- 数据结构与算法
- DSA - 首页
- DSA - 概览
- DSA - 环境设置
- DSA - 算法基础
- DSA - 渐进分析
- 数据结构
- DSA - 数据结构基础
- DSA - 数据结构和类型
- DSA - 数组数据结构
- 链表
- DSA - 链表数据结构
- DSA - 双向链表数据结构
- DSA - 循环链表数据结构
- 栈与队列
- DSA - 栈数据结构
- DSA - 表达式解析
- DSA - 队列数据结构
- 搜索算法
- DSA - 搜索算法
- DSA - 线性搜索算法
- DSA - 二分搜索算法
- DSA - 插值搜索
- DSA - 跳跃搜索算法
- DSA - 指数搜索
- DSA - 斐波那契搜索
- DSA - 子列表搜索
- DSA - 哈希表
- 排序算法
- DSA - 排序算法
- DSA - 冒泡排序算法
- DSA - 插入排序算法
- DSA - 选择排序算法
- DSA - 归并排序算法
- DSA - 希尔排序算法
- DSA - 堆排序
- DSA - 桶排序算法
- DSA - 计数排序算法
- DSA - 基数排序算法
- DSA - 快速排序算法
- 图数据结构
- DSA - 图数据结构
- DSA - 深度优先遍历
- DSA - 广度优先遍历
- DSA - 生成树
- 树数据结构
- DSA - 树数据结构
- DSA - 树的遍历
- DSA - 二叉搜索树
- DSA - AVL树
- DSA - 红黑树
- DSA - B树
- DSA - B+树
- DSA - 伸展树
- DSA - 字典树
- DSA - 堆数据结构
- 递归
- DSA - 递归算法
- DSA - 使用递归实现汉诺塔
- DSA - 使用递归实现斐波那契数列
- 分治法
- DSA - 分治法
- DSA - 最大最小问题
- DSA - Strassen矩阵乘法
- DSA - Karatsuba算法
- 贪心算法
- DSA - 贪心算法
- DSA - 旅行商问题(贪心算法)
- DSA - Prim最小生成树
- DSA - Kruskal最小生成树
- DSA - Dijkstra最短路径算法
- DSA - 地图着色算法
- DSA - 分数背包问题
- DSA - 带截止日期的作业排序
- DSA - 最佳合并模式算法
- 动态规划
- DSA - 动态规划
- DSA - 矩阵链乘法
- DSA - Floyd-Warshall算法
- DSA - 0-1背包问题
- DSA - 最长公共子序列算法
- DSA - 旅行商问题(动态规划)
- 近似算法
- DSA - 近似算法
- DSA - 顶点覆盖算法
- DSA - 集合覆盖问题
- DSA - 旅行商问题(近似算法)
- 随机化算法
- DSA - 随机化算法
- DSA - 随机化快速排序算法
- DSA - Karger最小割算法
- DSA - Fisher-Yates洗牌算法
- DSA有用资源
- DSA - 问答
- DSA - 快速指南
- DSA - 有用资源
- DSA - 讨论
分治算法

使用分治法,手头的问题被分解成更小的子问题,然后每个子问题独立解决。当我们继续将子问题分解成更小的子问题时,我们最终可能会到达一个无法再进行分解的阶段。这些最小的子问题使用原始解法进行解决,因为计算它们需要较少的时间。最后,将所有子问题的解合并起来,以获得原始问题的解。
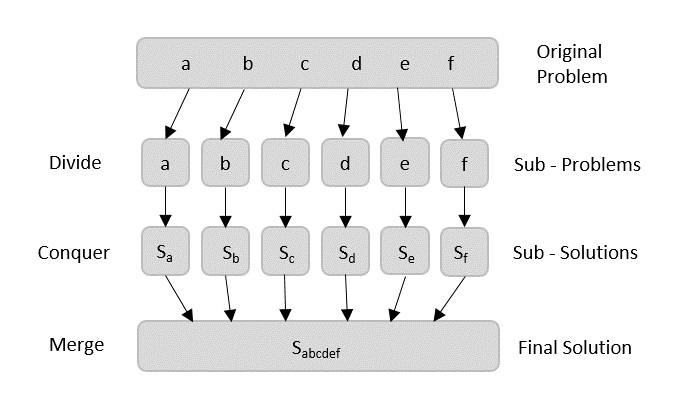
从广义上讲,我们可以将分治方法理解为一个三步过程。
分解/拆分
此步骤涉及将问题分解成更小的子问题。子问题应代表原始问题的一部分。此步骤通常采用递归方法来划分问题,直到没有子问题可以进一步划分。在此阶段,子问题的大小变为原子级别,但仍然代表实际问题的一部分。
解决/征服
此步骤接收许多需要解决的较小子问题。通常,在此级别,问题被认为是“自行解决”的。
合并/组合
当较小的子问题得到解决时,此阶段递归地将它们组合起来,直到它们形成原始问题的解决方案。这种算法方法以递归方式工作,并且解决和合并步骤非常接近,以至于它们看起来像一个步骤。
数组作为输入
各种算法可以以各种方式接收输入,以便可以使用分治技术解决它们。数组就是其中之一。在需要列表形式输入的算法中,例如各种排序算法,数组数据结构最常使用。
在下面的排序算法的输入中,数组输入被分解成子问题,直到它们无法进一步分解。
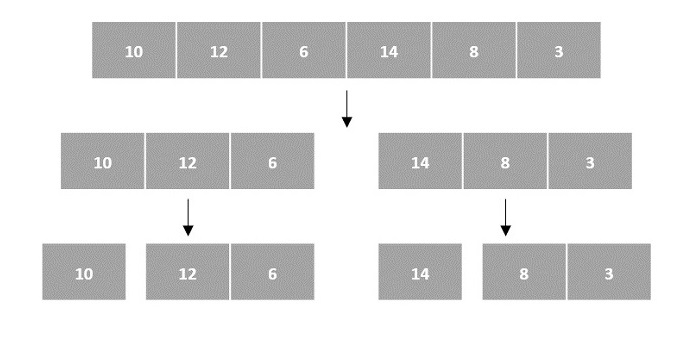
然后,子问题被排序(解决步骤)并合并以形成原始数组的解决方案(合并步骤)。
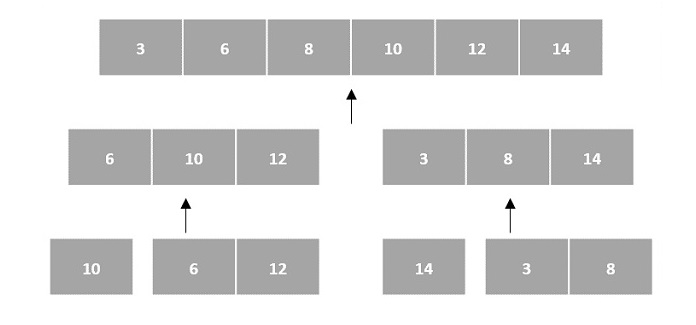
由于数组是索引的线性数据结构,因此排序算法最常使用数组数据结构来接收输入。
链表作为输入
另一种可用于接收分治算法输入的数据结构是链表(例如,使用链表进行归并排序)。与数组类似,链表也是线性数据结构,按顺序存储数据。
考虑链表上的归并排序算法;遵循非常流行的龟兔算法,列表被分割,直到它无法进一步分割。
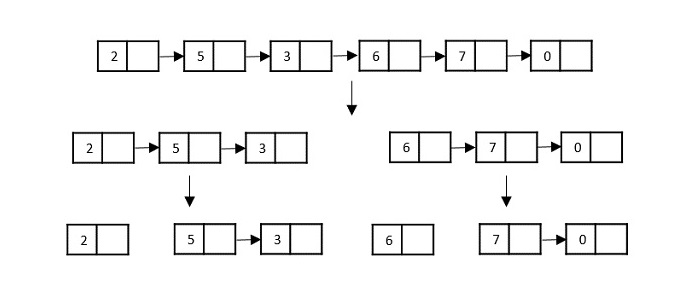
然后,对列表中的节点进行排序(解决)。然后递归地组合(或合并)这些节点,直到达到最终解决方案。
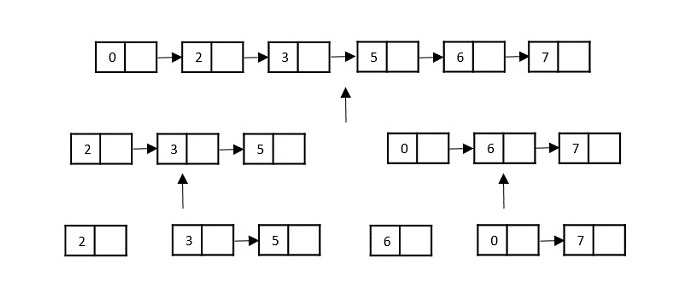
各种搜索算法也可以在链表数据结构上执行,但使用略有不同的技术,因为链表不是索引的线性数据结构。必须使用列表节点中可用的指针来处理它们。
分治法的优缺点
分治法支持并行性,因为子问题是独立的。因此,使用此技术设计的算法可以在多处理器系统或不同的机器上同时运行。
在这种方法中,大多数算法都是使用递归设计的,因此内存管理非常高。对于递归函数,使用堆栈,其中需要存储函数状态。
分治法的示例
以下计算机算法基于分治编程方法 -
最近点对(点)
有各种方法可以解决任何计算机问题,但上面提到的方法是分治法的很好的例子。