- 数据结构与算法
- DSA - 首页
- DSA - 概述
- DSA - 环境搭建
- DSA - 算法基础
- DSA - 渐进分析
- 数据结构
- DSA - 数据结构基础
- DSA - 数据结构和类型
- DSA - 数组数据结构
- 链表
- DSA - 链表数据结构
- DSA - 双向链表数据结构
- DSA - 循环链表数据结构
- 栈与队列
- DSA - 栈数据结构
- DSA - 表达式解析
- DSA - 队列数据结构
- 搜索算法
- DSA - 搜索算法
- DSA - 线性搜索算法
- DSA - 二分搜索算法
- DSA - 插值搜索
- DSA - 跳跃搜索算法
- DSA - 指数搜索
- DSA - 斐波那契搜索
- DSA - 子列表搜索
- DSA - 哈希表
- 排序算法
- DSA - 排序算法
- DSA - 冒泡排序算法
- DSA - 插入排序算法
- DSA - 选择排序算法
- DSA - 归并排序算法
- DSA - 希尔排序算法
- DSA - 堆排序
- DSA - 桶排序算法
- DSA - 计数排序算法
- DSA - 基数排序算法
- DSA - 快速排序算法
- 图数据结构
- DSA - 图数据结构
- DSA - 深度优先遍历
- DSA - 广度优先遍历
- DSA - 生成树
- 树数据结构
- DSA - 树数据结构
- DSA - 树的遍历
- DSA - 二叉搜索树
- DSA - AVL 树
- DSA - 红黑树
- DSA - B 树
- DSA - B+ 树
- DSA - 伸展树
- DSA - 字典树
- DSA - 堆数据结构
- 递归
- DSA - 递归算法
- DSA - 使用递归实现汉诺塔
- DSA - 使用递归实现斐波那契数列
- 分治法
- DSA - 分治法
- DSA - 最大最小问题
- DSA - Strassen 矩阵乘法
- DSA - Karatsuba 算法
- 贪心算法
- DSA - 贪心算法
- DSA - 旅行商问题(贪心算法)
- DSA - Prim 最小生成树
- DSA - Kruskal 最小生成树
- DSA - Dijkstra 最短路径算法
- DSA - 地图着色算法
- DSA - 分数背包问题
- DSA - 带截止日期的作业排序
- DSA - 最优合并模式算法
- 动态规划
- DSA - 动态规划
- DSA - 矩阵链乘法
- DSA - Floyd-Warshall 算法
- DSA - 0-1 背包问题
- DSA - 最长公共子序列算法
- DSA - 旅行商问题(动态规划)
- 近似算法
- DSA - 近似算法
- DSA - 顶点覆盖算法
- DSA - 集合覆盖问题
- DSA - 旅行商问题(近似算法)
- 随机化算法
- DSA - 随机化算法
- DSA - 随机化快速排序算法
- DSA - Karger 最小割算法
- DSA - Fisher-Yates 洗牌算法
- DSA 有用资源
- DSA - 问答
- DSA - 快速指南
- DSA - 有用资源
- DSA - 讨论
数据结构 - 排序技术
排序是指以特定格式排列数据。排序算法指定以特定顺序排列数据的方式。最常见的顺序是数值顺序或字典顺序。
排序的重要性在于,如果数据以排序的方式存储,则可以将数据搜索优化到非常高的水平。排序还用于以更易读的格式表示数据。以下是现实生活中排序的一些示例:
电话簿 - 电话簿按人名存储电话号码,以便可以轻松搜索姓名。
字典 - 字典按字母顺序存储单词,以便于搜索任何单词。
原地排序和非原地排序
排序算法可能需要一些额外的空间来比较和临时存储少量数据元素。这些算法不需要任何额外的空间,并且据说排序是在原地发生的,或者例如,在数组本身内。这称为原地排序。冒泡排序是原地排序的一个例子。
但是,在某些排序算法中,程序需要大于或等于被排序元素的空间。使用等于或更多空间的排序称为非原地排序。归并排序是非原地排序的一个例子。
稳定排序和非稳定排序
如果排序算法在排序内容后不更改其出现顺序的相似内容,则称为稳定排序。
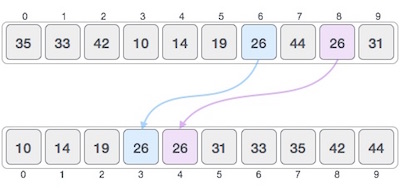
如果排序算法在排序内容后更改其出现顺序的相似内容,则称为不稳定排序。
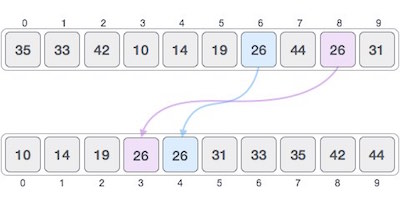
当我们希望维护原始元素的顺序(例如元组)时,算法的稳定性很重要。
自适应排序算法和非自适应排序算法
如果排序算法利用要排序的列表中已经“排序”的元素,则称该排序算法为自适应的。也就是说,在排序时,如果源列表中有一些元素已经排序,则自适应算法将考虑这一点,并会尝试不重新排序它们。
非自适应算法是不考虑已经排序的元素的算法。它们试图强制重新排序每个元素以确认其排序性。
重要术语
在讨论排序技术时,通常会创造一些术语,以下是它们的简要介绍:
升序
如果后续元素大于前一个元素,则称一系列值处于升序。例如,1、3、4、6、8、9 按升序排列,因为每个后续元素都大于前一个元素。
降序
如果后续元素小于当前元素,则称一系列值处于降序。例如,9、8、6、4、3、1 按降序排列,因为每个后续元素都小于前一个元素。
非递增序
如果后续元素小于或等于序列中其前一个元素,则称一系列值处于非递增序。当序列包含重复值时,会出现此顺序。例如,9、8、6、3、3、1 按非递增序排列,因为每个后续元素都小于或等于(对于 3)但不大于任何前一个元素。
非递减序
如果后续元素大于或等于序列中其前一个元素,则称一系列值处于非递减序。当序列包含重复值时,会出现此顺序。例如,1、3、3、6、8、9 按非递减序排列,因为每个后续元素都大于或等于(对于 3)但不小于前一个元素。
有几种可用的排序技术来对各种数据结构的内容进行排序。以下是一些: