- 数据结构与算法
- DSA - 首页
- DSA - 概述
- DSA - 环境搭建
- DSA - 算法基础
- DSA - 渐近分析
- 数据结构
- DSA - 数据结构基础
- DSA - 数据结构和类型
- DSA - 数组数据结构
- 链表
- DSA - 链表数据结构
- DSA - 双向链表数据结构
- DSA - 循环链表数据结构
- 栈与队列
- DSA - 栈数据结构
- DSA - 表达式解析
- DSA - 队列数据结构
- 搜索算法
- DSA - 搜索算法
- DSA - 线性查找算法
- DSA - 二分查找算法
- DSA - 插值搜索
- DSA - 跳跃搜索算法
- DSA - 指数搜索
- DSA - 斐波那契搜索
- DSA - 子列表搜索
- DSA - 哈希表
- 排序算法
- DSA - 排序算法
- DSA - 冒泡排序算法
- DSA - 插入排序算法
- DSA - 选择排序算法
- DSA - 归并排序算法
- DSA - 希尔排序算法
- DSA - 堆排序
- DSA - 桶排序算法
- DSA - 计数排序算法
- DSA - 基数排序算法
- DSA - 快速排序算法
- 图数据结构
- DSA - 图数据结构
- DSA - 深度优先遍历
- DSA - 广度优先遍历
- DSA - 生成树
- 树数据结构
- DSA - 树数据结构
- DSA - 树的遍历
- DSA - 二叉搜索树
- DSA - AVL树
- DSA - 红黑树
- DSA - B树
- DSA - B+树
- DSA - 伸展树
- DSA - 字典树
- DSA - 堆数据结构
- 递归
- DSA - 递归算法
- DSA - 使用递归实现汉诺塔
- DSA - 使用递归实现斐波那契数列
- 分治法
- DSA - 分治法
- DSA - 最大最小问题
- DSA - Strassen矩阵乘法
- DSA - Karatsuba算法
- 贪心算法
- DSA - 贪心算法
- DSA - 旅行商问题(贪心法)
- DSA - Prim最小生成树
- DSA - Kruskal最小生成树
- DSA - Dijkstra最短路径算法
- DSA - 地图着色算法
- DSA - 分数背包问题
- DSA - 带截止日期的作业排序
- DSA - 最优合并模式算法
- 动态规划
- DSA - 动态规划
- DSA - 矩阵链乘法
- DSA - Floyd-Warshall算法
- DSA - 0-1背包问题
- DSA - 最长公共子序列算法
- DSA - 旅行商问题(动态规划法)
- 近似算法
- DSA - 近似算法
- DSA - 顶点覆盖算法
- DSA - 集合覆盖问题
- DSA - 旅行商问题(近似算法)
- 随机化算法
- DSA - 随机化算法
- DSA - 随机化快速排序算法
- DSA - Karger最小割算法
- DSA - Fisher-Yates洗牌算法
- DSA有用资源
- DSA - 问答
- DSA - 快速指南
- DSA - 有用资源
- DSA - 讨论
二分查找算法

二分查找是一种快速搜索算法,其运行时间复杂度为O(log n)。这种搜索算法基于分治的思想,因为它在搜索前将数组分成两半。为了使该算法正常工作,数据集合必须已排序。
二分查找通过比较集合中最中间的项目来查找特定的键值。如果匹配成功,则返回项目的索引。但如果中间项的值大于键值,则搜索中间项的右子数组。否则,搜索左子数组。这个过程递归地继续进行,直到子数组的大小减小到零。
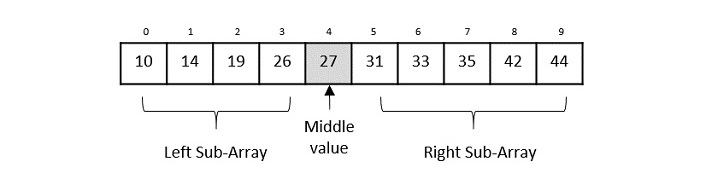
二分查找算法
二分查找算法是一种区间搜索方法,它只在区间内执行搜索。二分查找算法的输入必须始终是一个已排序的数组,因为它根据大于或小于的值将数组划分为子数组。算法遵循以下步骤:
步骤1 - 选择数组中的中间项,并将其与要搜索的键值进行比较。如果匹配,则返回中位数的位置。
步骤2 - 如果它与键值不匹配,则检查键值是否大于或小于中位数。
步骤3 - 如果键值较大,则在右子数组中执行搜索;但如果键值小于中位数,则在左子数组中执行搜索。
步骤4 - 迭代地重复步骤1、2和3,直到子数组的大小变为1。
步骤5 - 如果键值不存在于数组中,则算法返回搜索失败。
伪代码
二分查找算法的伪代码如下所示:
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x
set lowerBound = midPoint + 1
if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedure
分析
由于二分查找算法迭代地执行搜索,因此计算时间复杂度不像线性查找算法那样容易。
输入数组通过在每次不成功的迭代后将其划分为多个子数组来迭代地搜索。因此,形成的递归关系将是一个除法函数。
简单来说:
在第一次迭代中,在整个数组中搜索元素。因此,数组长度 = n。
在第二次迭代中,只搜索原始数组的一半。因此,数组长度 = n/2。
在第三次迭代中,搜索前一个子数组的一半。这里,数组长度将为 = n/4。
类似地,在第i次迭代中,数组长度将变为n/2i
为了实现成功的搜索,在最后一次迭代后,数组长度必须为1。因此:
n/2i = 1
这给了我们:
n = 2i
在两边应用对数,
log n = log 2i log n = i. log 2 i = log n
二分查找算法的时间复杂度为O(log n)
示例
为了使二分查找工作,目标数组必须已排序。我们将通过一个图解示例学习二分查找的过程。以下是我们的已排序数组,让我们假设我们需要使用二分查找搜索值31的位置。

首先,我们将使用此公式确定数组的一半:
mid = low + (high - low) / 2
这里是:0 + (9 - 0) / 2 = 4(4.5的整数部分)。所以,4是数组的中点。

现在我们将位置4处存储的值与要搜索的值31进行比较。我们发现位置4处的值是27,这并不匹配。由于该值大于27并且我们有一个已排序的数组,因此我们也知道目标值必须位于数组的上半部分。

我们将low更改为mid + 1,并再次找到新的mid值。
low = mid + 1 mid = low + (high - low) / 2
我们的新mid现在是7。我们将位置7处存储的值与我们的目标值31进行比较。
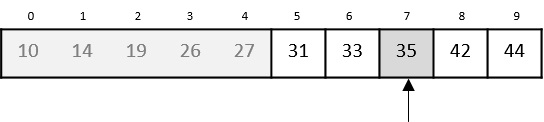
位置7处存储的值并不匹配,它小于我们正在寻找的值。因此,该值必须位于此位置的下半部分。

因此,我们再次计算mid。这次是5。
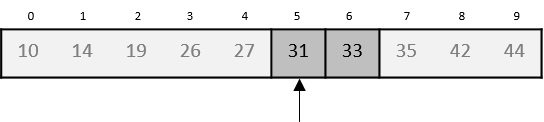
我们将位置5处存储的值与我们的目标值进行比较。我们发现它匹配。

我们得出结论,目标值31存储在位置5。
二分查找将可搜索项减半,从而大大减少了需要进行的比较次数。
实现
二分查找是一种快速搜索算法,其运行时间复杂度为O(log n)。这种搜索算法基于分治的思想。为了使该算法正常工作,数据集合必须已排序。
#include<stdio.h>
void binary_search(int a[], int low, int high, int key){
int mid;
mid = (low + high) / 2;
if (low <= high) {
if (a[mid] == key)
printf("Element found at index: %d\n", mid);
else if(key < a[mid])
binary_search(a, low, mid-1, key);
else if (a[mid] < key)
binary_search(a, mid+1, high, key);
} else if (low > high)
printf("Unsuccessful Search\n");
}
int main(){
int i, n, low, high, key;
n = 5;
low = 0;
high = n-1;
int a[10] = {12, 14, 18, 22, 39};
key = 22;
binary_search(a, low, high, key);
key = 23;
binary_search(a, low, high, key);
return 0;
}
输出
Element found at index: 3 Unsuccessful Search
#include <iostream>
using namespace std;
void binary_search(int a[], int low, int high, int key){
int mid;
mid = (low + high) / 2;
if (low <= high) {
if (a[mid] == key)
cout << "Element found at index: " << mid << endl;
else if(key < a[mid])
binary_search(a, low, mid-1, key);
else if (a[mid] < key)
binary_search(a, mid+1, high, key);
} else if (low > high)
cout << "Unsuccessful Search" <<endl;
}
int main(){
int i, n, low, high, key;
n = 5;
low = 0;
high = n-1;
int a[10] = {12, 14, 18, 22, 39};
key = 22;
binary_search(a, low, high, key);
key = 23;
binary_search(a, low, high, key);
return 0;
}
输出
Element found at index: 3 Unsuccessful Search
import java.io.*;
import java.util.*;
public class BinarySearch {
static void binary_search(int a[], int low, int high, int key) {
int mid = (low + high) / 2;
if (low <= high) {
if (a[mid] == key)
System.out.println("Element found at index: " + mid);
else if(key < a[mid])
binary_search(a, low, mid-1, key);
else if (a[mid] < key)
binary_search(a, mid+1, high, key);
} else if (low > high)
System.out.println("Unsuccessful Search");
}
public static void main(String args[]) {
int n, key, low, high;
n = 5;
low = 0;
high = n-1;
int a[] = {12, 14, 18, 22, 39};
key = 22;
binary_search(a, low, high, key);
key = 23;
binary_search(a, low, high, key);
}
}
输出
Element found at index: 3 Unsuccessful Search
def binary_search(a, low, high, key):
mid = (low + high) // 2
if (low <= high):
if(a[mid] == key):
print("The element is present at index:", mid)
elif(key < a[mid]):
binary_search(a, low, mid-1, key)
elif (a[mid] < key):
binary_search(a, mid+1, high, key)
if(low > high):
print("Unsuccessful Search")
a = [6, 12, 14, 18, 22, 39, 55, 182]
n = len(a)
low = 0
high = n-1
key = 22
binary_search(a, low, high, key)
key = 54
binary_search(a, low, high, key)
输出
The element is present at index: 4 Unsuccessful Search