义,丢弃之前的定义。
为了模拟方法重载,我们可以使用一种变通方法,为方法参数定义默认值None,这样它就可以使用一个、两个或三个参数。
示例
class example:
def add(self, a = None, b = None, c = None):
x=0
if a !=None and b != None and c != None:
x = a+b+c
elif a !=None and b != None and c == None:
x = a+b
return x
obj = example()
print (obj.add(10,20,30))
print (obj.add(10,20))
它将产生以下**输出**:
60 30
通过这种变通方法,我们能够在Python类中加入方法重载。
Python的标准库没有其他实现方法重载的规定。但是,我们可以为此目的使用名为`MultipleDispatch`的第三方模块中的`dispatch`函数。
首先,你需要安装`Multipledispatch`模块。
pip install multipledispatch
这个模块有一个`@dispatch`装饰器。它接受要传递给要重载的方法的参数数量。使用`@dispatch`装饰器定义`add()`方法的多个副本,如下所示:
示例
from multipledispatch import dispatch
class example:
@dispatch(int, int)
def add(self, a, b):
x = a+b
return x
@dispatch(int, int, int)
def add(self, a, b, c):
x = a+b+c
return x
obj = example()
print (obj.add(10,20,30))
print (obj.add(10,20))
输出
执行此代码后,将产生以下输出:
60 30
Python - 动态绑定
在面向对象编程中,动态绑定的概念与多态性密切相关。在Python中,动态绑定是在运行时而不是在编译时解析方法或属性的过程。
根据多态性特性,不同的对象对相同的方法调用会根据其各自的实现做出不同的响应。这种行为是通过方法重写实现的,子类在其超类中提供自己对方法的实现。
Python解释器根据对象的类型或类层次结构在运行时确定要调用的适当方法或属性。这意味着要调用的特定方法或属性是动态确定的,基于对象的实际类型。
示例
下面的例子说明了Python中的动态绑定:
class shape:
def draw(self):
print ("draw method")
return
class circle(shape):
def draw(self):
print ("Draw a circle")
return
class rectangle(shape):
def draw(self):
print ("Draw a rectangle")
return
shapes = [circle(), rectangle()]
for shp in shapes:
shp.draw()
它将产生以下**输出**:
Draw a circle Draw a rectangle
正如你所看到的,`draw()`方法根据对象的类型动态绑定到相应的实现。这就是Python中动态绑定的实现方式。
鸭子类型
另一个与动态绑定密切相关的概念是**鸭子类型**。一个对象是否适合特定用途取决于某些方法或属性的存在,而不是其类型。这使得Python具有更大的灵活性和代码重用性。
鸭子类型是像Python(Perl、Ruby、PHP、Javascript等)这样的动态类型语言的一个重要特性,它关注的是对象的行为而不是其特定类型。根据“鸭子类型”的概念,“如果它像鸭子一样行走,像鸭子一样嘎嘎叫,那么它一定是一只鸭子”。
鸭子类型允许不同类型的对象互换使用,只要它们具有所需的方法或属性。目标是提高灵活性和代码重用性。这是一个更广泛的概念,它强调对象的行为和接口而不是正式类型。
这是一个鸭子类型的例子:
class circle:
def draw(self):
print ("Draw a circle")
return
class rectangle:
def draw(self):
print ("Draw a rectangle")
return
class area:
def area(self):
print ("calculate area")
return
def duck_function(obj):
obj.draw()
objects = [circle(), rectangle(), area()]
for obj in objects:
duck_function(obj)
它将产生以下**输出**:
Draw a circle Draw a rectangle Traceback (most recent call last): File "C:\Python311\hello.py", line 21, in <module> duck_function(obj) File "C:\Python311\hello.py", line 17, in duck_function obj.draw() AttributeError: 'area' object has no attribute 'draw'
`duck_function()`最重要的是它不关心接收对象的具体类型。它只需要对象具有`draw()`方法。如果一个对象通过具有必要行为而“像鸭子一样嘎嘎叫”,则在调用`draw()`方法时将其视为“鸭子”。
因此,在鸭子类型中,重点是对象的行为而不是其显式类型,允许不同类型的对象互换使用,只要它们表现出所需的行为。
Python - 动态类型
Python语言最突出的特点之一是它是一种动态类型语言。基于编译器的语言C/C++、Java等是静态类型的。让我们尝试理解静态类型和动态类型之间的区别。
在静态类型语言中,必须在为变量赋值之前声明每个变量及其数据类型。任何其他类型的值对于编译器都是不可接受的,它会引发编译时错误。
让我们来看一下下面的Java程序片段:
public class MyClass {
public static void main(String args[]) {
int var;
var="Hello";
System.out.println("Value of var = " + var);
}
}
这里,`var`被声明为一个整型变量。当我们尝试为它赋值一个字符串值时,编译器会给出以下错误消息:
/MyClass.java:4: error: incompatible types: String cannot be converted to int
x="Hello";
^
1 error
Python中的变量只是一个标签,或者是对存储在内存中的对象的引用,而不是一个命名的内存位置。因此,不需要事先声明类型。因为它只是一个标签,所以它可以放在另一个对象上,这个对象可以是任何类型。
在Java中,变量的类型决定了它可以存储什么,不能存储什么。在Python中则相反。在这里,数据(即对象)的类型决定了变量的类型。首先,让我们在一个变量中存储一个字符串并检查其类型。
>>> var="Hello"
>>> print ("id of var is ", id(var))
id of var is 2822590451184
>>> print ("type of var is ", type(var))
type of var is <class 'str'>
所以,`var`是字符串类型。但是,它不是永久绑定的。它只是一个标签;可以赋值给任何其他类型的对象,例如浮点数,它将存储一个不同的`id()`:
>>> var=25.50
>>> print ("id of var is ", id(var))
id of var is 2822589562256
>>> print ("type of var is ", type(var))
type of var is <class 'float'>
或一个元组。`var`标签现在位于不同的对象上。
>>> var=(10,20,30)
>>> print ("id of var is ", id(var))
id of var is 2822592028992
>>> print ("type of var is ", type(var))
type of var is <class 'tuple'>
我们可以看到,每次`var`引用一个新对象时,它的类型都会改变。这就是Python是一种动态类型语言的原因。
Python的动态类型特性使其比C/C++和Java更灵活。但是,它容易出现运行时错误,因此程序员必须小心。
Python - 抽象
抽象是面向对象编程的重要原则之一。它指的是一种编程方法,通过这种方法,只有关于对象的相关数据才会被暴露,而隐藏所有其他细节。这种方法有助于降低复杂性并提高应用程序开发效率。
抽象有两种类型。一种是数据抽象,其中原始数据实体通过数据结构隐藏,该数据结构可以在内部处理隐藏的数据实体。另一种类型称为过程抽象。它指的是隐藏过程的底层实现细节。
在面向对象编程术语中,如果一个类不能被实例化,则该类被称为抽象类,也就是说你不能拥有抽象类的对象。但是,你可以将它用作基类或父类来构建其他类。
要在Python中形成一个抽象类,它必须继承`abc`模块中定义的`ABC`类。此模块在Python的标准库中可用。此外,该类必须至少有一个抽象方法。同样,抽象方法是不能被调用的方法,但可以被重写。你需要用`@abstractmethod`装饰器来装饰它。
示例
from abc import ABC, abstractmethod
class demo(ABC):
@abstractmethod
def method1(self):
print ("abstract method")
return
def method2(self):
print ("concrete method")
`demo`类继承了`ABC`类。有一个`method1()`是抽象方法。注意,该类可能还有其他非抽象(具体)方法。
如果你尝试声明`demo`类的对象,Python会引发`TypeError`:
obj = demo()
^^^^^^
TypeError: Can't instantiate abstract class demo with abstract method method1
此处的demo类可以用作另一个类的父类。但是,子类必须重写父类中的抽象方法。否则,Python会抛出此错误:
TypeError: Can't instantiate abstract class concreteclass with abstract method method1
因此,在下面的示例中给出了重写抽象方法的子类:
from abc import ABC, abstractmethod
class democlass(ABC):
@abstractmethod
def method1(self):
print ("abstract method")
return
def method2(self):
print ("concrete method")
class concreteclass(democlass):
def method1(self):
super().method1()
return
obj = concreteclass()
obj.method1()
obj.method2()
输出
执行此代码后,将产生以下输出:
abstract method concrete method
Python - 封装
封装的原理是面向对象编程范式所基于的主要支柱之一。Python对封装的实现采取了不同的方法。
我们知道,类是对象的自定义原型。它定义了一组数据成员和方法,能够处理数据。根据数据封装的原理,描述对象的那些数据成员对外部环境是隐藏的。它们只能用于类中定义的方法进行处理。另一方面,方法本身可以从类上下文外部访问。因此,对象数据被方法封装。这种封装的结果是防止了对对象数据的任何无意访问。
像C++和Java这样的语言使用访问修饰符来限制对类成员(即变量和方法)的访问。这些语言具有关键字public、protected和private来指定访问类型。
如果类成员可以从程序的任何地方访问,则称其为公共成员。私有成员只能从类内部访问。通常,方法定义为公共的,实例变量是私有的。这种私有实例变量和公共方法的安排确保了封装的实现。
与这些语言不同,Python没有规定可以指定类成员可能具有的访问类型。默认情况下,Python类中的所有变量和方法都是公共的,如下例所示。
示例1
这里,我们有一个带有实例变量name和age的Employee类。此类的对象具有这两个属性。可以直接从类外部访问它们,因为它们是公共的。
class Student:
def __init__(self, name="Rajaram", marks=50):
self.name = name
self.marks = marks
s1 = Student()
s2 = Student("Bharat", 25)
print ("Name: {} marks: {}".format(s1.name, s2.marks))
print ("Name: {} marks: {}".format(s2.name, s2.marks))
它将产生以下**输出**:
Name: Rajaram marks: 50 Name: Bharat marks: 25
在上面的示例中,实例变量在类内部初始化。但是,没有限制从类外部访问实例变量的值,这与封装的原则相违背。
尽管没有关键字强制执行可见性,但Python有一种以特殊方式命名实例变量的约定。在Python中,使用单下划线或双下划线作为变量/方法名称的前缀来模拟受保护和私有访问修饰符的行为。
如果变量以单个双下划线开头(例如“__age”),则实例变量是私有的;类似地,如果变量名称以单个下划线开头(例如“_salary”)
示例2
让我们修改Student类。添加另一个实例变量salary。通过在其前面添加双下划线,将name设为私有,将marks设为私有。
class Student:
def __init__(self, name="Rajaram", marks=50):
self.__name = name
self.__marks = marks
def studentdata(self):
print ("Name: {} marks: {}".format(self.__name, self.__marks))
s1 = Student()
s2 = Student("Bharat", 25)
s1.studentdata()
s2.studentdata()
print ("Name: {} marks: {}".format(s1.__name, s2.__marks))
print ("Name: {} marks: {}".format(s2.__name, __s2.marks))
运行此代码时,将产生以下**输出**:
Name: Rajaram marks: 50
Name: Bharat marks: 25
Traceback (most recent call last):
File "C:\Python311\hello.py", line 14, in <module>
print ("Name: {} marks: {}".format(s1.__name, s2.__marks))
AttributeError: 'Student' object has no attribute '__name'
上面的输出清楚地表明,实例变量name和age虽然可以通过类内部声明的方法(studentdata()方法)访问,但是由于双下划线前缀使变量成为私有的,因此不允许从类外部访问它们,从而引发AttributeError。
Python不会完全阻止对私有数据的访问。它只是留给程序员的智慧,不要编写任何从类外部访问它的代码。您仍然可以通过Python的名称改编技术访问私有成员。
名称改编是将具有双下划线的成员名称更改为 object._class__variable 形式的过程。如果需要,仍然可以从类外部访问它,但应避免这种做法。
在我们的示例中,私有实例变量“__name”通过将其更改为以下格式来进行改编:
obj._class__privatevar
因此,要访问“s1”对象的“__marks”实例变量的值,将其更改为“s1._Student__marks”。
将上述程序中的 print() 语句更改为:
print (s1._Student__marks)
它现在打印50,即s1的分数。
因此,我们可以得出结论,Python并没有完全按照面向对象编程理论那样实现封装。它通过规定命名约定,并允许程序员在确实需要在公共作用域中访问私有数据时使用名称改编技术,从而采取了一种更成熟的方法。
Python - 接口
在软件工程中,接口是一种软件架构模式。接口类似于类,但其方法只有原型签名定义,没有任何实现主体。推荐的功能需要由具体的类来实现。
在Java等语言中,有interface关键字,这使得定义接口很容易。Python没有它或任何类似的关键字。因此,与抽象类一样,使用相同的ABC类和@abstractmethod装饰器。
抽象类和接口在Python中看起来很相似。两者之间唯一的区别在于抽象类可能有一些非抽象方法,而接口中的所有方法都必须是抽象的,并且实现类必须重写所有抽象方法。
示例
from abc import ABC, abstractmethod
class demoInterface(ABC):
@abstractmethod
def method1(self):
print ("Abstract method1")
return
@abstractmethod
def method2(self):
print ("Abstract method1")
return
上述接口有两个抽象方法。与抽象类一样,我们不能实例化接口。
obj = demoInterface()
^^^^^^^^^^^^^^^
TypeError: Can't instantiate abstract class demoInterface with abstract methods method1, method2
让我们提供一个实现这两个抽象方法的类。如果它不包含所有抽象方法的实现,Python会显示以下错误:
obj = concreteclass()
^^^^^^^^^^^^^^^
TypeError: Can't instantiate abstract class concreteclass with abstract method method2
以下类实现了这两种方法:
class concreteclass(demoInterface):
def method1(self):
print ("This is method1")
return
def method2(self):
print ("This is method2")
return
obj = concreteclass()
obj.method1()
obj.method2()
输出
执行此代码后,将产生以下输出:
This is method1 This is method2
Python - 包
在Python中,模块是一个带有.py扩展名的Python脚本,包含类、函数等对象。Python中的包进一步扩展了模块化方法的概念。包是一个包含一个或多个模块文件的文件夹;此外还有一个特殊的“__init__.py”文件,它可以为空,但可以包含包列表。
让我们创建一个名为mypackage的Python包。请按照以下步骤操作:
创建一个外部文件夹来保存mypackage的内容。让它的名字是packagedemo。
在其中,创建另一个文件夹mypackage。这将是我们即将构建的Python包。两个Python模块areafuntions.py和mathfunctions.py将创建在mypackage内部。
在mypackage文件夹内创建一个空的"__init__.py"文件。
稍后,我们将在外部文件夹中存储一个Python脚本example.py来测试我们的包。
文件/文件夹结构应如下所示:

使用您喜欢的代码编辑器,将以下两个Python模块保存到mypackage文件夹中。
# mathfunctions.py def sum(x,y): val = x+y return val def average(x,y): val = (x+y)/2 return val def power(x,y): val = x**y return val
创建另一个Python脚本:
# areafunctions.py def rectangle(w,h): area = w*h return area def circle(r): import math area = math.pi*math.pow(r,2) return area
现在让我们在该包文件夹上方的Python脚本的帮助下测试myexample包。请参考上面的文件夹结构。
#example.py
from mypackage.areafunctions import rectangle
print ("Area :", rectangle(10,20))
from mypackage.mathsfunctions import average
print ("average:", average(10,20))
此程序从mypackage导入函数。如果执行上述脚本,您应该得到以下输出:
Area : 200 average: 15.0
定义包列表
您可以将包中选择的函数或任何其他资源放入"__init__.py"文件中。让我们在其中放入以下代码。
from .areafunctions import circle from .mathsfunctions import sum, power
要从该包导入可用的函数,请将以下脚本保存为testpackage.py,与之前一样,保存在包文件夹上方。
#testpackage.py
from mypackage import power, circle
print ("Area of circle:", circle(5))
print ("10 raised to 2:", power(10,2))
它将产生以下**输出**:
Area of circle: 78.53981633974483 10 raised to 2: 100
包安装
现在,我们能够从包文件夹上方的脚本访问包资源。为了能够在文件系统的任何地方使用该包,您需要使用PIP实用程序安装它。
首先,将以下脚本保存在父文件夹中,位于包文件夹的级别。
#setup.py from setuptools import setup setup(name='mypackage', version='0.1', description='Package setup script', url='#', author='anonymous', author_email='test@gmail.com', license='MIT', packages=['mypackage'], zip_safe=False)
在命令提示符下运行PIP实用程序,同时停留在父文件夹中。
C:\Users\user\packagedemo>pip3 install . Processing c:\users\user\packagedemo Preparing metadata (setup.py) ... done Installing collected packages: mypackage Running setup.py install for mypackage ... done Successfully installed mypackage-0.1
您现在应该能够在任何环境中导入包的内容。
C:\Users>python Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import mypackage >>> mypackage.circle(5) 78.53981633974483
Python - 内部类
在Python中,在另一个类中定义的类称为内部类。有时内部类也称为嵌套类。如果实例化内部类,则父类也可以使用内部类的对象。内部类的对象成为外部类的属性之一。内部类自动继承外部类的属性,而无需正式建立继承关系。
语法
class outer:
def __init__(self):
pass
class inner:
def __init__(self):
pass
内部类允许您对类进行分组。嵌套类的优点之一是更容易理解哪些类是相关的。内部类具有局部作用域。它充当外部类的一个属性。
示例
在以下代码中,我们有student作为外部类,subjects作为内部类。student的__init__()构造函数初始化name属性和subjects类的实例。另一方面,内部subjects类的构造函数初始化两个实例变量sub1、sub2。
外部类的show()方法使用已实例化的对象调用内部类的方法。
class student:
def __init__(self):
self.name = "Ashish"
self.subs = self.subjects()
return
def show(self):
print ("Name:", self.name)
self.subs.display()
class subjects:
def __init__(self):
self.sub1 = "Phy"
self.sub2 = "Che"
return
def display(self):
print ("Subjects:",self.sub1, self.sub2)
s1 = student()
s1.show()
执行这段代码后,将产生以下输出:
Name: Ashish Subjects: Phy Che
完全可以独立声明外部类的对象,并使其调用它自己的display()方法。
sub = student().subjects().display()
它将列出科目。
Python - 匿名类和对象
Python的内置type()函数返回对象所属的类。在Python中,类(内置类或用户定义类)都是class类型的对象。
示例
class myclass:
def __init__(self):
self.myvar=10
return
obj = myclass()
print ('class of int', type(int))
print ('class of list', type(list))
print ('class of dict', type(dict))
print ('class of myclass', type(myclass))
print ('class of obj', type(obj))
它将产生以下**输出**:
class of int <class 'type'> class of list <class 'type'> class of dict <class 'type'> class of myclass <class 'type'>
type()具有以下三个参数的版本:
语法
newclass=type(name, bases, dict)
使用上述语法,可以动态创建类。三个函数类型参数为:
name - 类的名称,成为新类的__name__属性
bases - 包含父类的元组。如果不是派生类,则可以为空
dict - 形成新类命名空间的字典,包含属性、方法及其值。
我们可以使用上述版本的type()函数创建匿名类。name参数为空字符串,第二个参数是一个包含一个类object类的元组(请注意,Python中的每个类都继承自object类)。我们将某些实例变量添加到第三个参数字典中。现在我们暂时保持它为空。
anon=type('', (object, ), {})
要创建此匿名类的对象:
obj = anon()
print ("type of obj:", type(obj))
结果表明该对象是匿名类。
type of obj: <class '__main__.'>
示例
我们还可以动态添加实例变量和实例方法。请看这个例子:
def getA(self):
return self.a
obj = type('',(object,),{'a':5,'b':6,'c':7,'getA':getA,'getB':lambda self : self.b})()
print (obj.getA(), obj.getB())
它将产生以下**输出**:
5 6
Python - 单例类
单例类是一个只能创建一个对象的类。当您执行一些繁重的操作(例如创建数据库连接)时,这有助于优化内存使用。
示例
class SingletonClass:
_instance = None
def __new__(cls):
if cls._instance is None:
print('Creating the object')
cls._instance = super(SingletonClass, cls).__new__(cls)
return cls._instance
obj1 = SingletonClass()
print(obj1)
obj2 = SingletonClass()
print(obj2)
这就是上述代码的工作方式:
当声明Python类的实例时,它会在内部调用__new__()方法。我们重写了__new__()方法,该方法在创建类的对象时由Python内部调用。它检查我们的实例变量是否为None。如果实例变量为None,则创建一个新对象并调用super()方法,并返回包含此类对象的实例变量。
如果创建多个对象,则很明显该对象只在第一次创建;之后,将返回相同的对象实例。
Creating the object <__main__.SingletonClass object at 0x000002A5293A6B50> <__main__.SingletonClass object at 0x000002A5293A6B50>
Python - 包装器类
Python中的函数是一阶对象。函数可以将另一个函数作为其参数,并在其中包装另一个函数定义。这有助于修改函数而不实际更改它。这样的函数称为装饰器。
此功能也可用于包装类。此技术用于在通过包装其逻辑在装饰器内实例化类后管理类。
示例
def decorator_function(Wrapped):
class Wrapper:
def __init__(self,x):
self.wrap = Wrapped(x)
def print_name(self):
return self.wrap.name
return Wrapper
@decorator_function
class Wrapped:
def __init__(self,x):
self.name = x
obj = Wrapped('TutorialsPoint')
print(obj.print_name())
这里,Wrapped是要包装的类的名称。它作为参数传递给函数。在函数内部,我们有一个Wrapper类,使用传递类的属性修改其行为,并返回修改后的类。返回的类被实例化,现在可以调用其方法。
执行这段代码后,将产生以下输出:
TutorialsPoint
Python - 枚举
术语“枚举”是指为一组字符串分配固定常量值的过程,以便可以通过与其绑定的值来标识每个字符串。Python 的标准库提供了enum模块。enum模块中包含的Enum类用作父类来定义一组标识符的枚举——通常以大写形式编写。
示例1
from enum import Enum class subjects(Enum): ENGLISH = 1 MATHS = 2 SCIENCE = 3 SANSKRIT = 4
在上面的代码中,“subjects”是枚举。它具有不同的枚举成员,例如,subjects.MATHS。每个成员都分配了一个值。
每个成员都是枚举类subjects的一个对象,并且具有name和value属性。
obj = subjects.MATHS print (type(obj), obj.value)
结果如下所示输出−
<enum 'subjects'> 2
示例2
与枚举成员绑定的值不一定是整数,也可以是字符串。请参见以下示例−
from enum import Enum class subjects(Enum): ENGLISH = "E" MATHS = "M" GEOGRAPHY = "G" SANSKRIT = "S" obj = subjects.SANSKRIT print (type(obj), obj.name, obj.value)
它将产生以下**输出**:
<enum 'subjects'> SANSKRIT S
示例3
您可以使用for循环按其在定义中出现的顺序迭代枚举成员−
for sub in subjects: print (sub.name, sub.value)
它将产生以下**输出**:
ENGLISH E MATHS M GEOGRAPHY G SANSKRIT S
可以通过分配给它的唯一值或通过其name属性访问枚举成员。因此,subjects("E")以及subjects["ENGLISH"]都返回subjects.ENGLISH成员。
示例 4
枚举类不能出现相同的成员两次,但是可以为多个成员分配相同的值。为了确保每个成员都有一个唯一的值与其绑定,请使用@unique装饰器。
from enum import Enum, unique @unique class subjects(Enum): ENGLISH = 1 MATHS = 2 GEOGRAPHY = 3 SANSKRIT = 2
这将引发如下异常−
@unique
^^^^^^
raise ValueError('duplicate values found in %r: %s' %
ValueError: duplicate values found in <enum 'subjects'>: SANSKRIT -> MATHS
Enum类是一个可调用类,因此您可以使用以下定义枚举的替代方法−
from enum import Enum
subjects = Enum("subjects", "ENGLISH MATHS SCIENCE SANSKRIT")
Enum构造函数在此处使用两个参数。第一个是枚举的名称。第二个参数是一个字符串,其中包含枚举成员符号名称,用空格分隔。
Python - 反射
在面向对象编程中,反射是指提取有关任何正在使用的对象的信息的能力。您可以了解对象的类型,它是否是任何其他类的子类,它的属性是什么等等。Python 的标准库有很多函数可以反映对象的不同属性。反射有时也称为内省。
让我们回顾一下反射函数。
type() 函数
我们已经多次使用过这个函数。它会告诉你一个对象属于哪个类。
示例
以下语句打印不同内置数据类型对象的相应类
print (type(10))
print (type(2.56))
print (type(2+3j))
print (type("Hello World"))
print (type([1,2,3]))
print (type({1:'one', 2:'two'}))
在这里,您将得到以下输出:
<class 'int'> <class 'float'> <class 'complex'> <class 'str'> <class 'list'> <class 'dict'>
让我们验证用户定义类对象的类型−
class test: pass obj = test() print (type(obj))
它将产生以下**输出**:
<class '__main__.test'>
isinstance() 函数
这是 Python 中的另一个内置函数,它确定一个对象是否是给定类的实例
语法
isinstance(obj, class)
此函数始终返回布尔值,如果对象确实属于给定类,则返回 true,否则返回 false。
示例
以下语句返回 True −
print (isinstance(10, int))
print (isinstance(2.56, float))
print (isinstance(2+3j, complex))
print (isinstance("Hello World", str))
相反,这些语句打印 False。
print (isinstance([1,2,3], tuple))
print (isinstance({1:'one', 2:'two'}, set))
它将产生以下**输出**:
True True True True False False
您也可以使用用户定义的类执行检查
class test: pass obj = test() print (isinstance(obj, test))
它将产生以下**输出**:
True
在 Python 中,即使类也是对象。所有类都是 object 类的对象。可以通过以下代码验证−
class test: pass print (isinstance(int, object)) print (isinstance(str, object)) print (isinstance(test, object))
以上所有打印语句都打印 True。
issubclass() 函数
此函数检查一个类是否是另一个类的子类。适用于类,不适用于它们的实例。
如前所述,所有 Python 类都是从 object 类继承的。因此,以下打印语句的输出对于所有情况都是 True。
class test: pass print (issubclass(int, object)) print (issubclass(str, object)) print (issubclass(test, object))
它将产生以下**输出**:
True True True
callable() 函数
如果对象调用某个过程,则该对象是可调用的。Python 函数执行某个过程,是一个可调用对象。因此 callable(function) 返回 True。任何函数,内置函数、用户定义函数或方法都是可调用的。内置数据类型(如 int、str 等)的对象不可调用。
示例
def test():
pass
print (callable("Hello"))
print (callable(abs))
print (callable(list.clear([1,2])))
print (callable(test))
字符串对象不可调用。但 abs 是一个可调用的函数。list 的 pop 方法是可调用的,但 clear() 实际上是对函数的调用,而不是函数对象,因此不可调用
它将产生以下**输出**:
False True True False True
如果类实例具有 __call__() 方法,则它是可调用的。在下面的示例中,test 类包含 __call__() 方法。因此,它的对象可以像调用函数一样使用。因此,具有 __call__() 函数的类的对象是可调用的。
class test:
def __init__(self):
pass
def __call__(self):
print ("Hello")
obj = test()
obj()
print ("obj is callable?", callable(obj))
它将产生以下**输出**:
Hello obj is callable? True
getattr() 函数
内置函数 getattr() 检索对象的命名属性的值。
示例
class test:
def __init__(self):
self.name = "Manav"
obj = test()
print (getattr(obj, "name"))
它将产生以下**输出**:
Manav
setattr() 函数
内置函数 setattr() 为对象添加一个新属性并为其赋值。它还可以更改现有属性的值。
在下面的示例中,test 类对象只有一个属性 - name。我们使用 setattr 添加 age 属性并修改 name 属性的值。
class test:
def __init__(self):
self.name = "Manav"
obj = test()
setattr(obj, "age", 20)
setattr(obj, "name", "Madhav")
print (obj.name, obj.age)
它将产生以下**输出**:
Madhav 20
hasattr() 函数
此内置函数如果给定属性可用于对象参数,则返回 True,否则返回 false。我们使用相同的 test 类并检查它是否具有某个属性。
class test:
def __init__(self):
self.name = "Manav"
obj = test()
print (hasattr(obj, "age"))
print (hasattr(obj, "name"))
它将产生以下**输出**:
False True
dir() 函数
如果此内置函数没有参数调用,则返回当前作用域中的名称。对于任何对象作为参数,它都会返回给定对象的属性列表,以及从中可以访问的属性。
对于模块对象 - 该函数返回模块的属性。
对于类对象 - 该函数返回其属性,并递归返回其基类的属性。
对于任何其他对象 - 其属性、其类的属性以及其类的基类的属性(递归)。
示例
print ("dir(int):", dir(int))
它将产生以下**输出**:
dir(int): ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
示例
print ("dir(dict):", dir(dict))
它将产生以下**输出**:
dir(dict): ['__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__ior__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__ror__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
示例
class test:
def __init__(self):
self.name = "Manav"
obj = test()
print ("dir(obj):", dir(obj))
它将产生以下**输出**:
dir(obj): ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name']
Python - 语法错误
通常,计算机程序中会出现三种类型的错误:语法错误、逻辑错误和运行时错误。语法错误是编写程序时遇到的最常见类型的错误,无论您是编程新手还是经验丰富的程序员。语法错误基本上与某种语言的语法规则有关。
每当不遵循语言规定的规则时,就会发生语法错误。在 Python 中,为标识符命名有明确的规则,即变量、函数、类、模块或任何 Python 对象。同样,应根据定义的语法使用 Python 关键字。每当不遵循这些规则时,Python 解释器都会显示语法错误消息。
下面给出了在 Python 交互式 shell 中声明变量的一个简单示例。
>>> name="Python
File "<stdin>", line 1
name="Python
^
SyntaxError: unterminated string literal (detected at line 1)
Python 解释器显示语法错误以及某些解释性消息。在上面的示例中,由于引号符号未关闭,因此发生语法错误。
同样,Python 要求每个函数名称后面都应跟括号,在括号内应给出函数参数。
在以下示例中,我们得到一个语法错误−
>>> print "Hello"
File "<stdin>", line 1
print "Hello"
^^^^^^^^^^^^^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print(...)?
原因可以从错误消息中理解,即 print() 函数缺少括号。
Python 编程有很多流行的 IDE。它们中的大多数都使用彩色语法突出显示,这使得很容易直观地识别错误。
VS Code 就是这样的 IDE 之一。在输入指令时,语法错误会适当地突出显示。
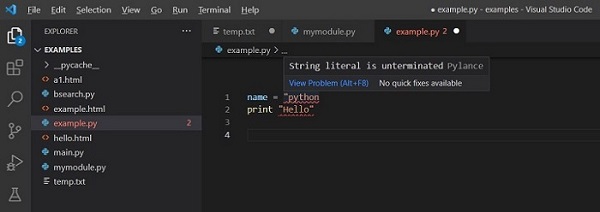
错误已突出显示。如果您将光标放在那里,VS Code 会提供有关错误的更多信息。如果您仍然继续执行代码,则错误消息将出现在命令终端中。
语法错误很容易识别和纠正。像 VS Code 这样的 IDE 使其变得容易。但是,有时,您的代码不会显示任何语法错误,但程序的输出仍然不是您预期的结果。这种错误是逻辑错误。它们很难检测到,因为错误在于代码中使用的逻辑。您会通过经验学习如何纠正逻辑错误。VS Code 和其他 IDE 具有监视和断点等功能来捕获这些错误。
第三种类型的错误是运行时错误,也称为异常。您的程序中没有任何语法错误,也没有任何逻辑错误。大多数情况下,程序会给出预期的输出,但在某些特定情况下,您会得到程序的异常行为,例如程序异常终止或给出一些荒谬的结果。
导致异常的因素通常是程序外部的。例如,错误的输入、类型转换或 IO 设备故障等。
什么是异常?
异常是在程序执行期间发生的事件,它会中断程序指令的正常流程。通常,当 Python 脚本遇到无法处理的情况时,它会引发异常。异常是一个表示错误的 Python 对象。
当 Python 脚本引发异常时,它必须立即处理异常,否则它将终止并退出。
Python 的标准库定义了标准异常类。与其他 Python 类一样,异常也是 Object 类的子类。以下是 Python 异常的对象层次结构。
object
BaseException
Exception
ArithmeticError
FloatingPointError
OverflowError
ZeroDivisionError
AssertionError
AttributeError
BufferError
EOFError
ImportError
ModuleNotFoundError
LookupError
IndexError
KeyError
MemoryError
NameError
OSError
ReferenceError
RuntimeError
StopAsyncIteration
StopIteration
SyntaxError
Python - 异常处理
如果您有一些可能引发异常的可疑代码,您可以通过将可疑代码放在try: 块中来保护您的程序。在try: 块之后,包括一个except: 语句,然后是一个尽可能优雅地处理问题的代码块。
try: 块包含可能出现异常的语句
如果发生异常,程序将跳转到except: 块。
如果try: 块中没有异常,则跳过except: 块。
语法
这是try...except...else块的简单语法−
try: You do your operations here ...................... except ExceptionI: If there is ExceptionI, then execute this block. except ExceptionII: If there is ExceptionII, then execute this block. ...................... else: If there is no exception then execute this block.
以下是一些关于上述语法的要点−
单个try语句可以有多个except语句。当try块包含可能抛出不同类型异常的语句时,这很有用。
您还可以提供一个泛型except子句,该子句处理任何异常。
在except子句之后,您可以包含一个else子句。如果try:块中的代码没有引发异常,则执行else块中的代码。
else块非常适合不需要try:块保护的代码。
示例
此示例打开一个文件,在文件中写入内容并优雅地退出,因为根本没有任何问题。
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
except IOError:
print ("Error: can\'t find file or read data")
else:
print ("Written content in the file successfully")
fh.close()
它将产生以下**输出**:
Written content in the file successfully
但是,将open()函数中的mode参数更改为“w”。如果testfile不存在,程序会在except块中遇到IOError,并打印以下错误消息−
Error: can't find file or read data
Python - try-except 代码块
你也可以使用没有定义异常的except语句,如下所示:
try: You do your operations here ...................... except: If there is any exception, then execute this block. ...................... else: If there is no exception then execute this block.
这种 try-except 语句会捕获所有发生的异常。但是,这种 try-except 语句不被认为是良好的编程实践,因为它捕获所有异常,但不会让程序员识别可能出现问题的根本原因。
你也可以使用相同的 except 语句来处理多个异常,如下所示:
try: You do your operations here ...................... except(Exception1[, Exception2[,...ExceptionN]]]): If there is any exception from the given exception list, then execute this block. ...................... else: If there is no exception then execute this block.
Python - try-finally 代码块
你可以将finally: 代码块与try: 代码块一起使用。finally: 代码块用于放置必须执行的任何代码,无论 try 代码块是否引发异常。
try-finally 语句的语法如下所示:
try: You do your operations here; ...................... Due to any exception, this may be skipped. finally: This would always be executed. ......................
注意 - 你可以提供 except 子句或 finally 子句,但不能同时提供两者。你也不可以在 finally 子句中使用 else 子句。
示例
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
finally:
print ("Error: can\'t find file or read data")
fh.close()
如果你没有权限以写入模式打开文件,则会产生以下输出:
Error: can't find file or read data
同样的例子可以更简洁地写成如下:
try:
fh = open("testfile", "w")
try:
fh.write("This is my test file for exception handling!!")
finally:
print ("Going to close the file")
fh.close()
except IOError:
print ("Error: can\'t find file or read data")
当 try 代码块中抛出异常时,执行会立即传递到finally代码块。在finally代码块中的所有语句执行完毕后,异常将再次被抛出,如果在 try-except 语句的上一层存在 except 语句,则会在其中处理该异常。
带有参数的异常
异常可以有一个参数,该参数是一个值,提供关于问题的更多信息。参数的内容因异常而异。你可以通过在 except 子句中提供一个变量来捕获异常的参数,如下所示:
try: You do your operations here ...................... except ExceptionType as Argument: You can print value of Argument here...
如果你编写代码来处理单个异常,你可以在 except 语句中在异常名称后面添加一个变量。如果你要捕获多个异常,你可以在异常元组后面添加一个变量。
此变量接收异常的值,其中主要包含异常的原因。该变量可以接收单个值或多个值(以元组的形式)。此元组通常包含错误字符串、错误号和错误位置。
示例
以下是单个异常的示例:
# Define a function here.
def temp_convert(var):
try:
return int(var)
except ValueError as Argument:
print("The argument does not contain numbers\n",Argument)
# Call above function here.
temp_convert("xyz")
它将产生以下**输出**:
The argument does not contain numbers invalid literal for int() with base 10: 'xyz'
Python - 抛出异常
你可以通过使用 raise 语句以几种方式引发异常。raise 语句的通用语法如下所示:
语法
raise [Exception [, args [, traceback]]]
这里,Exception 是异常的类型(例如,NameError),argument 是异常参数的值。参数是可选的;如果不提供,则异常参数为 None。
最后一个参数 traceback 也是可选的(在实践中很少使用),如果存在,则是用于异常的 traceback 对象。
示例
异常可以是字符串、类或对象。Python 核心引发的多数异常都是类,其参数是该类的实例。定义新的异常非常容易,可以按如下方式完成:
def functionName( level ):
if level <1:
raise Exception(level)
# The code below to this would not be executed
# if we raise the exception
return level
注意 - 为了捕获异常,“except”子句必须引用以类对象或简单字符串形式抛出的相同异常。例如,要捕获上述异常,我们必须按如下方式编写 except 子句:
try: Business Logic here... except Exception as e: Exception handling here using e.args... else: Rest of the code here...
以下示例说明了引发异常的使用:
def functionName( level ):
if level <1:
raise Exception(level)
# The code below to this would not be executed
# if we raise the exception
return level
try:
l=functionName(-10)
print ("level=",l)
except Exception as e:
print ("error in level argument",e.args[0])
这将产生以下输出:
error in level argument -10
Python - 异常链
异常链是一种通过在将捕获的异常包装在新异常中后重新抛出该异常来处理异常的技术。原始异常被保存为新异常的属性(例如 cause)。
在处理一个异常“A”的过程中,可能会发生另一个异常“B”。为了调试问题,了解这两个异常都很有用。有时,异常处理程序故意重新引发异常很有用,这样做是为了提供额外信息或将异常转换为另一种类型。
在 Python 3.x 中,可以实现异常链。如果 except 部分中存在任何未处理的异常,则该异常将附加到正在处理的异常中,并包含在错误消息中。
示例
在以下代码片段中,尝试打开不存在的文件会引发 FileNotFoundError。except 块会检测到它。在处理时,会引发另一个异常。
try:
open("nofile.txt")
except OSError:
raise RuntimeError("unable to handle error")
它将产生以下**输出**:
Traceback (most recent call last):
File "/home/cg/root/64afcad39c651/main.py", line 2, in <module>
open("nofile.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'nofile.txt'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/cg/root/64afcad39c651/main.py", line 4, in <module>
raise RuntimeError("unable to handle error")
RuntimeError: unable to handle error
raise . . from
如果你在 raise 语句中使用可选的 from 子句,则表示异常是另一个异常的直接结果。当转换异常时,这可能很有用。from 关键字后的标记应为异常对象。
try:
open("nofile.txt")
except OSError as exc:
raise RuntimeError from exc
它将产生以下**输出**:
Traceback (most recent call last):
File "/home/cg/root/64afcad39c651/main.py", line 2, in <module>
open("nofile.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'nofile.txt'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/cg/root/64afcad39c651/main.py", line 4, in <module>
raise RuntimeError from exc
RuntimeError
raise . . from None
如果在 from 子句中使用 None 而不是异常对象,则会禁用在前面示例中找到的自动异常链。
try:
open("nofile.txt")
except OSError as exc:
raise RuntimeError from None
它将产生以下**输出**:
Traceback (most recent call last): File "C:\Python311\hello.py", line 4, in <module> raise RuntimeError from None RuntimeError
__context__ 和 __cause__
在 except 块中引发异常会自动将捕获的异常添加到新异常的 __context__ 属性。同样,你也可以使用表达式raise ... from语法将 __cause__ 添加到任何异常。
try:
try:
raise ValueError("ValueError")
except ValueError as e1:
raise TypeError("TypeError") from e1
except TypeError as e2:
print("The exception was", repr(e2))
print("Its __context__ was", repr(e2.__context__))
print("Its __cause__ was", repr(e2.__cause__))
它将产生以下**输出**:
The exception was TypeError('TypeError')
Its __context__ was ValueError('ValueError')
Its __cause__ was ValueError('ValueError')
Python - 嵌套 try 块
在 Python 程序中,如果在try块或其except块内存在另一个try-except结构,则称为嵌套 try 块。当外部块和内部块可能导致不同的错误时,需要这样做。为了处理它们,我们需要嵌套 try 块。
我们从具有单个“try - except - finally”结构的示例开始。如果 try 内部的语句遇到异常,则由 except 块处理。无论是否发生异常,finally 块始终都会执行。
示例1
这里,try块存在“除以 0”的情况,因此except块开始发挥作用。它配备了使用 Exception 类处理通用异常的功能。
a=10
b=0
try:
print (a/b)
except Exception:
print ("General Exception")
finally:
print ("inside outer finally block")
它将产生以下**输出**:
General Exception inside outer finally block
示例2
现在让我们看看如何嵌套try结构。我们将另一个“try - except - finally”块放在现有的 try 块内。内部 try 的 except 关键字现在处理通用 Exception,而我们要求外部 try 的 except 块处理 ZeroDivisionError。
由于内部try块中没有发生异常,因此不会调用其相应的通用 Except。除以 0 的情况由外部 except 子句处理。
a=10
b=0
try:
print (a/b)
try:
print ("This is inner try block")
except Exception:
print ("General exception")
finally:
print ("inside inner finally block")
except ZeroDivisionError:
print ("Division by 0")
finally:
print ("inside outer finally block")
它将产生以下**输出**:
Division by 0 inside outer finally block
示例3
现在我们反转一下情况。在嵌套的try块中,外部块没有引发任何异常,但导致除以 0 的语句在内部 try 中,因此异常由内部except块处理。显然,对应于外部try: 的except部分不会被调用。
a=10
b=0
try:
print ("This is outer try block")
try:
print (a/b)
except ZeroDivisionError:
print ("Division by 0")
finally:
print ("inside inner finally block")
except Exception:
print ("General Exception")
finally:
print ("inside outer finally block")
它将产生以下**输出**:
This is outer try block Division by 0 inside inner finally block inside outer finally block
最后,让我们讨论一下嵌套块中可能发生的另一种情况。虽然外部try: 中没有任何异常,但没有合适的 except 块来处理内部try: 块中的异常。
示例 4
在以下示例中,内部try: 遇到“除以 0”,但其对应的 except: 正在查找 KeyError 而不是 ZeroDivisionError。因此,异常对象被传递到后续 except 语句的 except: 块,该语句与外部 try: 语句匹配。在那里,zeroDivisionError 异常被捕获并处理。
a=10
b=0
try:
print ("This is outer try block")
try:
print (a/b)
except KeyError:
print ("Key Error")
finally:
print ("inside inner finally block")
except ZeroDivisionError:
print ("Division by 0")
finally:
print ("inside outer finally block")
它将产生以下**输出**:
This is outer try block inside inner finally block Division by 0 inside outer finally block
Python - 用户自定义异常
Python 还允许你通过从标准内置异常派生类来创建你自己的异常。
这是一个包含用户定义的 MyException 类的示例。这里,创建了一个从基类 Exception 类继承的类。当你需要在捕获异常时显示更具体的信时,这非常有用。
在try块中,每当 num 变量的值小于 0 或大于 100 时,都会引发用户定义的异常,并在except块中捕获。变量 e 用于创建 MyException 类的实例。
示例
class MyException(Exception):
"Invalid marks"
pass
num = 10
try:
if num <0 or num>100:
raise MyException
except MyException as e:
print ("Invalid marks:", num)
else:
print ("Marks obtained:", num)
输出
对于不同的num值,程序显示以下输出:
Marks obtained: 10 Invalid marks: 104 Invalid marks: -10
Python - 日志记录
术语“日志记录”指的是记录某个过程中不同中间事件的机制。在软件应用程序中记录日志有助于开发人员调试和跟踪应用程序逻辑中的任何错误。Python 的标准库包含 logging 模块,可以使用该模块生成和记录应用程序日志。
在程序中间歇性地使用 print() 语句来检查不同变量和对象的中值是一种常见做法。它有助于开发人员验证程序是否按预期运行。但是,日志记录比间歇性 print 语句更有益,因为它提供了对事件的更多洞察。
日志级别
日志记录的一个重要功能是你可以生成不同严重性级别的日志消息。logging 模块定义了以下级别及其值。
| 级别 | 使用时间 | 值 |
|---|---|---|
DEBUG |
详细信息,通常仅在诊断问题时才感兴趣。 |
10 |
INFO |
确认事情按预期工作。 |
20 |
WARNING |
表明发生了意外情况,或表明不久的将来会出现某些问题(例如,“磁盘空间不足”)。软件仍在按预期工作。 |
30 |
ERROR |
由于更严重的问题,软件无法执行某些功能。 |
40 |
CRITICAL |
严重错误,表明程序本身可能无法继续运行。 |
50 |
示例
以下代码说明了如何生成日志消息。
import logging
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
它将产生以下**输出**:
WARNING:root:This is a warning message ERROR:root:This is an error message CRITICAL:root:This is a critical message
请注意,此处仅显示 WARNING 级别后的日志消息。这是因为 root(默认记录器)忽略所有高于 WARNING 严重性级别的严重性级别。请注意,严重性级别记录在每一行的第一个冒号 (:) 之前。同样,root 也是显示在 LogRecord 中的记录器的名称。
日志记录配置
可以使用 BasicConfig() 方法自定义程序生成的日志。你可以定义一个或多个以下参数进行配置:
filename - 指定创建 FileHandler,使用指定的 filename,而不是 StreamHandler。
filemode - 如果指定了 filename,则以这种模式打开文件。默认为 'a'。
datefmt - 使用指定的日期/时间格式,time.strftime() 接受。
style - 如果指定了 format,则对格式字符串使用此样式。分别是 printf 样式、str.format() 或 string.Template 的 '%', '{' 或 '$' 之一。默认为 '%'。
level - 将根记录器级别设置为指定的级别。
错误处理 (errors) − 如果此关键字参数与文件名一起指定,则在创建 FileHandler 时使用其值,并在打开输出文件时使用。如果未指定,则使用值“backslashreplace”。请注意,如果指定 None,则会将其原样传递给 open(),这意味着它将与传递“errors”相同。
示例
要记录 DEBUG 级别以上的所有消息,请将 level 参数设置为 logging.DEBUG。
import logging
logging.basicConfig(level=logging.DEBUG)
logging.debug('This message will get logged')
它将产生以下**输出**:
DEBUG:root:This message will get logged
要将日志消息记录到文件而不是在控制台上回显它们,请使用 filename 参数。
import logging
logging.basicConfig(filename='logs.txt', filemode='w', level=logging.DEBUG)
logging.warning('This messagewill be saved to a file')
控制台上不会显示任何输出。但是,在当前目录中创建了一个 logs.txt 文件,其中包含文本 WARNING:root:This message will be saved to a file。
日志消息中的变量数据
大多数情况下,您希望在日志消息中包含一个或多个变量的值,以便更好地了解应用程序运行时生成的错误原因。为此,可以使用任何动态字符串格式化技术,例如str类的 format() 方法或 f-字符串。
示例
import logging
logging.basicConfig(level=logging.DEBUG)
marks = 120
logging.error("Invalid marks:{} Marks must be between 0 to 100".format(marks))
subjects = ["Phy", "Maths"]
logging.warning("Number of subjects: {}. Should be at least three".format(len(subjects)))
它将产生以下**输出**:
ERROR:root:Invalid marks:120 Marks must be between 0 to 100 WARNING:root:Number of subjects: 2. Should be at least three
Python - 断言
断言是一种健全性检查,您可以在完成程序测试后将其打开或关闭。
最简单的理解断言的方法是将其比作 raise-if 语句(或者更准确地说,是 raise-if-not 语句)。测试一个表达式,如果结果为假,则引发异常。
断言由 assert 语句执行,这是 Python 中最新引入的关键字,在 1.5 版本中引入。
程序员通常在函数开始时放置断言以检查有效输入,并在函数调用后检查有效输出。
assert 语句
当遇到 assert 语句时,Python 会评估伴随的表达式,该表达式应该为真。如果表达式为假,Python 将引发 AssertionError 异常。
assert 的语法为:
assert Expression[, Arguments]
如果断言失败,Python 使用 ArgumentExpression 作为 AssertionError 的参数。可以使用 try-except 语句捕获和处理 AssertionError 异常,就像处理任何其他异常一样。如果未处理它们,它们将终止程序并产生回溯。
示例
print ('enter marks out of 100')
num=75
assert num>=0 and num<=100
print ('marks obtained: ', num)
num=125
assert num>=0 and num<=100
print ('marks obtained: ', num)
它将产生以下**输出**:
enter marks out of 100
marks obtained: 75
Traceback (most recent call last):
File "C:\Users\user\example.py", line 7, in <module>
assert num>=0 and num<=100
^^^^^^^^
AssertionError
要显示自定义错误消息,请在 assert 语句中的表达式后添加一个字符串:
assert num>=0 and num<=100, "only numbers in 0-100 accepted"
AssertionError 也是一个内置异常。因此它可以用作 except 块中的参数。当输入导致 AssertionError 异常时,它将由 except 块处理。except 块将 assert 语句中的字符串视为异常对象。
try:
num=int(input('enter a number'))
assert (num >=0), "only non negative numbers accepted"
print (num)
except AssertionError as msg:
print (msg)
Python - 内置异常
以下是 Python 中可用的标准异常列表:
| 序号 | 异常名称和描述 |
|---|---|
| 1 | 异常 所有异常的基类 |
| 2 | StopIteration 当迭代器的 next() 方法不指向任何对象时引发。 |
| 3 | SystemExit 由 sys.exit() 函数引发。 |
| 4 | StandardError 除 StopIteration 和 SystemExit 之外,所有内置异常的基类。 |
| 5 | ArithmeticError 所有针对数字计算发生的错误的基类。 |
| 6 | OverflowError 当计算超过数字类型的最大限制时引发。 |
| 7 | FloatingPointError 当浮点计算失败时引发。 |
| 8 | ZeroDivisionError 当对所有数字类型进行零除或模运算时引发。 |
| 9 | AssertionError 在 Assert 语句失败的情况下引发。 |
| 10 | AttributeError 在属性引用或赋值失败的情况下引发。 |
| 11 | EOFError 当 raw_input() 或 input() 函数没有输入并且达到文件结尾时引发。 |
| 12 | ImportError 当 import 语句失败时引发。 |
| 13 | KeyboardInterrupt 当用户中断程序执行时引发,通常是通过按 Ctrl+C。 |
| 14 | LookupError 所有查找错误的基类。 |
| 15 | IndexError 当在序列中找不到索引时引发。 |
| 16 | KeyError 当在字典中找不到指定的键时引发。 |
| 17 | NameError 当在本地或全局命名空间中找不到标识符时引发。 |
| 18 | UnboundLocalError 当尝试访问函数或方法中的局部变量但尚未为其赋值时引发。 |
| 19 | EnvironmentError 所有在 Python 环境之外发生的异常的基类。 |
| 20 | IOError 当输入/输出操作失败时引发,例如 print 语句或 open() 函数在尝试打开不存在的文件时。 |
| 21 | OSError 针对与操作系统相关的错误引发。 |
| 22 | SyntaxError 当 Python 语法中存在错误时引发。 |
| 23 | IndentationError 当缩进未正确指定时引发。 |
| 24 | SystemError 当解释器发现内部问题时引发,但是当遇到此错误时,Python 解释器不会退出。 |
| 25 | SystemExit 当使用 sys.exit() 函数退出 Python 解释器时引发。如果代码中未处理,则会导致解释器退出。 |
| 26 | TypeError 当尝试对指定数据类型无效的操作或函数时引发。 |
| 27 | ValueError 当数据类型的内置函数具有有效的参数类型,但参数具有无效的值时引发。 |
| 28 | RuntimeError 当生成的错误不属于任何类别时引发。 |
| 29 | NotImplementedError 当需要在继承类中实现的抽象方法实际上未实现时引发。 |
以下是一些标准异常示例:
IndexError
尝试访问无效索引处的项目时显示。
numbers=[10,20,30,40] for n in range(5): print (numbers[n])
它将产生以下**输出**:
10 20 30 40 Traceback (most recent call last): print (numbers[n]) IndexError: list index out of range
ModuleNotFoundError
当找不到模块时显示。
import notamodule Traceback (most recent call last): import notamodule ModuleNotFoundError: No module named 'notamodule'
KeyError
当找不到字典键时发生。
D1={'1':"aa", '2':"bb", '3':"cc"}
print ( D1['4'])
Traceback (most recent call last):
D1['4']
KeyError: '4'
ImportError
当指定的函数不可导入时显示。
from math import cube Traceback (most recent call last): from math import cube ImportError: cannot import name 'cube'
StopIteration
当迭代器流耗尽后调用 next() 函数时出现此错误。
.it=iter([1,2,3]) next(it) next(it) next(it) next(it) Traceback (most recent call last): next(it) StopIteration
TypeError
当运算符或函数应用于不合适的类型的对象时显示。
print ('2'+2)
Traceback (most recent call last):
'2'+2
TypeError: must be str, not int
ValueError
当函数的参数类型不合适时显示。
print (int('xyz'))
Traceback (most recent call last):
int('xyz')
ValueError: invalid literal for int() with base 10: 'xyz'
NameError
当找不到对象时遇到此错误。
print (age) Traceback (most recent call last): age NameError: name 'age' is not defined
ZeroDivisionError
当除法中的第二个运算数为零时显示。
x=100/0 Traceback (most recent call last): x=100/0 ZeroDivisionError: division by zero
KeyboardInterrupt
当用户在程序执行期间按下中断键(通常是 Control-C)时。
name=input('enter your name')
enter your name^c
Traceback (most recent call last):
name=input('enter your name')
KeyboardInterrupt
Python - 多线程
默认情况下,计算机程序以顺序方式执行指令,从开始到结束。多线程是指将主要任务划分为多个子任务并以重叠方式执行它们的机制。这使得执行速度比单线程更快。
操作系统能够并发处理多个进程。它为每个进程分配单独的内存空间,这样一来,一个进程就不能访问或写入其他进程的空间。另一方面,线程可以被认为是单个程序中的轻量级子进程。单个程序的线程共享分配给它的内存空间。
进程内的多个线程与主线程共享相同的数 据空间,因此可以比单独的进程更容易地共享信息或彼此通信。
由于它们是轻量级的,不需要大量的内存开销;它们比进程更便宜。
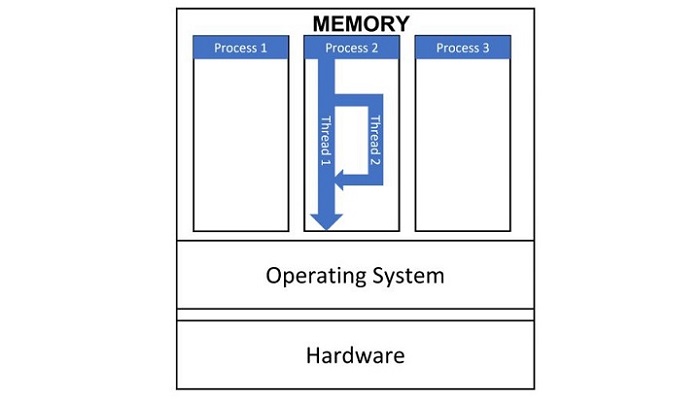
进程总是从单个线程(主线程)开始。根据需要,可以启动新线程并将子任务委派给它。现在这两个线程以重叠的方式工作。当分配给辅助线程的任务结束后,它与主线程合并。
Python - 线程生命周期
线程对象会经历不同的阶段。创建新的线程对象后,必须启动它。这将调用线程类的 run() 方法。此方法包含新线程要执行的进程的逻辑。当 run() 方法结束时,线程完成其任务,新创建的线程与主线程合并。
线程运行时,可以将其暂停预定义的时间段,或者可以要求其暂停直到发生某个事件。在指定的时间间隔或进程结束后,线程恢复。
Python 的标准库包含两个模块,“_thread”和“threading”,它们包含处理线程的功能。“_thread”模块是一个低级 API。在 Python 3 中,包含了threading 模块,它提供了更全面的线程管理功能。
Python _thread 模块
_thread 模块(之前的thread模块)自 2.0 版以来一直是 Python 标准库的一部分。它是一个用于线程管理的低级 API,并作为许多其他具有高级并发执行功能(如 threading 和 multiprocessing)的模块的支持。
Python - threading 模块
较新的 threading 模块提供了更强大、更高级别的线程管理支持。
Thread 类表示在单独的控制线程中运行的活动。有两种方法可以指定活动:通过将可调用对象传递给构造函数,或者通过在子类中覆盖 run() 方法。
threading.Thread(target, name, args, kwarg, daemon)
参数
target − 当新线程启动时要调用的函数。默认为 None,这意味着不调用任何内容。
name − 是线程名称。默认情况下,会构造一个唯一的名称,例如“Thread-N”。
daemon − 如果设置为 True,则新线程在后台运行。
args 和 kwargs − 要传递给目标函数的可选参数。
Python - 创建线程
_thread 模块中包含的start_new_thread()函数用于在正在运行的程序中创建新线程。
语法
_thread.start_new_thread ( function, args[, kwargs] )
此函数启动一个新线程并返回其标识符。
参数
function − 新创建的线程开始运行并调用指定的函数。如果函数需要任何参数,则可以将其作为参数 args 和 kwargs 传递。
示例
import _thread
import time
# Define a function for the thread
def thread_task( threadName, delay):
for count in range(1, 6):
time.sleep(delay)
print ("Thread name: {} Count: {}".format ( threadName, count ))
# Create two threads as follows
try:
_thread.start_new_thread( thread_task, ("Thread-1", 2, ) )
_thread.start_new_thread( thread_task, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while True:
pass
它将产生以下**输出**:
Thread name: Thread-1 Count: 1 Thread name: Thread-2 Count: 1 Thread name: Thread-1 Count: 2 Thread name: Thread-1 Count: 3 Thread name: Thread-2 Count: 2 Thread name: Thread-1 Count: 4 Thread name: Thread-1 Count: 5 Thread name: Thread-2 Count: 3 Thread name: Thread-2 Count: 4 Thread name: Thread-2 Count: 5 Traceback (most recent call last): File "C:\Users\user\example.py", line 17, in <module> while True: KeyboardInterrupt
程序进入无限循环。您必须按“ctrl-c”才能停止。
Python - 启动线程
此 start() 方法启动线程的活动。创建线程对象后必须调用一次此方法。
start() 方法会自动在单独的线程中调用对象的 run() 方法。但是,如果调用此方法多次,则会引发 RuntimeError。
语法
以下是使用 start() 方法启动线程的语法:
threading.thread.start()
示例
请看下面的例子:
thread1 = myThread("Thread-1")
# Start new Thread
thread1.start()
这会自动调用 run() 方法。
run() 方法
run() 方法表示线程的活动。可以在子类中覆盖它。对象不会调用标准 run() 方法,而是调用作为目标参数传递给其构造函数的函数。
Python - 合并线程
线程类中的 join() 方法会阻塞调用线程,直到调用其 join() 方法的线程终止。终止可能是正常的,也可能是由于未处理的异常导致的——或者直到可选的超时发生。它可以被多次调用。如果尝试加入当前线程,则 join() 会引发 RuntimeError 异常。在线程启动之前尝试调用 join() 也会引发相同的异常。
语法
thread.join(timeout)
参数
超时 (timeout) —— 它应该是一个浮点数,指定线程阻塞的超时时间。
join() 方法始终返回 None。你必须在 join() 之后调用 is_alive() 来判断是否发生了超时——如果线程仍然存活,则 join() 调用超时了。当 timeout 参数不存在或为 None 时,操作将阻塞直到线程终止。
一个线程可以被多次加入。
示例
thread1.start() thread2.start() thread1.join() thread2.join()
is_alive() 方法
此方法返回线程是否存活。它在调用 run() 方法之前和 run() 方法终止之后返回 True。
Python - 线程命名
线程的名称仅用于标识目的,在语义上没有任何作用。多个线程可以具有相同的名称。线程名称可以在 thread() 构造函数的参数之一中指定。
thread(name)
这里 name 是线程名称。默认情况下,会构造一个唯一的名称,例如 "Thread-N"。
Thread 对象也具有一个属性对象,用于线程名称属性的 getter 和 setter 方法。
thread.name = "Thread-1"
守护进程属性 (The daemon Property)
一个布尔值,指示此线程是守护线程 (True) 还是非守护线程 (False)。必须在调用 start() 之前设置此属性。
示例
要使用 threading 模块实现新线程,您需要执行以下操作:
定义 _Thread_ 类的新的子类。
重写 _init__(self [,args])_ 方法以添加其他参数。
然后,重写 run(self [,args]) 方法以实现线程启动时应执行的操作。
创建新的 Thread 子类后,您可以创建其实例,然后通过调用 start() 方法启动新线程,该方法会依次调用 run() 方法。
import threading
import time
class myThread (threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
def run(self):
print ("Starting " + self.name)
for count in range(1,6):
time.sleep(5)
print ("Thread name: {} Count: {}".format ( self.name, count ))
print ("Exiting " + self.name)
# Create new threads
thread1 = myThread("Thread-1")
thread2 = myThread("Thread-2")
# Start new Threads
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
它将产生以下**输出**:
Starting Thread-1 Starting Thread-2 Thread name: Thread-1 Count: 1 Thread name: Thread-2 Count: 1 Thread name: Thread-1 Count: 2 Thread name: Thread-2 Count: 2 Thread name: Thread-1 Count: 3 Thread name: Thread-2 Count: 3 Thread name: Thread-1 Count: 4 Thread name: Thread-2 Count: 4 Thread name: Thread-1 Count: 5 Exiting Thread-1 Thread name: Thread-2 Count: 5 Exiting Thread-2 Exiting Main Thread
Python - 线程调度
Python 支持程序中的多线程。多线程程序可以独立执行多个子任务,这允许并行执行任务。
Python 解释器将 Python 线程请求映射到 POSIX/pthreads 或 Windows 线程。因此,与普通线程类似,Python 线程由主机操作系统处理。
但是,Python 解释器不支持线程调度。因此,使用 Python 解释器无法实现线程优先级、调度方案和线程抢占。Python 线程的调度和上下文切换由主机调度程序控制。
Python 确实以 sched 模块作为标准库的形式支持任务调度。它可用于创建机器人和其他监控和自动化应用程序。_sched_ 模块实现了一个通用的事件调度器,用于在特定时间运行任务。它提供了类似于 Windows 或 Linux 中任务调度的工具。
_scheduler_ 类在 _sched_ 内置模块中定义。
scheduler(timefunc=time.monotonic, delayfunc=time.sleep)
_scheduler_ 类中定义的方法包括:
scheduler.enter() —— 可以调度事件在延迟后或特定时间运行。要使用延迟调度它们,请使用 enter() 方法。
scheduler.cancel() —— 从队列中删除事件。如果事件不是队列中当前存在的事件,此方法将引发 ValueError。
scheduler.run(blocking=True) —— 运行所有已计划的事件。
可以调度事件在延迟后或特定时间运行。要使用延迟调度它们,请使用 enter() 方法,它接受四个参数。
表示延迟的数字
优先级值
要调用的函数
函数的参数元组
示例1
此示例计划了两个不同的事件:
import sched
import time
scheduler = sched.scheduler(time.time, time.sleep)
def schedule_event(name, start):
now = time.time()
elapsed = int(now - start)
print('elapsed=',elapsed, 'name=', name)
start = time.time()
print('START:', time.ctime(start))
scheduler.enter(2, 1, schedule_event, ('EVENT_1', start))
scheduler.enter(5, 1, schedule_event, ('EVENT_2', start))
scheduler.run()
它将产生以下**输出**:
START: Mon Jun 5 15:37:29 2023 elapsed= 2 name= EVENT_1 elapsed= 5 name= EVENT_2
示例2
让我们来看另一个例子,以更好地理解这个概念:
import sched
from datetime import datetime
import time
def addition(a,b):
print("Performing Addition : ", datetime.now())
print("Time : ", time.monotonic())
print("Result : ", a+b)
s = sched.scheduler()
print("Start Time : ", datetime.now())
event1 = s.enter(10, 1, addition, argument = (5,6))
print("Event Created : ", event1)
s.run()
print("End Time : ", datetime.now())
它将产生以下**输出**:
Start Time : 2023-06-05 15:49:49.508400
Event Created : Event(time=774087.453, priority=1, sequence=0, action=<function addition at 0x000001FFE71A1080>, argument=(5, 6), kwargs={})
Performing Addition : 2023-06-05 15:49:59.512213
Time : 774087.484
Result : 11
End Time : 2023-06-05 15:49:59.559659
Python - 线程池
什么是线程池?
线程池是一种自动管理工作线程池的机制。池中的每个线程都称为工作线程或工作者线程。任务完成后,可以重复使用工作线程。单个线程一次只能执行一个任务。
线程池控制何时创建线程以及线程在未使用时应执行的操作。
与手动启动、管理和关闭线程相比,使用线程池的效率要高得多,尤其是在处理大量任务时。
Python 中的多线程并发地执行某个函数。可以通过 _concurrent.futures_ 模块中定义的 _ThreadPoolExecutor_ 类来实现多个线程异步执行函数。
_concurrent.futures_ 模块包括 _Future_ 类和两个 _Executor_ 类:_ThreadPoolExecutor_ 和 _ProcessPoolExecutor_。
_Future_ 类
_concurrent.futures.Future_ 类负责处理任何可调用对象(例如函数)的异步执行。要获取 _Future_ 类的对象,应在任何 _Executor_ 对象上调用 _submit()_ 方法。不应通过其构造函数直接创建它。
_Future_ 类中的重要方法:
result(timeout=None)
此方法返回调用返回的值。如果调用尚未完成,则此方法将等待最多 timeout 秒。如果在 timeout 秒内调用未完成,则将引发 _TimeoutError_。如果未指定 timeout,则等待时间没有限制。
cancel()
此方法尝试取消调用。如果调用当前正在执行或已完成运行并且无法取消,则该方法将返回 False,否则调用将被取消,该方法将返回 True。
cancelled()
如果调用已成功取消,此方法将返回 True。
running()
如果调用当前正在执行且无法取消,此方法将返回 True。
done()
如果调用已成功取消或完成运行,此方法将返回 True。
_ThreadPoolExecutor_ 类
此类表示指定数量的最大工作线程池,用于异步执行调用。
concurrent.futures.ThreadPoolExecutor(max_threads)
示例
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def square(numbers):
for val in numbers:
ret = val*val
sleep(1)
print("Number:{} Square:{}".format(val, ret))
def cube(numbers):
for val in numbers:
ret = val*val*val
sleep(1)
print("Number:{} Cube:{}".format(val, ret))
if __name__ == '__main__':
numbers = [1,2,3,4,5]
executor = ThreadPoolExecutor(4)
thread1 = executor.submit(square, (numbers))
thread2 = executor.submit(cube, (numbers))
print("Thread 1 executed ? :",thread1.done())
print("Thread 2 executed ? :",thread2.done())
sleep(2)
print("Thread 1 executed ? :",thread1.done())
print("Thread 2 executed ? :",thread2.done())
它将产生以下**输出**:
Thread 1 executed ? : False Thread 2 executed ? : False Number:1 Square:1 Number:1 Cube:1 Number:2 Square:4 Number:2 Cube:8 Thread 1 executed ? : False Thread 2 executed ? : False Number:3 Square:9 Number:3 Cube:27 Number:4 Square:16 Number:4 Cube:64 Number:5 Square:25 Number:5 Cube:125 Thread 1 executed ? : True Thread 2 executed ? : True
Python - 主线程
每个 Python 程序至少有一个称为主线程的执行线程。默认情况下,主线程是非守护线程。
有时,我们可能需要在程序中创建其他线程以并发执行代码。
以下是创建新线程的语法:
object = threading.Thread(target, daemon)
_Thread()_ 构造函数创建一个新对象。通过调用 _start()_ 方法,新线程开始运行,它会自动调用作为参数传递给 _target_ 参数的函数(默认为 _run_)。第二个参数是“daemon”,默认为 None。
示例
from time import sleep
from threading import current_thread
from threading import Thread
# function to be executed by a new thread
def run():
# get the current thread
thread = current_thread()
# is it a daemon thread?
print(f'Daemon thread: {thread.daemon}')
# create a new thread
thread = Thread(target=run)
# start the new thread
thread.start()
# block for a 0.5 sec
sleep(0.5)
它将产生以下**输出**:
Daemon thread: False
因此,通过以下语句创建线程:
t1=threading.Thread(target=run)
此语句创建一个非守护线程。启动后,它将调用 _run()_ 方法。
Python - 线程优先级
Python 标准库中的 _queue_ 模块在必须在线程之间安全交换信息的多线程编程中很有用。此模块中的 _PriorityQueue_ 类实现了所有必需的锁定语义。
使用优先级队列,条目保持排序(使用 _heapq_ 模块),并且首先检索最低值条目。
_Queue_ 对象具有以下方法来控制队列:
get() —— _get()_ 从队列中删除并返回一个项目。
put() —— _put()_ 将项目添加到队列。
qsize() —— _qsize()_ 返回当前在队列中的项目数。
empty() —— _empty()_ 如果队列为空,则返回 True;否则返回 False。
full() —— _full()_ 如果队列已满,则返回 True;否则返回 False。
queue.PriorityQueue(maxsize=0)
这是优先级队列的构造函数。_maxsize_ 是一个整数,它设置可以放入队列中的项目数量的上限。如果 _maxsize_ 小于或等于零,则队列大小是无限的。
首先检索最低值条目(最低值条目是 _min(entries)_ 将返回的条目)。条目的典型模式是形式为:
(priority_number, data)
示例
from time import sleep
from random import random, randint
from threading import Thread
from queue import PriorityQueue
queue = PriorityQueue()
def producer(queue):
print('Producer: Running')
for i in range(5):
# create item with priority
value = random()
priority = randint(0, 5)
item = (priority, value)
queue.put(item)
# wait for all items to be processed
queue.join()
queue.put(None)
print('Producer: Done')
def consumer(queue):
print('Consumer: Running')
while True:
# get a unit of work
item = queue.get()
if item is None:
break
sleep(item[1])
print(item)
queue.task_done()
print('Consumer: Done')
producer = Thread(target=producer, args=(queue,))
producer.start()
consumer = Thread(target=consumer, args=(queue,))
consumer.start()
producer.join()
consumer.join()
它将产生以下**输出**:
Producer: Running Consumer: Running (0, 0.15332707626852804) (2, 0.4730737391435892) (2, 0.8679231358257962) (3, 0.051924220435665025) (4, 0.23945882716108446) Producer: Done Consumer: Done
Python - 守护线程
有时,需要在后台执行任务。一种特殊类型的线程用于后台任务,称为守护线程。换句话说,守护线程在后台执行任务。
需要注意的是,守护线程执行这样的非关键任务,虽然可能对应用程序有用,但如果它们失败或在操作中途被取消,也不会妨碍应用程序。
此外,守护线程将无法控制何时终止。一旦所有非守护线程完成,程序将终止,即使此时仍有守护线程正在运行。
这是守护线程和非守护线程之间的主要区别。如果只有守护线程正在运行,则进程将退出;如果至少有一个非守护线程正在运行,则进程将无法退出。
| 守护线程 (Daemon) | 非守护线程 (Non-daemon) |
|---|---|
| 如果只有守护线程正在运行(或没有线程正在运行),则进程将退出。 | 如果至少有一个非守护线程正在运行,则进程将不会退出。 |
创建守护线程
要创建守护线程,需要将 _daemon_ 属性设置为 True。
t1=threading.Thread(daemon=True)
如果创建线程对象时没有任何参数,则也可以在调用 _start()_ 方法之前将其 _daemon_ 属性设置为 True。
t1=threading.Thread() t1.daemon=True
示例
请看下面的例子:
from time import sleep
from threading import current_thread
from threading import Thread
# function to be executed in a new thread
def run():
# get the current thread
thread = current_thread()
# is it a daemon thread?
print(f'Daemon thread: {thread.daemon}')
# create a new thread
thread = Thread(target=run, daemon=True)
# start the new thread
thread.start()
# block for a 0.5 sec for daemon thread to run
sleep(0.5)
它将产生以下**输出**:
Daemon thread: True
守护线程可以执行支持程序中非守护线程的任务。例如:
创建在后台存储日志信息的文件。
在后台执行网络抓取。
自动将数据保存到后台的数据库中。
示例
如果将正在运行的线程配置为守护线程,则会引发 _RuntimeError_。请看下面的例子:
from time import sleep
from threading import current_thread
from threading import Thread
# function to be executed in a new thread
def run():
# get the current thread
thread = current_thread()
# is it a daemon thread?
print(f'Daemon thread: {thread.daemon}')
thread.daemon = True
# create a new thread
thread = Thread(target=run)
# start the new thread
thread.start()
# block for a 0.5 sec for daemon thread to run
sleep(0.5)
它将产生以下**输出**:
Exception in thread Thread-1 (run):
Traceback (most recent call last):
. . . .
. . . .
thread.daemon = True
^^^^^^^^^^^^^
File "C:\Python311\Lib\threading.py", line 1219, in daemon
raise RuntimeError("cannot set daemon status of active thread")
RuntimeError: cannot set daemon status of active thread
Python - 线程同步
Python 提供的 _threading_ 模块包含一个易于实现的锁定机制,允许您同步线程。通过调用 _Lock()_ 方法创建一个新的锁,该方法返回新的锁。
新锁对象的 _acquire(blocking)_ 方法用于强制线程同步运行。可选的 _blocking_ 参数允许您控制线程是否等待获取锁。
如果 _blocking_ 设置为 0,则如果无法获取锁,线程将立即返回 0 值;如果获取了锁,则返回 1。如果 _blocking_ 设置为 1,则线程将阻塞并等待锁被释放。
新锁对象的release()方法用于在不再需要锁定时释放锁。
示例
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print ("Exiting Main Thread")
输出
执行上述代码时,会产生以下输出:
Starting Thread-1 Starting Thread-2 Thread-1: Thu Jul 13 21:10:11 2023 Thread-1: Thu Jul 13 21:10:12 2023 Thread-1: Thu Jul 13 21:10:13 2023 Thread-2: Thu Jul 13 21:10:15 2023 Thread-2: Thu Jul 13 21:10:17 2023 Thread-2: Thu Jul 13 21:10:19 2023 Exiting Main Thread
Python - 线程间通信
线程共享分配给进程的内存。因此,同一进程中的线程可以相互通信。为了促进线程间通信,threading模块提供了Event对象和Condition对象。
Event 对象
Event对象管理内部标志的状态。该标志最初为false,使用set()方法变为true,使用clear()方法重置为false。wait()方法会阻塞,直到标志为true。
Event 对象的方法:
is_set() 方法
当且仅当内部标志为true时返回True。
set() 方法
将内部标志设置为true。所有等待它变为true的线程都被唤醒。一旦标志为true,调用wait()的线程根本不会阻塞。
clear() 方法
将内部标志重置为false。随后,调用wait()的线程将阻塞,直到调用set()再次将内部标志设置为true。
wait(timeout=None) 方法
阻塞直到内部标志为true。如果在进入时内部标志为true,则立即返回。否则,阻塞直到另一个线程调用set()将标志设置为true,或直到可选的超时发生。
当timeout参数存在且不为None时,它应该是一个浮点数,以秒为单位指定操作的超时时间。
示例
以下代码尝试模拟交通流量由交通信号灯状态(绿色或红色)控制的情况。
程序中包含两个线程,分别针对两个不同的函数。signal_state()函数定期设置和重置事件,指示信号从绿色变为红色。
traffic_flow()函数等待事件被设置,并在事件保持设置状态时运行一个循环。
from threading import *
import time
def signal_state():
while True:
time.sleep(5)
print("Traffic Police Giving GREEN Signal")
event.set()
time.sleep(10)
print("Traffic Police Giving RED Signal")
event.clear()
def traffic_flow():
num=0
while num<10:
print("Waiting for GREEN Signal")
event.wait()
print("GREEN Signal ... Traffic can move")
while event.is_set():
num=num+1
print("Vehicle No:", num," Crossing the Signal")
time.sleep(2)
print("RED Signal ... Traffic has to wait")
event=Event()
t1=Thread(target=signal_state)
t2=Thread(target=traffic_flow)
t1.start()
t2.start()
输出
Waiting for GREEN Signal Traffic Police Giving GREEN Signal GREEN Signal ... Traffic can move Vehicle No: 1 Crossing the Signal Vehicle No: 2 Crossing the Signal Vehicle No: 3 Crossing the Signal Vehicle No: 4 Crossing the Signal Vehicle No: 5 Crossing the Signal Signal is RED RED Signal ... Traffic has to wait Waiting for GREEN Signal Traffic Police Giving GREEN Signal GREEN Signal ... Traffic can move Vehicle No: 6 Crossing the Signal Vehicle No: 7 Crossing the Signal Vehicle No: 8 Crossing the Signal Vehicle No: 9 Crossing the Signal Vehicle No: 10 Crossing the Signal
Condition 对象
threading模块中的Condition类实现条件变量对象。Condition对象强制一个或多个线程等待,直到被另一个线程通知。Condition与可重入锁相关联。Condition对象具有acquire()和release()方法,它们调用关联锁的相应方法。
threading.Condition(lock=None)
以下是Condition对象的 方法:
acquire(*args)
获取底层锁。此方法调用底层锁上的相应方法;返回值是该方法返回的任何值。
release()
释放底层锁。此方法调用底层锁上的相应方法;没有返回值。
wait(timeout=None)
此方法释放底层锁,然后阻塞,直到被另一个线程对同一条件变量的notify()或notify_all()调用唤醒,或者直到可选的超时发生。一旦被唤醒或超时,它重新获取锁并返回。
wait_for(predicate, timeout=None)
此实用程序方法可能会重复调用wait(),直到满足谓词,或直到超时发生。返回值是谓词的最后一个返回值,如果方法超时,则将评估为False。
notify(n=1)
此方法最多唤醒n个等待条件变量的线程;如果没有线程正在等待,则它是一个空操作。
notify_all()
唤醒所有等待此条件的线程。此方法的作用类似于notify(),但唤醒所有等待线程而不是一个线程。如果调用线程在调用此方法时没有获取锁,则会引发RuntimeError。
示例
在下面的代码中,线程t2运行taskB()函数,t1运行taskA()函数。t1线程获取条件并发出通知。此时,t2线程处于等待状态。条件释放后,等待线程继续使用通知函数生成的随机数。
from threading import *
import time
import random
numbers=[]
def taskA(c):
while True:
c.acquire()
num=random.randint(1,10)
print("Generated random number:", num)
numbers.append(num)
print("Notification issued")
c.notify()
c.release()
time.sleep(5)
def taskB(c):
while True:
c.acquire()
print("waiting for update")
c.wait()
print("Obtained random number", numbers.pop())
c.release()
time.sleep(5)
c=Condition()
t1=Thread(target=taskB, args=(c,))
t2=Thread(target=taskA, args=(c,))
t1.start()
t2.start()
执行这段代码后,将产生以下输出:
waiting for update Generated random number: 4 Notification issued Obtained random number 4 waiting for update Generated random number: 6 Notification issued Obtained random number 6 waiting for update Generated random number: 10 Notification issued Obtained random number 10 waiting for update
Python - 线程死锁
死锁可以描述为一种并发故障模式。它是程序中的一种情况,其中一个或多个线程等待永远不会发生的条件。结果,线程无法继续执行,程序卡住或冻结,必须手动终止。
死锁情况可能在您的并发程序中以多种方式出现。死锁绝不是故意开发的,实际上,它们实际上是代码中的副作用或错误。
线程死锁的常见原因如下:
尝试两次获取相同互斥锁的线程。
相互等待的线程(例如,A等待B,B等待A)。
当线程未能释放资源(例如锁、信号量、条件、事件等)时。
以不同顺序获取互斥锁的线程(例如,未能执行锁排序)。
如果多线程应用程序中的多个线程尝试访问同一资源,例如对同一文件执行读/写操作,则可能会导致数据不一致。因此,重要的是同步并发处理,以便当一个线程使用资源时,将其锁定以防止其他线程访问。
Python提供的threading模块包含一个易于实现的锁定机制,允许您同步线程。通过调用Lock()方法创建一个新的锁,该方法返回新的锁。
Lock 对象
Lock类的对象有两种可能的状态:锁定或解锁,最初在创建时处于解锁状态。锁不属于任何特定线程。
Lock类定义了acquire()和release()方法。
acquire() 方法
当状态为解锁时,此方法将状态更改为锁定并立即返回。该方法采用可选的blocking参数。
语法
Lock.acquire(blocking, timeout)
参数
blocking - 如果设置为False,则表示不阻塞。如果设置blocking为True的调用会阻塞,则立即返回False;否则,将锁设置为锁定并返回True。
此方法的返回值为True,如果锁成功获取;否则为False。
release() 方法
当状态为锁定状态时,此方法在另一个线程中将其更改为解锁状态。这可以从任何线程调用,而不只是获取锁的线程。
语法
Lock.release()
release()方法只能在锁定状态下调用。如果尝试释放解锁的锁,则会引发RuntimeError。
当锁被锁定,将其重置为解锁,然后返回。如果任何其他线程阻塞等待锁解锁,则允许其中恰好一个线程继续执行。此方法没有返回值。
示例
在下面的程序中,两个线程尝试调用synchronized()方法。其中一个线程获取锁并获得访问权限,而另一个线程等待。当第一个线程的run()方法完成时,锁被释放,synchronized方法可用于第二个线程。
当两个线程都加入时,程序结束。
from threading import Thread, Lock
import time
lock=Lock()
threads=[]
class myThread(Thread):
def __init__(self,name):
Thread.__init__(self)
self.name=name
def run(self):
lock.acquire()
synchronized(self.name)
lock.release()
def synchronized(threadName):
print ("{} has acquired lock and is running synchronized method".format(threadName))
counter=5
while counter:
print ('**', end='')
time.sleep(2)
counter=counter-1
print('\nlock released for', threadName)
t1=myThread('Thread1')
t2=myThread('Thread2')
t1.start()
threads.append(t1)
t2.start()
threads.append(t2)
for t in threads:
t.join()
print ("end of main thread")
它将产生以下**输出**:
Thread1 has acquired lock and is running synchronized method ********** lock released for Thread1 Thread2 has acquired lock and is running synchronized method ********** lock released for Thread2 end of main thread
Semaphore 对象
Python使用另一种称为信号量的机制支持线程同步。这是著名的计算机科学家Edsger W. Dijkstra发明的最古老的同步技术之一。
信号量的基本概念是使用一个内部计数器,每个acquire()调用递减,每个release()调用递增。计数器永远不会低于零;当acquire()发现它为零时,它会阻塞,等待直到其他一些线程调用release()。
threading模块中的Semaphore类定义了acquire()和release()方法。
acquire() 方法
如果在进入时内部计数器大于零,则将其减一并立即返回True。
如果在进入时内部计数器为零,则阻塞直到被对release()的调用唤醒。一旦被唤醒(并且计数器大于0),则将计数器减1并返回True。每个对release()的调用都将唤醒恰好一个线程。线程唤醒的顺序是任意的。
如果blocking参数设置为False,则不阻塞。如果没有任何参数的调用会阻塞,则立即返回False;否则,执行与不带参数调用相同的事情,并返回True。
release() 方法
释放信号量,将内部计数器加1。当它在进入时为零并且其他线程正在等待它再次大于零时,唤醒n个这些线程。
示例
from threading import *
import time
# creating thread instance where count = 3
lock = Semaphore(4)
# creating instance
def synchronized(name):
# calling acquire method
lock.acquire()
for n in range(3):
print('Hello! ', end = '')
time.sleep(1)
print( name)
# calling release method
lock.release()
# creating multiple thread
thread_1 = Thread(target = synchronized , args = ('Thread 1',))
thread_2 = Thread(target = synchronized , args = ('Thread 2',))
thread_3 = Thread(target = synchronized , args = ('Thread 3',))
# calling the threads
thread_1.start()
thread_2.start()
thread_3.start()
它将产生以下**输出**:
Hello! Hello! Hello! Thread 1 Hello! Thread 2 Thread 3 Hello! Hello! Thread 1 Hello! Thread 3 Thread 2 Hello! Hello! Thread 1 Thread 3 Thread 2
Python - 中断线程
在多线程程序中,新线程中的任务可能需要停止。这可能是由于许多原因,例如:(a) 不再需要任务的结果,或者 (b) 任务的结果出错,或者 (c) 应用程序正在关闭。
可以使用threading.Event对象停止线程。Event对象管理内部标志的状态,该标志可以设置为已设置或未设置。
创建新的Event对象时,其标志最初未设置(false)。如果一个线程调用其set()方法,则可以在另一个线程中检查其标志值。如果发现为true,则可以终止其活动。
示例
在此示例中,我们有一个MyThread类。其对象开始执行run()方法。主线程休眠一段时间,然后设置一个事件。在检测到事件之前,run()方法中的循环会继续。一旦检测到事件,循环就会终止。
from time import sleep
from threading import Thread
from threading import Event
class MyThread(Thread):
def __init__(self, event):
super(MyThread, self).__init__()
self.event = event
def run(self):
i=0
while True:
i+=1
print ('Child thread running...',i)
sleep(0.5)
if self.event.is_set():
break
print()
print('Child Thread Interrupted')
event = Event()
thread1 = MyThread(event)
thread1.start()
sleep(3)
print('Main thread stopping child thread')
event.set()
thread1.join()
执行这段代码后,将产生以下输出:
Child thread running... 1 Child thread running... 2 Child thread running... 3 Child thread running... 4 Child thread running... 5 Child thread running... 6 Main thread stopping child thread Child Thread Interrupted
Python - 网络编程
Python标准库中的threading模块能够处理单个进程中的多个线程及其交互。运行在同一台机器上的两个进程之间的通信由Unix域套接字处理,而对于运行在通过TCP(传输控制协议)连接的不同机器上的进程,则使用Internet域套接字。
Python的标准库包含各种支持进程间通信和网络的内置模块。Python提供了两级访问网络服务的权限。在低级别,您可以访问底层操作系统中的基本套接字支持,这允许您为面向连接和无连接协议实现客户端和服务器。
Python还拥有提供对特定应用程序级网络协议(例如FTP、HTTP等)的更高级别访问的库。
| 协议 | 常用功能 | 端口号 | Python模块 |
|---|---|---|---|
| HTTP | 网页 | 80 | httplib, urllib, xmlrpclib |
| NNTP | Usenet新闻 | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送电子邮件 | 25 | smtplib |
| POP3 | 获取电子邮件 | 110 | poplib |
| IMAP4 | 获取电子邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 文档传输 | 70 | gopherlib, urllib |
Python - Socket 编程
标准库中的socket模块包含服务器和客户端在硬件级别通信所需的功能。
此模块提供对BSD套接字接口的访问。它适用于所有操作系统,例如Linux、Windows、MacOS。
什么是套接字?
套接字是双向通信通道的端点。套接字可以在进程内、同一台机器上的进程之间或不同大陆上的进程之间进行通信。
套接字由IP地址和端口号的组合标识。它应该在两端正确配置才能开始通信。
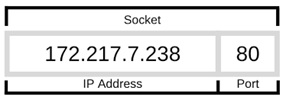
套接字可以实现多种不同的通道类型:Unix域套接字、TCP、UDP等等。套接字库提供用于处理常用传输的特定类,以及用于处理其余传输的通用接口。
套接字编程意味着以编程方式设置套接字,以便能够发送和接收数据。
有两种类型的通信协议:
面向连接的协议
无连接协议
TCP或传输控制协议是一种面向连接的协议。数据由服务器以数据包的形式传输,并按照相同的传输顺序由接收方组装。由于通信两端的套接字需要在开始之前设置,因此此方法更可靠。
UDP或用户数据报协议是无连接的。此方法不可靠,因为套接字不需要建立任何连接和终止过程来传输数据。
Python socket模块
此模块包含Socket类。套接字对象表示主机名和端口号对。构造方法具有以下签名:
语法
socket.socket (socket_family, socket_type, protocol=0)
参数
family – 默认情况下为AF_INET。其他值 - AF_INET6(八组四个十六进制数字)、AF_UNIX、AF_CAN(控制器局域网)或AF_RDS(可靠数据报套接字)。
socket_type – 应为SOCK_STREAM(默认值)、SOCK_DGRAM、SOCK_RAW或其他SOCK_常量之一。
protocol – 数字通常为零,可以省略。
返回值类型
此方法返回一个套接字对象。
获得套接字对象后,可以使用所需的方法创建客户端或服务器程序。
服务器套接字方法
在服务器上实例化的套接字称为服务器套接字。服务器上的套接字对象可以使用以下方法:
bind() 方法 – 此方法将套接字绑定到指定的IP地址和端口号。
listen() 方法 – 此方法启动服务器并进入监听循环,查找来自客户端的连接请求。
accept() 方法 – 当服务器拦截连接请求时,此方法接受请求并使用其地址标识客户端套接字。
要在服务器上创建套接字,请使用以下代码片段:
import socket
server = socket.socket()
server.bind(('localhost',12345))
server.listen()
client, addr = server.accept()
print ("connection request from: " + str(addr))
默认情况下,服务器绑定到本地机器的IP地址“localhost”,侦听任意空闲端口号。
客户端套接字方法
在客户端也设置了类似的套接字。它主要向在其IP地址和端口号上侦听的服务器套接字发送连接请求。
connect() 方法
此方法将一个包含两个项目的元组对象作为参数。这两个项目是服务器的IP地址和端口号。
obj=socket.socket() obj.connect((host,port))
服务器接受连接后,两个套接字对象都可以发送和/或接收数据。
send() 方法
服务器使用它拦截的地址将数据发送到客户端。
client.send(bytes)
客户端套接字将数据发送到它已建立连接的套接字。
sendall() 方法
类似于send()。但是,与send()不同的是,此方法会继续从字节发送数据,直到所有数据已发送或发生错误为止。成功时不返回任何值。
sendto() 方法
此方法仅在UDP协议的情况下使用。
recv() 方法
此方法用于检索发送到客户端的数据。在服务器的情况下,它使用已接受请求的远程套接字。
client.recv(bytes)
recvfrom() 方法
此方法在UDP协议的情况下使用。
Python - Socket 服务器
要编写Internet服务器,我们使用socket模块中提供的socket函数来创建一个套接字对象。然后使用套接字对象调用其他函数来设置套接字服务器。
现在调用bind(hostname, port)函数来为给定主机上的服务指定一个端口。
接下来,调用返回对象的accept方法。此方法等待客户端连接到您指定的端口,然后返回一个连接对象,该对象表示与该客户端的连接。
import socket
host = "127.0.0.1"
port = 5001
server = socket.socket()
server.bind((host,port))
server.listen()
conn, addr = server.accept()
print ("Connection from: " + str(addr))
while True:
data = conn.recv(1024).decode()
if not data:
break
data = str(data).upper()
print (" from client: " + str(data))
data = input("type message: ")
conn.send(data.encode())
conn.close()
Python - Socket 客户端
让我们编写一个非常简单的客户端程序,它打开到给定端口5001和给定localhost的连接。使用Python的socket模块函数创建套接字客户端非常简单。
socket.connect(hosname, port)打开到端口上主机名的TCP连接。打开套接字后,您可以像任何IO对象一样从中读取数据。完成后,请记住关闭它,就像关闭文件一样。
以下代码是一个非常简单的客户端,它连接到给定的主机和端口,从套接字读取任何可用数据,然后在输入“q”时退出。
import socket
host = '127.0.0.1'
port = 5001
obj = socket.socket()
obj.connect((host,port))
message = input("type message: ")
while message != 'q':
obj.send(message.encode())
data = obj.recv(1024).decode()
print ('Received from server: ' + data)
message = input("type message: ")
obj.close()
先运行服务器代码。它开始监听。
然后启动客户端代码。它发送请求。
请求已接受。客户端地址已识别
输入一些文本并按Enter键。
接收到的数据被打印。将数据发送到客户端。
收到来自服务器的数据。
输入“q”时循环终止。
服务器-客户端交互如下所示:
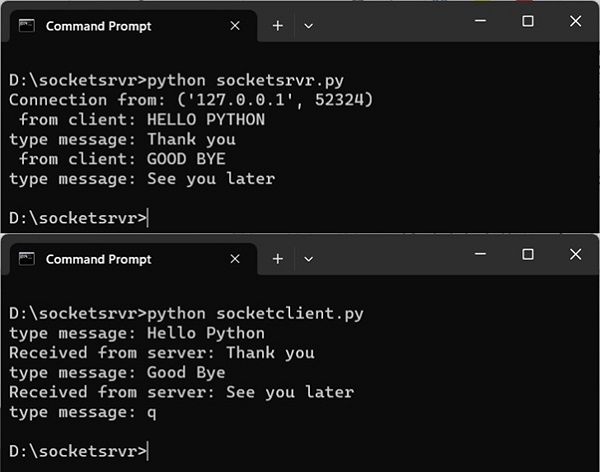
我们已经在本地机器上使用socket模块实现了客户端-服务器通信。要将服务器和客户端代码放在网络上的两台不同的机器上,我们需要找到服务器机器的IP地址。
在Windows上,您可以通过运行ipconfig命令来查找IP地址。ifconfig命令是Ubuntu上的等效命令。
使用IPv4地址值更改服务器和客户端代码中的主机字符串,然后像以前一样运行它们。
使用Socket模块进行Python文件传输
以下程序演示如何使用套接字通信将文件从服务器传输到客户端。
服务器代码
建立连接的代码与之前相同。接受连接请求后,服务器上的文件将以二进制模式打开以进行读取,并且字节将连续读取并发送到客户端流,直到达到文件结尾。
import socket
host = "127.0.0.1"
port = 5001
server = socket.socket()
server.bind((host, port))
server.listen()
conn, addr = server.accept()
data = conn.recv(1024).decode()
filename='test.txt'
f = open(filename,'rb')
while True:
l = f.read(1024)
if not l:
break
conn.send(l)
print('Sent ',repr(l))
f.close()
print('File transferred')
conn.close()
客户端代码
在客户端,一个新文件以wb模式打开。从服务器接收到的数据流被写入文件。随着流的结束,输出文件被关闭。客户端机器上将创建一个新文件。
import socket
s = socket.socket()
host = "127.0.0.1"
port = 5001
s.connect((host, port))
s.send("Hello server!".encode())
with open('recv.txt', 'wb') as f:
while True:
print('receiving data...')
data = s.recv(1024)
if not data:
break
f.write(data)
f.close()
print('Successfully received')
s.close()
print('connection closed')
Python socketserver模块
Python标准库中的socketserver模块是一个框架,用于简化编写网络服务器的任务。模块中包含以下类,它们表示同步服务器:

这些类与相应的RequestHandler类一起工作以实现服务。BaseServer是模块中所有Server对象的超类。
TCPServer类使用互联网TCP协议,在客户端和服务器之间提供连续的数据流。构造函数自动尝试调用server_bind()和server_activate()。其他参数传递给BaseServer基类。
您还必须创建一个StreamRequestHandler类的子类。它提供self.rfile和self.wfile属性来读取或写入以获取请求数据或将数据返回给客户端。
UDPServer和DatagramRequestHandler – 这些类用于UDP协议。
DatagramRequestHandler和UnixDatagramServer – 这些类使用Unix域套接字;它们在非Unix平台上不可用。
服务器代码
您必须编写一个RequestHandler类。它为每个与服务器的连接实例化一次,并且必须覆盖handle()方法以实现与客户端的通信。
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
self.data = self.request.recv(1024).strip()
host,port=self.client_address
print("{}:{} wrote:".format(host,port))
print(self.data.decode())
msg=input("enter text .. ")
self.request.sendall(msg.encode())
在服务器分配的端口号上,TCPServer类的对象调用forever()方法将服务器置于监听模式,并接受来自客户端的传入请求。
if __name__ == "__main__":
HOST, PORT = "localhost", 9999
with socketserver.TCPServer((HOST, PORT), MyTCPHandler) as server:
server.serve_forever()
客户端代码
使用socketserver时,客户端代码与socket客户端应用程序大致相似。
import socket
import sys
HOST, PORT = "localhost", 9999
while True:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
# Connect to server and send data
sock.connect((HOST, PORT))
data = input("enter text .. .")
sock.sendall(bytes(data + "\n", "utf-8"))
# Receive data from the server and shut down
received = str(sock.recv(1024), "utf-8")
print("Sent: {}".format(data))
print("Received: {}".format(received))
在一个命令提示符终端中运行服务器代码。为客户端实例打开多个终端。您可以模拟服务器和多个客户端之间的并发通信。
| 服务器 | 客户端-1 | 客户端-2 |
|---|---|---|
|
D:\socketsrvr>python myserver.py 127.0.0.1:54518 wrote from client-1 enter text .. hello 127.0.0.1:54522 wrote how are you enter text .. fine 127.0.0.1:54523 wrote from client-2 enter text .. hi client-2 127.0.0.1:54526 wrote good bye enter text .. bye bye 127.0.0.1:54530 wrote thanks enter text .. bye client-2 |
D:\socketsrvr>python myclient.py enter text .. . from client-1 Sent from client-1 Received: hello enter text .. . how are you Sent how are you Received: fine enter text .. . good bye Sent: good bye Received: bye bye enter text .. . |
D:\socketsrvr>python myclient.py enter text .. . from client-2 Sent from client-2 Received: hi client-2 enter text .. . thanks Sent: thanks Received bye client-2 enter text .. . |
Python - URL 处理
在互联网世界中,不同的资源由URL(统一资源定位符)标识。与Python标准库捆绑在一起的urllib包提供了一些处理URL的实用程序。它包含以下模块:
urllib.parse模块用于将URL解析为其各个部分。
urllib.request模块包含用于打开和读取URL的函数。
urllib.error模块包含urllib.request引发的异常的定义。
urllib.robotparser模块解析robots.txt文件。
urllib.parse模块
此模块作为标准接口,用于从URL字符串中获取各个部分。该模块包含以下函数:
urlparse(urlstring)
将URL解析为六个组件,返回一个包含6个项目的命名元组。每个元组项目都是一个字符串,对应于以下属性:
| 属性 | 索引 | 值 |
|---|---|---|
| scheme | 0 | URL方案说明符 |
| netloc | 1 | 网络位置部分 |
| path | 2 | 分层路径 |
| params | 3 | 最后一个路径元素的参数 |
| query | 4 | 查询组件 |
| fragment | 5 | 片段标识符 |
| username | 用户名 | |
| password | 密码 | |
| hostname | 主机名(小写) | |
| Port | 端口号(整数,如果存在) |
示例
from urllib.parse import urlparse
url = "https://example.com/employees/name/?salary>=25000"
parsed_url = urlparse(url)
print (type(parsed_url))
print ("Scheme:",parsed_url.scheme)
print ("netloc:", parsed_url.netloc)
print ("path:", parsed_url.path)
print ("params:", parsed_url.params)
print ("Query string:", parsed_url.query)
print ("Frgment:", parsed_url.fragment)
它将产生以下**输出**:
<class 'urllib.parse.ParseResult'> Scheme: https netloc: example.com path: /employees/name/ params: Query string: salary>=25000 Frgment:
parse_qs(qs))
此函数解析作为字符串参数给出的查询字符串。数据作为字典返回。字典键是唯一的查询变量名,值是每个名称的值列表。
要进一步将查询字符串中的查询参数提取到字典中,请按如下方式使用ParseResult对象的query属性的parse_qs()函数:
from urllib.parse import urlparse, parse_qs
url = "https://example.com/employees?name=Anand&salary=25000"
parsed_url = urlparse(url)
dct = parse_qs(parsed_url.query)
print ("Query parameters:", dct)
它将产生以下**输出**:
Query parameters: {'name': ['Anand'], 'salary': ['25000']}
urlsplit(urlstring)
这类似于urlparse(),但不从URL中拆分params。如果需要允许将参数应用于URL路径部分的每个段的较新URL语法,则通常应使用它而不是urlparse()。
urlunparse(parts)
此函数是 urlparse() 函数的反函数。它根据 urlparse() 函数返回的元组构造 URL。parts 参数可以是任何六项可迭代对象。这将返回一个等效的 URL。
示例
from urllib.parse import urlunparse
lst = ['https', 'example.com', '/employees/name/', '', 'salary>=25000', '']
new_url = urlunparse(lst)
print ("URL:", new_url)
它将产生以下**输出**:
URL: https://example.com/employees/name/?salary>=25000
urlunsplit(parts)
将 urlsplit() 返回的元组元素组合成一个完整的 URL 字符串。parts 参数可以是任何五项可迭代对象。
urllib.request 模块
此模块定义了有助于打开 URL 的函数和类。
urlopen() 函数
此函数打开给定的 URL,该 URL 可以是字符串或 Request 对象。可选的 timeout 参数指定阻塞操作的超时时间(以秒为单位)。实际上,这仅适用于 HTTP、HTTPS 和 FTP 连接。
此函数始终返回一个可以用作上下文管理器并具有 url、headers 和 status 属性的对象。
对于 HTTP 和 HTTPS URL,此函数返回一个略微修改过的 http.client.HTTPResponse 对象。
示例
以下代码使用 urlopen() 函数读取图像文件的二进制数据,并将其写入本地文件。您可以使用任何图像查看器在您的计算机上打开图像文件。
from urllib.request import urlopen
obj = urlopen("https://tutorialspoint.com/static/images/simply-easy-learning.jpg")
data = obj.read()
img = open("img.jpg", "wb")
img.write(data)
img.close()
它将产生以下**输出**:

Request 对象
urllib.request 模块包含 Request 类。此类是对 URL 请求的抽象。构造函数需要一个必需的字符串参数,即有效的 URL。
语法
urllib.request.Request(url, data, headers, origin_req_host, method=None)
参数
url − 一个有效的 URL 字符串
data − 指定要发送到服务器的其他数据的对象。此参数只能与 HTTP 请求一起使用。数据可以是字节、类文件对象和字节类对象的迭代器。
headers − 应该是标头及其关联值的字典。
origin_req_host − 应该是原始事务的请求主机
method − 应该是指示 HTTP 请求方法的字符串。GET、POST、PUT、DELETE 和其他 HTTP 动词之一。默认为 GET。
示例
from urllib.request import Request
obj = Request("https://tutorialspoint.com/")
此 Request 对象现在可以用作 urlopen() 方法的参数。
from urllib.request import Request, urlopen
obj = Request("https://tutorialspoint.com/")
resp = urlopen(obj)
urlopen() 函数返回一个 HttpResponse 对象。调用其 read() 方法可以获取给定 URL 上的资源。
from urllib.request import Request, urlopen
obj = Request("https://tutorialspoint.com/")
resp = urlopen(obj)
data = resp.read()
print (data)
发送数据
如果将 data 参数定义为 Request 构造函数,则将向服务器发送 POST 请求。数据应该是以字节表示的任何对象。
示例
from urllib.request import Request, urlopen
from urllib.parse import urlencode
values = {'name': 'Madhu',
'location': 'India',
'language': 'Hindi' }
data = urlencode(values).encode('utf-8')
obj = Request("https://example.com", data)
发送标头
Request 构造函数还接受 header 参数,以便将标头信息推送到请求中。它应该是一个字典对象。
headers = {'User-Agent': user_agent}
obj = Request("https://example.com", data, headers)
urllib.error 模块
urllib.error 模块中定义了以下异常:
URLError
由于没有网络连接(没有到指定服务器的路由)或指定的服务器不存在,因此引发 URLError。在这种情况下,引发的异常将具有 'reason' 属性。
from urllib.request import Request, urlopen
import urllib.error as err
obj = Request("http://www.nosuchserver.com")
try:
urlopen(obj)
except err.URLError as e:
print(e)
它将产生以下**输出**:
HTTP Error 403: Forbidden
HTTPError
每次服务器发送 HTTP 响应时,它都与一个数字“状态代码”相关联。该代码指示服务器为何无法完成请求。默认处理程序将为您处理其中一些响应。对于它无法处理的那些响应,urlopen() 函数将引发 HTTPError。HTTPErrors 的典型示例是“404”(未找到页面),“403”(请求被禁止)和“401”(需要身份验证)。
from urllib.request import Request, urlopen
import urllib.error as err
obj = Request("https://pythonlang.cn/fish.html")
try:
urlopen(obj)
except err.HTTPError as e:
print(e.code)
它将产生以下**输出**:
404
Python - 泛型
在 Python 中,泛型是一种机制,您可以使用它来定义可以在多个类型上运行同时保持类型安全的函数、类或方法。通过泛型的实现,可以编写可重用且可在不同数据类型中使用的代码。它确保提高代码灵活性和类型正确性。
Python 中的泛型使用类型提示实现。此功能从 Python 3.5 版本开始引入。
通常,您不需要声明变量类型。类型由分配给它的值动态确定。Python 解释器不执行类型检查,因此可能会引发运行时异常。
Python 的新类型提示功能有助于提示用户要传递的参数的预期类型。
类型提示允许您指定变量、函数参数和返回值的预期类型。泛型通过引入类型变量扩展了此功能,类型变量表示在使用泛型函数或类时可以替换为特定类型的泛型类型。
示例1
让我们来看一下定义泛型函数的以下示例:
from typing import List, TypeVar, Generic
T = TypeVar('T')
def reverse(items: List[T]) -> List[T]:
return items[::-1]
在这里,我们定义了一个名为“reverse”的泛型函数。该函数接受一个列表('List[T]')作为参数,并返回相同类型的列表。类型变量“T”表示泛型类型,在使用该函数时将用特定类型替换。
示例2
reverse() 函数使用不同的数据类型调用:
numbers = [1, 2, 3, 4, 5] reversed_numbers = reverse(numbers) print(reversed_numbers) fruits = ['apple', 'banana', 'cherry'] reversed_fruits = reverse(fruits) print(reversed_fruits)
它将产生以下**输出**:
[5, 4, 3, 2, 1] ['cherry', 'banana', 'apple']
示例3
以下示例将泛型与泛型类一起使用:
from typing import List, TypeVar, Generic
T = TypeVar('T')
class Box(Generic[T]):
def __init__(self, item: T):
self.item = item
def get_item(self) -> T:
return self.item
Let us create objects of the above generic class with int and str type
box1 = Box(42)
print(box1.get_item())
box2 = Box('Hello')
print(box2.get_item())
它将产生以下**输出**:
42 Hello
Python - 日期和时间
Python 程序可以通过多种方式处理日期和时间。在日期格式之间进行转换是计算机的常见任务。Python 标准库中的以下模块处理与日期和时间相关的处理:
DateTime 模块
Time 模块
Calendar 模块
什么是 Tick 区间?
时间间隔是以秒为单位的浮点数。特定时刻以自 1970 年 1 月 1 日凌晨 12:00(纪元)以来的秒数表示。
Python 中有一个常用的time模块,它提供用于处理时间以及在表示之间进行转换的函数。函数time.time()返回自 1970 年 1 月 1 日凌晨 12:00(纪元)以来的滴答数表示的当前系统时间。
示例
import time # This is required to include time module.
ticks = time.time()
print ("Number of ticks since 12:00am, January 1, 1970:", ticks)
这将产生如下结果:
Number of ticks since 12:00am, January 1, 1970: 1681928297.5316436
使用滴答数进行日期运算很容易。但是,纪元之前的日期不能以这种形式表示。遥远的将来的日期也无法以这种方式表示 - UNIX 和 Windows 的截止点是在 2038 年的某个时候。
什么是 TimeTuple?
许多 Python 的时间函数将时间处理为包含 9 个数字的元组,如下所示:
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | 4 位数年 | 2016 |
| 1 | 月 | 1 到 12 |
| 2 | 日 | 1 到 31 |
| 3 | 小时 | 0 到 23 |
| 4 | 分钟 | 0 到 59 |
| 5 | 秒 | 0 到 61(60 或 61 是闰秒) |
| 6 | 星期几 | 0 到 6(0 是星期一) |
| 7 | 一年中的第几天 | 1 到 366(儒略日) |
| 8 | 夏令时 | -1、0、1,-1 表示库确定 DST |
例如:
>>>import time >>> print (time.localtime())
这将产生如下输出:
time.struct_time(tm_year=2023, tm_mon=4, tm_mday=19, tm_hour=23, tm_min=49, tm_sec=8, tm_wday=2, tm_yday=109, tm_isdst=0)
上述元组等效于 struct_time 结构。此结构具有以下属性:
| 索引 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2016 |
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61(60 或 61 是闰秒) |
| 6 | tm_wday | 0 到 6(0 是星期一) |
| 7 | tm_yday | 1 到 366(儒略日) |
| 8 | tm_isdst | -1、0、1,-1 表示库确定 DST |
获取当前时间
要将自纪元以来的秒数浮点值的时间瞬间转换为时间元组,请将浮点值传递给返回具有所有有效九个项目的 time 元组的函数(例如,localtime)。
import time
localtime = time.localtime(time.time())
print ("Local current time :", localtime)
这将产生以下结果,可以将其格式化为任何其他可表示的形式:
Local current time : time.struct_time(tm_year=2023, tm_mon=4, tm_mday=19, tm_hour=23, tm_min=42, tm_sec=41, tm_wday=2, tm_yday=109, tm_isdst=0)
获取格式化的时间
您可以根据需要格式化任何时间,但是获取易于阅读的格式的时间的一种简单方法是asctime():
import time
localtime = time.asctime( time.localtime(time.time()) )
print ("Local current time :", localtime)
这将产生以下输出:
Local current time : Wed Apr 19 23:45:27 2023
获取一个月的日历
calendar 模块提供了各种方法来处理年历和月历。在这里,我们打印给定月份(2008 年 1 月)的日历。
import calendar
cal = calendar.month(2023, 4)
print ("Here is the calendar:")
print (cal)
这将产生以下输出:
Here is the calendar:
April 2023
Mo Tu We Th Fr Sa Su
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
time 模块
Python 中有一个常用的time模块,它提供用于处理时间以及在表示之间进行转换的函数。以下是所有可用方法的列表。
| 序号 | 带有说明的函数 |
|---|---|
| 1 | time.altzone
如果定义了本地 DST 时区,则其相对于 UTC 的偏移量(以秒为单位),如果定义了本地 DST 时区,则为负值,如果本地 DST 时区在 UTC 以东(如西欧,包括英国)。仅当 daylight 非零时才使用此值。 |
| 2 | time.asctime([tupletime])
接受一个时间元组并返回一个可读的 24 个字符的字符串,例如“Tue Dec 11 18:07:14 2008”。 |
| 3 | time.clock( )
以浮点数秒的形式返回当前 CPU 时间。为了测量不同方法的计算成本,time.clock 的值比 time.time() 的值更有用。 |
| 4 | time.ctime([secs])
类似于 asctime(localtime(secs)),如果没有参数,则类似于 asctime( ) |
| 5 | time.gmtime([secs])
接受以自纪元以来的秒数表示的瞬间,并返回一个包含 UTC 时间的 time 元组 t。注意:t.tm_isdst 始终为 0 |
| 6 | time.localtime([secs])
接受以自纪元以来的秒数表示的瞬间,并返回一个包含本地时间的时间元组 t(t.tm_isdst 为 0 或 1,具体取决于 DST 是否根据本地规则适用于瞬间 secs)。 |
| 7 | time.mktime(tupletime)
接受以本地时间表示为时间元组的瞬间,并返回一个浮点值,其中包含以自纪元以来的秒数表示的瞬间。 |
| 8 | time.sleep(secs)
将调用线程挂起 secs 秒。 |
| 9 | time.strftime(fmt[,tupletime])
接受以本地时间表示为时间元组的瞬间,并返回一个字符串,该字符串表示由字符串 fmt 指定的瞬间。 |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y')
根据格式字符串 fmt 解析 str,并以时间元组格式返回瞬间。 |
| 11 | time.time( )
返回当前时间瞬间,即自纪元以来的浮点数秒。 |
| 12 | time.tzset()
重置库例程使用的时区转换规则。环境变量 TZ 指定如何执行此操作。 |
让我们简要介绍一下这些函数。
time 模块有两个重要的属性。它们是:
| 序号 | 带有说明的属性 |
|---|---|
| 1 | time.timezone 属性 time.timezone 是本地时区(不含 DST)相对于 UTC 的偏移量(在美洲 >0;在大多数欧洲、亚洲、非洲 <=0)。 |
| 2 | time.tzname 属性 time.tzname 是一对与区域设置相关的字符串,它们分别是本地时区(不含 DST)和含 DST 的名称。 |
calendar 模块
calendar 模块提供与日历相关的函数,包括打印给定月份或年份的文本日历的函数。
默认情况下,calendar 将星期一作为一周的第一天,将星期日作为最后一天。要更改此设置,请调用calendar.setfirstweekday()函数。
以下是calendar模块中可用函数的列表:
| 序号 | 带有说明的函数 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串,包含 year 年份的日历,格式化为三列,列间用 c 个空格隔开。w 是每个日期的字符宽度;每行的长度为 21*w+18+2*c。l 是每一周的行数。 |
| 2 | calendar.firstweekday( ) 返回当前一周开始日期的设置。默认情况下,首次导入 calendar 时,此值为 0,表示星期一。 |
| 3 | calendar.isleap(year) 如果 year 是闰年,则返回 True;否则返回 False。 |
| 4 | calendar.leapdays(y1,y2) 返回 range(y1,y2) 范围内年份的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串,包含 year 年 month 月份的日历,每行表示一周,另加两行标题。w 是每个日期的字符宽度;每行的长度为 7*w+6。l 是每一周的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数列表的列表。每个子列表表示一周。year 年 month 月之外的日期设置为 0;该月内的日期设置为其月份中的日期,从 1 开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是 year 年 month 月份第一天对应的星期几的代码;第二个是该月的总天数。星期几代码为 0(星期一)到 6(星期日);月份数字为 1 到 12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 类似于 print calendar.calendar(year,w,l,c)。 |
| 9 | calendar.prmonth(year,month,w=2,l=1) 类似于 print calendar.month(year,month,w,l)。 |
| 10 | calendar.setfirstweekday(weekday) 将每一周的第一天设置为星期几代码 weekday。星期几代码为 0(星期一)到 6(星期日)。 |
| 11 | calendar.timegm(tupletime) time.gmtime 的逆函数:接受时间元组形式的时间点,并返回自纪元以来的浮点型秒数。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的星期几代码。星期几代码为 0(星期一)到 6(星期日);月份数字为 1(一月)到 12(十二月)。 |
datetime 模块
Python 的 datetime 模块包含在标准库中。它包含有助于操作日期和时间数据并执行日期时间运算的类。
datetime 类的对象要么是已知时区的,要么是未知时区的。如果对象包含时区信息,则它是已知时区的;否则,它被归类为未知时区的。date 类对象是未知时区的,而 time 和 datetime 对象是已知时区的。
date
date 对象表示一个日期,包含年、月和日。当前的格里高利历在两个方向上无限期地扩展。
语法
datetime.date(year, month, day)
参数必须是整数,范围如下:
year − MINYEAR <= year <= MAXYEAR
month − 1 <= month <= 12
day − 1 <= day <= 给定月份和年份的天数
如果任何参数的值超出这些范围,则会引发 ValueError。
示例
from datetime import date
date1 = date(2023, 4, 19)
print("Date:", date1)
date2 = date(2023, 4, 31)
它将产生以下**输出**:
Date: 2023-04-19 Traceback (most recent call last): File "C:\Python311\hello.py", line 8, in <module> date2 = date(2023, 4, 31) ValueError: day is out of range for month
date 类属性
date.min − 可表示的最早日期,date(MINYEAR, 1, 1)。
date.max − 可表示的最新日期,date(MAXYEAR, 12, 31)。
date.resolution − 不同 date 对象之间可能的最小差值。
date.year − 包含在 MINYEAR 和 MAXYEAR 之间。
date.month − 包含在 1 和 12 之间。
date.day − 包含在 1 和给定年份给定月份的天数之间。
示例
from datetime import date
# Getting min date
mindate = date.min
print("Minimum Date:", mindate)
# Getting max date
maxdate = date.max
print("Maximum Date:", maxdate)
Date1 = date(2023, 4, 20)
print("Year:", Date1.year)
print("Month:", Date1.month)
print("Day:", Date1.day)
它将产生以下**输出**:
Minimum Date: 0001-01-01 Maximum Date: 9999-12-31 Year: 2023 Month: 4 Day: 20
date 类中的类方法
today() − 返回当前本地日期。
fromtimestamp(timestamp) − 返回与 POSIX 时间戳对应的本地日期,例如 time.time() 返回的日期。
fromordinal(ordinal) − 返回与儒略日对应的日期,其中公元 1 年 1 月 1 日的儒略日为 1。
fromisoformat(date_string) − 返回与任何有效的 ISO 8601 格式的 date_string 对应的日期,序数日期除外。
示例
from datetime import date
print (date.today())
d1=date.fromisoformat('2023-04-20')
print (d1)
d2=date.fromisoformat('20230420')
print (d2)
d3=date.fromisoformat('2023-W16-4')
print (d3)
它将产生以下**输出**:
2023-04-20 2023-04-20 2023-04-20 2023-04-20
date 类中的实例方法
replace() − 通过关键字参数指定的新值替换指定的属性,返回一个新的日期。
timetuple() − 返回 time.struct_time,类似于 time.localtime() 返回的结构。
toordinal() − 返回日期的儒略日,其中公元 1 年 1 月 1 日的儒略日为 1。对于任何日期对象 d,date.fromordinal(d.toordinal()) == d。
weekday() − 返回星期几的整数代码,其中星期一为 0,星期日为 6。
isoweekday() − 返回星期几的整数代码,其中星期一为 1,星期日为 7。
isocalendar() − 返回一个包含三个组件的命名元组对象:年、周和星期几。
isoformat() − 返回一个以 ISO 8601 格式(YYYY-MM-DD)表示日期的字符串。
__str__() − 对于日期 d,str(d) 等效于 d.isoformat()
ctime() − 返回表示日期的字符串
strftime(format) − 返回表示日期的字符串,由显式格式字符串控制。
__format__(format) − 与 date.strftime() 相同。
示例
from datetime import date
d = date.fromordinal(738630) # 738630th day after 1. 1. 0001
print (d)
print (d.timetuple())
# Methods related to formatting string output
print (d.isoformat())
print (d.strftime("%d/%m/%y"))
print (d.strftime("%A %d. %B %Y"))
print (d.ctime())
print ('The {1} is {0:%d}, the {2} is {0:%B}.'.format(d, "day", "month"))
# Methods for to extracting 'components' under different calendars
t = d.timetuple()
for i in t:
print(i)
ic = d.isocalendar()
for i in ic:
print(i)
# A date object is immutable; all operations produce a new object
print (d.replace(month=5))
它将产生以下**输出**:
2023-04-20 time.struct_time(tm_year=2023, tm_mon=4, tm_mday=20, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=110, tm_isdst=-1) 2023-04-20 20/04/23 Thursday 20. April 2023 Thu Apr 20 00:00:00 2023 The day is 20, the month is April. 2023 4 20 0 0 0 3 110 -1 2023 16 4 2023-05-20
time
time 类对象表示一天中的本地时间。它独立于任何特定日期。如果对象包含 tzinfo 详细信息,则它是已知时区的对象。如果为 None,则 time 对象是未知时区的对象。
语法
datetime.time(hour=0, minute=0, second=0, microsecond=0, tzinfo=None)
所有参数都是可选的。tzinfo 可以是 None,也可以是 tzinfo 子类的实例。其余参数必须是以下范围内的整数:
hour − 0 <= hour < 24,
minute − 0 <= minute < 60,
second − 0 <= second < 60,
microsecond − 0 <= microsecond < 1000000
如果任何参数的值超出这些范围,则会引发 ValueError。
示例
from datetime import time
time1 = time(8, 14, 36)
print("Time:", time1)
time2 = time(minute = 12)
print("time", time2)
time3 = time()
print("time", time3)
time4 = time(hour = 26)
它将产生以下**输出**:
Time: 08:14:36 time 00:12:00 time 00:00:00 Traceback (most recent call last): File "/home/cg/root/64b912f27faef/main.py", line 12, intime4 = time(hour = 26) ValueError: hour must be in 0..23
类属性
time.min − 可表示的最早时间,time(0, 0, 0, 0)。
time.max − 可表示的最新时间,time(23, 59, 59, 999999)。
time.resolution − 不同 time 对象之间可能的最小差值。
示例
from datetime import time print(time.min) print(time.max) print (time.resolution)
它将产生以下**输出**:
00:00:00 23:59:59.999999 0:00:00.000001
实例属性
time.hour − 在 range(24) 内
time.minute − 在 range(60) 内
time.second − 在 range(60) 内
time.microsecond − 在 range(1000000) 内
time.tzinfo − time 构造函数的 tzinfo 参数,或 None。
示例
from datetime import time t = time(8,23,45,5000) print(t.hour) print(t.minute) print (t.second) print (t.microsecond)
它将产生以下**输出**:
8 23 455000
实例方法
replace() − 返回具有相同值的时间,但指定关键字参数给出的属性除外。
isoformat() − 返回一个以 ISO 8601 格式表示时间的字符串。
__str__() − 对于时间 t,str(t) 等效于 t.isoformat()。
strftime(format) − 返回一个表示时间的字符串,由显式格式字符串控制。
__format__(format) − 与 time.strftime() 相同。
utcoffset() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.utcoffset(None)。
dst() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.dst(None)。
tzname() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.tzname(None),或引发异常。
datetime
datetime 类对象同时包含日期和时间信息。它假设当前的格里高利历在两个方向上无限期地扩展;就像 time 对象一样,每一天都有 3600*24 秒。
语法
datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0)
year、month 和 day 参数是必需的。
year − MINYEAR <= year <= MAXYEAR,
month − 1 <= month <= 12,
day − 1 <= day <= 给定月份和年份的天数,
hour − 0 <= hour < 24,
minute − 0 <= minute < 60,
second −0 <= second < 60,
microsecond − 0 <= microsecond < 1000000,
fold − 在 [0, 1] 中。
如果任何参数的值超出范围,则会引发 ValueError。
示例
from datetime import datetime dt = datetime(2023, 4, 20) print(dt) dt = datetime(2023, 4, 20, 11, 6, 32, 5000) print(dt)
它将产生以下**输出**:
2023-04-20 00:00:00 2023-04-20 11:06:32.005000
类属性
datetime.min − 可表示的最早 datetime,datetime(MINYEAR, 1, 1, tzinfo=None)。
datetime.max − 可表示的最新 datetime,datetime(MAXYEAR, 12, 31, 23, 59, 59, 999999, tzinfo=None)。
datetime.resolution − 不同 datetime 对象之间可能的最小差值,timedelta(microseconds=1)。
示例
from datetime import datetime
min = datetime.min
print("Min DateTime ", min)
max = datetime.max
print("Max DateTime ", max)
它将产生以下**输出**:
Min DateTime 0001-01-01 00:00:00 Max DateTime 9999-12-31 23:59:59.999999
实例属性
datetime.year − 包含在 MINYEAR 和 MAXYEAR 之间。
datetime.month − 包含在 1 和 12 之间。
datetime.day − 包含在 1 和给定年份给定月份的天数之间。
datetime.hour − 在 range(24) 内
datetime.minute − 在 range(60) 内
datetime.second − 在 range(60) 内
datetime.microsecond − 在 range(1000000) 内。
datetime.tzinfo − 传递给 datetime 构造函数的 tzinfo 对象,如果没有传递则为 None。
datetime.fold − 在 [0, 1] 中。用于在重复的时间间隔内消除歧义。
示例
from datetime import datetime
dt = datetime.now()
print("Day: ", dt.day)
print("Month: ", dt.month)
print("Year: ", dt.year)
print("Hour: ", dt.hour)
print("Minute: ", dt.minute)
print("Second: ", dt.second)
它将产生以下**输出**:
Day: 20 Month: 4 Year: 2023 Hour: 15 Minute: 5 Second: 52
类方法
today() − 返回当前本地 datetime,tzinfo 为 None。
now(tz=None) − 返回当前本地日期和时间。
utcnow() − 返回当前 UTC 日期和时间,tzinfo 为 None。
utcfromtimestamp(timestamp) − 返回与 POSIX 时间戳对应的 UTC datetime,tzinfo 为 None。
fromtimestamp(timestamp, timezone.utc) − 在符合 POSIX 标准的平台上,它等效于 datetime(1970, 1, 1, tzinfo=timezone.utc) + timedelta(seconds=timestamp)
fromordinal(ordinal) − 返回与儒略日对应的 datetime,其中公元 1 年 1 月 1 日的儒略日为 1。
fromisoformat(date_string) − 返回与任何有效的 ISO 8601 格式的 date_string 对应的 datetime。
实例方法
date() − 返回具有相同年、月和日的 date 对象。
time() − 返回具有相同小时、分钟、秒、微秒和 fold 的 time 对象。
timetz() − 返回具有相同小时、分钟、秒、微秒、fold 和 tzinfo 属性的 time 对象。另请参见方法 time()。
replace() − 返回具有相同属性的 datetime,但指定关键字参数给出的属性除外。
astimezone(tz=None) − 返回一个具有新的 tzinfo 属性 tz 的 datetime 对象。
utcoffset() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.utcoffset(self)。
dst() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.dst(self)。
tzname() − 如果 tzinfo 为 None,则返回 None,否则返回 self.tzinfo.tzname(self)。
timetuple() − 返回 time.struct_time,类似于 time.localtime() 返回的结构。
datetime.toordinal() − 返回日期的儒略日。
timestamp() − 返回与 datetime 实例对应的 POSIX 时间戳。
isoweekday() − 返回星期几的整数代码,其中星期一为 1,星期日为 7。
isocalendar() − 返回一个包含三个组件的命名元组:年、周和星期几。
isoformat(sep='T', timespec='auto') − 返回一个以 ISO 8601 格式表示日期和时间的字符串。
__str__() − 对于 datetime 实例 d,str(d) 等效于 d.isoformat(' ')。
ctime() − 返回一个表示日期和时间的字符串。
strftime(format) − 返回一个表示日期和时间的字符串,由显式格式字符串控制。
__format__(format) − 与 strftime() 相同。
示例
from datetime import datetime, date, time, timezone
# Using datetime.combine()
d = date(2022, 4, 20)
t = time(12, 30)
datetime.combine(d, t)
# Using datetime.now()
d = datetime.now()
print (d)
# Using datetime.strptime()
dt = datetime.strptime("23/04/20 16:30", "%d/%m/%y %H:%M")
# Using datetime.timetuple() to get tuple of all attributes
tt = dt.timetuple()
for it in tt:
print(it)
# Date in ISO format
ic = dt.isocalendar()
for it in ic:
print(it)
它将产生以下**输出**:
2023-04-20 15:12:49.816343 2020 4 23 16 30 0 3 114 -1 2020 17 4
timedelta
timedelta 对象表示两个日期或两个时间对象之间的时间差。
语法
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
在内部,属性以天、秒和微秒存储。其他参数将转换为这些单位:
毫秒转换为 1000 微秒。
分钟转换为 60 秒。
小时转换为 3600 秒。
星期转换为 7 天。
然后对天、秒和微秒进行标准化,使其表示唯一。
示例
以下示例显示 Python 内部只存储天、秒和微秒。
from datetime import timedelta delta = timedelta( days=100, seconds=27, microseconds=10, milliseconds=29000, minutes=5, hours=12, weeks=2 ) # Only days, seconds, and microseconds remain print (delta)
它将产生以下**输出**:
114 days, 12:05:56.000010
示例
以下示例演示如何将 timedelta 对象添加到 datetime 对象。
from datetime import datetime, timedelta
date1 = datetime.now()
date2= date1+timedelta(days = 4)
print("Date after 4 days:", date2)
date3 = date1-timedelta(15)
print("Date before 15 days:", date3)
它将产生以下**输出**:
Date after 4 days: 2023-04-24 18:05:39.509905 Date before 15 days: 2023-04-05 18:05:39.509905
类属性
timedelta.min − 最小的 timedelta 对象,timedelta(-999999999)。
timedelta.max − 最大的 timedelta 对象,timedelta(days=999999999, hours=23, minutes=59, seconds=59, microseconds=999999)。
timedelta.resolution − 不相等 timedelta 对象之间可能的最小差值,timedelta(microseconds=1)
示例
from datetime import timedelta
# Getting minimum value
min = timedelta.min
print("Minimum value:", min)
max = timedelta.max
print("Maximum value", max)
它将产生以下**输出**:
Minimum value: -999999999 days, 0:00:00 Maximum value 999999999 days, 23:59:59.999999
实例属性
由于内部只存储天、秒和微秒,因此这些是timedelta对象的唯一实例属性。
days − 包含 -999999999 到 999999999
seconds − 包含 0 到 86399
microseconds − 包含 0 到 999999
实例方法
timedelta.total_seconds() − 返回持续时间内包含的总秒数。
示例
from datetime import timedelta year = timedelta(days=365) years = 5 * year print (years) print (years.days // 365) 646 year_1 = years // 5 print(year_1.days)
它将产生以下**输出**:
1825 days, 0:00:00 5 365
Python - 数学
Python 的标准库提供 math 模块。此模块包含许多预定义函数,用于执行不同的数学运算。这些函数不适用于复数。cmath 模块包含复数的数学函数。
math 模块中的函数
以下是 math 模块中可用函数的列表:
| 序号 | 方法和说明 |
|---|---|
| 1 | acos (x) 返回 x 的反余弦值(以弧度表示)。 |
| 2 | acosh (x) 返回 x 的反双曲余弦值。 |
| 3 | asin 返回 x 的反正弦值(以弧度表示)。 |
| 4 | asinh (x) 返回 x 的反双曲正弦值。 |
| 5 | atan 返回 x 的反正切值(以弧度表示)。 |
| 6 | atan2 返回 atan(y/x)(以弧度表示)。 |
| 7 | atanh (x) 返回 x 的反双曲正切值。 |
| 8 | cbrt (x) 返回 x 的立方根。 |
| 9 | ceil(x) x 的上界:不小于 x 的最小整数。 |
| 10 | comb (x,y) 返回从 y 个项目中选择 x 个项目的方法数(可重复选择,无序)。 |
| 11 | copysign(x,y) 返回一个浮点数,其大小与 x 相同,但符号与 y 相同。 |
| 12 | cos (x) 返回 x 弧度的余弦值。 |
| 13 | cosh (x) 返回 x 的双曲余弦值。 |
| 14 | degrees 将角度 x 从弧度转换为度。 |
| 15 | dist (x,y) 返回两点 x 和 y 之间的欧几里得距离。 |
| 16 | e 数学常数 e = 2.718281...,精确到可用精度。 |
| 17 | erf (x) 返回 x 处的误差函数。 |
| 18 | erfc (x) 返回 x 处的互补误差函数。 |
| 19 | exp (x) 返回 e 的 x 次幂,其中 e = 2.718281... |
| 20 | exp2 (x) 返回 2 的 x 次幂。 |
| 21 | expm1 (x) 返回 e 的 x 次幂减 1。 |
| 22 | fabs(x) x 的绝对值(浮点数)。 |
| 23 | factorial(x) 返回 x 的阶乘(整数)。 |
| 24 | floor (x) x 的下界:不大于 x 的最大整数。 |
| 25 | fmod (x,y) 始终返回浮点数,类似于 x%y |
| 26 | frexp (x) 返回给定数字 x 的尾数和指数。 |
| 27 | fsum (iterable) 任何可迭代对象中所有数字的和,返回浮点数。 |
| 28 | gamma (x) 返回 x 处的伽马函数。 |
| 29 | gcd (x,y,z) 返回指定整数参数的最大公约数。 |
| 30 | hypot 返回欧几里得范数,sqrt(x*x + y*y)。 |
| 31 | inf 浮点正无穷大。等效于 float('inf') 的输出。 |
| 32 | isclose (x,y) 如果值 x 和 y 彼此接近,则返回 True,否则返回 False。 |
| 33 | isfinite (x) 如果既不是无穷大也不是 NaN,则返回 True,否则返回 False。 |
| 34 | isinf (x) 如果 x 是正无穷大或负无穷大,则返回 True,否则返回 False。 |
| 35 | isnan (x) 如果 x 是 NaN(非数字),则返回 True,否则返回 False。 |
| 36 | isqrt (x) 返回非负整数 x 的整数平方根。 |
| 37 | lcm (x1, x2, ..) 返回指定整数参数的最小公倍数。 |
| 38 | ldexp (x,y) 返回 x * (2**y)。这是函数 frexp() 的逆函数。 |
| 39 | lgamma (x) 返回 x 处的伽马函数绝对值的自然对数。 |
| 40 | log (x) 返回 x 的自然对数(以 e 为底)。 |
| 41 | log10 (x) 返回 x 的以 10 为底的对数。 |
| 42 | log1p (x) 返回 1+x 的自然对数(以 e 为底)。 |
| 43 | log2 (x) 返回 x 的以 2 为底的对数。 |
| 44 | modf (x) x 的小数部分和整数部分组成的两个元素的元组。两部分都与 x 符号相同。整数部分作为浮点数返回。 |
| 45 | nan 浮点“非数字”(NaN)值。 |
| 46 | nextafter (x,y) 返回 x 之后朝向 y 的下一个浮点值。 |
| 47 | perm (x,y) 返回从 y 个项目中选择 x 个项目的方法数(不可重复选择,有序)。 |
| 48 | pi 数学常数 π = 3.141592...,精确到可用精度。 |
| 49 | pow (x,y) 返回 x 的 y 次幂。 |
| 50 | prod (iterable) 返回输入可迭代对象中所有元素的乘积。 |
| 51 | radians 将角度 x 从度转换为弧度。 |
| 52 | remainder (x,y) 返回 x 对 y 的余数。 |
| 53 | sin (x) 返回 x 弧度的正弦值。 |
| 54 | sinh (x) 返回 x 的反双曲正弦值。 |
| 55 | sqrt (x) 返回 x 的平方根。 |
| 56 | tan (x) 返回 x 弧度的正切值。 |
| 57 | tanh (x) 返回 x 的双曲正切值。 |
| 58 | tau 数学常数 τ = 6.283185...,精确到可用精度。 |
| 59 | trunc (x) 返回去除小数部分后的 x,保留整数部分。 |
| 60 | ulp 返回浮点数 x 的最低有效位的数值。 |
这些函数可以分为以下几类:
Python - 迭代器
Python 中的迭代器是一个表示数据流的对象。它遵循迭代器协议,该协议要求它支持 __iter__() 和 __next__() 方法。Python 的内置方法 iter() 实现 __iter__() 方法。它接收一个可迭代对象并返回迭代器对象。内置的 next() 函数在内部调用迭代器的 __next__() 方法,返回流中的连续项目。当没有更多数据可用时,将引发 StopIteration 异常。
Python 在处理集合数据类型(如列表、元组或字符串)时隐式地使用迭代器。这就是为什么这些数据类型被称为可迭代对象的原因。我们通常使用 for 循环迭代可迭代对象,如下所示:
for element in sequence: print (element)
Python 的内置方法 iter() 实现 __iter__() 方法。它接收一个可迭代对象并返回迭代器对象。
示例
以下代码从序列类型列表、字符串和元组中获取迭代器对象。iter() 函数还从字典中返回键迭代器。但是,int 不是可迭代的,因此它会产生 TypeError。
print (iter("aa"))
print (iter([1,2,3]))
print (iter((1,2,3)))
print (iter({}))
print (iter(100))
它将产生以下**输出**:
<str_ascii_iterator object at 0x000001BB03FFAB60>
<list_iterator object at 0x000001BB03FFAB60>
<tuple_iterator object at 0x000001BB03FFAB60>
<dict_keyiterator object at 0x000001BB04181670>
Traceback (most recent call last):
File "C:\Users\user\example.py", line 5, in <module>
print (iter(100))
^^^^^^^^^
TypeError: 'int' object is not iterable
迭代器对象具有 __next__() 方法。每次调用它时,它都会返回迭代器流中的下一个元素。当流耗尽时,会引发 StopIteration 错误。对 next() 函数的调用等同于调用迭代器对象的 __next__() 方法。
示例
it = iter([1,2,3]) print (next(it)) print (it.__next__()) print (it.__next__()) print (next(it))
它将产生以下**输出**:
1
2
3
Traceback (most recent call last):
File "C:\Users\user\example.py", line 5, in <module>
print (next(it))
^^^^^^^^
StopIteration
示例
您可以使用异常处理机制来捕获 StopIteration。
it = iter([1,2,3, 4, 5])
print (next(it))
while True:
try:
no = next(it)
print (no)
except StopIteration:
break
它将产生以下**输出**:
1 2 3 4 5
要在 Python 中定义自定义迭代器类,该类必须定义 __iter__() 和 __next__() 方法。
在下面的示例中,Oddnumbers 是一个实现 __iter__() 和 __next__() 方法的类。每次调用 __next__() 时,数字都会递增 2,从而在 1 到 10 的范围内流式传输奇数。
示例
class Oddnumbers:
def __init__(self, end_range):
self.start = -1
self.end = end_range
def __iter__(self):
return self
def __next__(self):
if self.start < self.end-1:
self.start += 2
return self.start
else:
raise StopIteration
countiter = Oddnumbers(10)
while True:
try:
no = next(countiter)
print (no)
except StopIteration:
break
它将产生以下**输出**:
1 3 5 7 9
异步迭代器
从 Python 3.10 版本开始,添加了两个内置函数 aiter() 和 anext()。aiter() 函数返回一个异步迭代器对象。它是经典迭代器的异步对应部分。任何异步迭代器都必须支持 __aiter__() 和 __anext__() 方法。这两个方法由这两个内置函数在内部调用。
与经典迭代器一样,异步迭代器提供一个对象流。当流耗尽时,将引发 StopAsyncIteration 异常。
在下面给出的示例中,声明了一个异步迭代器类 Oddnumbers。它实现了 __aiter__() 和 __anext__() 方法。每次迭代都会返回下一个奇数,程序会等待一秒钟,以便它可以异步执行任何其他进程。
与常规函数不同,异步函数被称为协程,并使用 asyncio.run() 方法执行。main() 协程包含一个 while 循环,它连续获取奇数,如果数字超过 9,则引发 StopAsyncIteration。
示例
import asyncio
class Oddnumbers():
def __init__(self):
self.start = -1
def __aiter__(self):
return self
async def __anext__(self):
if self.start >= 9:
raise StopAsyncIteration
self.start += 2
await asyncio.sleep(1)
return self.start
async def main():
it = Oddnumbers()
while True:
try:
awaitable = anext(it)
result = await awaitable
print(result)
except StopAsyncIteration:
break
asyncio.run(main())
它将产生以下**输出**:
1 3 5 7 9
Python - 生成器
Python 中的生成器是一种特殊的函数,它返回一个迭代器对象。它看起来类似于普通的 Python 函数,因为它的定义也以 def 关键字开头。但是,它在末尾不使用 return 语句,而是使用 yield 关键字。
语法
def generator(): . . . . . . yield obj it = generator() next(it) . . .
函数末尾的 return 语句表示函数体的执行结束,函数中的所有局部变量都将超出范围。如果再次调用该函数,则会重新初始化局部变量。
生成器函数的行为有所不同。它第一次像普通函数一样被调用,但是当它的 yield 语句出现时,它的执行会暂时暂停,并将控制权转移回去。产生的结果由调用者使用。对 next() 内置函数的调用会从暂停的地方重新启动生成器的执行,并为迭代器生成下一个对象。该循环会重复,因为后续的 yield 会提供迭代器中的下一个项目,直到它耗尽。
示例1
下面代码中的函数是一个生成器,它连续地从 1 到 5 生成整数。当被调用时,它返回一个迭代器。每次调用 next() 时,控制权都会转移回生成器并获取下一个整数。
def generator(num):
for x in range(1, num+1):
yield x
return
it = generator(5)
while True:
try:
print (next(it))
except StopIteration:
break
它将产生以下**输出**:
1 2 3 4 5
生成器函数返回一个动态迭代器。因此,它比从 Python 序列对象获得的普通迭代器更节省内存。例如,如果要获取斐波那契数列中的前 n 个数字。您可以编写一个普通函数并构建一个斐波那契数列表,然后使用循环迭代该列表。
示例2
下面是获取斐波那契数列表的普通函数:
def fibonacci(n):
fibo = []
a, b = 0, 1
while True:
c=a+b
if c>=n:
break
fibo.append(c)
a, b = b, c
return fibo
f = fibonacci(10)
for i in f:
print (i)
它将产生以下输出:
1 2 3 5 8
上面的代码将所有斐波那契数列数字收集到一个列表中,然后使用循环遍历该列表。想象一下,我们想要一个很大的斐波那契数列。在这种情况下,所有数字都必须收集到一个列表中,这需要大量的内存。这就是生成器有用的地方,因为它生成列表中的单个数字并将其提供给使用者。
示例3
以下代码是基于生成器的斐波那契数列表解决方案:
def fibonacci(n):
a, b = 0, 1
while True:
c=a+b
if c>=n:
break
yield c
a, b = b, c
return
f = fibonacci(10)
while True:
try:
print (next(f))
except StopIteration:
break
异步生成器
异步生成器是一个返回异步迭代器的协程。协程是用 async 关键字定义的 Python 函数,它可以调度和等待其他协程和任务。就像普通的生成器一样,异步生成器每次调用 anext() 函数(而不是 next() 函数)时都会生成迭代器中的增量项目。
语法
async def generator(): . . . . . . yield obj it = generator() anext(it) . . .
示例 4
以下代码演示了一个协程生成器,它在async for循环的每次迭代中都会生成递增的整数。
import asyncio
async def async_generator(x):
for i in range(1, x+1):
await asyncio.sleep(1)
yield i
async def main():
async for item in async_generator(5):
print(item)
asyncio.run(main())
它将产生以下**输出**:
1 2 3 4 5
示例5
现在让我们为斐波那契数编写一个异步生成器。为了模拟协程中的某些异步任务,程序在生成下一个数字之前调用 sleep() 方法持续 1 秒。结果,您将在延迟一秒后在屏幕上看到打印的数字。
import asyncio
async def fibonacci(n):
a, b = 0, 1
while True:
c=a+b
if c>=n:
break
await asyncio.sleep(1)
yield c
a, b = b, c
return
async def main():
f = fibonacci(10)
async for num in f:
print (num)
asyncio.run(main())
它将产生以下**输出**:
1 2 3 5 8
Python - 闭包
本章我们来讨论Python中的闭包概念。在Python中,函数被称为一等对象。就像基本数据类型一样,函数也可以被赋值给变量,或者作为参数传递。
嵌套函数
你也可以嵌套声明函数,即在一个函数的主体内部定义另一个函数。
示例
def functionA():
print ("Outer function")
def functionB():
print ("Inner function")
functionB()
functionA()
它将产生以下**输出**:
Outer function Inner function
在上面的例子中,函数B在函数A内部定义。内部函数然后在外部函数的作用域内被调用。
如果外部函数接收任何参数,它可以传递给内部函数。
def functionA(name):
print ("Outer function")
def functionB():
print ("Inner function")
print ("Hi {}".format(name))
functionB()
functionA("Python")
它将产生以下输出:
Outer function Inner function Hi Python
什么是闭包?
闭包是一个嵌套函数,它可以访问来自封闭函数的变量,而封闭函数已经完成了它的执行。这样的变量不会绑定在局部作用域中。要使用不可变变量(数字或字符串),我们必须使用`nonlocal`关键字。
Python闭包的主要优点是,它可以帮助我们避免使用全局变量,并提供某种程度的数据隐藏。它们常用于Python装饰器。
示例
def functionA(name):
name ="New name"
def functionB():
print (name)
return functionB
myfunction = functionA("My name")
myfunction()
它将产生以下**输出**:
New name
在上面的例子中,我们有一个函数A,它创建并返回另一个函数functionB。嵌套函数B是闭包。
外部函数A返回一个函数B,并将其赋值给myfunction变量。即使它已经完成了执行,打印闭包仍然可以访问name变量。
`nonlocal`关键字
在Python中,`nonlocal`关键字允许访问局部作用域之外的变量。这在闭包中用于修改存在于外部变量作用域中的不可变变量。
示例
def functionA():
counter =0
def functionB():
nonlocal counter
counter+=1
return counter
return functionB
myfunction = functionA()
retval = myfunction()
print ("Counter:", retval)
retval = myfunction()
print ("Counter:", retval)
retval = myfunction()
print ("Counter:", retval)
它将产生以下**输出**:
Counter: 1 Counter: 2 Counter: 3
Python - 装饰器
Python中的装饰器是一个函数,它接收另一个函数作为参数。参数函数是被装饰器装饰的函数。装饰器扩展了参数函数的行为,而无需实际修改它。
本章我们将学习如何使用Python装饰器。
Python中的函数是一等对象。这意味着它可以作为参数传递给另一个函数,就像其他数据类型(如数字、字符串或列表等)一样。也可以在一个函数内部定义另一个函数。这样的函数称为嵌套函数。此外,函数也可以返回其他函数。
语法
装饰器函数的典型定义如下:
def decorator(arg_function): #arg_function to be decorated
def nested_function():
#this wraps the arg_function and extends its behaviour
#call arg_function
arg_function()
return nested_function
这是一个普通的Python函数:
def function():
print ("hello")
现在你可以通过将它传递给装饰器来装饰这个函数,以扩展它的行为:
function=decorator(function)
如果现在执行这个函数,它将显示由装饰器扩展的输出。
示例1
下面的代码是一个简单的装饰器示例:
def my_function(x):
print("The number is=",x)
def my_decorator(some_function,num):
def wrapper(num):
print("Inside wrapper to check odd/even")
if num%2 == 0:
ret= "Even"
else:
ret= "Odd!"
some_function(num)
return ret
print ("wrapper function is called")
return wrapper
no=10
my_function = my_decorator(my_function, no)
print ("It is ",my_function(no))
`my_function()` 只打印接收到的数字。但是,通过将其传递给 `my_decorator` 来修改其行为。内部函数接收数字并返回它是奇数还是偶数。上述代码的输出是:
wrapper function is called Inside wrapper to check odd/even The number is= 10 It is Even
示例2
装饰函数的一种优雅方法是在其定义之前,使用 `@` 符号加上装饰器的名称。上面的例子使用这种表示法重写:
def my_decorator(some_function):
def wrapper(num):
print("Inside wrapper to check odd/even")
if num%2 == 0:
ret= "Even"
else:
ret= "Odd!"
some_function(num)
return ret
print ("wrapper function is called")
return wrapper
@my_decorator
def my_function(x):
print("The number is=",x)
no=10
print ("It is ",my_function(no))
Python的标准库定义了以下内置装饰器:
`@classmethod` 装饰器
`classmethod` 是一个内置函数。它将方法转换为类方法。类方法与实例方法不同。在类中定义的实例方法由其对象调用。该方法接收一个由 `self` 引用的隐式对象。另一方面,类方法隐式地接收类本身作为第一个参数。
语法
要声明类方法,使用以下装饰器表示法:
class Myclass: @classmethod def mymethod(cls): #....
`@classmethod` 的形式如前所述是函数装饰器。`mymethod` 接收对类的引用。它可以由类及其对象调用。这意味着 `Myclass.mymethod` 和 `Myclass().mymethod` 都是有效的调用。
示例3
让我们通过以下示例了解类方法的行为:
class counter:
count=0
def __init__(self):
print ("init called by ", self)
counter.count=counter.count+1
print ("count=",counter.count)
@classmethod
def showcount(cls):
print ("called by ",cls)
print ("count=",cls.count)
c1=counter()
c2=counter()
print ("class method called by object")
c1.showcount()
print ("class method called by class")
counter.showcount()
在类定义中,`count` 是一个类属性。`__init__()` 方法是构造函数,显然是一个实例方法,因为它接收 `self` 作为对象引用。声明的每个对象都会调用此方法并将 `count` 加 1。
`@classmethod` 装饰器将 `showcount()` 方法转换为类方法,即使它是被其对象调用,它也接收对类的引用作为参数。即使 `c1` 对象调用 `showcount`,它也会显示 `counter` 类的引用。
它将显示以下**输出**:
init called by <__main__.counter object at 0x000001D32DB4F0F0> count= 1 init called by <__main__.counter object at 0x000001D32DAC8710> count= 2 class method called by object called by <class '__main__.counter'> count= 2 class method called by class called by <class '__main__.counter'>
`@staticmethod` 装饰器
`staticmethod` 也是Python标准库中的内置函数。它将方法转换为静态方法。静态方法无论是由类的实例还是类本身调用,都不会接收任何引用参数。在类中声明静态方法使用以下表示法:
语法
class Myclass: @staticmethod def mymethod(): #....
即使 `Myclass.mymethod` 和 `Myclass().mymethod` 都是有效的调用,静态方法也不会接收任何引用。
示例 4
`counter` 类修改如下:
class counter:
count=0
def __init__(self):
print ("init called by ", self)
counter.count=counter.count+1
print ("count=",counter.count)
@staticmethod
def showcount():
print ("count=",counter.count)
c1=counter()
c2=counter()
print ("class method called by object")
c1.showcount()
print ("class method called by class")
counter.showcount()
和以前一样,在 `__init__()` 方法内部声明每个对象时,类属性 `count` 会递增。但是,由于 `mymethod()` 是一个静态方法,它既不接收 `self` 参数也不接收 `cls` 参数。因此,类属性 `count` 的值使用对 `counter` 的显式引用显示。
上述代码的**输出**如下:
init called by <__main__.counter object at 0x000002512EDCF0B8> count= 1 init called by <__main__.counter object at 0x000002512ED48668> count= 2 class method called by object count= 2 class method called by class count= 2
`@property` 装饰器
Python 的 `property()` 内置函数是访问类实例变量的接口。`@property` 装饰器将实例方法转换为与同名只读属性的“getter”,并将属性的文档字符串设置为“获取实例变量的当前值”。
您可以使用以下三个装饰器来定义属性:
**`@property`** - 将方法声明为属性。
**`@
.setter`** - 指定用于设置属性值的属性的 setter 方法。 **`@
.deleter`** - 指定作为删除属性的属性的删除方法。
`property()` 函数返回的属性对象具有 getter、setter 和删除方法。
property(fget=None, fset=None, fdel=None, doc=None)
`fget` 参数是 getter 方法,`fset` 是 setter 方法。它可以选择具有 `fdel` 作为删除对象的方法,而 `doc` 是文档字符串。
属性对象的 setter 和 getter 也可以使用以下语法赋值。
speed = property() speed=speed.getter(speed, get_speed) speed=speed.setter(speed, set_speed)
其中 `get_speed()` 和 `set_speeds()` 是用于检索和设置 `Car` 类中实例变量 `speed` 值的实例方法。
上述语句可以使用 `@property` 装饰器实现。使用该装饰器,`car` 类被重写为:
class car:
def __init__(self, speed=40):
self._speed=speed
return
@property
def speed(self):
return self._speed
@speed.setter
def speed(self, speed):
if speed<0 or speed>100:
print ("speed limit 0 to 100")
return
self._speed=speed
return
c1=car()
print (c1.speed) #calls getter
c1.speed=60 #calls setter
属性装饰器是一种非常方便且推荐的处理实例属性的方法。
Python - 递归
一个调用自身的函数称为递归函数。当某个问题用自身来定义时,使用此方法。虽然这涉及迭代,但使用迭代方法来解决此问题可能会很繁琐。递归方法为看似复杂的问题提供了一个非常简洁的解决方案。
递归最流行的例子是阶乘的计算。数学上阶乘定义为:
n! = n × (n-1)!
可以看出,我们使用阶乘本身来定义阶乘。因此,这是一个编写递归函数的合适案例。让我们展开上述定义来计算 5 的阶乘值。
5! = 5 × 4! 5 × 4 × 3! 5 × 4 × 3 × 2! 5 × 4 × 3 × 2 × 1! 5 × 4 × 3 × 2 × 1 = 120
虽然我们可以使用循环执行此计算,但它的递归函数通过递减数字直到达到 1 来连续调用它。
示例1
以下示例显示了如何使用递归函数来计算阶乘:
def factorial(n):
if n == 1:
print (n)
return 1
else:
print (n,'*', end=' ')
return n * factorial(n-1)
print ('factorial of 5=', factorial(5))
它将产生以下**输出**:
5 * 4 * 3 * 2 * 1 factorial of 5= 120
让我们再看一个例子来了解递归是如何工作的。手头的问题是检查给定数字是否在一个列表中。
虽然我们可以使用 for 循环并比较每个数字来对列表中的某个数字进行顺序搜索,但顺序搜索效率不高,尤其是在列表太大时。二分查找算法检查索引“high”是否大于索引“low”。根据“mid”变量中存在的值,再次调用函数以搜索元素。
我们有一个按升序排列的数字列表。然后我们找到列表的中点,并根据所需数字是否小于或大于中点的数字,将检查限制在中点的左侧或右侧。
下图显示了二分查找的工作原理:
示例2
以下代码实现了递归二分查找技术:
def bsearch(my_list, low, high, elem):
if high >= low:
mid = (high + low) // 2
if my_list[mid] == elem:
return mid
elif my_list[mid] > elem:
return bsearch(my_list, low, mid - 1, elem)
else:
return bsearch(my_list, mid + 1, high, elem)
else:
return -1
my_list = [5,12,23, 45, 49, 67, 71, 77, 82]
num = 67
print("The list is")
print(my_list)
print ("Check for number:", num)
my_result = bsearch(my_list,0,len(my_list)-1,num)
if my_result != -1:
print("Element found at index ", str(my_result))
else:
print("Element not found!")
它将产生以下**输出**:
The list is [5, 12, 23, 45, 49, 67, 71, 77, 82] Check for number: 67 Element found at index 5
您可以检查列表中不同数字的输出,以及列表中不存在的数字。
Python - 正则表达式
正则表达式是一系列特殊的字符,它可以帮助您使用包含在模式中的特殊语法来匹配或查找其他字符串或字符串集。正则表达式也称为regex,是一系列字符,用于定义文本中的搜索模式。通常称为regex或regexp;它是一系列字符,用于指定文本中的匹配模式。通常,此类模式由字符串搜索算法用于字符串的“查找”或“查找和替换”操作,或用于输入验证。
数据科学项目中的大规模文本处理需要对文本数据进行操作。许多编程语言(包括Python)都支持正则表达式处理。Python的标准库为此目的提供了`re`模块。
由于`re`模块中定义的大多数函数都使用原始字符串,让我们首先了解什么是原始字符串。
原始字符串
正则表达式使用反斜杠字符('\')来指示特殊形式或允许使用特殊字符而不调用它们的特殊含义。另一方面,Python使用相同的字符作为转义字符。因此,Python使用原始字符串表示法。
如果字符串在引号符号之前以r或R为前缀,则它成为原始字符串。因此,'Hello'是一个普通字符串,而r'Hello'是一个原始字符串。
>>> normal="Hello" >>> print (normal) Hello >>> raw=r"Hello" >>> print (raw) Hello
在正常情况下,两者之间没有区别。但是,当转义字符嵌入到字符串中时,普通字符串实际上会解释转义序列,而原始字符串不会处理转义字符。
>>> normal="Hello\nWorld" >>> print (normal) Hello World >>> raw=r"Hello\nWorld" >>> print (raw) Hello\nWorld
在上面的例子中,当打印普通字符串时,转义字符'\n'被处理以引入换行符。但是,由于原始字符串运算符'r',转义字符的效果不会根据其含义进行转换。
元字符
大多数字母和字符都会与自身匹配。但是,某些字符是特殊的元字符,不与自身匹配。元字符是具有特殊含义的字符,类似于通配符中的 *。
以下是元字符的完整列表:
. ^ $ * + ? { } [ ] \ | ( )
方括号符号 [ 和 ] 表示您希望匹配的一组字符。字符可以单独列出,也可以作为字符范围列出,用“-”分隔。
| 序号 | 元字符 & 描述 |
|---|---|
| 1 | [abc] 匹配字符 a、b 或 c 中的任何一个 |
| 2 | [a-c] 使用范围表示相同的字符集。 |
| 3 | [a-z] 仅匹配小写字母。 |
| 4 | [0-9] 仅匹配数字。 |
| 5 | '^' 对 [] 中的字符集取反。[^5] 将匹配除 '5' 之外的任何字符。 |
'\' 是转义元字符。当后面跟着各种字符时,它会形成各种特殊的序列。如果您需要匹配 [ 或 \,可以在它们前面加上反斜杠以消除它们的特殊含义:\[ 或 \\。
下面列出了以 '\' 开头的此类特殊序列表示的预定义字符集:
| 序号 | 元字符 & 描述 |
|---|---|
| 1 | \d 匹配任何十进制数字;这等效于类 [0-9]。 |
| 2 | \D 匹配任何非数字字符;这等效于类 [^0-9]。 |
| 3 | \s匹配任何空白字符;这等效于类 [\t\n\r\f\v]。 |
| 4 | \S 匹配任何非空白字符;这等效于类 [^\t\n\r\f\v]。 |
| 5 | \w 匹配任何字母数字字符;这等效于类 [a-zA-Z0-9_]。 |
| 6 | \W 匹配任何非字母数字字符。等效于类 [^a-zA-Z0-9_]。 |
| 7 | . 匹配除换行符 '\n' 之外的任何单个字符。 |
| 8 | ? 匹配其左侧模式的 0 次或 1 次出现 |
| 9 | + 匹配其左侧模式的 1 次或多次出现 |
| 10 | * 匹配其左侧模式的 0 次或多次出现 |
| 11 | \b 单词和非单词之间的边界,/B 与 /b 相反 |
| 12 | [..] 匹配方括号中的任何单个字符,[^..] 匹配方括号中不存在的任何单个字符。 |
| 13 | \ 它用于特殊含义的字符,例如 \. 用于匹配句点或 \+ 用于匹配加号。 |
| 14 | {n,m} 匹配前面至少 n 次最多 m 次出现 |
| 15 | a|b 匹配 a 或 b |
Python 的 re 模块提供了用于查找匹配项、搜索模式以及用其他字符串替换匹配字符串等的有用函数。
re.match() 函数
此函数尝试使用可选的 flags 在 string 的开头匹配 RE pattern。
以下是此函数的语法:
re.match(pattern, string, flags=0)
以下是参数的描述:
| 序号 | 参数 & 描述 |
|---|---|
| 1 | pattern 这是要匹配的正则表达式。 |
| 2 | String 这是字符串,将在其中搜索在字符串开头匹配模式。 |
| 3 | Flags 您可以使用按位 OR (|) 指定不同的标志。这些是修饰符,在下表中列出。 |
re.match 函数在成功时返回一个匹配对象,失败时返回None。匹配对象实例包含有关匹配的信息:它从哪里开始和结束,它匹配的子字符串等。
匹配对象的 start() 方法返回模式在字符串中的起始位置,end() 返回结束位置。
如果找不到模式,则匹配对象为 None。
我们使用匹配对象的 group(num) 或 groups() 函数来获取匹配的表达式。
| 序号 | 匹配对象方法 & 描述 |
|---|---|
| 1 | group(num=0)此方法返回整个匹配项(或特定的子组 num) |
| 2 | groups()此方法在一个元组中返回所有匹配的子组(如果没有,则为空) |
示例
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'Cats', line)
print (matchObj.start(), matchObj.end())
print ("matchObj.group() : ", matchObj.group())
它将产生以下**输出**:
0 4 matchObj.group() : Cats
re.search() 函数
此函数使用可选的 flags 搜索 string 中 RE pattern 的第一次出现。
以下是此函数的语法:
re.search(pattern, string, flags=0)
以下是参数的描述:
| 序号 | 参数 & 描述 |
|---|---|
| 1 | Pattern 这是要匹配的正则表达式。 |
| 2 | String 这是字符串,将在其中搜索在字符串任何位置匹配模式。 |
| 3 | Flags 您可以使用按位 OR (|) 指定不同的标志。这些是修饰符,在下表中列出。 |
re.search 函数在成功时返回一个匹配对象,失败时返回none。我们使用匹配对象的 group(num) 或 groups() 函数来获取匹配的表达式。
| 序号 | 匹配对象方法 & 描述 |
|---|---|
| 1 | group(num=0)此方法返回整个匹配项(或特定的子组 num) |
| 2 | groups()此方法在一个元组中返回所有匹配的子组(如果没有,则为空) |
示例
import re
line = "Cats are smarter than dogs"
matchObj = re.search( r'than', line)
print (matchObj.start(), matchObj.end())
print ("matchObj.group() : ", matchObj.group())
它将产生以下**输出**:
17 21 matchObj.group() : than
匹配与搜索
Python 提供了两种基于正则表达式的不同基本操作:match 只检查字符串开头的匹配项,而 search 检查字符串中任何位置的匹配项(这是 Perl 默认执行的操作)。
示例
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print ("search --> searchObj.group() : ", searchObj.group())
else:
print ("Nothing found!!")
执行上述代码时,它会产生以下输出:
No match!! search --> matchObj.group() : dogs
re.findall() 函数
findall() 函数返回字符串中模式的所有不重叠匹配项,作为一个字符串或元组列表。字符串从左到右扫描,匹配项按找到的顺序返回。结果中包含空匹配项。
语法
re.findall(pattern, string, flags=0)
参数
| 序号 | 参数 & 描述 |
|---|---|
| 1 | Pattern 这是要匹配的正则表达式。 |
| 2 | String 这是字符串,将在其中搜索在字符串任何位置匹配模式。 |
| 3 | Flags 您可以使用按位 OR (|) 指定不同的标志。这些是修饰符,在下表中列出。 |
示例
import re string="Simple is better than complex." obj=re.findall(r"ple", string) print (obj)
它将产生以下**输出**:
['ple', 'ple']
以下代码在句子中获取单词列表,借助 findall() 函数。
import re string="Simple is better than complex." obj=re.findall(r"\w*", string) print (obj)
它将产生以下**输出**:
['Simple', '', 'is', '', 'better', '', 'than', '', 'complex', '', '']
re.sub() 函数
使用正则表达式的最重要的re方法之一是sub。
语法
re.sub(pattern, repl, string, max=0)
此方法将 string 中 RE pattern 的所有出现替换为 repl,除非提供了 max,否则替换所有出现。此方法返回修改后的字符串。
示例
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print ("Phone Num : ", num)
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print ("Phone Num : ", num)
它将产生以下**输出**:
Phone Num : 2004-959-559 Phone Num : 2004959559
示例
以下示例使用 sub() 函数替换所有出现的 is 为 was 单词:
import re string="Simple is better than complex. Complex is better than complicated." obj=re.sub(r'is', r'was',string) print (obj)
它将产生以下**输出**:
Simple was better than complex. Complex was better than complicated.
re.compile() 函数
compile() 函数将正则表达式模式编译成正则表达式对象,可以使用其 match()、search() 及其他方法进行匹配。
语法
re.compile(pattern, flags=0)
Flags
| 序号 | 修饰符 & 描述 |
|---|---|
| 1 | re.I 执行不区分大小写的匹配。 |
| 2 | re.L 根据当前区域设置解释单词。此解释会影响字母数字组(\w 和 \W),以及单词边界行为(\b 和 \B)。 |
| 3 | re. M 使 $ 匹配行尾(不仅仅是字符串的结尾),并使 ^ 匹配任何行的开头(不仅仅是字符串的开头)。 |
| 4 | re.S 使句点 (.) 匹配任何字符,包括换行符。 |
| 5 | re.U 根据 Unicode 字符集解释字母。此标志会影响 \w、\W、\b、\B 的行为。 |
| 6 | re.X 允许使用“更简洁”的正则表达式语法。它忽略空格(集合 [] 内部除外,或者当用反斜杠转义时),并将未转义的 # 视为注释标记。 |
序列:
prog = re.compile(pattern) result = prog.match(string)
等效于:
result = re.match(pattern, string)
但是,当在一个程序中多次使用表达式时,使用 re.compile() 并保存生成的正则表达式对象以供重复使用效率更高。
示例
import re string="Simple is better than complex. Complex is better than complicated." pattern=re.compile(r'is') obj=pattern.match(string) obj=pattern.search(string) print (obj.start(), obj.end()) obj=pattern.findall(string) print (obj) obj=pattern.sub(r'was', string) print (obj)
它将产生以下输出:
7 9 ['is', 'is'] Simple was better than complex. Complex was better than complicated.
re.finditer() 函数
此函数返回一个迭代器,在字符串中为 RE 模式的所有不重叠匹配项生成匹配对象。
语法
re.finditer(pattern, string, flags=0)
示例
import re string="Simple is better than complex. Complex is better than complicated." pattern=re.compile(r'is') iterator = pattern.finditer(string) print (iterator ) for match in iterator: print(match.span())
它将产生以下**输出**:
(7, 9) (39, 41)
Python 正则表达式的用例
查找所有副词
findall() 匹配模式的所有出现,而不仅仅是 search() 的第一个出现。例如,如果作者想要查找某些文本中的所有副词,他们可能会如下使用 findall():
import re text = "He was carefully disguised but captured quickly by police." obj = re.findall(r"\w+ly\b", text) print (obj)
它将产生以下**输出**:
['carefully', 'quickly']
查找以元音开头的单词
import re text = 'Errors should never pass silently. Unless explicitly silenced.' obj=re.findall(r'\b[aeiouAEIOU]\w+', text) print (obj)
它将产生以下**输出**:
['Errors', 'Unless', 'explicitly']
Python - PIP
Python 的标准库是一个大型的现成模块和包集合。除了这些包之外,Python 程序员通常还需要使用某些第三方库。第三方 Python 包托管在一个名为 Python 包索引的存储库中 (https://pypi.ac.cn/)。
要从此存储库安装包,您需要一个包管理器工具。PIP 是最流行的包管理器之一。
PIP 实用程序会自动与 Python 的标准发行版一起安装,尤其是在 3.4 版及更高版本中。它位于 Python 安装目录内的 scripts 文件夹中。例如,当在 Windows 计算机上安装 Python 3.11 时,您可以在 C:\Python311\Scripts 文件夹中找到 pip3.exe。
如果默认情况下未安装pip,则可以通过以下步骤安装。
从以下 URL 下载 get-pip.py 脚本:
https://bootstrap.pypa.io/get-pip.py
要安装,请从命令提示符运行上述脚本:
c:\Python311>python get-pip.py
在 scripts 文件夹中,pip 和 pip3 都存在。如果使用 pip 安装某个包,则将安装其与 Python 2.x 兼容的版本。因此,要安装与 Python 3 兼容的版本,请使用 pip3。
安装包
要从 PyPI 安装某个包,请使用 PIP 的 install 命令。以下命令在当前 Python 安装中安装 Flask 库。
pip3 install flask
该包及其任何依赖项都将从 PyPI 存储库安装。上述命令在终端中生成以下日志:
Collecting flask
Downloading Flask-2.2.3-py3-none-any.whl (101 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
101.8/101.8 kB 3.0 MB/s eta 0:00:00
Collecting Werkzeug>=2.2.2
Downloading Werkzeug-2.2.3-py3-none-any.whl (233 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
233.6/233.6 kB 7.2 MB/s eta 0:00:00
Collecting Jinja2>=3.0
Downloading Jinja2-3.1.2-py3-none-any.whl (133 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
133.1/133.1 kB 8.2 MB/s eta 0:00:00
Collecting itsdangerous>=2.0
Downloading itsdangerous-2.1.2-py3-none-any.whl (15 kB)
Collecting click>=8.0
Downloading click-8.1.3-py3-none-any.whl (96 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
96.6/96.6 kB 5.4 MB/s eta 0:00:00
Requirement already satisfied: colorama in
c:\users\mlath\appdata\roaming\python\python311\site-packages (from
click>=8.0->flask) (0.4.6)
Collecting MarkupSafe>=2.0
Downloading MarkupSafe-2.1.2-cp311-cp311-win_amd64.whl (16 kB)
Installing collected packages: MarkupSafe, itsdangerous, click,
Werkzeug, Jinja2, flask
Successfully installed Jinja2-3.1.2 MarkupSafe-2.1.2 Werkzeug-2.2.3
click-8.1.3 flask-2.2.3 itsdangerous-2.1.2
默认情况下,将安装所需包的最新可用版本。要指定所需的版本,
pip3 install flask==2.0.0
要测试包安装是否完成,请打开 Python 解释器并尝试导入它并检查版本。如果包未成功安装,则会收到 ModuleNotFoundError。
>>> import flask >>> print (flask.__version__) 2.2.3 >>> import dummypackage Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'dummypackage'
PIP 实用程序可与以下工具配合使用:
使用需求规范符的 PyPI(和其他索引)。
VCS 项目网址。
本地项目目录。
本地或远程源存档。
使用 requirements.txt
您可以通过在一个名为 requirements.txt 的文本文件中提及所需包的列表来一次性执行包安装。
例如,以下 requirements.txt 文件包含要为 FastAPI 库安装的依赖项列表。
anyio==3.6.2 click==8.1.3 colorama==0.4.6 fastapi==0.88.0 gunicorn==20.1.0 h11==0.14.0 idna==3.4 pydantic==1.10.4 sniffio==1.3.0 starlette==0.22.0 typing_extensions==4.4.0 uvicorn==0.20.0
现在在 PIP install 命令中使用 -r 开关。
pip3 install -r requirements.txt
PIP 实用程序与以下命令一起使用:
pip uninstall
此命令用于卸载已安装的一个或多个包。
语法
pip3 uninstall package, [package2, package3, . . ]
这将卸载包及其依赖项。
示例
pip3 uninstall flask
在继续之前,系统会询问您是否确认删除。
pip3 uninstall flask Found existing installation: Flask 2.2.3 Uninstalling Flask-2.2.3: Would remove: c:\python311\lib\site-packages\flask-2.2.3.dist-info\* c:\python311\lib\site-packages\flask\* c:\python311\scripts\flask.exe Proceed (Y/n)?
pip list
此命令列出已安装的包,包括可编辑的包。包按不区分大小写的排序顺序列出。
语法
pip3 list
pip list 命令可以使用以下开关:
-o, --outdated: 列出过时的包
pip3 list --outdated Package Version Latest Type -------- ------- ------- ----- debugpy 1.6.6 1.6.7 wheel ipython 8.11.0 8.12.0 wheel pip 22.3.1 23.0.1 wheel Pygments 2.14.0 2.15.0 wheel setuptools 65.5.0 67.6.1 wheel
-u, --uptodate: 列出最新的包
pip3 list --uptodate Package Version -------- --------- ------- click 8.1.3 colorama 0.4.6 executing 1.2.0 Flask 2.2.3 jedi 0.18.2 Jinja2 3.1.2 python-dateutil 2.8.2 pyzmq 25.0.2 six 1.16.0 Werkzeug 2.2.3
pip show
此命令显示有关一个或多个已安装包的信息。输出采用符合 RFC 的邮件头格式。
语法
pip3 show package
示例
pip3 show flask Name: Flask Version: 2.2.3 Summary: A simple framework for building complex web applications. Home-page: https://palletsprojects.com/p/flask Author: Armin Ronacher Author-email: armin.ronacher@active-4.com License: BSD-3-Clause Location: C:\Python311\Lib\site-packages Requires: click, itsdangerous, Jinja2, Werkzeug Required-by:
pip freeze
此命令以需求格式输出已安装的包。所有包都按不区分大小写的排序顺序列出。
语法
pip3 freeze
可以使用以下命令将此命令的输出重定向到文本文件:
pip3 freeze > requirements.txt
pip download
此命令从以下位置下载包:
使用需求规范符的 PyPI(和其他索引)。
VCS 项目网址。
本地项目目录。
本地或远程源存档。
实际上,`pip download` 执行与 `pip install` 相同的解析和下载操作,但它不会安装依赖项,而是将下载的发行版收集到指定的目录中(默认为当前目录)。稍后可以将此目录作为 `pip install --find-links` 的值,以方便离线或受限环境下的包安装。
语法
pip3 download somepackage
`pip search`
此命令搜索 PyPI 包,其名称或摘要包含给定的查询。
语法
pip3 search query
`pip config`
此命令用于管理本地和全局配置。
子命令
list − 列出活动配置(或来自指定的文件)。
edit − 在编辑器中编辑配置文件。
get − 获取与 command.option 关联的值。
set − 设置 command.option=value。
unset − 取消与 command.option 关联的值。
debug − 列出配置文件及其下定义的值。
配置键应使用点分隔的命令和选项名称,前缀为 "global" 的键将影响所有命令。
示例
pip config set global.index-url https://example.org/
这将配置所有命令的索引 URL。
pip config set download.timeout 10
这将仅为 "pip download" 命令配置 10 秒的超时。
Python - 数据库访问
程序执行期间输入和生成的数据存储在 RAM 中。如果需要永久存储,则需要将其存储在数据库表中。有多种关系数据库管理系统 (RDBMS) 可供使用。
- GadFly
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Informix
- Oracle
- Sybase
- SQLite
- 等等…
本章我们将学习如何使用 Python 访问数据库,如何将 Python 对象的数据存储到 SQLite 数据库中,以及如何从 SQLite 数据库中检索数据并使用 Python 程序进行处理。
关系数据库使用 SQL(结构化查询语言)对数据库表执行 INSERT/DELETE/UPDATE 操作。但是,SQL 的实现因数据库类型而异。这会引发兼容性问题。一个数据库的 SQL 指令与另一个数据库不匹配。
为了克服这种不兼容性,PEP(Python 增强提案)249 中提出了一种通用接口。此提案称为 DB-API,要求用于与 Python 交互的数据库驱动程序必须符合 DB-API。
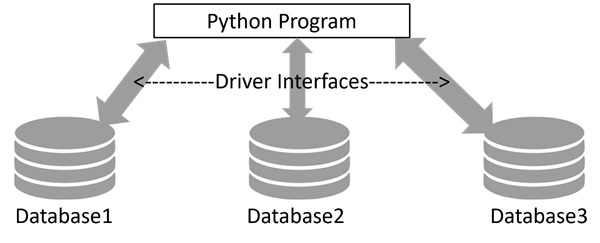
Python 的标准库包含 sqlite3 模块,这是一个与 DB_API 兼容的 SQLite3 数据库驱动程序,它也是 DB-API 的参考实现。
由于所需的 DB-API 接口是内置的,我们可以轻松地将 SQLite 数据库与 Python 应用程序一起使用。对于其他类型的数据库,您需要安装相关的 Python 包。
| 数据库 | Python 包 |
|---|---|
| Oracle | cx_oracle, pyodbc |
| SQL Server | pymssql, pyodbc |
| PostgreSQL | PostgreSQL |
| MySQL | MySQL Connector/Python, pymysql |
诸如 sqlite3 之类的 DB-API 模块包含连接和游标类。连接对象通过提供所需的连接凭据(例如服务器名称和端口号,以及用户名和密码(如果适用))来使用 connect() 方法获得。连接对象处理数据库的打开和关闭,以及提交或回滚事务的事务控制机制。
从连接对象获得的游标对象在执行所有 CRUD 操作时充当数据库的句柄。
sqlite3 模块
SQLite 是一种无服务器、基于文件的轻量级事务关系数据库。它不需要任何安装,也不需要用户名和密码等凭据即可访问数据库。
Python 的 sqlite3 模块包含用于 SQLite 数据库的 DB-API 实现。它由 Gerhard Häring 编写的。让我们学习如何使用 sqlite3 模块通过 Python 访问数据库。
让我们从导入 sqlite3 并检查其版本开始。
>>> import sqlite3 >>> sqlite3.sqlite_version '3.39.4'
连接对象
连接对象由 sqlite3 模块中的 connect() 函数设置。此函数的第一个位置参数是一个字符串,表示 SQLite 数据库文件的路径(相对或绝对)。该函数返回一个指向数据库的连接对象。
>>> conn=sqlite3.connect('testdb.sqlite3')
>>> type(conn)
<class 'sqlite3.Connection'>
连接类中定义了多种方法。其中一种是 cursor() 方法,它返回一个游标对象,我们将在下一节中了解它。事务控制是通过连接对象的 commit() 和 rollback() 方法实现的。连接类具有重要的方法来定义要在 SQL 查询中使用的自定义函数和聚合。
游标对象
接下来,我们需要从连接对象获取游标对象。在对数据库执行任何 CRUD 操作时,它是数据库的句柄。连接对象上的 cursor() 方法返回游标对象。
>>> cur=conn.cursor() >>> type(cur) <class 'sqlite3.Cursor'>
现在,我们可以借助其可用于游标对象的 execute() 方法执行所有 SQL 查询操作。此方法需要一个字符串参数,该参数必须是有效的 SQL 语句。
创建数据库表
我们现在将在新创建的 'testdb.sqlite3' 数据库中添加 Employee 表。在下面的脚本中,我们调用游标对象的 execute() 方法,并向其提供一个包含 CREATE TABLE 语句的字符串。
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry='''
CREATE TABLE Employee (
EmpID INTEGER PRIMARY KEY AUTOINCREMENT,
FIRST_NAME TEXT (20),
LAST_NAME TEXT(20),
AGE INTEGER,
SEX TEXT(1),
INCOME FLOAT
);
'''
try:
cur.execute(qry)
print ('Table created successfully')
except:
print ('error in creating table')
conn.close()
运行上述程序时,将在当前工作目录中创建包含 Employee 表的数据库。
我们可以通过在 SQLite 控制台中列出此数据库中的表来验证。
sqlite> .open mydb.sqlite sqlite> .tables Employee
INSERT 操作
当您想将记录创建到数据库表中时,需要 INSERT 操作。
示例
以下示例执行 SQL INSERT 语句,以在 EMPLOYEE 表中创建一个记录:
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry="""INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
cur.execute(qry)
conn.commit()
print ('Record inserted successfully')
except:
conn.rollback()
print ('error in INSERT operation')
conn.close()
您还可以使用参数替换技术来执行 INSERT 查询,如下所示:
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry="""INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES (?, ?, ?, ?, ?)"""
try:
cur.execute(qry, ('Makrand', 'Mohan', 21, 'M', 5000))
conn.commit()
print ('Record inserted successfully')
except Exception as e:
conn.rollback()
print ('error in INSERT operation')
conn.close()
READ 操作
任何数据库上的 READ 操作都意味着从数据库中提取一些有用的信息。
一旦建立了数据库连接,您就可以对该数据库进行查询了。您可以使用 fetchone() 方法提取单个记录,也可以使用 fetchall() 方法从数据库表中提取多个值。
fetchone() − 它提取查询结果集的下一行。结果集是在使用游标对象查询表时返回的对象。
fetchall() − 它提取结果集中的所有行。如果结果集中的某些行已经被提取,那么它将从结果集中检索剩余的行。
rowcount − 这是一个只读属性,返回受 execute() 方法影响的行数。
示例
在下面的代码中,游标对象执行 SELECT * FROM EMPLOYEE 查询。结果集使用 fetchall() 方法获得。我们使用 for 循环打印结果集中的所有记录。
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry="SELECT * FROM EMPLOYEE"
try:
# Execute the SQL command
cur.execute(qry)
# Fetch all the rows in a list of lists.
results = cur.fetchall()
for row in results:
fname = row[1]
lname = row[2]
age = row[3]
sex = row[4]
income = row[5]
# Now print fetched result
print ("fname={},lname={},age={},sex={},income={}".format(fname, lname, age, sex, income ))
except Exception as e:
print (e)
print ("Error: unable to fecth data")
conn.close()
它将产生以下**输出**:
fname=Mac,lname=Mohan,age=20,sex=M,income=2000.0 fname=Makrand,lname=Mohan,age=21,sex=M,income=5000.0
UPDATE 操作
任何数据库上的 UPDATE 操作都意味着更新数据库中已经存在的记录。
以下过程更新所有 income=2000 的记录。在这里,我们将收入增加 1000。
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry="UPDATE EMPLOYEE SET INCOME = INCOME+1000 WHERE INCOME=?"
try:
# Execute the SQL command
cur.execute(qry, (1000,))
# Fetch all the rows in a list of lists.
conn.commit()
print ("Records updated")
except Exception as e:
print ("Error: unable to update data")
conn.close()
DELETE 操作
当您想要从数据库中删除某些记录时,需要 DELETE 操作。以下是删除 EMPLOYEE 中 INCOME 小于 2000 的所有记录的过程。
import sqlite3
conn=sqlite3.connect('testdb.sqlite3')
cur=conn.cursor()
qry="DELETE FROM EMPLOYEE WHERE INCOME<?"
try:
# Execute the SQL command
cur.execute(qry, (2000,))
# Fetch all the rows in a list of lists.
conn.commit()
print ("Records deleted")
except Exception as e:
print ("Error: unable to delete data")
conn.close()
执行事务
事务是一种确保数据一致性的机制。事务具有以下四个属性:
原子性 − 事务要么完成,要么什么也不发生。
一致性 − 事务必须从一致状态开始,并使系统处于一致状态。
隔离性 − 事务的中间结果在当前事务之外不可见。
持久性 − 一旦事务提交,其效果将是持久的,即使在系统故障之后也是如此。

Python DB API 2.0 提供两种方法来提交或回滚事务。
示例
您已经知道如何实现事务。这是一个类似的示例:
# Prepare SQL query to DELETE required records sql = "DELETE FROM EMPLOYEE WHERE AGE > ?" try: # Execute the SQL command cursor.execute(sql, (20,)) # Commit your changes in the database db.commit() except: # Rollback in case there is any error db.rollback()
COMMIT 操作
Commit 是一种操作,它向数据库发出信号以完成更改,并且在此操作之后,无法撤销任何更改。
这是一个调用 commit 方法的简单示例。
db.commit()
ROLLBACK 操作
如果您对一个或多个更改不满意,并且想要完全撤销这些更改,则使用 rollback() 方法。
这是一个调用 rollback() 方法的简单示例。
db.rollback()
PyMySQL 模块
PyMySQL 是一个从 Python 连接到 MySQL 数据库服务器的接口。它实现了 Python 数据库 API v2.0,并包含一个纯 Python MySQL 客户端库。PyMySQL 的目标是成为 MySQLdb 的直接替代品。
安装 PyMySQL
在继续之前,请确保您的机器上已安装 PyMySQL。只需在您的 Python 脚本中键入以下内容并执行它:
import PyMySQL
如果它产生以下结果,则表示未安装 MySQLdb 模块:
Traceback (most recent call last):
File "test.py", line 3, in <module>
Import PyMySQL
ImportError: No module named PyMySQL
最新的稳定版本可在 PyPI 上获得,并可以使用 pip 安装:
pip install PyMySQL
注意 − 确保您具有安装上述模块的 root 权限。
MySQL 数据库连接
在连接到 MySQL 数据库之前,请确保以下几点:
您已创建数据库 TESTDB。
您已在 TESTDB 中创建表 EMPLOYEE。
此表包含字段 FIRST_NAME、LAST_NAME、AGE、SEX 和 INCOME。
已设置用户 ID“testuser”和密码“test123”以访问 TESTDB。
您的机器上已正确安装 Python 模块 PyMySQL。
您已阅读 MySQL 教程以了解 MySQL 基础知识。
示例
要在前面的示例中使用 MySQL 数据库而不是 SQLite 数据库,我们需要更改 connect() 函数,如下所示:
import PyMySQL
# Open database connection
db = PyMySQL.connect("localhost","testuser","test123","TESTDB" )
除了此更改之外,每个数据库操作都可以顺利执行。
处理错误
错误来源有很多。一些例子包括执行的 SQL 语句中的语法错误、连接失败或为已取消或完成的语句句柄调用 fetch 方法。
DB API 定义了许多必须存在于每个数据库模块中的错误。下表列出了这些异常。
| 序号 | 异常和描述 |
|---|---|
| 1 | Warning 用于非致命性问题。必须是 StandardError 的子类。 |
| 2 | Error 错误的基类。必须是 StandardError 的子类。 |
| 3 | InterfaceError 用于数据库模块中的错误,而不是数据库本身。必须是 Error 的子类。 |
| 4 | DatabaseError 用于数据库中的错误。必须是 Error 的子类。 |
| 5 | DataError DatabaseError 的子类,指的是数据中的错误。 |
| 6 | OperationalError DatabaseError 的子类,指的是诸如与数据库的连接丢失之类的错误。这些错误通常超出 Python 脚本编写者的控制范围。 |
| 7 | IntegrityError DatabaseError 的子类,用于会破坏关系完整性的情况,例如唯一性约束或外键。 |
| 8 | InternalError DatabaseError 的子类,指数据库模块内部发生的错误,例如游标不再处于活动状态。 |
| 9 | ProgrammingError DatabaseError 的子类,指诸如表名错误以及其他可以归咎于用户的错误。 |
| 10 | NotSupportedError DatabaseError 的子类,指尝试调用不受支持的功能。 |
Python - 弱引用
Python 在实现垃圾收集策略时使用引用计数机制。每当内存中的对象被引用时,计数器加 1。另一方面,当引用被移除时,计数器减 1。如果后台运行的垃圾收集器发现任何计数为 0 的对象,它将被移除,并回收其占用的内存。
弱引用是一种不会阻止对象被垃圾回收的引用。当需要为大型对象实现缓存以及需要减少循环引用带来的痛苦时,它非常重要。
为了创建弱引用,Python 提供了一个名为 weakref 的模块。
此模块中的 ref 类管理对对象的弱引用。调用时,它会检索原始对象。
创建弱引用 -
weakref.ref(class())
示例
import weakref
class Myclass:
def __del__(self):
print('(Deleting {})'.format(self))
obj = Myclass()
r = weakref.ref(obj)
print('object:', obj)
print('reference:', r)
print('call r():', r())
print('deleting obj')
del obj
print('r():', r())
删除被引用对象后调用引用对象将返回 None。
它将产生以下**输出**:
object: <__main__.Myclass object at 0x00000209D7173290> reference: <weakref at 0x00000209D7175940; to 'Myclass' at 0x00000209D7173290> call r(): <__main__.Myclass object at 0x00000209D7173290> deleting obj (Deleting <__main__.Myclass object at 0x00000209D7173290>) r(): None
回调函数
ref 类的构造函数有一个可选参数,称为回调函数,在被引用对象被删除时调用。
import weakref
class Myclass:
def __del__(self):
print('(Deleting {})'.format(self))
def mycallback(rfr):
"""called when referenced object is deleted"""
print('calling ({})'.format(rfr))
obj = Myclass()
r = weakref.ref(obj, mycallback)
print('object:', obj)
print('reference:', r)
print('call r():', r())
print('deleting obj')
del obj
print('r():', r())
它将产生以下**输出**:
object: <__main__.Myclass object at 0x000002A0499D3590> reference: <weakref at 0x000002A0499D59E0; to 'Myclass' at 0x000002A0499D3590> call r(): <__main__.Myclass object at 0x000002A0499D3590> deleting obj (Deleting <__main__.Myclass object at 0x000002A0499D3590>) calling (<weakref at 0x000002A0499D59E0; dead>) r(): None
对象终结
weakref 模块提供 finalize 类。当垃圾收集器收集对象时,将调用其对象。该对象将一直存在,直到引用对象被调用。
import weakref
class Myclass:
def __del__(self):
print('(Deleting {})'.format(self))
def finalizer(*args):
print('Finalizer{!r})'.format(args))
obj = Myclass()
r = weakref.finalize(obj, finalizer, "Call to finalizer")
print('object:', obj)
print('reference:', r)
print('call r():', r())
print('deleting obj')
del obj
print('r():', r())
它将产生以下**输出**:
object: <__main__.Myclass object at 0x0000021015103590>
reference: <finalize object at 0x21014eabe80; for 'Myclass' at
0x21015103590>
Finalizer('Call to finalizer',))
call r(): None
deleting obj
(Deleting <__main__.Myclass object at 0x0000021015103590>)
r(): None
weakref 模块提供 WeakKeyDictionary 和 WeakValueDictionary 类。它们不会像映射对象中那样保持对象的存活。它们更适合于创建多个对象的缓存。
WeakKeyDictionary
弱引用键的映射类。当不再有强引用指向键时,字典中的条目将被丢弃。
可以使用现有字典或不带任何参数创建 WeakKeyDictionary 类的实例。其功能与普通字典相同,可以向其中添加和删除映射条目。
在下面的代码中,创建了三个 Person 实例。然后,它使用一个字典创建一个 WeakKeyDictionary 实例,其中键是 Person 实例,值是 Person 的姓名。
我们调用 keyrefs() 方法来检索弱引用。当对 Peron1 的引用被删除时,再次打印字典键。一个新的 Person 实例被添加到具有弱引用键的字典中。最后,我们再次打印字典的键。
示例
import weakref
class Person:
def __init__(self, person_id, name, age):
self.emp_id = person_id
self.name = name
self.age = age
def __repr__(self):
return "{} : {} : {}".format(self.person_id, self.name, self.age)
Person1 = Person(101, "Jeevan", 30)
Person2 = Person(102, "Ramanna", 35)
Person3 = Person(103, "Simran", 28)
weak_dict = weakref.WeakKeyDictionary({Person1: Person1.name, Person2: Person2.name, Person3: Person3.name})
print("Weak Key Dictionary : {}\n".format(weak_dict.data))
print("Dictionary Keys : {}\n".format([key().name for key in weak_dict.keyrefs()]))
del Person1
print("Dictionary Keys : {}\n".format([key().name for key in weak_dict.keyrefs()]))
Person4 = Person(104, "Partho", 32)
weak_dict.update({Person4: Person4.name})
print("Dictionary Keys : {}\n".format([key().name for key in weak_dict.keyrefs()]))
它将产生以下**输出**:
Weak Key Dictionary : {<weakref at 0x7f542b6d4180; to 'Person' at 0x7f542b8bbfd0>: 'Jeevan', <weakref at 0x7f542b6d5530; to 'Person' at 0x7f542b8bbeb0>: 'Ramanna', <weakref at 0x7f542b6d55d0; to 'Person' at 0x7f542b8bb7c0>: 'Simran'}
Dictionary Keys : ['Jeevan', 'Ramanna', 'Simran']
Dictionary Keys : ['Ramanna', 'Simran']
Dictionary Keys : ['Ramanna', 'Simran', 'Partho']
WeakValueDictionary
弱引用值的映射类。当不再有强引用指向值时,字典中的条目将被丢弃。
我们将演示如何使用 WeakValueDictionary 创建一个具有弱引用值的字典。
代码类似于前面的示例,但这次我们使用 Person 名称作为键,Person 实例作为值。我们使用 valuerefs() 方法检索字典的弱引用值。
示例
import weakref
class Person:
def __init__(self, person_id, name, age):
self.emp_id = person_id
self.name = name
self.age = age
def __repr__(self):
return "{} : {} : {}".format(self.person_id, self.name, self.age)
Person1 = Person(101, "Jeevan", 30)
Person2 = Person(102, "Ramanna", 35)
Person3 = Person(103, "Simran", 28)
weak_dict = weakref.WeakValueDictionary({Person1.name:Person1, Person2.name:Person2, Person3.name:Person3})
print("Weak Value Dictionary : {}\n".format(weak_dict.data))
print("Dictionary Values : {}\n".format([value().name for value in weak_dict.valuerefs()]))
del Person1
print("Dictionary Values : {}\n".format([value().name for value in weak_dict.valuerefs()]))
Person4 = Person(104, "Partho", 32)
weak_dict.update({Person4.name: Person4})
print("Dictionary Values : {}\n".format([value().name for value in weak_dict.valuerefs()]))
它将产生以下**输出**:
Weak Value Dictionary : {'Jeevan': <weakref at 0x7f3af9fe4180; to 'Person' at 0x7f3afa1c7fd0>, 'Ramanna': <weakref at 0x7f3af9fe5530; to 'Person' at 0x7f3afa1c7eb0>, 'Simran': <weakref at 0x7f3af9fe55d0; to 'Person' at 0x7f3afa1c77c0>}
Dictionary Values : ['Jeevan', 'Ramanna', 'Simran']
Dictionary Values : ['Ramanna', 'Simran']
Dictionary Values : ['Ramanna', 'Simran', 'Partho']
Python - 序列化
术语“对象序列化”是指将对象的状态转换为字节流的过程。创建后,此字节流可以进一步存储在文件中或通过套接字等传输。另一方面,从字节流重建对象称为反序列化。
Python 中序列化和反序列化的术语分别是 pickling 和 unpickling。Python 标准库中提供的 pickle 模块提供了序列化 (dump() 和 dumps()) 和反序列化 (load() 和 loads()) 函数。
pickle 模块使用非常 Python 特定的数据格式。因此,并非所有非 Python 编写的程序都能正确反序列化编码 (pickled) 数据。此外,从未经身份验证的来源反序列化数据也不被认为是安全的。
Pickle 协议
协议是在将 Python 对象构造和解构到/从二进制数据时使用的约定。目前,pickle 模块定义了 5 种不同的协议,如下所示:
| 序号 | 协议和说明 |
|---|---|
| 1 | 协议版本 0 原始的“人类可读”协议,与早期版本向后兼容。 |
| 2 | 协议版本 1 旧的二进制格式,也与早期版本的 Python 兼容。 |
| 3 | 协议版本 2 在 Python 2.3 中引入,提供了对新型类的有效 pickling。 |
| 4 | 协议版本 3 在 Python 3.0 中添加。当需要与其他 Python 3 版本兼容时推荐使用。 |
| 5 | 协议版本 4 在 Python 3.4 中添加。它增加了对超大型对象的支持。 |
要了解 Python 安装程序的最高和默认协议版本,请使用 pickle 模块中定义的以下常量:
>>> import pickle >>> pickle.HIGHEST_PROTOCOL 4 >>> pickle.DEFAULT_PROTOCOL 3
pickle 模块的 dump() 和 load() 函数执行 Python 数据的 pickling 和 unpickling。dump() 函数将 pickled 对象写入文件,load() 函数将数据从文件 unpickle 到 Python 对象。
dump() 和 load()
以下程序将字典对象 pickle 到二进制文件中。
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
执行上述代码后,字典对象的字节表示将存储在 data.txt 文件中。
要将数据从二进制文件 unpickle 或反序列化回字典,请运行以下程序。
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()
Python 控制台显示从文件中读取的字典对象。
{'age': 23, 'Gender': 'M', 'name': 'Ravi', 'marks': 75}
dumps() 和 loads()
pickle 模块还包含 dumps() 函数,该函数返回 pickled 数据的字符串表示形式。
>>> from pickle import dump
>>> dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
>>> dctstring=dumps(dct)
>>> dctstring
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.'
使用 loads() 函数 unpickle 字符串并获得原始字典对象。
from pickle import load dct=loads(dctstring) print (dct)
它将产生以下**输出**:
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}
Pickler 类
pickle 模块还定义了 Pickler 和 Unpickler 类。Pickler 类将 pickle 数据写入文件。Unpickler 类从文件读取二进制数据并构造 Python 对象。
要写入 Python 对象的 pickled 数据:
from pickle import pickler
f=open("data.txt","wb")
dct={'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}
Pickler(f).dump(dct)
f.close()
Unpickler 类
通过 unpickle 二进制文件读取数据:
from pickle import Unpickler
f=open("data.txt","rb")
dct=Unpickler(f).load()
print (dct)
f.close()
所有 Python 标准数据类型的对象都是可 pickling 的。此外,自定义类的对象也可以被 pickle 和 unpickle。
from pickle import *
class person:
def __init__(self):
self.name="XYZ"
self.age=22
def show(self):
print ("name:", self.name, "age:", self.age)
p1=person()
f=open("data.txt","wb")
dump(p1,f)
f.close()
print ("unpickled")
f=open("data.txt","rb")
p1=load(f)
p1.show()
Python 库还具有 marshal 模块,用于 Python 对象的内部序列化。
Python - 模板
Python 提供不同的文本格式化功能。包括格式化运算符、Python 的 format() 函数和 f-string。此外,Python 的标准库包含 string 模块,其中包含更多格式化选项。
string 模块中的 Template 类对于通过 PEP 292 中描述的替换技术动态地形成字符串对象很有用。其更简单的语法和功能使其比 Python 中其他内置字符串格式化工具更容易进行国际化翻译。
模板字符串使用 $ 符号进行替换。该符号后紧跟一个标识符,该标识符遵循形成有效 Python 标识符的规则。
语法
from string import Template
tempStr = Template('Hello $name')
Template 类定义了以下方法:
substitute()
此方法执行对 Template 对象中标识符的值的替换。可以使用关键字参数或字典对象来映射模板中的标识符。该方法返回一个新字符串。
示例1
以下代码使用关键字参数作为 substitute() 方法。
from string import Template
tempStr = Template('Hello. My name is $name and my age is $age')
newStr = tempStr.substitute(name = 'Pushpa', age = 26)
print (newStr)
它将产生以下**输出**:
Hello. My name is Pushpa and my age is 26
示例2
在下面的示例中,我们使用字典对象来映射模板字符串中的替换标识符。
from string import Template
tempStr = Template('Hello. My name is $name and my age is $age')
dct = {'name' : 'Pushpalata', 'age' : 25}
newStr = tempStr.substitute(dct)
print (newStr)
它将产生以下**输出**:
Hello. My name is Pushpalata and my age is 25
示例3
如果 substitute() 方法未提供足够的参数来与模板字符串中的标识符匹配,则 Python 将引发 KeyError。
from string import
tempStr = Template('Hello. My name is $name and my age is $age')
dct = {'name' : 'Pushpalata'}
newStr = tempStr.substitute(dct)
print (newStr)
它将产生以下**输出**:
Traceback (most recent call last): File "C:\Users\user\example.py", line 5, innewStr = tempStr.substitute(dct) ^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python311\Lib\string.py", line 121, in substitute return self.pattern.sub(convert, self.template) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python311\Lib\string.py", line 114, in convert return str(mapping[named]) ~~~~~~~^^^^^^^ KeyError: 'age'
safe_substitute()
此方法的行为类似于 substitute() 方法,但它不会在键不足或不匹配时引发错误。相反,原始占位符将完好无损地出现在结果字符串中。
示例 4
from string import Template
tempStr = Template('Hello. My name is $name and my age is $age')
dct = {'name' : 'Pushpalata'}
newStr = tempStr.safe_substitute(dct)
print (newStr)
它将产生以下**输出**:
Hello. My name is Pushpalata and my age is $age
is_valid()
如果模板具有无效的占位符(这将导致 substitute() 引发 ValueError),则返回 false。
get_identifiers()
返回模板中有效标识符的列表,按其首次出现的顺序排列,忽略任何无效标识符。
示例5
from string import Template
tempStr = Template('Hello. My name is $name and my age is $23')
print (tempStr.is_valid())
tempStr = Template('Hello. My name is $name and my age is $age')
print (tempStr.get_identifiers())
它将产生以下**输出**:
False ['name', 'age']
示例6
"$" 符号已被定义为替换字符。如果您需要字符串中出现 "$" 本身,则必须对其进行转义。换句话说,使用 $$ 在字符串中使用它。
from string import Template
tempStr = Template('The symbol for Dollar is $$')
print (tempStr.substitute())
它将产生以下**输出**:
The symbol for Dollar is $
示例 7
如果您希望使用除 "$" 之外的任何其他字符作为替换符号,请声明 Template 类的子类并赋值:
from string import Template
class myTemplate(Template):
delimiter = '#'
tempStr = myTemplate('Hello. My name is #name and my age is #age')
print (tempStr.substitute(name='Harsha', age=30))
Python - 输出格式化
本章将讨论不同的输出格式化技术。
字符串格式化运算符
Python 最酷的功能之一是字符串格式化运算符 %。此运算符是字符串独有的,弥补了缺少 C 的 printf() 系列函数的不足。C 语言中使用的格式说明符号 (%d %c %f %s 等) 在字符串中用作占位符。
以下是一个简单的示例:
print ("My name is %s and weight is %d kg!" % ('Zara', 21))
它将产生以下**输出**:
My name is Zara and weight is 21 kg!
format() 方法
Python 3.0 引入了 format() 方法到 str 类中,以更有效地处理复杂的字符串格式化。此方法此后已被反向移植到 Python 2.6 和 Python 2.7。
此内置字符串类的方法提供了进行复杂的变量替换和值格式化的能力。这种新的格式化技术被认为更优雅。
语法
format() 方法的通用语法如下:
str.format(var1, var2,...)
返回值
该方法返回一个格式化的字符串。
字符串本身包含占位符 {},变量的值将依次插入其中。
示例
name="Rajesh"
age=23
print ("my name is {} and my age is {} years".format(name, age))
它将产生以下**输出**:
my name is Rajesh and my age is 23 years
您可以将变量作为关键字参数传递给 format() 方法,并将变量名用作字符串中的占位符。
print ("my name is {name} and my age is {age}
years".format(name="Rajesh", age=23))
您还可以指定 C 样式的格式化符号。唯一的变化是使用 : 代替 %。例如,使用 {:s} 代替 %s,使用 {:d} 代替 %d。
name="Rajesh"
age=23
print ("my name is {:s} and my age is {:d} years".format(name, age))
f-strings
在 Python 中,f-strings 或文字字符串插值是另一种格式化工具。使用此格式化方法,您可以在字符串常量中使用嵌入式 Python 表达式。Python f-strings 更快、更易读、更简洁且错误更少。
字符串以 'f' 前缀开头,并在其中插入一个或多个占位符,其值将动态填充。
name = 'Rajesh'
age = 23
fstring = f'My name is {name} and I am {age} years old'
print (fstring)
它将产生以下**输出**:
My name is Rajesh and I am 23 years old
模板字符串
string 模块中的 Template 类提供了一种动态格式化字符串的替代方法。Template 类的优点之一是可以自定义格式化规则。
有效的模板字符串或占位符由两部分组成:“$” 符号后跟一个有效的 Python 标识符。
您需要创建一个 Template 类的对象,并将模板字符串作为参数传递给构造函数。
接下来,调用 Template 类的 substitute() 方法。它将作为参数提供的值放在模板字符串的位置。
示例
from string import Template temp_str = "My name is $name and I am $age years old" tempobj = Template(temp_str) ret = tempobj.substitute(name='Rajesh', age=23) print (ret)
它将产生以下**输出**:
My name is Rajesh and I am 23 years old
textwrap 模块
Python 的 textwrap 模块中的 wrap 类包含通过调整输入段落中的换行符来格式化和换行纯文本的功能。它有助于使文本格式良好且美观。
textwrap 模块具有以下便捷函数:
textwrap.wrap(text, width=70)
将文本(字符串)中的单个段落进行换行处理,使每行的字符数最多为 width 个。返回一个输出行的列表,不包含最后的换行符。可选关键字参数对应于 TextWrapper 实例的属性。width 默认值为 70。
textwrap.fill(text, width=70)
将文本中的单个段落进行换行处理,并返回包含换行后段落的单个字符串。
两种方法内部都会创建一个 TextWrapper 类对象并对其调用单个方法。由于实例不会被重用,因此创建您自己的 TextWrapper 对象效率更高。
示例
import textwrap text = ''' Python is a high-level, general-purpose programming language. Its design philosophy emphasizes code readability with the use of significant indentation via the off-side rule. Python is dynamically typed and garbage-collected. It supports multiple programming paradigms, including structured (particularly procedural), object-oriented and functional programming. It is often described as a "batteries included" language due to its comprehensive standard library. ''' wrapper = textwrap.TextWrapper(width=40) wrapped = wrapper.wrap(text = text) # Print output for element in wrapped: print(element)
它将产生以下**输出**:
Python is a high-level, general-purpose programming language. Its design philosophy emphasizes code readability with the use of significant indentation via the off-side rule. Python is dynamically typed and garbage-collected. It supports multiple programming paradigms, including structured (particularly procedural), objectoriented and functional programming. It is often described as a "batteries included" language due to its comprehensive standard library.
以下是 TextWrapper 对象定义的属性:
width − (默认值:70) 换行后行的最大长度。
expand_tabs − (默认值:True) 如果为 True,则文本中的所有制表符都将使用 text 的 expandtabs() 方法展开为空格。
tabsize − (默认值:8) 如果 expand_tabs 为 True,则文本中的所有制表符都将展开为零个或多个空格,具体取决于当前列和给定的制表符大小。
replace_whitespace − (默认值:True) 如果为 True,则在制表符展开后但在换行之前,wrap() 方法会将每个空格字符替换为单个空格。
drop_whitespace − (默认值:True) 如果为 True,则每行开头和结尾的空格(换行后但在缩进之前)将被删除。但是,如果段落开头有非空格字符,则段落开头的空格不会被删除。如果要删除的空格占用了整行,则整行都会被删除。
initial_indent − (默认值:'') 将附加到换行输出第一行的字符串。
subsequent_indent − (默认值:'') 将附加到换行输出除第一行之外的所有行的字符串。
fix_sentence_endings − (默认值:False) 如果为 True,则 TextWrapper 尝试检测句子结尾,并确保句子之间始终用两个空格隔开。对于等宽字体中的文本,这通常是需要的。
break_long_words − (默认值:True) 如果为 True,则长度超过 width 的单词将被拆分,以确保没有行的长度超过 width。如果为 False,则长单词不会被拆分,并且某些行的长度可能超过 width。
break_on_hyphens − (默认值:True) 如果为 True,则换行优先在空格处以及复合词中的连字符后进行,这在英语中是惯例。如果为 False,则只考虑空格作为潜在的换行位置。
shorten() 函数
折叠并截断给定的文本以适应给定的宽度。文本首先将其空格折叠。如果然后它适合*宽度*,则按原样返回。否则,尽可能多的单词被连接起来,然后附加占位符:
示例
import textwrap
python_desc = """Python is a general-purpose interpreted, interactive, object-oriented, and high-level programming language. It was created by Guido van Rossum during 1985- 1990. Like Perl, Python source code is also available under the GNU General Public License (GPL). This tutorial gives enough understanding on Python programming language."""
my_wrap = textwrap.TextWrapper(width = 40)
short_text = textwrap.shorten(text = python_desc, width=150)
print('\n\n' + my_wrap.fill(text = short_text))
它将产生以下**输出**:
Python is a general-purpose interpreted, interactive, object-oriented,and high level programming language. It was created by Guido van Rossum [...]
pprint 模块
Python 标准库中的 pprint 模块可以使 Python 数据结构的显示更美观。pprint 代表 pretty printer(漂亮打印机)。任何可以被 Python 解释器正确解析的数据结构都会被优雅地格式化。
格式化后的表达式尽可能保持在一行中,但如果长度超过格式化的 width 参数,则会换行。pprint 输出的一个独特功能是字典在显示表示形式被格式化之前会自动排序。
PrettyPrinter 类
pprint 模块包含 PrettyPrinter 类的定义。其构造函数采用以下格式:
语法
pprint.PrettyPrinter(indent, width, depth, stream, compact)
参数
indent − 定义在每个递归级别上添加的缩进。默认为 1。
width − 默认值为 80。所需的输出受此值限制。如果长度大于 width,则会换行。
depth − 控制要打印的级别数。
stream − 默认情况下为标准输出(stdout)——默认输出设备。它可以接收任何流对象,例如文件。
compact − 默认情况下设置为 False。如果为 True,则只显示可在 width 内调整的数据。
PrettyPrinter 类定义了以下方法:
pprint() 方法
打印 PrettyPrinter 对象的格式化表示。
pformat() 方法
根据构造函数的参数返回对象的格式化表示。
示例
以下示例演示了 PrettyPrinter 类的简单用法:
import pprint
students={"Dilip":["English", "Maths", "Science"],"Raju":{"English":50,"Maths":60, "Science":70},"Kalpana":(50,60,70)}
pp=pprint.PrettyPrinter()
print ("normal print output")
print (students)
print ("----")
print ("pprint output")
pp.pprint(students)
输出显示了普通打印和漂亮打印:
normal print output
{'Dilip': ['English', 'Maths', 'Science'], 'Raju': {'English': 50, 'Maths': 60, 'Science': 70}, 'Kalpana': (50, 60, 70)}
----
pprint output
{'Dilip': ['English', 'Maths', 'Science'],
'Kalpana': (50, 60, 70),
'Raju': {'English': 50, 'Maths': 60, 'Science': 70}}
pprint 模块还定义了与 PrettyPrinter 方法对应的便捷函数 pprint() 和 pformat()。下面的示例使用了 pprint() 函数。
from pprint import pprint
students={"Dilip":["English", "Maths", "Science"],
"Raju":{"English":50,"Maths":60, "Science":70},
"Kalpana":(50,60,70)}
print ("normal print output")
print (students)
print ("----")
print ("pprint output")
pprint (students)
示例
下一个示例使用 pformat() 方法和 pformat() 函数。要使用 pformat() 方法,首先要设置 PrettyPrinter 对象。在这两种情况下,格式化的表示都使用普通的 print() 函数显示。
import pprint
students={"Dilip":["English", "Maths", "Science"],
"Raju":{"English":50,"Maths":60, "Science":70},
"Kalpana":(50,60,70)}
print ("using pformat method")
pp=pprint.PrettyPrinter()
string=pp.pformat(students)
print (string)
print ('------')
print ("using pformat function")
string=pprint.pformat(students)
print (string)
以下是上述代码的输出:
using pformat method
{'Dilip': ['English', 'Maths', 'Science'],
'Kalpana': (50, 60, 70),
'Raju': {'English': 50, 'Maths': 60, 'Science': 70}}
------
using pformat function
{'Dilip': ['English', 'Maths', 'Science'],
'Kalpana': (50, 60, 70),
'Raju': {'English': 50, 'Maths': 60, 'Science': 70}}
漂亮打印也可以与自定义类一起使用。在类中重写了 __repr__() 方法。当使用 repr() 函数时,会调用 __repr__() 方法。它是 Python 对象的官方字符串表示。当我们将对象作为参数传递给 print() 函数时,它会打印 repr() 函数的返回值。
示例
在这个例子中,__repr__() 方法返回 player 对象的字符串表示:
import pprint
class player:
def __init__(self, name, formats=[], runs=[]):
self.name=name
self.formats=formats
self.runs=runs
def __repr__(self):
dct={}
dct[self.name]=dict(zip(self.formats,self.runs))
return (repr(dct))
l1=['Tests','ODI','T20']
l2=[[140, 45, 39],[15,122,36,67, 100, 49],[78,44, 12, 0, 23, 75]]
p1=player("virat",l1,l2)
pp=pprint.PrettyPrinter()
pp.pprint(p1)
以上代码的输出为:
{'virat': {'Tests': [140, 45, 39], 'ODI': [15, 122, 36, 67, 100, 49],
'T20': [78, 44, 12, 0, 23, 75]}}
Python - 性能测量
一个给定的问题可以用多种不同的算法来解决。因此,我们需要优化解决方案的性能。Python 的timeit 模块是一个用于衡量 Python 应用程序性能的有用工具。
此模块中的 timit() 函数测量 Python 代码的执行时间。
语法
timeit.timeit(stmt, setup, timer, number)
参数
stmt − 用于性能测量的代码片段。
setup − 要传递的参数或变量的设置详细信息。
timer − 使用默认计时器,因此可以跳过。
number − 代码将执行此次数。默认为 1000000。
示例
以下语句使用列表推导式返回从 0 到 100 的每个数字的 2 的倍数列表。
>>> [n*2 for n in range(100)] [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198]
为了测量上述语句的执行时间,我们使用 timeit() 函数,如下所示:
>>> from timeit import timeit
>>> timeit('[n*2 for n in range(100)]', number=10000)
0.0862189000035869
将执行时间与使用 for 循环附加数字的过程进行比较。
>>> string = ''' ... numbers=[] ... for n in range(100): ... numbers.append(n*2) ... ''' >>> timeit(string, number=10000) 0.1010853999905521
结果表明列表推导式效率更高。
语句字符串可以包含一个 Python 函数,可以将一个或多个参数作为设置代码传递给它。
我们将查找并比较使用循环的阶乘函数与其递归版本的执行时间。
使用 for 循环的普通函数为:
def fact(x):
fact = 1
for i in range(1, x+1):
fact*=i
return fact
递归阶乘的定义。
def rfact(x):
if x==1:
return 1
else:
return x*fact(x-1)
测试这些函数以计算 10 的阶乘。
print ("Using loop:",fact(10))
print ("Using Recursion",rfact(10))
Result
Using loop: 3628800
Using Recursion 3628800
现在我们将使用 timeit() 函数查找它们的各自执行时间。
import timeit
setup1="""
from __main__ import fact
x = 10
"""
setup2="""
from __main__ import rfact
x = 10
"""
print ("Performance of factorial function with loop")
print(timeit.timeit(stmt = "fact(x)", setup=setup1, number=10000))
print ("Performance of factorial function with Recursion")
print(timeit.timeit(stmt = "rfact(x)", setup=setup2, number=10000))
输出
Performance of factorial function with loop 0.00330029999895487 Performance of factorial function with Recursion 0.006506800003990065
递归函数比带循环的函数慢。
这样,我们可以对 Python 代码进行性能测量。
Python - 数据压缩
Python 的标准库包含丰富的用于数据压缩和存档的模块集合。可以选择任何适合其工作的模块。
以下是与数据压缩相关的模块:
| 序号 | 模块和说明 |
|---|---|
1 |
与 gzip 兼容的压缩。 |
2 |
支持 gzip 文件。 |
3 |
支持 bz2 压缩。 |
4 |
使用 LZMA 算法进行压缩。 |
5 |
处理 ZIP 档案。 |
6 |
读取和写入 tar 归档文件。 |
Python - CGI 编程
公共网关接口(CGI)是一套标准,定义了如何在 Web 服务器和自定义脚本之间交换信息。CGI 规范目前由 NCSA 维护。
什么是 CGI?
公共网关接口(CGI)是外部网关程序与信息服务器(例如 HTTP 服务器)交互的标准。
当前版本为 CGI/1.1,CGI/1.2 正在开发中。
网页浏览
为了理解 CGI 的概念,让我们看看当我们点击超链接来浏览特定的网页或 URL 时会发生什么。
您的浏览器联系 HTTP Web 服务器并请求 URL,即文件名。
Web 服务器解析 URL 并查找文件名。如果找到该文件,则将其发送回浏览器,否则发送错误消息,指示您请求的文件错误。
Web 浏览器接收来自 Web 服务器的响应,并显示接收到的文件或错误消息。
但是,可以设置 HTTP 服务器,以便每当请求某个目录中的文件时,该文件不会被发送回;而是将其作为程序执行,并且该程序输出的内容将被发送回以供您的浏览器显示。此功能称为公共网关接口或 CGI,程序称为 CGI 脚本。这些 CGI 程序可以是 Python 脚本、PERL 脚本、Shell 脚本、C 或 C++ 程序等。
CGI 架构图
Web 服务器支持和配置
在继续进行 CGI 编程之前,请确保您的 Web 服务器支持 CGI 并且已配置为处理 CGI 程序。所有要由 HTTP 服务器执行的 CGI 程序都保存在预配置的目录中。此目录称为 CGI 目录,按照惯例,其名称为 /var/www/cgi-bin。按照惯例,CGI 文件的扩展名为 .cgi,但您也可以将文件保留为 python 扩展名.py。
默认情况下,Linux 服务器配置为仅运行 /var/www 中 cgi-bin 目录中的脚本。如果要指定其他目录来运行 CGI 脚本,请在 httpd.conf 文件中注释以下几行:
<Directory "/var/www/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> <Directory "/var/www/cgi-bin"> Options All </Directory>
还应为 apache 服务器添加以下行,以将 .py 文件视为 cgi 脚本。
AddHandler cgi-script .py
在这里,我们假设您的 Web 服务器已成功启动并运行,并且您可以运行其他 CGI 程序,例如 Perl 或 Shell 等。
第一个 CGI 程序
这是一个简单的链接,它链接到名为 hello.py 的 CGI 脚本。此文件保存在 /var/www/cgi-bin 目录中,其内容如下。在运行 CGI 程序之前,请确保已使用chmod 755 hello.py UNIX 命令更改文件的模式以使其可执行。
print ("Content-type:text/html\r\n\r\n")
print ('<html>')
print ('<head>')
print ('<title>Hello Word - First CGI Program</title>')
print ('</head>')
print ('<body>')
print ('<h2>Hello Word! This is my first CGI program</h2>')
print ('</body>')
print ('</html>')
注意 - 脚本中的第一行必须是 Python 可执行文件的路径。它在 Python 程序中显示为注释,但它被称为 Shebang 行。
在 Linux 中,它应该是 #!/usr/bin/python3。
在 Windows 中,它应该是 #!c:/python311/python.exd。
在浏览器中输入以下 URL:
https:///cgi-bin/hello.py
Hello Word! This is my first CGI program
这个 hello.py 脚本是一个简单的 Python 脚本,它将其输出写入 STDOUT 文件,即屏幕。有一个重要且额外的功能可用,即要打印的第一行Content-type:text/html\r\n\r\n。此行发送回浏览器,它指定要显示在浏览器屏幕上的内容类型。
到目前为止,您一定已经了解了 CGI 的基本概念,并且可以使用 Python 编写许多复杂的 CGI 程序。此脚本还可以与任何其他外部系统交互以交换信息,例如 RDBMS。
HTTP 标头
行Content-type:text/html\r\n\r\n是 HTTP 标头的一部分,发送到浏览器以理解内容。所有 HTTP 标头都将采用以下形式:
HTTP Field Name: Field Content For Example Content-type: text/html\r\n\r\n
还有一些其他重要的 HTTP 标头,您将在 CGI 编程中经常使用。
| 序号 | 标头和说明 |
|---|---|
| 1 | Content-type 定义返回文件的格式的 MIME 字符串。例如 Content-type:text/html |
| 2 | Expires: Date 信息失效日期。浏览器使用此日期判断页面是否需要刷新。有效的日期字符串格式为 01 Jan 1998 12:00:00 GMT。 |
| 3 | 位置:URL 返回的 URL,而不是请求的 URL。您可以使用此字段将请求重定向到任何文件。 |
| 4 | 上次修改:日期 资源上次修改的日期。 |
| 5 | 内容长度:N 返回数据的长度(以字节为单位)。浏览器使用此值报告文件的预计下载时间。 |
| 6 | Set-Cookie:字符串 设置通过字符串传递的 Cookie。 |
CGI 环境变量
所有 CGI 程序都可以访问以下环境变量。这些变量在编写任何 CGI 程序时都起着重要作用。
| 序号 | 变量名称和描述 |
|---|---|
| 1 | CONTENT_TYPE 内容的数据类型。当客户端向服务器发送附加内容时使用,例如文件上传。 |
| 2 | CONTENT_LENGTH 查询信息的长度。仅对 POST 请求可用。 |
| 3 | HTTP_COOKIE 以键值对的形式返回设置的 Cookie。 |
| 4 | HTTP_USER_AGENT User-Agent 请求头字段包含有关发起请求的用户代理的信息。它是 web 浏览器的名称。 |
| 5 | PATH_INFO CGI 脚本的路径。 |
| 6 | QUERY_STRING 使用 GET 方法请求发送的 URL 编码信息。 |
| 7 | REMOTE_ADDR 发出请求的远程主机的 IP 地址。这对于日志记录或身份验证很有用。 |
| 8 | REMOTE_HOST 发出请求的主机的完全限定名称。如果此信息不可用,则可以使用 REMOTE_ADDR 获取 IP 地址。 |
| 9 | REQUEST_METHOD 用于发出请求的方法。最常见的方法是 GET 和 POST。 |
| 10 | SCRIPT_FILENAME CGI 脚本的完整路径。 |
| 11 | SCRIPT_NAME CGI 脚本的名称。 |
| 12 | SERVER_NAME 服务器的主机名或 IP 地址。 |
| 13 | SERVER_SOFTWARE 服务器正在运行的软件的名称和版本。 |
这是一个列出所有 CGI 变量的小型 CGI 程序。点击此链接查看结果 获取环境变量
import os
print ("Content-type: text/html\r\n\r\n");
print ("<font size=+1>Environment</font><\br>");
for param in os.environ.keys():
print ("<b>%20s</b>: %s<\br>" % (param, os.environ[param]))
GET 和 POST 方法
您一定遇到过许多需要将某些信息从浏览器传递到 web 服务器,最终传递到您的 CGI 程序的情况。最常见的是,浏览器使用两种方法将此信息传递到 web 服务器。这些方法是 GET 方法和 POST 方法。
使用 GET 方法传递信息
GET 方法发送附加到页面请求的编码用户信息。页面和编码信息由 ? 字符分隔,如下所示:
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2
GET 方法是从浏览器向 web 服务器传递信息的默认方法,它会生成一个长字符串,显示在浏览器的地址栏中。
如果您需要传递密码或其他敏感信息到服务器,请勿使用 GET 方法。
GET 方法有大小限制:请求字符串中只能发送 1024 个字符。
GET 方法使用 QUERY_STRING 头部发送信息,并且可以通过 QUERY_STRING 环境变量在您的 CGI 程序中访问。
您可以通过简单地连接键值对以及任何 URL 来传递信息,也可以使用 HTML <FORM> 标记使用 GET 方法传递信息。
简单的 URL 示例:GET 方法
这是一个简单的 URL,它使用 GET 方法将两个值传递给 hello_get.py 程序。
/cgi-bin/hello_get.py?first_name=Malhar&last_name=Lathkar
下面是处理 web 浏览器提供的输入的 hello_get.py 脚本。我们将使用 cgi 模块,它使访问传递的信息变得非常容易:
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print ("Content-type:text/html")
print()
print ("<html>")
print ('<head>')
print ("<title>Hello - Second CGI Program</title>")
print ('</head>')
print ('<body>')
print ("<h2>Hello %s %s</h2>" % (first_name, last_name))
print ('</body>')
print ('</html>')
这将生成以下结果:
Hello Malhar Lathkar
简单的表单示例:GET 方法
此示例使用 HTML 表单和提交按钮传递两个值。我们使用相同的 CGI 脚本 hello_get.py 来处理此输入。
<form action = "/cgi-bin/hello_get.py" method = "get"> First Name: <input type = "text" name = "first_name"> <br /> Last Name: <input type = "text" name = "last_name" /> <input type = "submit" value = "Submit" /> </form>
这是上面表单的实际输出,您输入名字和姓氏,然后点击提交按钮查看结果。
使用 POST 方法传递信息
将信息传递到 CGI 程序的一种通常更可靠的方法是 POST 方法。此方法以与 GET 方法完全相同的方式打包信息,但它不是在 URL 中的 ? 后面发送为文本字符串,而是将其作为单独的消息发送。此消息以标准输入的形式进入 CGI 脚本。
以下是处理 GET 和 POST 方法的相同 hello_get.py 脚本。
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"
让我们再次采用与上面相同的示例,该示例使用 HTML 表单和提交按钮传递两个值。我们使用相同的 CGI 脚本 hello_get.py 来处理此输入。
<form action = "/cgi-bin/hello_get.py" method = "post"> First Name: <input type = "text" name = "first_name"><br /> Last Name: <input type = "text" name = "last_name" /> <input type = "submit" value = "Submit" /> </form>
这是上面表单的实际输出。您输入名字和姓氏,然后点击提交按钮查看结果。
将复选框数据传递到 CGI 程序
当需要选择多个选项时,使用复选框。
这是一个带有两个复选框的表单的示例 HTML 代码:
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank"> <input type = "checkbox" name = "maths" value = "on" /> Maths <input type = "checkbox" name = "physics" value = "on" /> Physics <input type = "submit" value = "Select Subject" /> </form>
此代码的结果是以下表单:
以下是处理 web 浏览器为复选按钮提供的输入的 checkbox.cgi 脚本:
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('maths'):
math_flag = "ON"
else:
math_flag = "OFF"
if form.getvalue('physics'):
physics_flag = "ON"
else:
physics_flag = "OFF"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Checkbox - Third CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> CheckBox Maths is : %s</h2>" % math_flag
print "<h2> CheckBox Physics is : %s</h2>" % physics_flag
print "</body>"
print "</html>"
将单选按钮数据传递到 CGI 程序
当只需要选择一个选项时,使用单选按钮。
这是一个带有两个单选按钮的表单的示例 HTML 代码:
<form action = "/cgi-bin/radiobutton.py" method = "post" target = "_blank"> <input type = "radio" name = "subject" value = "maths" /> Maths <input type = "radio" name = "subject" value = "physics" /> Physics <input type = "submit" value = "Select Subject" /> </form>
此代码的结果是以下表单:
以下是处理 web 浏览器为单选按钮提供的输入的 radiobutton.py 脚本:
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('subject'):
subject = form.getvalue('subject')
else:
subject = "Not set"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Radio - Fourth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"
将文本区域数据传递到 CGI 程序
当需要将多行文本传递到 CGI 程序时,使用 TEXTAREA 元素。
这是一个带有 TEXTAREA 框的表单的示例 HTML 代码:
<form action = "/cgi-bin/textarea.py" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>
此代码的结果是以下表单:
以下是处理 web 浏览器提供的输入的 textarea.cgi 脚本:
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Entered Text Content is %s</h2>" % text_content
print "</body>"
将下拉框数据传递到 CGI 程序
当有很多选项可用但只选择一两个时,使用下拉框。
这是一个带有一个下拉框的表单的示例 HTML 代码:
<form action = "/cgi-bin/dropdown.py" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>
此代码的结果是以下表单:
以下是处理 web 浏览器提供的输入的 dropdown.py 脚本。
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('dropdown'):
subject = form.getvalue('dropdown')
else:
subject = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Dropdown Box - Sixth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"
在 CGI 中使用 Cookie
HTTP 协议是无状态协议。对于商业网站,需要在不同的页面之间维护会话信息。例如,一个用户注册在完成许多页面后结束。如何跨所有网页维护用户的会话信息?
在许多情况下,使用 Cookie 是记住和跟踪偏好、购买、佣金以及其他提高访客体验或网站统计信息所需信息的最高效方法。
工作原理?
您的服务器以 Cookie 的形式向访问者的浏览器发送一些数据。浏览器可能会接受 Cookie。如果是这样,它将作为纯文本记录存储在访问者的硬盘驱动器上。现在,当访问者到达您网站上的另一个页面时,Cookie 可供检索。检索后,您的服务器就知道/记住存储的内容。
Cookie 是 5 个可变长度字段的纯文本数据记录:
过期 - Cookie 将过期的日期。如果为空,则 Cookie 将在访问者退出浏览器时过期。
域名 - 您网站的域名。
路径 - 设置 Cookie 的目录或网页的路径。如果您想从任何目录或页面检索 Cookie,则可以为空。
安全 - 如果此字段包含单词“安全”,则 Cookie 只能使用安全服务器检索。如果此字段为空,则不存在此类限制。
名称 = 值 - Cookie 以键值对的形式设置和检索。
设置 Cookie
将 Cookie 发送到浏览器非常容易。这些 Cookie 与 HTTP 头一起发送到 Content-type 字段之前。假设您想设置 UserID 和 Password 作为 Cookie。设置 Cookie 的方法如下:
print "Set-Cookie:UserID = XYZ;\r\n" print "Set-Cookie:Password = XYZ123;\r\n" print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT;\r\n" print "Set-Cookie:Domain = www.tutorialspoint.com;\r\n" print "Set-Cookie:Path = /perl;\n" print "Content-type:text/html\r\n\r\n" ...........Rest of the HTML Content....
从这个例子中,您必须已经了解如何设置 Cookie。我们使用 Set-Cookie HTTP 头来设置 Cookie。
可以根据需要设置 Cookie 属性,例如 Expires、Domain 和 Path。值得注意的是,Cookie 是在发送神奇行 "Content-type:text/html\r\n\r\n" 之前设置的。
检索 Cookie
检索所有已设置的 Cookie 非常容易。Cookie 存储在 CGI 环境变量 HTTP_COOKIE 中,它们将具有以下形式:
key1 = value1;key2 = value2;key3 = value3....
这是一个关于如何检索 Cookie 的示例。
# Import modules for CGI handling
from os import environ
import cgi, cgitb
if environ.has_key('HTTP_COOKIE'):
for cookie in map(strip, split(environ['HTTP_COOKIE'], ';')):
(key, value ) = split(cookie, '=');
if key == "UserID":
user_id = value
if key == "Password":
password = value
print "User ID = %s" % user_id
print "Password = %s" % password
这将为上面脚本设置的 Cookie 生成以下结果:
User ID = XYZ Password = XYZ123
文件上传示例
要上传文件,HTML 表单必须将 enctype 属性设置为 multipart/form-data。带有文件类型的输入标记会创建一个“浏览”按钮。
<html>
<body>
<form enctype = "multipart/form-data" action = "save_file.py" method = "post">
<p>File: <input type = "file" name = "filename" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>
此代码的结果是以下表单:
为了避免用户向我们的服务器上传文件,以上示例已被故意禁用,但您可以在您的服务器上尝试以上代码。
以下是处理文件上传的脚本 save_file.py:
import cgi, os
import cgitb; cgitb.enable()
form = cgi.FieldStorage()
# Get filename here.
fileitem = form['filename']
# Test if the file was uploaded
if fileitem.filename:
# strip leading path from file name to avoid
# directory traversal attacks
fn = os.path.basename(fileitem.filename)
open('/tmp/' + fn, 'wb').write(fileitem.file.read())
message = 'The file "' + fn + '" was uploaded successfully'
else:
message = 'No file was uploaded'
print """\
Content-Type: text/html\n
<html>
<body>
<p>%s</p>
</body>
</html>
""" % (message,)
如果您在 Unix/Linux 上运行以上脚本,则需要注意替换文件分隔符,否则在您的 Windows 机器上,以上 open() 语句应该可以正常工作。
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))
如何显示“文件下载”对话框?
有时,您可能希望提供一个选项,用户可以点击一个链接,它会向用户弹出一个“文件下载”对话框,而不是显示实际内容。这非常容易实现,可以通过 HTTP 头实现。此 HTTP 头与上一节中提到的头不同。
例如,如果您想使 FileName 文件可以通过给定的链接下载,则其语法如下:
# HTTP Header
print "Content-Type:application/octet-stream; name = \"FileName\"\r\n";
print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n";
# Actual File Content will go here.
fo = open("foo.txt", "rb")
str = fo.read();
print str
# Close opend file
fo.close()
Python - XML 处理
XML 是一种可移植的开源语言,允许程序员开发其他应用程序可以读取的应用程序,而不管操作系统和/或开发语言如何。
什么是 XML?
可扩展标记语言 (XML) 是一种类似于 HTML 或 SGML 的标记语言。这是万维网联盟推荐的开放标准。
XML 对于跟踪少量到中等数量的数据非常有用,而无需基于 SQL 的后端。
XML 解析器架构和 API。
Python 标准库提供了一组最小但有用的接口来处理 XML。所有用于 XML 处理的子模块都位于 xml 包中。
xml.etree.ElementTree − ElementTree API,一个简单轻量级的 XML 处理器
xml.dom − DOM API 定义。
xml.dom.minidom − 最小化的 DOM 实现。
xml.dom.pulldom − 支持构建部分 DOM 树。
xml.sax − SAX2 基类和便捷函数。
xml.parsers.expat − Expat 解析器绑定。
处理 XML 数据最基本和最广泛使用的两个 API 是 SAX 和 DOM 接口。
可扩展标记语言简单 API (SAX) − 在这里,您为感兴趣的事件注册回调函数,然后让解析器处理文档。当您的文档很大或内存有限时,这很有用,它在从磁盘读取文件时进行解析,并且整个文件永远不会存储在内存中。
文档对象模型 (DOM) − 这是万维网联盟的一项建议,其中整个文件被读入内存并存储在分层(基于树)的形式中,以表示 XML 文档的所有特性。
在处理大型文件时,SAX 的处理速度显然不如 DOM 快。另一方面,仅使用 DOM 可能会严重消耗您的资源,尤其是在处理许多小文件时。
SAX 是只读的,而 DOM 允许更改 XML 文件。由于这两个不同的 API 实际上是互补的,因此您没有理由不能将它们都用于大型项目。
对于我们所有的 XML 代码示例,让我们使用一个简单的 XML 文件movies.xml作为输入−
<collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format> <year>2003</year> <rating>PG</rating> <stars>10</stars> <description>Talk about a US-Japan war</description> </movie> <movie title="Transformers"> <type>Anime, Science Fiction</type> <format>DVD</format> <year>1989</year> <rating>R</rating> <stars>8</stars> <description>A schientific fiction</description> </movie> <movie title="Trigun"> <type>Anime, Action</type> <format>DVD</format> <episodes>4</episodes> <rating>PG</rating> <stars>10</stars> <description>Vash the Stampede!</description> </movie> <movie title="Ishtar"> <type>Comedy</type> <format>VHS</format> <rating>PG</rating> <stars>2</stars> <description>Viewable boredom</description> </movie> </collection>
使用 SAX API 解析 XML
SAX 是用于事件驱动的 XML 解析的标准接口。使用 SAX 解析 XML 通常需要您通过子类化 xml.sax.ContentHandler 来创建自己的 ContentHandler。
您的 ContentHandler 处理您所用 XML 类型(s) 的特定标签和属性。ContentHandler 对象提供方法来处理各种解析事件。它的拥有者解析器在解析 XML 文件时调用 ContentHandler 方法。
startDocument 和 endDocument 方法分别在 XML 文件的开始和结束时被调用。characters(text) 方法通过参数 text 传递 XML 文件的字符数据。
在每个元素的开始和结束时都会调用 ContentHandler。如果解析器不是命名空间模式,则会调用 startElement(tag, attributes) 和 endElement(tag) 方法;否则,将调用相应的 startElementNS 和 endElementNS 方法。这里,tag 是元素标签,attributes 是 Attributes 对象。
以下是继续之前需要了解的其他重要方法−
make_parser 方法
以下方法创建一个新的解析器对象并将其返回。创建的解析器对象将是系统找到的第一个解析器类型。
xml.sax.make_parser( [parser_list] )
以下是参数的详细信息−
parser_list − 可选参数,包含一个要使用的解析器列表,这些解析器都必须实现 make_parser 方法。
parse 方法
以下方法创建一个 SAX 解析器并使用它来解析文档。
xml.sax.parse( xmlfile, contenthandler[, errorhandler])
以下是参数的详细信息−
xmlfile − 这是要从中读取的 XML 文件的名称。
contenthandler − 这必须是一个 ContentHandler 对象。
errorhandler − 如果指定,errorhandler 必须是 SAX ErrorHandler 对象。
parseString 方法
还有一个方法可以创建一个 SAX 解析器并解析指定的 XML 字符串。
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])
以下是参数的详细信息−
xmlstring − 这是要从中读取的 XML 字符串的名称。
contenthandler − 这必须是一个 ContentHandler 对象。
errorhandler − 如果指定,errorhandler 必须是 SAX ErrorHandler 对象。
示例
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print ("*****Movie*****")
title = attributes["title"]
print ("Title:", title)
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print ("Type:", self.type)
elif self.CurrentData == "format":
print ("Format:", self.format)
elif self.CurrentData == "year":
print ("Year:", self.year)
elif self.CurrentData == "rating":
print ("Rating:", self.rating)
elif self.CurrentData == "stars":
print ("Stars:", self.stars)
elif self.CurrentData == "description":
print ("Description:", self.description)
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")
这将产生以下结果−
*****Movie***** Title: Enemy Behind Type: War, Thriller Format: DVD Year: 2003 Rating: PG Stars: 10 Description: Talk about a US-Japan war *****Movie***** Title: Transformers Type: Anime, Science Fiction Format: DVD Year: 1989 Rating: R Stars: 8 Description: A schientific fiction *****Movie***** Title: Trigun Type: Anime, Action Format: DVD Rating: PG Stars: 10 Description: Vash the Stampede! *****Movie***** Title: Ishtar Type: Comedy Format: VHS Rating: PG Stars: 2 Description: Viewable boredom
有关 SAX API 文档的完整详细信息,请参阅标准Python SAX API。
使用 DOM API 解析 XML
文档对象模型 (“DOM”) 是万维网联盟 (W3C) 提供的一个跨语言 API,用于访问和修改 XML 文档。
DOM 对于随机访问应用程序非常有用。SAX 只允许您一次查看文档的一小部分。如果您正在查看一个 SAX 元素,则无法访问其他元素。
以下是如何快速加载 XML 文档并使用 xml.dom 模块创建 minidom 对象的最简单方法。minidom 对象提供了一个简单的解析器方法,可以快速从 XML 文件创建 DOM 树。
示例短语调用 minidom 对象的 parse(file [,parser]) 函数来解析 XML 文件,该文件由 file 指定为 DOM 树对象。
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print ("Root element : %s" % collection.getAttribute("shelf"))
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print ("*****Movie*****")
if movie.hasAttribute("title"):
print ("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print ("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print ("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print ("Rating: %s" % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print ("Description: %s" % description.childNodes[0].data)
这将产生以下输出:
Root element : New Arrivals *****Movie***** Title: Enemy Behind Type: War, Thriller Format: DVD Rating: PG Description: Talk about a US-Japan war *****Movie***** Title: Transformers Type: Anime, Science Fiction Format: DVD Rating: R Description: A schientific fiction *****Movie***** Title: Trigun Type: Anime, Action Format: DVD Rating: PG Description: Vash the Stampede! *****Movie***** Title: Ishtar Type: Comedy Format: VHS Rating: PG Description: Viewable boredom
有关 DOM API 文档的完整详细信息,请参阅标准Python DOM API。
ElementTree XML API
xml 包有一个 ElementTree 模块。这是一个简单轻量级的 XML 处理器 API。
XML 是一种类似树的分层数据格式。此模块中的“ElementTree”将整个 XML 文档视为一棵树。“Element”类表示此树中的单个节点。对 XML 文件的读写操作是在 ElementTree 级别进行的。与单个 XML 元素及其子元素的交互是在 Element 级别进行的。
创建 XML 文件
树是从根开始,然后是其他元素的元素的分层结构。每个元素都是使用此模块的 Element() 函数创建的。
import xml.etree.ElementTree as et
e=et.Element('name')
每个元素都具有一个标签和一个 attrib 属性,它是一个 dict 对象。对于树的起始元素,attrib 是一个空字典。
>>> root=xml.Element('employees')
>>> root.tag
'employees'
>>> root.attrib
{}
您现在可以设置一个或多个子元素添加到根元素下。每个子元素可能具有一个或多个子元素。使用 SubElement() 函数添加它们并定义其文本属性。
child=xml.Element("employee")
nm = xml.SubElement(child, "name")
nm.text = student.get('name')
age = xml.SubElement(child, "salary")
age.text = str(student.get('salary'))
每个子元素都通过 append() 函数添加到根元素中,如下所示:−
root.append(child)
添加所需数量的子元素后,使用 elementTree() 函数构造一个树对象−
tree = et.ElementTree(root)
整个树结构通过树对象的 write() 函数写入二进制文件−
f=open('employees.xml', "wb")
tree.write(f)
示例
在此示例中,树是由一系列字典项构建的。每个字典项都包含描述学生数据结构的键值对。因此构建的树被写入“myfile.xml”
import xml.etree.ElementTree as et
employees=[{'name':'aaa','age':21,'sal':5000},{'name':xyz,'age':22,'sal':6000}]
root = et.Element("employees")
for employee in employees:
child=xml.Element("employee")
root.append(child)
nm = xml.SubElement(child, "name")
nm.text = student.get('name')
age = xml.SubElement(child, "age")
age.text = str(student.get('age'))
sal=xml.SubElement(child, "sal")
sal.text=str(student.get('sal'))
tree = et.ElementTree(root)
with open('employees.xml', "wb") as fh:
tree.write(fh)
“myfile.xml”存储在当前工作目录中。
<employees><employee><name>aaa</name><age>21</age><sal>5000</sal></employee><employee><name>xyz</name><age>22</age><sal>60</sal></employee></employee>
解析 XML 文件
现在让我们读取上面示例中创建的“myfile.xml”。为此,将使用 ElementTree 模块中的以下函数−
ElementTree() − 此函数被重载为将元素的分层结构读取到树对象中。
tree = et.ElementTree(file='students.xml')
getroot() − 此函数返回树的根元素。
root = tree.getroot()
您可以获取元素下一级别子元素的列表。
children = list(root)
在下面的示例中,“myfile.xml”的元素和子元素被解析成一系列字典项。
示例
import xml.etree.ElementTree as et
tree = et.ElementTree(file='employees.xml')
root = tree.getroot()
employees=[]
children = list(root)
for child in children:
employee={}
pairs = list(child)
for pair in pairs:
employee[pair.tag]=pair.text
employees.append(employee)
print (employees)
它将产生以下**输出**:
[{'name': 'aaa', 'age': '21', 'sal': '5000'}, {'name': 'xyz', 'age':'22', 'sal': '6000'}]
修改 XML 文件
我们将使用 Element 的 iter() 函数。它为给定标签创建一个树迭代器,当前元素作为根。迭代器按文档(深度优先)顺序迭代此元素及其下面的所有元素。
让我们为所有“marks”子元素构建迭代器,并将每个 sal 标签的文本增加 100。
import xml.etree.ElementTree as et
tree = et.ElementTree(file='students.xml')
root = tree.getroot()
for x in root.iter('sal'):
s=int (x.text)
s=s+100
x.text=str(s)
with open("employees.xml", "wb") as fh:
tree.write(fh)
我们的“employees.xml”现在将相应地修改。我们还可以使用 set() 来更新某个键的值。
x.set(marks, str(mark))
Python - GUI 编程
Python 提供了各种开发图形用户界面 (GUI) 的选项。最重要的功能如下所示。
Tkinter − Tkinter 是 Python 对随 Python 一起提供的 Tk GUI 工具包的接口。我们将在本章中介绍此选项。
wxPython − 这是一个用于 wxWidgets GUI 工具包的开源 Python 接口。您可以在此处找到有关 WxPython 的完整教程这里。
PyQt − 这也是一个流行的跨平台 Qt GUI 库的 Python 接口。TutorialsPoint 有一个关于 PyQt5 的非常好的教程这里。
PyGTK − PyGTK 是一组用 Python 和 C 编写的 GTK + GUI 库包装器。完整的 PyGTK 教程可在这里找到。
PySimpleGUI − PySimpleGui 是一个开源的跨平台 Python GUI 库。它旨在为基于 Python 的 Tkinter、PySide 和 WxPython 工具包创建桌面 GUI 提供统一的 API。有关 PySimpleGUI 教程的详细信息,请单击这里。
Pygame − Pygame 是一个流行的 Python 库,用于开发视频游戏。它是一个免费的、开源的、跨平台的 Simple DirectMedia Library (SDL) 包装器。有关 Pygame 的全面教程,请访问此链接。
Jython − Jython 是 Java 的 Python 移植版本,它使 Python 脚本可以无缝访问本地机器上的 Java 类库http: //www.jython.org。
还有许多其他可用的接口,您可以在网上找到它们。
Tkinter 编程
Tkinter 是 Python 的标准 GUI 库。Python 与 Tkinter 结合使用,提供了一种快速简便的创建 GUI 应用程序的方法。Tkinter 为 Tk GUI 工具包提供了一个强大的面向对象接口。
tkinter 包包含以下模块−
Tkinter − 主 Tkinter 模块。
tkinter.colorchooser − 用于让用户选择颜色的对话框。
tkinter.commondialog − 此处列出的其他模块中定义的对话框的基类。
tkinter.filedialog − 常用对话框,允许用户指定要打开或保存的文件。
tkinter.font − 有助于处理字体的实用程序。
tkinter.messagebox − 访问标准 Tk 对话框。
tkinter.scrolledtext − 带有内置垂直滚动条的文本小部件。
tkinter.simpledialog − 基本对话框和便捷函数。
tkinter.ttk − Tk 8.5 中引入的主题小部件集,为主 tkinter 模块中的许多经典小部件提供了现代替代方案。
使用 Tkinter 创建 GUI 应用程序是一项简单的任务。您只需执行以下步骤即可。
导入 Tkinter 模块。
创建 GUI 应用程序主窗口。
将上述一个或多个小部件添加到 GUI 应用程序。
进入主事件循环以对用户触发的每个事件采取行动。
示例
# note that module name has changed from Tkinter in Python 2 # to tkinter in Python 3 import tkinter top = tkinter.Tk() # Code to add widgets will go here... top.mainloop()
这将创建一个如下窗口−
当程序变得更复杂时,使用面向对象编程方法可以使代码更有条理。
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
app = App()
app.mainloop()
Tkinter 小部件
Tkinter 提供各种控件,例如按钮、标签和文本框,这些控件用于 GUI 应用程序。这些控件通常称为小部件。
Tkinter 目前有 15 种小部件。我们在下表中介绍了这些小部件以及简要说明−
| 序号 | 运算符 & 说明 |
|---|---|
| 1 |
按钮
Button 小部件用于在应用程序中显示按钮。 |
| 2 |
画布
Canvas 小部件用于在应用程序中绘制形状,例如线条、椭圆、多边形和矩形。 |
| 3 |
复选框
复选框部件用于以复选框的形式显示多个选项。用户可以同时选择多个选项。 |
| 4 |
Entry(文本输入框)
Entry部件用于显示单行文本字段,用于接收用户的输入值。 |
| 5 |
Frame(框架)
Frame部件用作容器部件,用于组织其他部件。 |
| 6 |
Label(标签)
Label部件用于为其他部件提供单行标题。它也可以包含图像。 |
| 7 |
Listbox(列表框)
Listbox部件用于向用户提供选项列表。 |
| 8 |
Menubutton(菜单按钮)
Menubutton部件用于在应用程序中显示菜单。 |
| 9 |
Menu(菜单)
Menu部件用于向用户提供各种命令。这些命令包含在Menubutton中。 |
| 10 |
Message(消息框)
Message部件用于显示多行文本字段,用于接收用户的输入值。 |
| 11 |
Radiobutton(单选按钮)
Radiobutton部件用于以单选按钮的形式显示多个选项。用户一次只能选择一个选项。 |
| 12 |
Scale(滑块)
Scale部件用于提供一个滑块部件。 |
| 13 |
Scrollbar(滚动条)
Scrollbar部件用于为各种部件(例如列表框)添加滚动功能。 |
| 14 |
Text(文本框)
Text部件用于显示多行文本。 |
| 15 |
Toplevel(顶级窗口)
Toplevel部件用于提供一个单独的窗口容器。 |
| 16 |
Spinbox(旋转框)
Spinbox部件是标准Tkinter Entry部件的一个变体,可用于从固定数量的值中进行选择。 |
| 17 |
PanedWindow(窗格窗口)
PanedWindow是一个容器部件,可以包含任意数量的窗格,这些窗格可以水平或垂直排列。 |
| 18 |
LabelFrame(标签框架)
LabelFrame是一个简单的容器部件。其主要目的是充当复杂窗口布局的间隔符或容器。 |
| 19 |
tkMessageBox(消息框)
此模块用于在应用程序中显示消息框。 |
让我们详细研究这些部件。
标准属性
让我们看看如何指定一些常用属性,例如大小、颜色和字体。
让我们简要地学习它们——
几何管理
所有Tkinter部件都可以访问特定的几何管理方法,这些方法的目的是在父部件区域中组织部件。Tkinter公开了以下几何管理器类:pack、grid和place。
pack()方法——这个几何管理器在将部件放置到父部件之前,将部件组织成块。
grid()方法——这个几何管理器以表格结构的方式在父部件中组织部件。
place()方法——这个几何管理器通过将部件放置在父部件中的特定位置来组织部件。
让我们简要地学习几何管理方法——
SimpleDialog(简单对话框)
tkinter包中的simpledialog模块包含一个对话框类和一些便捷函数,用于通过模态对话框接收用户输入。它包含一个标签、一个输入部件和两个按钮“确定”和“取消”。这些函数是——
askfloat(title, prompt, **kw)——接受浮点数。
askinteger(title, prompt, **kw)——接受整数输入。
askstring(title, prompt, **kw)——接受用户的文本输入。
以上三个函数提供的对话框会提示用户输入所需类型的数值。如果按下“确定”,则返回输入;如果按下“取消”,则返回None。
askinteger
from tkinter.simpledialog import askinteger
from tkinter import *
from tkinter import messagebox
top = Tk()
top.geometry("100x100")
def show():
num = askinteger("Input", "Input an Integer")
print(num)
B = Button(top, text ="Click", command = show)
B.place(x=50,y=50)
top.mainloop()
它将产生以下**输出**:
askfloat
from tkinter.simpledialog import askfloat
from tkinter import *
top = Tk()
top.geometry("100x100")
def show():
num = askfloat("Input", "Input a floating point number")
print(num)
B = Button(top, text ="Click", command = show)
B.place(x=50,y=50)
top.mainloop()
它将产生以下**输出**:
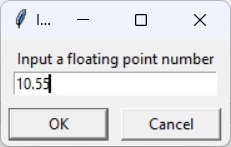
askstring
from tkinter.simpledialog import askstring
from tkinter import *
top = Tk()
top.geometry("100x100")
def show():
name = askstring("Input", "Enter you name")
print(name)
B = Button(top, text ="Click", command = show)
B.place(x=50,y=50)
top.mainloop()
它将产生以下**输出**:
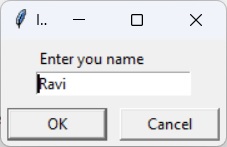
FileDialog模块(文件对话框)
Tkinter包中的filedialog模块包含一个FileDialog类。它还定义了方便用户执行打开文件、保存文件和打开目录操作的便捷函数。
- filedialog.asksaveasfilename()
- filedialog.asksaveasfile()
- filedialog.askopenfilename()
- filedialog.askopenfile()
- filedialog.askdirectory()
- filedialog.askopenfilenames()
- filedialog.askopenfiles()
askopenfile
此函数允许用户从文件系统中选择所需的文件。文件对话框窗口具有“打开”和“取消”按钮。按下“确定”时返回文件名及其路径,按下“取消”时返回None。
from tkinter.filedialog import askopenfile
from tkinter import *
top = Tk()
top.geometry("100x100")
def show():
filename = askopenfile()
print(filename)
B = Button(top, text ="Click", command = show)
B.place(x=50,y=50)
top.mainloop()
它将产生以下**输出**:
ColorChooser(颜色选择器)
tkinter包中包含的colorchooser模块具有允许用户通过颜色对话框选择所需颜色对象的特性。askcolor()函数显示颜色对话框,其中包含预定义的颜色样本以及通过设置RGB值来选择自定义颜色的功能。该对话框返回所选颜色的RGB值元组及其十六进制值。
from tkinter.colorchooser import askcolor
from tkinter import *
top = Tk()
top.geometry("100x100")
def show():
color = askcolor()
print(color)
B = Button(top, text ="Click", command = show)
B.place(x=50,y=50)
top.mainloop()
它将产生以下**输出**:
((0, 255, 0), '#00ff00')
ttk模块
ttk代表Tk主题部件。ttk模块从Tk 8.5开始引入。它提供了额外的优势,包括在X11下进行抗锯齿字体渲染和窗口透明度。它为Tkinter提供了主题和样式支持。
ttk模块捆绑了18个部件,其中12个部件已经存在于Tkinter中。导入ttk会用新的部件覆盖这些部件,这些部件旨在在所有平台上都具有更好、更现代的外观。
ttk中的6个新部件是:Combobox、Separator、Sizegrip、Treeview、Notebook和ProgressBar。
要覆盖基本的Tk部件,导入应遵循Tk导入——
from tkinter import * from tkinter.ttk import *
原始的Tk部件将自动被tkinter.ttk部件替换。它们是Button、Checkbutton、Entry、Frame、Label、LabelFrame、Menubutton、PanedWindow、Radiobutton、Scale和Scrollbar。
新的部件在跨平台方面提供了更好的外观和感觉;但是,替换的部件并不完全兼容。主要区别在于,诸如“fg”、“bg”以及其他与部件样式相关的部件选项不再存在于Ttk部件中。而是使用ttk.Style类来获得改进的样式效果。
ttk模块中的新部件是——
Notebook(笔记本)——此部件管理一系列“选项卡”,您可以在这些选项卡之间切换,从而更改当前显示的窗口。
ProgressBar(进度条)——此部件用于通过使用动画来显示进度或加载过程。
Separator(分隔符)——使用分隔线来分隔不同的部件。
Treeview(树形视图)——此部件用于以树状层次结构将项目组合在一起。每个项目都有一个文本标签、一个可选图像和一个可选数据值列表。
Combobox(组合框)——用于创建下拉选项列表,用户可以从中选择一个选项。
Sizegrip(大小调整器)——在屏幕的右下角创建一个小的把手,可用于调整窗口大小。
Combobox部件(组合框)
Python ttk Combobox显示下拉选项列表,并一次显示一个选项。它是Entry部件的子类。因此,它继承了Entry类的许多选项和方法。
语法
from tkinter import ttk Combo = ttk.Combobox(master, values.......)
get()函数用于检索Combobox的当前值。
示例
from tkinter import *
from tkinter import ttk
top = Tk()
top.geometry("200x150")
frame = Frame(top)
frame.pack()
langs = ["C", "C++", "Java",
"Python", "PHP"]
Combo = ttk.Combobox(frame, values = langs)
Combo.set("Pick an Option")
Combo.pack(padx = 5, pady = 5)
top.mainloop()
它将产生以下**输出**:
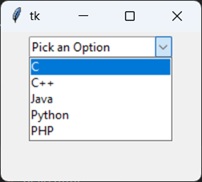
Progressbar(进度条)
ttk ProgressBar部件及其如何用于创建加载屏幕或显示当前任务的进度。
语法
ttk.Progressbar(parent, orient, length, mode)
参数
Parent(父容器)——放置ProgressBar的容器,例如root或Tkinter框架。
Orient(方向)——定义ProgressBar的方向,可以是垂直或水平。
Length(长度)——通过接收整数数值来定义ProgressBar的宽度。
Mode(模式)——此参数有两个选项:确定和不确定。
示例
下面给出的代码创建了一个进度条,其中包含三个按钮,这些按钮与三个不同的函数链接。
第一个函数将进度条中的“值”或“进度”增加20。这是通过step()函数完成的,该函数接收一个整数数值来更改进度量。(默认为1.0)
第二个函数将进度条中的“值”或“进度”减少20。
第三个函数打印出进度条中的当前进度级别。
import tkinter as tk from tkinter import ttk root = tk.Tk() frame= ttk.Frame(root) def increment(): progressBar.step(20) def decrement(): progressBar.step(-20) def display(): print(progressBar["value"]) progressBar= ttk.Progressbar(frame, mode='determinate') progressBar.pack(padx = 10, pady = 10) button= ttk.Button(frame, text= "Increase", command= increment) button.pack(padx = 10, pady = 10, side = tk.LEFT) button= ttk.Button(frame, text= "Decrease", command= decrement) button.pack(padx = 10, pady = 10, side = tk.LEFT) button= ttk.Button(frame, text= "Display", command= display) button.pack(padx = 10, pady = 10, side = tk.LEFT) frame.pack(padx = 5, pady = 5) root.mainloop()
它将产生以下**输出**:
Notebook(笔记本)
Tkinter ttk模块有一个名为Notebook的有用新部件。它是一组容器(例如框架),这些容器内部包含许多部件作为子部件。
每个“选项卡”或“窗口”都有一个与其关联的选项卡ID,用于确定要切换到哪个选项卡。
您可以像在常规文本编辑器中一样在这些容器之间切换。
语法
notebook = ttk.Notebook(master, *options)
示例
在这个示例中,我们将以两种不同的方式将3个窗口添加到我们的Notebook部件中。第一种方法涉及add()函数,该函数只是将一个新选项卡附加到末尾。另一种方法是insert()函数,它可以用来将选项卡添加到特定位置。
add()函数需要一个必需参数,即要添加的容器部件,其余参数是可选参数,例如text(显示为选项卡标题的文本)、image和compound。
insert()函数需要一个tab_id,它定义了应该插入它的位置。tab_id可以是索引值,也可以是字符串文字,例如“end”,它会将其附加到末尾。
import tkinter as tk
from tkinter import ttk
root = tk.Tk()
nb = ttk.Notebook(root)
# Frame 1 and 2
frame1 = ttk.Frame(nb)
frame2 = ttk.Frame(nb)
label1 = ttk.Label(frame1, text = "This is Window One")
label1.pack(pady = 50, padx = 20)
label2 = ttk.Label(frame2, text = "This is Window Two")
label2.pack(pady = 50, padx = 20)
frame1.pack(fill= tk.BOTH, expand=True)
frame2.pack(fill= tk.BOTH, expand=True)
nb.add(frame1, text = "Window 1")
nb.add(frame2, text = "Window 2")
frame3 = ttk.Frame(nb)
label3 = ttk.Label(frame3, text = "This is Window Three")
label3.pack(pady = 50, padx = 20)
frame3.pack(fill= tk.BOTH, expand=True)
nb.insert("end", frame3, text = "Window 3")
nb.pack(padx = 5, pady = 5, expand = True)
root.mainloop()
它将产生以下**输出**:
Treeview(树形视图)
Treeview部件用于以表格或层次结构的方式显示项目。它支持创建项目行和列的功能,并且还允许项目具有子项目,从而形成层次结构。
语法
tree = ttk.Treeview(container, **options)
选项
| 序号 | 选项&描述 |
|---|---|
| 1 | columns 列名列表 |
| 2 | displaycolumns 列标识符列表(符号或整数索引),指定显示哪些数据列以及它们的显示顺序,或者字符串“#all”。 |
| 3 | height 可见的行数。 |
| 4 | padding 指定部件的内部填充。可以是整数或4个值的列表。 |
| 5 | selectmode “extended”、“browse”或“none”之一。如果设置为“extended”(默认值),则可以选择多个项目。如果设置为“browse”,则一次只能选择一个项目。如果设置为“none”,则用户无法更改选择。 |
| 6 | show 包含零个或多个以下值的列表,指定要显示的树的哪些元素。默认为“tree headings”,即显示所有元素。 |
示例
在这个示例中,我们将创建一个简单的Treeview ttk部件,并将一些数据填充到其中。我们已经将一些数据存储在一个列表中,这些数据将在我们的read_data()函数中读取并添加到Treeview部件中。
我们首先需要定义一个列名列表/元组。我们省略了列“Name”,因为已经存在一个名称为空的(默认)列。
然后,我们将该列表/元组分配给Treeview中的columns选项,然后定义“headings”,其中列是实际的列,而标题只是显示部件时出现的列标题。我们为每个列命名。“#0”是默认列的名称。
tree.insert()函数具有以下参数——
Parent(父项)——如果没有父项,则保留为空字符串。
Position(位置)——我们想要添加新项目的位置。要追加,请使用tk.END
Iid(项目ID)——用于稍后跟踪相关项目的项目ID。
Text(文本)——我们将为此分配列表中的第一个值(名称)。
我们将传递从列表中获得的其他两个值。
完整代码
import tkinter as tk
import tkinter.ttk as ttk
from tkinter import simpledialog
root = tk.Tk()
data = [
["Bobby",26,20000],
["Harrish",31,23000],
["Jaya",18,19000],
["Mark",22, 20500],
]
index=0
def read_data():
for index, line in enumerate(data):
tree.insert('', tk.END, iid = index,
text = line[0], values = line[1:])
columns = ("age", "salary")
tree= ttk.Treeview(root, columns=columns ,height = 20)
tree.pack(padx = 5, pady = 5)
tree.heading('#0', text='Name')
tree.heading('age', text='Age')
tree.heading('salary', text='Salary')
read_data()
root.mainloop()
它将产生以下**输出**:
Sizegrip(大小调整器)
Sizegrip部件基本上是一个小的箭头状把手,通常放置在屏幕的右下角。在屏幕上拖动Sizegrip也会调整其附加到的容器的大小。
语法
sizegrip = ttk.Sizegrip(parent, **options)
示例
import tkinter as tk
import tkinter.ttk as ttk
root = tk.Tk()
root.geometry("100x100")
frame = ttk.Frame(root)
label = ttk.Label(root, text = "Hello World")
label.pack(padx = 5, pady = 5)
sizegrip = ttk.Sizegrip(frame)
sizegrip.pack(expand = True, fill = tk.BOTH, anchor = tk.SE)
frame.pack(padx = 10, pady = 10, expand = True, fill = tk.BOTH)
root.mainloop()
它将产生以下**输出**:
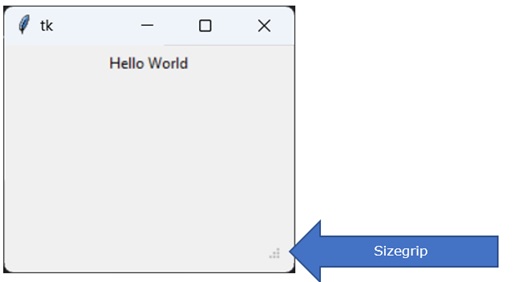
Separator(分隔符)
ttk Separator部件是一个非常简单的部件,它只有一个用途,那就是通过在部件之间绘制一条线来帮助将部件“分隔”成组/分区。我们可以将这条线(分隔符)的方向更改为水平或垂直,并更改其长度/高度。
语法
separator = ttk.Separator(parent, **options)
“orient” 属性可以是 tk.VERTICAL 或 tk.HORIZONTAL,分别表示垂直和水平分隔符。
示例
这里我们创建了两个 Label 组件,然后在它们之间创建了一个水平分隔符。
import tkinter as tk
import tkinter.ttk as ttk
root = tk.Tk()
root.geometry("200x150")
frame = ttk.Frame(root)
label = ttk.Label(frame, text = "Hello World")
label.pack(padx = 5)
separator = ttk.Separator(frame,orient= tk.HORIZONTAL)
separator.pack(expand = True, fill = tk.X)
label = ttk.Label(frame, text = "Welcome To TutorialsPoint")
label.pack(padx = 5)
frame.pack(padx = 10, pady = 50, expand = True, fill = tk.BOTH)
root.mainloop()
它将产生以下**输出**:
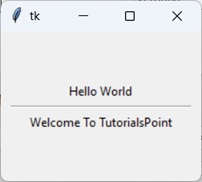
Python - 命令行参数
要运行 Python 程序,我们在操作系统的命令提示符终端执行以下命令。例如,在 Windows 中,在 Windows 命令提示符终端输入以下命令。
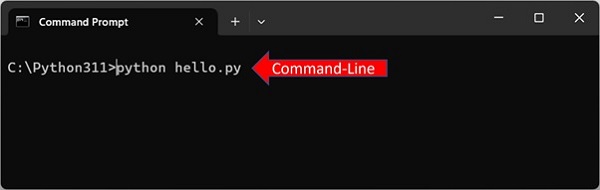
命令提示符 C:\>(或 Linux 操作系统中的 $)前面的行称为命令行。
如果程序需要接受用户的输入,则使用 Python 的 input() 函数。当从命令行执行程序时,用户输入将从命令终端接受。
示例
name = input("Enter your name: ")
print ("Hello {}. How are you?".format(name))
程序从命令提示符终端运行,如下所示:
很多时候,您可能需要将程序要使用的数据放在命令行本身,并在程序内部使用它。在命令行中提供数据的示例可以是 Windows 或 Linux 中的任何 DOS 命令。
在 Windows 中,您可以使用以下 DOS 命令将文件 hello.py 重命名为 hi.py。
C:\Python311>ren hello.py hi.py
在 Linux 中,您可以使用 mv 命令:
$ mv hello.py hi.py
这里 ren 或 mv 是需要旧文件名和新文件名的命令。由于它们与命令一起放在一行中,因此它们被称为命令行参数。
您可以从命令行向 Python 程序传递值。Python 将参数收集到列表对象中。Python 的 sys 模块通过 sys.argv 变量提供对任何命令行参数的访问。sys.argv 是命令行参数列表,sys.argv[0] 是程序,即脚本名称。
hello.py 脚本使用 input() 函数在脚本运行后接受用户输入。让我们将其更改为从命令行接受输入。
import sys
print ('argument list', sys.argv)
name = sys.argv[1]
print ("Hello {}. How are you?".format(name))
从命令行运行程序,如下图所示:
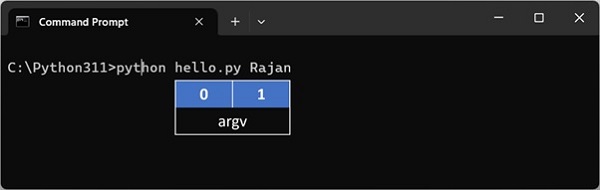
输出如下所示:
C:\Python311>python hello.py Rajan argument list ['hello.py', 'Rajan'] Hello Rajan. How are you?
命令行参数始终存储在字符串变量中。要将它们用作数字,可以使用类型转换函数适当地转换它们。
在下面的示例中,两个数字作为命令行参数输入。在程序内部,我们使用 int() 函数将它们解析为整型变量。
import sys
print ('argument list', sys.argv)
first = int(sys.argv[1])
second = int(sys.argv[2])
print ("sum = {}".format(first+second))
它将产生以下**输出**:
C:\Python311>python hello.py 10 20 argument list ['hello.py', '10', '20'] sum = 30
Python 的标准库包含几个有用的模块来解析命令行参数和选项:
getopt - C 风格的命令行选项解析器。
argparse - 用于命令行选项、参数和子命令的解析器。
getopt 模块
Python 提供了一个 getopt 模块,可帮助您解析命令行选项和参数。此模块提供两个函数和一个异常来启用命令行参数解析。
getopt.getopt 方法
此方法解析命令行选项和参数列表。以下是此方法的简单语法:
getopt.getopt(args, options, [long_options])
以下是参数的详细信息−
args - 这是要解析的参数列表。
options - 这是脚本要识别的选项字母字符串,需要参数的选项后面应跟一个冒号 (:)。
long_options - 这是一个可选参数,如果指定,必须是包含长选项名称的字符串列表,这些选项应受支持。需要参数的长选项后面应跟一个等号 (=)。要仅接受长选项,options 应为空字符串。
此方法返回一个包含两个元素的值:第一个是 (选项,值) 对的列表,第二个是剥离选项列表后剩余的程序参数列表。
返回的每个选项值对都将选项作为其第一个元素,短选项 (例如,'-x') 前缀为一个连字符,长选项 (例如,'--long-option') 前缀为两个连字符。
异常 getopt.GetoptError
当在参数列表中找到无法识别的选项,或者当需要参数的选项未给出任何参数时,将引发此异常。
异常的参数是指示错误原因的字符串。属性 msg 和 opt 给出错误消息和相关选项。
示例
假设我们想通过命令行传递两个文件名,并且我们还想提供一个选项来检查脚本的使用情况。脚本的使用情况如下:
usage: test.py -i <inputfile> -o <outputfile>
以下是测试脚本 test.py:
import sys, getopt
def main(argv):
inputfile = ''
outputfile = ''
try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])
except getopt.GetoptError:
print ('test.py -i <inputfile> -o <outputfile>')
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print ('test.py -i <inputfile> -o <outputfile>')
sys.exit()
elif opt in ("-i", "--ifile"):
inputfile = arg
elif opt in ("-o", "--ofile"):
outputfile = arg
print ('Input file is "', inputfile)
print ('Output file is "', outputfile)
if __name__ == "__main__":
main(sys.argv[1:])
现在,按如下方式运行上述脚本:
$ test.py -h usage: test.py -i <inputfile> -o <outputfile> $ test.py -i BMP -o usage: test.py -i <inputfile> -o <outputfile> $ test.py -i inputfile -o outputfile Input file is " inputfile Output file is " outputfile
argparse 模块
argparse 模块提供了编写非常易于使用的命令行界面的工具。它处理如何解析收集在 sys.argv 列表中的参数,自动生成帮助信息,并在给出无效选项时发出错误消息。
设计命令行界面的第一步是设置解析器对象。这是通过 argparse 模块中的 ArgumentParser() 函数完成的。该函数可以将解释性字符串作为 description 参数。
首先,我们的脚本将在没有任何参数的情况下从命令行执行。仍然使用解析器对象的 parse_args() 方法,因为它没有给出任何参数,所以什么也不做。
import argparse parser=argparse.ArgumentParser(description="sample argument parser") args=parser.parse_args()
运行上述脚本时:
C:\Python311>python parser1.py C:\Python311>python parser1.py -h usage: parser1.py [-h] sample argument parser options: -h, --help show this help message and exit
第二个命令行用法给出 -help 选项,它会生成如下所示的帮助消息。-help 参数默认可用。
现在让我们定义一个参数,该参数对于脚本运行是必需的,如果没有给出,脚本应该抛出错误。这里我们通过 add_argument() 方法定义参数 'user'。
import argparse
parser=argparse.ArgumentParser(description="sample argument parser")
parser.add_argument("user")
args=parser.parse_args()
if args.user=="Admin":
print ("Hello Admin")
else:
print ("Hello Guest")
此脚本的帮助信息现在以 'user' 的形式显示一个位置参数。程序检查其值是否为 'Admin',并打印相应的邮件。
C:\Python311>python parser2.py --help usage: parser2.py [-h] user sample argument parser positional arguments: user options: -h, --help show this help message and exit
使用以下命令:
C:\Python311>python parser2.py Admin Hello Admin
但以下用法显示 Hello Guest 消息。
C:\Python311>python parser2.py Rajan Hello Guest
add_argument() 方法
我们可以在 add_argument() 方法中为参数分配默认值。
import argparse
parser=argparse.ArgumentParser(description="sample argument parser")
parser.add_argument("user", nargs='?',default="Admin")
args=parser.parse_args()
if args.user=="Admin":
print ("Hello Admin")
else:
print ("Hello Guest")
这里 nargs 是应该使用的命令行参数的数量。'?'。如果可能,将从命令行使用一个参数,并作为一个项目生成。如果没有命令行参数,则将生成来自 default 的值。
默认情况下,所有参数都将被视为字符串。要明确提及参数的类型,请在 add_argument() 方法中使用 type 参数。所有 Python 数据类型都是 type 的有效值。
import argparse
parser=argparse.ArgumentParser(description="add numbers")
parser.add_argument("first", type=int)
parser.add_argument("second", type=int)
args=parser.parse_args()
x=args.first
y=args.second
z=x+y
print ('addition of {} and {} = {}'.format(x,y,z))
它将产生以下**输出**:
C:\Python311>python parser3.py 10 20 addition of 10 and 20 = 30
在上面的示例中,参数是必需的。要添加可选参数,请在其名称前加上双破折号 --。在以下情况下,surname 参数是可选的,因为它以双破折号 (--surname) 为前缀。
import argparse
parser=argparse.ArgumentParser()
parser.add_argument("name")
parser.add_argument("--surname")
args=parser.parse_args()
print ("My name is ", args.name, end=' ')
if args.surname:
print (args.surname)
以单破折号为前缀的一个字母参数名称充当短名称选项。
C:\Python311>python parser3.py Anup My name is Anup C:\Python311>python parser3.py Anup --surname Gupta My name is Anup Gupta
如果需要参数的值仅来自定义列表,则将其定义为 choices 参数。
import argparse
parser=argparse.ArgumentParser()
parser.add_argument("sub", choices=['Physics', 'Maths', 'Biology'])
args=parser.parse_args()
print ("My subject is ", args.sub)
请注意,如果参数的值不在列表中,则会显示无效的选择错误。
C:\Python311>python parser3.py Physics
My subject is Physics
C:\Python311>python parser3.py History
usage: parser3.py [-h] {Physics,Maths,Biology}
parser3.py: error: argument sub: invalid choice: 'History' (choose from
'Physics', 'Maths', 'Biology')
Python - 文档字符串
在 Python 中,文档字符串是一个字符串字面量,用作不同 Python 对象(例如函数、模块、类及其方法和包)的文档。它是所有这些构造定义中的第一行,并成为 __doc__ 属性的值。
函数的文档字符串
def addition(x, y):
'''This function returns the sum of two numeric arguments'''
return x+y
print ("Docstring of addition function:", addition.__doc__)
它将产生以下**输出**:
Docstring of addition function: This function returns the sum of two numeric arguments
文档字符串可以用单引号、双引号或三引号编写。但是,大多数情况下您可能需要描述性文本作为文档,因此使用三引号是可取的。
所有内置模块和函数都具有 __doc__ 属性,该属性返回其文档字符串。
math 模块的文档字符串
import math
print ("Docstring of math module:", math.__doc__)
它将产生以下**输出**:
Docstring of math module: This module provides access to the mathematical functions defined by the C standard.
内置函数的文档字符串
以下代码显示 random 模块中 abs() 函数和 randint() 函数的文档字符串。
print ("Docstring of built-in abs() function:", abs.__doc__)
import random
print ("Docstring of random.randint() function:",
random.randint.__doc__)
它将产生以下输出:
Docstring of built-in abs() function: Return the absolute value of the argument. Docstring of random.randint() function: Return random integer in range [a, b], including both end points.
内置类的文档字符串
内置类的文档字符串通常更具解释性,因此文本包含多行。下面,我们检查内置 dict 类的文档字符串
print ("Docstring of built-in dict class:", dict.__doc__)
它将产生以下**输出**:
Docstring of built-in dict class: dict() -> new empty dictionary
dict(mapping) -> new dictionary initialized from a mapping object's
(key, value) pairs
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2)
Template 类的文档字符串
Template 类在 Python 标准库的 string 模块中定义。其文档字符串如下:
from string import Template
print ("Docstring of Template class:", Template.__doc__)
它将产生以下**输出**:
Docstring of Template class: A string class for supporting $- substitutions.
帮助系统中的文档字符串
文档字符串也由 Python 的内置帮助服务使用。例如,检查 Python 解释器中 abs() 函数的帮助:
>>> help (abs) Help on built-in function abs in module builtins: abs(x, /) Return the absolute value of the argument.
同样,在解释器终端中定义一个函数并运行 help 命令。
>>> def addition(x,y): ... '''addtion(x,y) ... Returns the sum of x and y ... ''' ... return x+y ... >>> help (addition) Help on function addition in module __main__: addition(x, y) addtion(x,y) Returns the sum of x and y
文档字符串还被 IDE 用于在编辑代码时提供有用的类型提示信息。
文档字符串作为注释
出现在这些对象(函数、方法、类、模块或包)之外的字符串字面量会被解释器忽略,因此它们类似于注释(以 # 符号开头)。
# This is a comment
print ("Hello World")
'''This is also a comment'''
print ("How are you?")
Python - JSON
JSON 代表 JavaScript 对象表示法。它是一种轻量级的数据交换格式。它类似于 pickle。但是,pickle 序列化是 Python 特定的,而 JSON 格式由多种语言实现。Python 标准库中的 json 模块实现了类似于 pickle 和 marshal 模块的对象序列化功能。
就像 pickle 模块一样,json 模块也提供 dumps() 和 loads() 函数,用于将 Python 对象序列化为 JSON 编码的字符串,以及 dump() 和 load() 函数,用于将序列化后的 Python 对象写入/读取到文件。
dumps() - 此函数将对象转换为 JSON 格式。
loads() - 此函数将 JSON 字符串转换回 Python 对象。
以下示例演示了这些函数的基本用法:
示例1
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
print (s, type(s))
data = json.loads(s)
print (data, type(data))
它将产生以下**输出**:
["Rakesh", {"marks": [50, 60, 70]}] <class 'str'>
['Rakesh', {'marks': [50, 60, 70]}] <class 'list'>
dumps() 函数可以采用可选的 sort_keys 参数。默认情况下为 False。如果设置为 True,则字典键将按排序顺序出现在 JSON 字符串中。
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data, sort_keys=True)
示例2
dumps() 函数还有一个可选参数,称为 indent,它采用数字作为值。它决定 JSON 字符串格式化表示的每个段的长度,类似于 pprint 输出。
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data, indent = 2)
print (s)
它将产生以下输出:
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]
json 模块还具有与上述函数对应的面向对象 API。模块中定义了两个类:JSONEncoder 和 JSONDecoder。
JSONEncoder 类
此类的对象是 Python 数据结构的编码器。每个 Python 数据类型都将转换为相应的 JSON 类型,如下表所示:
| Python | JSON |
|---|---|
| Dict | object |
| list, tuple | array |
| Str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
JSONEncoder 类由 JSONEncoder() 构造函数实例化。编码器类中定义了以下重要方法:
encode() - 将 Python 对象序列化为 JSON 格式。
iterencode() - 编码对象并返回一个迭代器,生成对象中每个项目的编码形式。
indent - 确定编码字符串的缩进级别。
sort_keys - 为 true 或 false,使键按排序顺序出现或不出现。
check_circular - 如果为 True,则检查容器类型对象中的循环引用。
以下示例编码 Python 列表对象。
示例
import json
data=['Rakesh',{'marks':(50,60,70)}]
e=json.JSONEncoder()
使用 iterencode() 方法,编码字符串的每个部分如下所示:
import json
data=['Rakesh',{'marks':(50,60,70)}]
e=json.JSONEncoder()
for obj in e.iterencode(data):
print (obj)
它将产生以下输出:
["Rakesh"
,
{
"marks"
:
[50
, 60
, 70
]
}
]
JSONDEcoder 类
此类的对象有助于将 json 字符串解码回 Python 数据结构。此类中的主要方法是 decode()。以下示例代码从前面步骤中编码的字符串中检索 Python 列表对象。
示例
import json
data=['Rakesh',{'marks':(50,60,70)}]
e=json.JSONEncoder()
s = e.encode(data)
d=json.JSONDecoder()
obj = d.decode(s)
print (obj, type(obj))
它将产生以下**输出**:
['Rakesh', {'marks': [50, 60, 70]}] <class 'list'>
JSON 与文件/流
json 模块定义了 load() 和 dump() 函数,用于将 JSON 数据写入文件类对象(可能是磁盘文件或字节流)并从中读取数据。
dump() 函数
此函数将 Python 对象数据编码为 JSON 格式,并将其写入文件。该文件必须具有写入权限。
示例
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()
此代码将在当前目录中创建 'json.txt' 文件。其内容如下所示:
["Rakesh", {"marks": [50, 60, 70]}]
load() 函数
此函数从文件中加载 JSON 数据,并从中构建 Python 对象。该文件必须以读取权限打开。
示例
import json
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
Python - 发送邮件
在互联网上处理和传递电子邮件的应用程序称为“邮件服务器”。简单邮件传输协议 (SMTP) 是一种协议,用于处理发送电子邮件和邮件服务器之间的电子邮件路由。它是电子邮件传输的互联网标准。
Python 提供 smtplib 模块,该模块定义了一个 SMTP 客户端会话对象,可用于将邮件发送到任何具有 SMTP 或 ESMTP 监听守护程序的互联网计算机。
smtplib.SMTP() 函数
要发送电子邮件,需要使用以下函数获取 SMTP 类的对象:
import smtplib smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
以下是参数的详细信息−
host − 这是运行 SMTP 服务器的主机。您可以指定主机的 IP 地址或域名,例如 tutorialspoint.com。这是一个可选参数。
port − 如果您提供了 host 参数,则需要指定 SMTP 服务器正在侦听的端口。通常此端口为 25。
local_hostname − 如果您的 SMTP 服务器正在您的本地计算机上运行,则可以只指定 localhost 作为选项。
SMTP 对象具有以下方法:
connect(host, port, source_address) − 此方法建立与给定端口上的主机的连接。
login(user, password) − 登录需要身份验证的 SMTP 服务器。
quit() − 终止 SMTP 会话。
data(msg) − 将消息数据发送到服务器。
docmd(cmd, args) − 发送命令并返回其响应代码。
ehlo(name) − 用于标识自身的 hostname。
starttls() − 将与 SMTP 服务器的连接置于 TLS 模式。
getreply() − 获取服务器响应代码组成的服务器回复。
putcmd(cmd, args) − 向服务器发送命令。
send_message(msg, from_addr, to_addrs) − 将消息转换为字节字符串并将其传递给 sendmail。
smtpd 模块
Python 预装的 smtpd 模块具有本地 SMTP 调试服务器。您可以通过启动它来测试电子邮件功能。它不会实际将电子邮件发送到指定的地址,而是将其丢弃并将内容打印到控制台。运行本地调试服务器意味着无需处理消息加密或使用凭据登录到电子邮件服务器。
您可以在命令提示符中键入以下内容来启动本地 SMTP 调试服务器:
python -m smtpd -c DebuggingServer -n localhost:1025
示例
以下程序使用 smtplib 功能发送测试电子邮件。
import smtplib
def prompt(prompt):
return input(prompt).strip()
fromaddr = prompt("From: ")
toaddrs = prompt("To: ").split()
print("Enter message, end with ^D (Unix) or ^Z (Windows):")
# Add the From: and To: headers at the start!
msg = ("From: %s\r\nTo: %s\r\n\r\n"
% (fromaddr, ", ".join(toaddrs)))
while True:
try:
line = input()
except EOFError:
break
if not line:
break
msg = msg + line
print("Message length is", len(msg))
server = smtplib.SMTP('localhost', 1025)
server.set_debuglevel(1)
server.sendmail(fromaddr, toaddrs, msg)
server.quit()
基本上,我们使用 sendmail() 方法,指定三个参数:
发件人 − 包含发件人地址的字符串。
收件人 − 字符串列表,每个收件人一个。
邮件内容 − 根据各种 RFC 中指定的格式编写的字符串消息。
我们已经启动了 SMTP 调试服务器。运行此程序。系统会提示用户输入发件人 ID、收件人和邮件内容。
python example.py From: abc@xyz.com To: xyz@abc.com Enter message, end with ^D (Unix) or ^Z (Windows): Hello World ^Z
控制台会显示以下日志:
From: abc@xyz.com reply: retcode (250); Msg: b'OK' send: 'rcpt TO:<xyz@abc.com>\r\n' reply: b'250 OK\r\n' reply: retcode (250); Msg: b'OK' send: 'data\r\n' reply: b'354 End data with <CR><LF>.<CR><LF>\r\n' reply: retcode (354); Msg: b'End data with <CR><LF>.<CR><LF>' data: (354, b'End data with <CR><LF>.<CR><LF>') send: b'From: abc@xyz.com\r\nTo: xyz@abc.com\r\n\r\nHello World\r\n.\r\n' reply: b'250 OK\r\n' reply: retcode (250); Msg: b'OK' data: (250, b'OK') send: 'quit\r\n' reply: b'221 Bye\r\n' reply: retcode (221); Msg: b'Bye'
运行 SMTPD 服务器的终端显示以下 输出:
---------- MESSAGE FOLLOWS ---------- b'From: abc@xyz.com' b'To: xyz@abc.com' b'X-Peer: ::1' b'' b'Hello World' ------------ END MESSAGE ------------
使用 gmail SMTP
让我们看一下下面的脚本,该脚本使用 Google 的 smtp 邮件服务器发送电子邮件。
首先,使用 gmail 的 smtp 服务器和 527 端口设置 SMTP 对象。然后,SMTP 对象通过调用 ehlo() 命令来标识自身。我们还将传输层安全激活到传出的邮件消息中。
接下来,通过将凭据作为参数传递给它来调用 login() 命令。最后,通过附加预定格式的标头来组装邮件消息,并使用 sendmail() 方法发送。之后关闭 SMTP 对象。
import smtplib
content="Hello World"
mail=smtplib.SMTP('smtp.gmail.com', 587)
mail.ehlo()
mail.starttls()
sender='mvl@gmail.com'
recipient='tester@gmail.com'
mail.login('mvl@gmail.com','******')
header='To:'+receipient+'\n'+'From:' \
+sender+'\n'+'subject:testmail\n'
content=header+content
mail.sendmail(sender, recipient, content)
mail.close()
在运行上述脚本之前,必须将发件人的 gmail 帐户配置为允许“安全性较低的应用”。访问以下链接。
https://myaccount.google.com/lesssecureapps 将显示的切换按钮设置为 ON。
如果一切顺利,请执行上述脚本。邮件应发送到收件人的收件箱。
Python - 扩展
您可以将使用任何编译语言(如 C、C++ 或 Java)编写的任何代码集成或导入到另一个 Python 脚本中。此代码被认为是“扩展”。
Python 扩展模块只不过是一个普通的 C 库。在 Unix 机器上,这些库通常以 .so(共享对象)结尾。在 Windows 机器上,您通常会看到 .dll(动态链接库)。
编写扩展的先决条件
要开始编写扩展,您将需要 Python 头文件。
在 Unix 机器上,这通常需要安装特定于开发人员的软件包。
Windows 用户在使用二进制 Python 安装程序时,会将这些头文件作为软件包的一部分获得。
此外,假设您精通 C 或 C++,才能使用 C 编程编写任何 Python 扩展。
首先了解 Python 扩展
要首次了解 Python 扩展模块,需要将代码分成四个部分:
头文件 Python.h。
您要公开为模块接口的 C 函数。
一个表,将您的函数名称(Python 开发人员看到的)映射到扩展模块内的 C 函数。
一个初始化函数。
头文件 Python.h
您需要在 C 源文件中包含 Python.h 头文件,这使您可以访问用于将模块挂接到解释器的内部 Python API。
确保在任何其他可能需要的头文件之前包含 Python.h。您需要在要从 Python 调用的函数之后遵循包含项。
C 函数
C 函数实现的签名始终采用以下三种形式之一:
static PyObject *MyFunction(PyObject *self, PyObject *args); static PyObject *MyFunctionWithKeywords(PyObject *self, PyObject *args, PyObject *kw); static PyObject *MyFunctionWithNoArgs(PyObject *self);
前面每个声明都返回一个 Python 对象。Python 中没有像 C 中那样的 void 函数。如果您不希望函数返回值,则返回 Python 的 None 值的 C 等效值。Python 头文件定义了一个宏 Py_RETURN_NONE,它可以为我们做到这一点。
您的 C 函数名称可以是任何您喜欢的名称,因为它们永远不会在扩展模块之外可见。它们被定义为 static 函数。
您的 C 函数通常通过组合 Python 模块和函数名称来命名,如下所示:
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
这是一个名为 module 模块内的 func 的 Python 函数。您将把 C 函数的指针放入模块的方法表中,该表通常位于源代码的下一部分。
方法映射表
此方法表是一个简单的 PyMethodDef 结构数组。该结构看起来像这样:
struct PyMethodDef {
char *ml_name;
PyCFunction ml_meth;
int ml_flags;
char *ml_doc;
};
以下是此结构成员的描述:
ml_name − 这是 Python 解释器在 Python 程序中使用时呈现的函数名称。
ml_meth − 这是具有上一节中描述的任何一个签名的函数的地址。
ml_flags − 这告诉解释器 ml_meth 使用哪三个签名。
此标志通常值为 METH_VARARGS。
如果要允许关键字参数进入您的函数,则此标志可以与 METH_KEYWORDS 进行按位 OR 运算。
它也可以具有 METH_NOARGS 值,这表示您不想接受任何参数。
mml_doc − 这是函数的文档字符串,如果您不想编写文档字符串,则可以为 NULL。
此表需要以哨兵结束,该哨兵为相应的成员包含 NULL 和 0 值。
示例
对于上述定义的函数,我们有以下方法映射表:
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
初始化函数
扩展模块的最后一部分是初始化函数。加载模块时,Python 解释器会调用此函数。函数必须命名为 initModule,其中 Module 是模块的名称。
初始化函数需要从您将要构建的库中导出。Python 头文件定义 PyMODINIT_FUNC 以包含适当的咒语,以便在编译的特定环境中发生这种情况。您所要做的就是在定义函数时使用它。
您的 C 初始化函数通常具有以下总体结构:
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}
以下是 Py_InitModule3 函数的描述:
func − 这是要导出的函数。
module_methods − 这是上面定义的映射表名称。
docstring − 这是您要在扩展中提供的注释。
将所有这些放在一起,看起来像这样:
#include <Python.h>
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}
示例
一个使用上述所有概念的简单示例:
#include <Python.h>
static PyObject* helloworld(PyObject* self)
{
return Py_BuildValue("s", "Hello, Python extensions!!");
}
static char helloworld_docs[] =
"helloworld( ): Any message you want to put here!!\n";
static PyMethodDef helloworld_funcs[] = {
{"helloworld", (PyCFunction)helloworld,
METH_NOARGS, helloworld_docs},
{NULL}
};
void inithelloworld(void)
{
Py_InitModule3("helloworld", helloworld_funcs,
"Extension module example!");
}
这里使用 Py_BuildValue 函数来构建 Python 值。将上述代码保存在 hello.c 文件中。我们将看到如何编译和安装此模块以便从 Python 脚本调用。
构建和安装扩展
distutils 包使以标准方式分发 Python 模块(纯 Python 和扩展模块)变得非常容易。模块以源代码形式分发,通常通过名为 setup.py 的安装脚本进行构建和安装。
对于上述模块,您需要准备以下 setup.py 脚本:
from distutils.core import setup, Extension
setup(name='helloworld', version='1.0', \
ext_modules=[Extension('helloworld', ['hello.c'])])
现在,使用以下命令,该命令将执行所有必要的编译和链接步骤,使用正确的编译器和链接器命令和标志,并将生成的动态库复制到适当的目录:
$ python setup.py install
在基于 Unix 的系统上,您很可能需要以 root 用户身份运行此命令,才能有权写入 site-packages 目录。这在 Windows 上通常不是问题。
导入扩展
安装扩展后,您将能够像下面这样在 Python 脚本中导入和调用该扩展:
import helloworld print helloworld.helloworld()
这将产生以下输出:
Hello, Python extensions!!
传递函数参数
由于您很可能希望定义接受参数的函数,因此您可以为 C 函数使用其他签名之一。例如,以下接受一些参数的函数将这样定义:
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Parse args and do something interesting here. */
Py_RETURN_NONE;
}
包含新函数条目的方法表将如下所示:
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ "func", module_func, METH_VARARGS, NULL },
{ NULL, NULL, 0, NULL }
};
您可以使用 API PyArg_ParseTuple 函数从传递到 C 函数的一个 PyObject 指针中提取参数。
PyArg_ParseTuple 的第一个参数是 args 参数。这是您将要解析的对象。第二个参数是一个格式字符串,用于描述您期望参数出现的形式。每个参数在格式字符串中都由一个或多个字符表示,如下所示。
static PyObject *module_func(PyObject *self, PyObject *args) {
int i;
double d;
char *s;
if (!PyArg_ParseTuple(args, "ids", &i, &d, &s)) {
return NULL;
}
/* Do something interesting here. */
Py_RETURN_NONE;
}
编译模块的新版本并导入它使您可以使用任意数量的任意类型参数来调用新函数:
module.func(1, s="three", d=2.0) module.func(i=1, d=2.0, s="three") module.func(s="three", d=2.0, i=1)
您可能会想出更多变化。
PyArg_ParseTuple 函数
这是 PyArg_ParseTuple 函数的标准签名:
int PyArg_ParseTuple(PyObject* tuple,char* format,...)
此函数对于错误返回 0,对于成功返回非 0 值。Tuple 是作为 C 函数的第二个参数的 PyObject*。这里的 format 是一个 C 字符串,用于描述必需参数和可选参数。
以下是 PyArg_ParseTuple 函数的格式代码列表:
| 代码 | C 类型 | 含义 |
|---|---|---|
| c | char | 长度为 1 的 Python 字符串将成为 C char。 |
| d | double | Python float 将成为 C double。 |
| f | float | Python float 将成为 C float。 |
| i | int | Python int 将成为 C int。 |
| l | long | Python int 将成为 C long。 |
| L | long long | Python 的 int 类型转换为 C 语言的 long long 类型。 |
| O | PyObject* | 获取指向 Python 参数的非空借用引用。 |
| S | char* | 将不含嵌入空字符的 Python 字符串转换为 C 语言的 char*。 |
| s# | char*+int | 将任意 Python 字符串转换为 C 语言的地址和长度。 |
| t# | char*+int | 将只读单段缓冲区转换为 C 语言的地址和长度。 |
| u | Py_UNICODE* | 将不含嵌入空字符的 Python Unicode 字符串转换为 C 语言的 Py_UNICODE*。 |
| u# | Py_UNICODE*+int | 将任意 Python Unicode 字符串转换为 C 语言的地址和长度。 |
| w# | char*+int | 将读写单段缓冲区转换为 C 语言的地址和长度。 |
| z | char* | 类似于 s,也接受 None(将 C 语言的 char* 设置为 NULL)。 |
| z# | char*+int | 类似于 s#,也接受 None(将 C 语言的 char* 设置为 NULL)。 |
| (...) | 根据…… | Python 序列被视为每个项目一个参数。 |
| | | 以下参数是可选的。 | |
| : | 格式结束,后跟用于错误消息的函数名。 | |
| ; | 格式结束,后跟完整的错误消息文本。 |
返回值
Py_BuildValue 使用的格式字符串与 PyArg_ParseTuple 非常相似。与其传入要构建的值的地址,不如传入实际的值。以下是一个实现加法函数的示例。
static PyObject *foo_add(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("i", a + b);
}
如果用 Python 实现,它将如下所示:
def add(a, b): return (a + b)
您可以从函数中返回两个值。这将在 Python 中使用列表捕获。
static PyObject *foo_add_subtract(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("ii", a + b, a - b);
}
如果用 Python 实现,它将如下所示:
def add_subtract(a, b): return (a + b, a - b)
Py_BuildValue 函数
以下是Py_BuildValue 函数的标准签名:
PyObject* Py_BuildValue(char* format,...)
这里的 format 是一个 C 字符串,它描述了要构建的 Python 对象。Py_BuildValue 的后续参数是用于构建结果的 C 值。PyObject* 结果是一个新引用。
下表列出了常用的代码字符串,其中零个或多个代码字符串连接成一个格式字符串。
| 代码 | C 类型 | 含义 |
|---|---|---|
| c | char | C 语言的 char 类型转换为长度为 1 的 Python 字符串。 |
| d | double | C 语言的 double 类型转换为 Python 的 float 类型。 |
| f | float | C 语言的 float 类型转换为 Python 的 float 类型。 |
| i | int | C 语言的 int 类型转换为 Python 的 int 类型。 |
| l | long | C 语言的 long 类型转换为 Python 的 int 类型。 |
| N | PyObject* | 传递一个 Python 对象并窃取一个引用。 |
| O | PyObject* | 传递一个 Python 对象并像平常一样增加其引用计数 (INCREF)。 |
| O& | convert+void* | 任意转换 |
| s | char* | 将 C 语言的以 null 结尾的 char* 转换为 Python 字符串,或将 NULL 转换为 None。 |
| s# | char*+int | 将 C 语言的 char* 和长度转换为 Python 字符串,或将 NULL 转换为 None。 |
| u | Py_UNICODE* | 将 C 语言的以 null 结尾的字符串转换为 Python Unicode 字符串,或将 NULL 转换为 None。 |
| u# | Py_UNICODE*+int | 将 C 语言的字符串和长度转换为 Python Unicode 字符串,或将 NULL 转换为 None。 |
| w# | char*+int | 将读写单段缓冲区转换为 C 语言的地址和长度。 |
| z | char* | 类似于 s,也接受 None(将 C 语言的 char* 设置为 NULL)。 |
| z# | char*+int | 类似于 s#,也接受 None(将 C 语言的 char* 设置为 NULL)。 |
| (...) | 根据…… | 从 C 值构建 Python 元组。 |
| [...] | 根据…… | 从 C 值构建 Python 列表。 |
| {...} | 根据…… | 从 C 值构建 Python 字典,键值交替出现。 |
代码 {...} 从偶数个 C 值构建字典,键值交替出现。例如,Py_BuildValue("{issi}",23,"zig","zag",42) 返回一个类似于 Python 的 {23:'zig','zag':42} 的字典。
Python - 工具/实用程序
标准库包含许多模块,这些模块既可以用作模块,也可以用作命令行实用程序。
dis 模块
dis 模块是 Python 反汇编器。它将字节码转换为更适合人类阅读的格式。
示例
import dis
def sum():
vara = 10
varb = 20
sum = vara + varb
print ("vara + varb = %d" % sum)
# Call dis function for the function.
dis.dis(sum)
这将产生以下结果−
3 0 LOAD_CONST 1 (10)
2 STORE_FAST 0 (vara)
4 4 LOAD_CONST 2 (20)
6 STORE_FAST 1 (varb)
6 8 LOAD_FAST 0 (vara)
10 LOAD_FAST 1 (varb)
12 BINARY_ADD
14 STORE_FAST 2 (sum)
7 16 LOAD_GLOBAL 0 (print)
18 LOAD_CONST 3 ('vara + varb = %d')
20 LOAD_FAST 2 (sum)
22 BINARY_MODULO
24 CALL_FUNCTION 1
26 POP_TOP
28 LOAD_CONST 0 (None)
30 RETURN_VALUE
pdb 模块
pdb 模块是标准的 Python 调试器。它基于 bdb 调试器框架。
您可以从命令行运行调试器(键入 n [或 next] 转到下一行,键入 help 获取可用命令列表):
示例
在尝试运行pdb.py之前,请将您的路径正确设置为 Python 库目录。让我们尝试上面的示例 sum.py:
$pdb.py sum.py
> /test/sum.py(3)<module>()
-> import dis
(Pdb) n
> /test/sum.py(5)<module>()
-> def sum():
(Pdb) n
>/test/sum.py(14)<module>()
-> dis.dis(sum)
(Pdb) n
6 0 LOAD_CONST 1 (10)
3 STORE_FAST 0 (vara)
7 6 LOAD_CONST 2 (20)
9 STORE_FAST 1 (varb)
9 12 LOAD_FAST 0 (vara)
15 LOAD_FAST 1 (varb)
18 BINARY_ADD
19 STORE_FAST 2 (sum)
10 22 LOAD_CONST 3 ('vara + varb = %d')
25 LOAD_FAST 2 (sum)
28 BINARY_MODULO
29 PRINT_ITEM
30 PRINT_NEWLINE
31 LOAD_CONST 0 (None)
34 RETURN_VALUE
--Return--
> /test/sum.py(14)<module>()->None
-v dis.dis(sum)
(Pdb) n
--Return--
> <string>(1)<module>()->None
(Pdb)
profile 模块
profile 模块是标准的 Python 性能分析器。您可以从命令行运行性能分析器:
示例
让我们尝试分析以下程序:
vara = 10 varb = 20 sum = vara + varb print "vara + varb = %d" % sum
现在,尝试使用cProfile.py运行此文件sum.py,如下所示:
$cProfile.py sum.py
vara + varb = 30
4 function calls in 0.000 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 sum.py:3(<module>)
1 0.000 0.000 0.000 0.000 {execfile}
1 0.000 0.000 0.000 0.000 {method ......}
tabnanny 模块
tabnanny 模块检查 Python 源文件是否存在歧义缩进。如果文件以某种方式混合使用制表符和空格,从而扰乱缩进,无论您使用什么制表符大小,nanny 都会抱怨。
示例
让我们尝试分析以下程序:
vara = 10 varb = 20 sum = vara + varb print "vara + varb = %d" % sum
如果您尝试使用 tabnanny.py 运行一个正确的文件,它就不会抱怨,如下所示:
$tabnanny.py -v sum.py 'sum.py': Clean bill of health.
Python - GUIs
在本章中,您将学习一些流行的 Python IDE(集成开发环境)以及如何使用 IDE 进行程序开发。
要使用 Python 的脚本模式,您需要将 Python 指令序列保存在文本文件中,并以.py扩展名保存。您可以使用操作系统上提供的任何文本编辑器。每当解释器遇到错误时,都需要反复编辑和运行源代码。为了避免这种繁琐的方法,可以使用 IDE。IDE 是一个一站式解决方案,用于键入、编辑源代码、检测错误和执行程序。
IDLE
Python 的标准库包含IDLE模块。IDLE 代表集成开发和学习环境。顾名思义,它在学习阶段非常有用。它包括一个 Python 交互式 shell 和一个代码编辑器,定制以满足 Python 语言结构的需求。它的一些重要功能包括语法高亮、自动完成、可自定义界面等。
要编写 Python 脚本,请从“文件”菜单打开一个新的文本编辑器窗口。
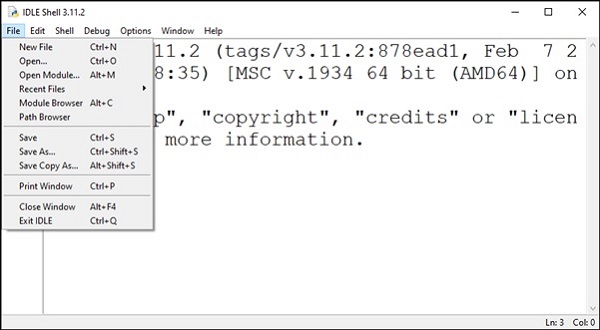
将打开一个新的编辑器窗口,您可以在其中输入 Python 代码。保存并使用“运行”菜单运行它。
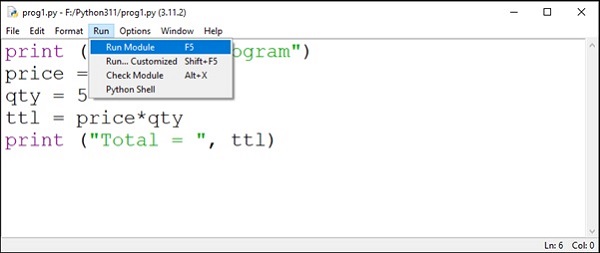
Jupyter Notebook
Jupyter Notebook 最初是作为 IPython 的 Web 接口开发的,它支持多种语言。名称本身来源于受支持语言名称中的字母——Julia、PYThon 和R。Jupyter notebook 是一个客户端服务器应用程序。服务器在 localhost 上启动,浏览器充当其客户端。
使用 PIP 安装 Jupyter notebook:
pip3 install jupyter
从命令行调用。
C:\Users\Acer>jupyter notebook
服务器在 localhost 的 8888 端口启动。
系统的默认浏览器将打开链接https://:8888/tree以显示仪表板。
打开一个新的 Python notebook。它显示 IPython 风格的输入单元格。输入 Python 指令和运行单元格。
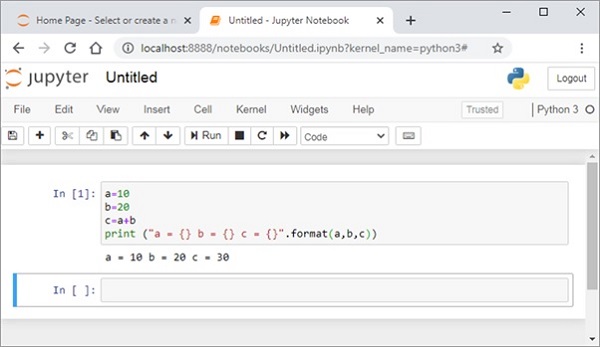
Jupyter notebook 是一款多功能工具,数据科学家广泛使用它来显示内联数据可视化。notebook 可以方便地转换为 PDF、HTML 或 Markdown 格式并分发。
VS Code
Microsoft 开发了一个名为 VS Code(Visual Studio Code)的源代码编辑器,它支持多种语言,包括 C++、Java、Python 等。它提供语法高亮、自动完成、调试器和版本控制等功能。
VS Code 是一个免费软件。可以从https://vscode.js.cn/下载和安装。
从开始菜单(在 Windows 中)启动 VS Code。
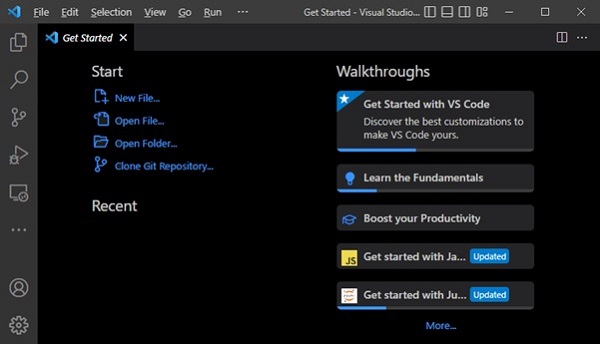
您也可以从命令行启动 VS Code:
C:\test>code .
除非安装了相应的语言扩展,否则无法使用 VS Code。VS Code 的扩展市场上有许多用于语言编译器和其他实用程序的扩展。从“扩展”选项卡(Ctrl+Shift+X)搜索 Python 扩展并安装它。
激活 Python 扩展后,您需要设置 Python 解释器。按 Ctrl+Shift+P 并选择 Python 解释器。
打开一个新的文本文件,输入 Python 代码并保存文件。
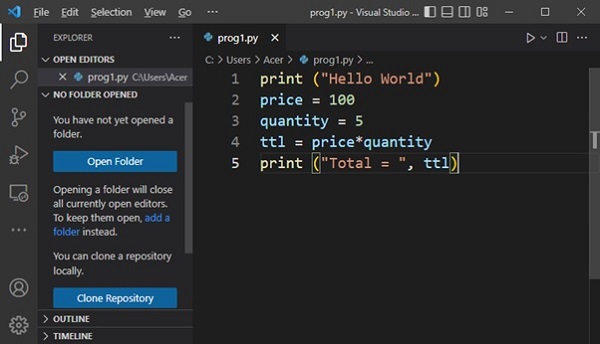
打开命令提示符终端并运行程序。
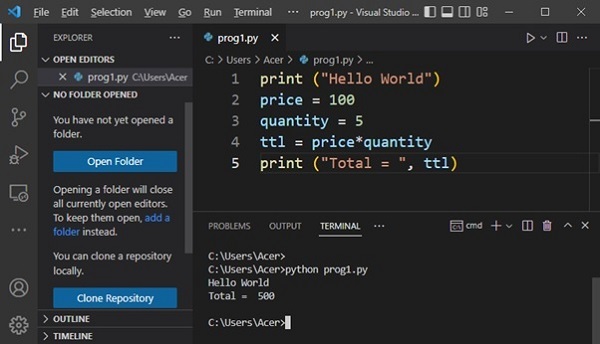
PyCharm
PyCharm 是另一个流行的 Python IDE。它是由捷克软件公司 JetBrains 开发的。其功能包括代码分析、图形调试器、与版本控制系统的集成等。PyCharm 支持使用 Django 进行 Web 开发。
可以从https://www.jetbrains.com/pycharm/download下载社区版和专业版。
下载并安装最新版本:2022.3.2 并打开 PyCharm。欢迎屏幕如下所示:
当您启动新项目时,PyCharm 会根据您选择的文件夹位置和选择的 Python 解释器版本为其创建一个虚拟环境。
您现在可以添加项目所需的一个或多个 Python 脚本。在这里,我们在 main.py 文件中添加一个示例 Python 代码。
要执行程序,请从“运行”菜单中选择,或使用 Shift+F10 快捷键。
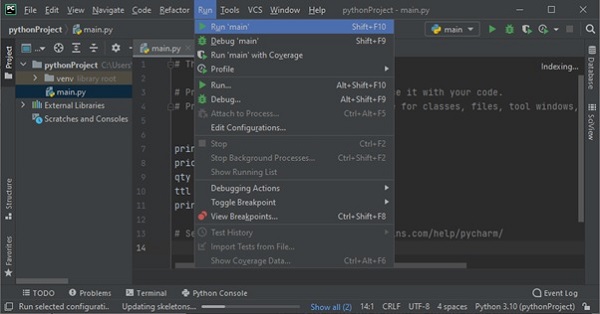
输出将显示在控制台窗口中,如下所示: