- 数据结构与算法
- DSA - 首页
- DSA - 概述
- DSA - 环境搭建
- DSA - 算法基础
- DSA - 渐进分析
- 数据结构
- DSA - 数据结构基础
- DSA - 数据结构和类型
- DSA - 数组数据结构
- 链表
- DSA - 链表数据结构
- DSA - 双向链表数据结构
- DSA - 循环链表数据结构
- 栈与队列
- DSA - 栈数据结构
- DSA - 表达式解析
- DSA - 队列数据结构
- 搜索算法
- DSA - 搜索算法
- DSA - 线性搜索算法
- DSA - 二分搜索算法
- DSA - 插值搜索
- DSA - 跳跃搜索算法
- DSA - 指数搜索
- DSA - 斐波那契搜索
- DSA - 子列表搜索
- DSA - 哈希表
- 排序算法
- DSA - 排序算法
- DSA - 冒泡排序算法
- DSA - 插入排序算法
- DSA - 选择排序算法
- DSA - 归并排序算法
- DSA - 希尔排序算法
- DSA - 堆排序
- DSA - 桶排序算法
- DSA - 计数排序算法
- DSA - 基数排序算法
- DSA - 快速排序算法
- 图数据结构
- DSA - 图数据结构
- DSA - 深度优先遍历
- DSA - 广度优先遍历
- DSA - 生成树
- 树数据结构
- DSA - 树数据结构
- DSA - 树的遍历
- DSA - 二叉搜索树
- DSA - AVL 树
- DSA - 红黑树
- DSA - B 树
- DSA - B+ 树
- DSA - 伸展树
- DSA - 字典树
- DSA - 堆数据结构
- 递归
- DSA - 递归算法
- DSA - 使用递归实现汉诺塔
- DSA - 使用递归实现斐波那契数列
- 分治法
- DSA - 分治法
- DSA - 最大-最小问题
- DSA - Strassen 矩阵乘法
- DSA - Karatsuba 算法
- 贪心算法
- DSA - 贪心算法
- DSA - 旅行商问题(贪心法)
- DSA - Prim 最小生成树
- DSA - Kruskal 最小生成树
- DSA - Dijkstra 最短路径算法
- DSA - 地图着色算法
- DSA - 分数背包问题
- DSA - 带截止日期的作业排序
- DSA - 最优合并模式算法
- 动态规划
- DSA - 动态规划
- DSA - 矩阵链乘法
- DSA - Floyd-Warshall 算法
- DSA - 0-1 背包问题
- DSA - 最长公共子序列算法
- DSA - 旅行商问题(动态规划法)
- 近似算法
- DSA - 近似算法
- DSA - 顶点覆盖算法
- DSA - 集合覆盖问题
- DSA - 旅行商问题(近似法)
- 随机化算法
- DSA - 随机化算法
- DSA - 随机化快速排序算法
- DSA - Karger 最小割算法
- DSA - Fisher-Yates 洗牌算法
- DSA 有用资源
- DSA - 问答
- DSA - 快速指南
- DSA - 有用资源
- DSA - 讨论
插值搜索算法

插值搜索是二分搜索的一种改进变体。这种搜索算法基于所需值的探测位置。为了使该算法正常工作,数据集合应以排序且均匀分布的形式存在。
二分搜索在时间复杂度方面相较于线性搜索具有巨大优势。线性搜索的最坏情况复杂度为 Ο(n),而二分搜索为 Ο(log n)。
在某些情况下,目标数据的存储位置可以提前知道。例如,在电话簿中,如果我们想搜索“Morpheus”的电话号码。在这里,线性搜索甚至二分搜索都会显得缓慢,因为我们可以直接跳转到存储以'M'开头的名称的内存空间。
二分搜索中的定位
在二分搜索中,如果未找到所需数据,则其余列表将被分成两部分,较低部分和较高部分。搜索将在其中一个部分进行。
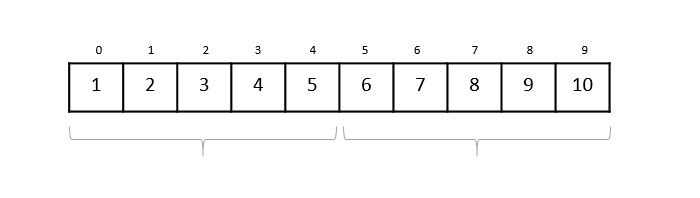
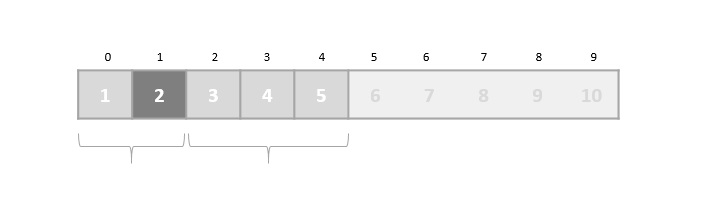
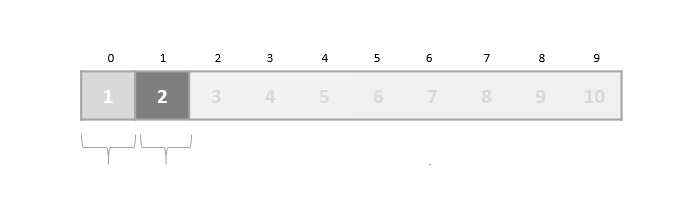
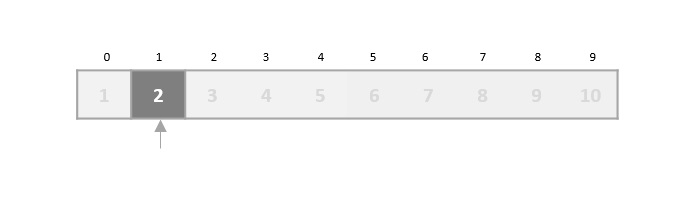
即使数据已排序,二分搜索也不会利用探测所需数据位置的优势。
插值搜索中的位置探测
插值搜索通过计算探测位置来查找特定项。最初,探测位置是集合中最中间项的位置。


如果找到匹配项,则返回该项的索引。为了将列表分成两部分,我们使用以下方法:
$$mid\, =\, Lo\, +\, \frac{\left ( Hi\, -\, Lo \right )\ast \left ( X\, -\, A\left [ Lo \right ] \right )}{A\left [ Hi \right ]\, -\, A\left [ Lo \right ]}$$
其中:
A = list Lo = Lowest index of the list Hi = Highest index of the list A[n] = Value stored at index n in the list
如果中间项大于该项,则在中间项右侧的子数组中再次计算探测位置。否则,在中间项左侧的子数组中搜索该项。此过程也将在子数组上继续,直到子数组的大小减小到零。
插值搜索算法
由于它是现有 BST 算法的改进,因此我们提到了使用位置探测搜索“目标”数据值索引的步骤:
1. Start searching data from middle of the list. 2. If it is a match, return the index of the item, and exit. 3. If it is not a match, probe position. 4. Divide the list using probing formula and find the new middle. 5. If data is greater than middle, search in higher sub-list. 6. If data is smaller than middle, search in lower sub-list. 7. Repeat until match.
伪代码
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X
Set Lo to Mid+1
else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End Procedure
分析
插值搜索算法的运行时复杂度为 Ο(log (log n)),而在有利情况下,BST 的运行时复杂度为 Ο(log n)。
示例
为了理解插值搜索中涉及的逐步过程,让我们看一个示例并围绕它进行操作。
考虑下面给出的已排序元素数组:
让我们搜索元素 19。
解决方案
与二分搜索不同,在这种方法中,中间点是使用以下公式选择的:
$$mid\, =\, Lo\, +\, \frac{\left ( Hi\, -\, Lo \right )\ast \left ( X\, -\, A\left [ Lo \right ] \right )}{A\left [ Hi \right ]\, -\, A\left [ Lo \right ]}$$
因此,在此给定的数组输入中,
Lo = 0, A[Lo] = 10 Hi = 9, A[Hi] = 44 X = 19
应用公式查找列表中的中间点,我们得到
$$mid\, =\, 0\, +\, \frac{\left ( 9\, -\, 0 \right )\ast \left ( 19\, -\, 10 \right )}{44\, -\, 10}$$
$$mid\, =\, \frac{9\ast 9}{34}$$
$$mid\, =\, \frac{81}{34}\,=\,2.38$$
由于 mid 是索引值,因此我们只考虑小数的整数部分。即,mid = 2。
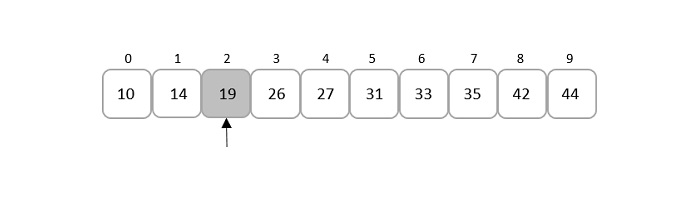
将给定的键元素(即 19)与存在于中间索引处的元素进行比较,发现这两个元素匹配。
因此,该元素位于索引 2 处。
实现
插值搜索是二分搜索的一种改进变体。这种搜索算法基于所需值的探测位置。为了使该算法正常工作,数据集合应以排序且均匀分布的形式存在。
#include<stdio.h>
#define MAX 10
// array of items on which linear search will be conducted.
int list[MAX] = { 10, 14, 19, 26, 27, 31, 33, 35, 42, 44 };
int interpolation_search(int data){
int lo = 0;
int hi = MAX - 1;
int mid = -1;
int comparisons = 1;
int index = -1;
while(lo <= hi) {
printf("Comparison %d \n" , comparisons ) ;
printf("lo : %d, list[%d] = %d\n", lo, lo, list[lo]);
printf("hi : %d, list[%d] = %d\n", hi, hi, list[hi]);
comparisons++;
// probe the mid point
mid = lo + (((double)(hi - lo) / (list[hi] - list[lo])) * (data - list[lo]));
printf("mid = %d\n",mid);
// data found
if(list[mid] == data) {
index = mid;
break;
} else {
if(list[mid] < data) {
// if data is larger, data is in upper half
lo = mid + 1;
} else {
// if data is smaller, data is in lower half
hi = mid - 1;
}
}
}
printf("Total comparisons made: %d", --comparisons);
return index;
}
int main(){
//find location of 33
int location = interpolation_search(33);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("Element not found.");
return 0;
}
输出
Comparison 1 lo : 0, list[0] = 10 hi : 9, list[9] = 44 mid = 6 Total comparisons made: 1 Element found at location: 7
#include<iostream>
using namespace std;
#define MAX 10
// array of items on which linear search will be conducted.
int list[MAX] = { 10, 14, 19, 26, 27, 31, 33, 35, 42, 44 };
int interpolation_search(int data){
int lo = 0;
int hi = MAX - 1;
int mid = -1;
int comparisons = 1;
int index = -1;
while(lo <= hi) {
cout << "Comparison " << comparisons << endl;
cout << "lo : " << lo << " list[" << lo << "] = " << list[lo] << endl;
cout << "hi : " << hi << " list[" << hi << "] = " << list[hi] << endl;
comparisons++;
// probe the mid point
mid = lo + (((double)(hi - lo) / (list[hi] - list[lo])) * (data - list[lo]));
cout << "mid = " << mid;
// data found
if(list[mid] == data) {
index = mid;
break;
} else {
if(list[mid] < data) {
// if data is larger, data is in upper half
lo = mid + 1;
} else {
// if data is smaller, data is in lower half
hi = mid - 1;
}
}
}
cout << "\nTotal comparisons made: " << (--comparisons);
return index;
}
int main(){
//find location of 33
int location = interpolation_search(33);
// if element was found
if(location != -1)
cout << "\nElement found at location: " << (location+1);
else
cout << "Element not found.";
return 0;
}
输出
Comparison 1 lo : 0 list[0] = 10 hi : 9 list[9] = 44 mid = 6 Total comparisons made: 1 Element found at location: 7
import java.io.*;
public class InterpolationSearch {
static int interpolation_search(int data, int[] list) {
int lo = 0;
int hi = list.length - 1;
int mid = -1;
int comparisons = 1;
int index = -1;
while(lo <= hi) {
System.out.println("Comparison " + comparisons);
System.out.println("lo : " + lo + " list[" + lo + "] = " + list[lo]);
System.out.println("hi : " + hi + " list[" + hi + "] = " + list[hi]);
comparisons++;
// probe the mid point
mid = lo + (((hi - lo) * (data - list[lo])) / (list[hi] - list[lo]));
System.out.println("mid = " + mid);
// data found
if(list[mid] == data) {
index = mid;
break;
} else {
if(list[mid] < data) {
// if data is larger, data is in upper half
lo = mid + 1;
} else {
// if data is smaller, data is in lower half
hi = mid - 1;
}
}
}
System.out.println("Total comparisons made: " + (--comparisons));
return index;
}
public static void main(String args[]) {
int[] list = { 10, 14, 19, 26, 27, 31, 33, 35, 42, 44 };
//find location of 33
int location = interpolation_search(33, list);
// if element was found
if(location != -1)
System.out.println("Element found at location: " + (location+1));
else
System.out.println("Element not found.");
}
}
输出
Comparison 1 lo : 0 list[0] = 10 hi : 9 list[9] = 44 mid = 6 Total comparisons made: 1 Element found at location: 7
def interpolation_search( data, arr):
lo = 0
hi = len(arr) - 1
mid = -1
comparisons = 1
index = -1
while(lo <= hi):
print("Comparison ", comparisons)
print("lo : ", lo)
print("list[", lo, "] = ")
print(arr[lo])
print("hi : ", hi)
print("list[", hi, "] = ")
print(arr[hi])
comparisons = comparisons + 1
#probe the mid point
mid = lo + (((hi - lo) * (data - arr[lo])) // (arr[hi] - arr[lo]))
print("mid = ", mid)
#data found
if(arr[mid] == data):
index = mid
break
else:
if(arr[mid] < data):
#if data is larger, data is in upper half
lo = mid + 1
else:
#if data is smaller, data is in lower half
hi = mid - 1
print("Total comparisons made: ")
print(comparisons-1)
return index
arr = [10, 14, 19, 26, 27, 31, 33, 35, 42, 44]
#find location of 33
location = interpolation_search(33, arr)
#if element was found
if(location != -1):
print("Element found at location: ", (location+1))
else:
print("Element not found.")
输出
Comparison 1 lo : 0 list[ 0 ] = 10 hi : 9 list[ 9 ] = 44 mid = 6 Total comparisons made: 1 Element found at location: 7