- Unix Commands Reference
- Unix Commands - Home
awk Command in Linux
awk is a scripting language designed for advanced text manipulation. With awk command, you can process data line by line, compare patterns, split records into fields and perform other useful actions.
The awk command is different from other programming languages because of its data-driven nature. It means that you define actions to be performed against input text. If you want to transform your data files and produce formatted reports, then awk should be one of the most preferable choices for this action.
Table of Contents
Here is a comprehensive guide to the options available with the awk command −
- How to Install awk Command in Linux?
- Syntax for awk Command in Linux
- Different Options Available for awk Command
- Examples of awk Command in Linux
How to Install awk Command in Linux?
Most Linux distributions come with awk preinstalled. However, in case it is not available, you can directly install from the official Linux repository. Different Linux systems use different package managers to install a package from a Linux repository.
For example, to install awk command on Debian-based distributions like Ubuntu, Debian, and other such systems, you can use the apt command provided below −
sudo apt install gawk
The REHL, CentOS and Fedora users can use the following command to install awk command-line utility on their systems −
sudo yum install gawk
If you are using Alpine Linux, you can use the below-given command to install awk on your system −
sudo apk add gawk
Syntax for awk Command in Linux
The basic syntax of awk command on Linux is provided below −
awk options 'selection _criteria {action }' input-file > output-file
Here,
- options are different flags that alter awk behavior.
- selection_criteria is a pattern to match against records.
- action is the operation to perform on matched lines.
- input-file is the file you want to process.
- output-file is the file where results are written.
Different Options Available for awk Command
There are different options available for awk command, there are discussed in the table below −
| Option | Description |
|---|---|
| -F fs | Set the input field separator. The default value is the whitespace. |
| -f program-file | Read the awk program from a file. |
| -v var=value | Declares a variable. |
Essential awk Variables and Separators
In this section, we will explore the fundamental variables used in awk, including field variables, record-related variables, and separators.
- Field Variables of awk − awk uses field variables like $1, $2, $3, etc., to represent individual pieces of data within a line (record). For example, $1 refers to the first field (usually the first word) of a line, and $0 represents the entire line.
- NR (Number of Records) − NR keeps track of the current count of input records (usually lines) processed by awk.
- NF (Number of Fields) − NF counts the number of fields within the current input record (line) and helps when you need to work with specific columns.
- FS (Field Separator) − FS defines the character used to split fields on an input line. By default, it is whitespace (space or tab), but you can change it (e.g., to a comma) using -F option.
- RS (Record Separator) − RS stores the current record separator character (usually a newline). It determines how awk breaks input into records.
- OFS (Output Field Separator) − OFS separates fields when awk prints them; the default is a blank space, but you can customize it.
- ORS (Output Record Separator) − ORS separates output lines when awk prints results; by default, it’s a newline character.
Examples of awk Command in Linux
Let’s explore some examples of awk commands on Linux systems. For examples, we will use an input file named file.txt that includes the following text −
CREDITS, EXPDATE, USER, GROUP 99, 01 jan 2024, mark, team:admin 52, 08 feb 2024, tom, team 45, 12 march 2024, david, team 32, 20 apr 2023, jerry, team:support
Note − The file name and text inside the file will be different in your case.
Default Behavior
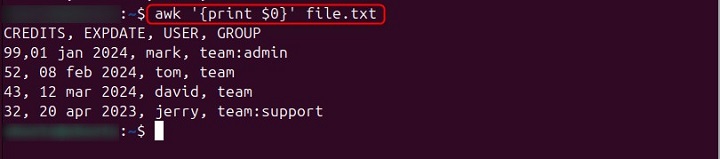
By default, awk processes data one record at a time, where a record is typically a line from the input file. You can print the entire record (line) using the following command −
awk '{print $0}' myfile.txt
Print Lines Matching a Pattern
You can also use awk to print lines that match a specific pattern. For example, to print lines containing the word “CREDITS”, use the following command −
awk '/CREDITS/ {print}' file.txt

Split a Line into Fields
awk automatically splits each record into fields based on a delimiter (usually whitespace). To print the first field (usually the first word) of each record, simply run the below-given command −
awk '{print $1}' file.txt

The above command will print the first word from each line in a file.
Print Specific Columns
You can also extract specific columns from a file using awk. For example, to print the second and fourth columns, you can use the following command −
awk '{print $2, $4}' file.txt

Conditional Actions
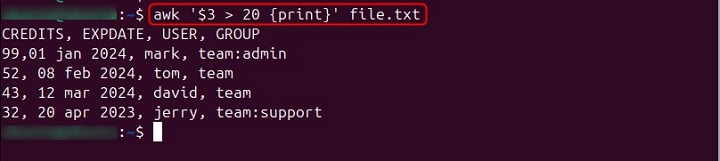
With awk, you can also perform actions based on conditions. For example, to print lines where the third column value is greater than 20, use the below-given command −
awk '$3 > 20 {print}' file.txt
Custom Delimiters
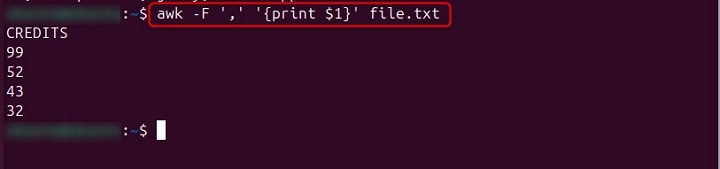
If your data is delimited by a character other than whitespace (e.g., comma), specify it using -F. To print the first field (using a comma as delimiter) −
awk -F',' '{print $1}' file.csv
Summarize Data
To calculate the total of a specific column, for example column 3, use the following command −
awk '{sum+=$3} END {print "Total =", sum}' file.txt

Print Each Line with Line Numbers
To print each line with the desired line number, use the below-given command −
awk '{print NR,$0}' file.txt

Here, NR will keep track of the number of records (lines) processed.
Extract First and Last Fields
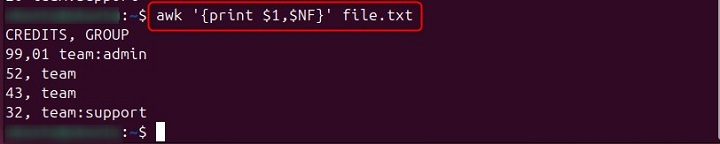
If you want to extract the first field (CREDIT) and the last field (GROUP) from each line from the given file, then use the following command −
awk '{print $1,$NF}' file.txt
Prepend Line Numbers to Each Line
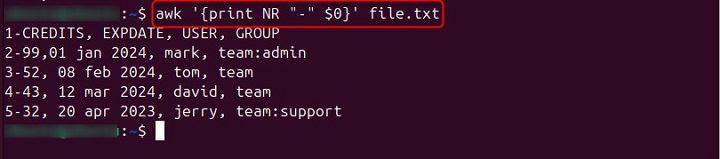
If you want to prepend each line in the input file with its line number (NR), followed by a hyphen and the entire content of that line, you can use the following awk command −
awk '{print NR "- " $0 }' file.txt
In this way, you can use the awk command to manipulate your text according to your needs.
Conclusion
awk is a powerful scripting language used in Linux for manipulating texts according to the user's needs. This tutorial has provided an overview of awk with its syntax and different options that can be used with the awk command.